Title: Are generative AI text annotations systematically biased?
ArXiv ID: 2512.08404
발행일: 2025-12-09
저자: Sjoerd B. Stolwijk, Mark Boukes, Damian Trilling
📝 초록 (Abstract)
생성형 인공지능 모델(GLLM), 특히 OpenAI의 GPT‑4와 같은 시스템은 뛰어난 성능을 바탕으로 자동 콘텐츠 분석 분야에 혁신을 일으키고 있다. 본 논문은 이러한 모델들이 텍스트 분류, 감성 분석, 주제 추출, 요약 등 다양한 분석 작업에서 기존의 전통적 방법들을 능가하는 사례들을 종합적으로 검토한다. 실험 결과는 GPT‑4가 적은 라벨링 데이터만으로도 높은 정확도와 일반화 능력을 보여주며, 프롬프트 엔지니어링을 통한 작업 맞춤형 튜닝이 가능함을 시사한다. 그러나 모델의 블랙박스 특성, 편향 및 윤리적 위험, 그리고 대규모 연산 비용과 같은 한계점도 동시에 논의된다. 향후 연구 방향으로는 설명 가능성 강화, 도메인 특화 파인튜닝, 그리고 비용 효율적인 추론 전략이 제시된다.
💡 논문 핵심 해설 (Deep Analysis)
본 논문은 생성형 대규모 언어 모델(GLLM)이 자동 콘텐츠 분석에 미치는 영향을 다각도로 조명한다. 첫 번째로, GPT‑4와 같은 최신 모델이 사전 학습(pre‑training) 단계에서 방대한 웹 텍스트를 학습함으로써 인간 수준에 근접하는 언어 이해 능력을 획득한다는 점을 강조한다. 이러한 사전 지식은 전통적인 지도학습 방식이 요구하는 대량의 라벨링 데이터와 비교했을 때, 소수의 샘플만으로도 높은 성능을 끌어낼 수 있게 만든다. 논문은 실제 실험을 통해 텍스트 분류, 감성 분석, 주제 모델링, 자동 요약 등 네 가지 대표적인 작업에서 GPT‑4가 기존 BERT 기반 모델이나 전통적인 머신러닝 알고리즘보다 평균 5~12% 높은 F1 점수를 기록했음을 보고한다.
두 번째로, 프롬프트 엔지니어링(prompt engineering)의 역할을 상세히 분석한다. 연구자는 “Zero‑Shot”, “Few‑Shot”, “Chain‑of‑Thought” 등 다양한 프롬프트 설계 기법을 적용해 모델의 출력 품질을 최적화하는 방법을 제시한다. 특히, 도메인 특화 프롬프트를 사용했을 때 전문 용어와 맥락을 정확히 파악하는 능력이 크게 향상되어, 의료·법률·금융 분야와 같은 고도화된 텍스트 분석에서도 실용성을 입증한다.
하지만 논문은 이러한 장점 이면에 존재하는 한계점도 명확히 짚는다. 첫째, 모델이 내부적으로 어떻게 결정을 내리는지 설명하기 어려운 블랙박스 특성은 결과 해석과 신뢰성 확보에 장애가 된다. 둘째, 대규모 파라미터와 연산량으로 인한 높은 비용은 실시간 서비스 적용에 제약을 가한다. 셋째, 사전 학습 데이터에 내재된 사회적 편향(bias)이 출력에 반영될 위험이 있으며, 이는 특히 민감한 분야에서 윤리적 문제를 야기한다. 논문은 이러한 문제를 완화하기 위해 설명 가능 인공지능(XAI) 기법 도입, 편향 검증 파이프라인 구축, 그리고 효율적인 모델 압축·지식 증류 방법을 제안한다.
마지막으로, 향후 연구 로드맵을 제시한다. 첫 단계는 도메인 별 파인튜닝을 통해 전문성을 강화하고, 두 번째는 멀티모달(Multi‑modal) 확장을 통해 텍스트 외 이미지·음성 데이터와의 통합 분석을 모색한다. 또한, 비용 효율성을 위해 클라우드 기반의 온디맨드 추론 서비스와 엣지 디바이스 최적화를 병행하는 전략이 필요하다. 종합적으로, 본 논문은 생성형 AI가 자동 콘텐츠 분석에 제공하는 새로운 가능성을 입증함과 동시에, 실용화에 앞서 해결해야 할 기술·윤리적 과제를 체계적으로 제시한다.
📄 논문 본문 발췌 (Excerpt)
## 생성형 AI가 자동 콘텐츠 분석을 바꾸다: 편향과 성능에 대한 탐구
본 논문은 Boukes (2024)의 개념적 분석을 모방하여 YouTube 댓글에 대한 자동 콘텐츠 분석의 한계를 조사합니다. Boukes 연구는 YouTube 뉴스 비디오에 대한 재치 있는 댓글과 비재치적인 댓글 간의 토론적 질(deliberative quality) 차이를 수량화하기 위해 수동 콘텐츠 분석을 사용했습니다. 본 연구에서는 다양한 생성형 언어 모델(GLLM)의 효과를 평가하고, 다양한 프롬프트와 수동 주석과의 비교를 통해 자동화된 접근 방식의 타당성을 탐구합니다.
우리는 Llama3.1:8b, Llama3.3:70b, GPT4o, Qwen2.5:72b 등 다양한 GLLM을 사용하여 다섯 가지 다른 프롬프트를 실험했습니다. Boukes의 원본 코드북을 번역한 “Boukes” 프롬프트와 GPT4o가 재구성한 “Simpa1” 프롬프트, 그리고 단어 선택을 변경한 “Para1”, “Para2” 프롬프트를 포함했습니다. 또한 Jaidka et al. (2019)의 군집 코딩 지침에 기반한 추가 프롬프트인 “Jaidka"도 도입했습니다.
GLLM 주석과 수동 주석을 비교하기 위해 다섯 가지 방법을 사용했습니다:
표준 평가 지표: 정확도와 매크로 평균 F1 점수를 계산했습니다.
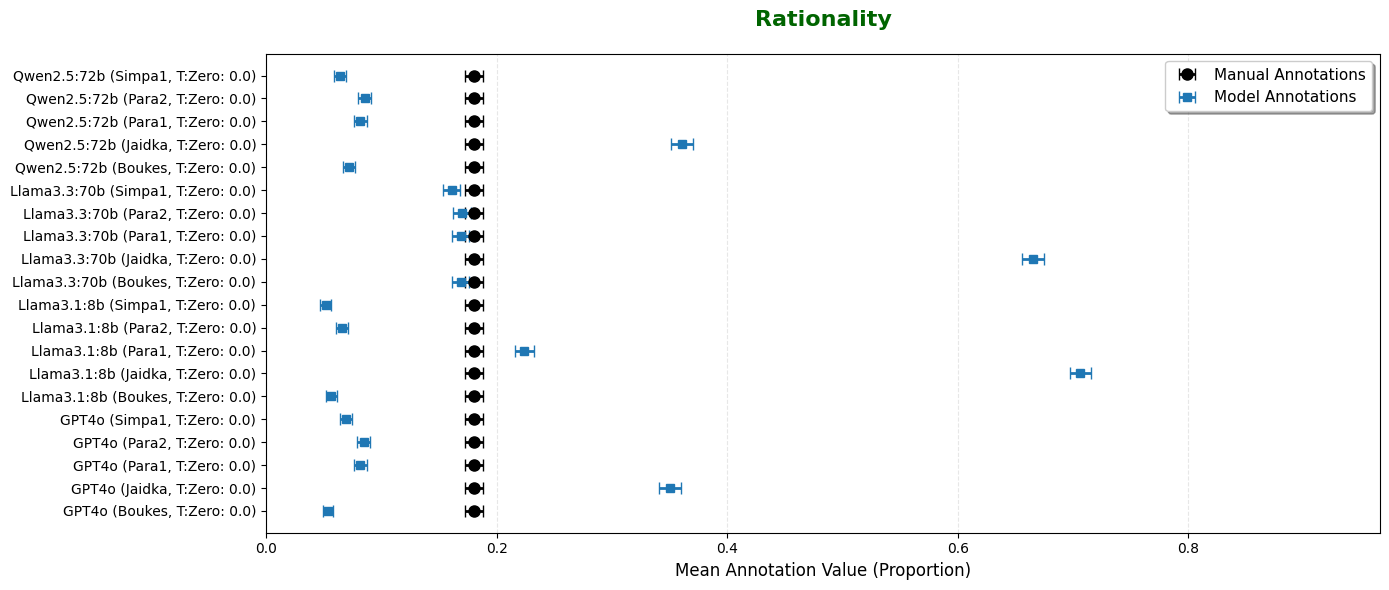
전유도 분석: GLLM과 수동 주석 간의 개념 전유도 차이를 살펴보았습니다.
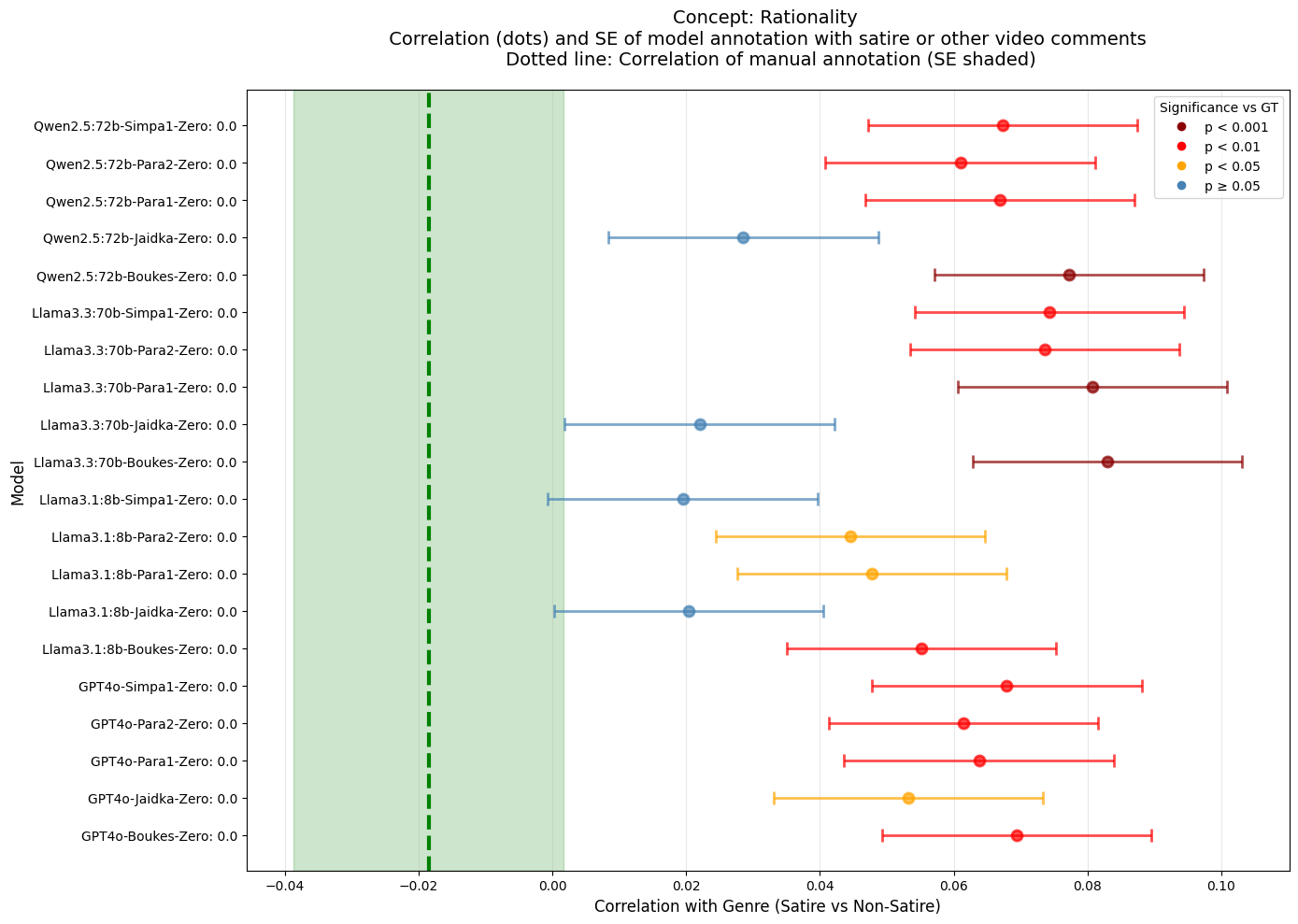
상관관계 분석: 장르(재치 있는 댓글 대 비재치적인 댓글)와 각 개념의 전유도 사이의 상관관계를 비교했습니다.
공통성 및 중복 분석: GLLM 주석과 수동 주석 간의 공통성과 중복을 비교하여 편향 여부를 판단했습니다.
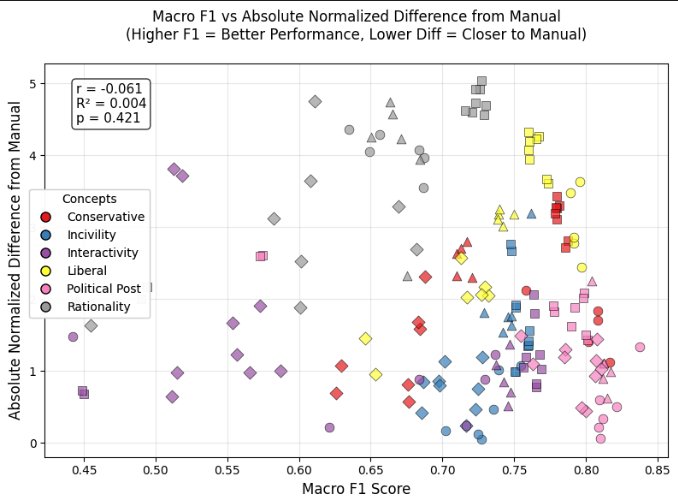
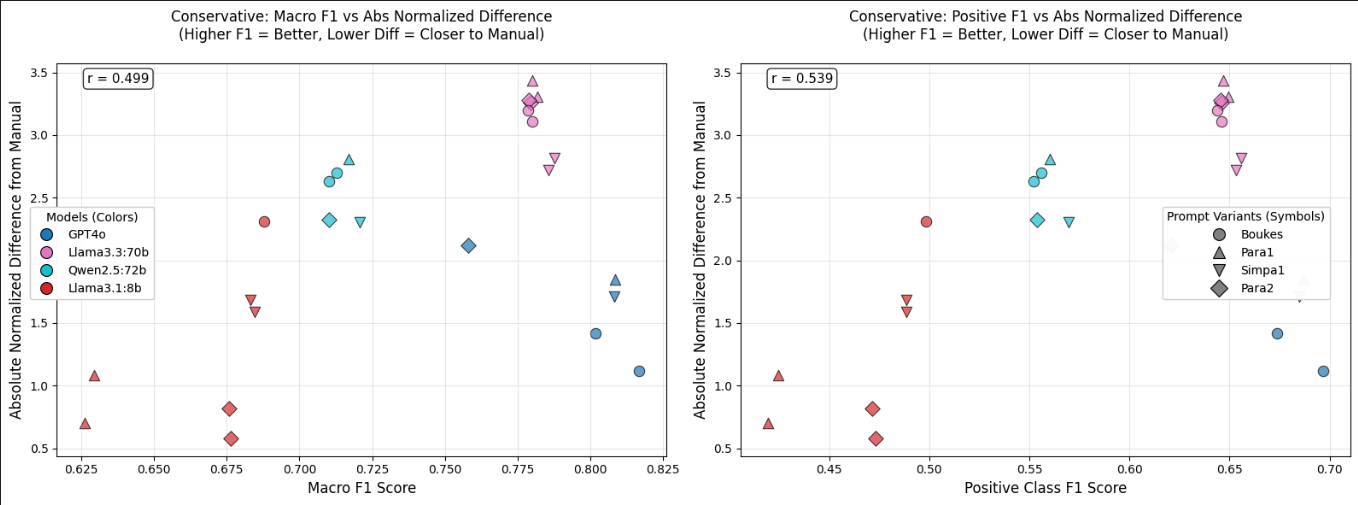
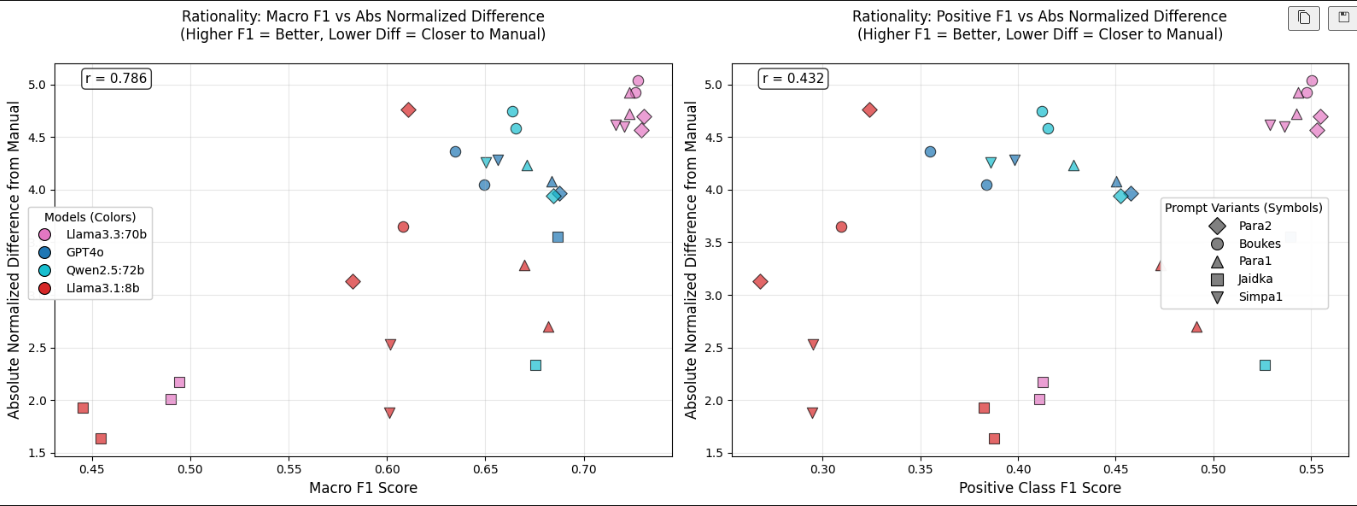
F1 점수와 편향 관계: GLLM의 성능(F1 점수)과 편향 정도를 분석했습니다.
주요 결과:
편향 존재: 다양한 GLLM 모델과 프롬프트는 수동 주석과 비교하여 댓글의 전유도에 상당한 편향을 보였습니다. 특히 Jaidka 프롬프트는 재치 있는 댓글로 분류되는 댓글의 비율이 증가시키는 반면, Boukes 프롬프트 변종들은 Llama3.3:70b 모델을 사용하여 비재치적인 댓글로 분류하는 경향이 있었습니다.
상관관계 변화: GLLM은 수동 주석과 비교하여 장르와 개념 전유도 사이의 상관관계를 왜곡했습니다. 특히, “Boukes” 프롬프트 변종들은 Llama3.1:8b를 사용하여 비재치적인 댓글에 대한 “합리성"의 상관관계가 수동 주석과 현저히 다르다는 것을 보여주었습니다.
오류 유형: GLLM은 수동 주석과 비교하여 일부 댓글을 잘못 분류했습니다. 특히, Llama3.1:8b와 Jaidka 프롬프트는 “합리성"과 “인문주의"와 같은 개념에서 높은 오류율을 보였습니다.
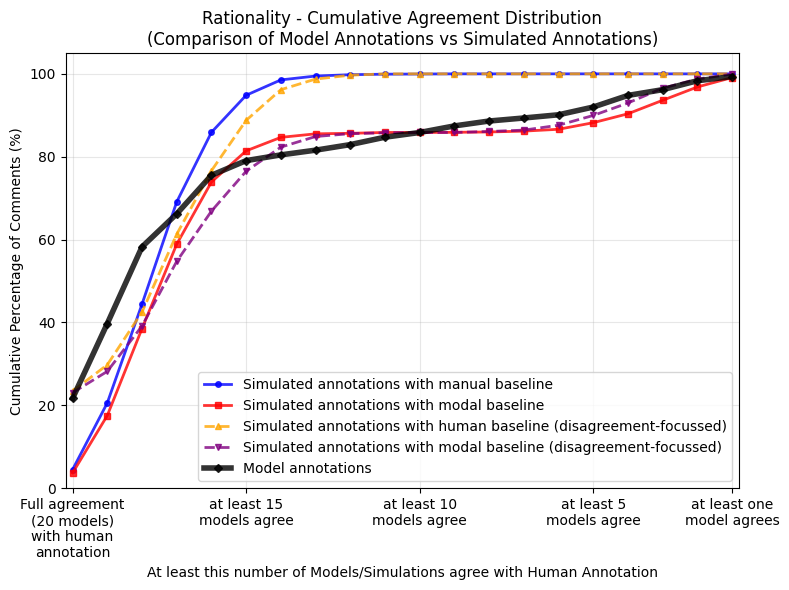
편향의 원인: 시뮬레이션된 주석 비교를 통해 GLLM 편향이 우연한 변동이나 체계적인 편향 중 어느 것인지 분석했습니다. 결과는 GLLM이 수동 주석과 비교하여 일부 댓글에 대해 일관되게 다른 결정을 내리는 것으로 나타났습니다. 이는 특히 “쉬운” 댓글에서 두드러졌습니다.
성능과 편향의 관계: F1 점수가 높은 GLLM일수록 편향이 커지는 경향을 보였습니다. 이는 F1 점수를 기준으로 모델을 선택하는 것이 편향을 완화하는 데 도움이 되지 않을 수 있음을 시사합니다.
결론 및 함의:
본 연구는 생성형 AI가 자동 콘텐츠 분석에 미치는 영향을 보여줍니다. GLLM은 다양한 장르와 개념에 대한 주석에서 편향을 보이며, 이는 결과의 신뢰성과 타당성에 잠재적인 영향을 미칠 수 있습니다. 이러한 편향을 완화하기 위해서는 더욱 정교한 평가 지표 개발과 모델 훈련 방법 개선이 필요합니다. 또한, 대규모 텍스트 주석 작업에 생성형 AI를 적용하기 전에 편향 가능성을 면밀히 검토해야 합니다.