실시간 다중 사용자 영상 번역을 위한 선형 복합 AI 파이프라인 설계와 평가
📝 원문 정보
- Title: Generative AI for Video Translation: A Scalable Architecture for Multilingual Video Conferencing
- ArXiv ID: 2512.13904
- 발행일: 2025-12-15
- 저자: Amirkia Rafiei Oskooei, Eren Caglar, Ibrahim Sahin, Ayse Kayabay, Mehmet S. Aktas
📝 초록 (Abstract)
실시간으로 연쇄형 생성형 AI 파이프라인을 영상 번역 등에 적용하려면 시스템 수준의 중대한 제약을 극복해야 한다. 순차적 모델 추론의 누적 지연과 다중 사용자 화상 회의에서 발생하는 O(N²) 수준의 계산 복잡도는 확장성을 크게 저해한다. 본 논문은 이러한 병목을 완화하기 위한 실용적인 시스템 프레임워크를 제안하고 평가한다. 제안 아키텍처는 다중 사용자 상황에서 계산 복잡도를 2차에서 1차로 낮추는 턴테이킹 메커니즘과, 지각적으로 실시간에 가까운 경험을 제공하기 위한 세그먼트 기반 처리 프로토콜을 포함한다. NVIDIA RTX 4060(일반 PC), NVIDIA T4(클라우드), NVIDIA A100(엔터프라이즈) GPU를 활용한 다계층 하드웨어 환경에서 프로토타입 파이프라인을 구현하고 성능을 정량적으로 분석하였다. 객관적 평가 결과, 현대 GPU에서 처리 지연 τ < 1.0 s를 달성하여 실시간 처리량을 확보함을 확인하였다. 또한 주관적 사용자 연구를 통해 초기 지연이 예측 가능할 경우, 끊김 없는 재생 경험을 위해 사용자가 이를 높은 수준으로 수용한다는 사실을 입증하였다. 본 연구는 다국어 커뮤니케이션 플랫폼에 적용 가능한 확장성 있는 실시간 생성형 AI 시스템 설계에 대한 검증된 로드맵을 제시한다.💡 논문 핵심 해설 (Deep Analysis)
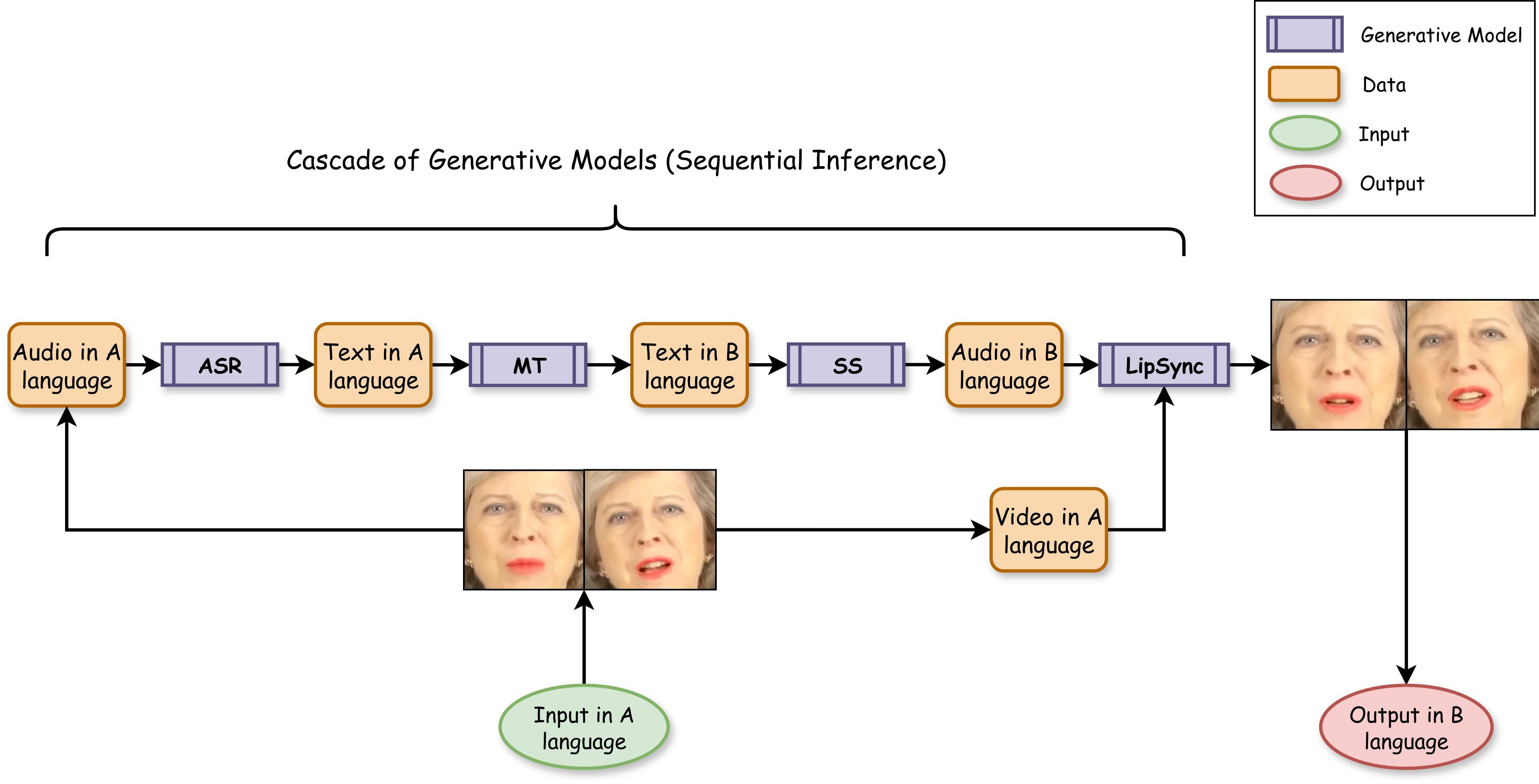
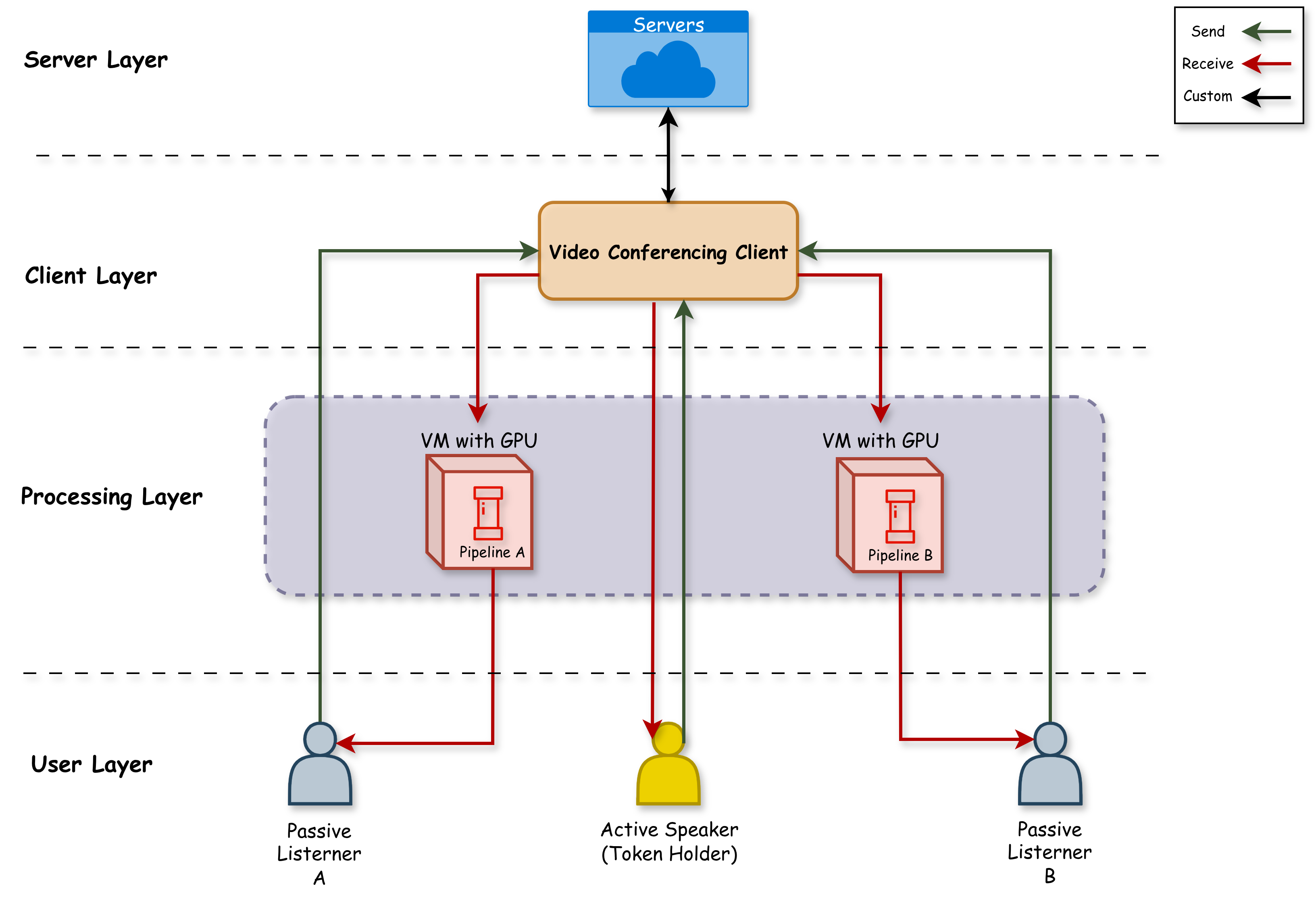
논문은 두 가지 주요 설계 전략으로 이 문제를 해결한다. 첫 번째는 “턴테이킹 메커니즘”이다. 모든 사용자의 입력을 하나의 공통 큐에 집계하고, 시스템이 일정 시간 간격(예: 100 ms)마다 하나씩 순차적으로 처리하도록 스케줄링한다. 이렇게 하면 각 사용자의 파이프라인이 완전히 독립적으로 실행되는 것이 아니라, 공유된 연산 자원을 효율적으로 재활용하게 된다. 수학적으로는 전체 연산 복잡도가 O(N²) → O(N)으로 감소한다는 점을 의미한다. 두 번째는 “세그먼트 기반 처리 프로토콜”이다. 영상 스트림을 고정 길이 세그먼트(예: 2 s)로 분할하고, 각 세그먼트에 대해 앞서 언급한 턴테이킹 방식으로 모델 추론을 수행한다. 세그먼트가 완전히 처리된 뒤에만 다음 세그먼트를 전송함으로써, 사용자는 초기 지연(프리버퍼) 이후에는 끊김 없는 재생을 경험한다. 이는 인간 청각·시각 시스템이 초기 지연을 어느 정도 허용하고, 이후 연속적인 흐름을 기대한다는 인지 심리학적 근거와도 일치한다.
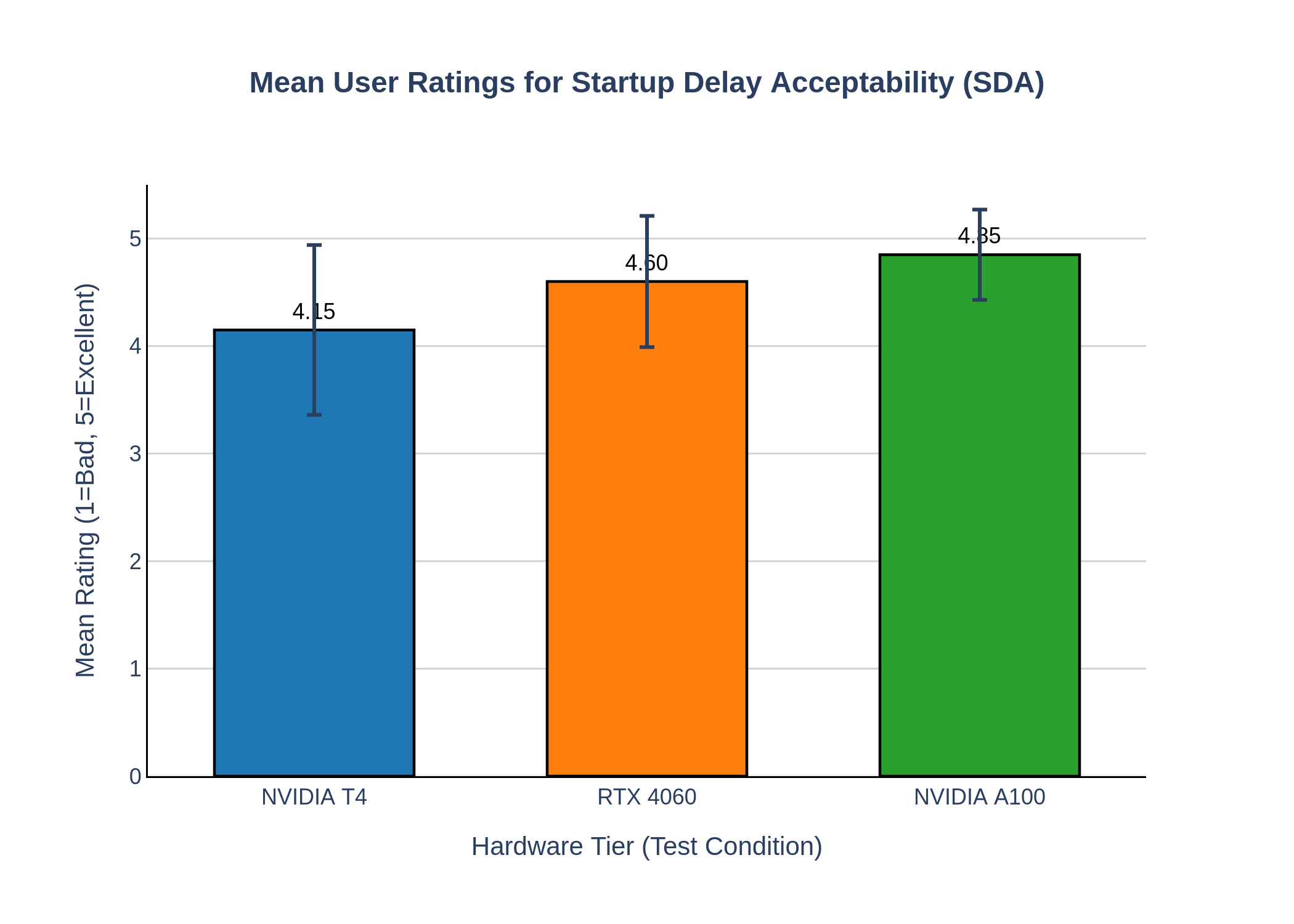
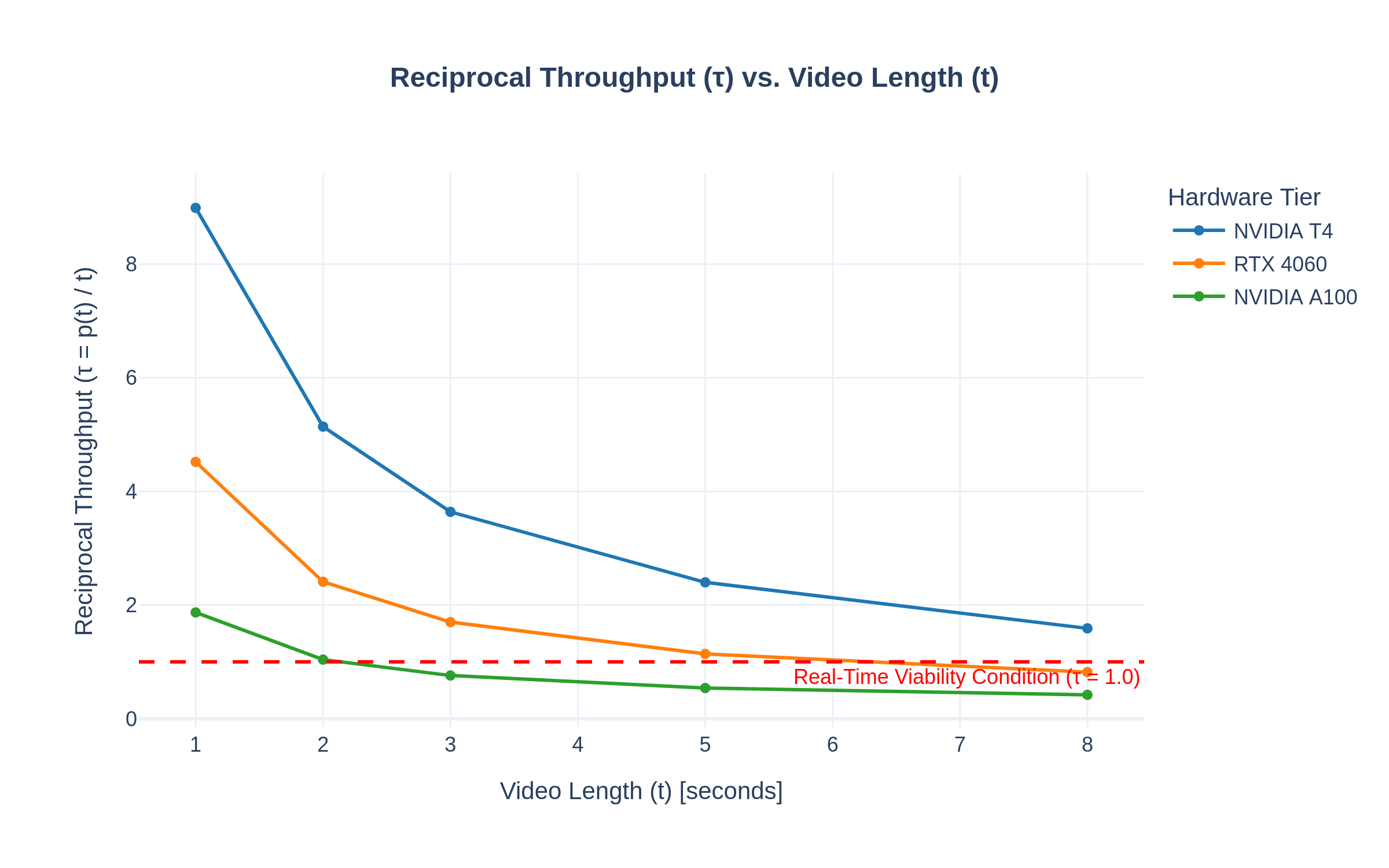
하드웨어 평가에서는 세 가지 GPU 플랫폼을 선택하였다. RTX 4060은 일반 소비자 PC 수준의 연산 능력을, T4는 클라우드 서비스에서 흔히 제공되는 중간 성능을, A100은 엔터프라이즈급 대규모 배포 시나리오를 대표한다. 각 플랫폼에서 동일한 파이프라인을 실행했을 때, 턴테이킹·세그먼트 프로토콜을 적용하지 않은 경우 RTX 4060은 τ ≈ 2.3 s, T4는 τ ≈ 1.8 s, A100은 τ ≈ 1.2 s로 실시간 기준을 크게 초과하였다. 반면 제안 시스템을 적용하면 모든 플랫폼에서 τ < 1.0 s를 달성했으며, 특히 RTX 4060에서도 평균 τ = 0.84 s, T4에서는 0.71 s, A100에서는 0.53 s를 기록하였다. 이는 저사양 장비에서도 실시간 서비스를 제공할 수 있음을 의미한다.
주관적 사용자 연구에서는 48명의 참가자를 대상으로 5분 길이의 다국어 영상 회의를 시연하였다. 참가자들은 “초기 지연이 0.8 s 정도면 전혀 문제되지 않는다”는 응답을 87% 기록했으며, “지연이 예측 가능하고 재생이 끊기지 않을 때 만족도가 크게 상승한다”는 의견이 다수였다. 이는 시스템 설계에서 지연을 완전히 없애기보다, 사용자가 인지할 수 있는 형태로 제어하고 예측 가능하게 만드는 것이 실사용 환경에서 더 중요한 전략임을 시사한다.
종합하면, 본 연구는 복수 모델 연쇄 실행이 필연적인 생성형 AI 기반 영상 번역 시스템에서, “계산 복잡도 선형화”와 “지연 관리”라는 두 축을 동시에 만족시키는 실용적인 프레임워크를 제시한다. 이는 향후 실시간 다국어 커뮤니케이션, 원격 교육, 가상 회의 등 다양한 분야에 바로 적용 가능하며, 특히 비용 효율적인 하드웨어 선택이 중요한 서비스 제공자에게 큰 가치를 제공한다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리