트랜스포머 기반의 전역 다목적 최적화: TAMO로 과학적 발견 가속화
읽는 시간: 3 분
...
📝 원문 정보
- Title: In-Context Multi-Objective Optimization
- ArXiv ID: 2512.11114
- 발행일: 2025-12-11
- 저자: Xinyu Zhang, Conor Hassan, Julien Martinelli, Daolang Huang, Samuel Kaski
📝 초록 (Abstract)
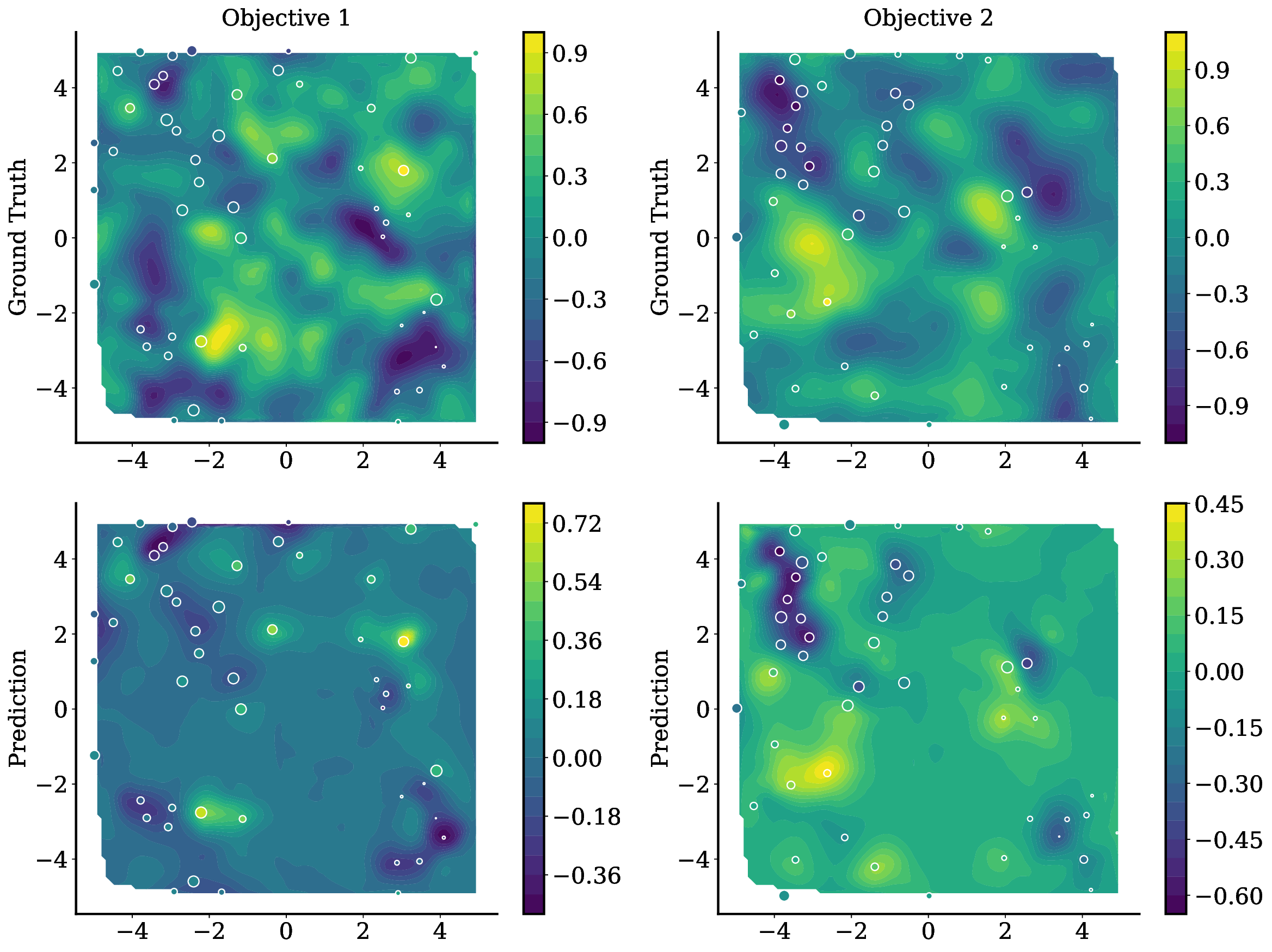
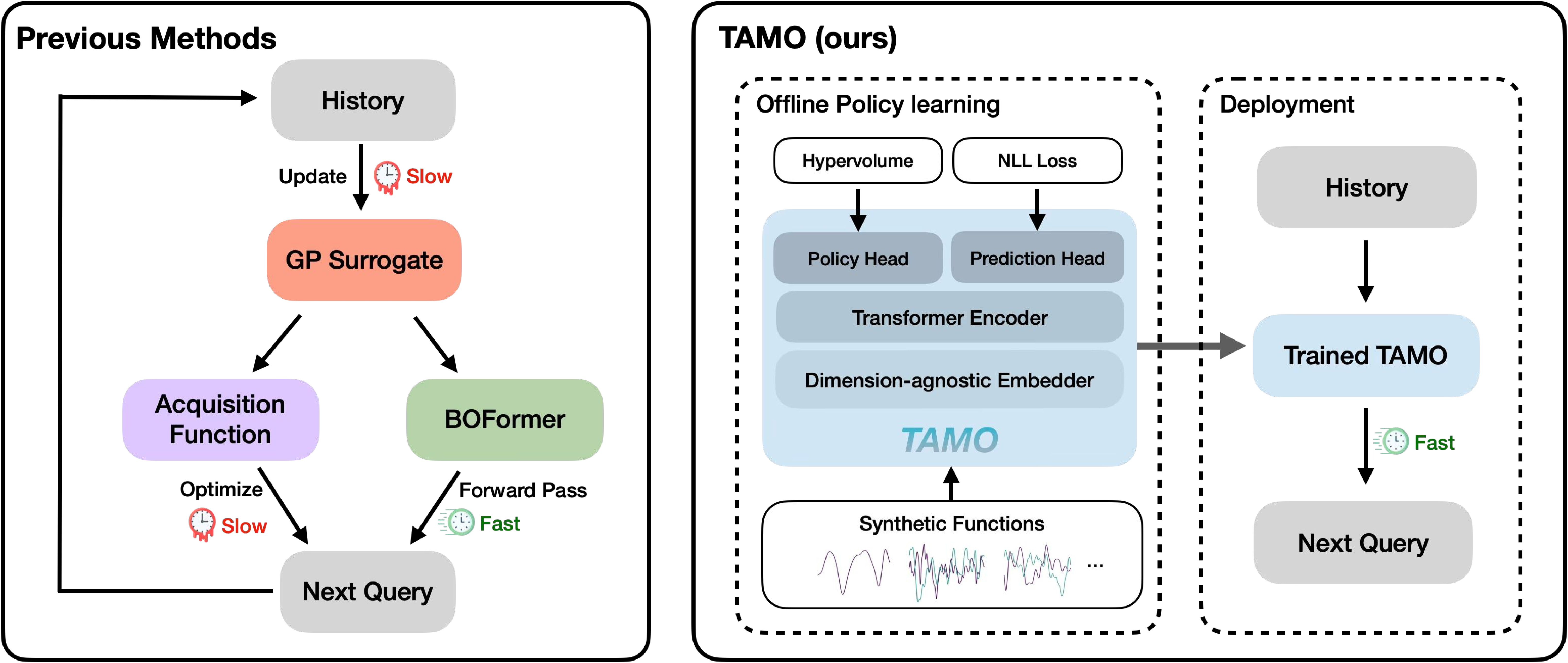
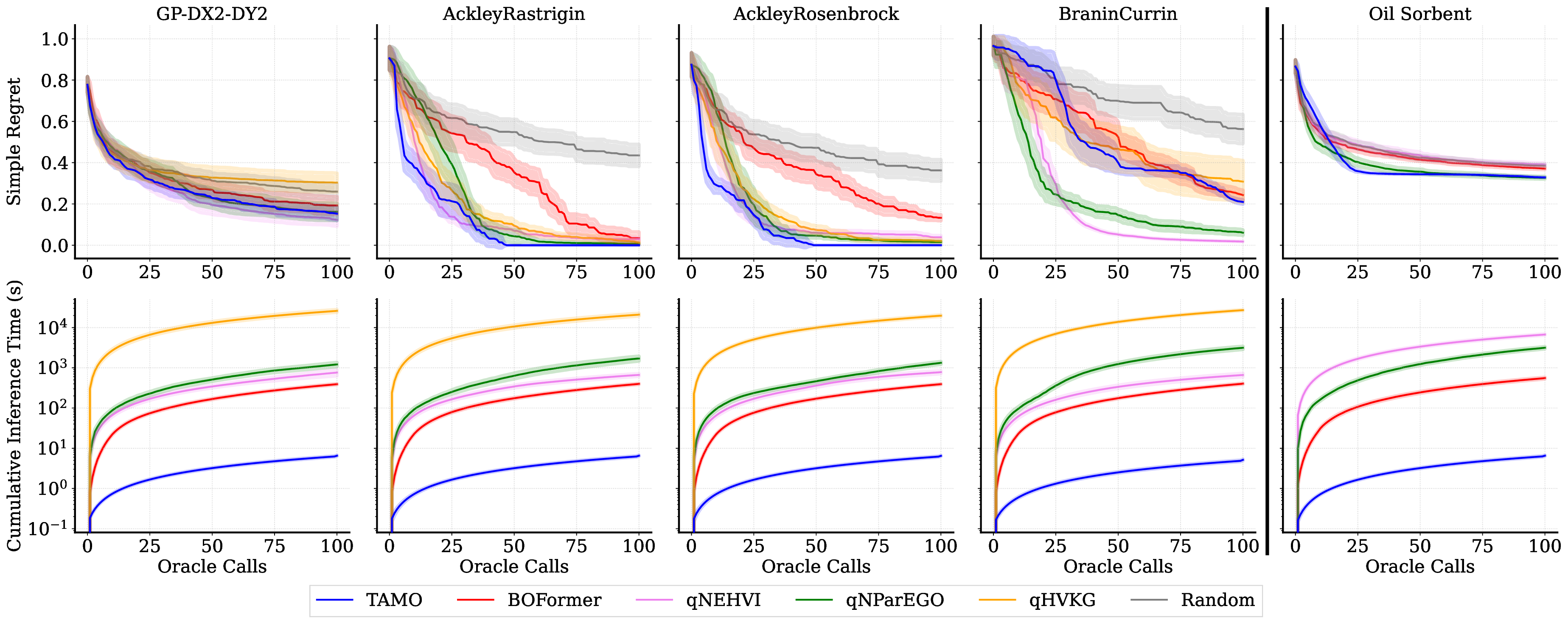
다양한 분야에서 상충하는 목표를 균형 있게 조정하는 것은 필수적입니다. 이는 약물 설계부터 자율 시스템에 이르기까지 적용됩니다. 다목적 베이지안 최적화는 이러한 비용이 많이 들고 흑자상자의 문제에 대한 유망한 해결책으로, 확률론적인 대리 모델을 적합시키고 탐색과 활용 사이의 균형을 맞추기 위해 새로운 설계를 선택하는 획득 함수를 사용합니다. 실제로는 각 문제마다 특화된 대리 모델과 획득 함수를 선택해야 하며, 이러한 설정은 다음 문제에 거의 전달되지 않습니다. 또한 다단계 계획이 필요한 경우 단시안적일 수 있으며, 특히 병렬 또는 시간 민감한 루프에서는 재적합 오버헤드가 발생합니다. 우리는 TAMO라는 완전히 앰마타이즈된, 다목적 흑자상 최적화를 위한 전역 정책을 제시합니다. TAMO는 다양한 입력 및 목표 차원에서 작동하는 트랜스포머 아키텍처를 사용하여 다양한 코퍼러스에서 사전 학습하고 새로운 문제로 이전할 수 있습니다: 테스트 시, 사전 학습된 모델은 단일 전방 패스로 다음 설계를 제안합니다. 정책을 전체 트레젝토리에 대한 누적 하이퍼볼륨 개선을 최대화하도록 강화 학습으로 사전 학습합니다. 전체 쿼리 기록을 조건부로 설정하여 파레토 전선을 근사합니다. 인공 벤치마크와 실제 작업에서, TAMO는 제안 시간을 대체 옵션에 비해 50-1000배까지 줄이면서 긴박한 평가 예산 하에서 파레토 품질을 일치시키거나 개선합니다. 이러한 결과는 트랜스포머가 완전히 문맥 내에서 다목적 최적화를 수행할 수 있음을 보여주며, 각 작업별 대리 모델 적합과 획득 엔지니어링을 제거하고 과학적 발견 워크플로우에 대한 플러그 앤 플레이 최적화를 위한 기초적인 경로를 열었습니다.💡 논문 핵심 해설 (Deep Analysis)
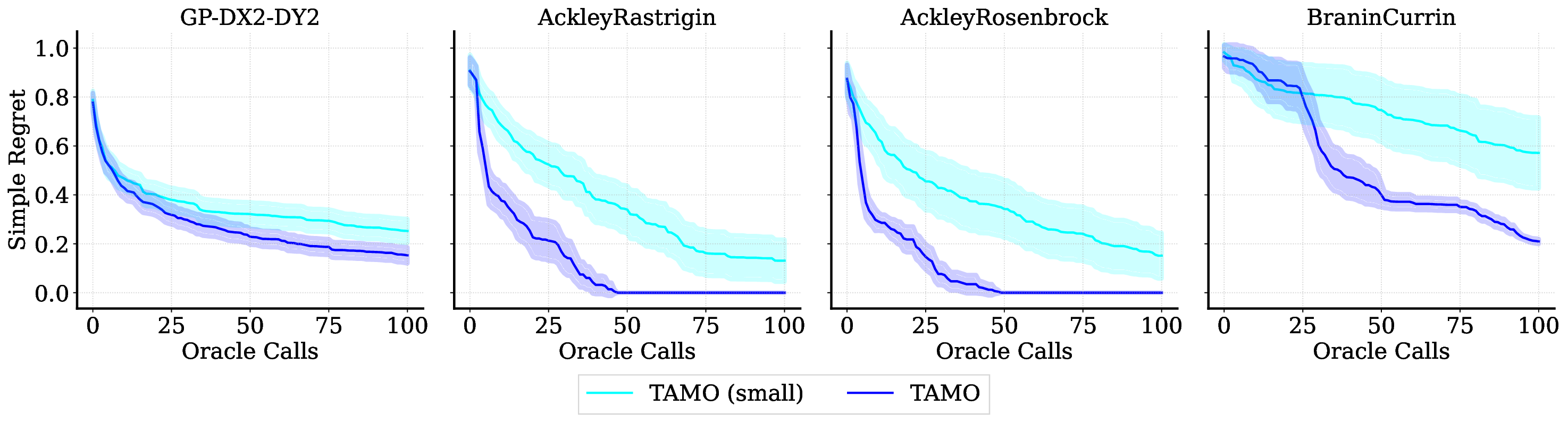
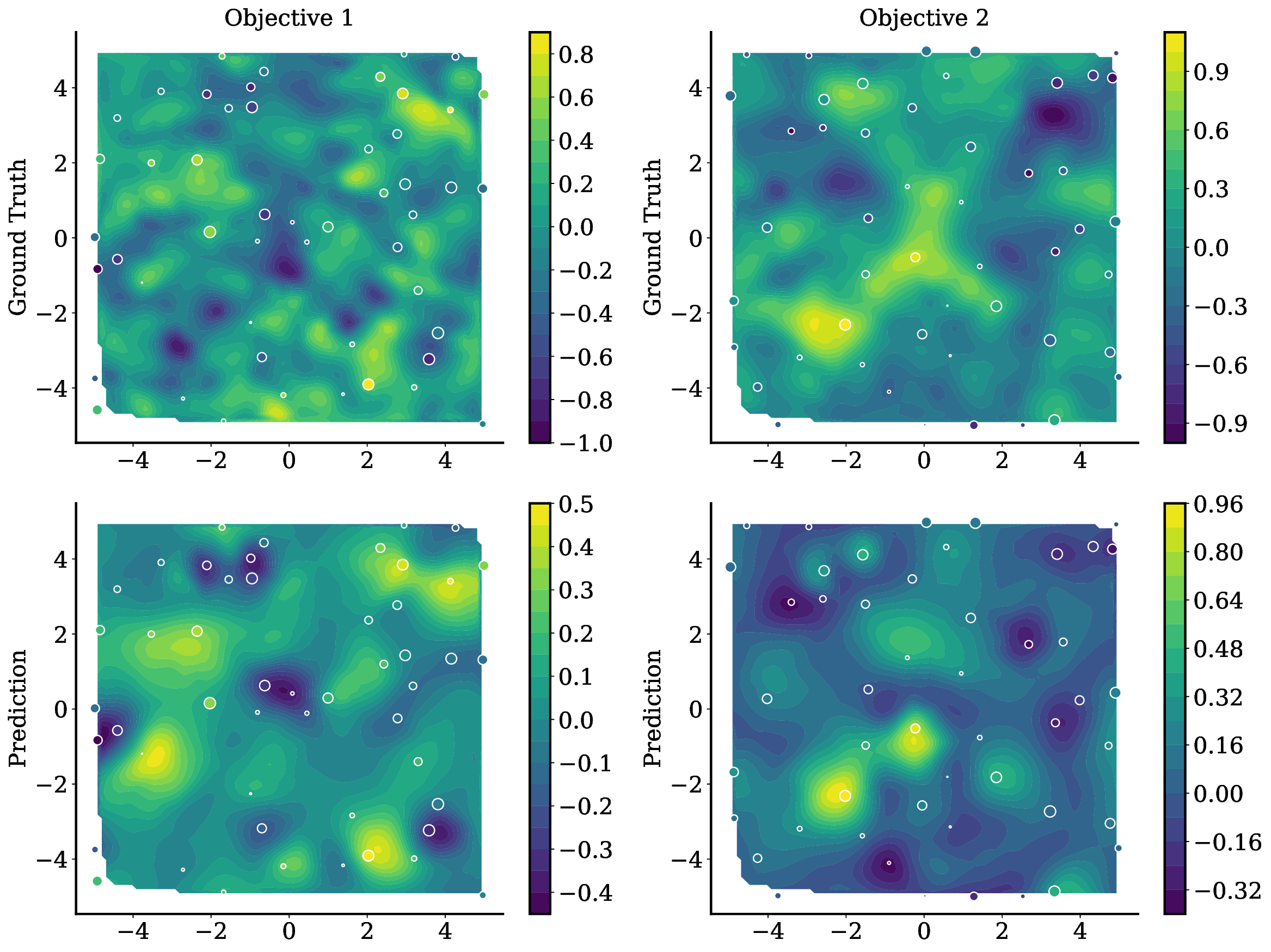
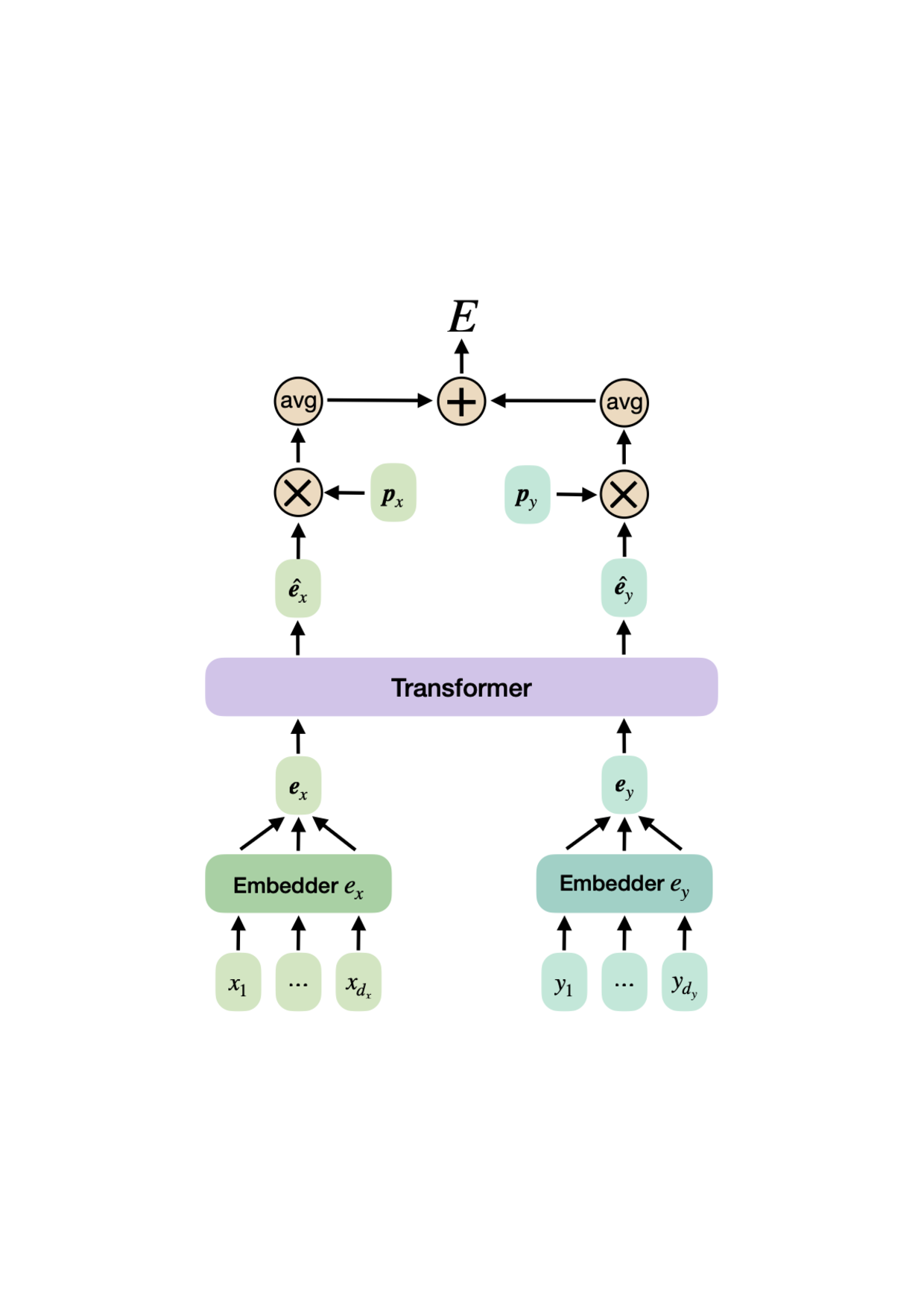
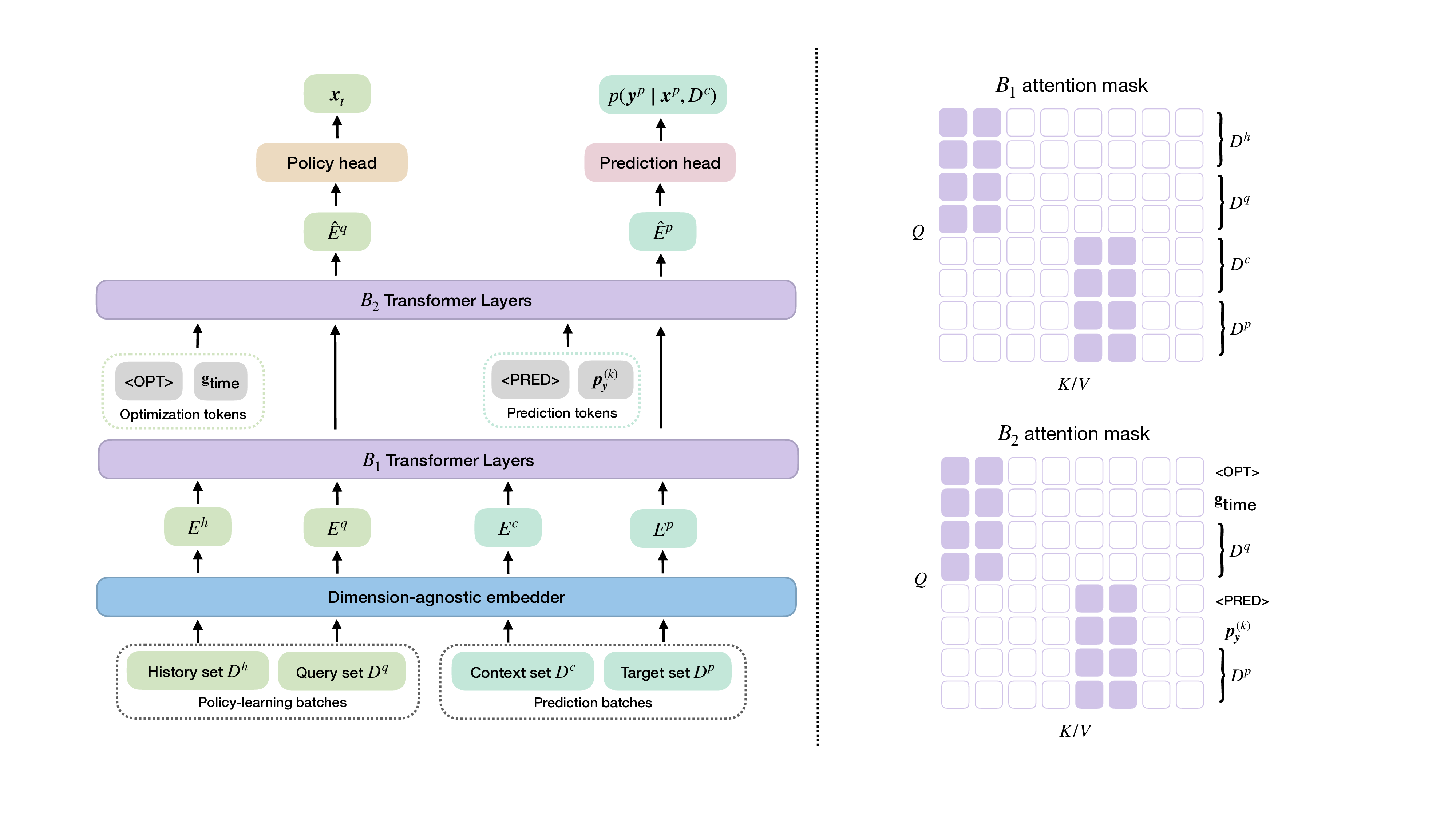
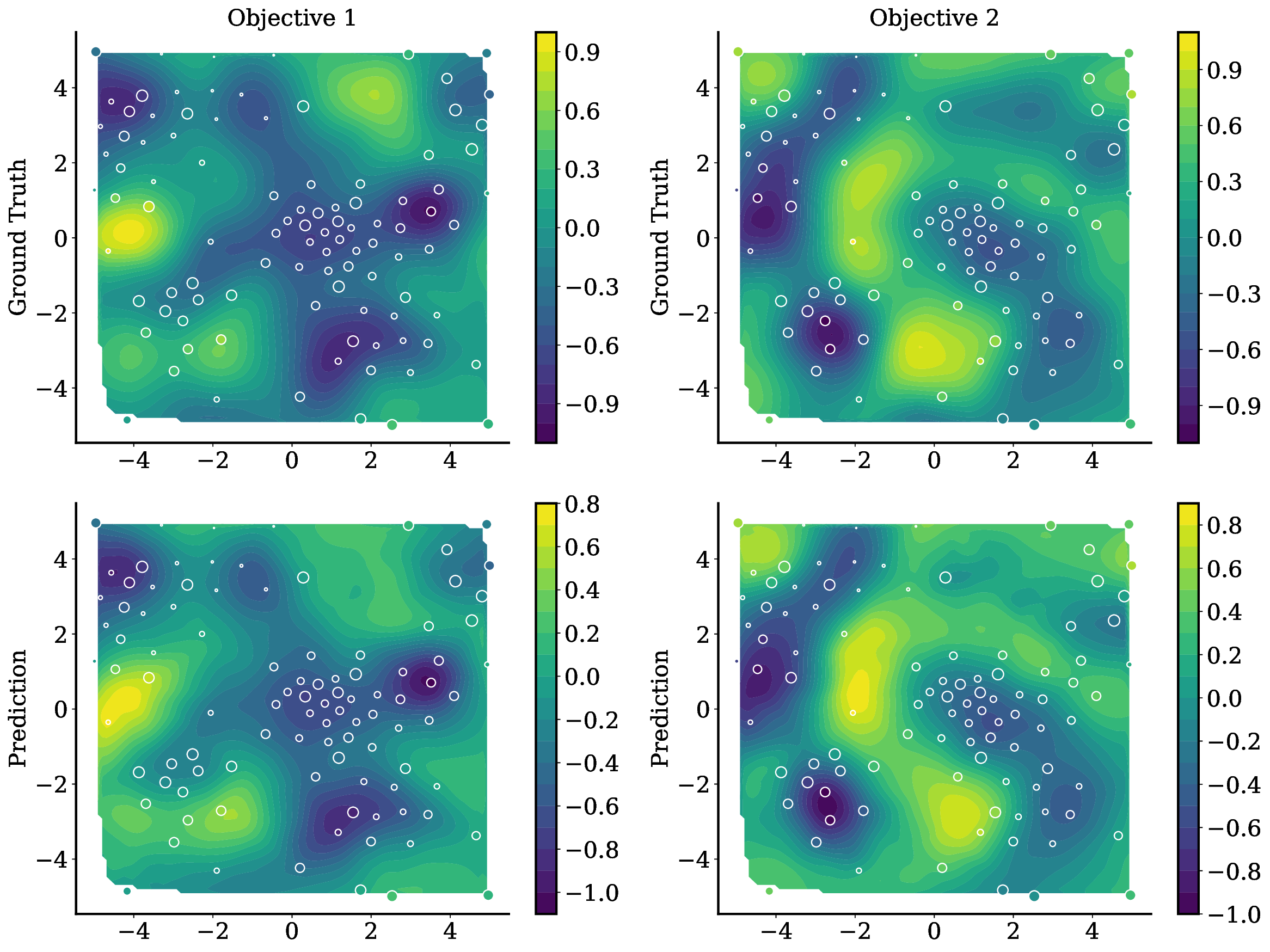
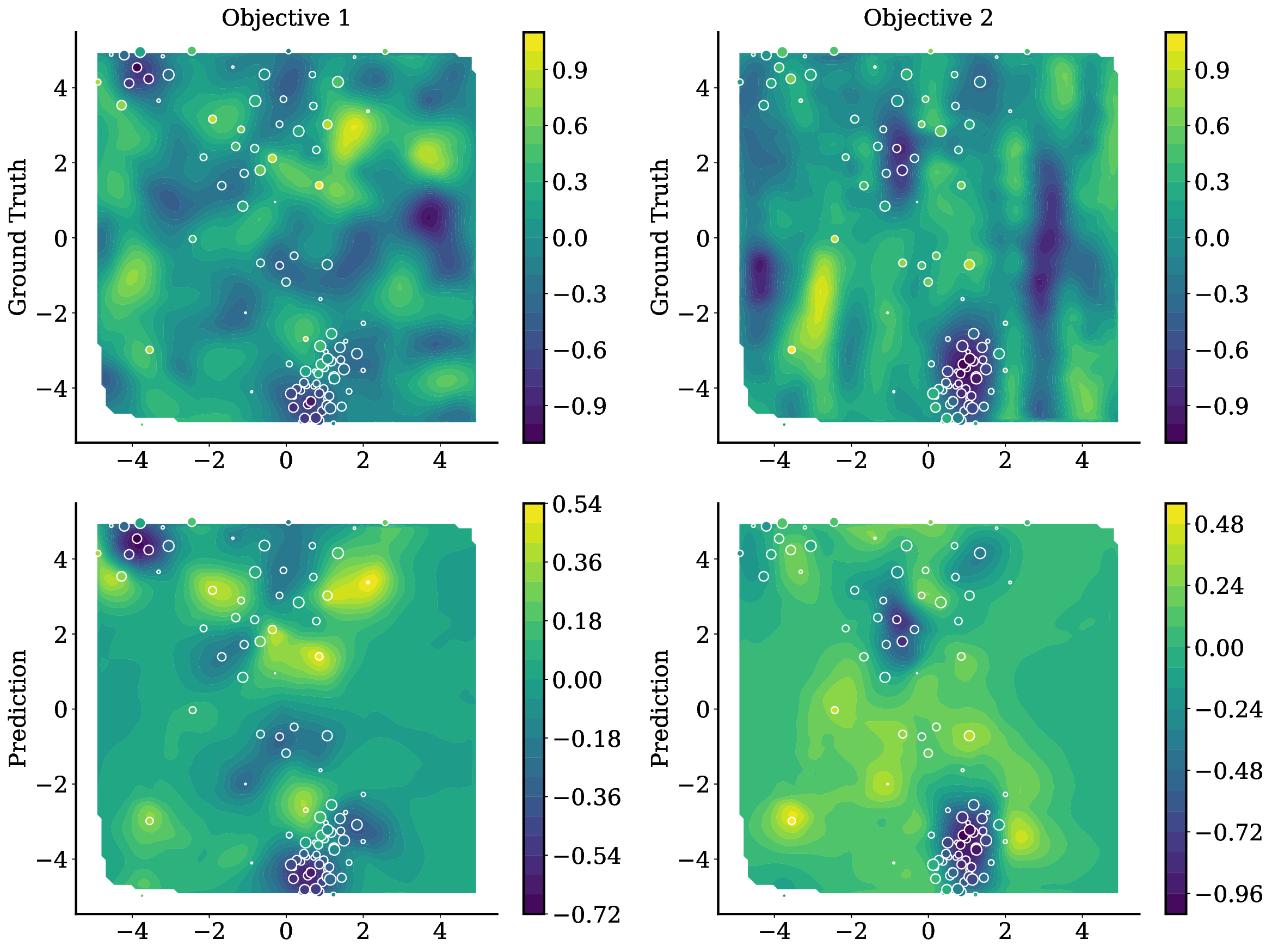
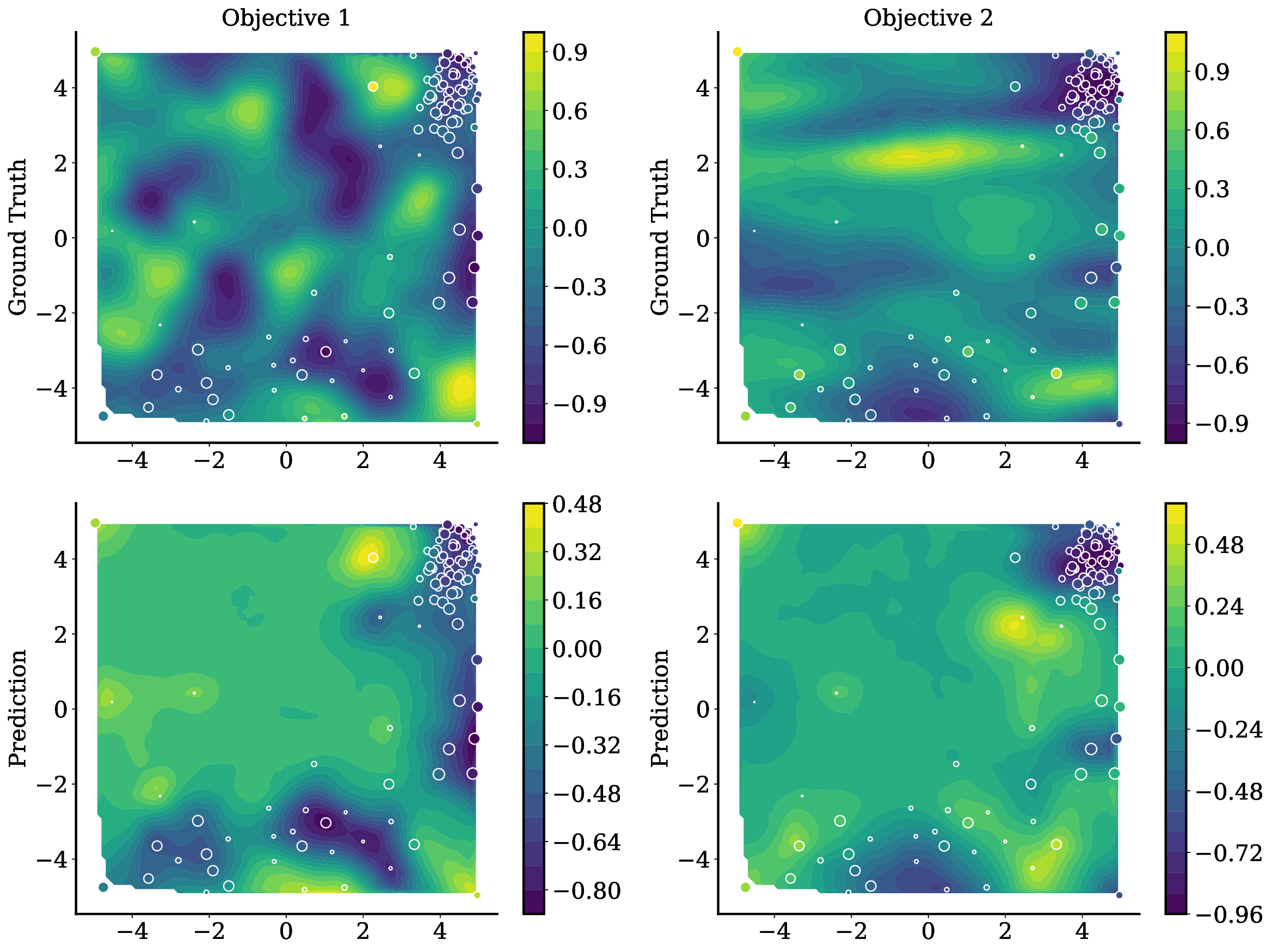
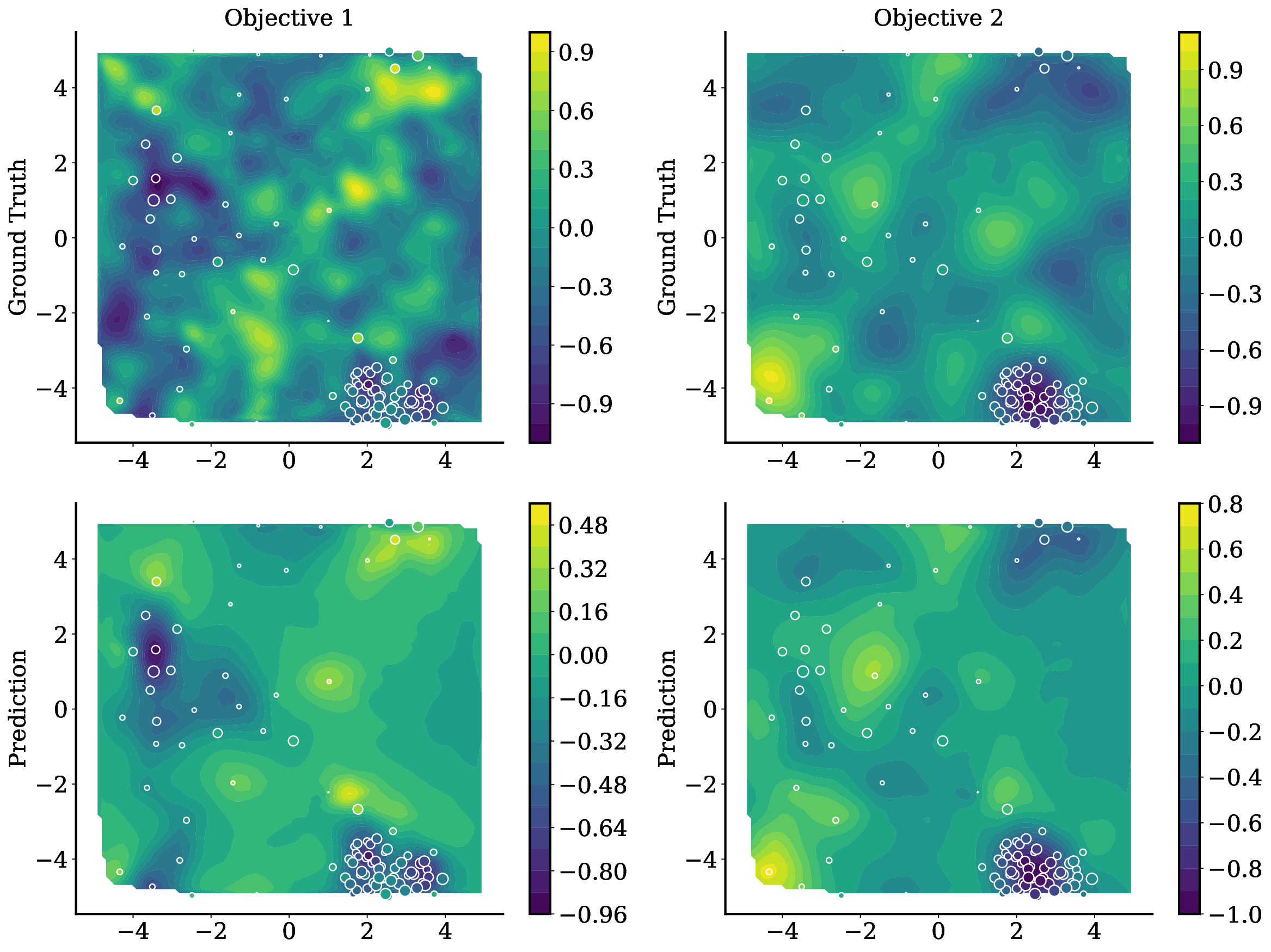
TAMO는 이러한 제약을 극복하기 위해 트랜스포머를 사용하여 다양한 입력 및 목표 차원에서 작동할 수 있도록 설계되었습니다. 이를 통해 TAMO는 사전 학습된 모델을 새로운 문제에 적용하는 데 필요한 재학습 없이도 효과적인 최적화를 수행할 수 있습니다. 특히, 강화 학습을 사용하여 정책을 사전 학습함으로써 전체 쿼리 기록을 조건부로 설정하고 파레토 전선을 근사하는 데 성공했습니다.
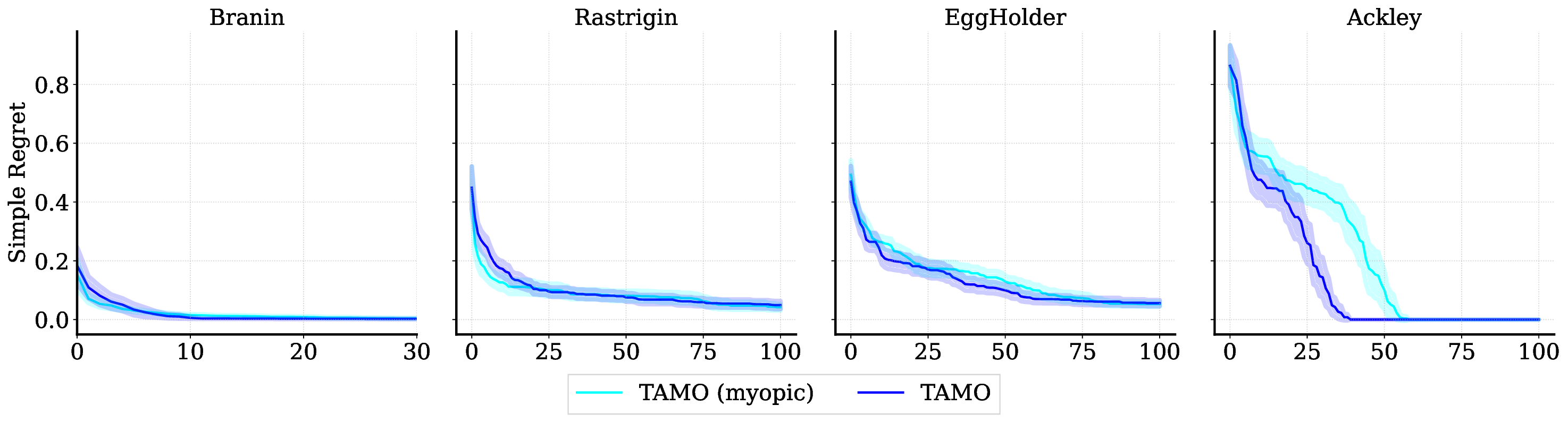
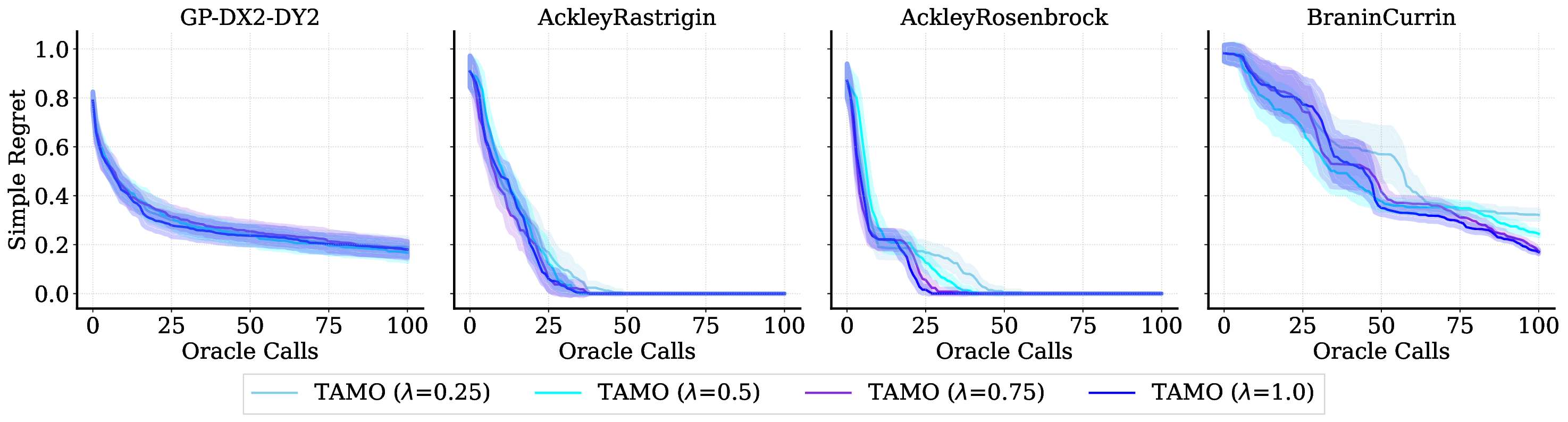
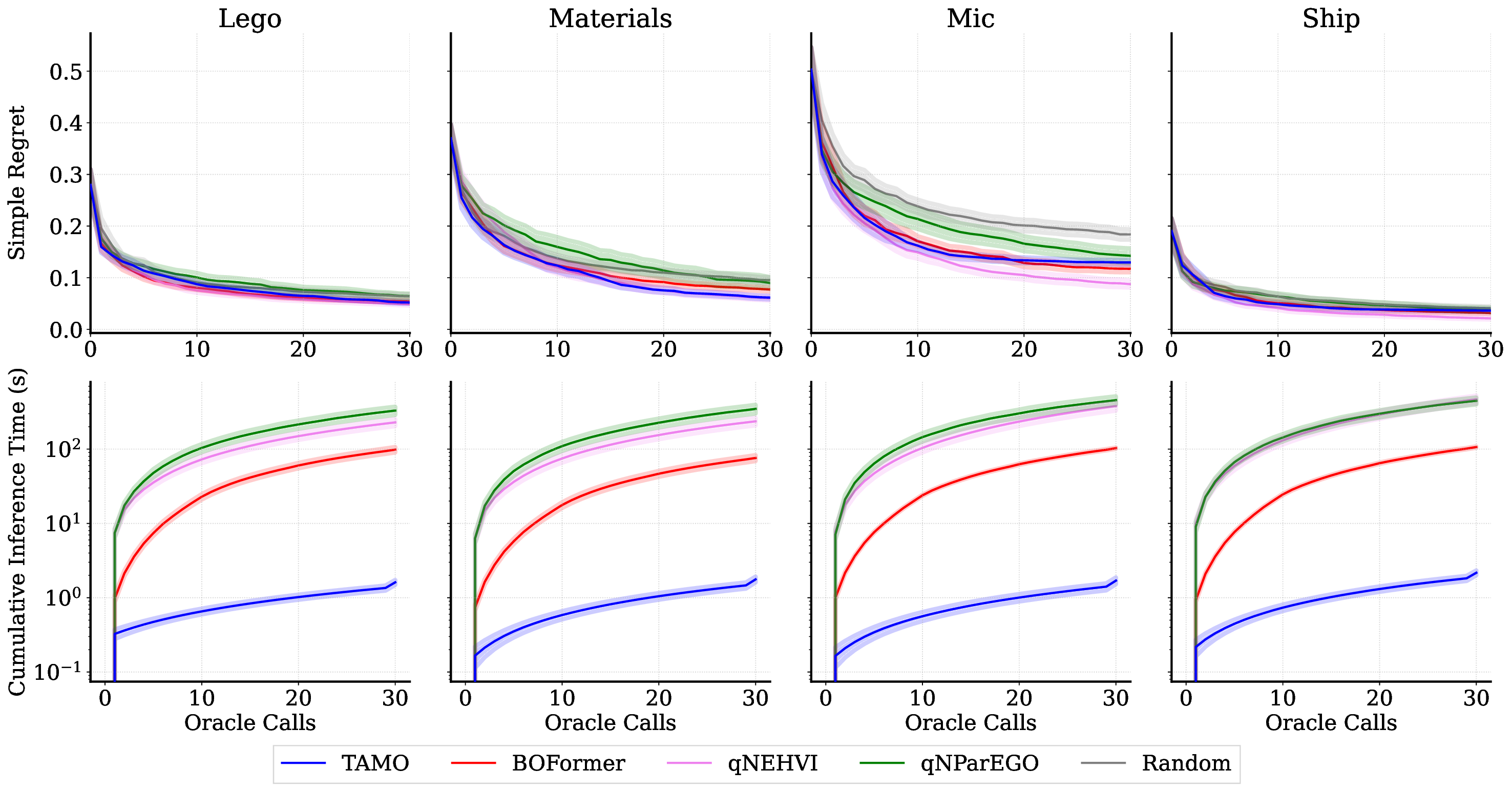
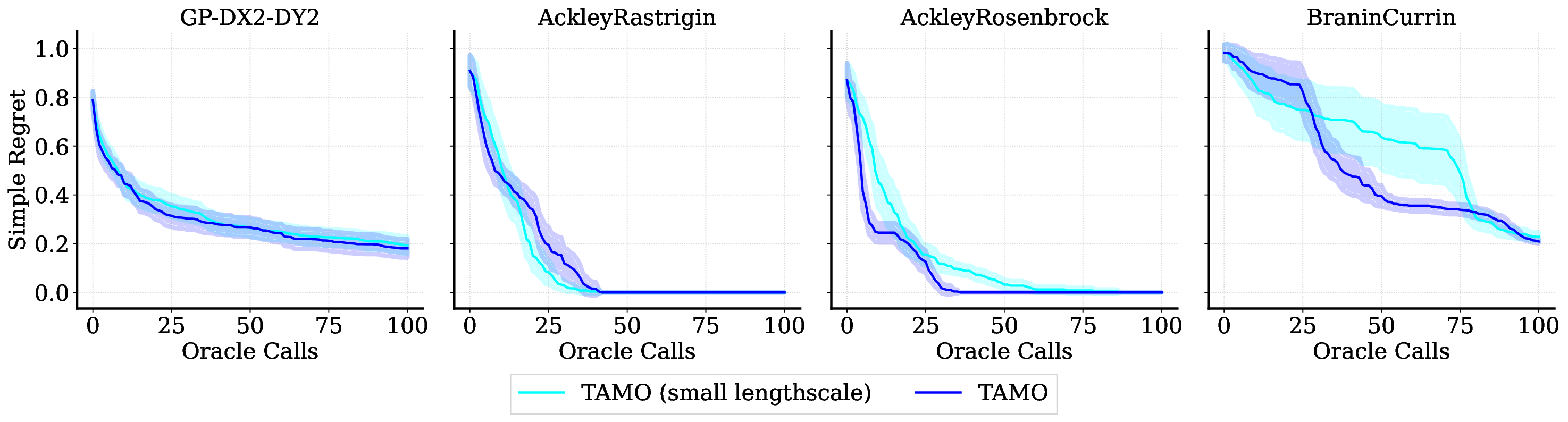
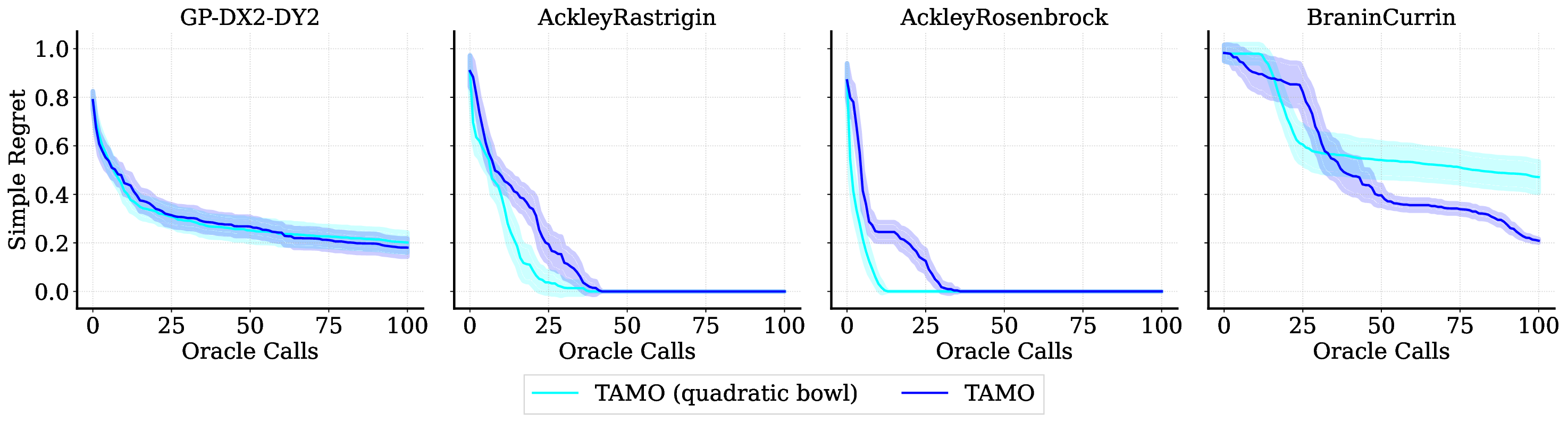
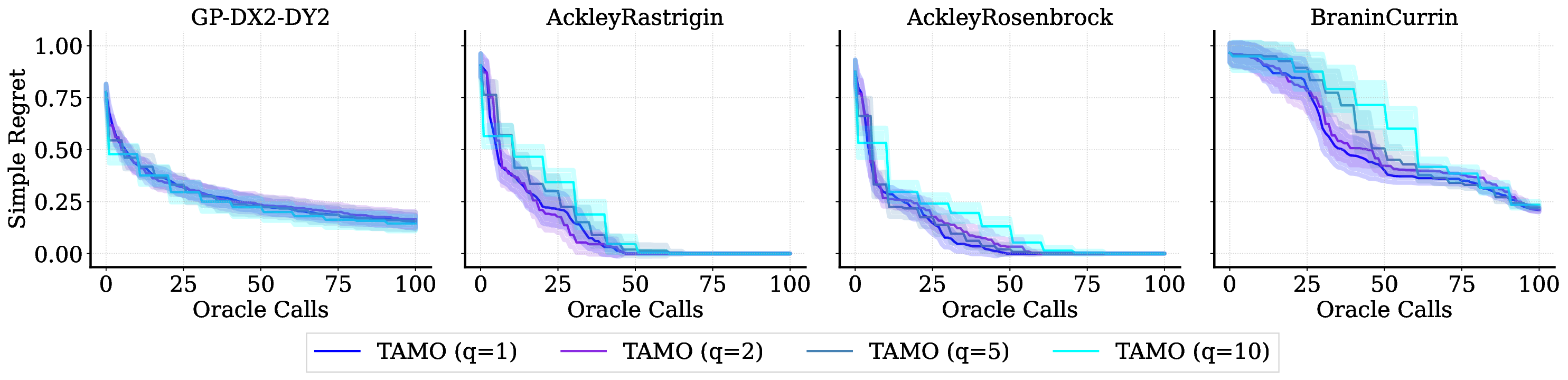
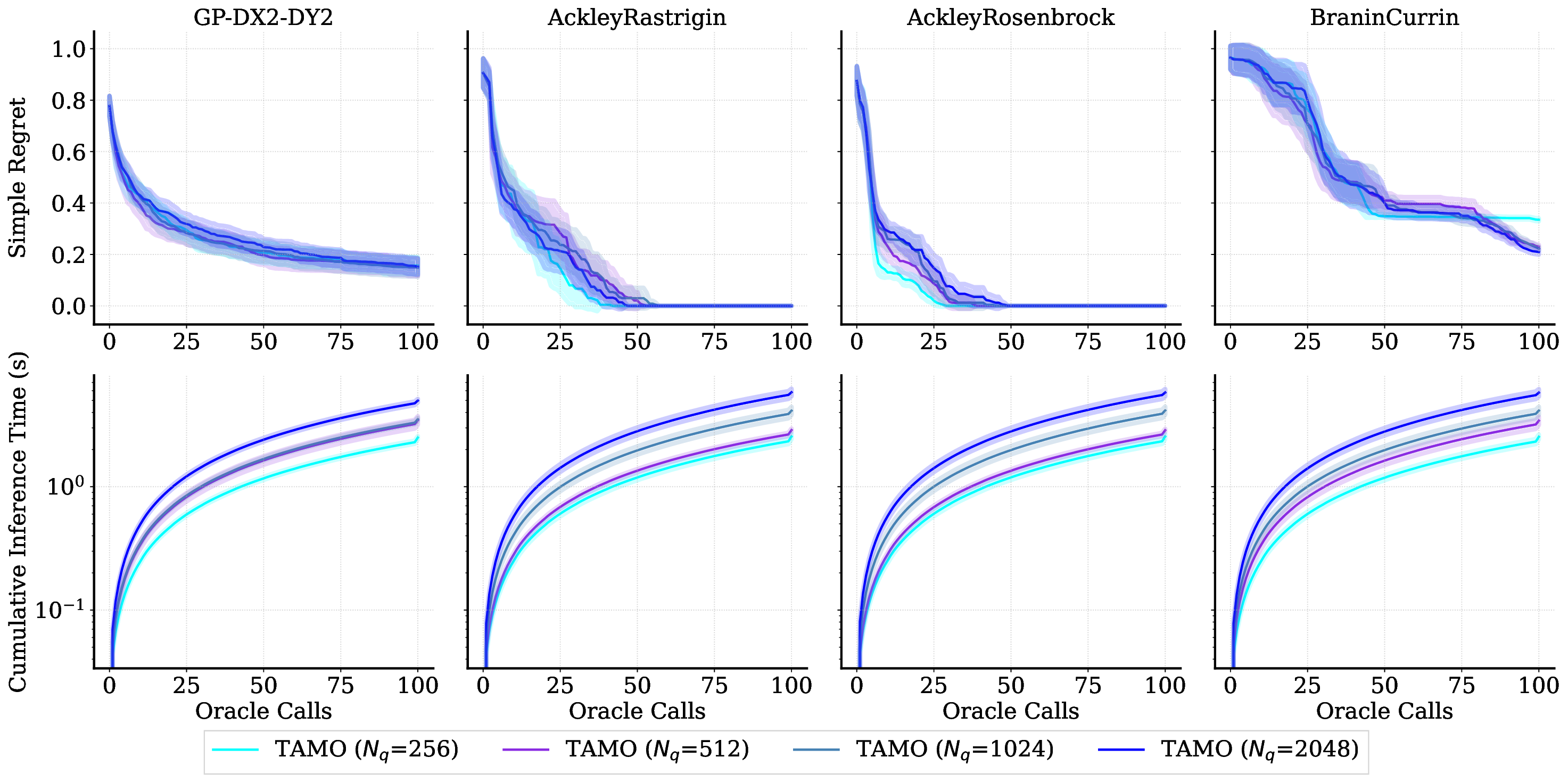
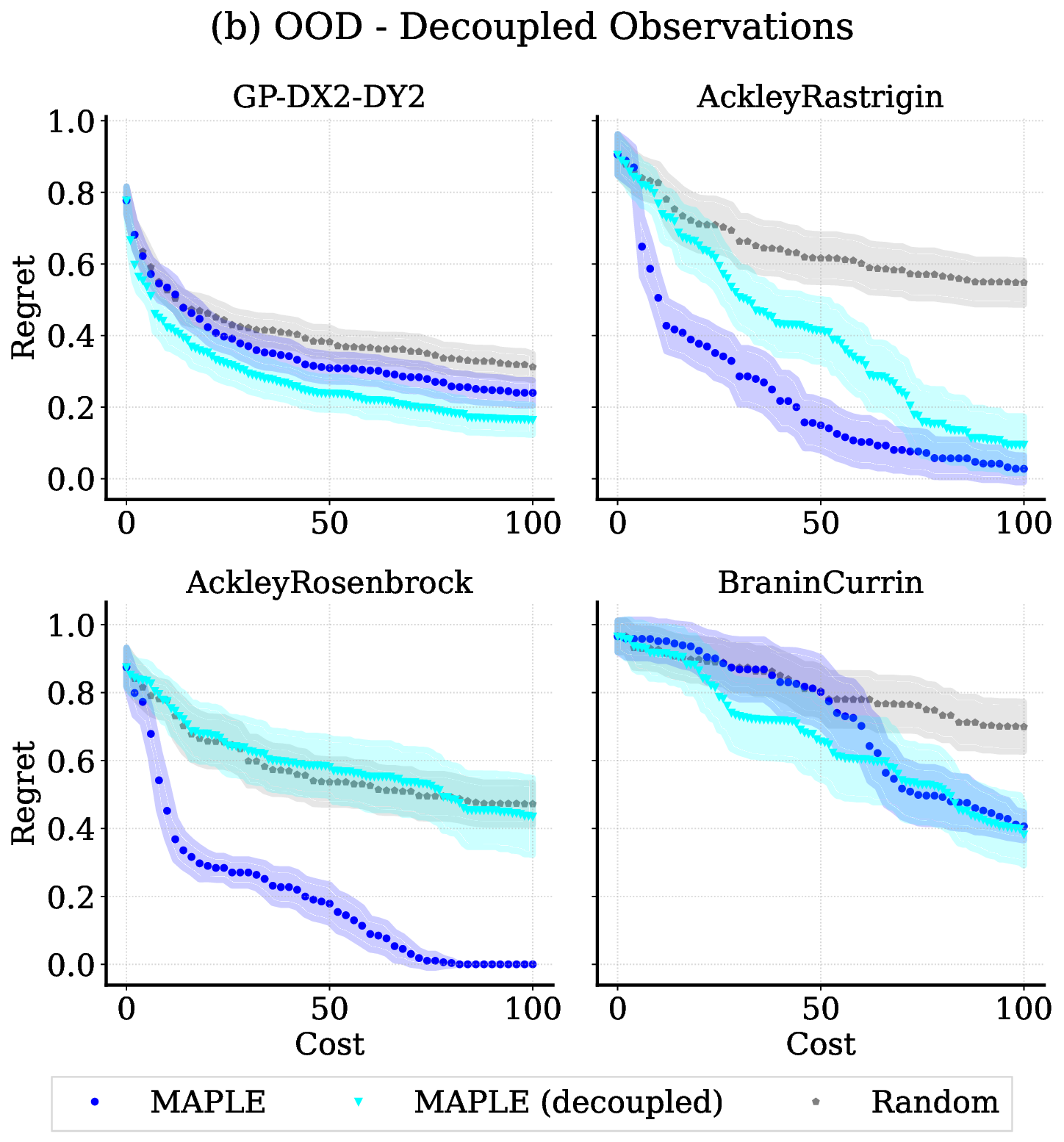
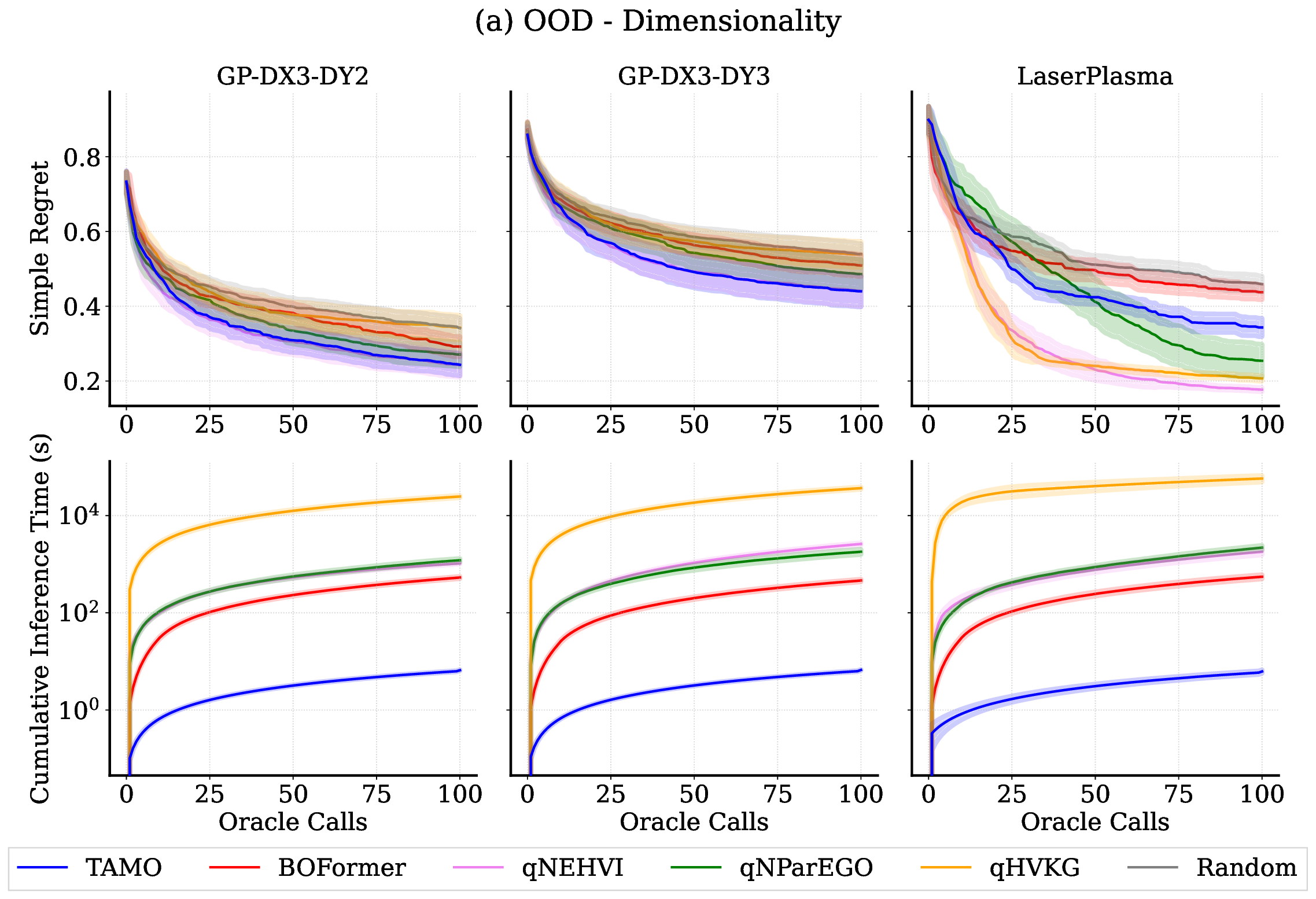
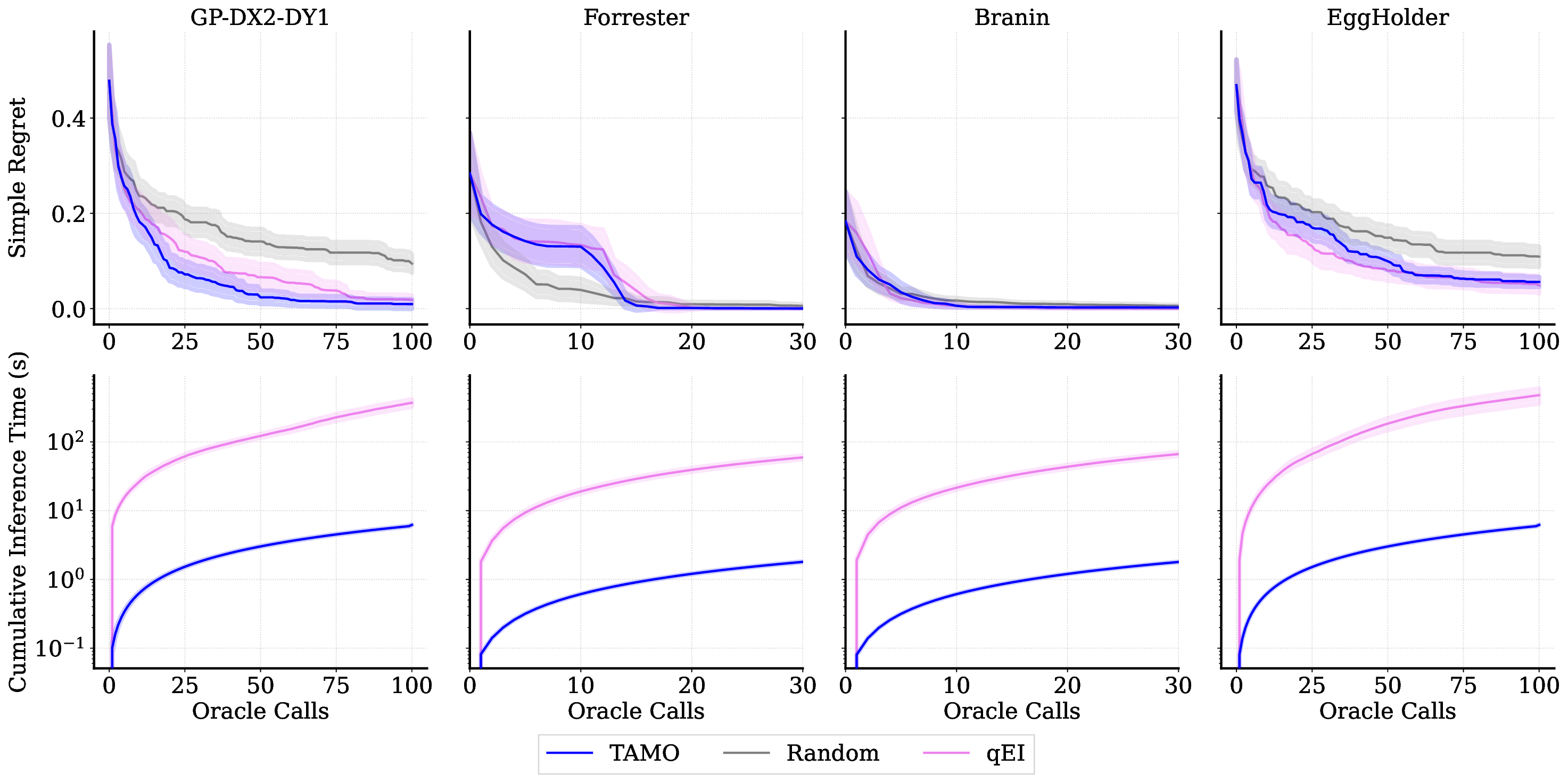
실험 결과는 TAMO의 효율성을 입증합니다. 인공 벤치마크와 실제 작업에서, TAMO는 제안 시간을 대체 옵션에 비해 50-1000배까지 줄이면서 파레토 품질을 일치시키거나 개선하는 데 성공했습니다. 이러한 결과는 트랜스포머가 완전히 문맥 내에서 다목적 최적화를 수행할 수 있음을 보여주며, 각 작업별 대리 모델 적합과 획득 엔지니어링을 제거하고 과학적 발견 워크플로우에 대한 플러그 앤 플레이 최적화를 위한 기초적인 경로를 열었습니다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리
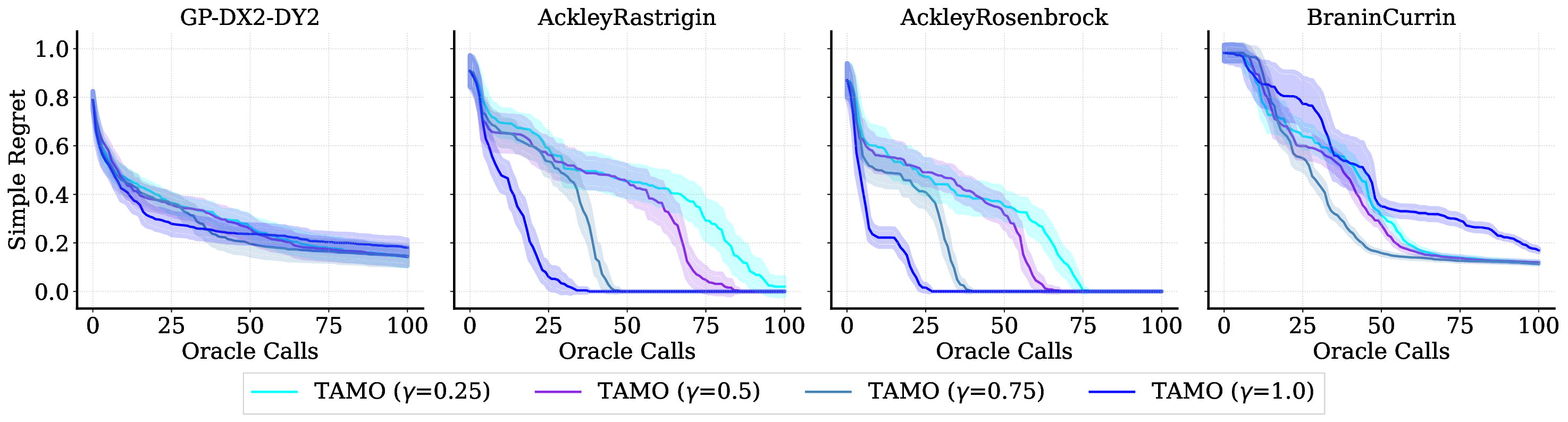
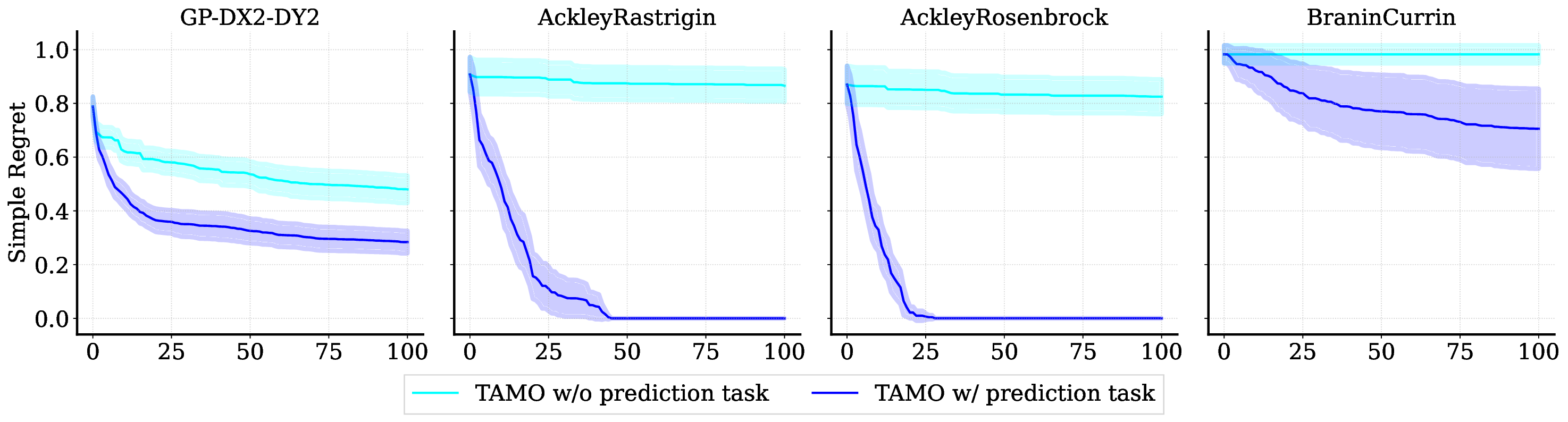
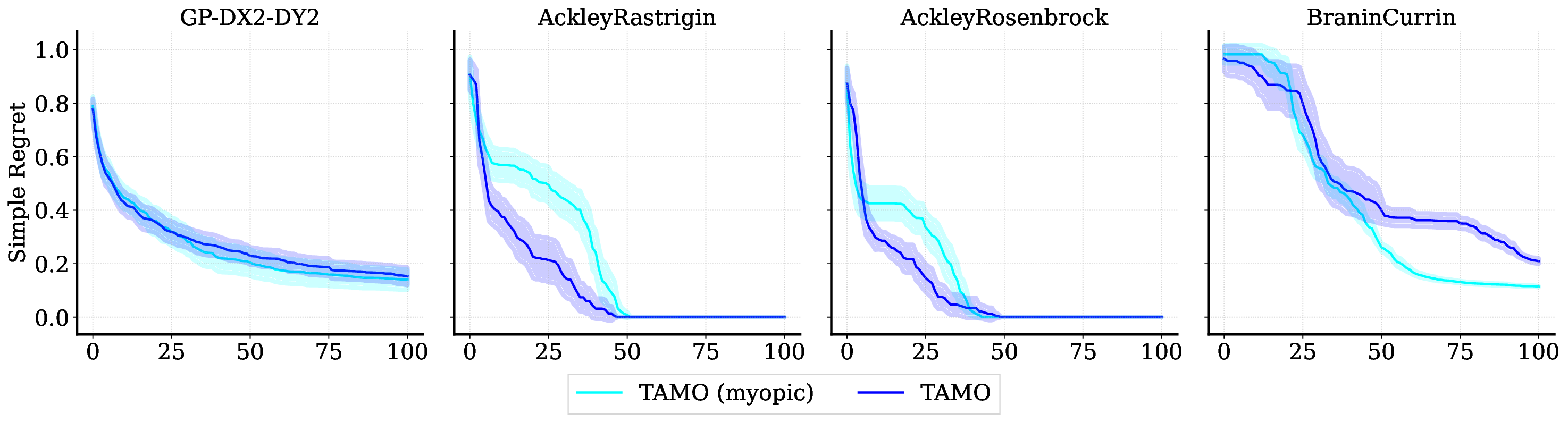
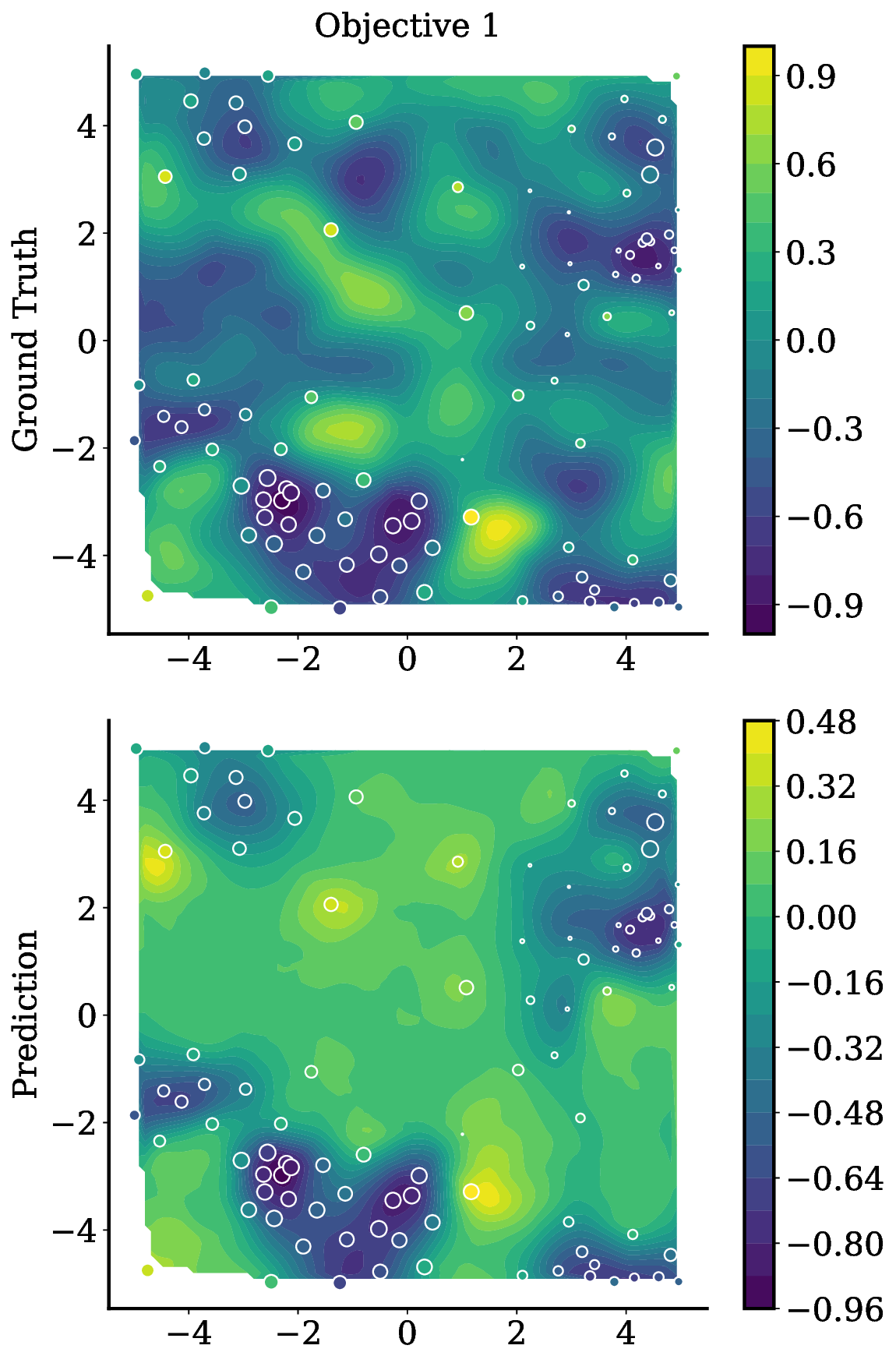
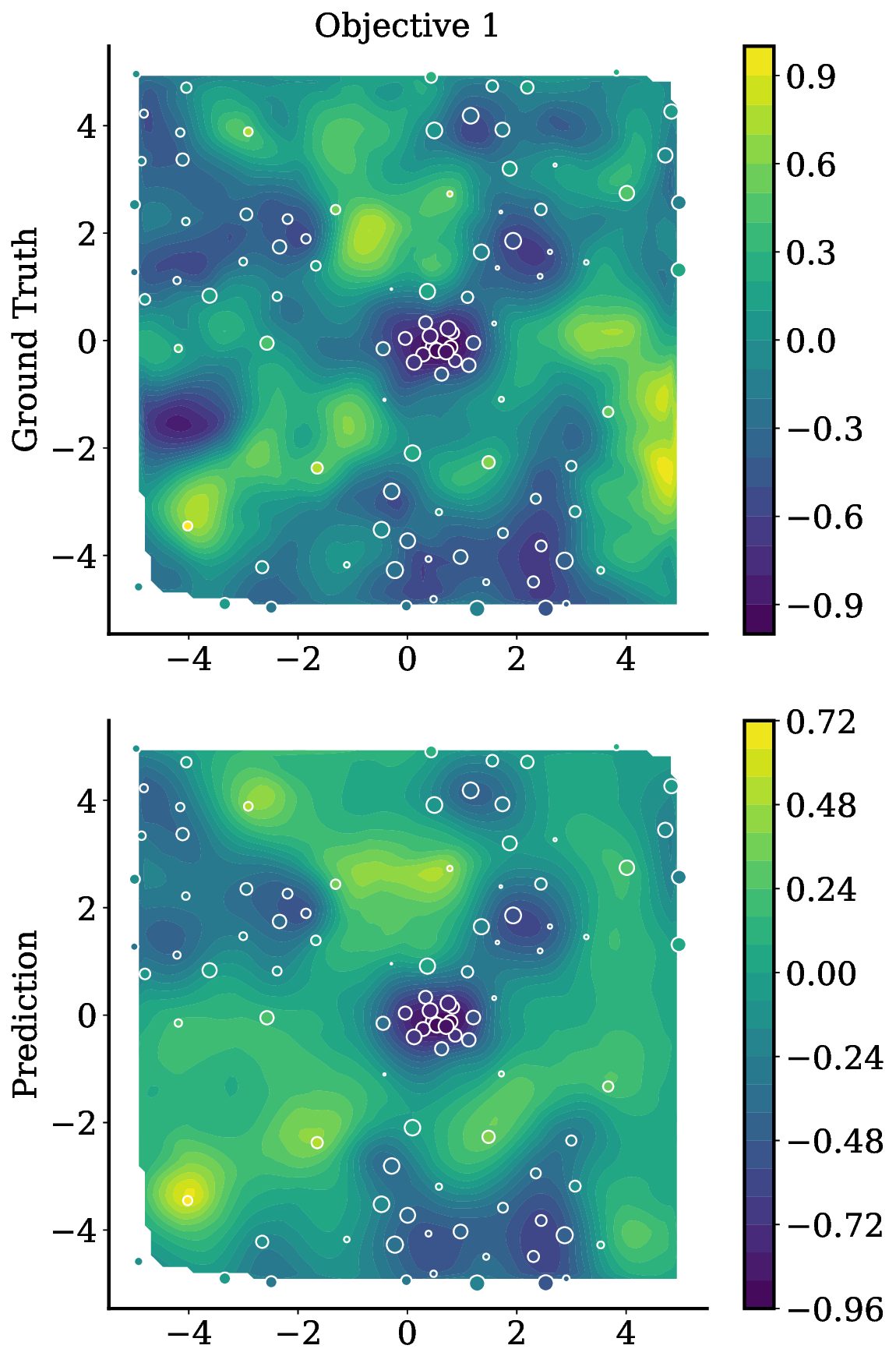
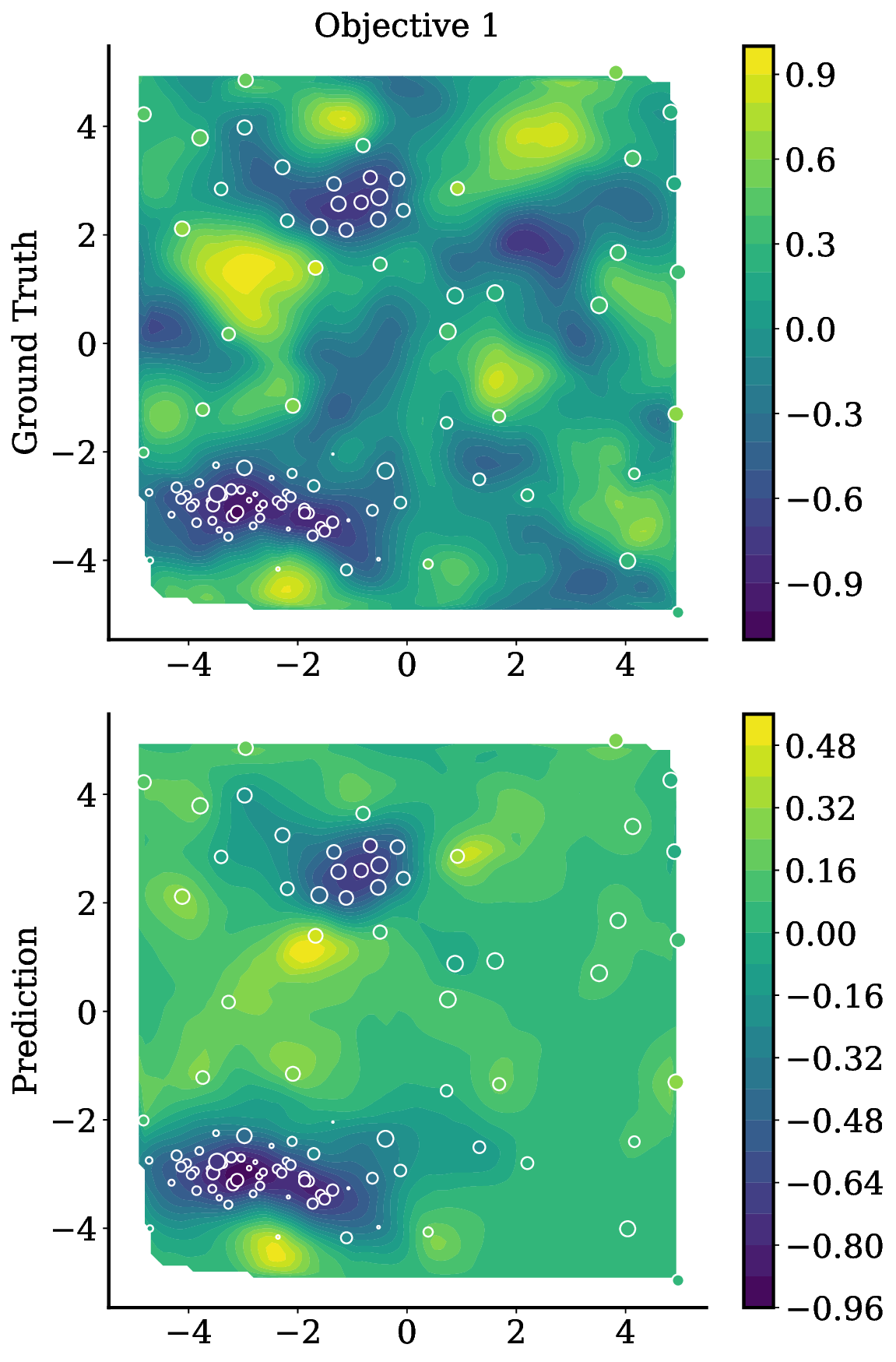
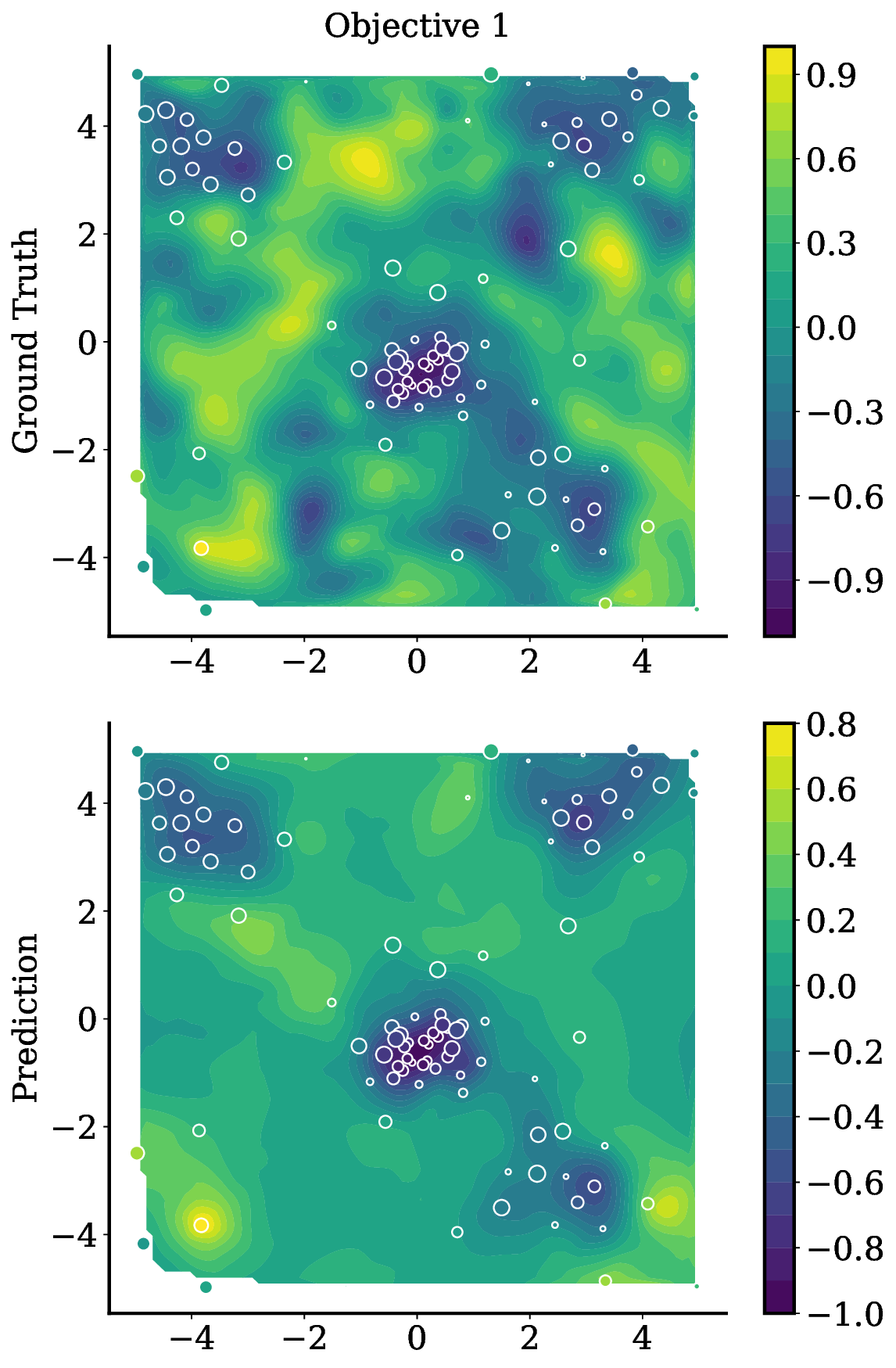
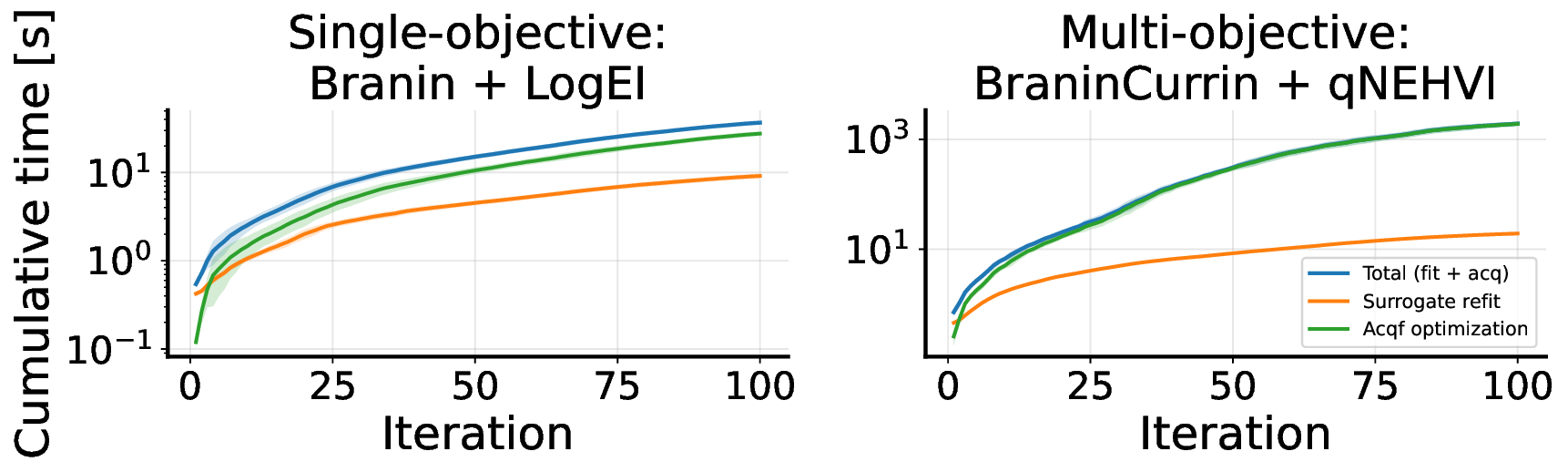
Reference
이 글은 ArXiv의 공개 자료를 바탕으로 AI가 자동 번역 및 요약한 내용입니다.
저작권은 원저자에게 있으며, 인류 지식 발전에 기여한 연구자분들께 감사드립니다.