반응형 학습을 통한 수학적 추론 모델의 효율적인 훈련: TRAPO 알고리즘
📝 원문 정보
- Title: TraPO: A Semi-Supervised Reinforcement Learning Framework for Boosting LLM Reasoning
- ArXiv ID: 2512.13106
- 발행일: 2025-12-15
- 저자: Shenzhi Yang, Guangcheng Zhu, Xing Zheng, Yingfan MA, Zhongqi Chen, Bowen Song, Weiqiang Wang, Junbo Zhao, Gang Chen, Haobo Wang
📝 초록 (Abstract)
증명 가능한 보상(Verifiable Rewards)을 활용하는 강화학습(RLVR)은 대규모 추론 모델(LRMs)을 학습시키는 데 효과적이지만, 이 방법은 높은 주석 비용이라는 문제를 안고 있습니다. 이를 해결하기 위해 최근 연구에서는 외부 감독 없이 모델의 내부 일관성에서 보상을 도출하는 무감독 RLVR 방법들을 탐색해왔습니다. 그러나 이러한 방법들은 훈련 후기 단계에서 모델 붕괴(Model Collapse) 문제를 겪곤 합니다. 본 연구에서는 소규모 라벨링 데이터셋을 활용하여 비라벨 샘플에 대한 RLVR 학습을 안내하는 새로운 준감독 RLVR 패러다임을 탐구합니다. 우리의 핵심 통찰은 감독된 보상이 비라벨 샘플에 대한 일관성 기반 훈련을 안정화시키고, 라벨링 인스턴스에서 검증된 추론 패턴만 강화학습에 포함시킨다는 것입니다. 이를 위해 TRAPO라는 효과적인 정책 최적화 알고리즘을 제안합니다. TRAPO는 학습 경로 유사성을 통해 신뢰할 수 있는 비라벨 샘플을 식별하는 방법으로, 6개의 널리 사용되는 수학 추론 벤치마크(AIME24/25, AMC, MATH-500, Minerva 및 Olympiad)와 3개의 분포 외부 작업(ARC-c, GPQA-diamond 및 MMLU-pro)에서 뛰어난 데이터 효율성과 강력한 일반화 성능을 보여줍니다. 1K 라벨링 샘플과 3K 비라벨 샘플만으로도 평균 정확도 42.6%를 달성하며, 45K 비라벨 샘플로 훈련된 최고의 무감독 방법(38.3%)을 능가합니다. 특히 4K 라벨링 샘플과 12K 비라벨 샘플을 사용할 때는 전체 45K 라벨링 샘플로 훈련된 완전 감독 모델보다 모든 벤치마크에서 우수한 성능을 보여주며, 라벨링 데이터의 10%만을 사용합니다.💡 논문 핵심 해설 (Deep Analysis)
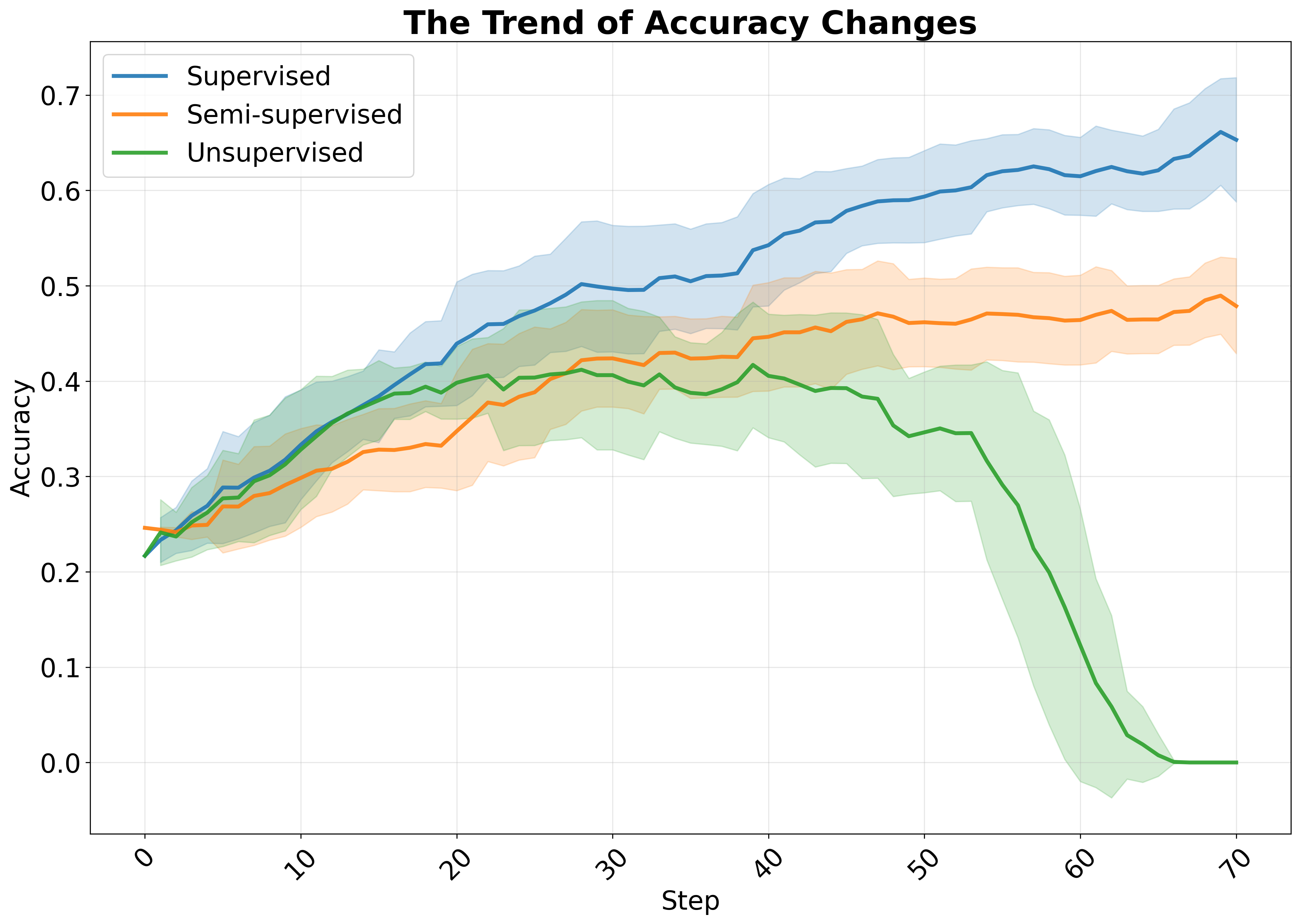
TRAPO 알고리즘은 학습 경로 유사성 분석을 통해 신뢰할 수 있는 비라벨 샘플을 식별하여, 이를 기반으로 정책 최적화를 수행합니다. 이 방법은 소량의 라벨링 데이터만으로도 모델이 안정적으로 훈련될 수 있도록 하며, 특히 분포 외부 작업에서도 우수한 성능을 보여주어 그 활용 가능성과 확장성을 입증하였습니다.
논문에서 제시된 결과는 TRAPO 알고리즘이 기존의 무감독 및 준감독 방법들보다 뛰어난 데이터 효율성과 정확도를 제공함을 보여줍니다. 특히, 전체 라벨링 샘플의 10%만으로도 완전 감독 모델에 버금가는 성능을 달성한 것은 이 연구의 중요한 기여입니다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리

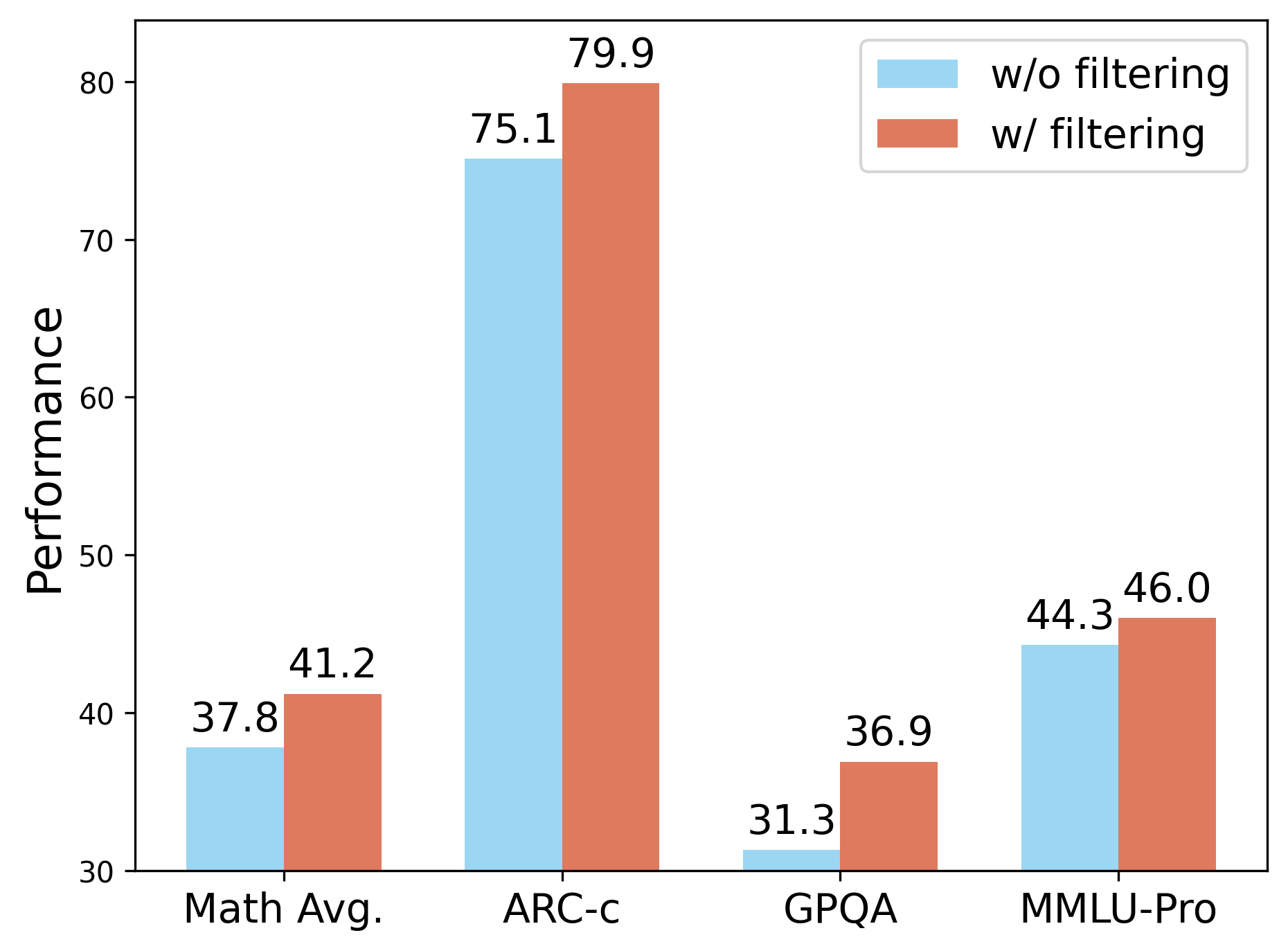
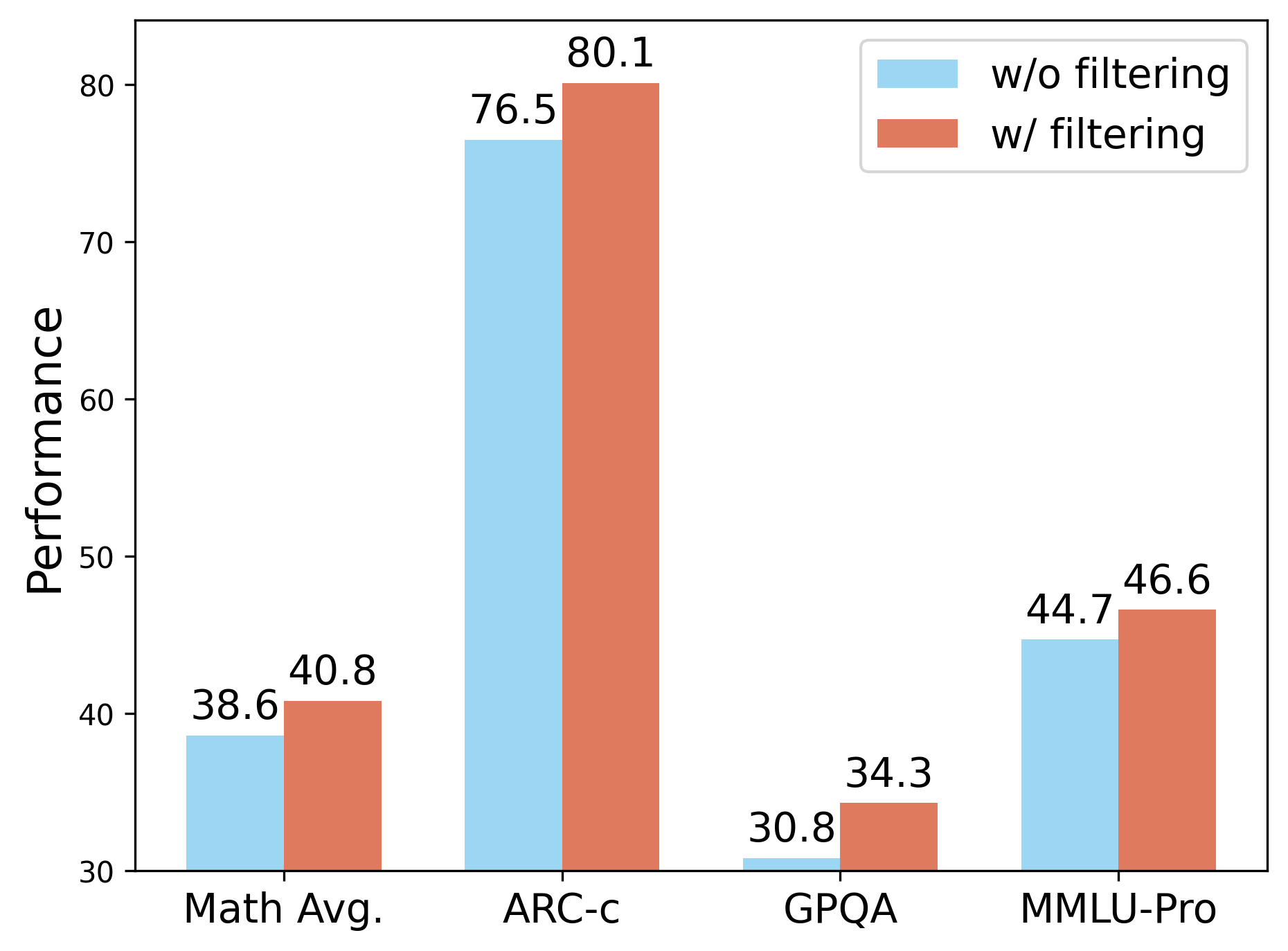
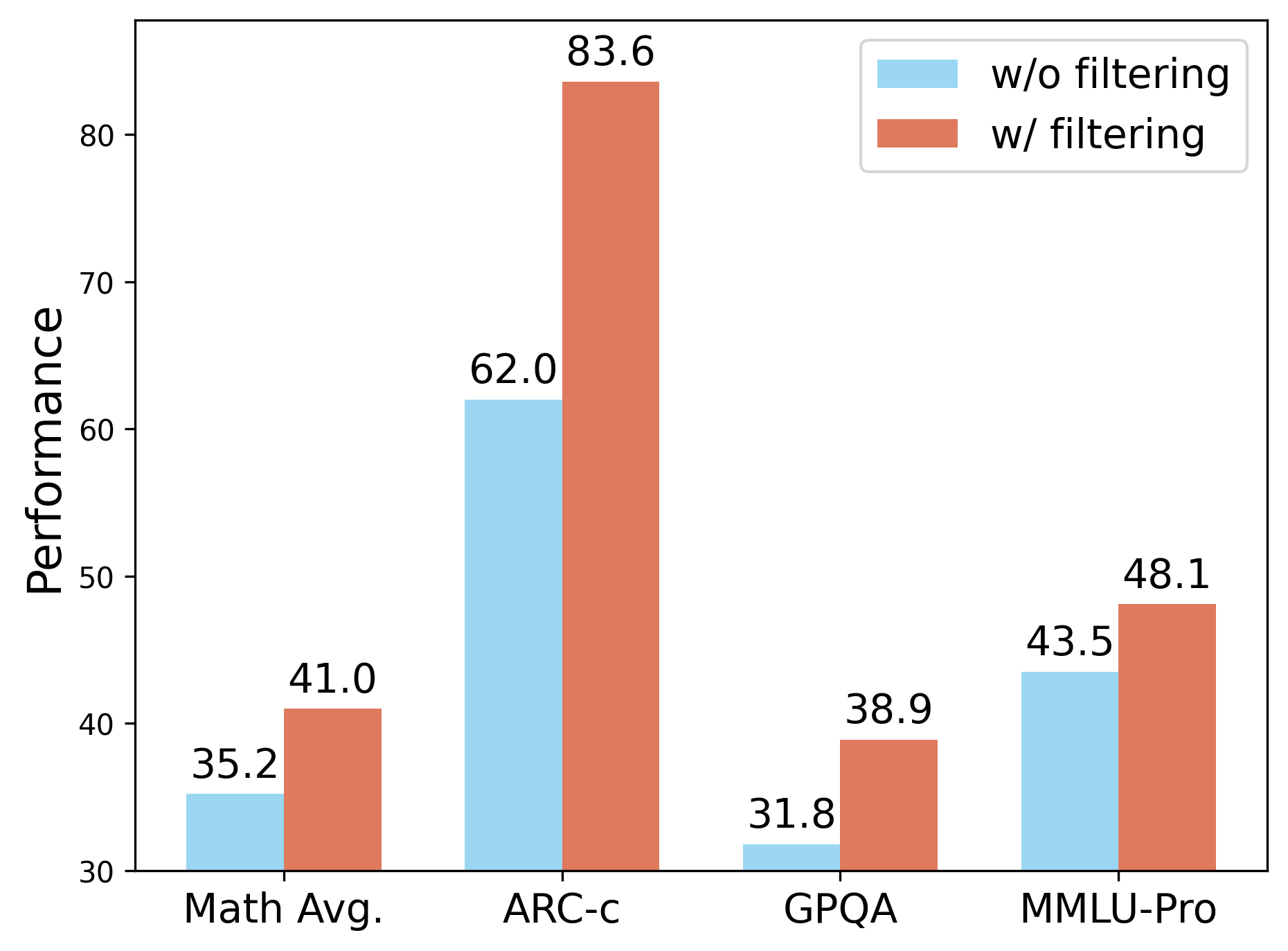

Reference
이 글은 ArXiv의 공개 자료를 바탕으로 AI가 자동 번역 및 요약한 내용입니다.
저작권은 원저자에게 있으며, 인류 지식 발전에 기여한 연구자분들께 감사드립니다.