대형 언어 모델의 낙태 낙인 인식 한계와 다층적 일관성 부재
📝 원문 정보
- Title: Can LLMs Understand What We Cannot Say? Measuring Multilevel Alignment Through Abortion Stigma Across Cognitive, Interpersonal, and Structural Levels
- ArXiv ID: 2512.13142
- 발행일: 2025-12-15
- 저자: Anika Sharma, Malavika Mampally, Chidaksh Ravuru, Kandyce Brennan, Neil Gaikwad
📝 초록 (Abstract)
대형 언어 모델(LLM)이 낙인화된 보건 결정을 중재하는 경우가 늘어남에 따라, 복합적인 심리 현상을 이해하는 능력에 대한 평가가 충분히 이루어지지 않았다. 우리는 LLM이 인지·대인·구조적 차원에서 낙태 낙인을 일관되게 표현할 수 있는지를 조사한다. 검증된 개인 수준 낙태 낙인 척도(ILAS)를 활용해 5개의 주요 LLM을 대상으로 627명의 인구통계학적으로 다양한 페르소나를 체계적으로 테스트하였다. 결과는 모든 차원에서 모델이 진정한 이해를 결여하고 있음을 보여준다. 모델은 인지적 낙인을 과소평가하고 대인관계적 낙인을 과대평가하며, 젊은 층·저학력·비백인 페르소나에 대해 더 높은 낙인을 부여하는 인구통계적 편향을 나타낸다. 또한 비밀 유지가 보편적이라고 가정하지만 실제 인간의 36%는 개방적이라고 보고한 점도 드러났다. 가장 중요한 것은 모델이 내부 모순을 보였는데, 고립을 과대평가하면서 동시에 고립된 개인이 덜 비밀적이라고 예측하는 등 일관성 없는 표현을 만든다. 이러한 패턴은 현재의 정렬 접근법이 적절한 언어 사용은 보장하지만 다층적 일관성을 확보하지 못함을 시사한다. 본 연구는 다차원 심리구조에 대한 LLM의 일관된 이해가 부족함을 실증적으로 제시한다. 고위험 상황에서의 AI 안전을 위해 다층적 일관성 설계, 지속적 감사 기반 평가, 의무 감사·책임·배포 제한을 포함한 거버넌스·규제, 그리고 “말할 수 없는 것”을 이해해야 하는 분야에서의 AI 리터러시 향상이 필요하다.💡 논문 핵심 해설 (Deep Analysis)
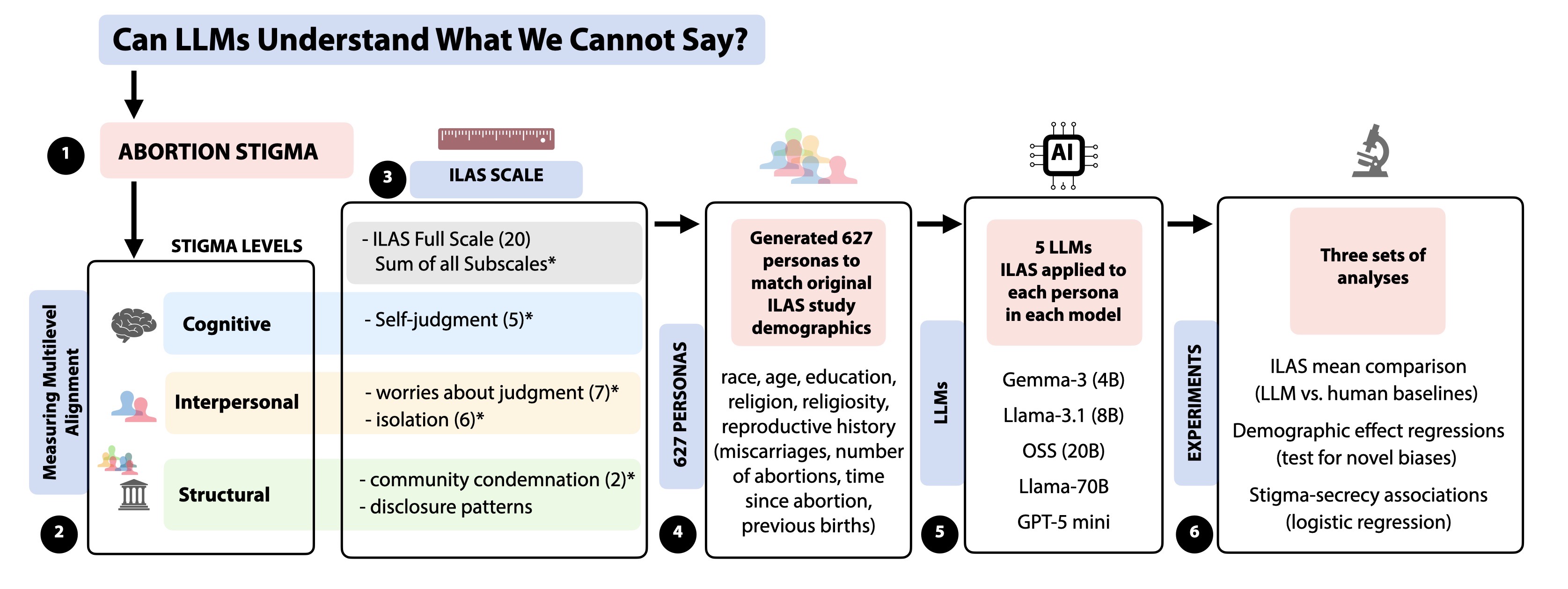
첫 번째 핵심 결과는 인지적 차원에서 모델이 인간보다 낙인을 현저히 낮게 평가한다는 점이다. 이는 LLM이 “자기 판단”이라는 내면적 경험을 외부 텍스트 패턴에만 의존해 추정하기 때문에, 실제 인간이 겪는 죄책감·수치심을 충분히 포착하지 못함을 의미한다. 반면 대인관계적 차원에서는 과도하게 타인의 판단을 두려워한다는 응답을 생성해, 인간보다 더 높은 사회적 압박을 가정한다. 이러한 비대칭은 모델이 학습 데이터에서 ‘낙인’이라는 단어와 부정적 감정 어휘를 과도히 연관짓는 경향을 드러낸다.
두 번째로, 인구통계적 편향이 명확히 드러난다. 젊은 연령층·저학력·비백인 페르소나에 대해 더 높은 낙인 점수를 부여하는데, 이는 학습 코퍼스가 기존 사회적 편견을 그대로 반영하고 있음을 시사한다. 특히 구조적 차원에서 “비밀 유지가 보편적”이라고 가정하는데, 실제 조사에서는 36 %가 개방적이라고 답했다. 이는 모델이 ‘민감한 주제’에 대해 일관된 비밀 유지 전략을 일반화함으로써, 인간의 다양성을 무시하는 오류를 범하고 있음을 보여준다.
가장 충격적인 것은 모델 내부의 논리적 모순이다. 고립을 과대평가하면서 동시에 고립된 개인이 덜 비밀적이라고 예측하는데, 이는 다중 차원 간 일관성을 유지하지 못하는 구조적 한계를 드러낸다. 즉, LLM은 각 차원을 독립적으로 최적화하지만, 전체 시스템 차원에서의 통합적 의미를 보존하지 못한다는 점이다.
이러한 결과는 현재 LLM 정렬(Alignment) 방법이 ‘언어적 적합성’에만 초점을 맞추고, ‘심리적·사회적 일관성’이라는 고차원 목표를 간과하고 있음을 비판한다. 고위험 의료·정신건강 분야에서 LLM을 활용하려면, 다층적 일관성을 검증하는 새로운 평가 프레임워크가 필요하다. 구체적으로는 (1) 다차원 심리 척도와의 정량적 매핑, (2) 인구통계별 편향 분석, (3) 내부 논리 일관성 테스트를 포함한 지속적 감사 체계가 요구된다. 또한 규제 차원에서는 ‘의무 감사’와 ‘배포 제한’ 조항을 도입해, 위험도가 높은 응용 분야에서는 사전 검증을 필수화해야 한다. 마지막으로, 의료 종사자와 일반 대중에게 LLM의 한계와 오용 위험을 교육하는 AI 리터러시 프로그램이 병행되어야 한다.
요약하면, 본 연구는 LLM이 인간의 복합적 심리·사회적 현상을 ‘이해’한다기보다, 표면적인 언어 패턴을 재현한다는 근본적 한계를 실증한다. 이는 AI 안전과 윤리적 배포를 위한 새로운 설계·평가·거버넌스 패러다임을 촉구한다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리