제로터치 네트워크 보안을 위한 자동화 프레임워크 SecLoop과 보안 인식 정책 최적화 SA GRPO
📝 원문 정보
- Title: Advancing LLM-Based Security Automation with Customized Group Relative Policy Optimization for Zero-Touch Networks
- ArXiv ID: 2512.09485
- 발행일: 2025-12-10
- 저자: Xinye Cao, Yihan Lin, Guoshun Nan, Qinchuan Zhou, Yuhang Luo, Yurui Gao, Zeliang Zhang, Haolang Lu, Qimei Cui, Yanzhao Hou, Xiaofeng Tao, Tony Q. S. Quek
📝 초록 (Abstract)
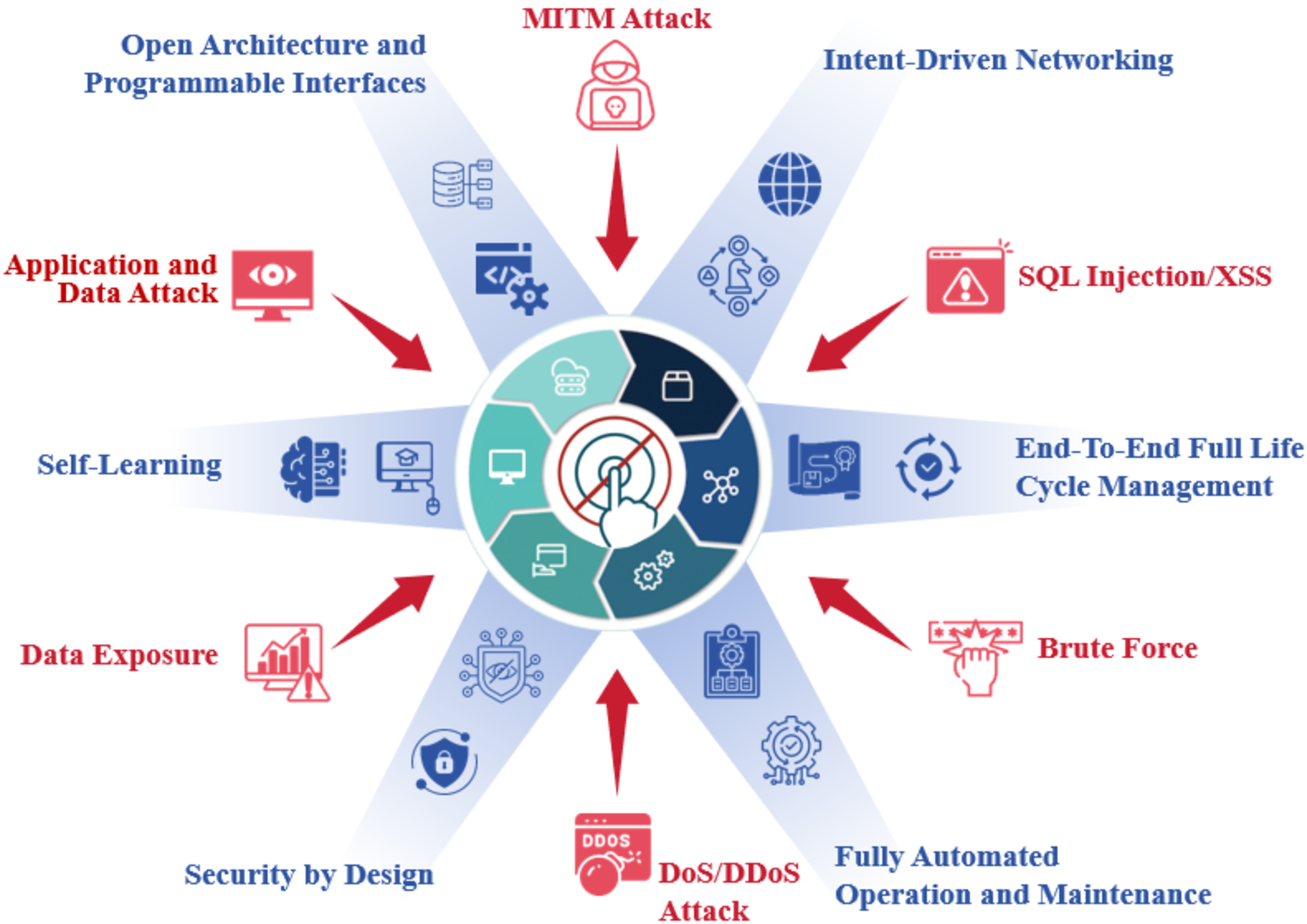
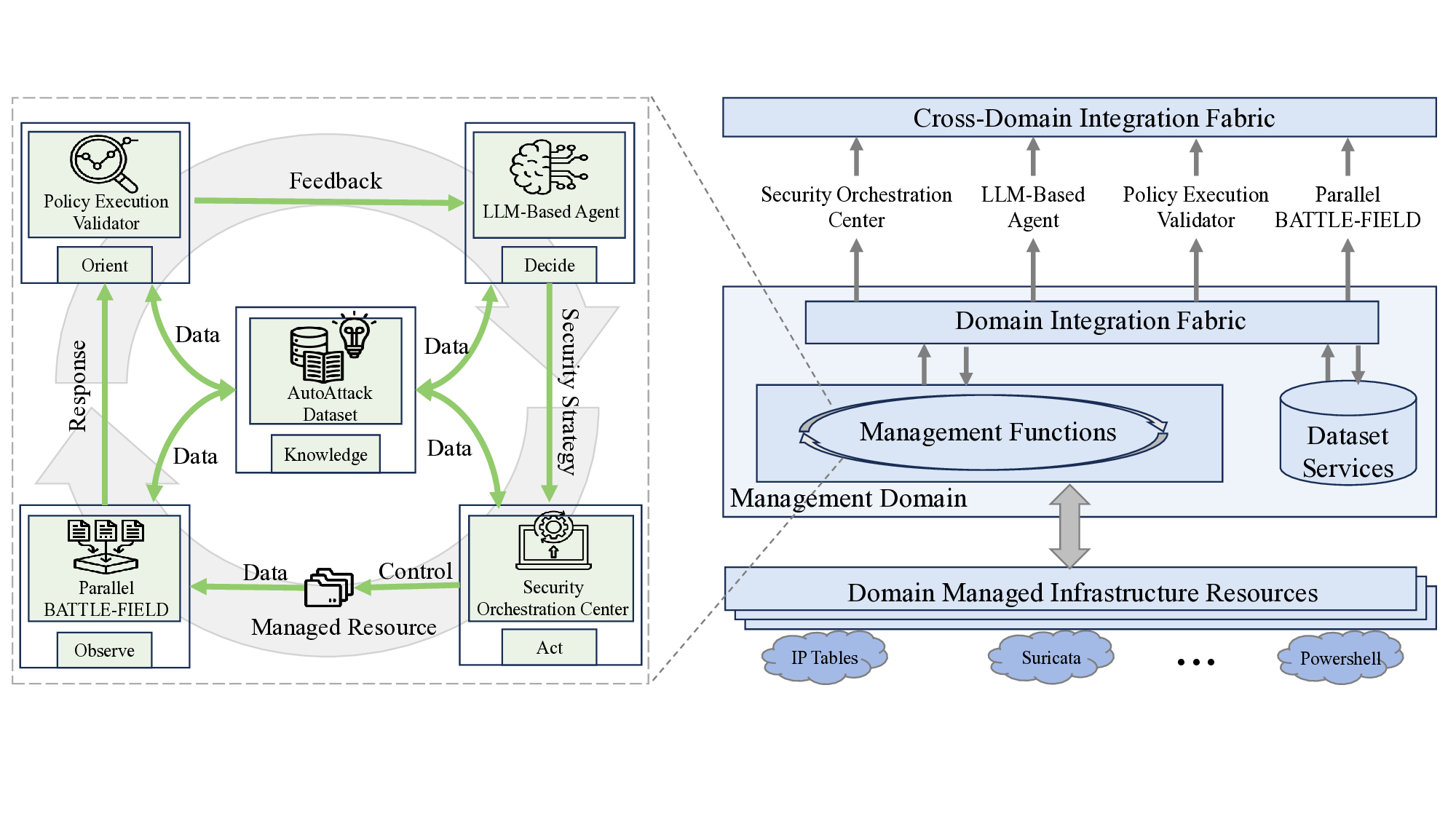
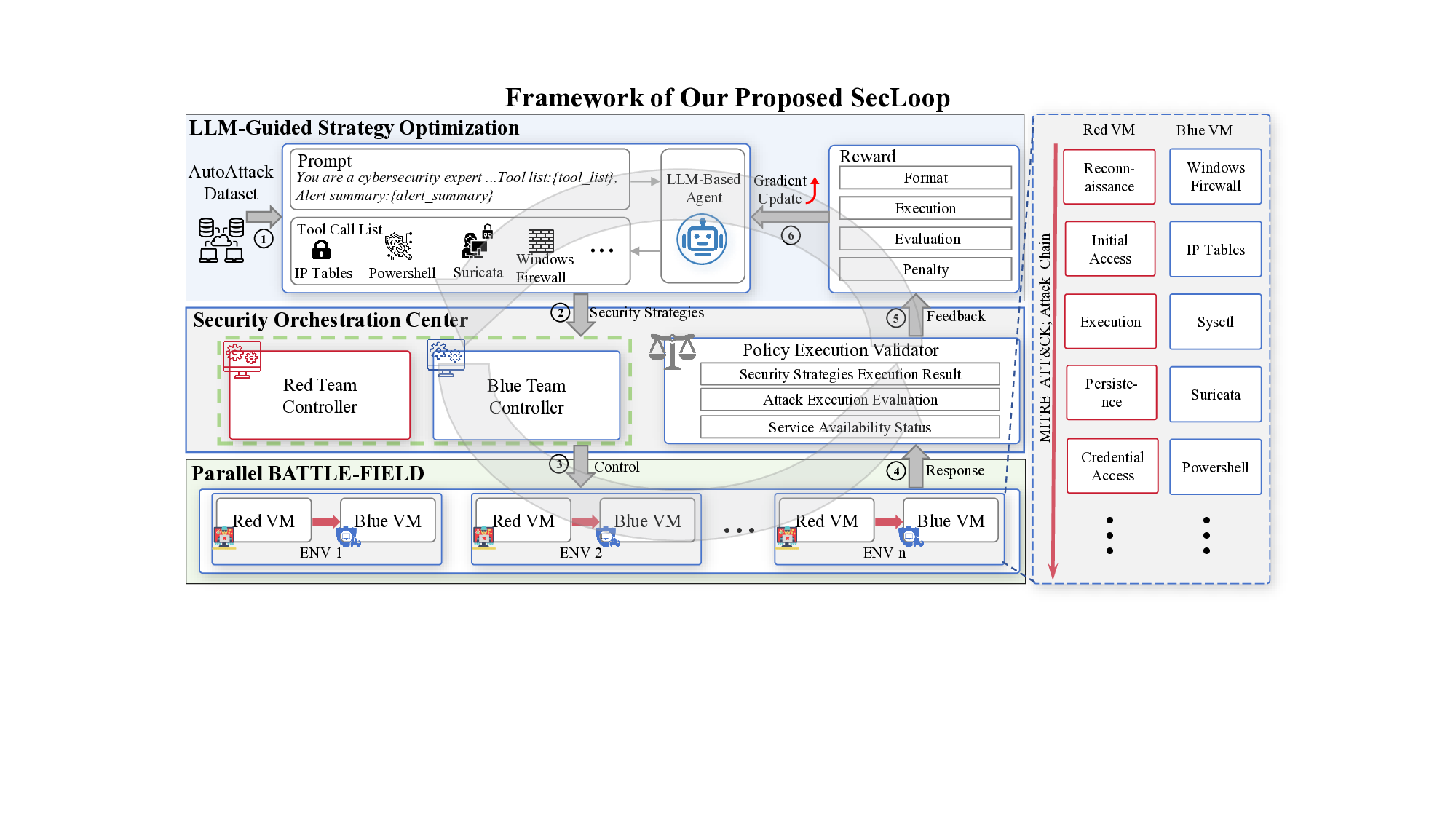
제로터치 네트워크(ZTN)는 6G 네트워크 관리의 완전 자동화와 지능화를 목표로 하는 혁신적 패러다임이다. 그러나 6G의 분산 구조, 높은 개방성 및 이질성은 공격 표면을 확대해 새로운 보안 위협을 초래한다. 이를 해결하기 위해 보안 자동화는 동적·복합 환경에서 지능형 보안 관리 역량을 제공하는 핵심 기술로 부상하고 있다. 본 논문은 6G ZTN에서 보안 자동화를 구현할 때 직면하는 두 가지 주요 과제, 즉 (1) 실시간·병렬·적대적 상황에서 보안 전략 생성‑검증‑업데이트 전 과정을 자동화하는 것, (2) 변화하는 위협과 동적 환경에 맞춰 보안 전략을 지속적으로 적응시키는 것을 해결하고자 한다. 이를 위해 전체 보안 수명주기에 대형 언어 모델(LLM)을 연계한 최초의 완전 자동화 프레임워크인 SecLoop을 제안한다. SecLoop은 전략 생성, 오케스트레이션, 대응, 피드백을 순환적으로 수행해 동적 네트워크 환경에서 지능형 방어를 가능하게 한다. 또한, 병렬 실행된 SecLoop으로부터 수집된 그룹 피드백을 대비 학습하는 보안 인식 그룹 상대 정책 최적화(SA‑GRPO) 알고리즘을 도입해 전략을 지속적으로 정제한다. 11개의 MITRE ATT&CK 프로세스와 20여 종류의 공격을 포함한 5개 벤치마크에서 수행한 실험 결과, 제안된 SecLoop과 SA‑GRPO가 기존 방법보다 현저히 우수함을 입증하였다. 향후 연구와 산업 적용을 위해 본 플랫폼을 공개할 예정이다.💡 논문 핵심 해설 (Deep Analysis)

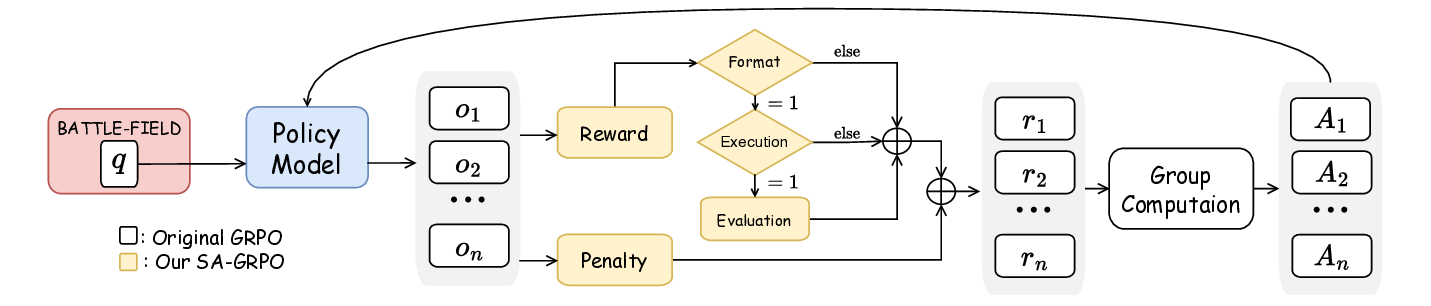
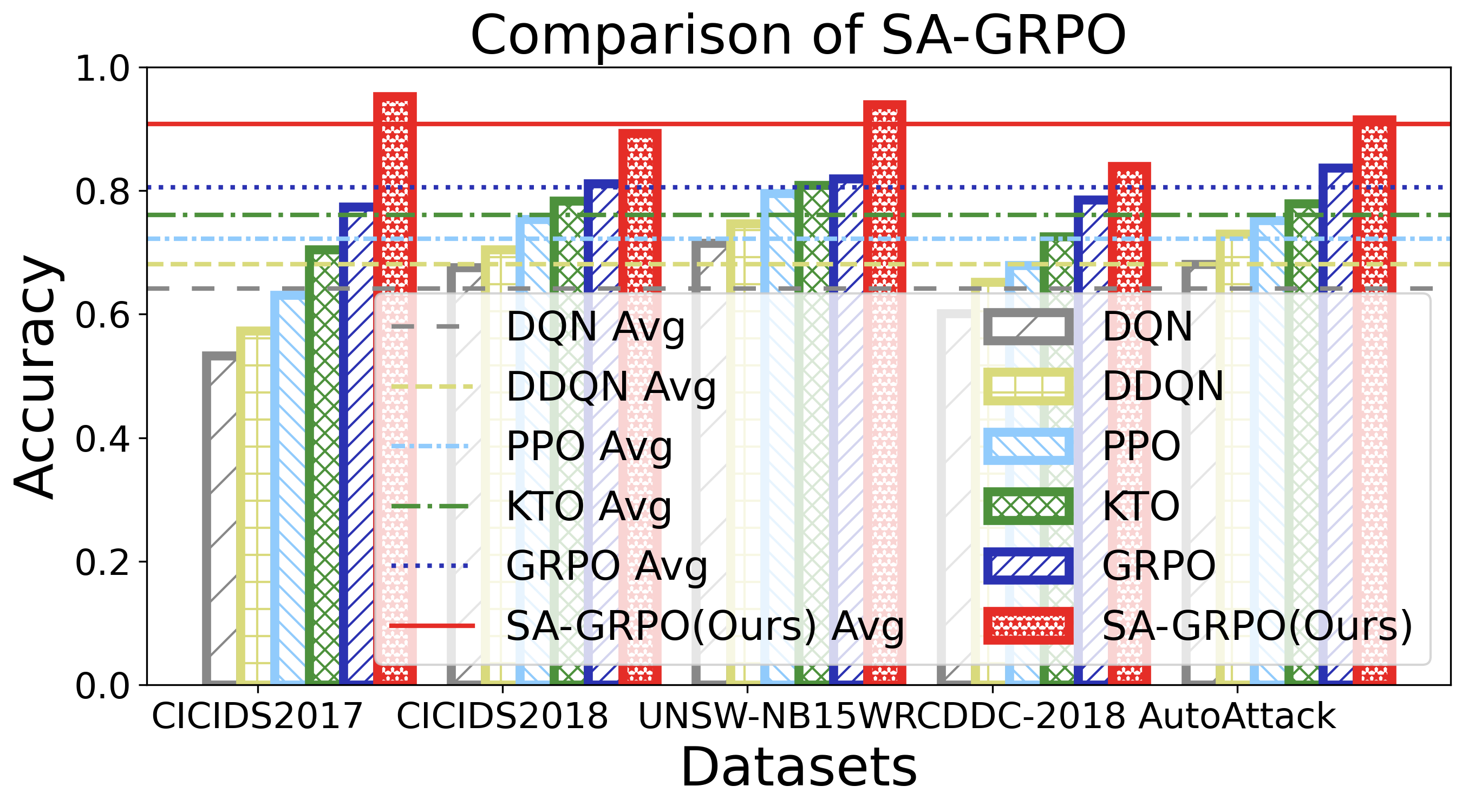
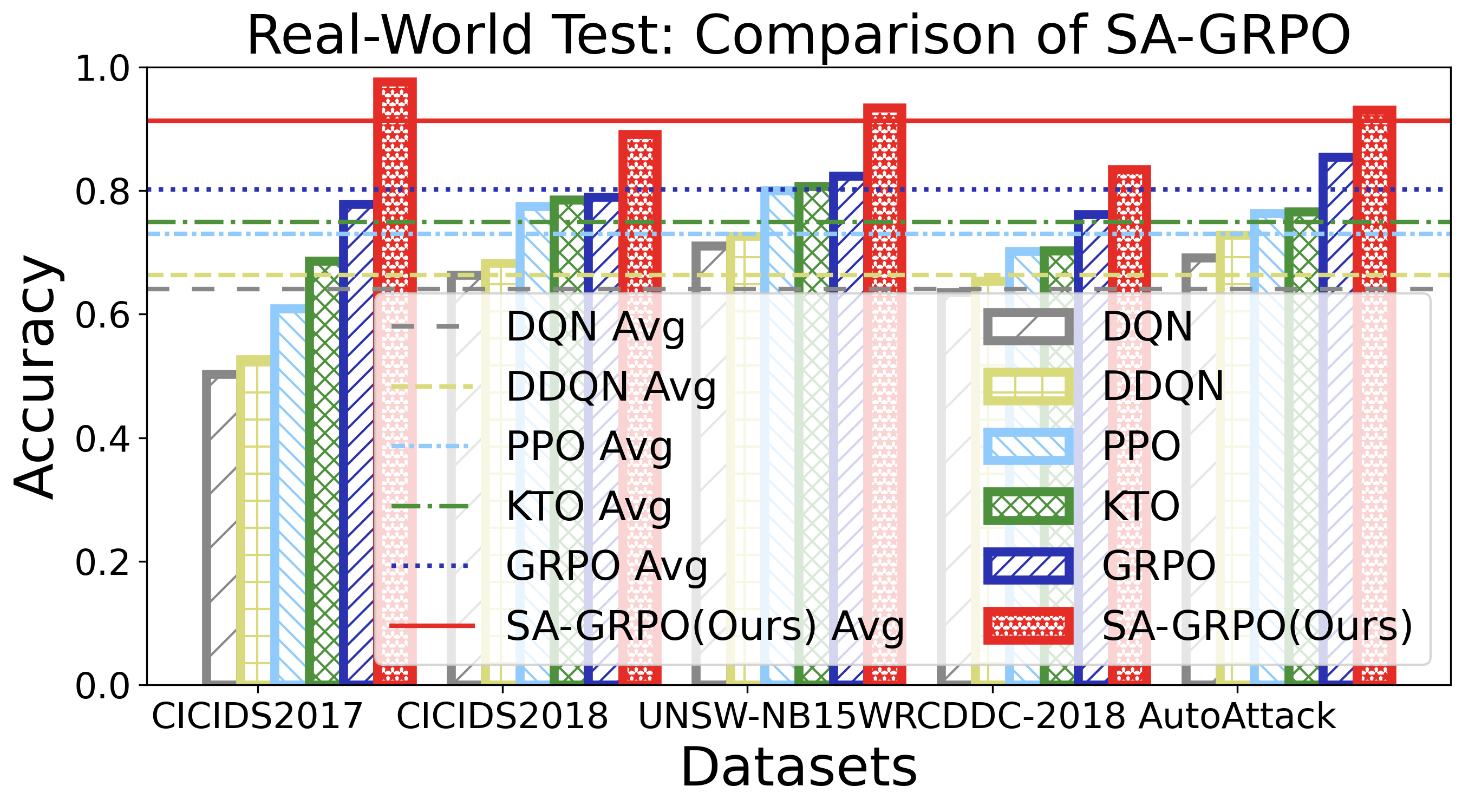
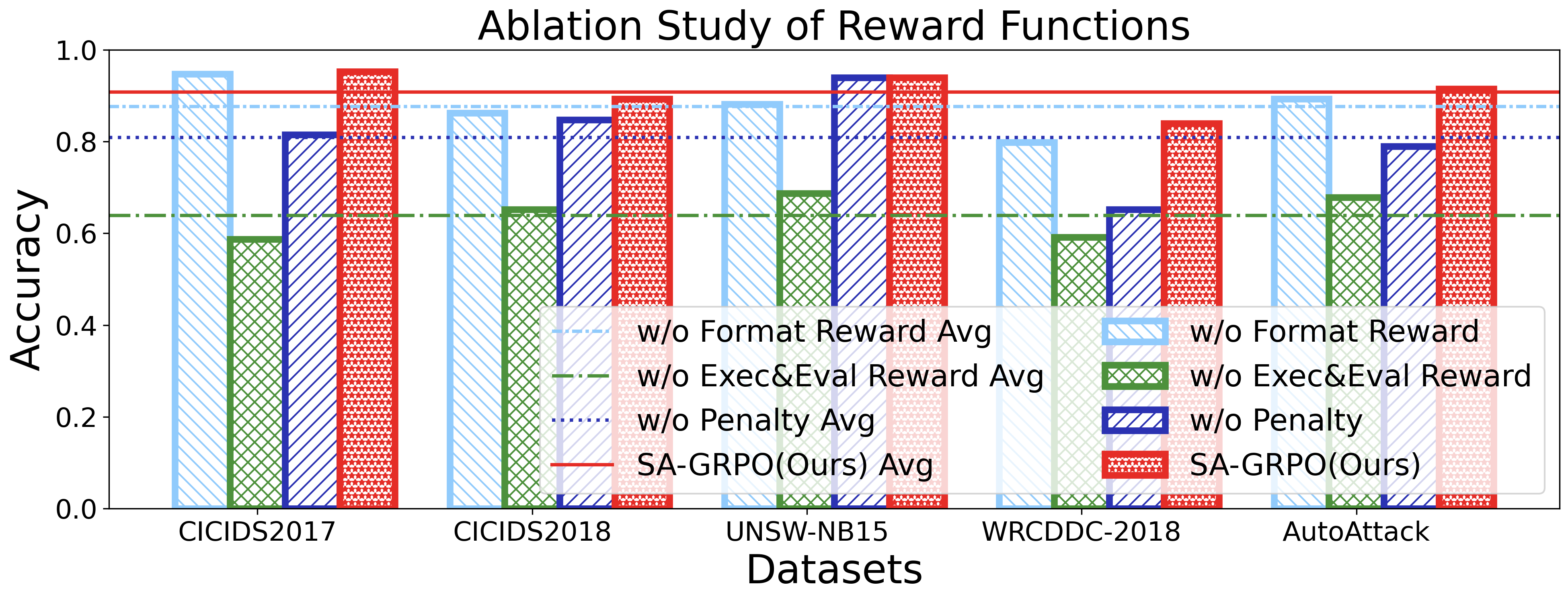
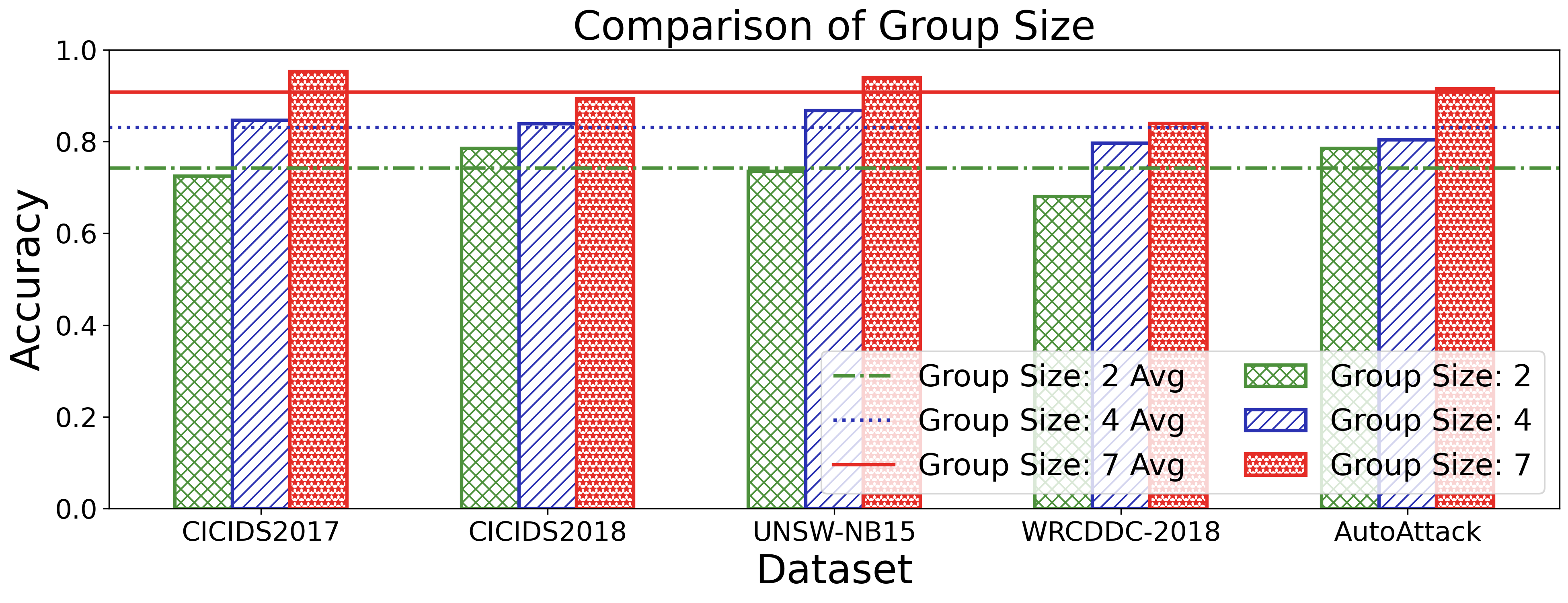
두 번째 과제는 “동적·적대적 환경에 대한 지속적 적응”이다. 6G 네트워크는 서비스와 인프라가 실시간으로 변동하고, 공격자는 지속적으로 새로운 전술을 도입한다. 저자들은 병렬로 실행되는 다수의 SecLoop 인스턴스로부터 얻은 피드백을 그룹 단위로 비교·대조하는 SA‑GRPO 알고리즘을 설계했다. 이 알고리즘은 강화학습의 정책 최적화 기법을 변형해, “그룹 상대”(group relative) 보상 구조를 도입함으로써 개별 인스턴스가 아닌 전체 집단의 성능 향상을 목표로 한다. 결과적으로 전략이 특정 공격에 과적합되는 위험을 완화하고, 다양한 위협에 대한 일반화된 방어 정책을 도출한다.
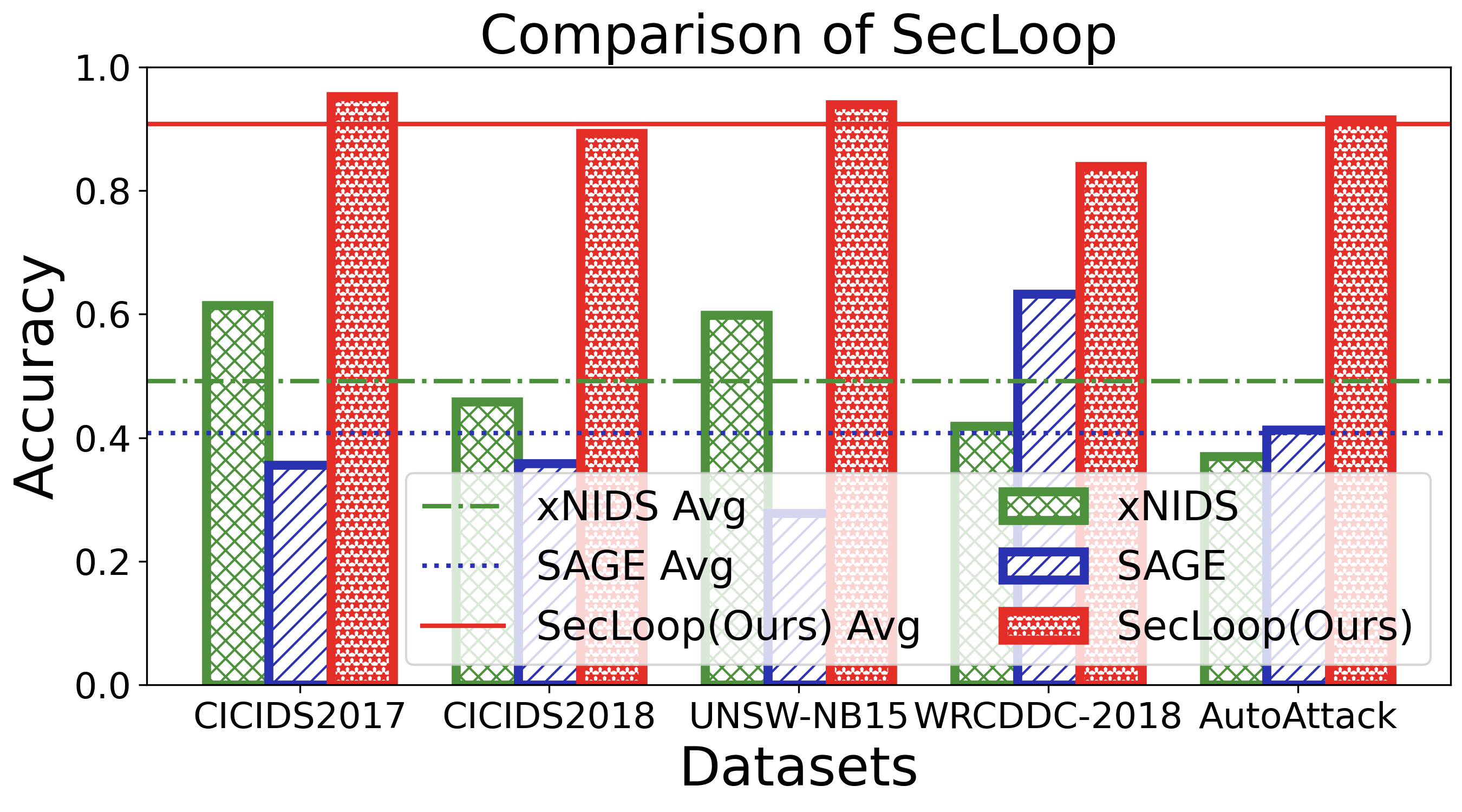
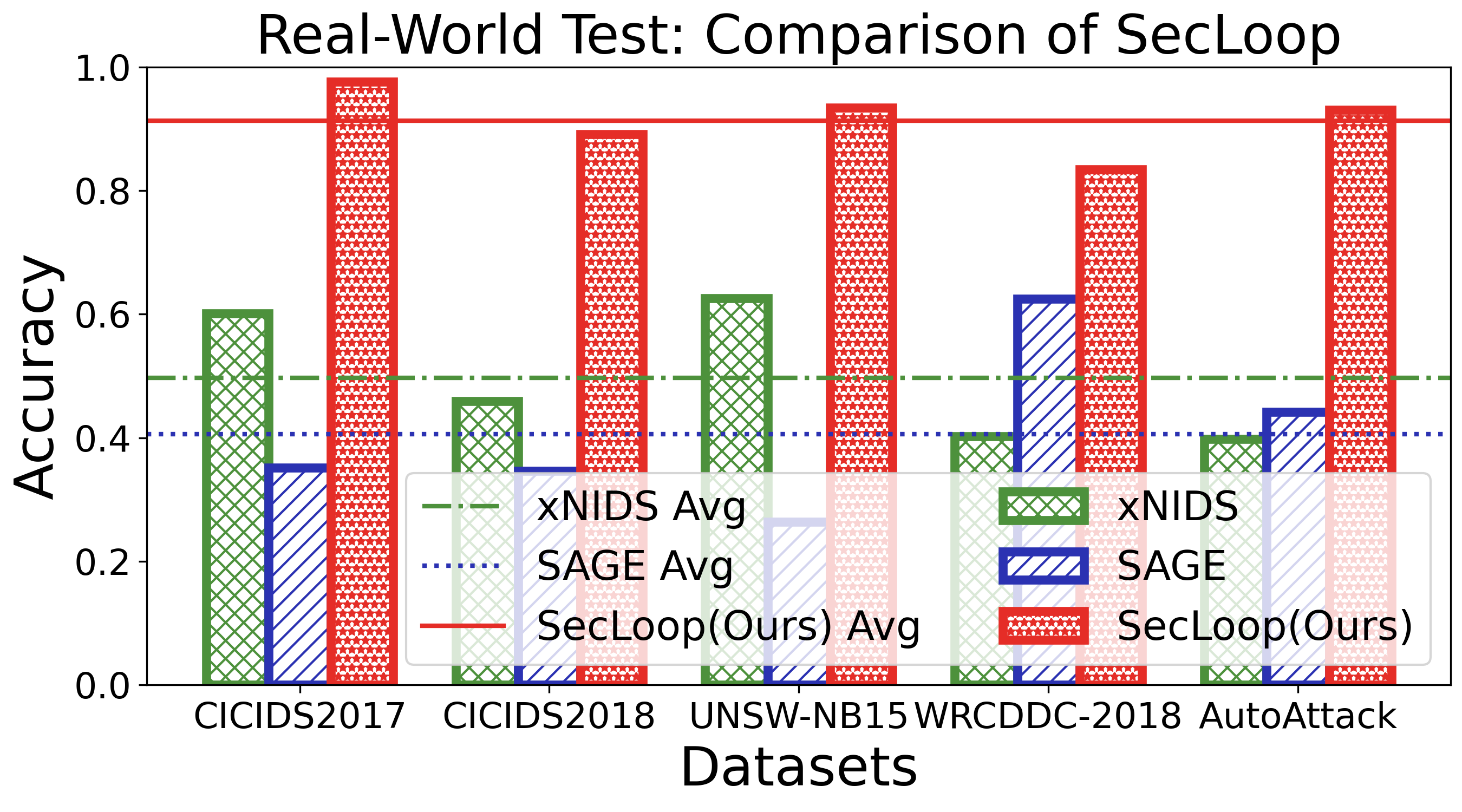
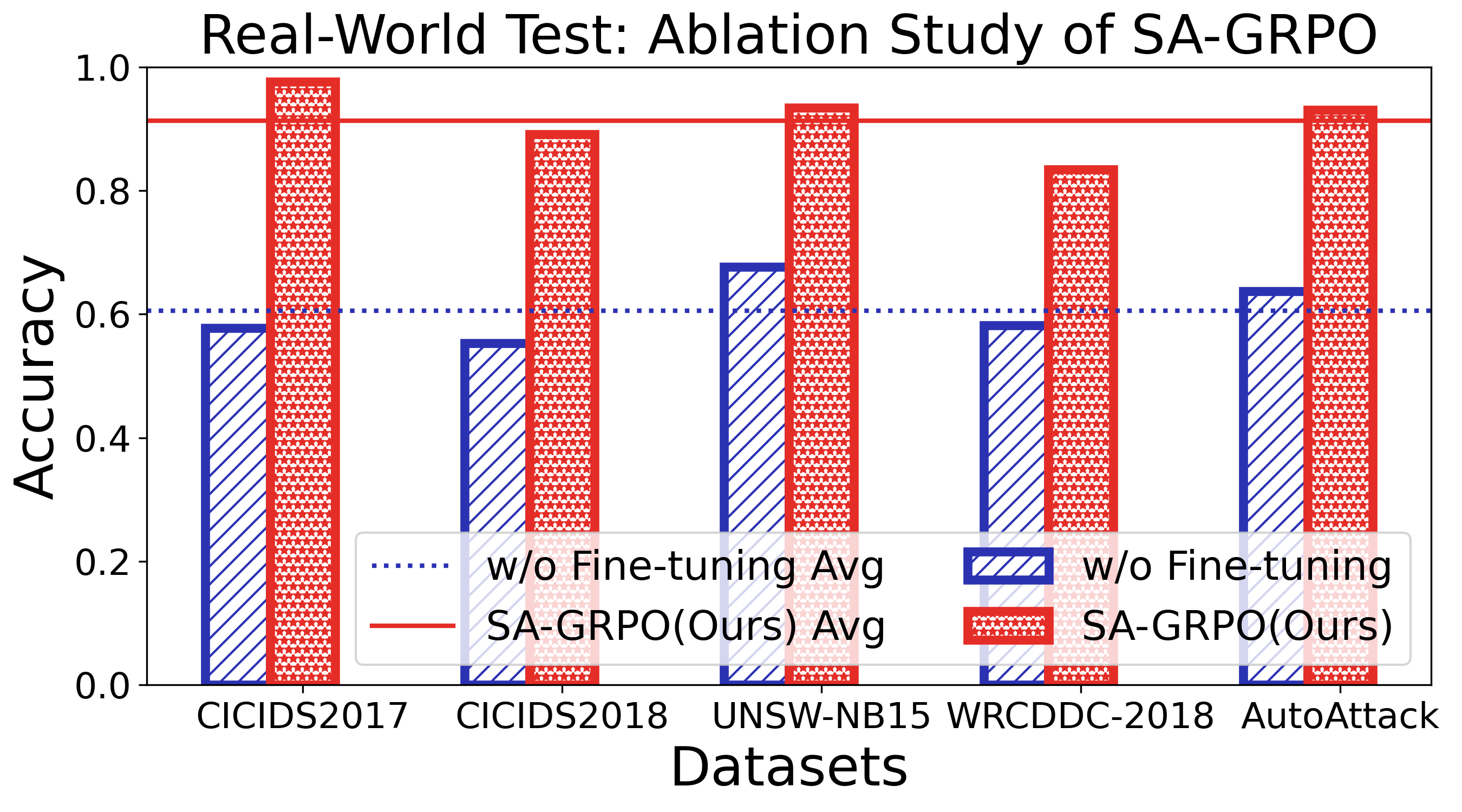
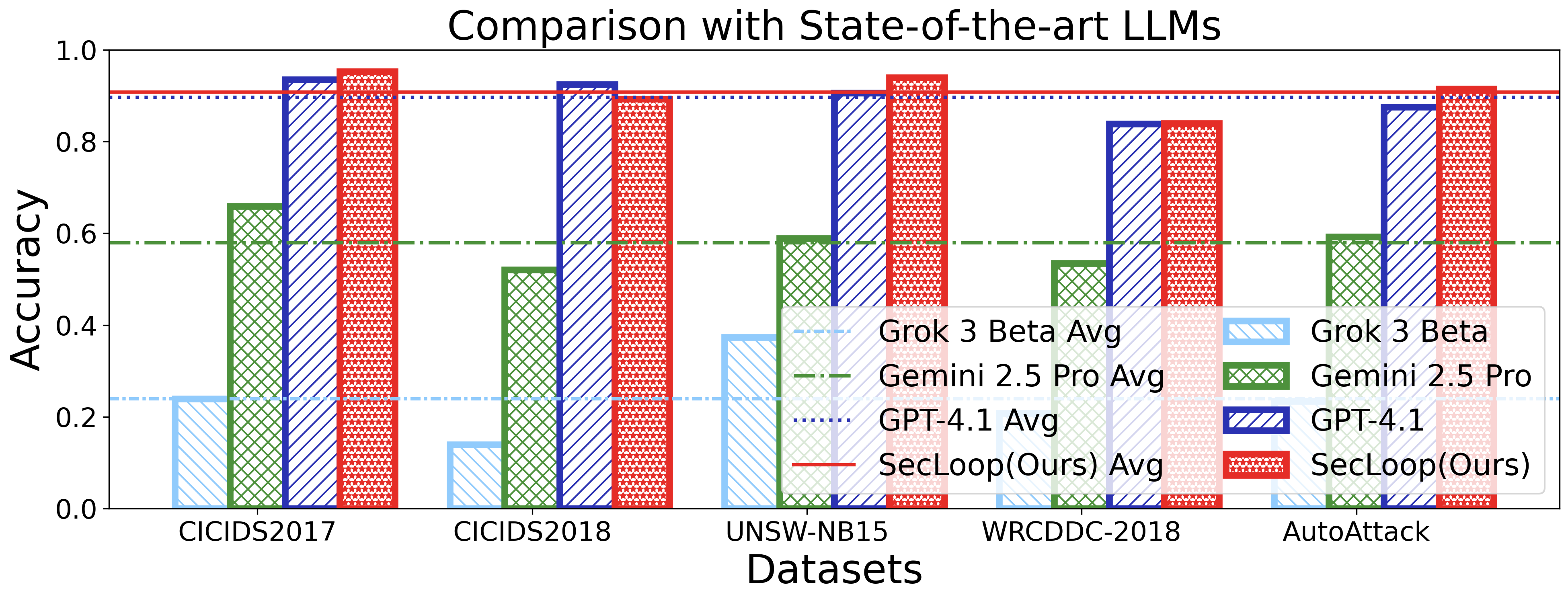
실험 설계는 MITRE ATT&CK 프레임워크를 기반으로 11개의 공격 프로세스와 20여 종류의 구체적 공격을 포함한 5개의 벤치마크를 사용해 포괄적이다. 이는 제안된 시스템이 실제 운영 환경에서 직면할 수 있는 복합적인 위협을 충분히 재현한다는 점에서 신뢰성을 높인다. 실험 결과는 기존 자동화 방어 시스템 대비 탐지 정확도, 대응 시간, 전략 업데이트 효율성 등 다각적인 지표에서 현저히 우수함을 보여준다.
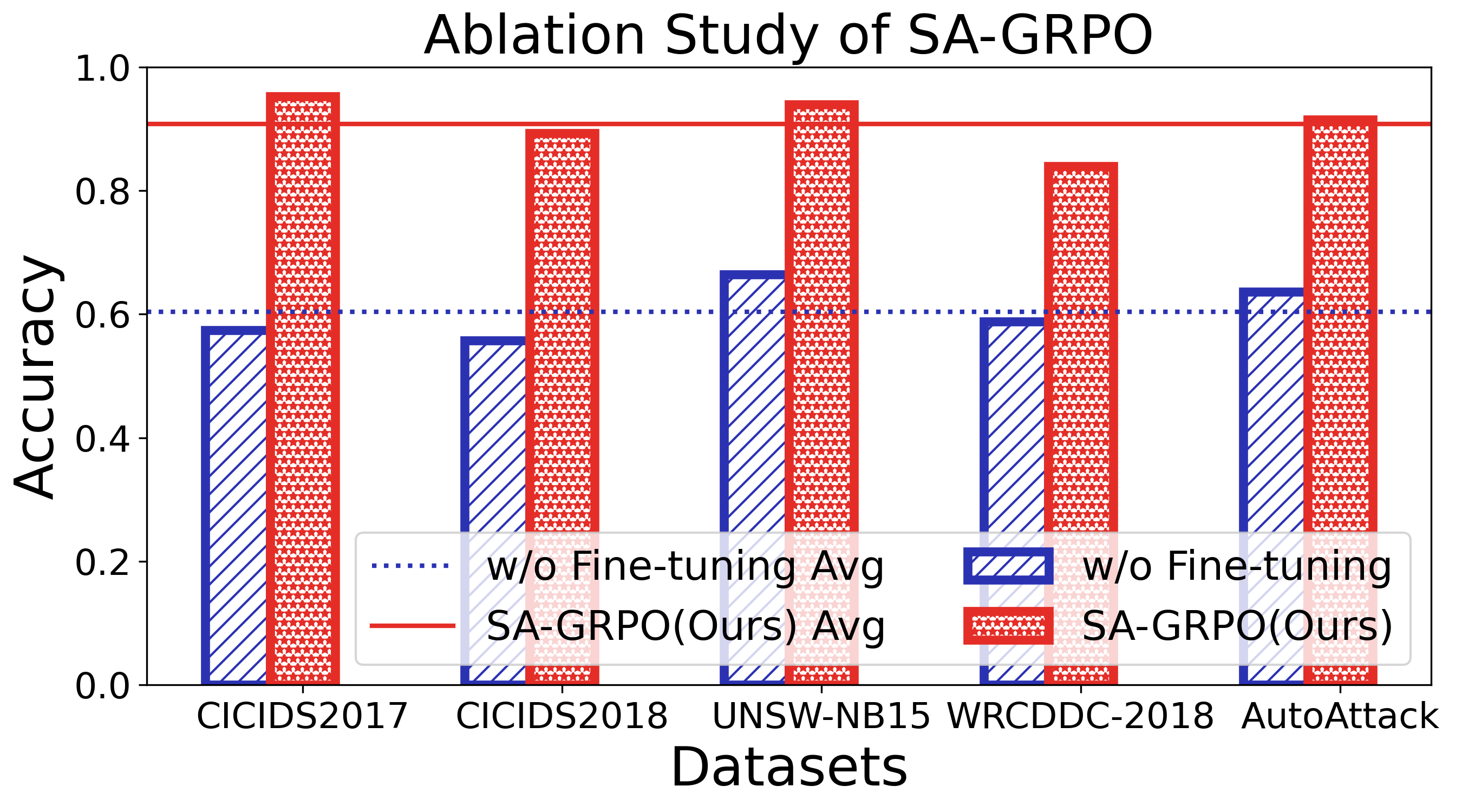
하지만 몇 가지 한계점도 존재한다. 첫째, LLM 기반 전략 생성은 사전 학습 데이터에 크게 의존한다는 점에서 새로운 공격 전술이 급변할 경우 초기 대응이 늦어질 가능성이 있다. 둘째, SA‑GRPO의 그룹 피드백 수집 과정은 대규모 네트워크에서 통신 오버헤드를 야기할 수 있다. 셋째, 실험이 주로 시뮬레이션 환경에 국한되어 있어 실제 6G 파일럿망에서의 적용 가능성을 검증하려면 추가적인 현장 테스트가 필요하다.
향후 연구 방향으로는 (1) LLM을 지속적으로 업데이트하는 온라인 학습 메커니즘, (2) 피드백 수집 비용을 최소화하는 경량화된 그룹 보상 설계, (3) 실제 6G 파일럿망과 연계한 장기 운영 평가 등이 제시될 수 있다. 전반적으로 본 논문은 6G 제로터치 네트워크 보안 자동화라는 새로운 연구 영역에 대한 로드맵을 제시하고, LLM과 강화학습을 융합한 실용적인 프레임워크를 제공함으로써 학계와 산업계 모두에 큰 파급 효과를 기대한다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리