3차원 신경망 표현을 활용한 얼굴 이미지 통합 설명
📝 원문 정보
- Title: Using Gaussian Splats to Create High-Fidelity Facial Geometry and Texture
- ArXiv ID: 2512.16397
- 발행일: 2025-12-18
- 저자: Haodi He, Jihun Yu, Ronald Fedkiw
📝 초록 (Abstract)
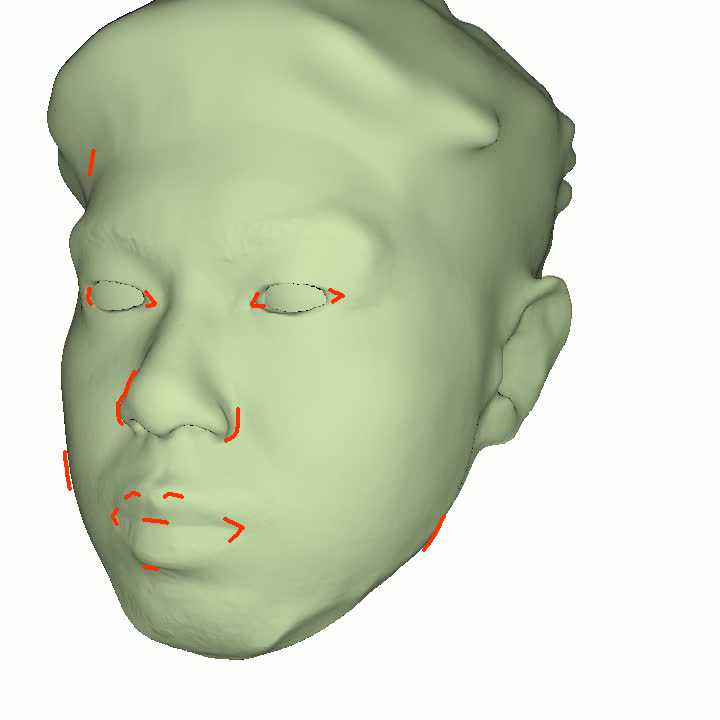
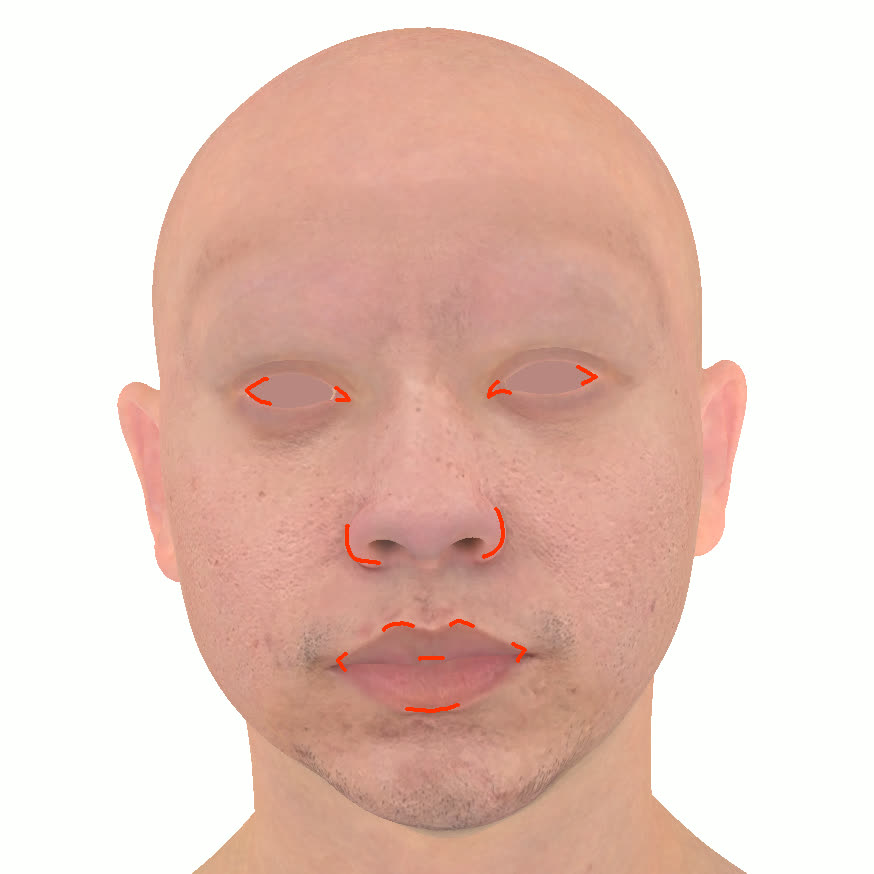
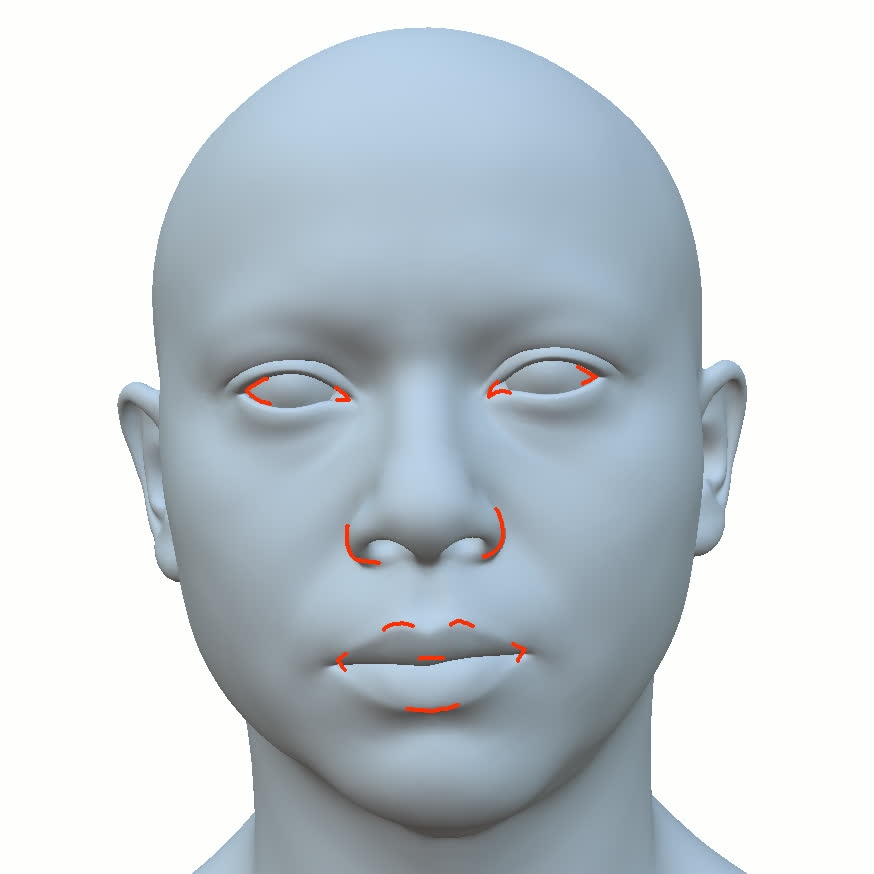
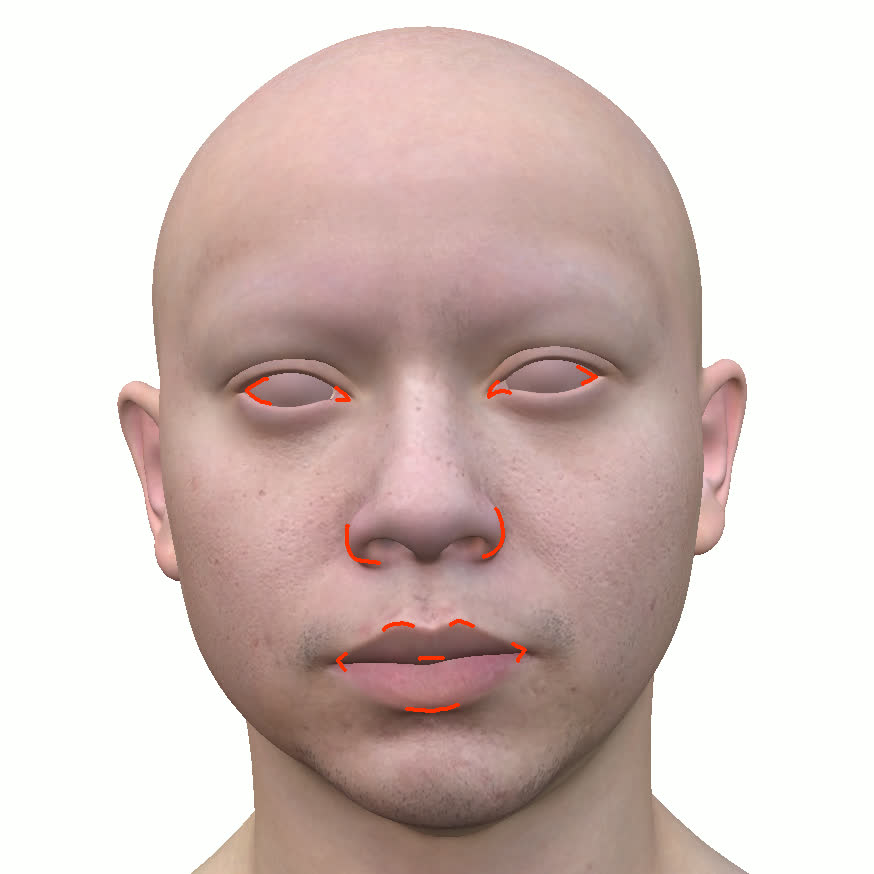
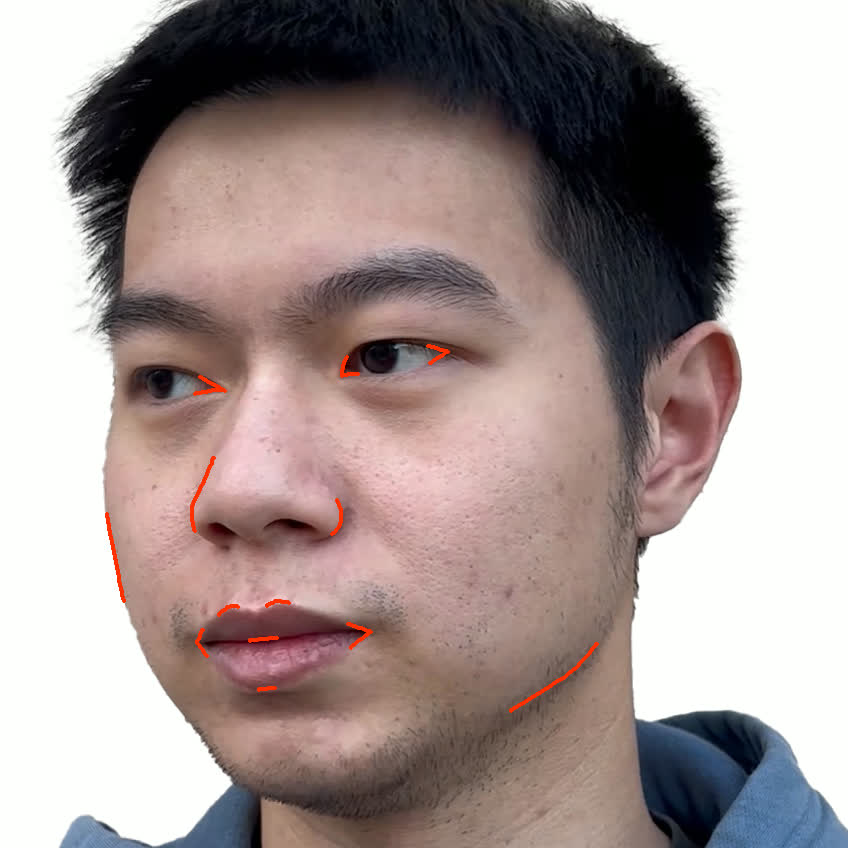
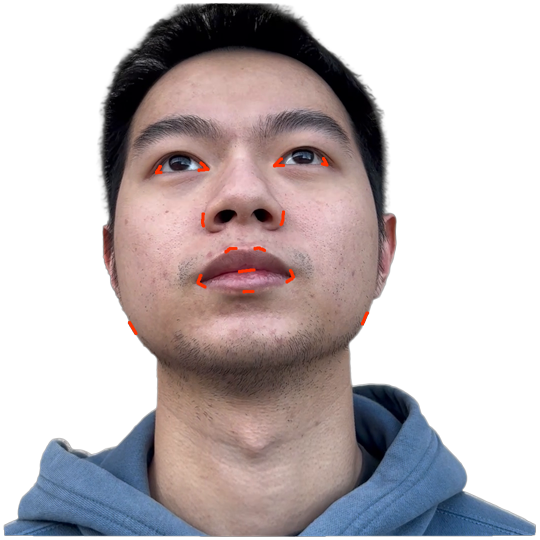
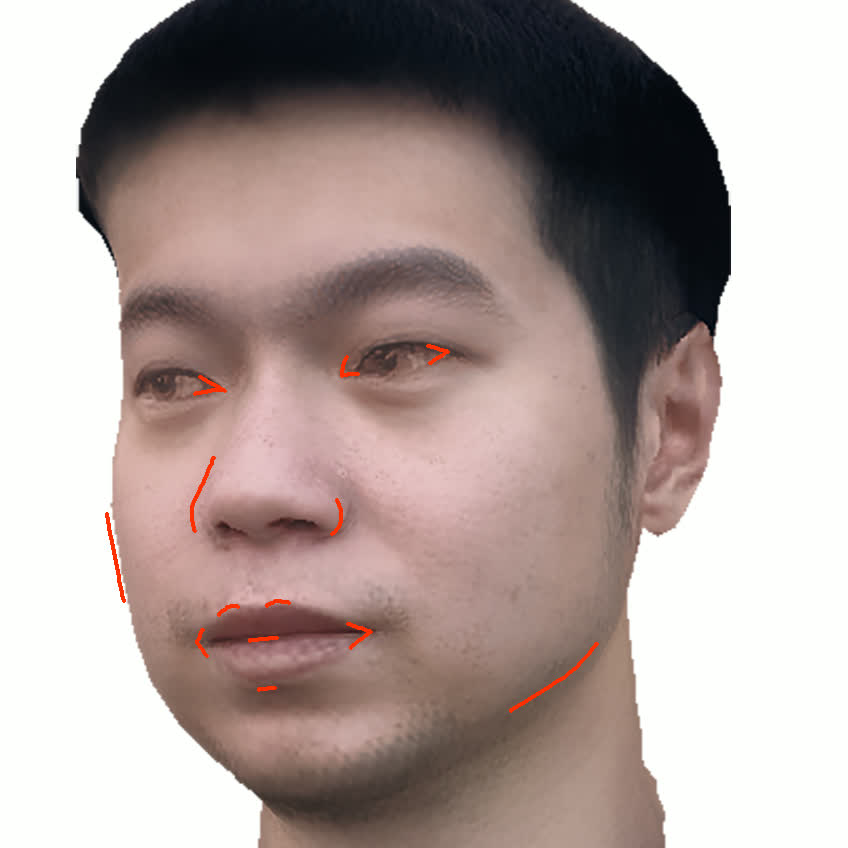
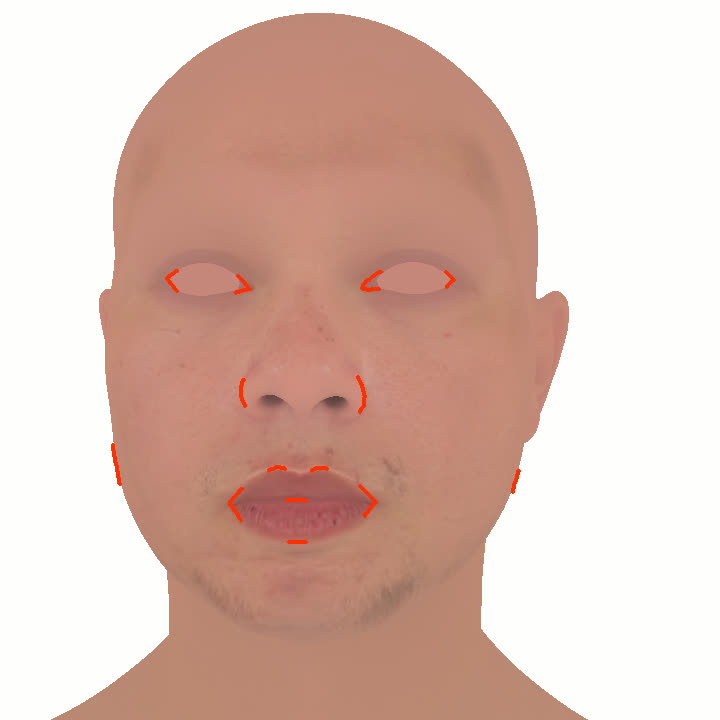
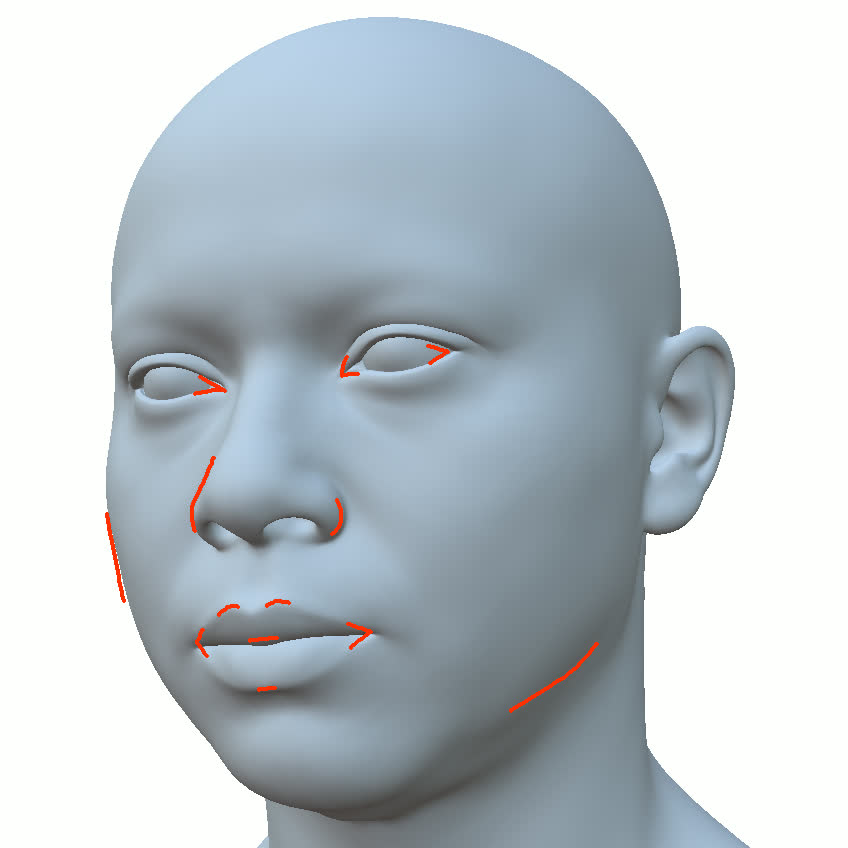
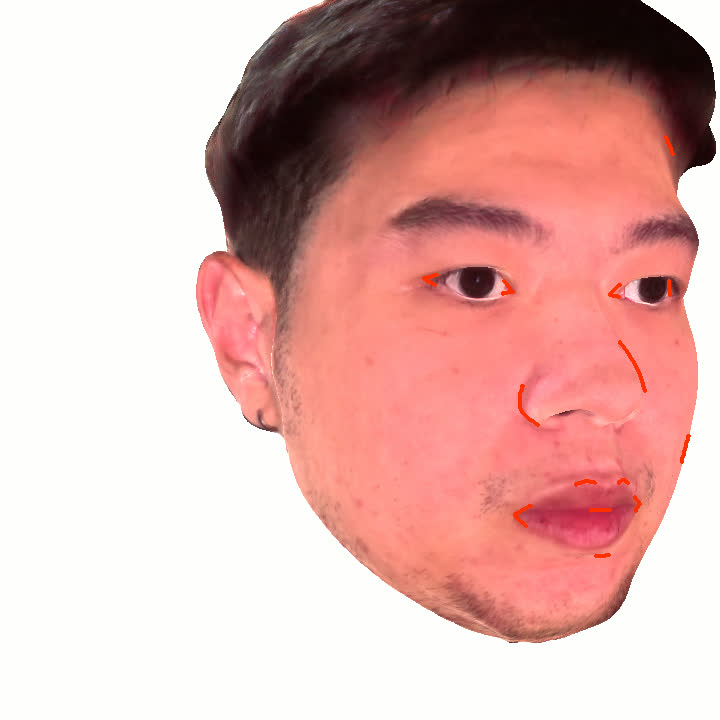
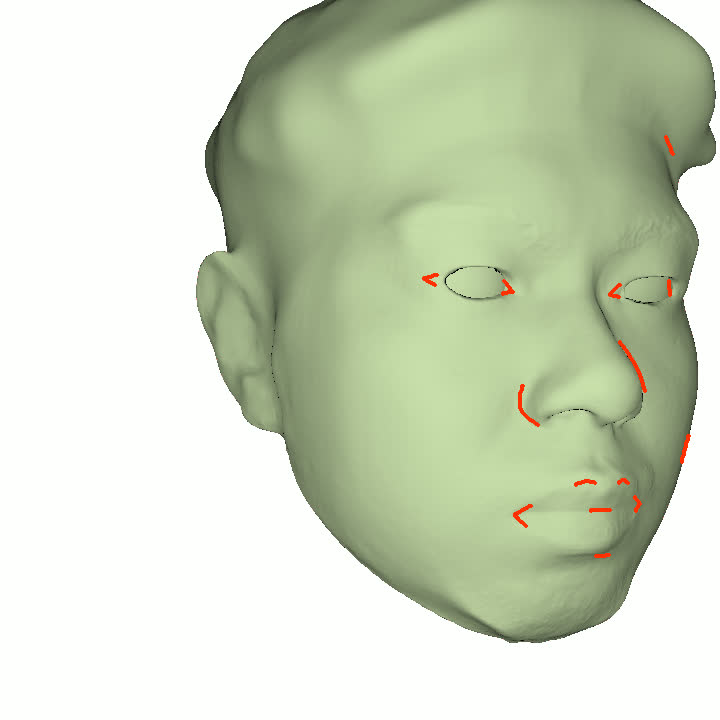
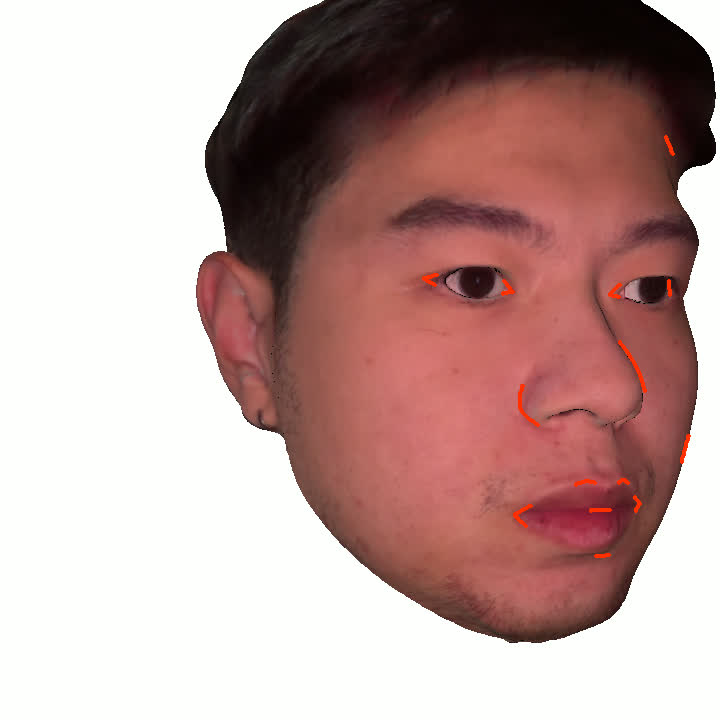
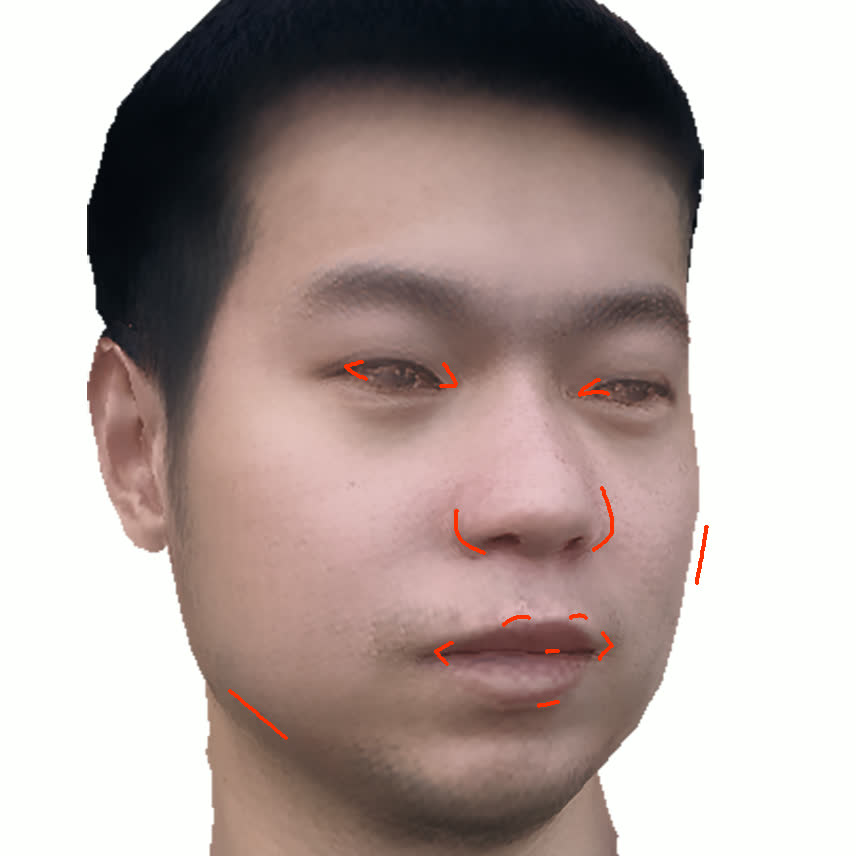
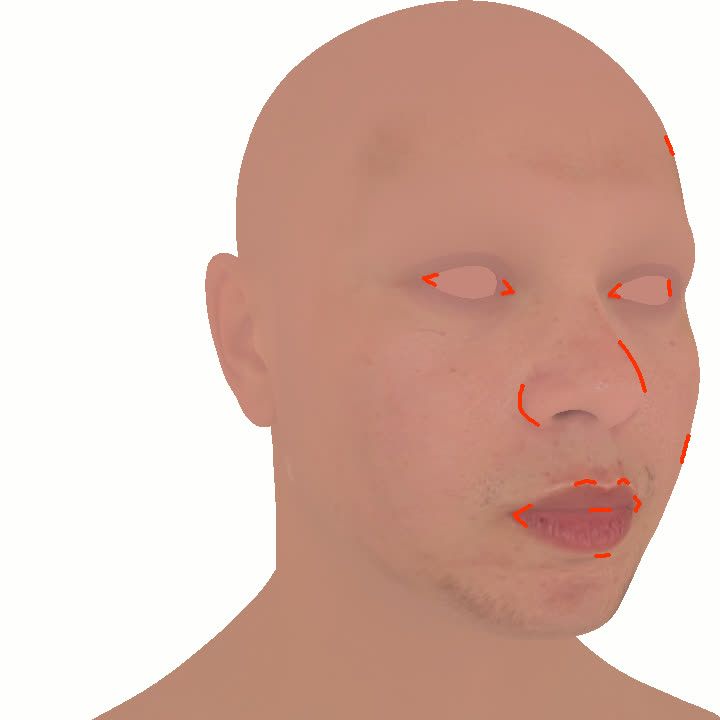
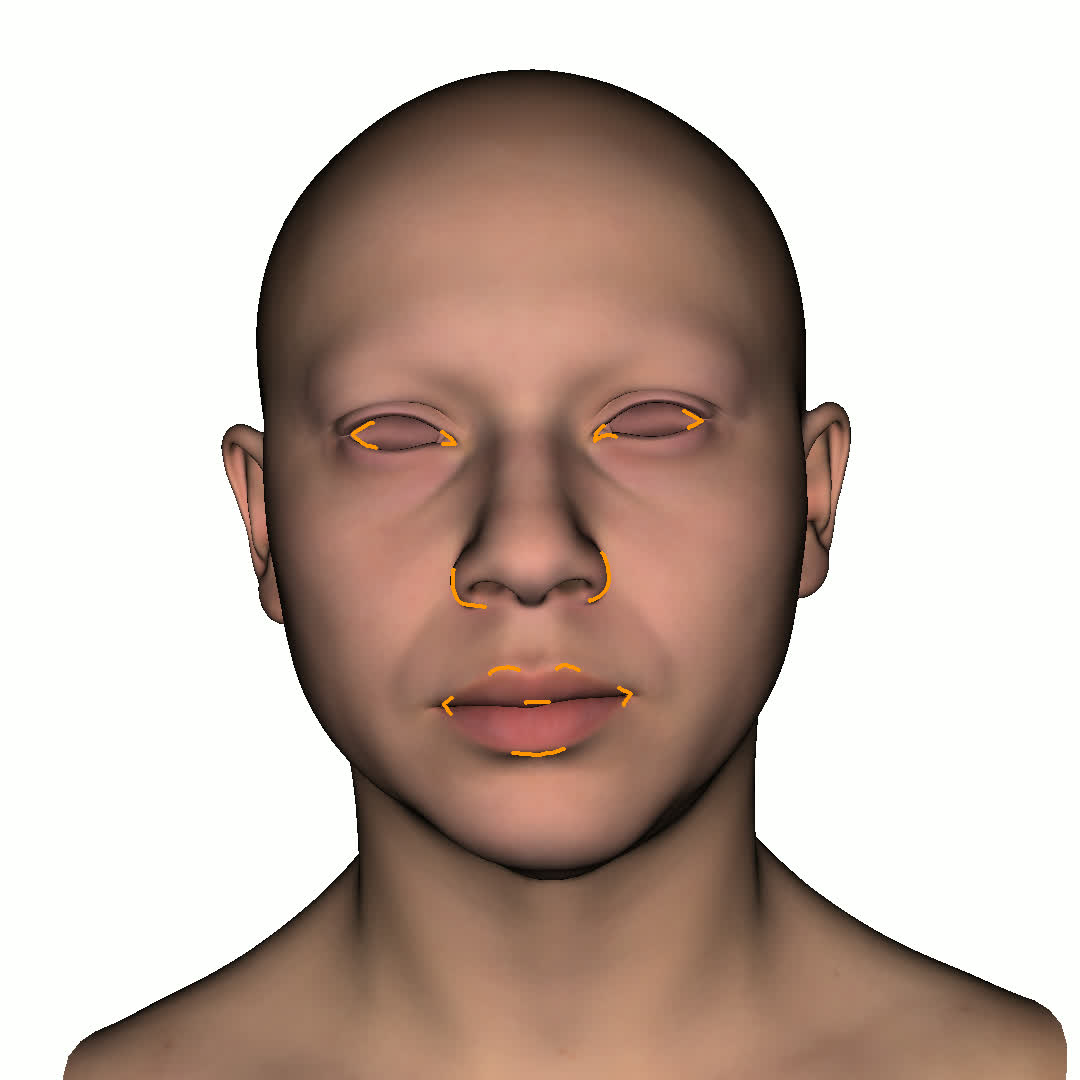
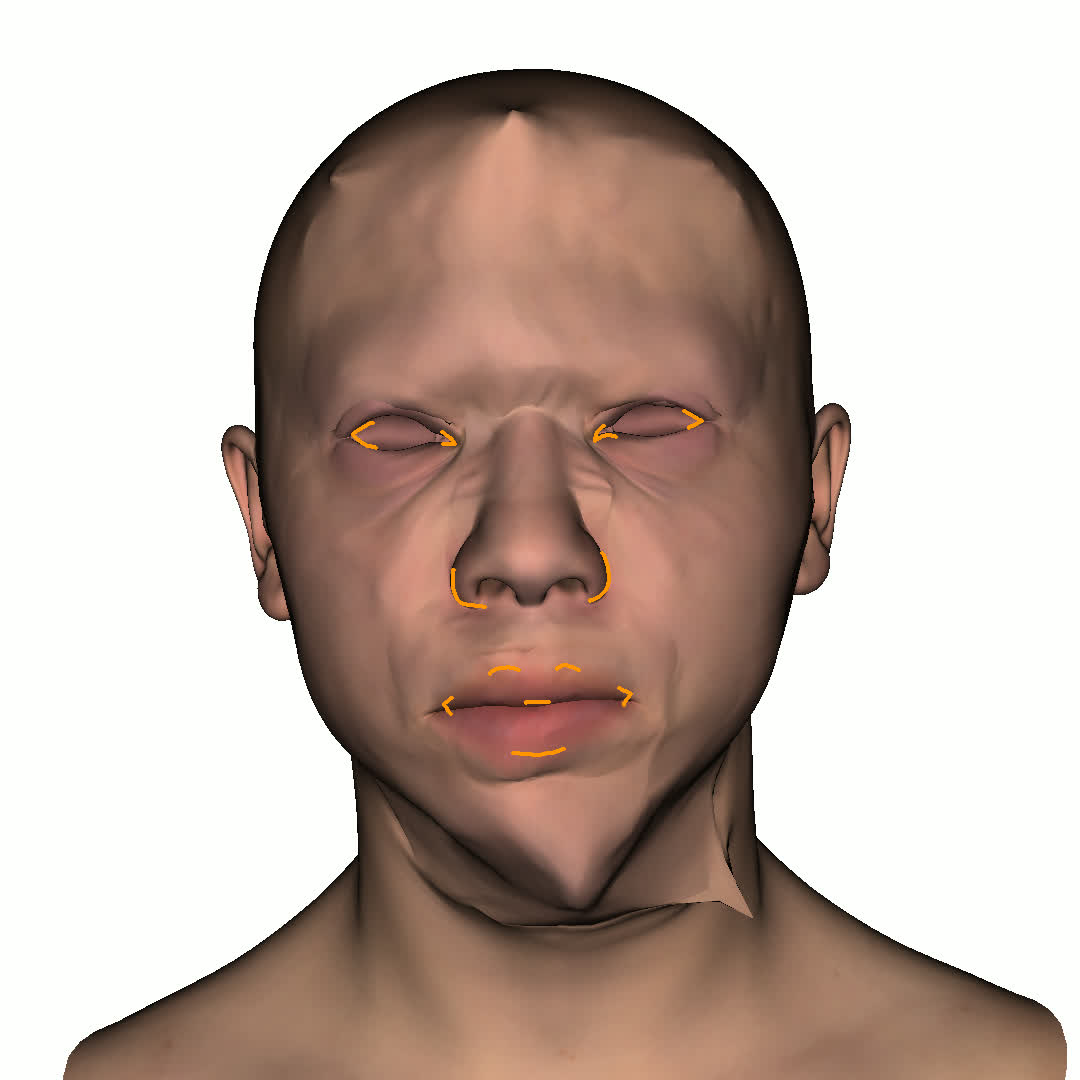
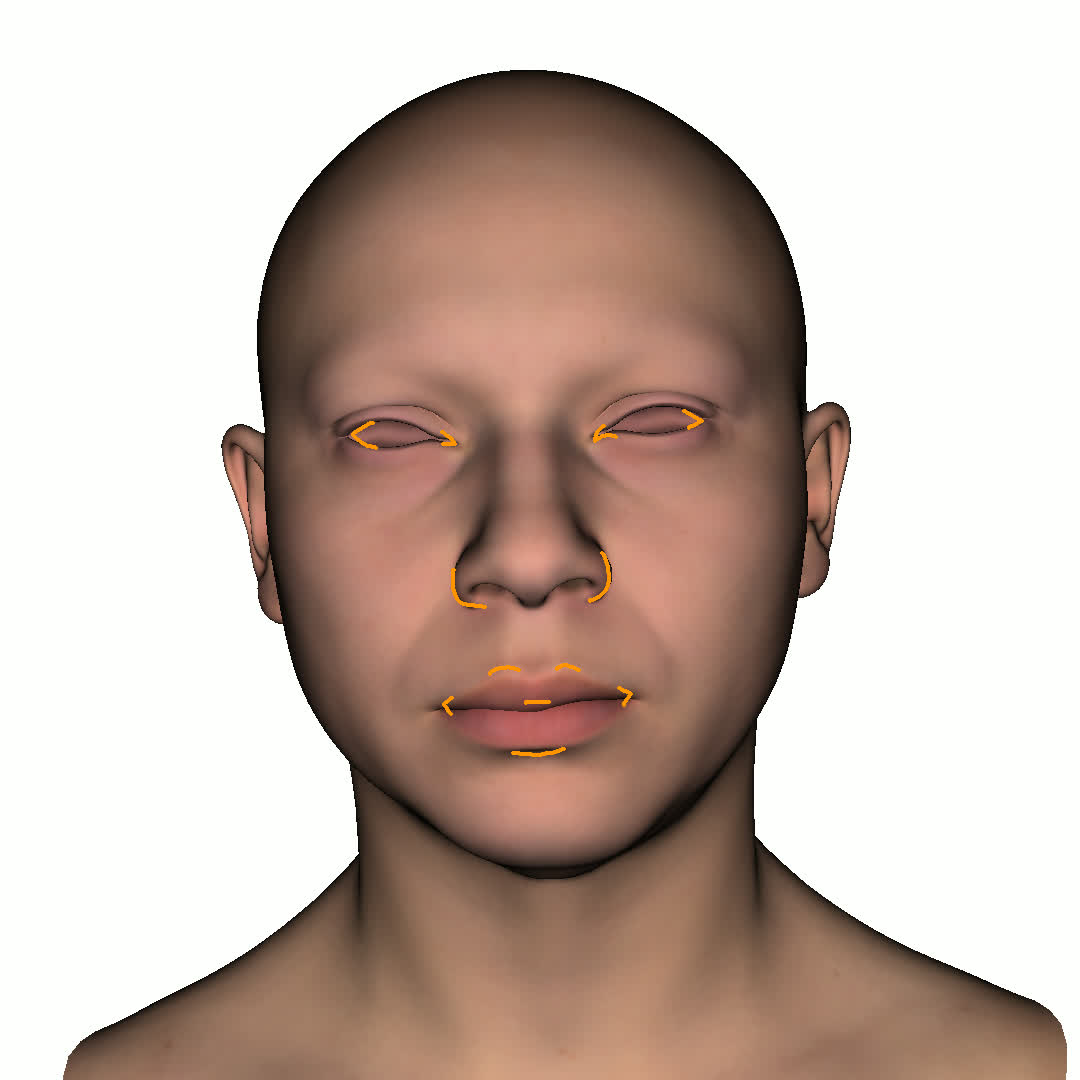
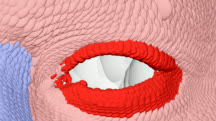
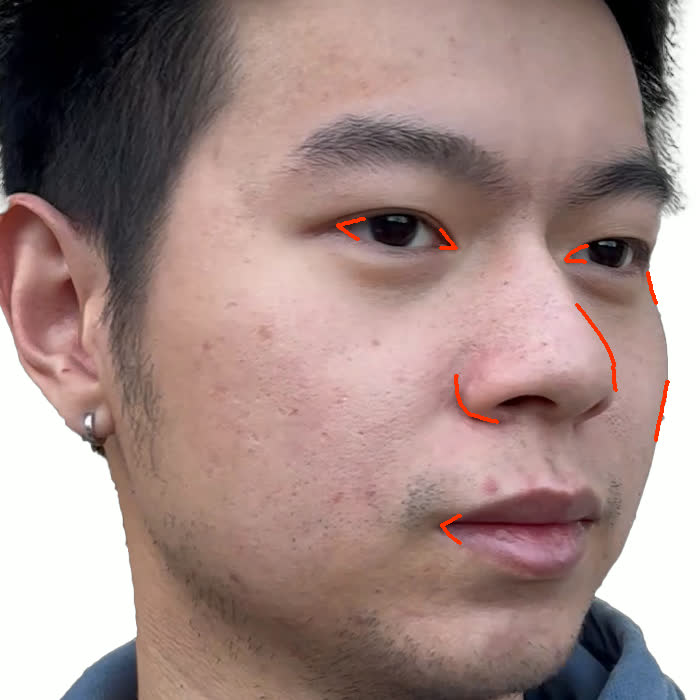
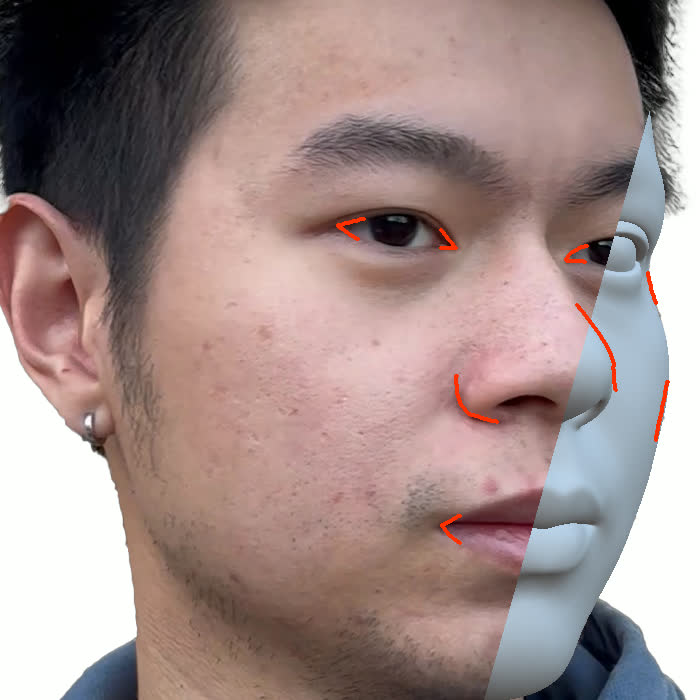
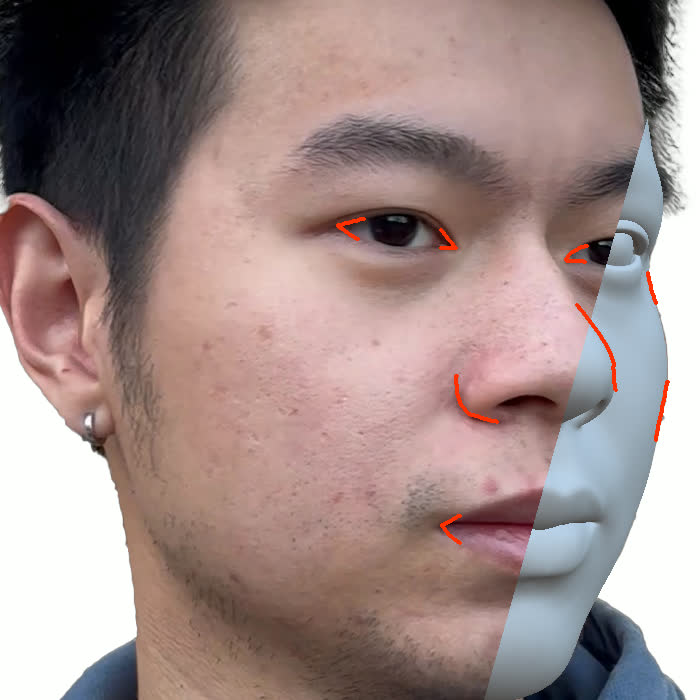
본 논문에서는 점점 더 인기 있는 3차원 신경망 표현을 이용하여 캘리브레이션되지 않은 여러 개의 인간 얼굴 이미지를 통합하고 일관된 설명을 제공하는 방법을 제시합니다. 우리의 접근 방식은 NeRFs보다 명확하며 제약 조건에 더 잘 대응할 수 있는 Gaussian Splatting을 활용합니다. 세그멘테이션 주석을 이용하여 얼굴의 의미적 영역을 정렬함으로써, 11장의 이미지만으로 중립 자세를 재구성할 수 있습니다(긴 동영상이 필요하지 않습니다). 우리는 Gaussians가 기본 삼각화 표면에 부드럽게 제약되도록 함으로써 구조화된 Gaussian Splat 재구성을 제공하고, 이는 후속의 정확도 향상을 위한 변동을 가능하게 합니다. 결과적으로 얻어진 삼각화 표면은 표준 그래픽 파이프라인에서 사용될 수 있습니다. 또한 가장 중요한 점으로, 우리는 정확한 기하학이 Gaussian Splats를 텍스처 공간으로 변환할 수 있게 함으로써 뷰에 따라 의존하는 신경망 텍스처로 처리할 수 있음을 보여줍니다. 이는 그래픽 파이프라인의 다른 자산이나 측면(기하학, 조명, 렌더러 등)을 수정하지 않고도 장면 내에서 Gaussian Splatting을 사용할 수 있게 합니다. 우리는 재조명 가능한 Gaussian 모델을 이용하여 텍스처와 조명을 분리하고 고해상도 알베도 텍스처를 얻어 표준 그래픽 파이프라인에서도 쉽게 사용할 수 있습니다. 우리의 시스템의 유연성으로 인해 불일치한 이미지, 심지어 호환되지 않는 조명 조건하에서도 학습을 할 수 있어 견고한 정규화를 가능하게 합니다. 마지막으로, 본 논문에서는 텍스트 기반 자산 생성 파이프라인에서 우리의 접근 방식의 효과성을 보여줍니다.💡 논문 핵심 해설 (Deep Analysis)

또한 본 논문은 Gaussians가 기본 삼각화 표면에 부드럽게 제약되도록 함으로써 구조화된 Gaussian Splat 재구성을 제공하고, 이를 통해 후속의 정확도 향상을 위한 변동을 가능하게 합니다. 이로 인해 얻어진 삼각화 표면은 표준 그래픽 파이프라인에서 사용될 수 있습니다.
특히 본 논문에서는 정확한 기하학이 Gaussian Splats를 텍스처 공간으로 변환할 수 있게 함으로써 뷰에 따라 의존하는 신경망 텍스처로 처리할 수 있음을 보여줍니다. 이는 그래픽 파이프라인의 다른 자산이나 측면(기하학, 조명, 렌더러 등)을 수정하지 않고도 장면 내에서 Gaussian Splatting을 사용할 수 있게 하는 중요한 발전입니다.
마지막으로 본 논문은 재조명 가능한 Gaussian 모델을 이용하여 텍스처와 조명을 분리하고 고해상도 알베도 텍스처를 얻어 표준 그래픽 파이프라인에서도 쉽게 사용할 수 있음을 보여줍니다. 이는 시스템의 유연성으로 인해 불일치한 이미지, 심지어 호환되지 않는 조명 조건하에서도 학습을 할 수 있어 견고한 정규화를 가능하게 합니다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리