JARVIS: 시각적 이해를 향상시키는 새로운 프레임워크
📝 원문 정보
- Title: Seeing Beyond Words: Self-Supervised Visual Learning for Multimodal Large Language Models
- ArXiv ID: 2512.15885
- 발행일: 2025-12-17
- 저자: Davide Caffagni, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, Pier Luigi Dovesi, Shaghayegh Roohi, Mark Granroth-Wilding, Rita Cucchiara
📝 초록 (Abstract)
다중모달 대형 언어 모델(MLLMs)은 최근 시각과 언어를 연결하는 데 인상적인 능력을 보여주었지만, 기본적인 시각적 추론 작업에서의 성능이 여전히 제한적이다. 이 한계는 MLLMs가 주로 텍스트 설명을 통해 시각 이해를 학습하기 때문이며, 이러한 설명은 주관적이며 본질적으로 불완전한 감독 신호다. 또한 다중모달 지시어 튜닝의 규모가 대규모 언어만의 사전 학습에 비해 작아 MLLMs는 언어 우선 순위를 과도하게 학습하고 시각적 세부 사항을 무시하는 경향이 있다. 이러한 문제점을 해결하기 위해 JEPA에서 영감을 받은 프레임워크인 JARVIS를 소개한다. 특히, 우리는 MLLMs 훈련의 표준 시각-언어 정렬 파이프라인에 I-JEPA 학습 패러다임을 통합한다. 우리의 접근 방법은 동결된 시각 기반 모델을 컨텍스트 및 타겟 인코더로 활용하고, LLM의 초기 레이어로 구현된 예측기를 훈련시켜 언어 감독에 의존하지 않고 이미지에서 구조적이고 의미론적인 규칙성을 학습한다. 표준 MLLM 벤치마크에서 수행한 광범위한 실험은 JARVIS가 다양한 LLM 패밀리에서 시각 중심의 벤치마크 성능을 일관되게 향상시키며, 다중모달 추론 능력을 저하시키지 않는다는 것을 보여준다. 우리의 소스 코드는 https://github.com/aimagelab/JARVIS 에서 공개적으로 이용 가능하다.💡 논문 핵심 해설 (Deep Analysis)
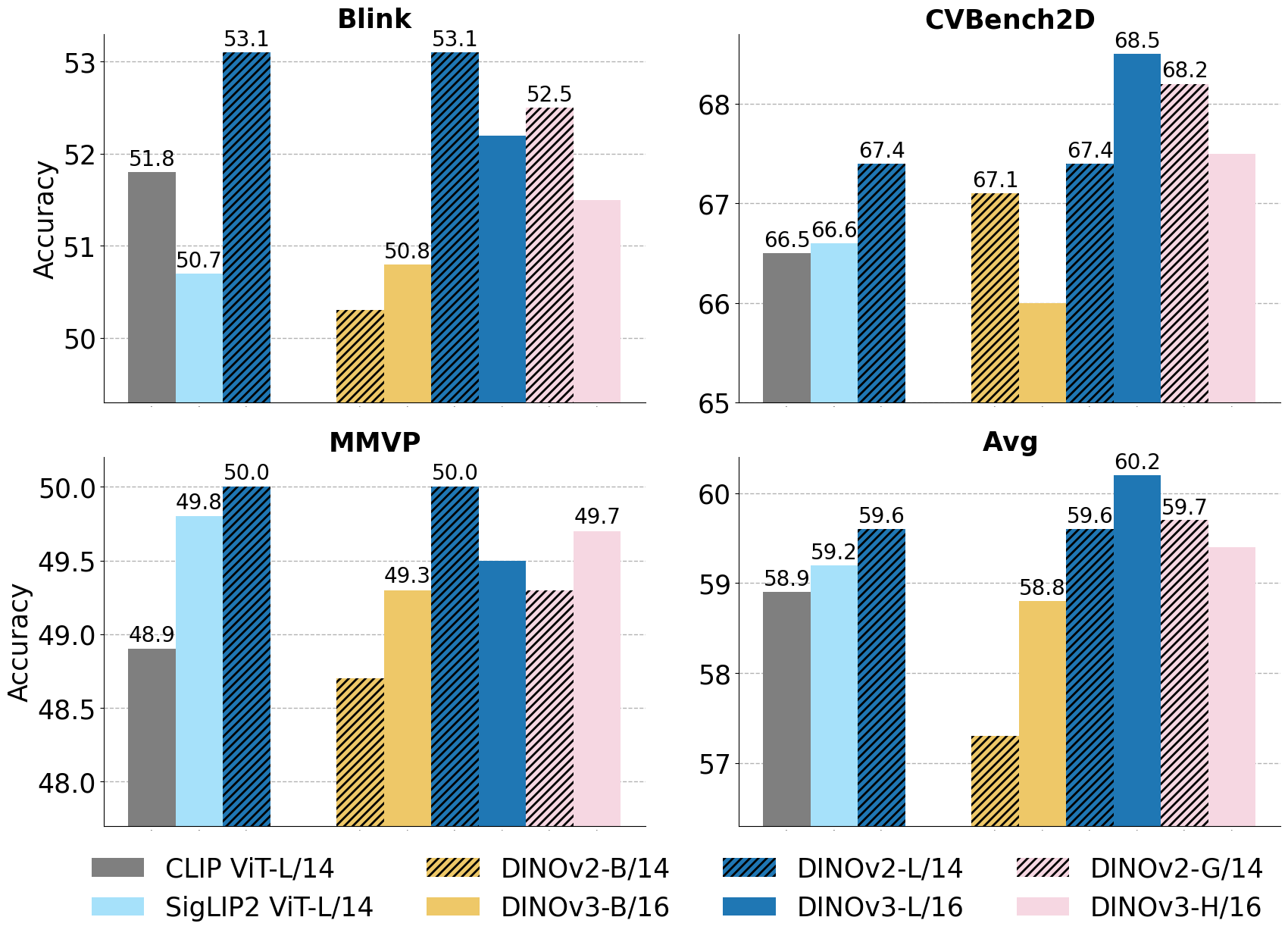
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리






























Reference
이 글은 ArXiv의 공개 자료를 바탕으로 AI가 자동 번역 및 요약한 내용입니다.
저작권은 원저자에게 있으며, 인류 지식 발전에 기여한 연구자분들께 감사드립니다.