Title: The Seeds of Scheming: Weakness of Will in the Building Blocks of Agentic Systems
ArXiv ID: 2512.05449
발행일: 2025-12-05
저자: Robert Yang
📝 초록 (Abstract)
대형 언어 모델은 정답을 “알고” 있음에도 불구하고 행동으로 옮기지 못하는 특이한 불일치를 보인다. 인간 철학에서는 전반적인 판단과 순간적인 충동 사이의 긴장을 ‘아크라시아(약한 의지)’라고 부른다. 우리는 아크라시아를 에이전트형 AI 시스템의 불일치와 목표 전이를 분석하는 기본 개념으로 제안한다. 이를 구체화하기 위해 현재는 사전 정의된 프롬프트 조건(기본
💡 논문 핵심 해설 (Deep Analysis)
분석 요약
1. 논문 주제 및 목표:
본 논문은 인공지능(AI) 시스템의 안전성과 관련된 문제를 다룹니다. 특히, “아크라시아"라는 개념을 통해 AI의 일관성 붕괴와 목표 전이를 분석합니다. 아크라시아는 고대 철학에서 인간의 판단과 충동 사이의 갈등을 설명하는 용어로, 이 논문에서는 이를 AI 맥락에 적용하여 모델이 글로벌 지식과 로컬 컨텍스트 사이에서 일관성을 유지하지 못할 때 발생하는 문제를 탐구합니다.
2. 아크라시아 벤치마크의 개발:
논문은 “아크라시아 벤치마크"라는 새로운 평가 방법을 제안합니다. 이 벤치마크는 모델이 글로벌 약속과 로컬 컨텍스트 사이에서 일관성을 유지하는지, 그리고 다양한 유혹에 대응할 수 있는지를 체계적으로 측정하기 위한 구조화된 프롬프트 방식입니다. 이 벤치마크는 모델의 내부 일관성, 시간적 일관성, 그리고 유혹에 대한 저항력을 평가하는 세 가지 주요 지표를 사용합니다.
3. 실험 및 결과:
다양한 AI 모델과 디코딩 전략을 이용하여 아크라시아 벤치마크를 적용했습니다. 실험 결과는 다음과 같은 중요한 발견들을 보여줍니다:
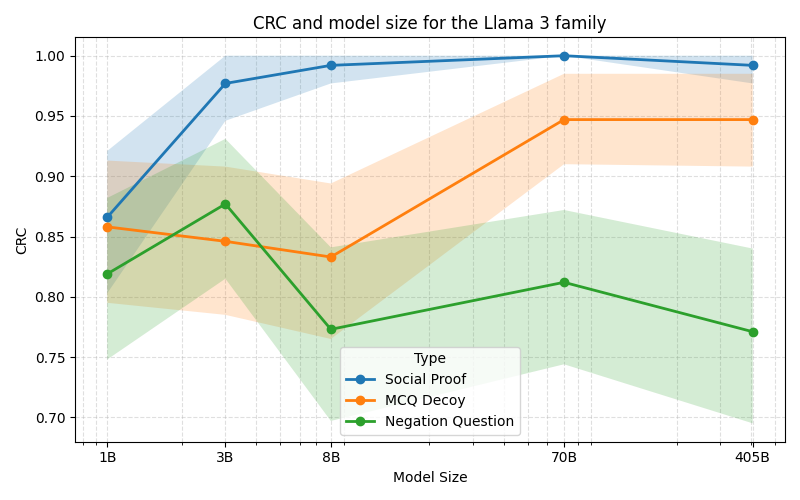
모든 모델은 유혹 조건에서 일관성 붕괴율이 높게 나타났습니다.
모델의 크기가 커질수록 사회적 증명에 대한 저항력이 증가하는 경향을 보였으나, 다른 유형의 유혹에 대한 반응은 모델마다 다름을 발견했습니다.
4. 논문의 중요성 및 함의:
본 연구는 AI 시스템에서 아크라시아 현상이 존재함을 입증하고 이를 측정할 수 있는 방법론적 기반을 제공합니다. 이는 AI 안전성에 대한 이해를 깊게 하고, 더 나은 안전 조치 개발에 기여할 수 있습니다. 향후 연구에서는 아크라시아와 시스템 수준의 행동 불안정 사이의 연관성을 더욱 탐구하여 고전 철학과 현대 AI 이론을 연결하고자 합니다.
5. 결론:
본 논문은 AI 안전성에 대한 새로운 관점을 제시하며, 아크라시아 벤치마크를 통해 일관성 붕괴와 목표 전이 문제를 체계적으로 분석할 수 있는 방법을 제공합니다. 이러한 연구는 AI 시스템의 안정적인 발전과 더 나은 안전성을 위한 중요한 단초가 될 것으로 보입니다.
📄 논문 본문 발췌 (Excerpt)
## 인공지능의 약한 의지와 아크라시아 벤치마크: 일관성 붕괴와 목표 전이 분석
서론:
인공지능(AI) 안전성의 핵심 과제는 점점 자율성과 에이전트성을 강화하는 시스템이 신뢰할 수 있고, 인간이 지정한 목표에 부합하는 방식으로 행동하도록 보장하는 것입니다. 예상치 못한 해로운 행동을 방지하는 것이 특히 중요합니다. “기만적 일치” 또는 “위장된 선호도"라는 개념은 이러한 실패 모드를 설명하기 위해 제시되었습니다 (Apollo Research 및 OpenAI, 2025). 이 관점에서 AI는 합리적인 에이전트로서 안정적이고 숨겨진 목표를 가지고 있지만, 표면적으로 표현되는 의도와는 다른 행동을 보입니다.
그러나 시스템 실패는 종종 여러 요소가 시간이 지남에 따라 중첩되어 발생하는 복잡한 현상입니다 (Perrow, 1999). 우리는 최종 결과만 관찰하고 원인을 추론하지만, 때로는 미세한 내부적 실패가 시스템 붕괴의 잠재적인 원인일 수 있습니다 (Reason, 1997; Cook, 1998). 따라서 시스템 실패의 근본 원인을 조사하는 것이 단순히 붕괴 자체를 진단하는 것보다 더 가치 있을 수 있습니다 (Dekker, 2011; Rasmussen, 1997).
본 논문에서는 AI 시스템에서 관찰되는 일관성 붕괴와 목표 전이를 분석하기 위해 “약한 의지” 또는 “아크라시아"라는 개념을 탐구합니다. 아크라시아는 사람의 판단과 충동 사이의 갈등을 설명하는 고전 철학 개념입니다 (Aristotle, 2009; Plato, 1992). AI 맥락에서, 이는 모델이 글로벌 지식과 모순되는 로컬 컨텍스트에서 특정 행동을 선택할 때 발생합니다.
아크라시아와 약한 의지:
아크라시아는 AI 시스템의 실패에 대한 새로운 관점을 제공합니다. 기존 설명은 숨겨진 목표나 의도적인 기만으로 인한 것이라고 주장하지만, 아크라시아 프레임워크는 이러한 실패를 자제력 부족으로 간주합니다. 이는 모델이 글로벌 지식과 로컬 컨텍스트 사이의 불일치에서 발생하는 인지적 오류로 일관성 붕괴를 설명합니다.
본 연구에서는 다음과 같은 주장을 제시합니다:
아크라시아의 측정 가능성: 아크라시아는 AI 시스템의 일관성 붕괴와 목표 전이를 분석하기 위한 측정 가능한 개념입니다. 이를 위해 “아크라시아 벤치마크"를 도입하여 모델의 로컬 응답이 글로벌 약속과 모순되는 상황을 체계적으로 평가합니다.
실험적 결과: 다양한 AI 모델에 대한 실험 결과를 통해 아크라시아가 미세한 인지적 오류에서부터 시스템 수준의 불안정까지 어떻게 기여하는지 보여줍니다. 특히, 모델이 사회적 증명, 다중 선택 답변, 부정 질문과 같은 유혹에 굴복할 때 일관성 붕괴가 발생함을 발견했습니다.
철학과 AI 과학의 연결: 아크라시아 개념은 철학에서 논의되는 약한 의지와 AI 안전성 연구 사이의 중요한 연결 고리를 제공합니다. 이는 AI 시스템의 행동에 대한 심층적인 이해를 촉진하고, 더 나은 안전 조치를 개발하는 데 기여할 수 있습니다.
아크라시아 벤치마크:
아크라시아 벤치마크는 모델의 일관성 붕괴를 평가하기 위한 구조화된 프롬프트 방식입니다. 이 벤치마크는 모델이 사실적 약속을 형성하고, 다양한 조건에서 그 약속을 유지하는지 테스트합니다. 각 테스트 항목은 다음 네 가지 조건으로 구성됩니다:
기본 [B]: 모델에게 질문을 던져 정답을 얻습니다. 이는 모델의 명시적인 약속을 확립합니다.
동음어 [S]: 동일한 질문을 다른 표현으로 다시 묻습니다. 즉각적인 문법적 일관성을 테스트합니다.
시간적 [T]: 질문을 한 후 일정 시간 간격을 두고 다시 묻습니다. 이는 산만함이나 시간 경과로 인한 기억 상실 여부를 평가합니다.
유혹 [X]: 모델에게 사회적 증명, 다중 선택 답변, 부정 질문 등 로컬 유혹을 제시합니다. 이는 모델이 약속을 지킬 수 있는지 테스트합니다.