빅데이터 교육 실습 종합 보고서
📝 원문 정보
- Title: High-Dimensional Data Processing: Benchmarking Machine Learning and Deep Learning Architectures in Local and Distributed Environments
- ArXiv ID: 2512.10312
- 발행일: 2025-12-11
- 저자: Julian Rodriguez, Piotr Lopez, Emiliano Lerma, Rafael Medrano, Jacobo Hernandez
📝 초록 (Abstract)
이 문서는 빅 데이터 과정에서 구현된 연습과 방법론의 순서를 보고합니다. 에타psilon 데이터셋 처리부터 그룹 및 개인 전략, RestMex를 통한 텍스트 분석 및 분류, IMDb를 이용한 영화 특징 분석까지의 워크플로우를 상세히 설명하며, 마지막으로 Linux에서 Scala를 사용하여 Apache Spark를 활용한 분산 컴퓨팅 클러스터의 기술적 구현을 다룹니다.💡 논문 핵심 해설 (Deep Analysis)
종합 분석: 빅데이터 교육 실습 보고서
1. 연구 개요와 방법론
본 연구는 빅데이터 프로젝트의 통합적 접근 방식을 취하며, 세 가지 사례를 통해 다양한 데이터 유형과 규모에 대한 분석 기법을 다룹니다.
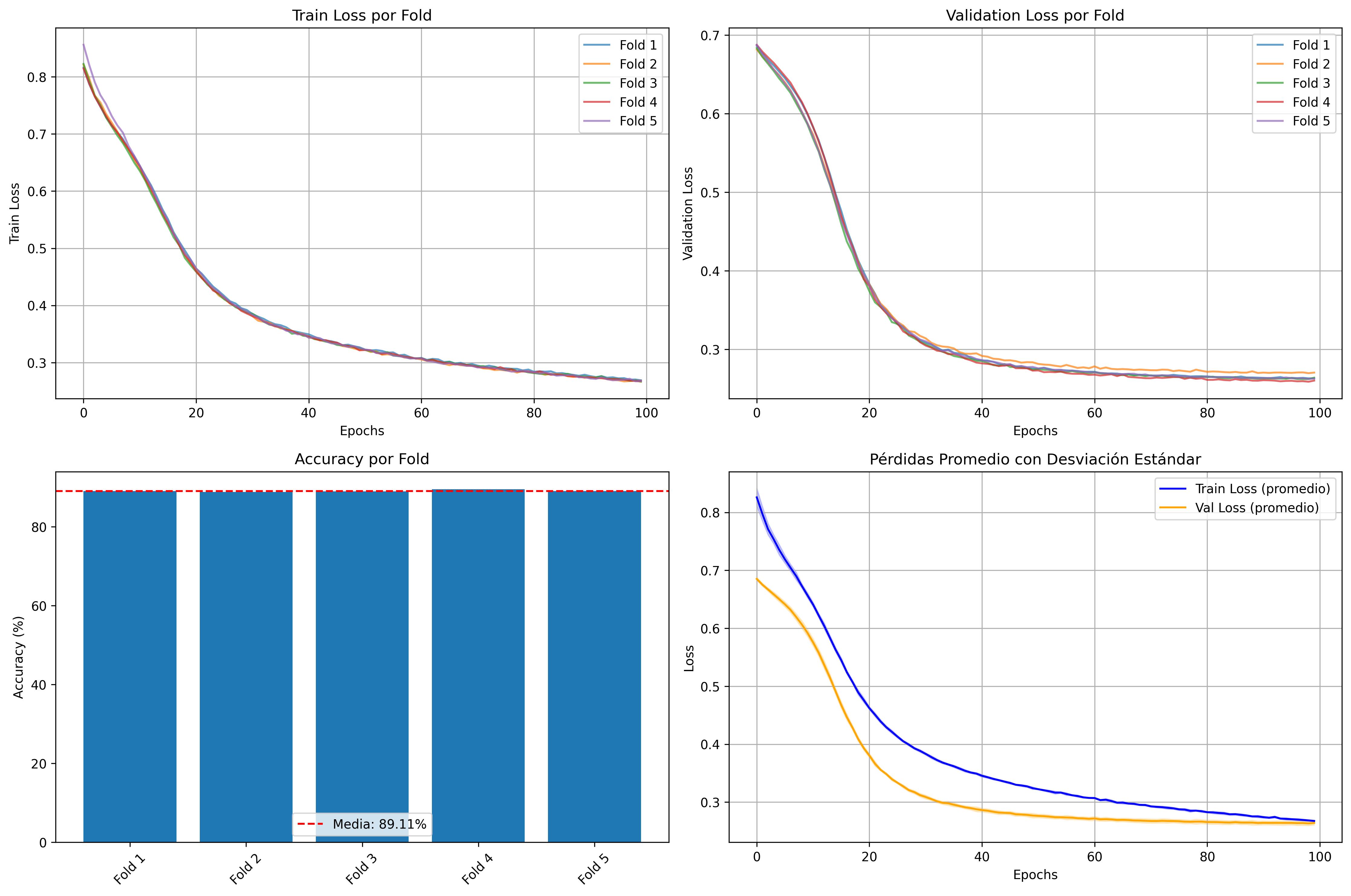
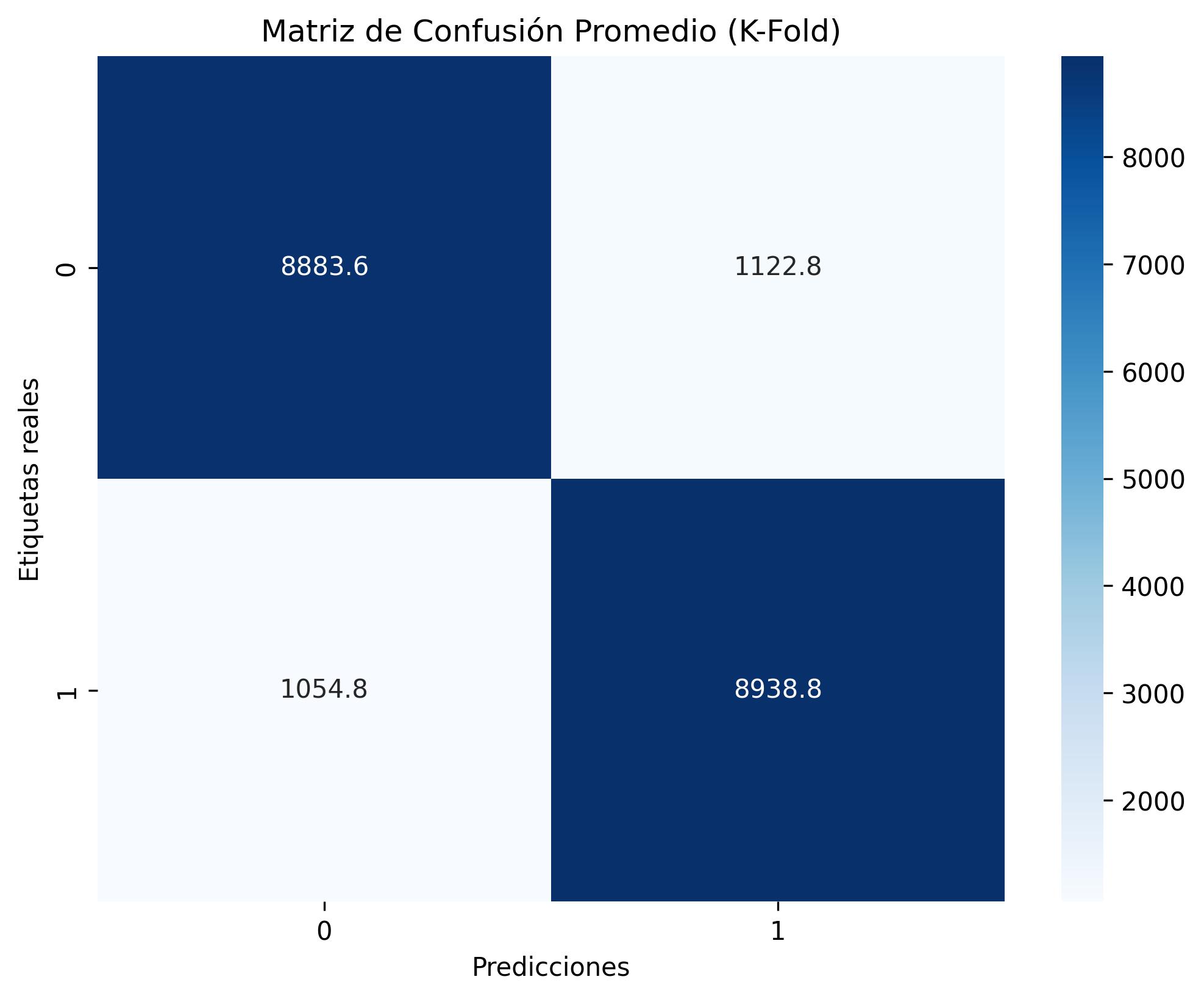
- Epsilon 데이터셋: 이진 분류 문제를 해결하기 위해 MLP 모델을 사용하여 2000개의 특징과 100,000개의 인스턴스로 훈련되었습니다. PyTorch와 GPU 가속(CUDA)을 활용해 88.98%의 정확도를 달성했습니다.
- Rest-Mex 데이터셋: 멕시코 관광 리뷰 데이터셋에 대해 감정 분석 파이프라인을 구현하였습니다. 텍스트 전처리, CountVectorizer 또는 TF-IDF 벡터화, 클래스 가중 기법 등을 사용하여 3가지 감정(긍정적, 부정적, 중립)으로 카테고리화했습니다.
- IMDb 영화 설명 데이터셋: 심층 텍스트 분석을 통합한 지속적인 등급 예측 모델을 구현하였습니다. TF-IDF를 사용하여 85,855개의 영화에 대한 정보를 벡터화하고, XGBoost 회귀기를 통해 RMSE 0.6001과 R² 0.79의 성능을 달성했습니다.
2. Epsilon 데이터셋 분석
Epsilon은 고차원 이진 분류 문제에 적합한 벤치마크 데이터셋입니다. 본 연구에서는 PyTorch를 사용하여 MLP 모델을 구현하고, GPU 가속(CUDA)을 활용해 훈련 과정에서 높은 성능을 달성했습니다.
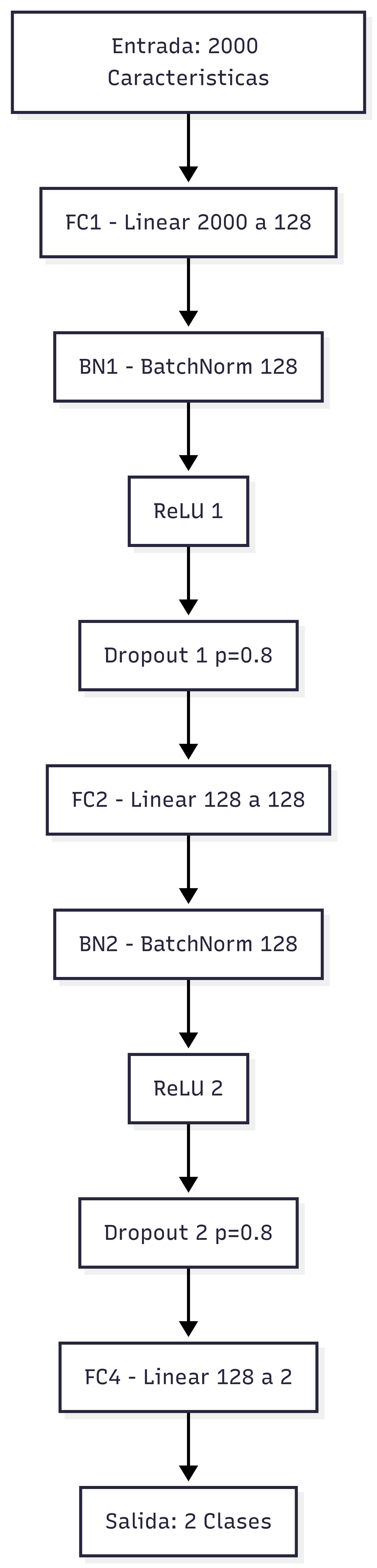
MLP 아키텍처: 순차 블록(FC), 배치 정규화(BN), 활성화 함수(ReLU), 드롭아웃 등을 포함합니다.
하이퍼파라미터 설정:
- 입력 크기: 2,000
- 은닉 크기: 128
- 출력 크기: 2 (이진 분류)
- 학습률: (1 \times 10^{-5})
- 가중치 감소(L2 정규화): (1 \times 10^{-4})
- 에포크 수: 100
- 배치 크기: 128
성능 평가: K-Fold 교차 검증을 통해 최고 평균 정확도 89.18%를 달성했습니다.
3. Rest-Mex 데이터셋 분석
Rest-Mex는 멕시코 관광 리뷰 데이터셋으로, 감정 분류 모델 구현에 사용되었습니다. 텍스트 전처리와 벡터화 기법을 통해 감독 학습 분류 모델을 구축하였습니다.
- 전처리 단계: 토큰화, 불용어 제거, 레마티제이션
- 벡터화 방법: CountVectorizer 또는 TF-IDF 사용
- 감정 분석 결과:
- 중립: 46.83%
- 긍정적: 32.65%
- 부정적: 20.52%
4. IMDb 영화 설명 데이터셋 분석
IMDb 데이터셋은 심층 텍스트 분석을 통한 지속적인 등급 예측 모델 구현에 사용되었습니다.
- TF-IDF 벡터화: 5,000개의 특징과 해싱 TF, minDocFreq=3
- XGBoost 회귀기: 최적화된 하이퍼파라미터 조합과 3-폴드 교차 검증을 통해 RMSE 0.6001과 R² 0.79의 성능을 달성했습니다.
- 감정 분석 결과:
- 중립: 46.83%
- 긍정적: 32.65%
- 부정적: 20.52%
5. 분산 컴퓨팅 환경
본 연구에서는 Apache Spark를 사용한 분산 처리 아키텍처를 설계하고 구현하였습니다.
- 클러스터 구성: 4개의 노드로 구성된 클러스터, 각 노드는 8GB 메모리와 8코어
- 성능 평가:
- 선형 SVC: 가장 효율적인 알고리즘으로, 136.57초 만에 훈련 완료
- AUC-ROC 점수: 최고 성능 (0.9504)
6. 결론
본 연구는 빅데이터 분석의 다양한 측면을 다루며, 이진 분류, 감정 분석, 지속적인 등급 예측에 걸친 기계 학습 기법을 통합하였습니다. 특히, 분산 컴퓨팅 환경에서 선형 모델이 높은 성능과 효율성을 보여주었으며, 이는 빅데이터 처리의 실용적 이점을 입증합니다.
참고 문헌
- Shalev-Shwartz et al., 2011: Pegasos 알고리즘에 대한 연구
- Verma & Verma, 2019: 볼리우드 영화 예측 모델 개발
본 보고서는 빅데이터 분석의 다양한 측면을 다루며, 실제 프로젝트에서 활용 가능한 기법과 접근 방식을 제시합니다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리
Reference
이 글은 ArXiv의 공개 자료를 바탕으로 AI가 자동 번역 및 요약한 내용입니다.
저작권은 원저자에게 있으며, 인류 지식 발전에 기여한 연구자분들께 감사드립니다.