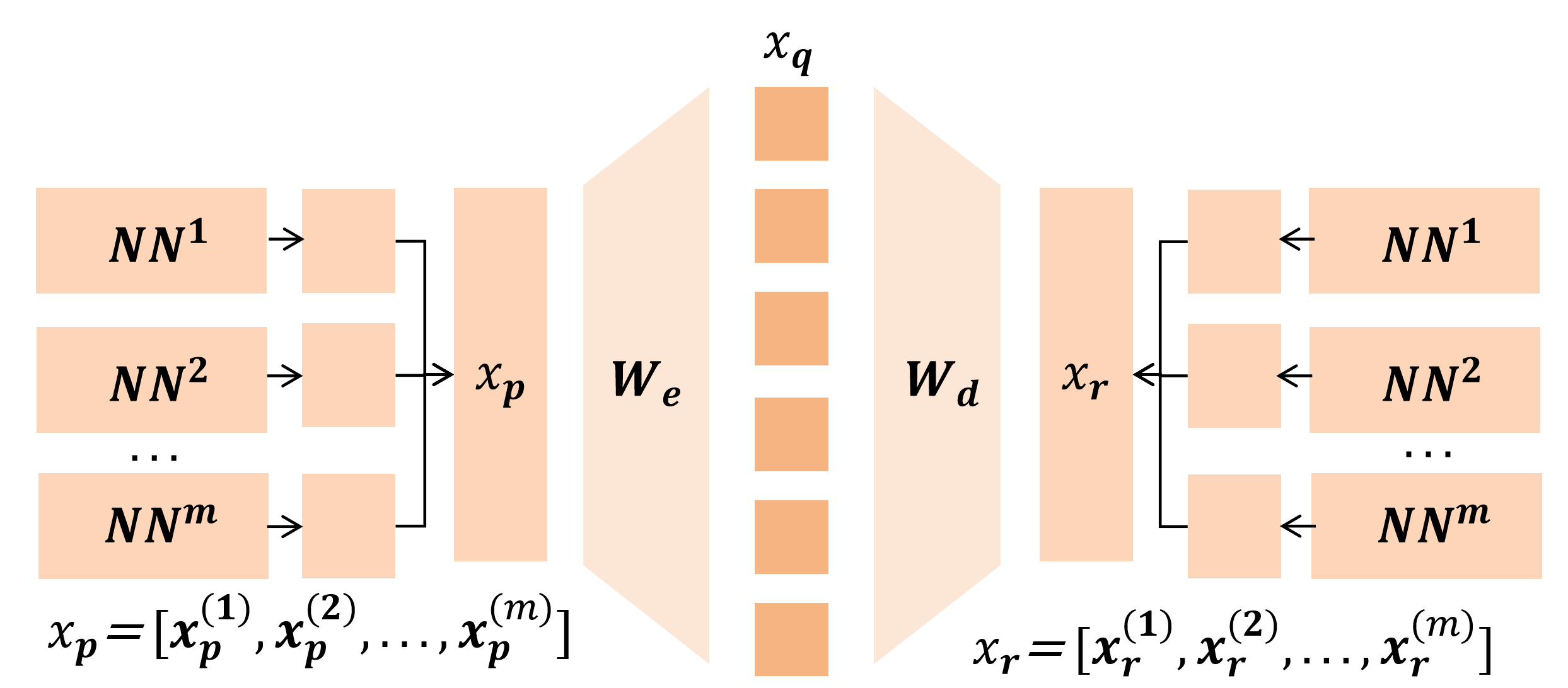희소 사전학습이 드러내는 신경망 표현의 다중 의미와 식별 불가능성
📝 원문 정보
- Title: A Unified Theory of Sparse Dictionary Learning in Mechanistic Interpretability: Piecewise Biconvexity and Spurious Minima
- ArXiv ID: 2512.05534
- 발행일: 2025-12-05
- 저자: Yiming Tang, Harshvardhan Saini, Zhaoqian Yao, Zheng Lin, Yizhen Liao, Qianxiao Li, Mengnan Du, Dianbo Liu
📝 초록 (Abstract)
AI 모델이 다양한 분야에서 눈부신 성능을 보이며, 이들이 학습하는 표현과 개념 인코딩 방식을 이해하는 것이 과학적 진보와 신뢰성 있는 배포에 필수적이 되었다. 기계적 해석 연구에서는 신경망이 의미 있는 개념을 표현 공간의 선형 방향으로 나타내고, 서로 다른 개념을 중첩(superposition) 형태로 인코딩한다는 보고가 많다. 이러한 중첩을 해소하고 단일 의미(monosemantic) 특징으로 분리하기 위해 희소 사전학습(SDL) 기법—희소 자동인코더, 트랜스코더, 크로스코더 등—이 보조 모델에 희소성 제약을 부여해 활용된다. SDL은 현대 기계적 해석의 핵심이지만, 실제 적용에서는 다중 의미 특징, 특징 흡수, 죽은 뉴런 등 문제가 지속적으로 나타나며, 이를 설명할 이론적 기반이 부족하다. 기존 이론은 가중치가 동일한 희소 자동인코더에만 국한돼 SDL 전체를 포괄하지 못한다. 본 연구는 주요 SDL 변형을 하나의 조각별 이중볼록(biconvex) 최적화 문제로 통합하는 최초의 이론적 틀을 제시하고, 전역 해 집합, 비식별성, 그리고 허위 최적점들을 규명한다. 이 분석을 통해 특징 흡수와 죽은 뉴런 현상을 원리적으로 설명한다. 또한, 완전한 진실 데이터에 접근해 이러한 병리를 드러내는 Linear Representation Bench를 도입한다. 이론에 기반한 새로운 기법인 feature anchoring을 제안하여 SDL의 식별 가능성을 회복하고, 합성 벤치마크 전반에 걸쳐 특징 복구 성능을 크게 향상시킨다.💡 논문 핵심 해설 (Deep Analysis)
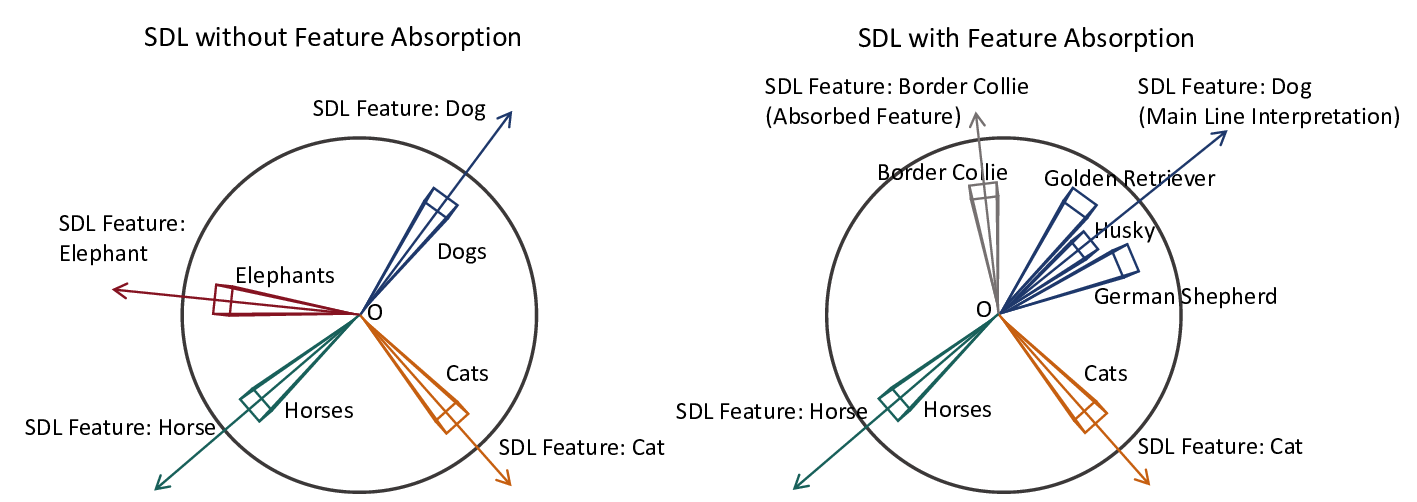
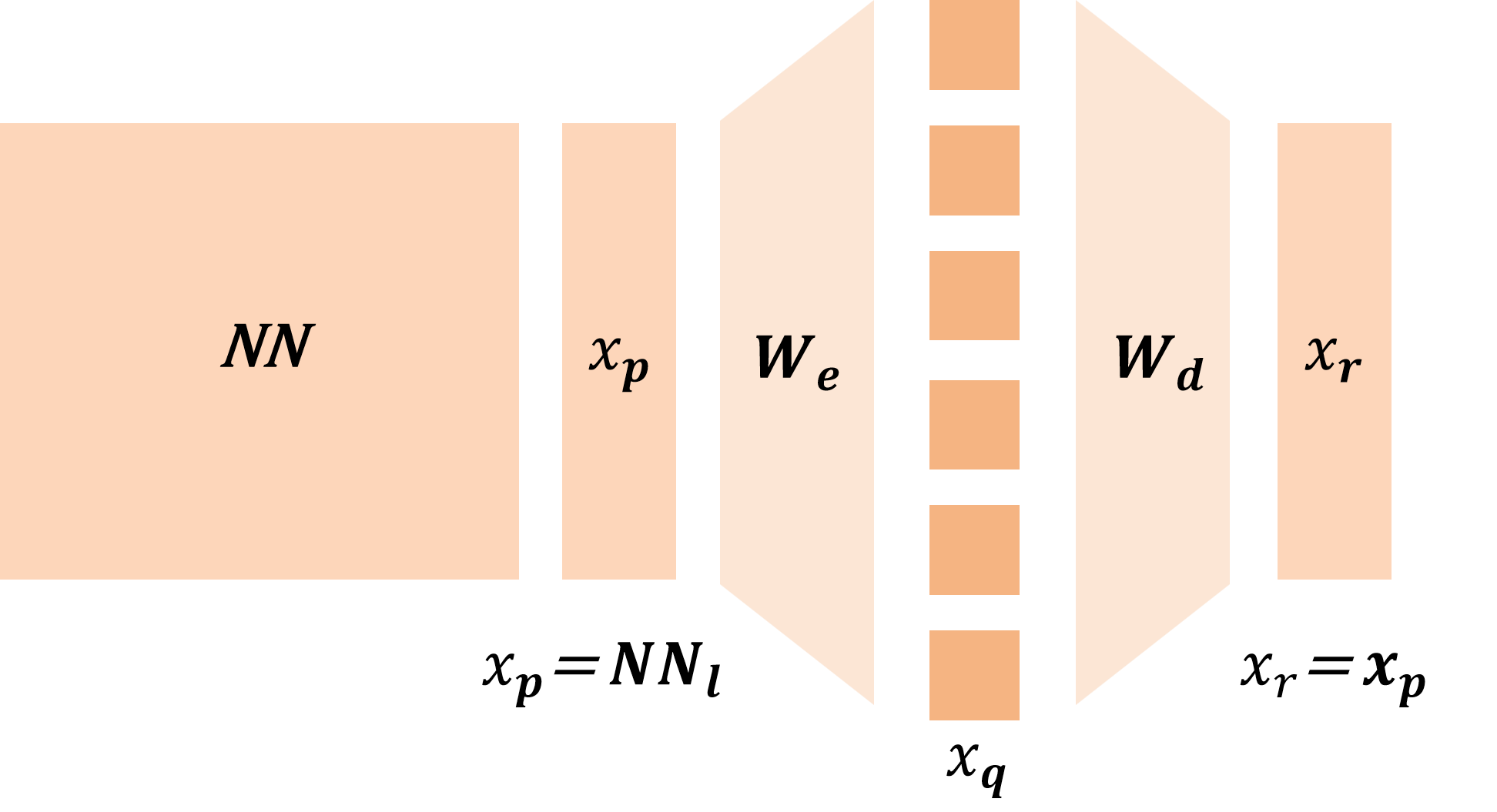
하지만 실제 실험에서는 기대와 달리 다중 의미(polysemantic) 특징이 여전히 나타나고, 일부 뉴런은 학습 과정에서 전혀 활성화되지 않는 ‘죽은 뉴런(dead neuron)’ 현상이 발생한다. 더 나아가, 이미 학습된 특징이 새로운 특징에 흡수되는 ‘특징 흡수(feature absorption)’ 현상도 관찰된다. 이러한 현상들은 현재까지 이론적으로 충분히 설명되지 못했으며, 기존의 이론적 분석은 가중치가 동일(tied-weight)인 희소 자동인코더에만 국한돼 SDL 전체를 포괄하지 못한다는 한계가 있다.
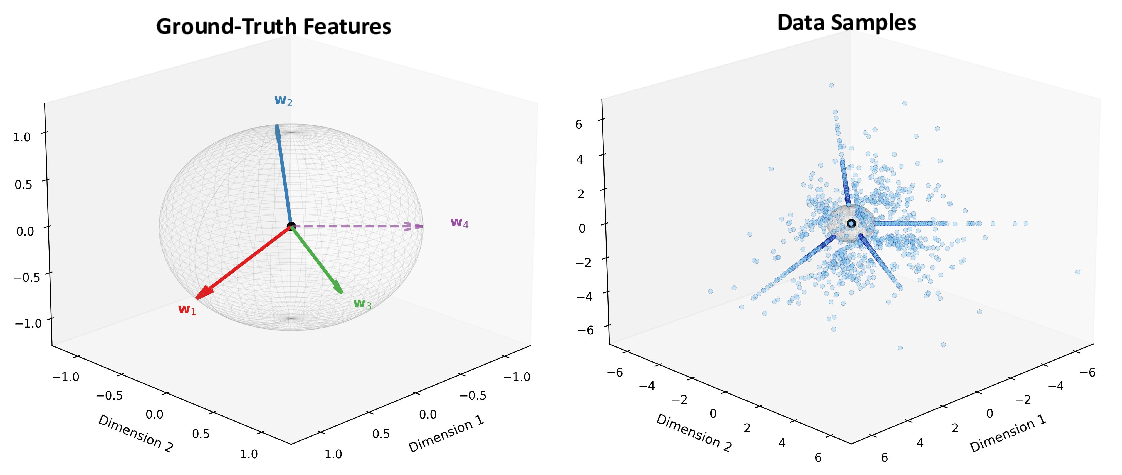
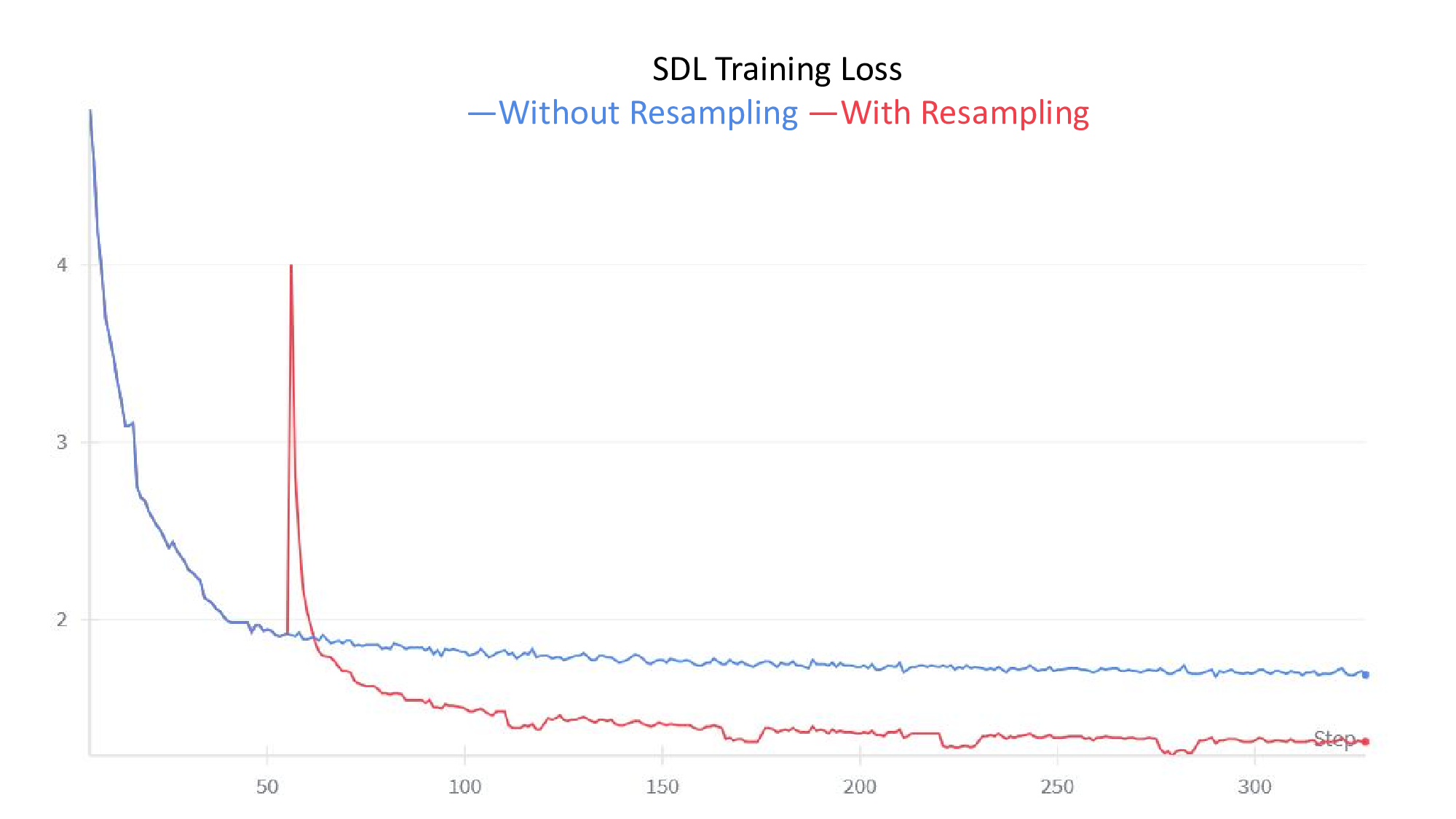
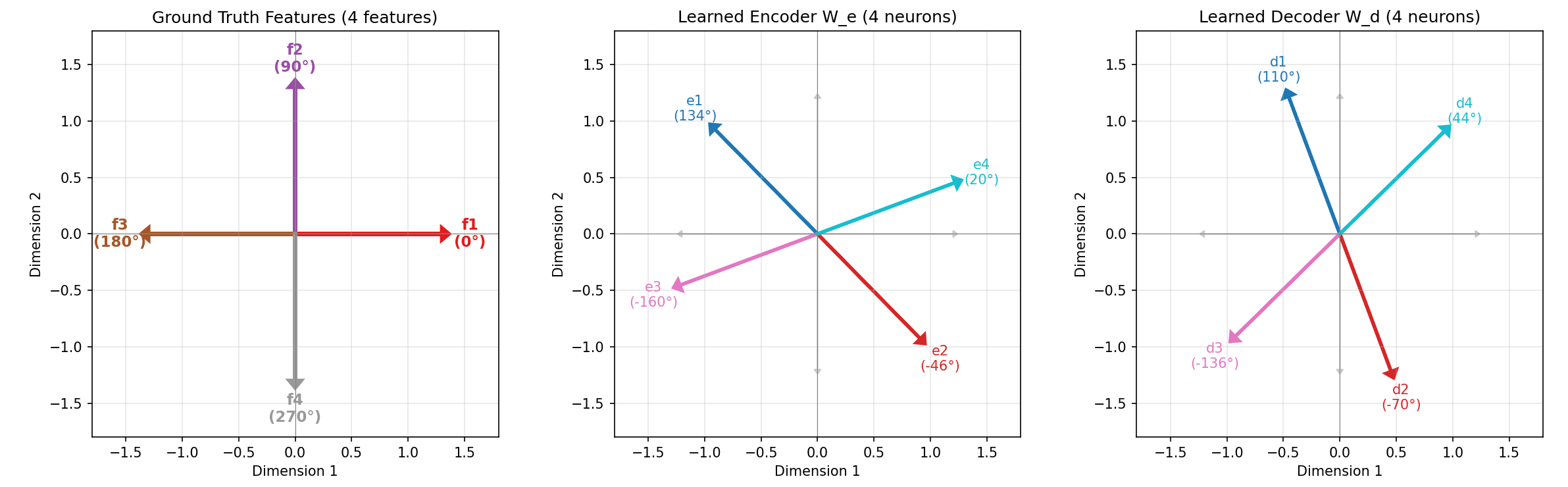
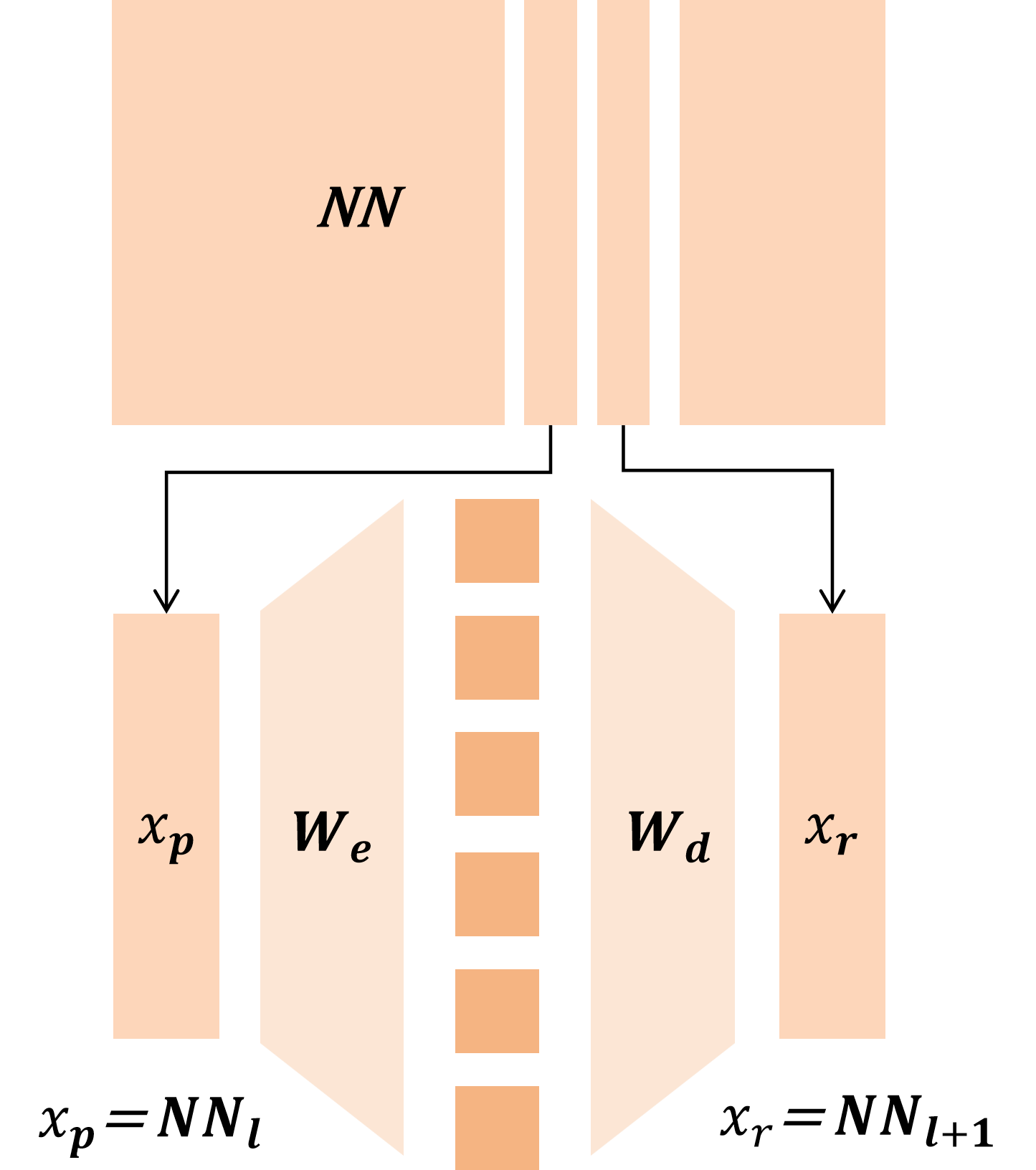
논문은 이러한 공백을 메우기 위해 모든 주요 SDL 변형을 하나의 ‘조각별 이중볼록(piecewise biconvex)’ 최적화 문제로 재구성한다. 이 수학적 프레임워크는 다음과 같은 중요한 결과를 도출한다. 첫째, 전역 최적해 집합이 어떻게 구성되는지 명시적으로 규명함으로써, 동일한 최적값을 갖는 여러 파라미터 조합이 존재할 수 있음을 보여준다(비식별성, non‑identifiability). 둘째, 최적화 과정에서 발생할 수 있는 허위 최적점(spurious optima)을 식별하고, 이들이 왜 특징 흡수와 죽은 뉴런을 초래하는지를 원리적으로 설명한다. 셋째, 이러한 이론적 통찰을 바탕으로 ‘Linear Representation Bench’를 설계하여, 완전한 진실(ground‑truth) 접근이 가능한 합성 데이터 환경에서 SDL의 병리를 체계적으로 드러낸다.
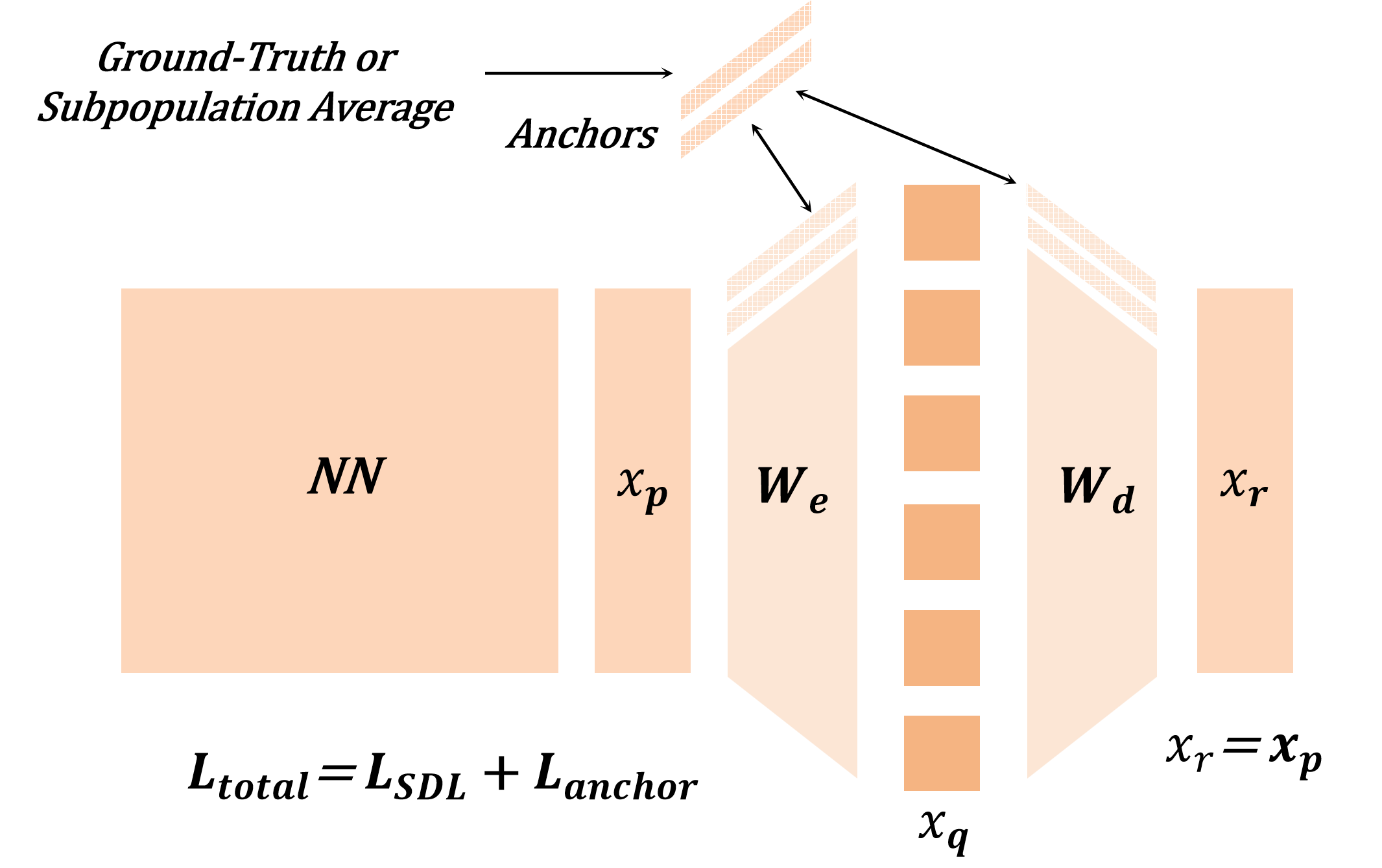
가장 혁신적인 기여는 ‘feature anchoring’이라는 새로운 기법이다. 이 방법은 사전 정의된 기준 특징을 학습 과정에 고정(anchor)함으로써, 파라미터 공간의 비식별성을 해소하고, 각 특징이 고유한 방향으로 수렴하도록 강제한다. 실험 결과, feature anchoring을 적용한 SDL은 기존 방법에 비해 합성 벤치마크에서 특징 복구 정확도가 크게 향상되었으며, 특히 다중 의미 특징과 죽은 뉴런 문제가 현저히 감소하였다.
이 연구는 SDL이 왜 기대한 대로 작동하지 않았는지에 대한 근본적인 원인을 제공하고, 기계적 해석 분야에서 보다 신뢰할 수 있는 도구를 구축하는 데 중요한 이정표가 된다. 앞으로의 연구는 이 이론을 실제 대규모 언어 모델이나 비전 모델에 적용하여, 복잡한 실세계 데이터에서도 동일한 식별 가능성과 해석 가능성을 확보하는 방향으로 확장될 수 있을 것이다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리