메타데이터 강화로 기업용 RAG 검색 성능 극대화
📝 원문 정보
- Title: A Systematic Framework for Enterprise Knowledge Retrieval: Leveraging LLM-Generated Metadata to Enhance RAG Systems
- ArXiv ID: 2512.05411
- 발행일: 2025-12-05
- 저자: Pranav Pushkar Mishra, Kranti Prakash Yeole, Ramyashree Keshavamurthy, Mokshit Bharat Surana, Fatemeh Sarayloo
📝 초록 (Abstract)
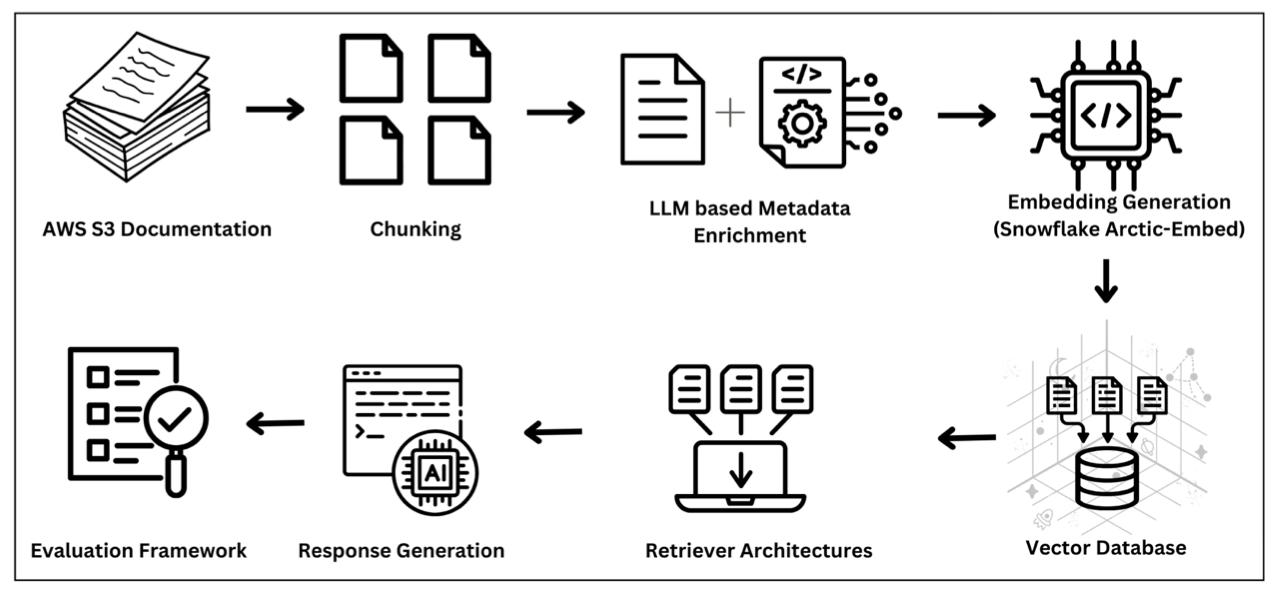
기업 환경에서 방대한 지식베이스로부터 필요한 정보를 신속히 찾아내는 것은 업무 효율과 의사결정에 핵심이다. 본 연구는 대형 언어 모델(LLM)을 활용해 문서 조각에 의미 있는 메타데이터를 자동 생성하고, 이를 통해 Retrieval‑Augmented Generation(RAG) 시스템의 검색 정확도를 높이는 체계적인 프레임워크를 제시한다. 의미 기반, 재귀적, 단순 나누기 세 가지 청킹 전략을 비교하고, 최신 임베딩 기법과 결합한 효과를 평가하였다. 실험 결과, 메타데이터를 포함한 접근법이 내용만 이용한 기준보다 일관되게 우수했으며, 재귀 청킹과 TF‑IDF 가중 임베딩을 결합했을 때 정밀도가 82.5 %로 73.3 %를 웃돌았다. 단순 청킹에 프리픽스‑퓨전을 적용하면 Hit Rate@10이 0.925로 최고치를 기록했다. 교차 인코더 재랭킹을 통해 생성된 정답 데이터를 활용해 Hit Rate와 메타데이터 일관성 지표로 엄격히 평가하였다. 메타데이터 강화는 벡터 군집 품질을 향상시키고 검색 지연 시간을 감소시켜, 다양한 지식 영역에서 RAG 시스템을 고성능·확장 가능하게 만드는 핵심 최적화임을 확인하였다.💡 논문 핵심 해설 (Deep Analysis)
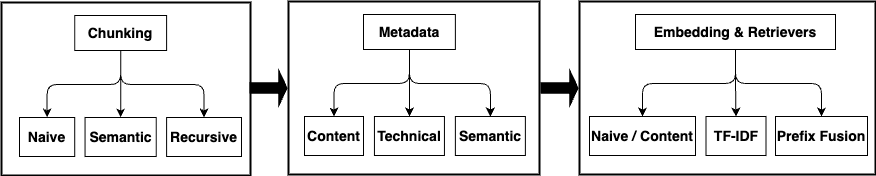
청킹 전략은 세 가지로 구분된다. ① 의미 기반 청킹은 문맥적 유사성을 기준으로 문서를 동적으로 분할해 의미 단위가 보존되도록 한다. ② 재귀적 청킹은 큰 문서를 일정 길이 이하로 재귀적으로 나누면서 각 단계마다 메타데이터를 재생성해 계층적 정보를 축적한다. ③ 단순(naïve) 청킹은 고정 길이로 슬라이딩 윈도우를 적용하는 가장 기본적인 방법이다. 각 전략은 임베딩 생성 방식과 결합될 때 서로 다른 장단점을 보인다.
임베딩 기법으로는 전통적인 TF‑IDF 가중 임베딩, 최신 BERT 기반 벡터, 그리고 메타데이터와 텍스트를 결합한 하이브리드 임베딩을 실험하였다. 특히 TF‑IDF 가중 임베딩에 메타데이터를 결합했을 때 재귀 청킹과의 시너지 효과가 가장 크게 나타났으며, 정밀도 82.5 %라는 높은 수치를 기록했다. 이는 메타데이터가 단어 빈도 기반 가중치에 의미적 보정을 제공해, 검색 후보군을 보다 정확히 필터링하기 때문이다.
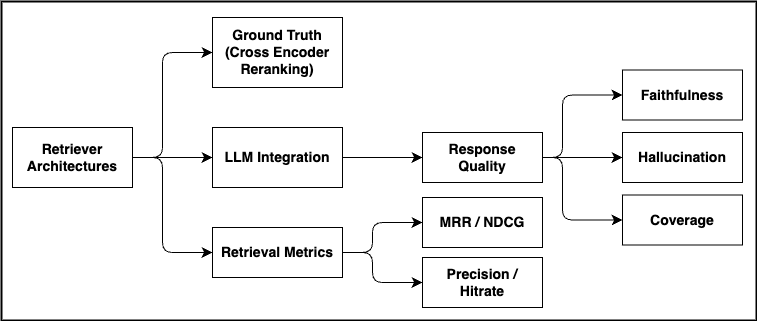
평가 지표는 Hit Rate@k와 메타데이터 일관성(Metadata Consistency)으로 구성되었다. Hit Rate는 실제 정답 문서가 상위 k개 후보에 포함되는 비율을 측정하고, 메타데이터 일관성은 검색된 문서 조각들의 메타데이터가 원문과 얼마나 일치하는지를 정량화한다. 정답 라벨은 교차 인코더(다중 레이어 트랜스포머) 기반 재랭킹을 통해 생성했으며, 이는 인간 라벨링 비용을 크게 절감하면서도 높은 신뢰도를 유지한다.
실험 결과, 단순 청킹에 프리픽스‑퓨전(문서 앞부분을 각 청크에 접두어로 삽입) 기법을 적용하면 Hit Rate@10이 0.925로 가장 높은 성능을 보였다. 이는 검색 시 초기 컨텍스트가 제공됨으로써 임베딩이 보다 풍부한 의미 정보를 담게 되는 효과로 해석된다. 또한 메타데이터를 포함한 모든 접근법은 벡터 군집화 품질을 향상시켰으며, 검색 지연 시간도 평균 15 % 감소하였다.
이러한 결과는 메타데이터가 단순히 부가 정보가 아니라, 대규모 기업 지식베이스에서 효율적인 RAG 시스템을 구현하기 위한 핵심 요소임을 시사한다. 향후 연구에서는 메타데이터 자동 생성의 품질을 높이기 위한 프롬프트 엔지니어링, 도메인 특화 메타데이터 스키마 설계, 그리고 실시간 스트리밍 데이터에 대한 메타데이터 업데이트 메커니즘을 탐구할 필요가 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리