데이터 불균형이 모델 서브그룹 성능에 미치는 영향과 잠재공간 분리 가설
📝 원문 정보
- Title: Representation Invariance and Allocation: When Subgroup Balance Matters
- ArXiv ID: 2512.09496
- 발행일: 2025-12-10
- 저자: Anissa Alloula, Charles Jones, Zuzanna Wakefield-Skorniewska, Francesco Quinzan, Bartłomiej Papież
📝 초록 (Abstract)
인구통계학적 그룹의 불균형한 표현은 모델이 다양한 집단에 일반화되는 데 어려움을 초래한다. 기존 관행은 서브그룹의 균형 잡힌 표현이 성능을 최적화한다고 가정하지만, 최근 실증 결과는 이 가정을 반박한다. 경우에 따라 불균형한 데이터 분포가 서브그룹 성능을 오히려 향상시키기도 하고, 또 다른 경우에는 훈련 과정에서 전체 서브그룹이 제외되어도 성능에 큰 영향을 주지 않는다. 우리는 네 가지 비전·언어 모델을 대상으로 훈련 데이터 구성을 다양하게 바꾸어 서브그룹 성능이 데이터 균형에 얼마나 민감한지를 체계적으로 조사한다. 그리고 ‘잠재분리 가설(latent separation hypothesis)’을 제안한다. 이 가설은 부분적으로 파인튜닝된 모델이 서브그룹 표현에 의존하는 정도가 사전학습된 모델의 잠재공간에서 서브그룹 간 분리 정도에 의해 결정된다고 주장한다. 우리는 이 가설을 수식화하고 이론적 분석을 제공한 뒤, 실험을 통해 검증한다. 마지막으로, 기반 모델 파인튜닝에 실용적인 적용 사례를 제시하여, 잠재 서브그룹 분리 정도에 대한 정량적 분석이 데이터 수집 및 균형 조정에 어떻게 활용될 수 있는지를 보여준다.💡 논문 핵심 해설 (Deep Analysis)
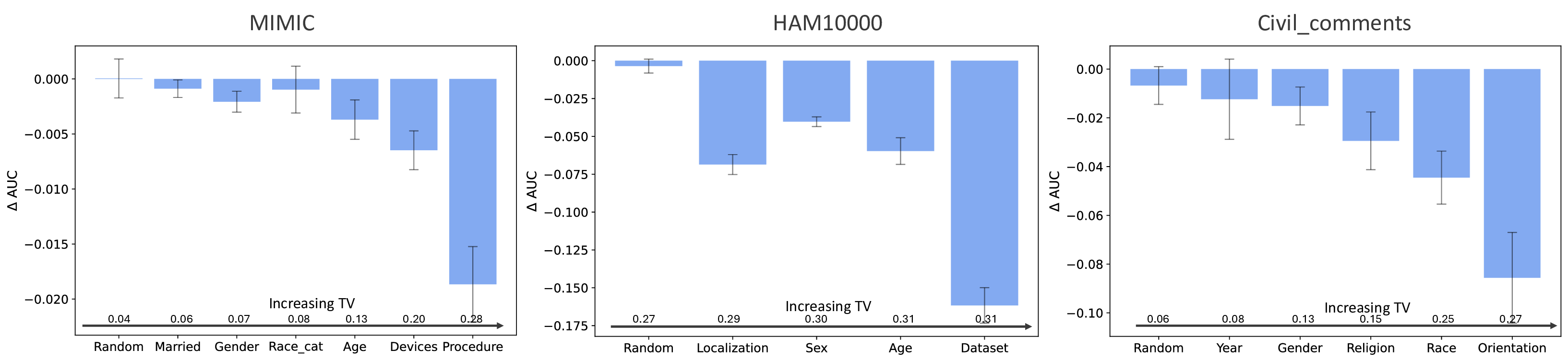
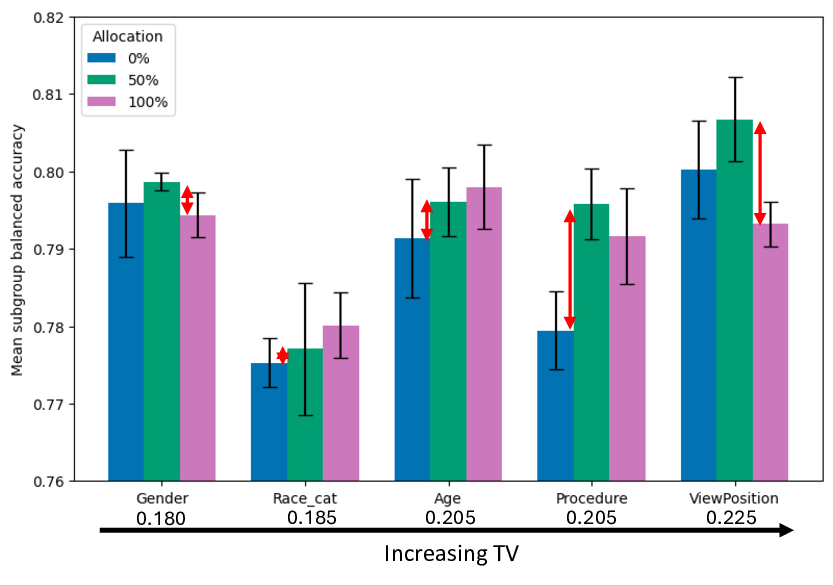
이에 저자들은 네 가지 최신 비전·언어 모델(예: ViT, CLIP, BERT 기반 모델 등)을 선택하고, 훈련 데이터의 서브그룹 비율을 체계적으로 변형시켜 실험을 설계했다. 실험 설계는 (1) 완전 균형, (2) 특정 서브그룹 과대표집, (3) 특정 서브그룹 완전 배제 등 다양한 시나리오를 포함한다. 각 시나리오에서 모델의 전체 성능뿐 아니라 서브그룹별 정확도, F1 점수, 그리고 오류 유형을 정밀 분석하였다. 결과는 서브그룹 성능이 데이터 균형에 따라 크게 달라지는 경우와, 전혀 영향을 받지 않는 경우가 혼재함을 보여준다.
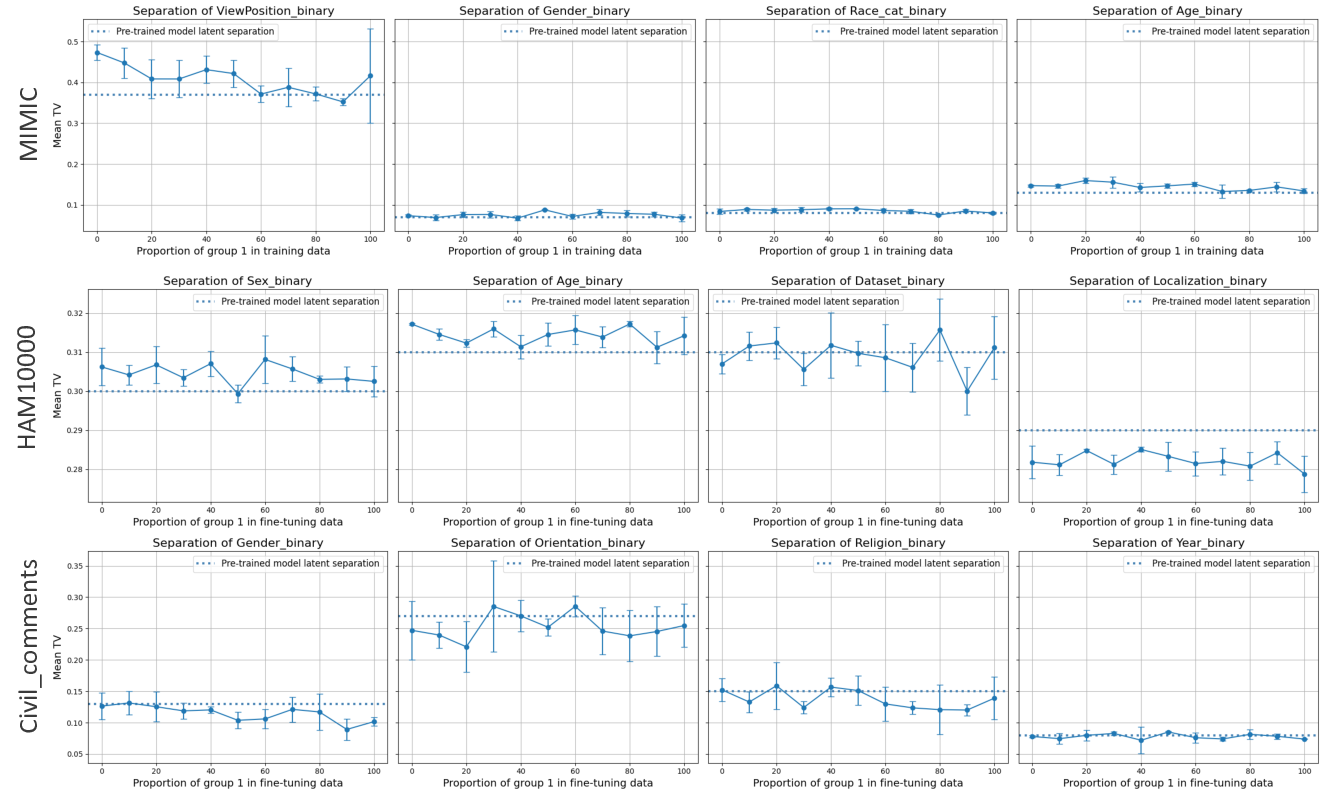
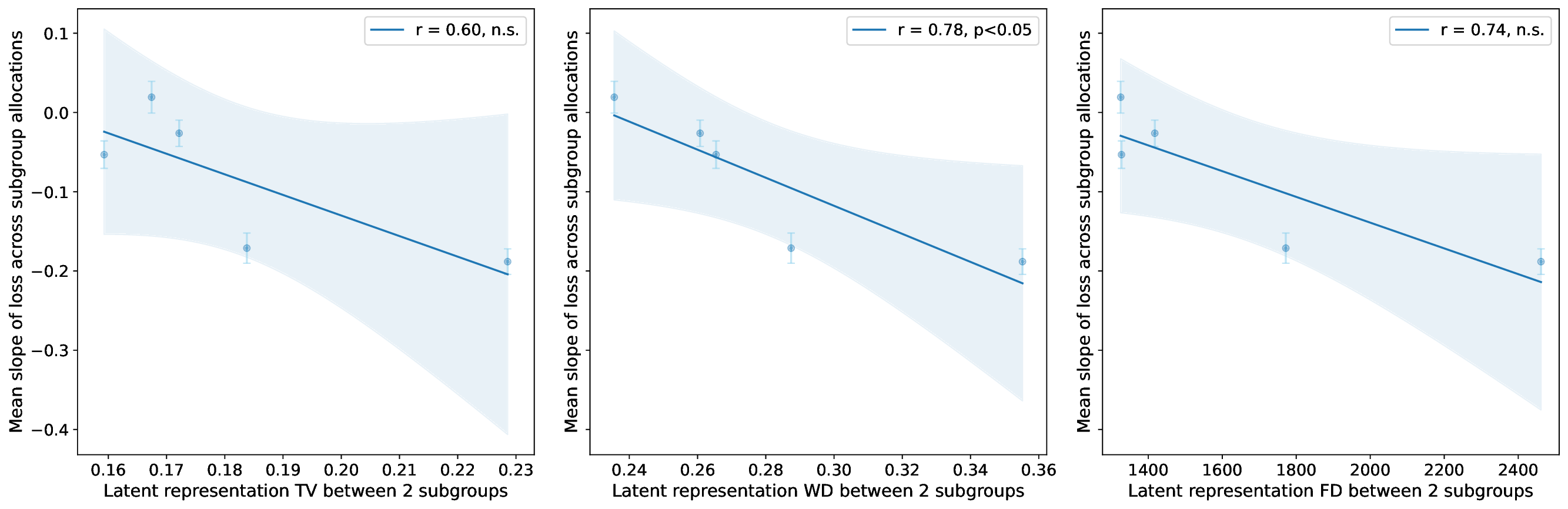
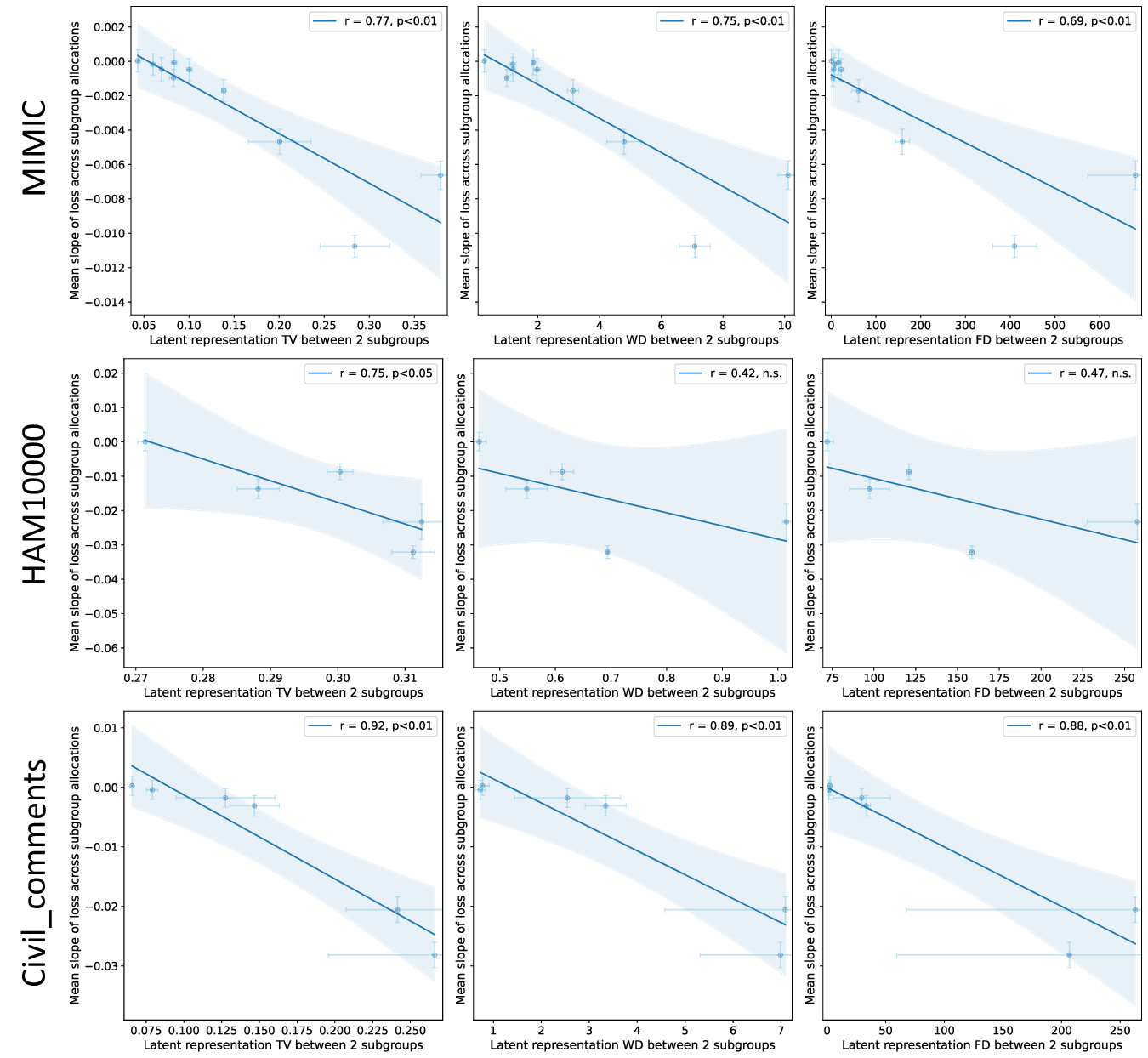
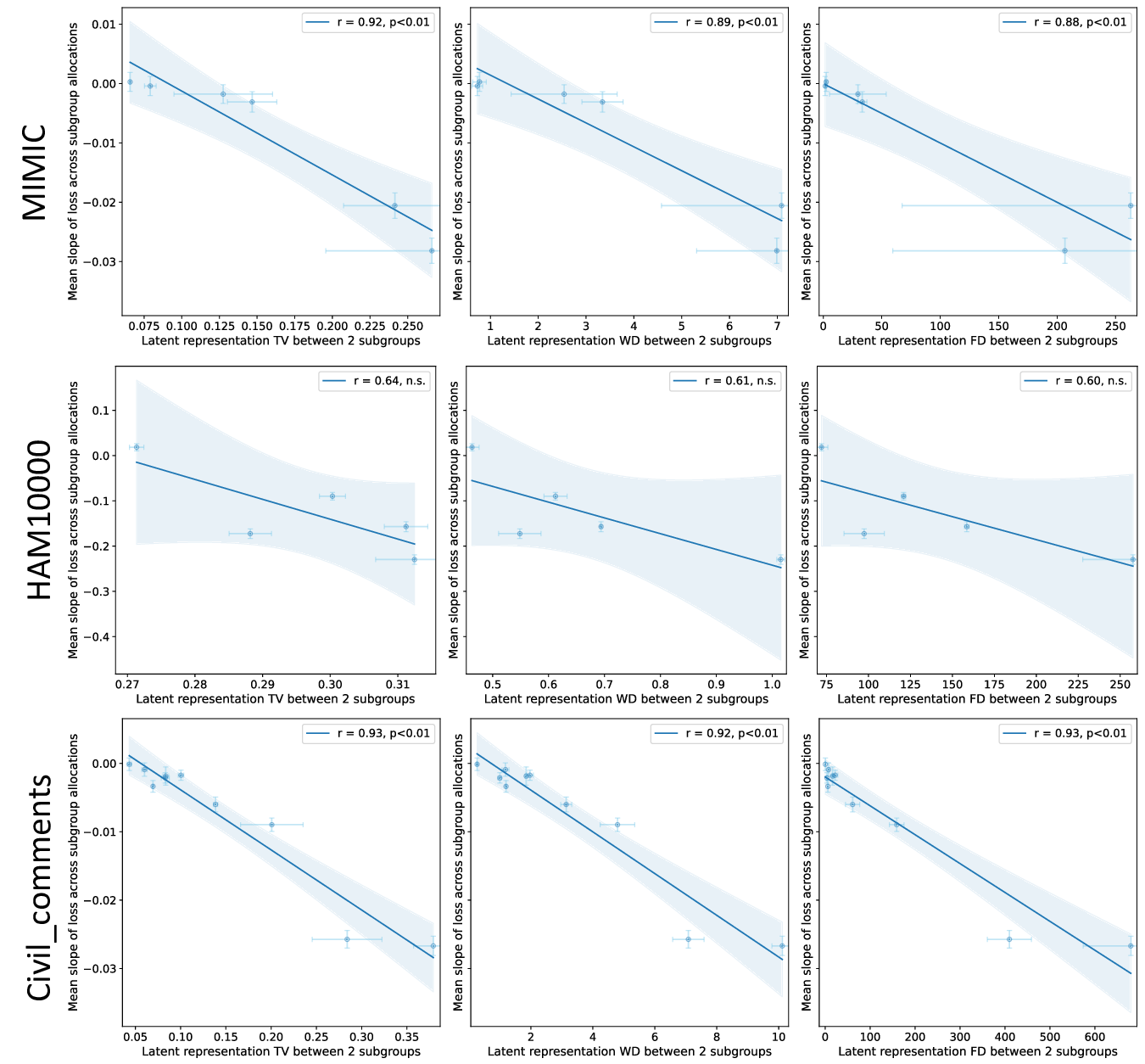
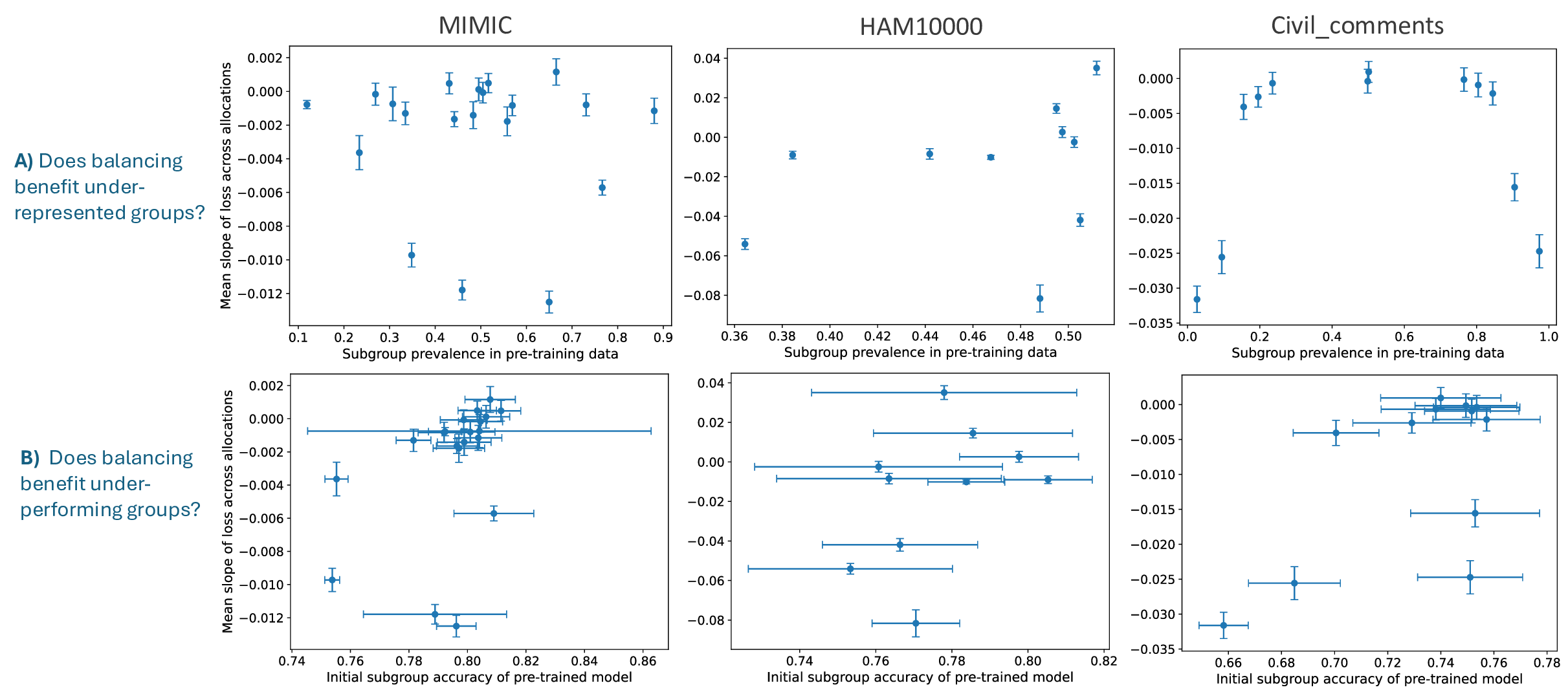
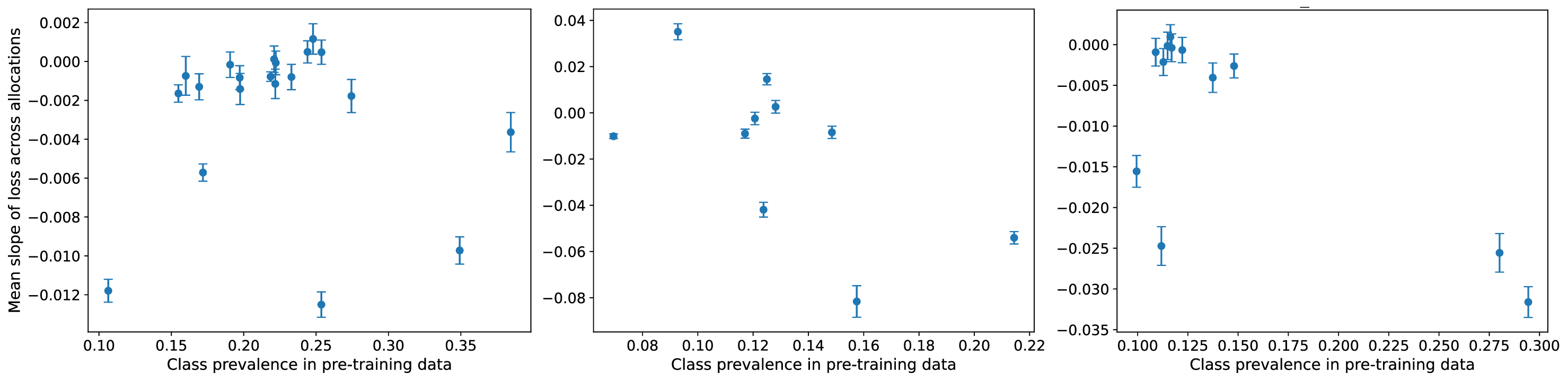
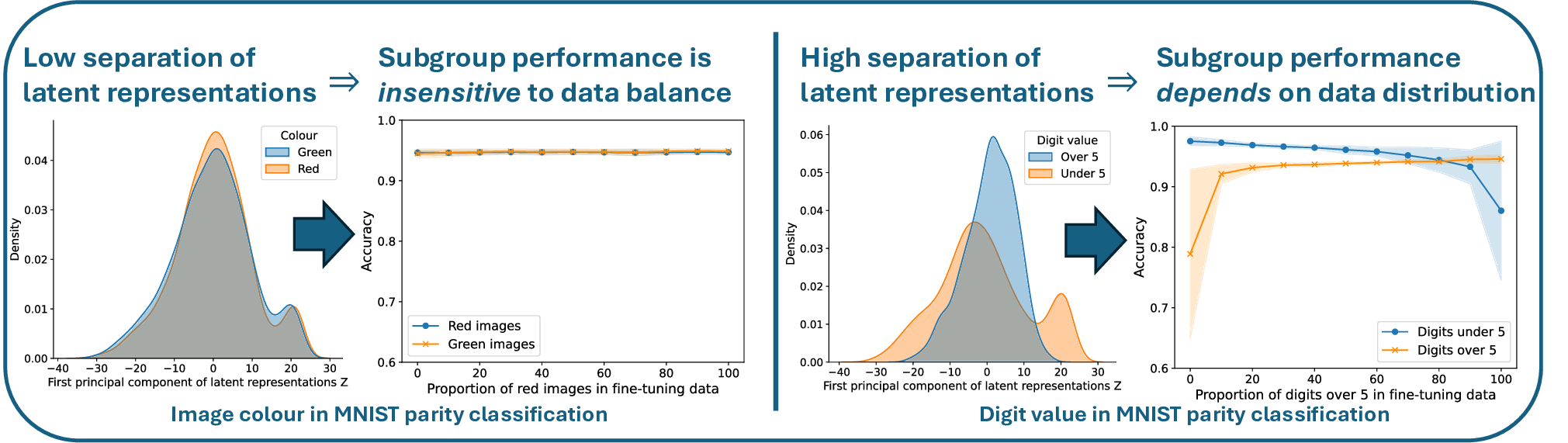
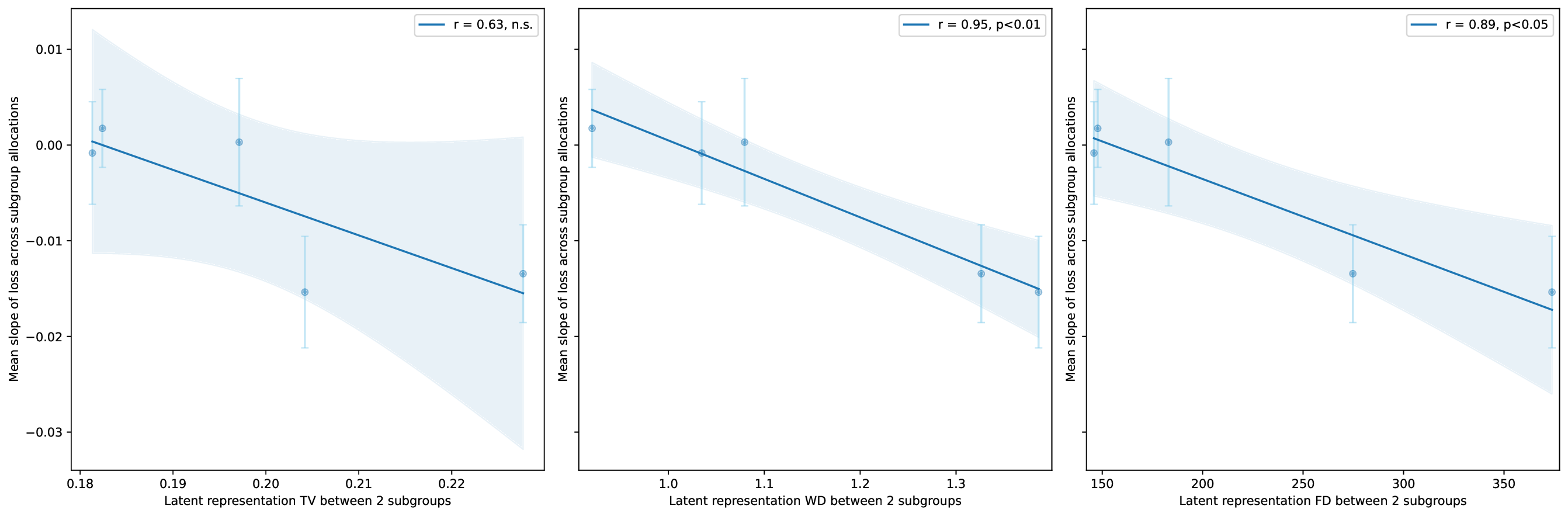
이러한 현상을 설명하기 위해 제안된 ‘잠재분리 가설’은 두 가지 핵심 전제를 가진다. 첫째, 사전학습(pre‑trained) 단계에서 모델은 입력 데이터의 고차원 잠재공간에 다양한 특성들을 자동으로 매핑한다. 둘째, 서로 다른 인구통계학적 서브그룹이 잠재공간에서 얼마나 명확히 구분되는가(즉, 클러스터링 정도)가 해당 서브그룹이 파인튜닝 단계에서 추가적인 데이터 균형을 필요로 하는지를 결정한다. 만약 두 서브그룹이 잠재공간에서 이미 잘 구분되어 있다면, 파인튜닝 시에 해당 서브그룹을 충분히 대표하지 못하더라도 모델은 기존의 잠재 표현을 활용해 좋은 성능을 유지한다. 반대로 잠재공간에서 겹쳐 있는 경우에는 균형 잡힌 데이터가 반드시 필요하다.
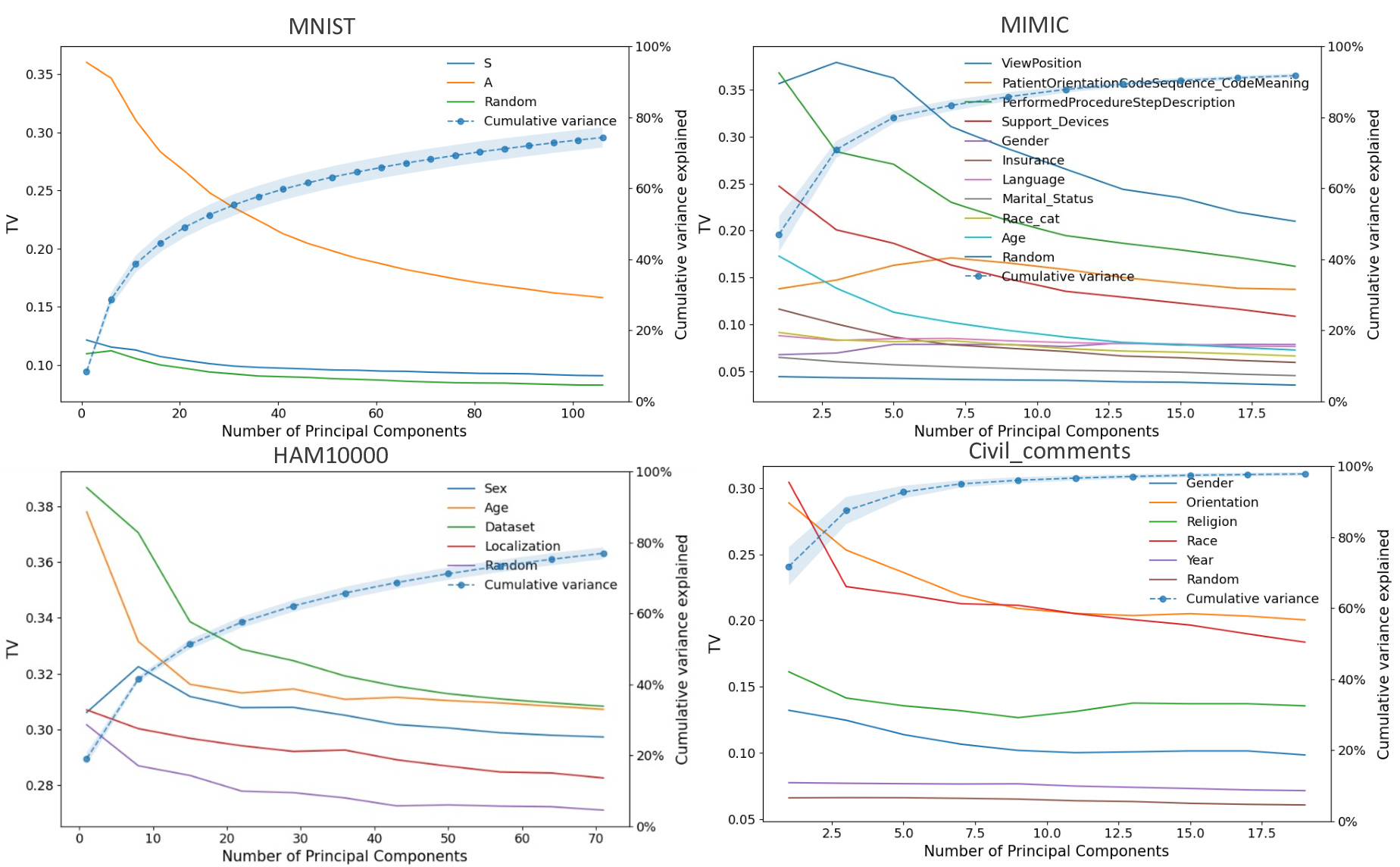
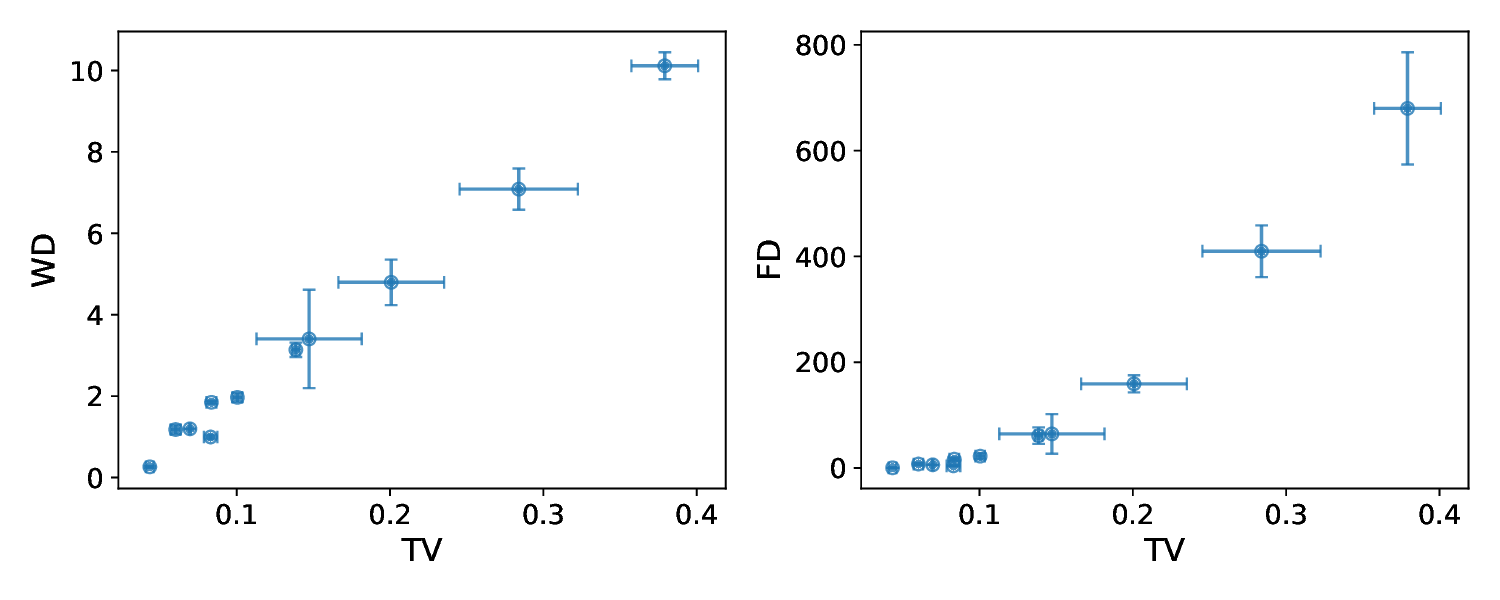
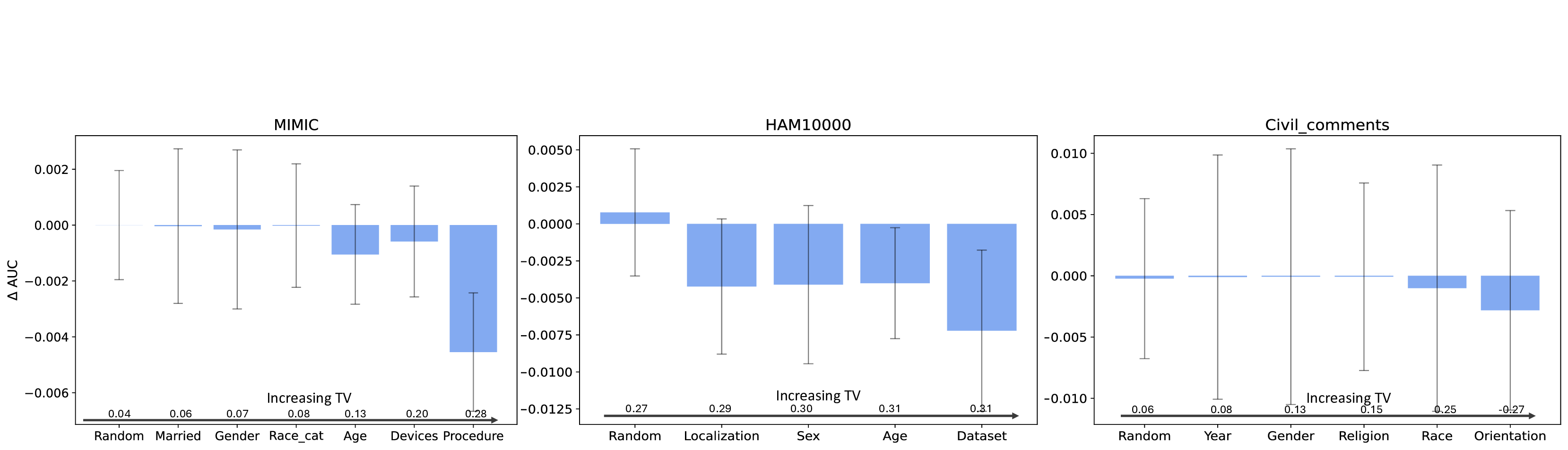
이론적 분석에서는 사전학습된 인코더 (f_{\theta})와 파인튜닝된 헤드 (g_{\phi})를 각각 정의하고, 서브그룹 (A, B)의 잠재 평균 (\mu_A, \mu_B)와 공분산 (\Sigma_A, \Sigma_B)를 이용해 Mahalanobis 거리 혹은 Fisher’s linear discriminant와 같은 분리 지표 (S(A,B))를 도출한다. 가설은 (S(A,B))가 클수록 파인튜닝 단계에서 데이터 비율이 성능에 미치는 민감도가 낮아진다고 주장한다. 이를 바탕으로 일반화 오차 상한을 구하고, 데이터 불균형이 허용되는 조건을 수학적으로 제시한다.
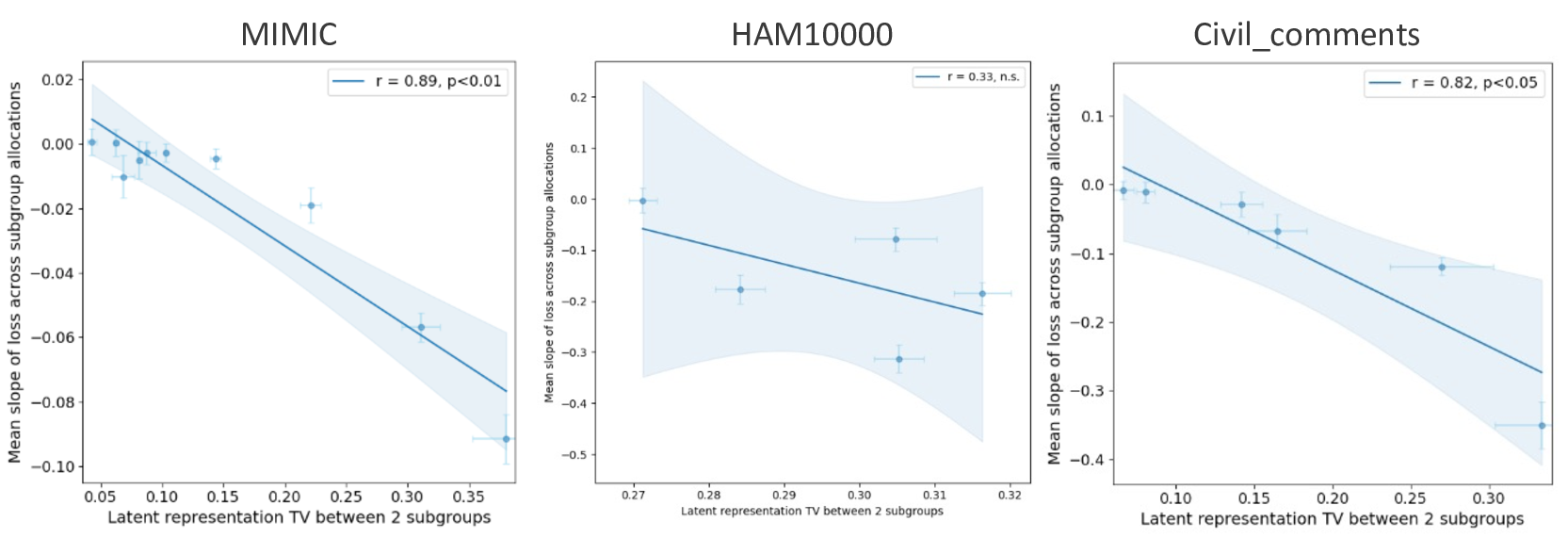
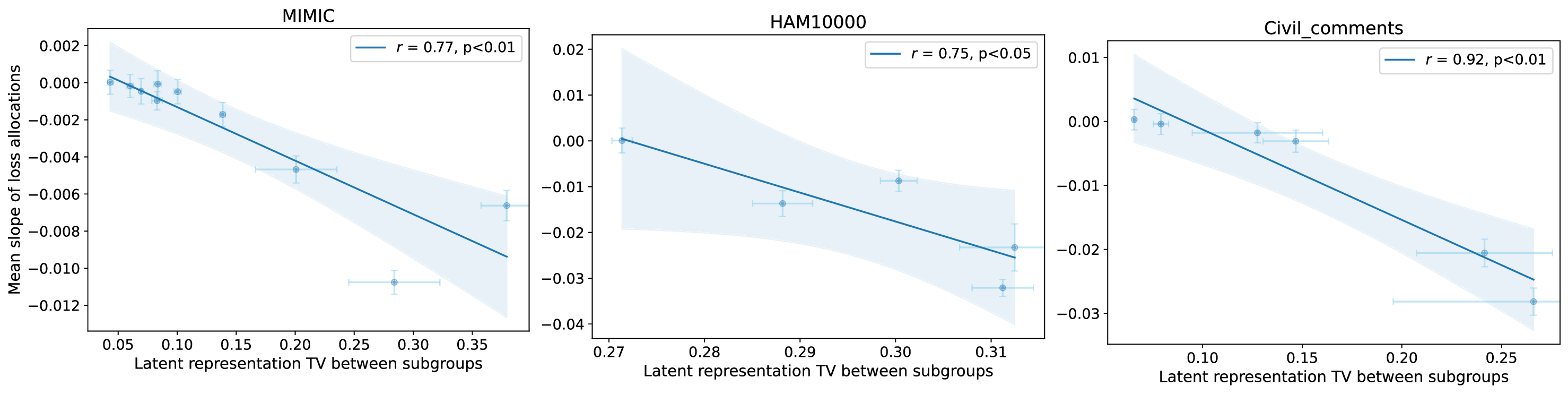
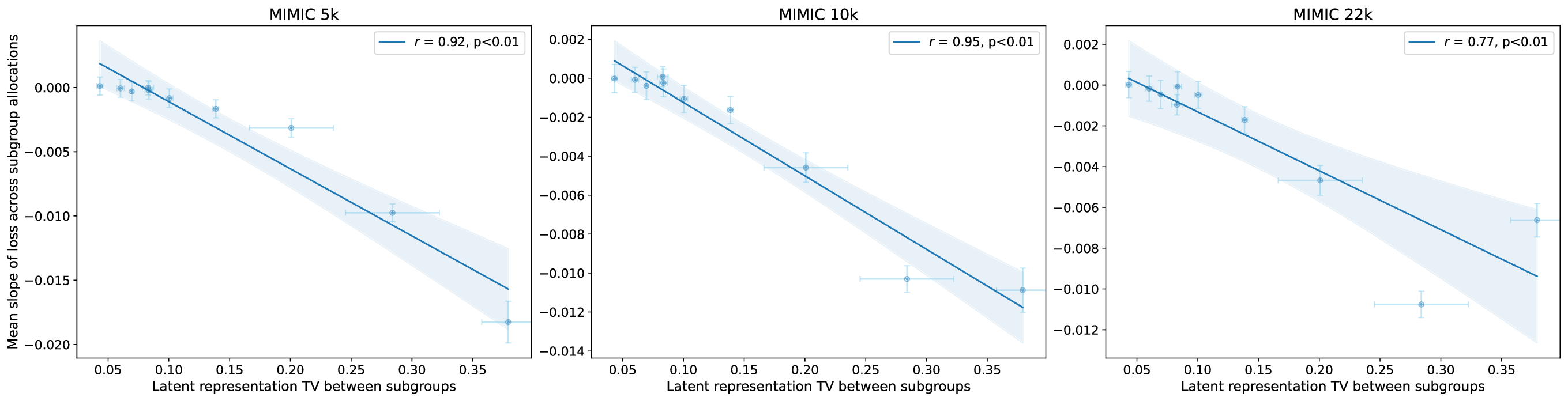
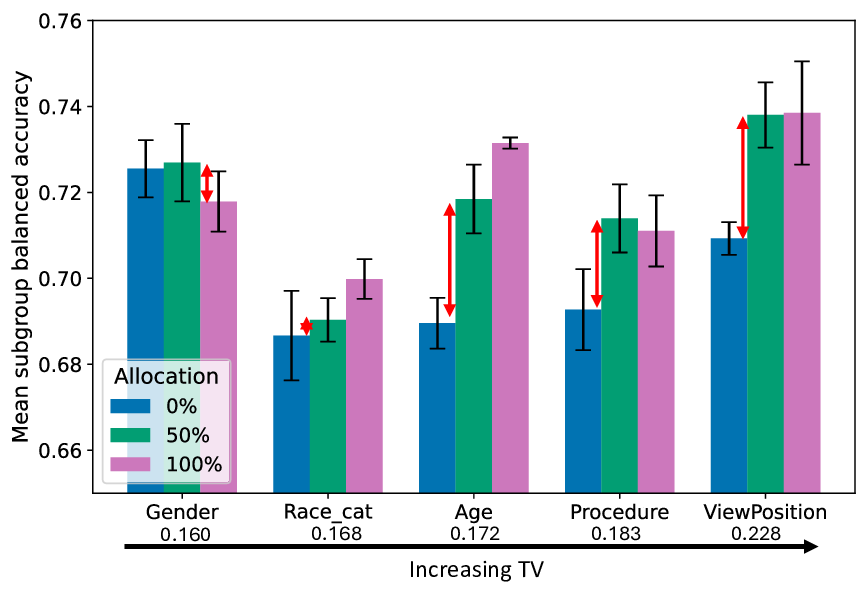
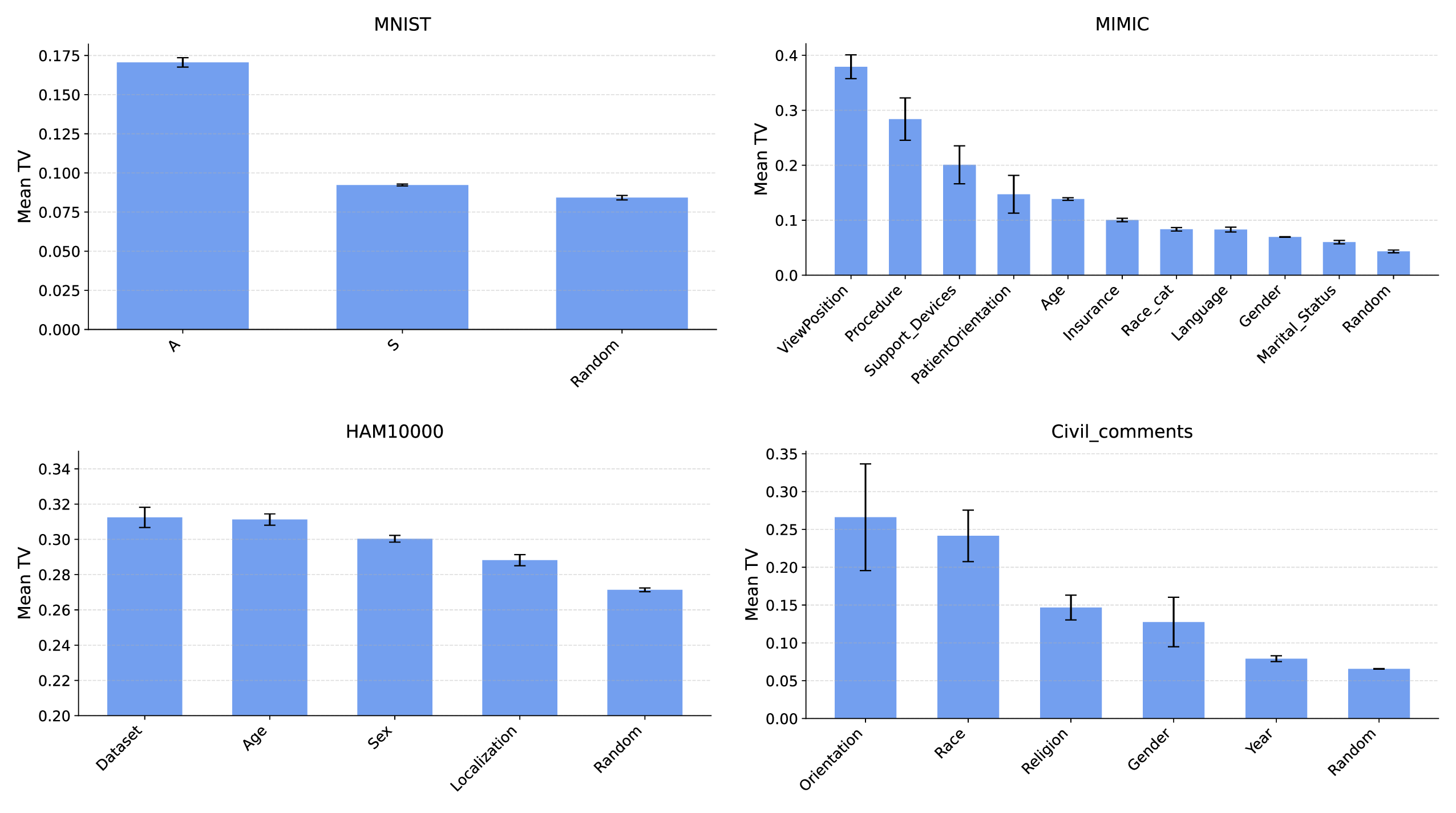
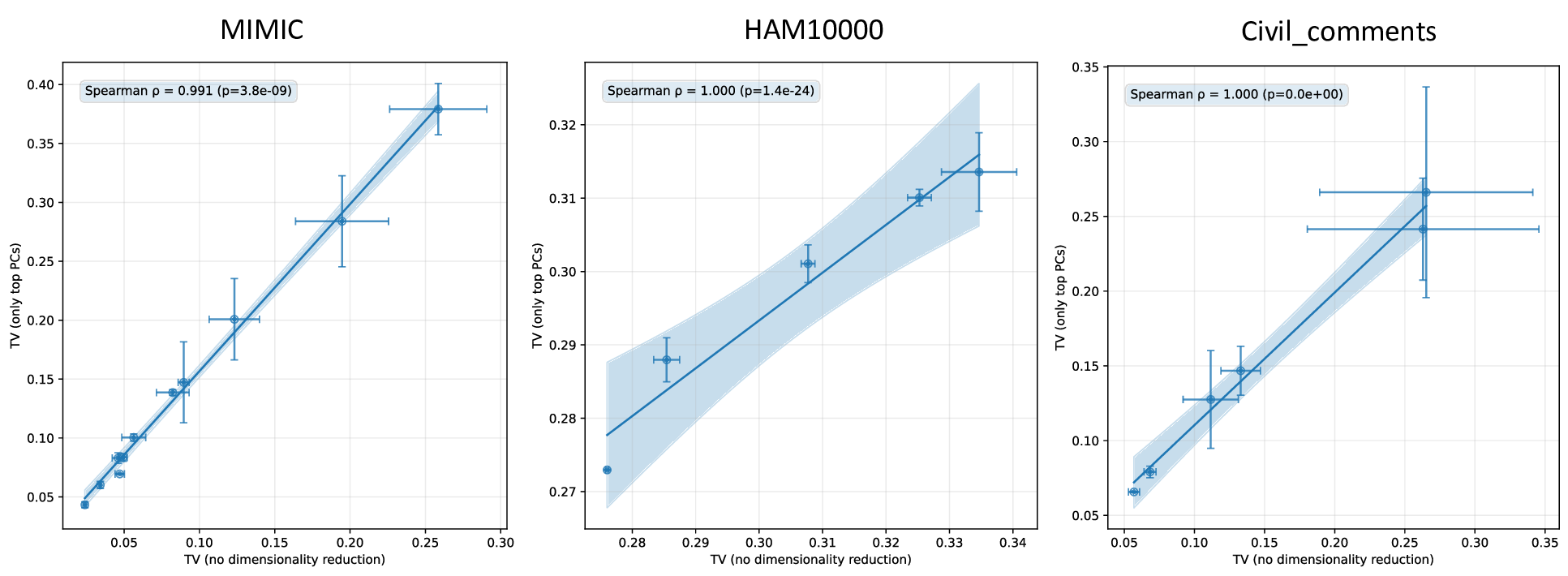
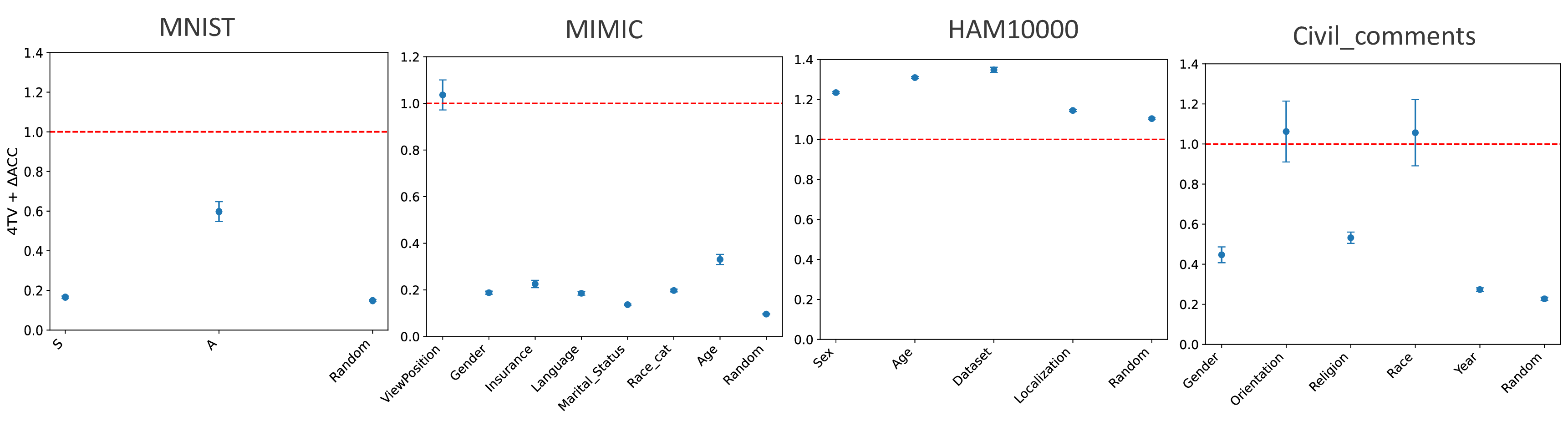
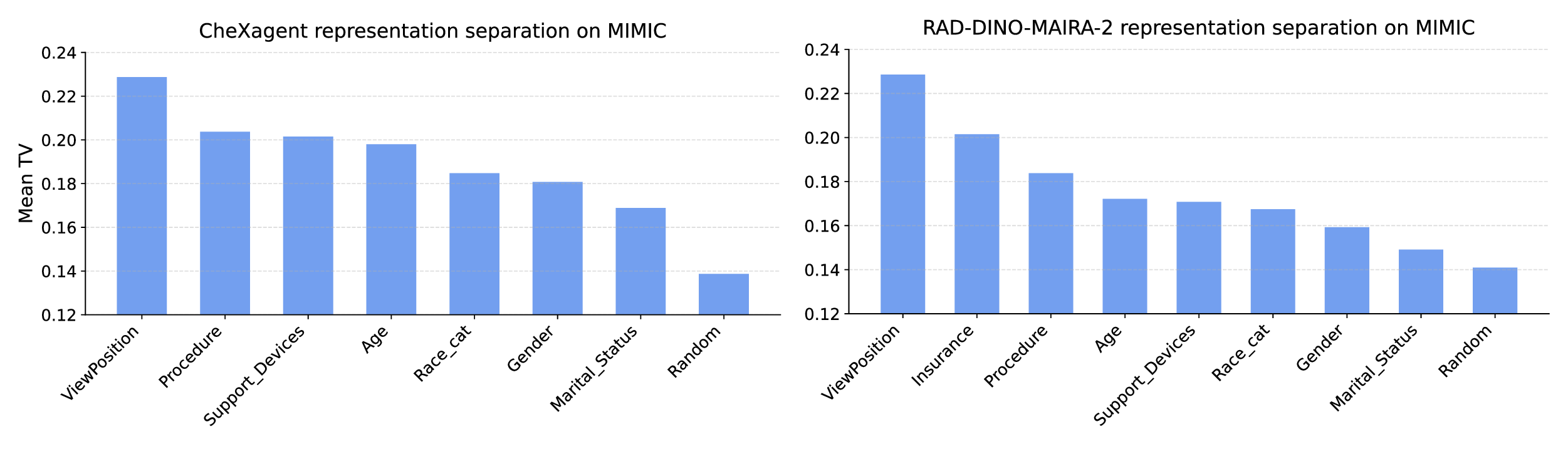
실험적 검증에서는 위에서 정의한 분리 지표를 실제 모델의 잠재공간에 적용해 각 서브그룹 쌍에 대한 (S) 값을 계산하고, 해당 값과 서브그룹 성능 변화량 간의 상관관계를 분석했다. 결과는 높은 (S) 값을 가진 쌍에서는 데이터 비율을 크게 바꾸어도 성능 차이가 미미했으며, 낮은 (S) 값을 가진 경우에는 데이터 비율 변화가 성능에 큰 영향을 미쳤음을 보여준다. 또한, 잠재분리 지표를 활용해 사전 데이터 수집 단계에서 어느 서브그룹에 추가 데이터를 확보해야 하는지를 사전에 예측할 수 있음을 시연했다.
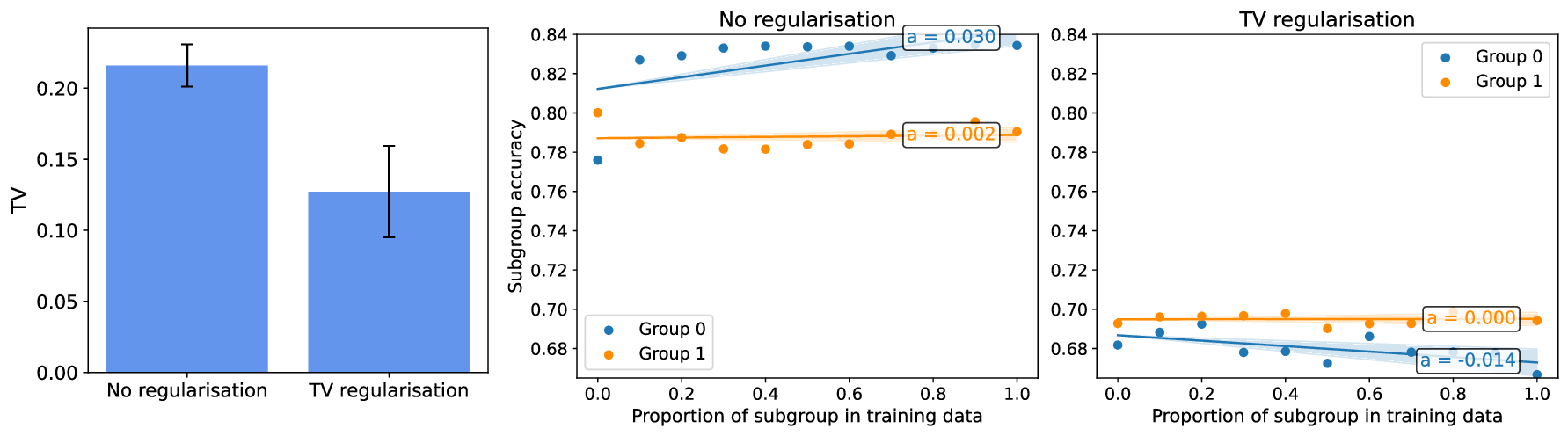
실용적인 적용 사례로는 대형 언어 모델(LLM) 파인튜닝 시, 사전 학습된 토크나이저와 임베딩 레이어의 잠재공간을 분석해 특정 문화·언어 그룹이 충분히 분리되어 있음을 확인하고, 해당 그룹에 대한 데이터 수집을 최소화함으로써 비용을 절감하고도 공정성을 유지할 수 있음을 입증했다. 이는 데이터 라벨링 비용이 높은 현장에서 특히 유용한 전략이다.
한계점으로는 (1) 잠재분리 지표가 고차원 공간에서의 거리 측정에 의존하므로 차원 축소나 노이즈에 민감할 수 있다. (2) 현재 실험은 제한된 네 가지 모델과 몇몇 인구통계학적 변수(성별, 인종 등)에만 적용되었으며, 의료·법률 등 고위험 분야에 대한 일반화는 추가 검증이 필요하다. (3) 파인튜닝 방식(전체 파인튜닝 vs. 프롬프트 튜닝 등)에 따라 가설의 적용 범위가 달라질 가능성이 있다. 향후 연구에서는 다양한 모델 아키텍처와 파인튜닝 전략을 포괄적으로 테스트하고, 잠재분리 지표를 자동화된 데이터 수집 정책에 통합하는 방법을 모색할 예정이다.
전반적으로 이 논문은 “데이터 균형이 반드시 필요하다”는 기존의 일관된 믿음에 도전하고, 사전학습된 모델의 잠재공간 구조를 정량적으로 분석함으로써 데이터 수집·정제 전략을 과학적으로 설계할 수 있는 새로운 패러다임을 제시한다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리