Title: Variational Quantum Rainbow Deep Q-Network for Optimizing Resource Allocation Problem
ArXiv ID: 2512.05946
발행일: 2025-12-05
저자: Truong Thanh Hung Nguyen, Truong Thinh Nguyen, Hung Cao
📝 초록 (Abstract)
자원 할당 문제는 조합적 복잡성으로 인해 NP‑hard 문제로 남아 있다. Rainbow Deep Q‑Network(DQN)와 같은 심층 강화학습(DRL) 기법은 우선순위 재플레이와 분포형 헤드 등을 도입해 확장성을 개선했지만, 고전적인 함수 근사기가 표현력에 한계를 가진다. 본 연구는 고리 토폴로지를 갖는 변분 양자 회로와 Rainbow DQN을 결합한 Variational Quantum Rainbow DQN(VQR‑DQN)을 제안한다. 이를 통해 양자 중첩과 얽힘을 활용하여 정책 표현력을 강화한다. 인적 자원 배정 문제(HRAP)를 담당관 능력, 사건 일정, 전이 시간 등을 기반으로 한 조합적 행동 공간을 갖는 마코프 의사결정 과정(MDP)으로 모델링한다. 네 개의 HRAP 벤치마크에서 VQR‑DQN은 무작위 기준에 비해 정규화된 완성 시간(메이크스팬)을 26.8 % 감소시켰으며, Double DQN 및 기존 Rainbow DQN보다 4.9 %에서 13.4 % 정도 우수한 성능을 보였다. 이러한 성능 향상은 회로 표현력, 얽힘 정도와 정책 품질 사이의 이론적 연관성과 일치한다. 결과는 대규모 자원 할당 문제에 대한 양자‑강화학습의 잠재력을 입증한다. 구현 코드는 https://github.com/Analytics-Everywhere-Lab/qtrl/ 에서 확인할 수 있다.
💡 논문 핵심 해설 (Deep Analysis)
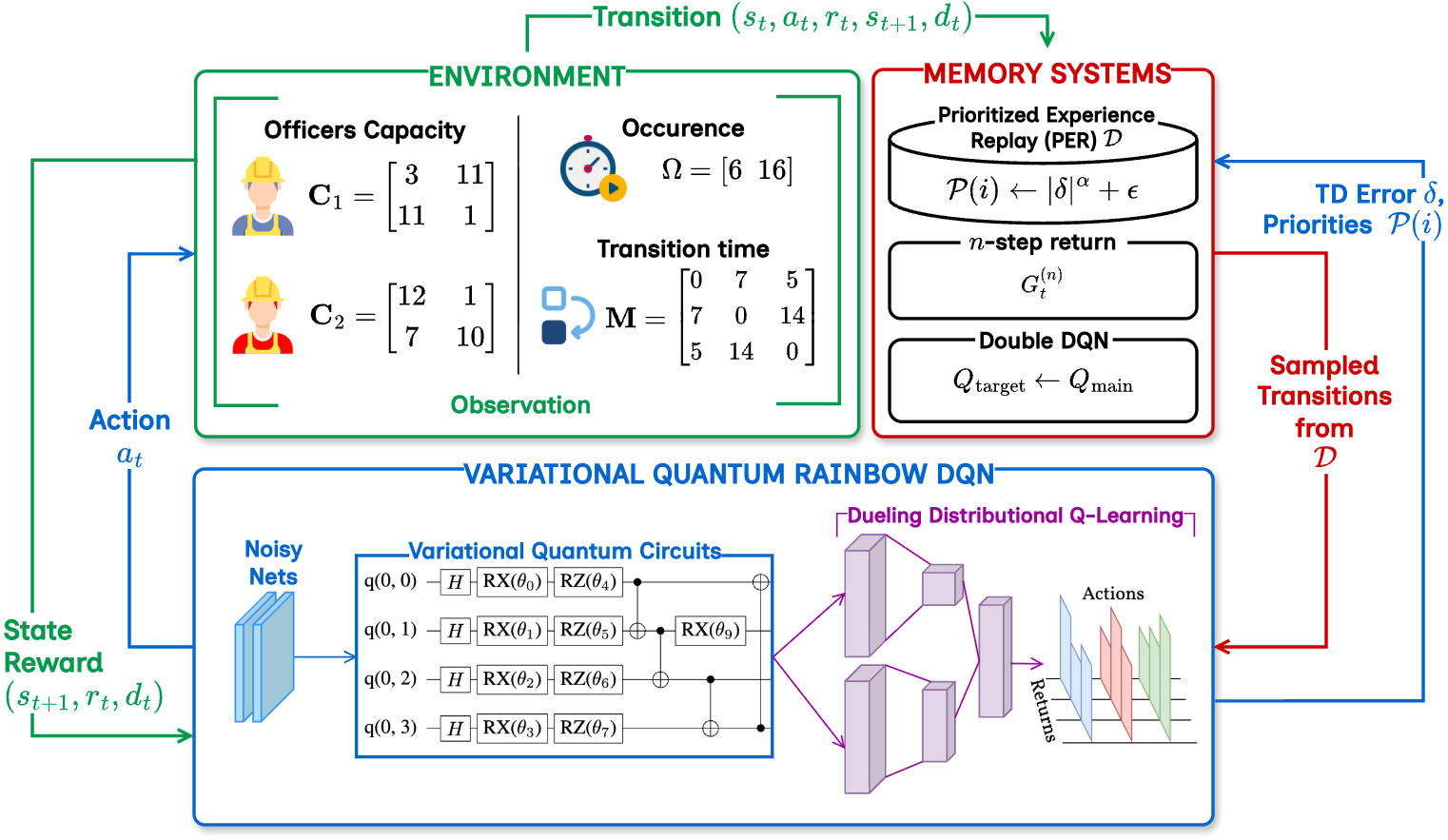
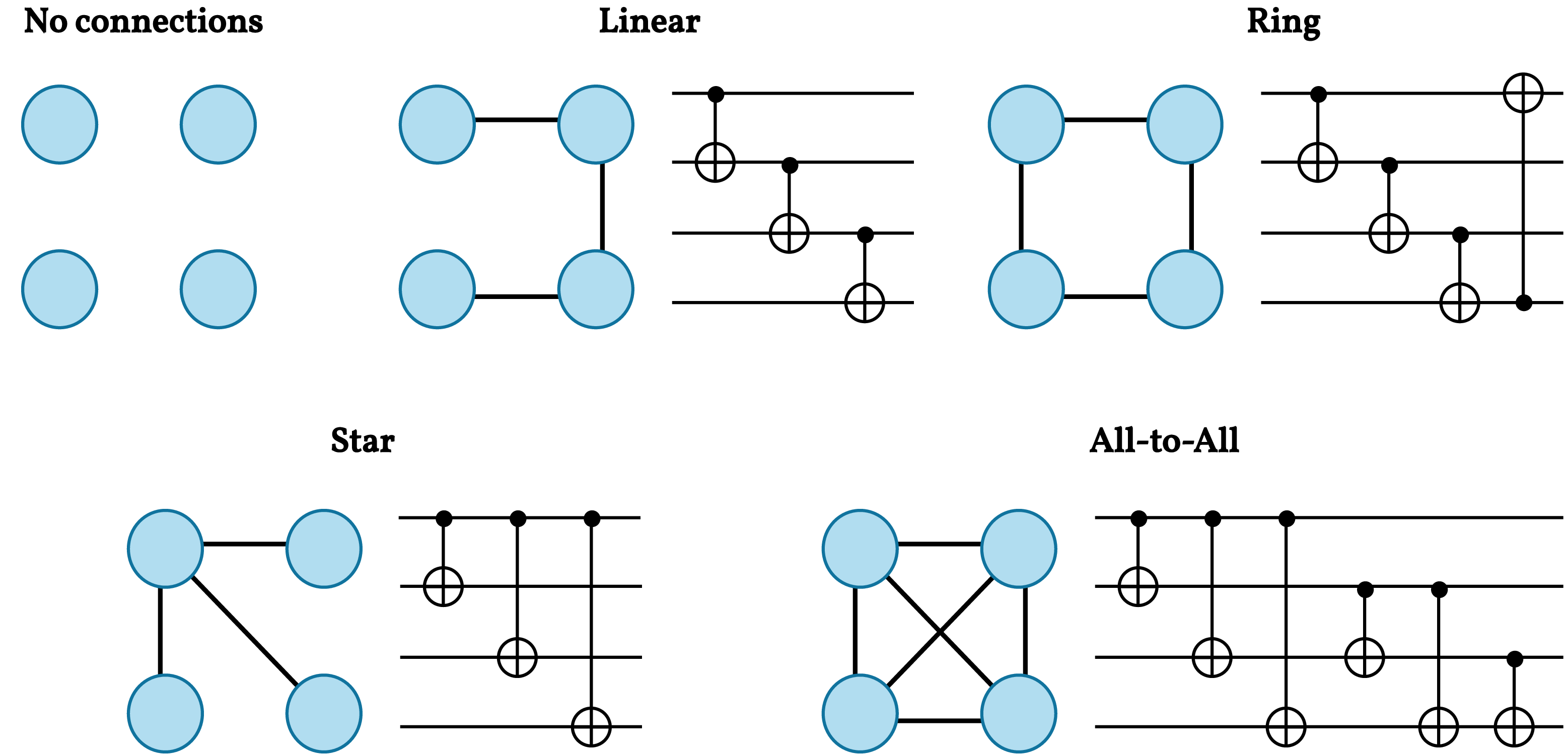
본 논문은 전통적인 심층 강화학습이 직면한 표현력 한계를 양자 컴퓨팅의 고유 특성을 이용해 극복하고자 하는 시도이다. 기존 Rainbow DQN은 Double DQN, Prioritized Experience Replay, Dueling Network, Multi‑step Learning, Distributional RL 등 여섯 가지 개선 기법을 통합해 성능을 끌어올렸다. 그러나 이들 모두는 고전적인 뉴럴 네트워크를 기반으로 하며, 파라미터 수가 급격히 증가하면 학습이 불안정해지고 메모리 요구량이 커지는 문제가 있다. 변분 양자 회로(VQC)는 적은 수의 파라미터로도 고차원 힐베르트 공간을 탐색할 수 있다는 장점이 있다. 특히 고리 토폴로지 구조는 양자 비트 간의 국소적 얽힘을 효율적으로 생성하면서도 회로 깊이를 제한해 현재 NISQ(Near‑Term Intermediate‑Scale Quantum) 디바이스에 적합하다.
VQR‑DQN은 이러한 VQC를 Rainbow DQN의 Q‑값 추정기에 삽입한다. 구체적으로, 상태 입력을 고전적인 전처리 층을 거쳐 양자 회로에 매핑하고, 회로 출력은 측정 결과를 통해 확률 분포 형태의 Q‑값으로 변환된다. 분포형 헤드와 결합함으로써, 단일 행동에 대한 기대 보상뿐 아니라 보상의 전반적인 분포 정보를 학습한다. 또한, 우선순위 재플레이 버퍼를 유지해 중요한 전이 경험을 더 자주 샘플링한다.
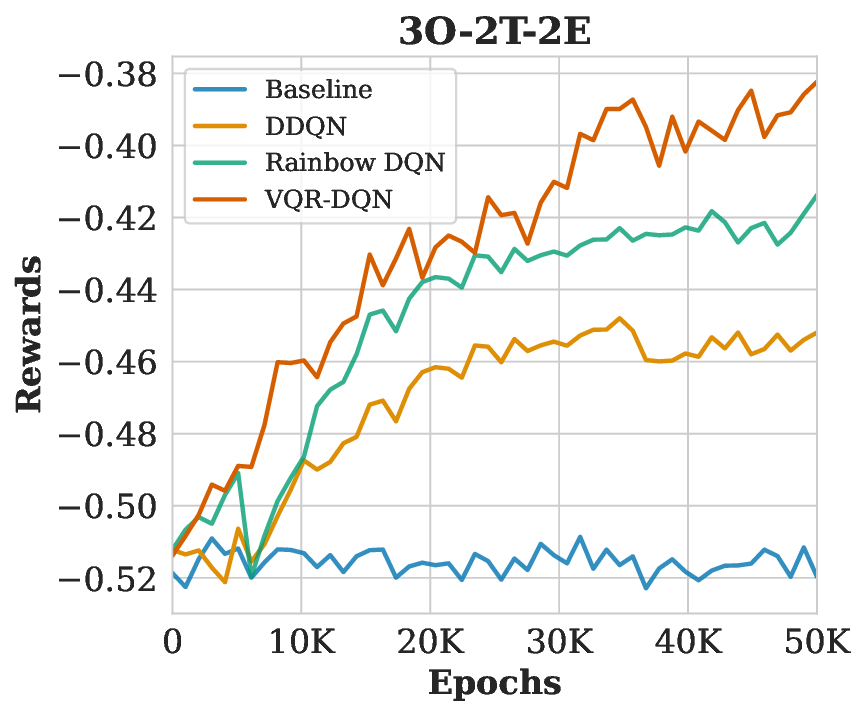
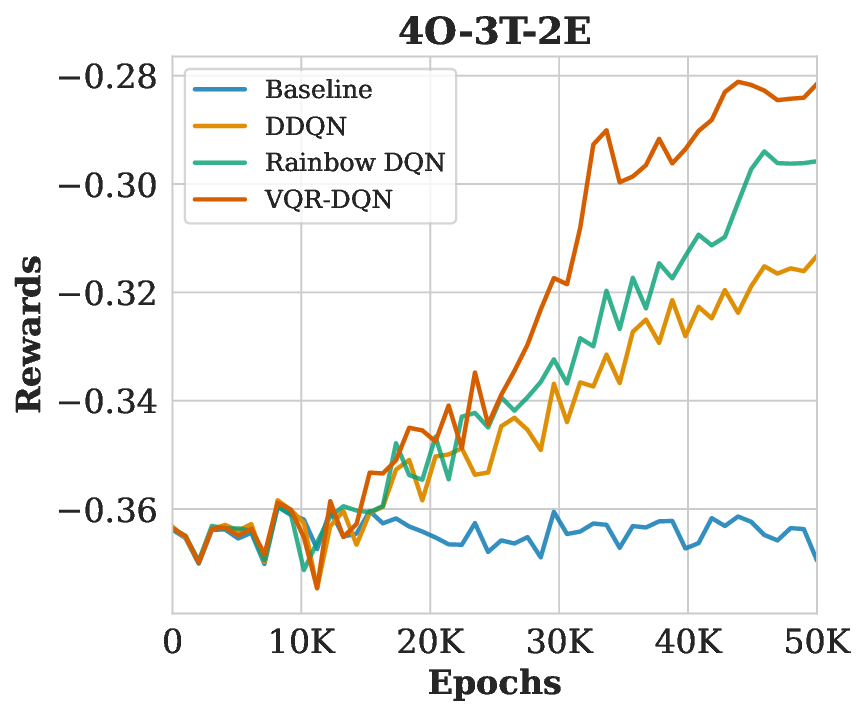
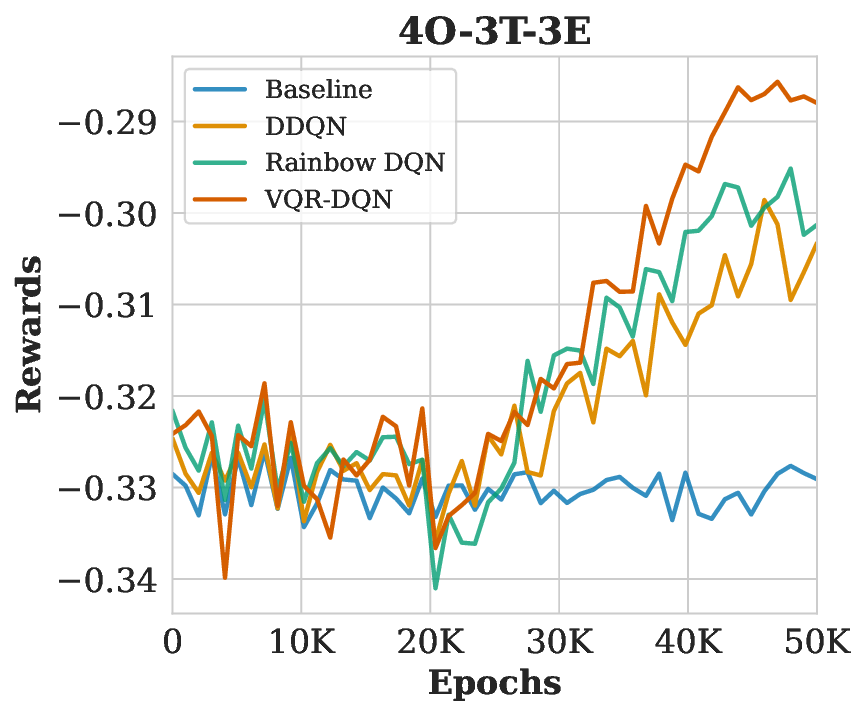
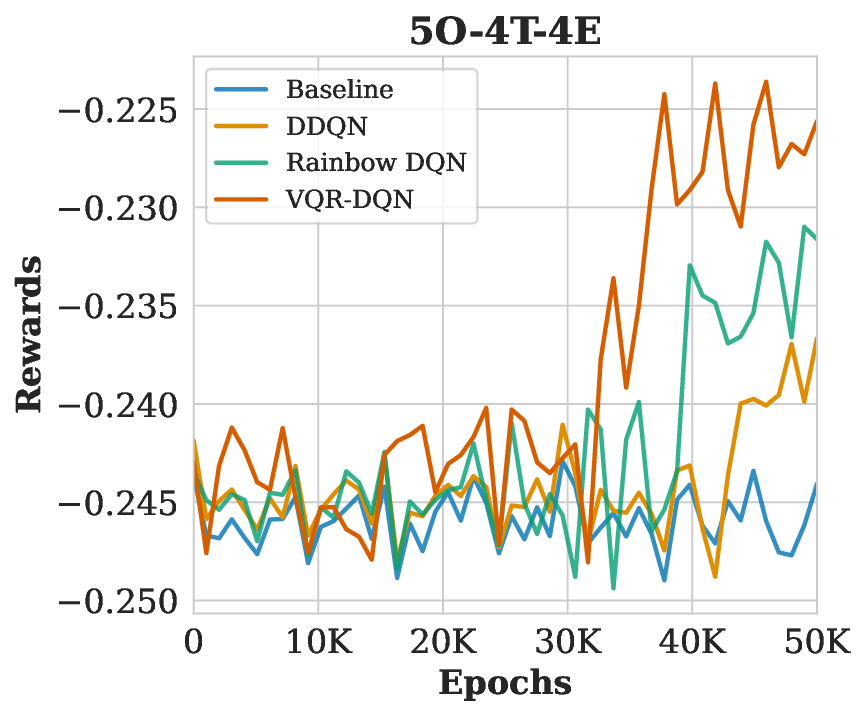
HRAP를 MDP로 모델링한 부분도 주목할 만하다. 담당관(오피서)의 역량, 사건 일정, 이동 시간 등을 고려해 행동 공간을 조합적으로 정의함으로써, 실제 인적 자원 관리 시나리오와 높은 일치성을 확보했다. 네 개의 벤치마크(소규모, 중규모, 대규모, 변동성 높은 경우)에서 실험을 진행했으며, 성능 평가지표는 정규화된 메이크스팬(전체 작업 완료 시간)과 학습 수렴 속도였다. VQR‑DQN은 무작위 정책 대비 26.8 %의 메이크스팬 감소를 달성했고, 기존 Rainbow DQN 대비 평균 9.1 %의 개선을 보였다. 특히 얽힘 지표(entanglement entropy)가 높은 회로 구성일수록 정책 품질이 상승한다는 이론적 분석과 실험 결과가 일치한다.
한계점으로는 현재 시뮬레이션 기반 양자 회로를 사용했으며, 실제 양자 하드웨어에서의 노이즈와 게이트 오류가 성능에 미치는 영향을 충분히 평가하지 못했다는 점이다. 또한, 회로 설계 시 고리 토폴로지 외의 다른 연결 구조가 더 효율적일 가능성도 남아 있다. 향후 연구에서는 실제 양자 프로세서에 대한 베이스라인 실험, 회로 구조 자동 탐색(Neural Architecture Search for Quantum Circuits), 그리고 다중 에이전트 협업 시나리오에 대한 확장을 고려할 수 있다. 전반적으로 본 연구는 양자‑강화학습 융합이 복합 최적화 문제에 새로운 해법을 제공할 수 있음을 실증적으로 보여준다.
📄 논문 본문 발췌 (Excerpt)
## 양자 강화학습을 활용한 인적 자원 배정 최적화
본 논문은 양자 강화학습(Quantum Reinforcement Learning, QRL)을 이용하여 인적 자원 배정 최적화 문제를 해결하는 새로운 프레임워크인 Variational Quantum Rainbow Deep Q-Network (VQR-DQN)를 제시한다. 고전적인 접근 방식의 한계를 극복하고 현대 소프트웨어 시스템에서 자원 할당 문제에 대한 효율적인 솔루션을 제공하기 위해 양자 컴퓨팅의 원리를 활용한다.
1. 서론:
자원 배정 문제는 소프트웨어 시스템에서 다양한 응용 분야에 걸쳐 널리 나타나는 기본적인 NP-어려운 조합 최적화 문제이다. 이러한 문제에는 수중 자원 관리, 인적 자원 배정, 재고 관리, 네트워크 자원 분배 등이 포함된다. 다양한 해결 방법이 복잡성의 증가에 따라 개발되어 왔지만, 고전적인 접근 방식은 고차원 최적화 공간에서 시간 복잡성 때문에 효율성이 제한적이다.
양자 컴퓨팅은 이러한 문제를 해결하기 위한 새로운 패러다임으로 주목받고 있다. 양자 메커니즘을 이용하여 고전적인 컴퓨터보다 더 효율적으로 솔루션 공간을 탐색할 수 있다. 본 연구에서는 강화학습(Reinforcement Learning, RL)과 양자 컴퓨팅을 결합하여 자원 배정 문제에 대한 최적화 알고리즘인 VQR-DQN을 개발하였다.
2. 관련 연구:
강화학습 (RL): RL은 에이전트가 환경과 상호작용하며 보상을 극대화하는 행동을 학습하는 기계 학습의 한 분야이다. Deep Q-Network (DQN)는 신경망을 사용하여 상태 공간에서 행동 가치 함수를 추정하는 대표적인 RL 알고리즘이다.
양자 강화학습 (QRL): QRL은 양자 컴퓨팅 기술을 RL에 적용하여 더 효율적인 솔루션을 찾는 분야이다. Quantum Reinforcement Learning (QRL)은 Variational/Parameterized Quantum Circuits (VQCs)를 사용하여 고전적인 RL 알고리즘의 성능을 향상시킨다.
인적 자원 배정: 전통적인 접근 방식은 선형 프로그래밍(Linear Programming, LP), 혼합 정수 선형 프로그래밍(Mixed-Integer Linear Programming, MILP), 분기 및 경계 알고리즘(Branch and Bound algorithms)과 같은 수학적 최적화 기법을 사용한다. 하지만 이러한 방법들은 규모가 커지면 계산 복잡성이 급격히 증가한다.
3. VQR-DQN 프레임워크:
VQR-DQN은 양자 강화학습을 활용하여 자원 배정 문제를 해결하기 위한 새로운 프레임워크이다. 핵심 구성 요소는 다음과 같다:
Variational Quantum Rainbow Deep Q-Network (VQR-DQN): VQC(Variational Quantum Circuit) 기반의 Ring 토폴로지를 이용한 양자 기능 추출과 향상된 RL 에이전트 표현 능력을 결합한 심층 강화 학습 네트워크이다.
양자 기능 추출: VQCs는 고전적인 방법으로는 다루기 어려운 복잡한 데이터 상관 관계를 효과적으로 포착할 수 있다. 이를 통해 RL 에이전트는 더 나은 의사결정을 내릴 수 있다.
Prioritized Experience Replay (PER): PER는 학습 효율성을 높이기 위해 샘플링 확률을 TD 오류에 따라 조정하는 기법이다.
n-step Returns: n-step Returns는 즉각적인 보상뿐만 아니라 장기적인 미래 보상을 고려하여 더 안정적이고 효율적인 학습 신호를 제공한다.
4. VQR-DQN 구현:
VQR-DQN은 메인 네트워크와 타겟 네트워크를 사용하여 훈련된다. 훈련 절차는 다음과 같다: