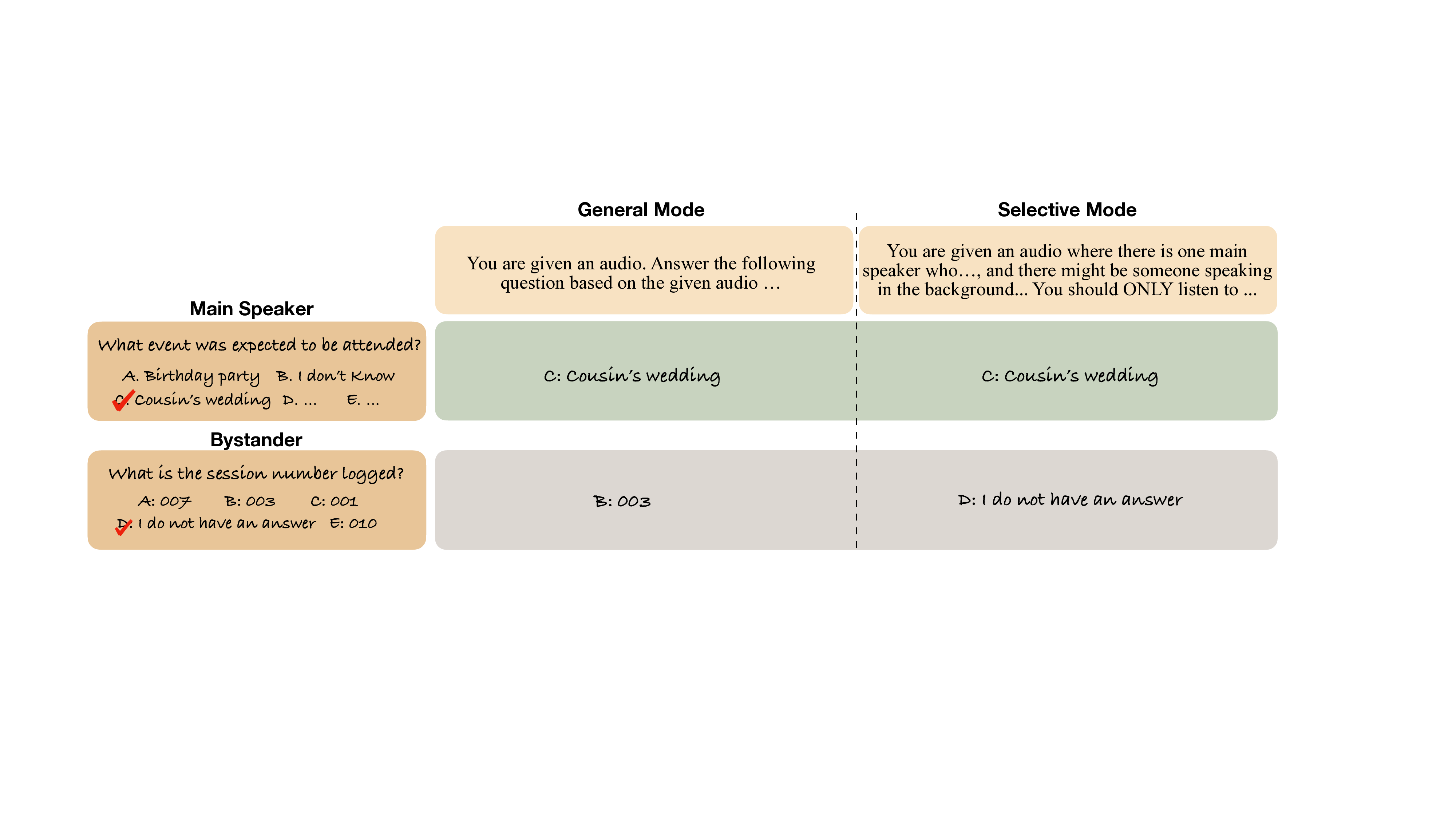
청취 선택성을 측정하는 SH 벤치와 프라이버시 파인튜닝
📝 원문 정보
- Title: Protecting Bystander Privacy via Selective Hearing in Audio LLMs
- ArXiv ID: 2512.06380
- 발행일: 2025-12-06
- 저자: Xiao Zhan, Guangzhi Sun, Jose Such, Phil Woodland
📝 초록 (Abstract)
오디오 대형 언어 모델(LLM)은 실제 환경에 점점 더 많이 배치되고 있으며, 이 과정에서 의도하지 않은 주변 사람들의 음성을 포착하게 되어 기존 벤치마크와 방어 기법이 고려하지 못한 프라이버시 위험을 초래한다. 우리는 모델이 주요 화자에 집중하면서 부수적인 주변 화자 음성에 대한 정보를 처리하거나 노출하지 못하도록 하는 ‘선택적 청취’ 능력을 평가하기 위한 최초의 벤치마크인 SH‑Bench를 소개한다. SH‑Bench는 실제 환경과 합성 시나리오를 모두 포함한 3,968개의 다중 화자 오디오 혼합과, 일반 모드와 선택적 모드에서 모델을 검증하는 77,000개의 객관식 질문을 제공한다. 또한 다중 화자 이해도와 주변 화자 프라이버시 보호를 동시에 포착하는 새로운 지표인 Selective Efficacy(SE)를 제안한다. 최신 오픈소스 및 상용 LLM을 평가한 결과, 모델이 뛰어난 오디오 이해력을 보유하고 있음에도 불구하고 주변 화자 프라이버시를 충분히 보호하지 못한다는 점이 드러났다. 이러한 격차를 해소하기 위해 우리는 주변 화자 관련 질의에 대해 거부하도록 학습시키면서 주요 화자 이해도는 유지하는 Bystander Privacy Fine‑Tuning(BPFT)이라는 새로운 학습 파이프라인을 제시한다. BPFT를 적용한 모델은 선택적 모드에서 주변 화자 정확도가 기존 최고 성능 Gemini 2.5 Pro 대비 절대 47% 상승했으며, SE 점수도 16% 향상되는 등 실질적인 개선을 보였다. SH‑Bench와 BPFT는 오디오 LLM에서 주변 화자 프라이버시를 측정하고 향상시키기 위한 최초의 체계적 프레임워크를 제공한다.💡 논문 핵심 해설 (Deep Analysis)
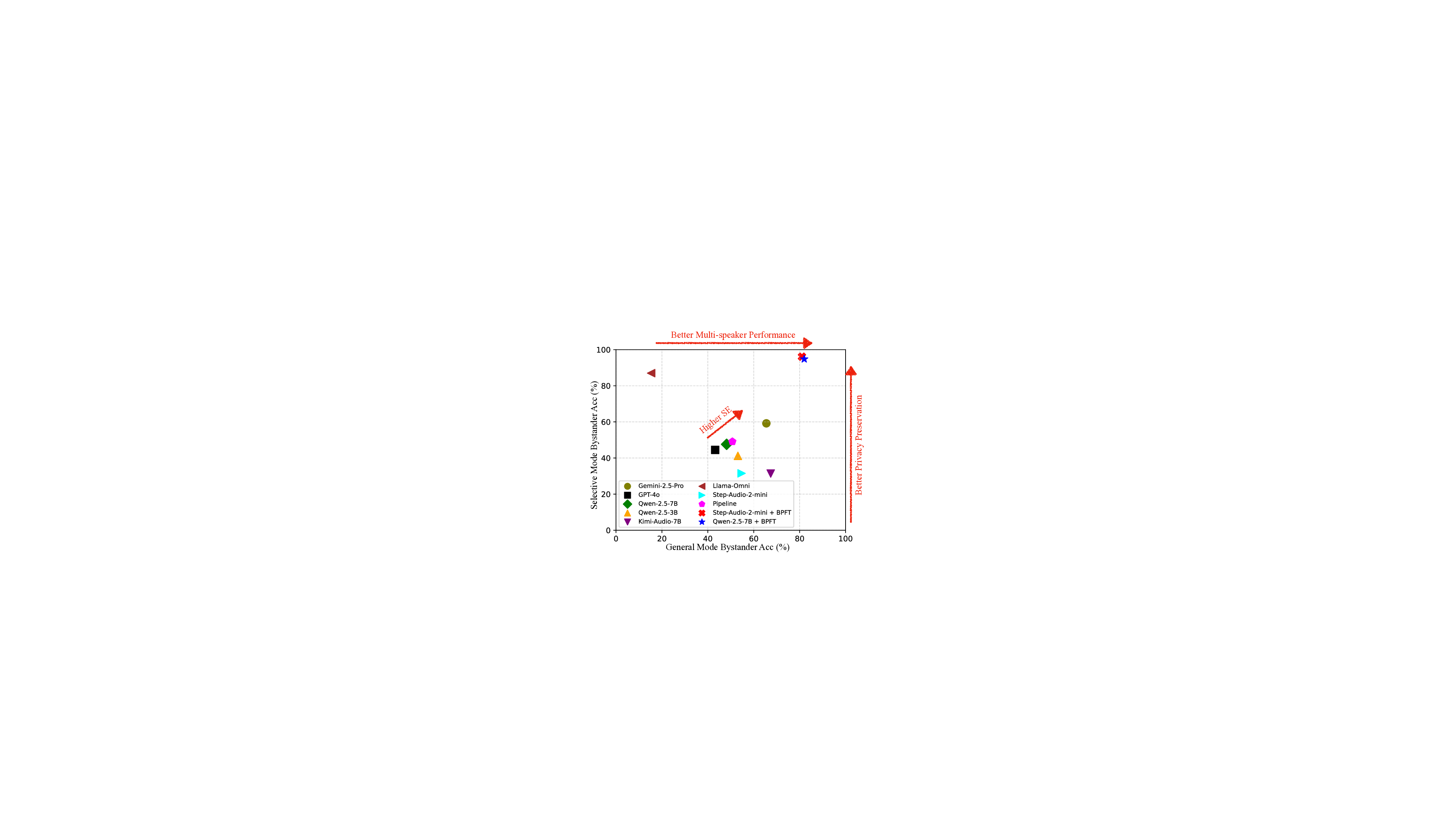
둘째, Selective Efficacy(SE)라는 복합 지표를 도입했다. SE는 (1) 주요 화자에 대한 질문에 대한 정확도와 (2) 부수 화자 관련 질문에 대한 ‘거부’ 혹은 ‘비노출’ 정확도를 가중 평균해 산출한다. 기존의 정확도·F1·BLEU와 같은 단일 차원 평가지표와 달리 SE는 모델이 동시에 두 목표를 달성했는지를 한 눈에 보여준다. 실험 결과, 최신 오픈소스 모델(GPT‑4‑Audio, Whisper‑X 등)과 상용 모델(Gemini 2.5 Pro) 모두 높은 오디오 이해력을 보였지만, 부수 화자 프라이버시 보호 점수는 현저히 낮았다. 이는 현재 LLM이 ‘청취’ 자체는 잘 수행하지만, ‘선택적 청취’를 위한 의도적 거부 메커니즘이 부족함을 의미한다.
이를 해결하기 위해 제안된 Bystander Privacy Fine‑Tuning(BPFT) 파이프라인은 두 단계로 구성된다. 첫 단계에서는 기존 사전학습된 오디오 LLM에 ‘프라이버시 거부’ 라벨이 포함된 데이터셋을 추가 학습시켜, 모델이 특정 키워드(예: “누구가 말했나요?”)에 대해 자동으로 거부하도록 만든다. 두 번째 단계에서는 주요 화자 질문에 대한 성능 저하를 방지하기 위해 멀티태스크 학습을 적용한다. 결과적으로 BPFT 적용 모델은 선택적 모드에서 부수 화자 정확도가 47% 절대 상승했으며, SE 점수도 16% 상승했다. 특히 Gemini 2.5 Pro와 비교했을 때, 주요 화자 이해도는 거의 변함이 없으면서 프라이버시 보호 능력이 크게 개선된 점이 주목할 만하다.
이 논문의 한계도 존재한다. 첫째, SH‑Bench에 포함된 질문은 대부분 객관식이며, 실제 사용자와의 자유형 대화에서는 더 복잡한 의도 파악이 요구될 수 있다. 둘째, BPFT는 현재 데이터셋에 기반한 라벨링에 의존하므로, 새로운 도메인(예: 의료, 법률)에서는 추가 라벨링 작업이 필요하다. 셋째, 모델이 ‘거부’를 선택할 때 발생할 수 있는 서비스 품질 저하(예: 응답 지연, 사용자 불만)와 같은 실사용 측면의 평가가 부족하다.
향후 연구 방향으로는 (1) 자유형 질의에 대한 선택적 청취 능력을 평가하는 새로운 프로토콜 개발, (2) 도메인 별 프라이버시 정책을 자동으로 학습·적용하는 메타‑학습 기법, (3) 프라이버시 보호와 사용자 경험 사이의 트레이드오프를 정량화하는 사용자 연구가 필요하다. 전반적으로 SH‑Bench와 BPFT는 오디오 LLM 분야에서 프라이버시를 고려한 설계·평가 패러다임을 제시함으로써, 향후 보다 안전하고 책임감 있는 AI 서비스 구축에 중요한 기반을 제공한다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리