말ayer 주의 풀링을 활용한 음성 인식 기술 혁신
읽는 시간: 3 분
...
📝 원문 정보
- Title: Rethinking Leveraging Pre-Trained Multi-Layer Representations for Speaker Verification
- ArXiv ID: 2512.22148
- 발행일: 2025-12-15
- 저자: Jin Sob Kim, Hyun Joon Park, Wooseok Shin, Sung Won Han
📝 초록 (Abstract)
최근 연구에서 사전 학습된 Transformer 모델로부터 얻은 계층별 출력을 활용하여 음성인증 분야에서 눈에 띄는 성과를 거두었다. 그러나 이러한 다수준 특징들을 정적 가중 평균을 넘어서 통합하는 방법론에 대한 탐구는 제한적이었다. 본 논문에서는 사전 학습된 음성 모델로부터 얻은 계층별 표현을 통합하기 위한 새로운 접근법인 Layer Attentive Pooling (LAP)을 제안한다. LAP은 각 계층의 중요성을 시간 동적으로 평가하고, 최대 풀링(max pooling)을 사용하여 평균화 대신 이를 적용한다. 또한, 사전 학습된 모델 출력에서 화자 임베딩을 추출하기 위한 가벼운 뒤쪽 화자 모델로 LAP과 Attentive Statistical Temporal Pooling (ASTP)을 포함한 구조를 제안한다. 실험 결과, VoxCeleb 벤치마크에서 우리의 컴팩트 아키텍처는 훈련 시간을 크게 줄이면서도 최고 수준의 성능을 달성함을 보여주었다. 우리는 또한 LAP 설계와 동적 가중치 메커니즘에 대해 분석하였다.💡 논문 핵심 해설 (Deep Analysis)
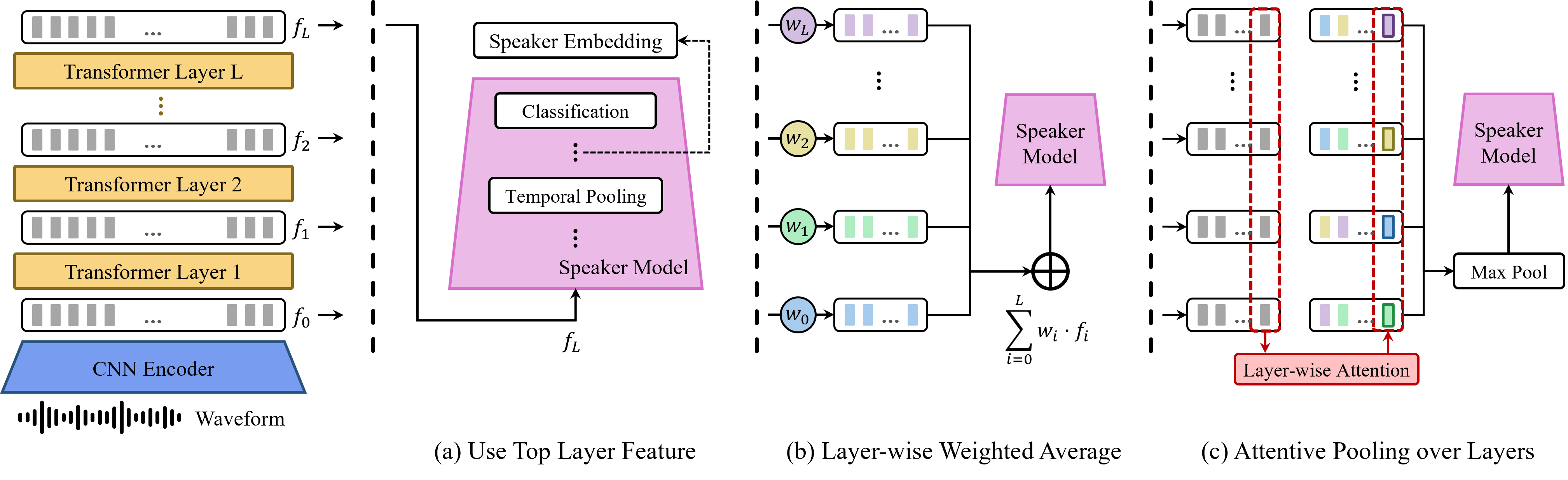
또한, 본 논문에서는 LAP과 Attentive Statistical Temporal Pooling (ASTP)을 결합하여 뒤쪽 화자 모델을 구성하는 새로운 아키텍처를 제안한다. 이 구조는 사전 학습된 모델의 출력에서 화자 임베딩을 효과적으로 추출할 수 있도록 설계되었다. 실험 결과, 이러한 접근법은 VoxCeleb 벤치마크에서 기존 방법보다 우수한 성능을 보여주었으며, 특히 훈련 시간이 크게 단축되는 장점도 확인되었다.
LAP의 동적 가중치 메커니즘은 화자 특성에 대한 민감성을 높이는 중요한 역할을 한다. 이는 각 계층에서 추출된 정보가 시간 경과에 따라 어떻게 변화하는지에 대해 더 정교하게 이해하고, 이를 통해 더욱 효과적인 화자 인식 모델을 구축할 수 있게 해준다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리
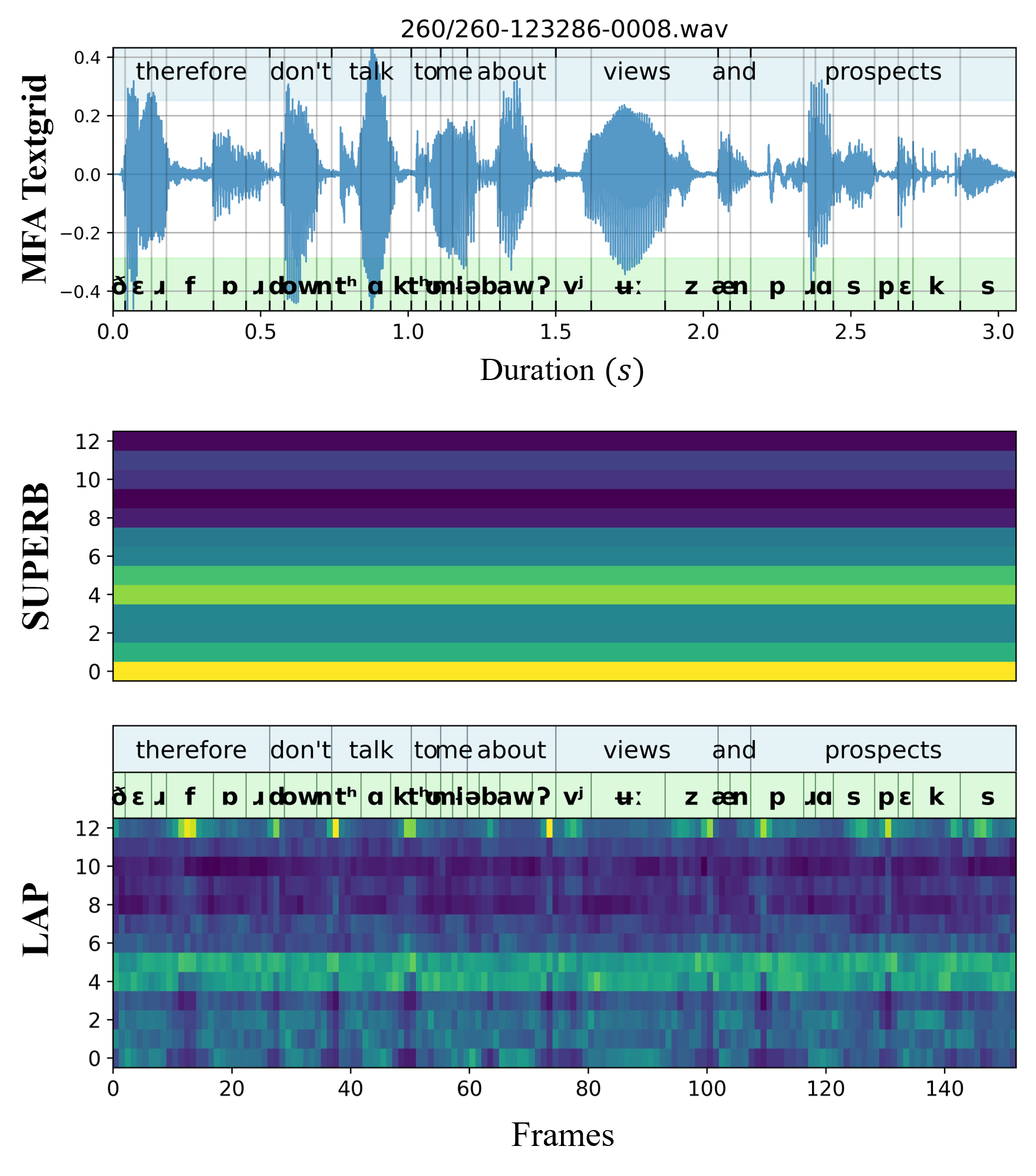
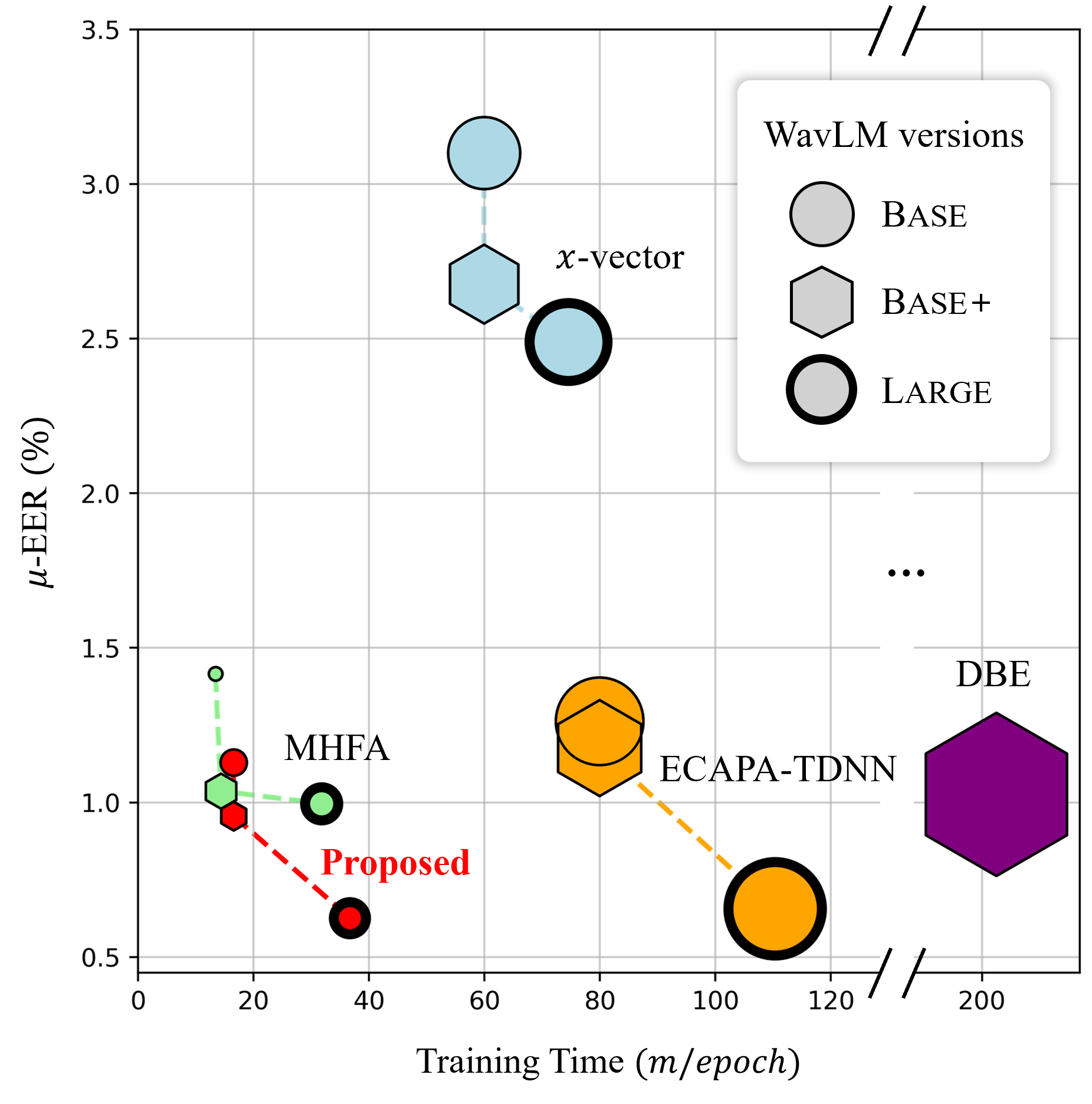
Reference
이 글은 ArXiv의 공개 자료를 바탕으로 AI가 자동 번역 및 요약한 내용입니다.
저작권은 원저자에게 있으며, 인류 지식 발전에 기여한 연구자분들께 감사드립니다.