레몬: 3D 공간 이해를 위한 통합 변형 모델
📝 원문 정보
- Title: Lemon: A Unified and Scalable 3D Multimodal Model for Universal Spatial Understanding
- ArXiv ID: 2512.12822
- 발행일: 2025-12-14
- 저자: Yongyuan Liang, Xiyao Wang, Yuanchen Ju, Jianwei Yang, Furong Huang
📝 초록 (Abstract)
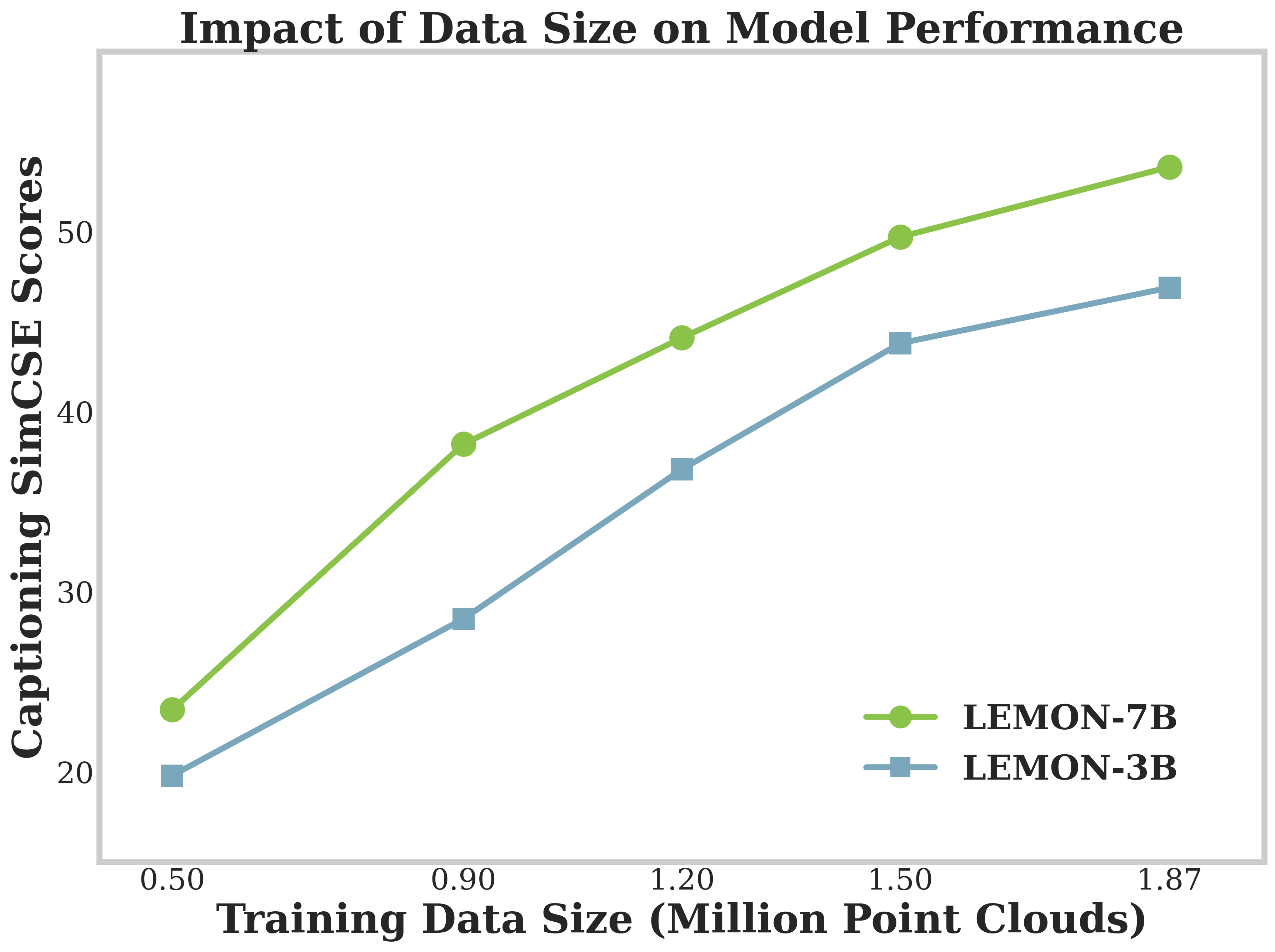
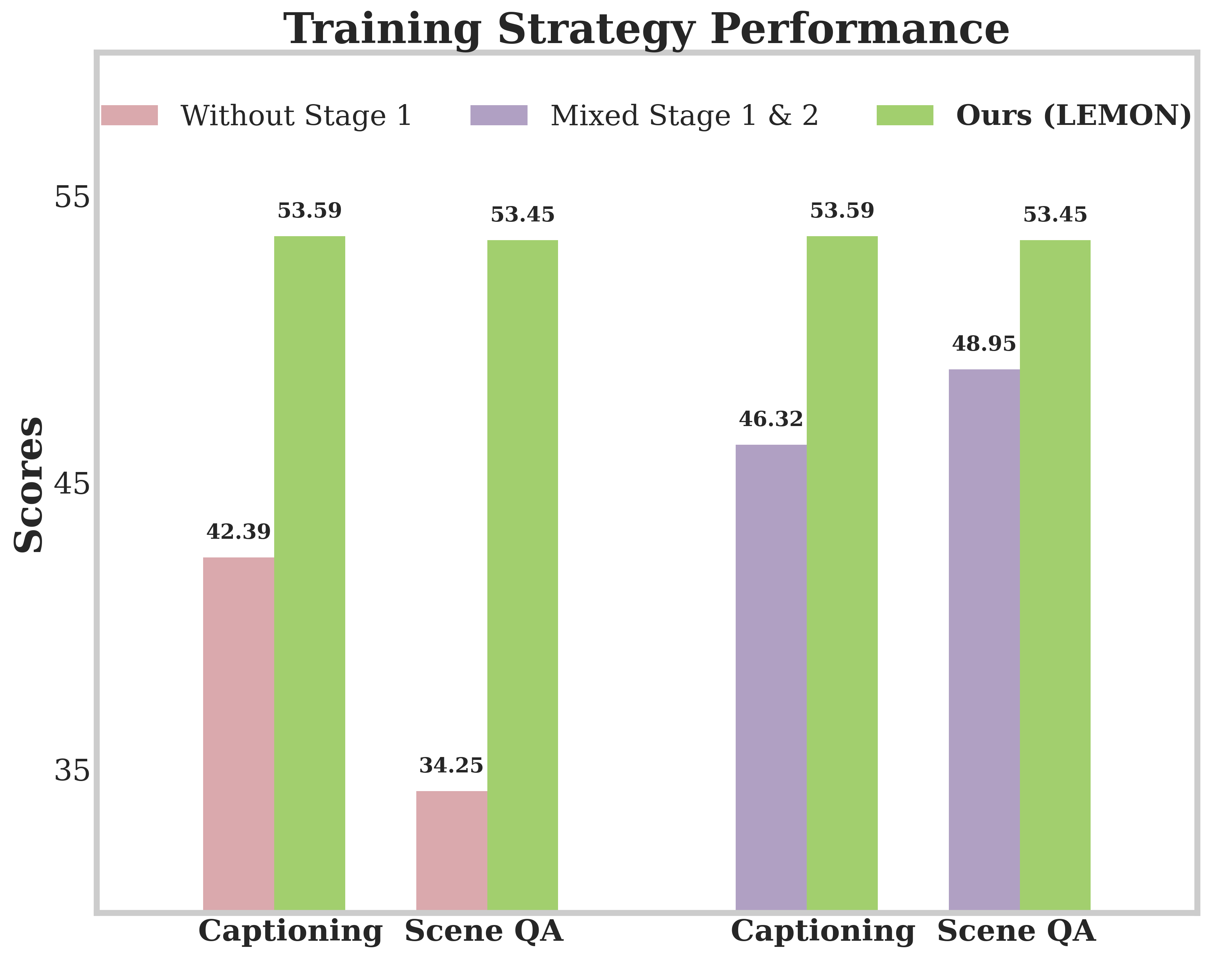
대규모 다중 모달 모델(LMMs)을 3D 이해에 확장하는 것은 고유한 도전 과제를 제기합니다. 점 클라우드 데이터는 희박하고 비정규이며, 기존의 모델은 모달성별 인코더를 사용하는 분리된 아키텍처에 의존하며, 트레이닝 파이프라인은 자주 불안정하고 확장성이 떨어집니다. 우리는 이러한 문제를 해결하기 위해 Lemon이라는 통합 변형 아키텍처를 소개합니다. 이 설계는 3D 점 클라우드 패치와 언어 토큰을 단일 시퀀스로 공동 처리함으로써, 기존 작업에서 사용된 모달성별 인코더와 교차모달 정렬 모듈에 의존하지 않습니다. 이 설계는 초기 공간-언어적 융합을 가능하게 하며, 중복되는 인코더를 제거하고 파라미터 효율성을 향상시키며, 더 효과적인 모델 확장을 지원합니다. 3D 데이터의 복잡성에 대응하기 위해, 우리는 공간적 맥락을 유지하는 구조화된 패치화 및 토큰화 방식과 객체 수준 인식에서 장면 수준 공간 추론까지 점진적으로 능력을 구축하는 세 단계 트레이닝 과정을 개발했습니다. Lemon은 3D 이해와 추론 작업, 특히 객체 인식과 캡셔닝 및 3D 장면의 공간 추론에서 새로운 최고 수준의 성능을 달성하며, 모델 크기와 트레이닝 데이터가 증가함에 따라 견고한 확장성을 보여줍니다. 우리의 연구는 실제 응용 프로그램에서 3D 공간 지능을 발전시키기 위한 통합 기반을 제공합니다.💡 논문 핵심 해설 (Deep Analysis)
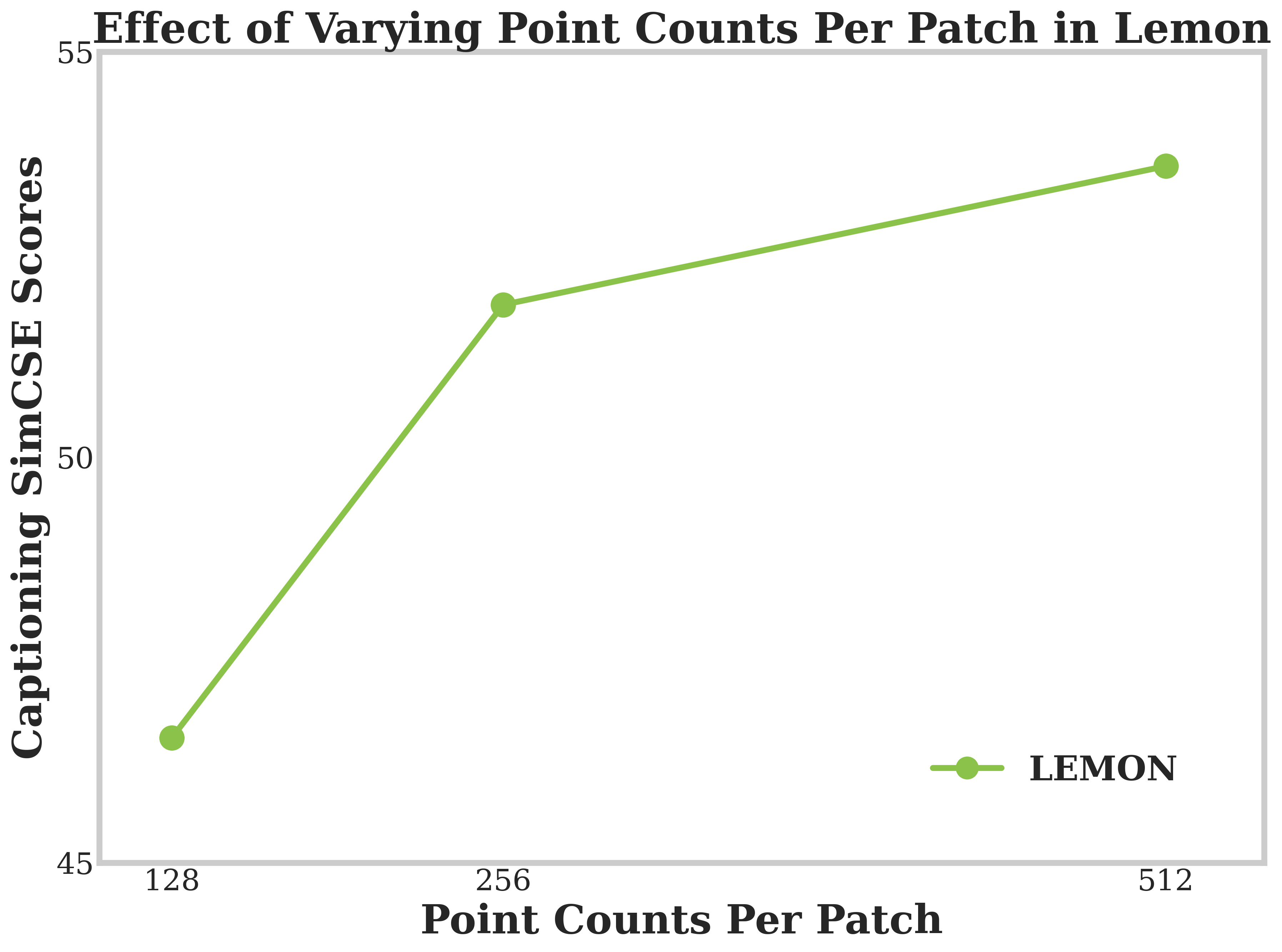
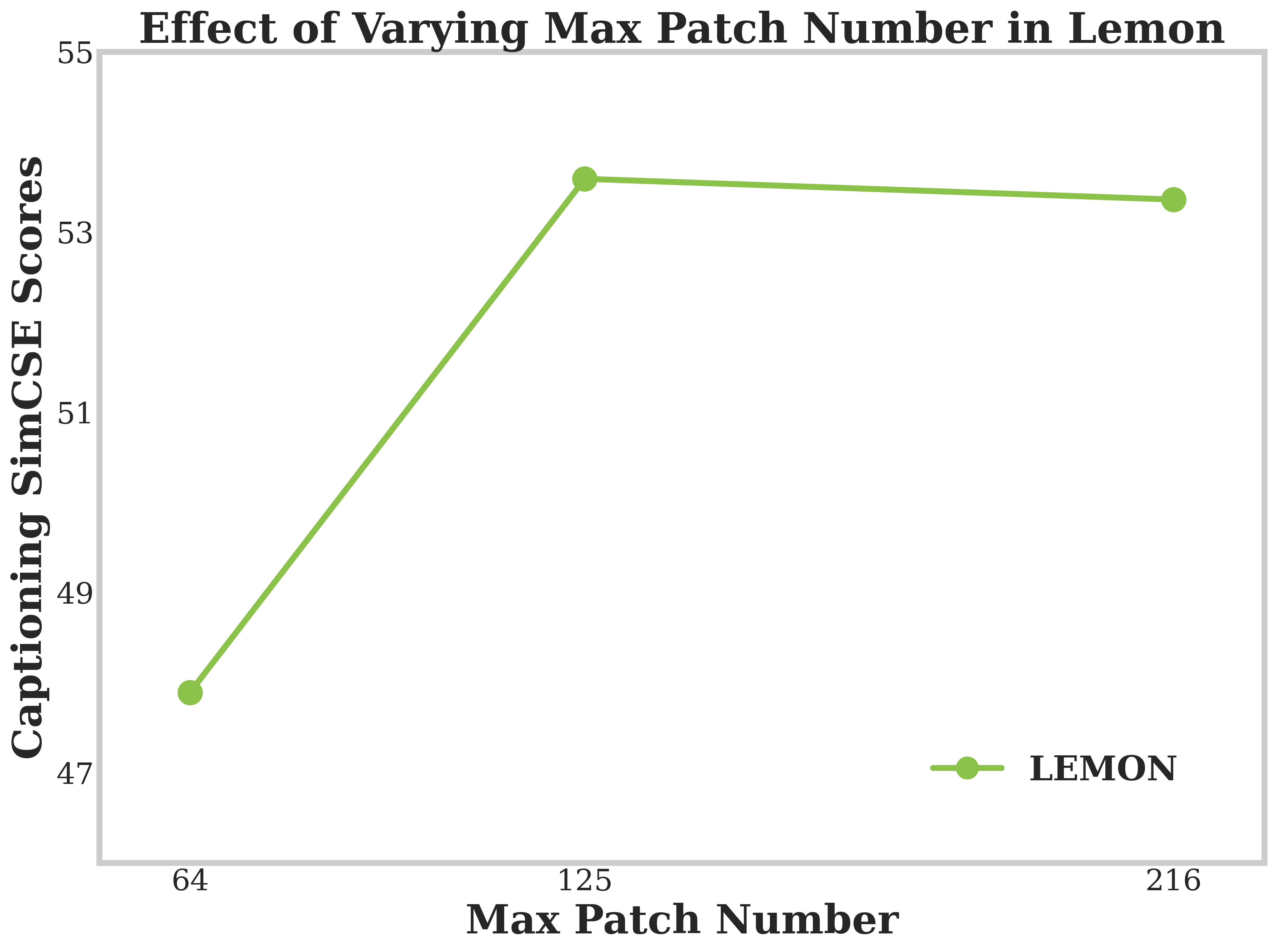
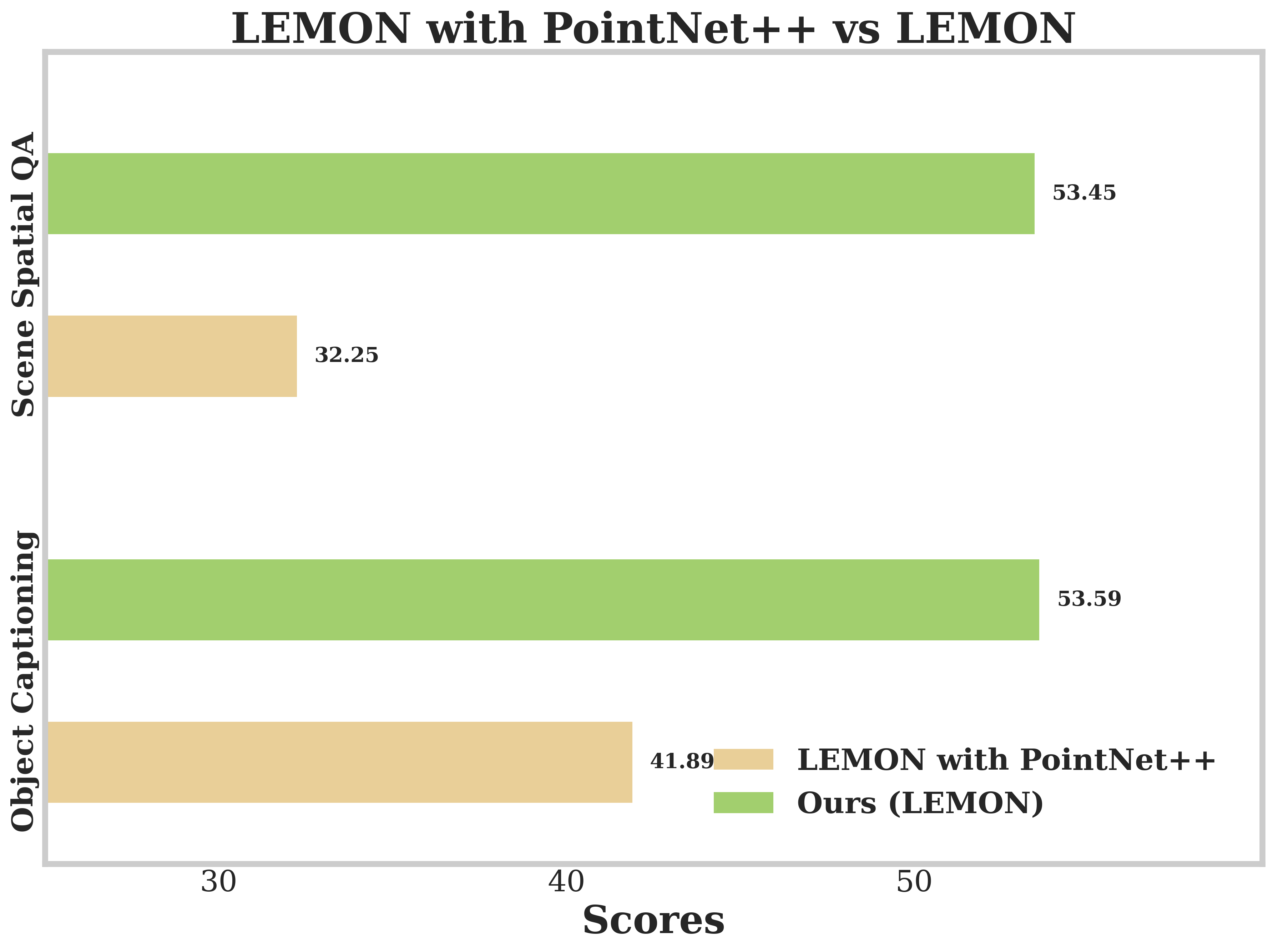
또한, Lemon은 3D 데이터의 특성에 맞게 구조화된 패치화 및 토큰화 방식을 개발하여 공간적 맥락을 유지하며, 세 단계 트레이닝 과정을 통해 점진적으로 능력을 확장합니다. 이러한 설계는 3D 이해와 추론 작업에서 뛰어난 성능을 보여주며, 특히 객체 인식과 캡셔닝 및 공간 추론에 있어서 새로운 최고 수준의 결과를 달성했습니다.
이 논문은 3D 데이터 처리에서의 중요한 도전 과제를 해결하고, 이를 통해 실제 응용 프로그램에서 3D 공간 지능을 발전시키는 데 기여할 수 있는 통합적인 기반을 제공합니다. Lemon 모델은 향후 연구와 개발에 있어 새로운 방향성을 제시하며, 특히 3D 데이터 처리를 필요로 하는 다양한 분야에서의 활용 가능성을 보여줍니다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리
Reference
이 글은 ArXiv의 공개 자료를 바탕으로 AI가 자동 번역 및 요약한 내용입니다.
저작권은 원저자에게 있으며, 인류 지식 발전에 기여한 연구자분들께 감사드립니다.