Title: Quantifying Memory Use in Reinforcement Learning with Temporal Range
ArXiv ID: 2512.06204
발행일: 2025-12-05
저자: Rodney Lafuente-Mercado, Daniela Rus, T. Konstantin Rusch
📝 초록 (Abstract)
훈련된 강화학습(RL) 정책이 과거 관측을 실제로 얼마나 활용하는지를 묻는다. 우리는 Temporal Range라는 모델에 독립적인 지표를 제안한다. 이 지표는 시간 창 전체에 걸친 다중 벡터 출력에 대한 1차 민감도를 입력 시퀀스에 대한 시간적 영향 프로파일로 취급하고, 크기 가중 평균 지연으로 요약한다. Temporal Range는 최종 타임스텝 s∈{t+1,…,T}에 대한 Jacobian 블록 ∂y_s/∂x_t ∈ℝ^{c×d}를 역전파 자동 미분으로 평균내어 계산한다. 선형 경우에는 몇 가지 자연스러운 공리로 잘 특성화된다. 진단·제어 과제(POPGym, 깜박임/가림, Copy‑k)와 다양한 아키텍처(MLP, RNN, SSM)에서 Temporal Range는 (i) 완전 관측 제어에서는 작게 유지되고, (ii) Copy‑k 과제에서는 실제 지연에 비례하며, (iii) 근접 최적 수익을 위한 최소 히스토리 창과 일치함을 윈도우 절삭 실험으로 확인한다. 또한 우리는 Compact Long Expressive Memory(LEM) 정책에 대해 Temporal Range를 보고, 이를 과제 수준 메모리의 프록시 읽기로 활용한다. 우리의 공리적 접근은 최근 범위 측정 연구를 기반으로 하며, 이를 시간 지연에 특화하고 RL 환경의 벡터 출력에 확장한다. 따라서 Temporal Range는 에이전트와 환경 간 메모리 의존성을 비교하고, 충분히 짧은 컨텍스트를 선택하는 실용적인 시퀀스별 지표를 제공한다.
💡 논문 핵심 해설 (Deep Analysis)
Temporal Range는 강화학습 에이전트가 과거 관측을 얼마나 활용하는지를 정량화하려는 시도에서 출발한다. 기존 연구에서는 정책 네트워크의 구조적 메모리 용량(예: RNN의 hidden size)이나 훈련된 모델의 성능을 통해 간접적으로 추정했지만, 실제 입력‑출력 관계가 어느 시점까지 영향을 미치는지는 명확히 드러나지 않았다. 이 논문은 그런 공백을 메우기 위해 “시간적 영향 프로파일”이라는 개념을 도입한다. 구체적으로, 시점 t 에서 입력 x_t 가 이후 시점 s ( t < s ≤ T )의 출력 y_s 에 미치는 1차 민감도, 즉 Jacobian ∂y_s/∂x_t 를 계산한다. 이 Jacobian은 c × d 차원의 행렬이며, 여기서 c 는 출력 차원, d 는 입력 차원이다. 모든 s 에 대해 평균을 취하면 시점 t 에 대한 전체 영향 강도가 얻어지고, 이를 시간 지연 lag 에 가중치로 곱해 평균하면 “Magnitude‑Weighted Average Lag”, 즉 Temporal Range가 산출된다.
계산상의 핵심은 역전파 자동 미분(reverse‑mode AD)이다. 일반적인 딥러닝 프레임워크는 손실에 대한 파라미터 그라디언트를 효율적으로 구하지만, 여기서는 손실 대신 각 y_s 에 대한 x_t 의 미분을 직접 추출한다. 이는 메모리와 연산량이 O(T²)로 늘어날 위험이 있지만, 논문에서는 블록‑단위 평균과 샘플링 전략을 통해 실용적인 비용으로 구현한다. 또한 선형 시스템에 대해서는 몇 가지 직관적인 공리—(1) 비음성성, (2) 시간 이동 불변성, (3) 합성 가능성—를 만족함을 증명함으로써 메트릭의 정당성을 확보한다.
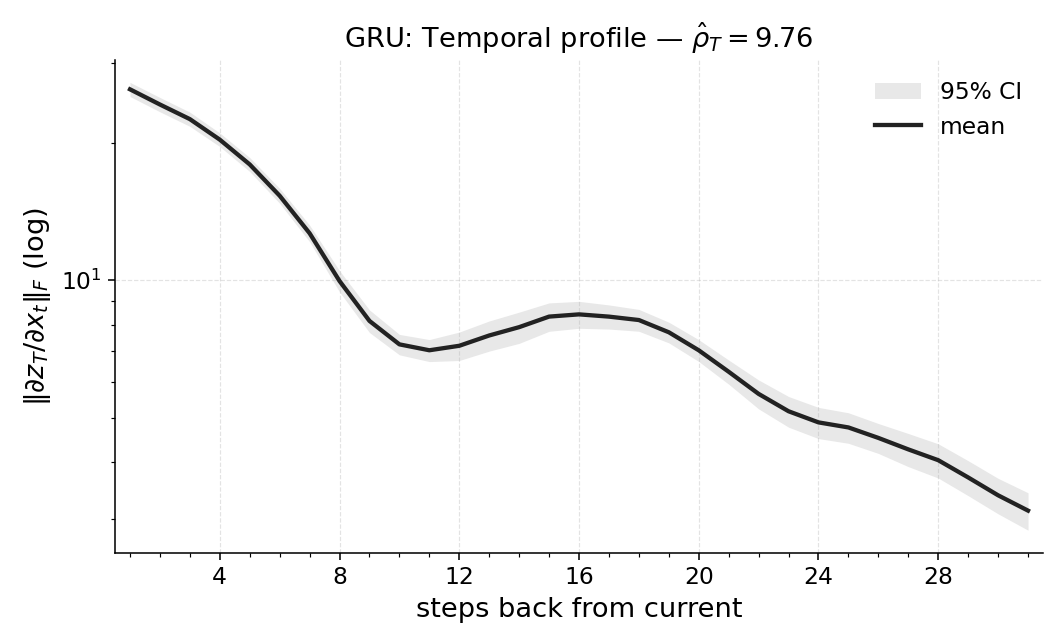
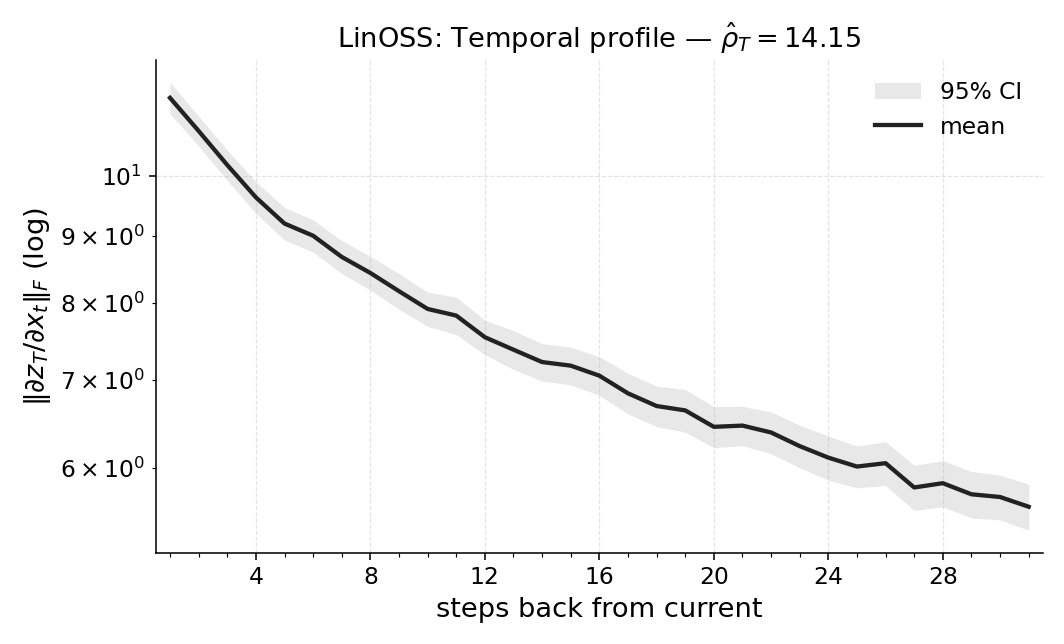
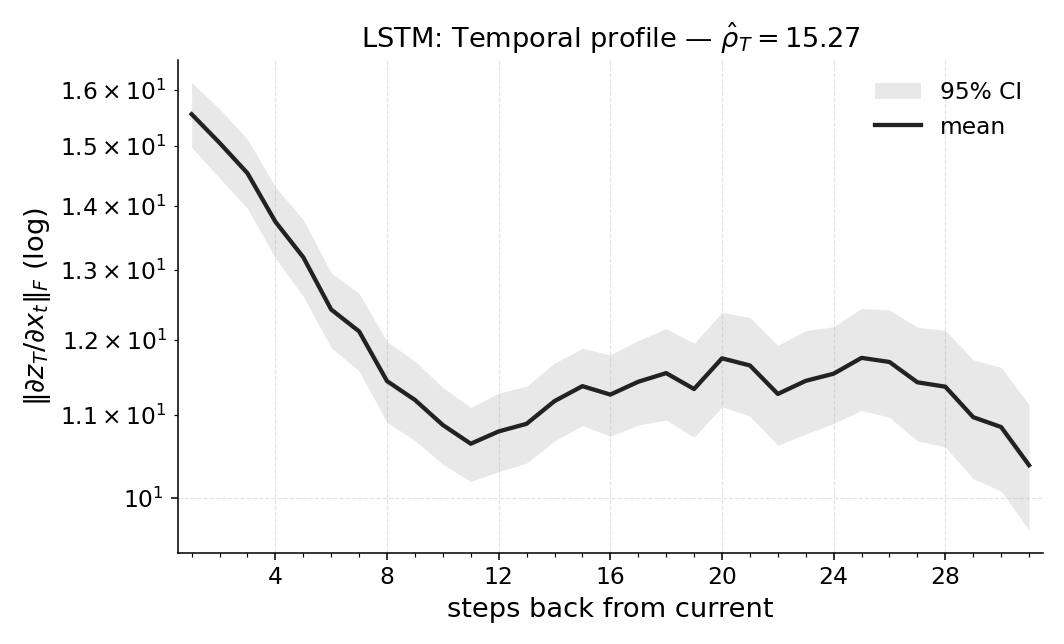
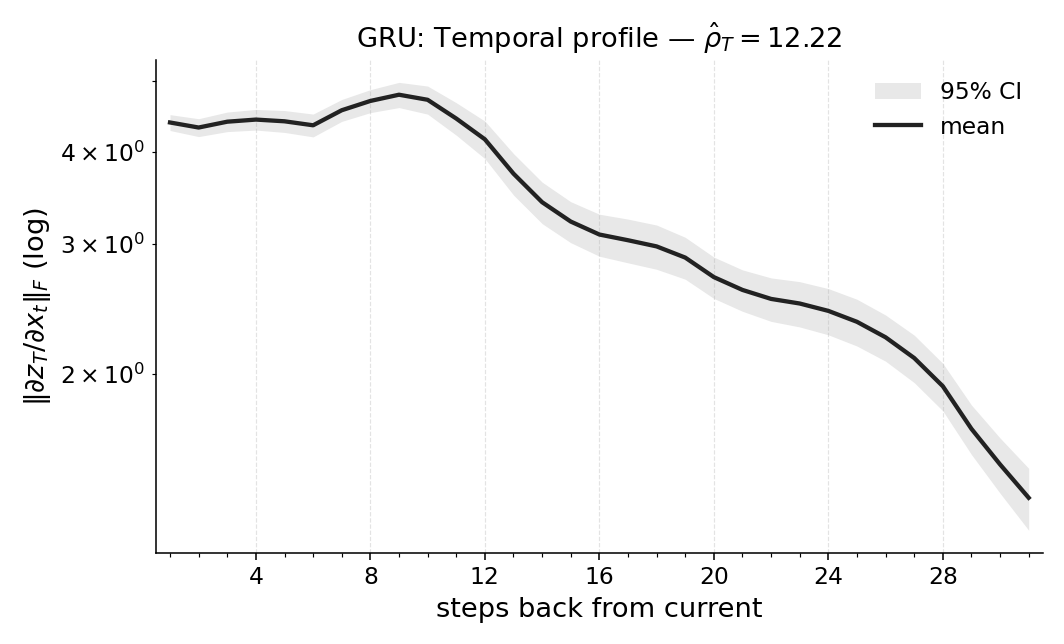
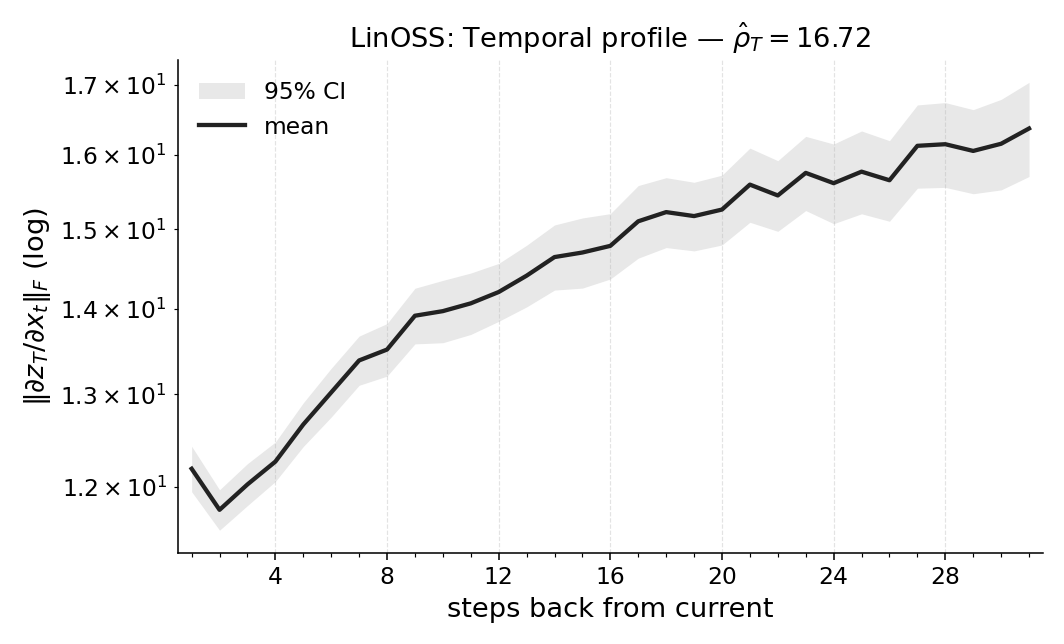
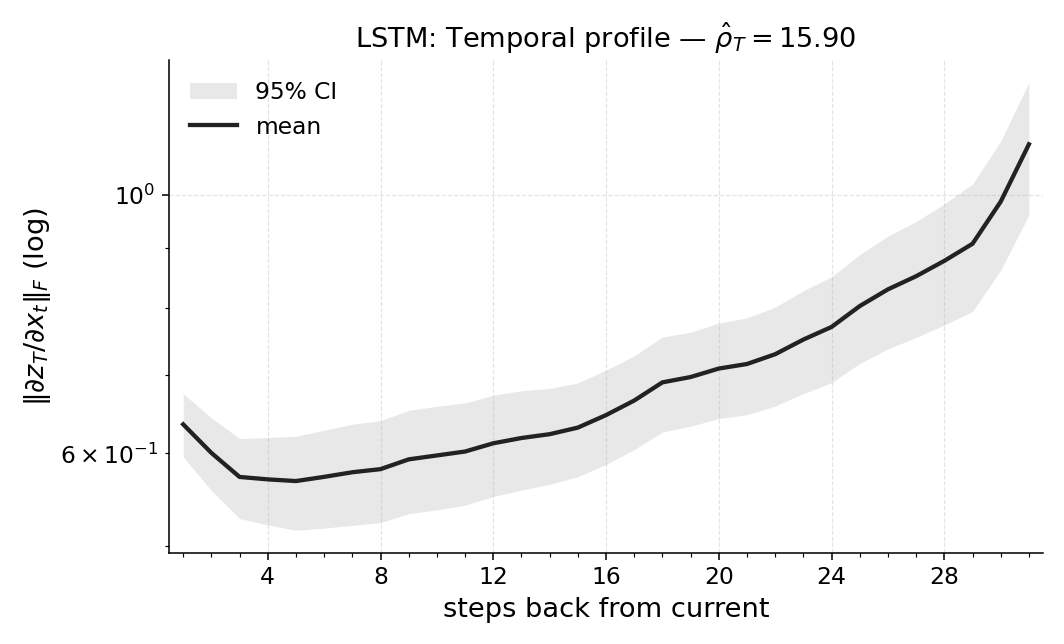
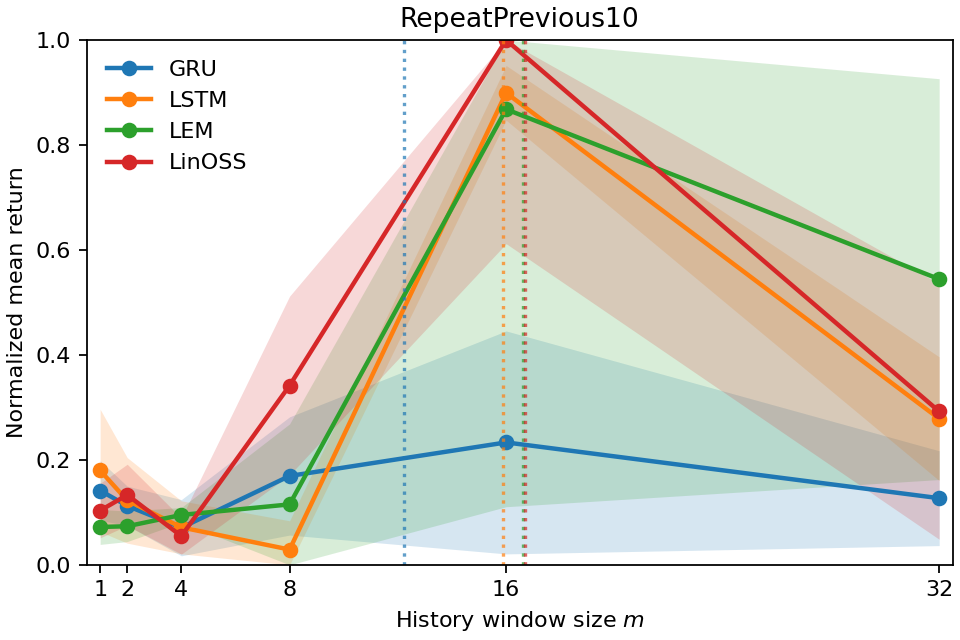
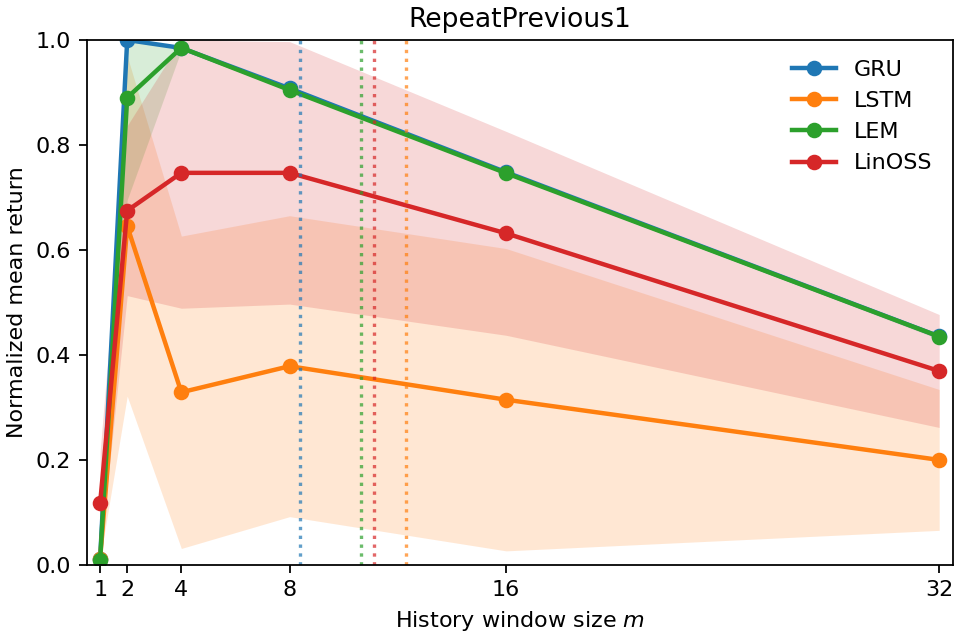
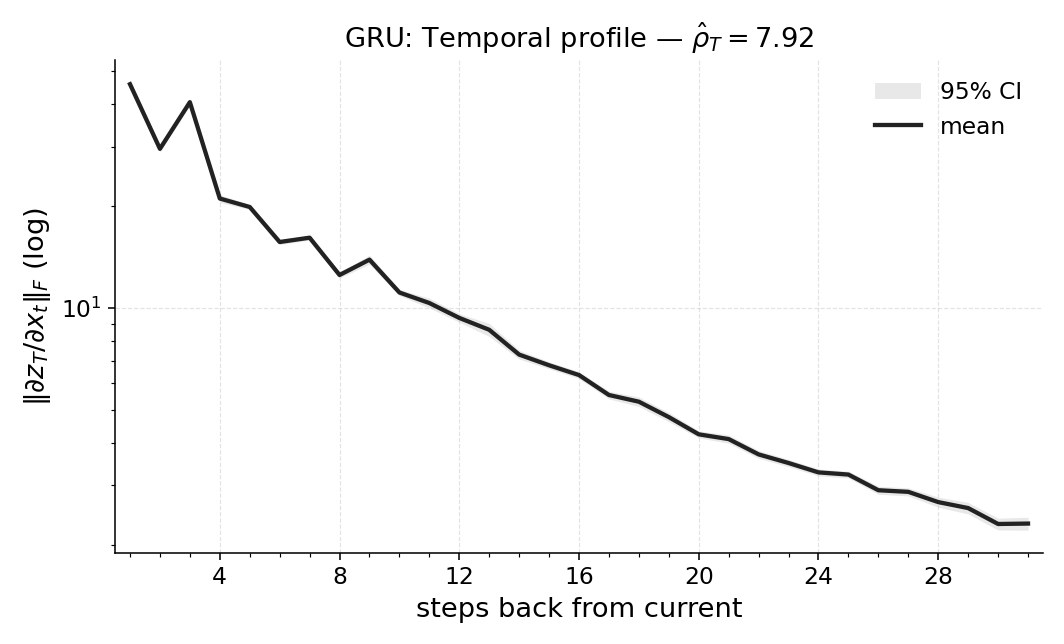
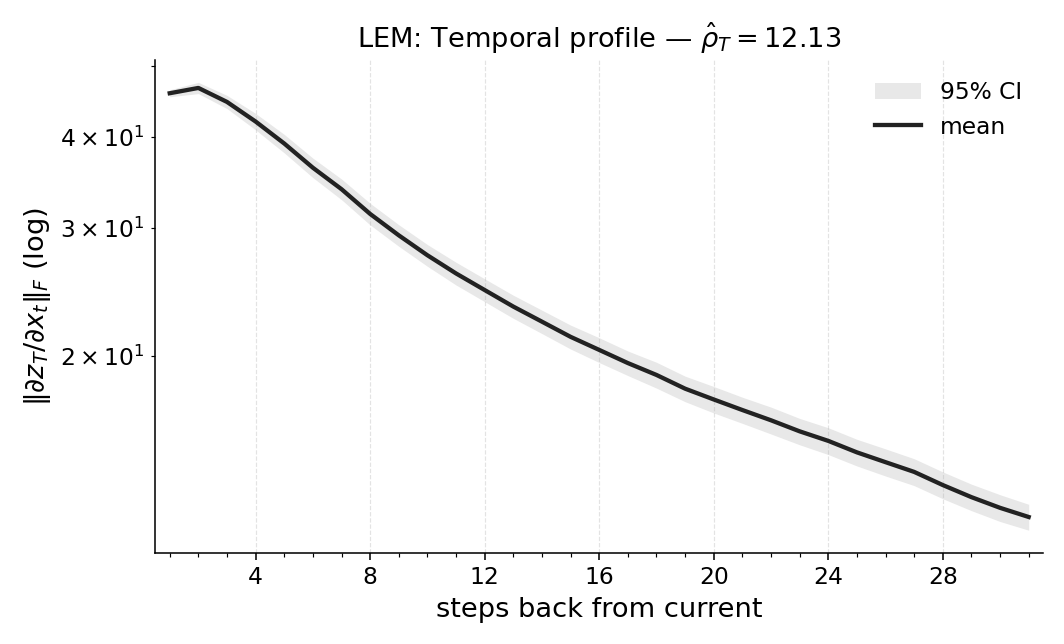
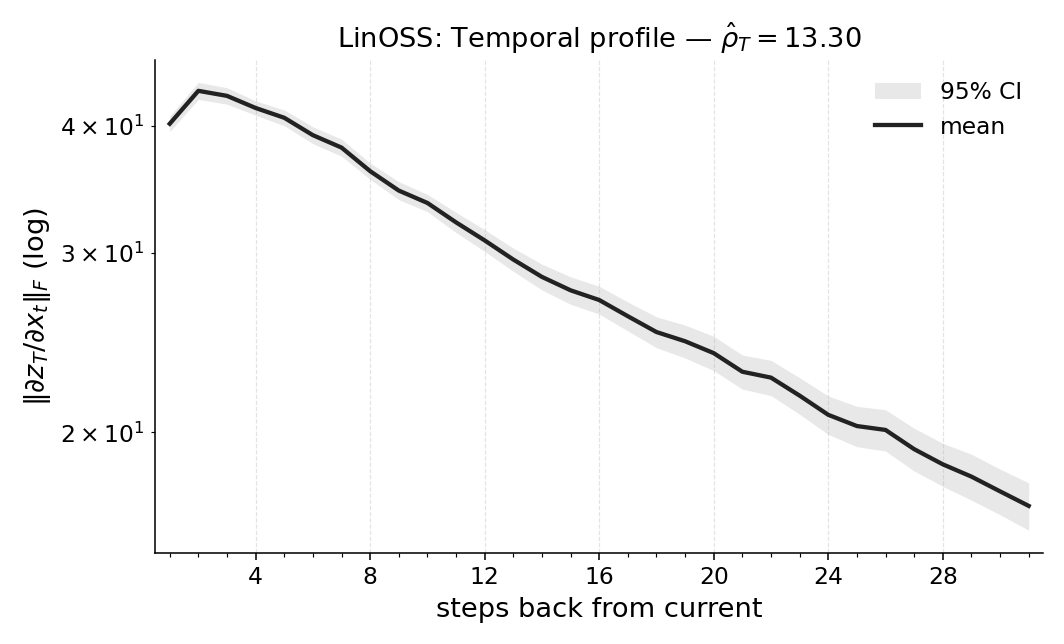
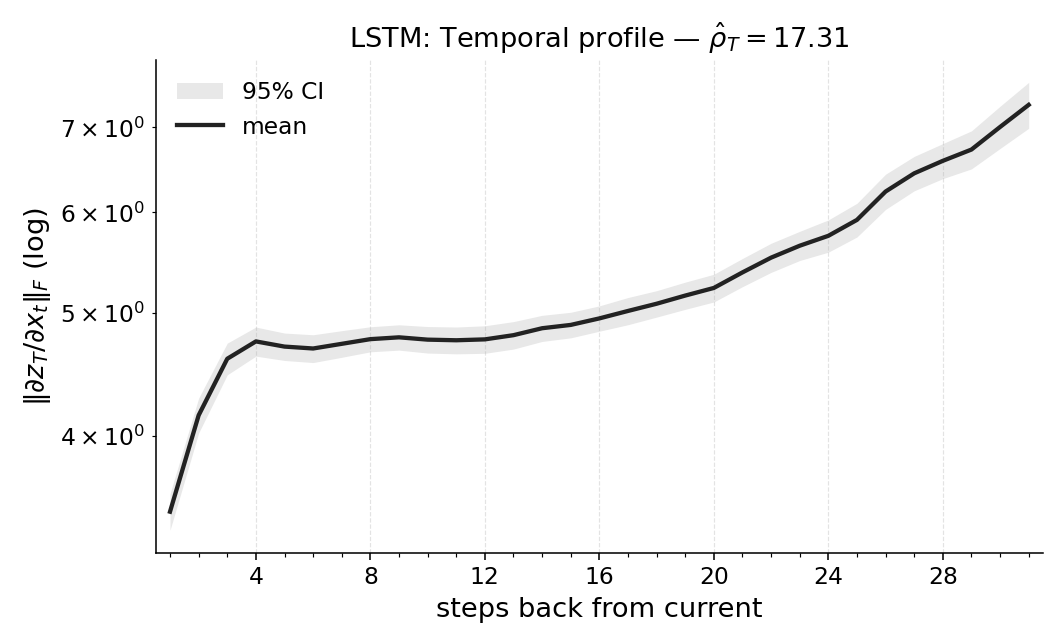
실험에서는 POPGym의 전통적인 제어 환경, 시각적 깜박임·가림 변형, 그리고 기억 요구가 명시적인 Copy‑k 과제를 사용한다. 완전 관측 제어에서는 Temporal Range가 1~2 스텝에 머물며, 정책이 현재 상태만으로 충분히 행동한다는 것을 보여준다. 반면 Copy‑k에서는 입력 시퀀스의 길이 k 에 비례해 Temporal Range가 증가하고, 이는 정책이 실제로 k 스텝 전까지의 정보를 보존하고 있음을 의미한다. 추가로, 다양한 네트워크 구조(MLP, RNN, SSM) 간 비교를 통해 구조가 메모리 활용에 미치는 영향을 정량화한다. 특히 SSM(Structured State Space Model)은 긴 시계열에 대해 효율적인 장기 의존성을 학습하지만, Temporal Range는 여전히 과제 요구에 맞춰 조정되는 것을 확인한다.
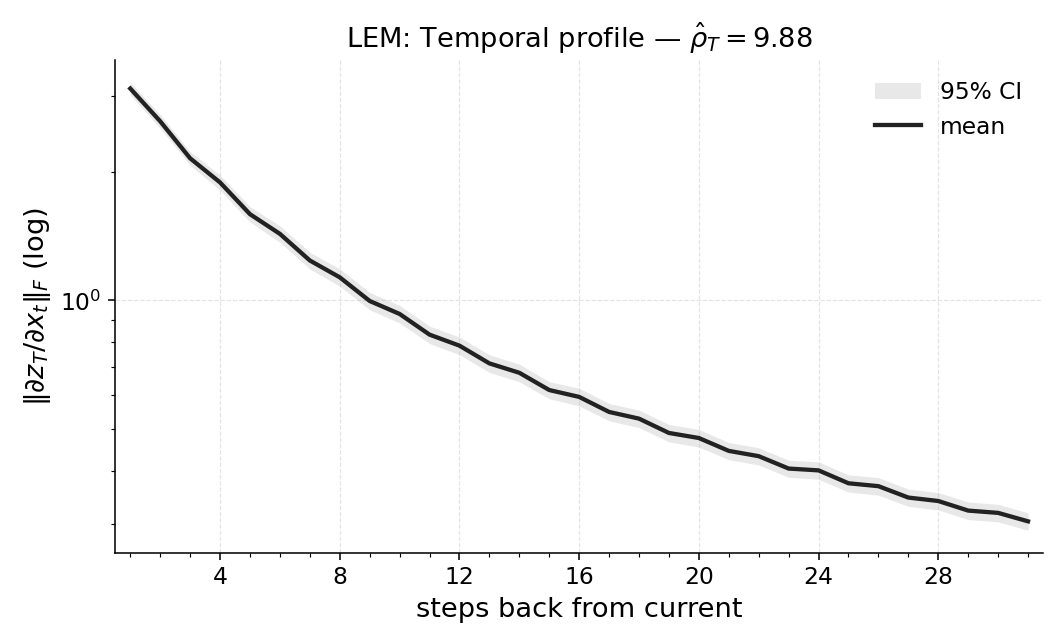
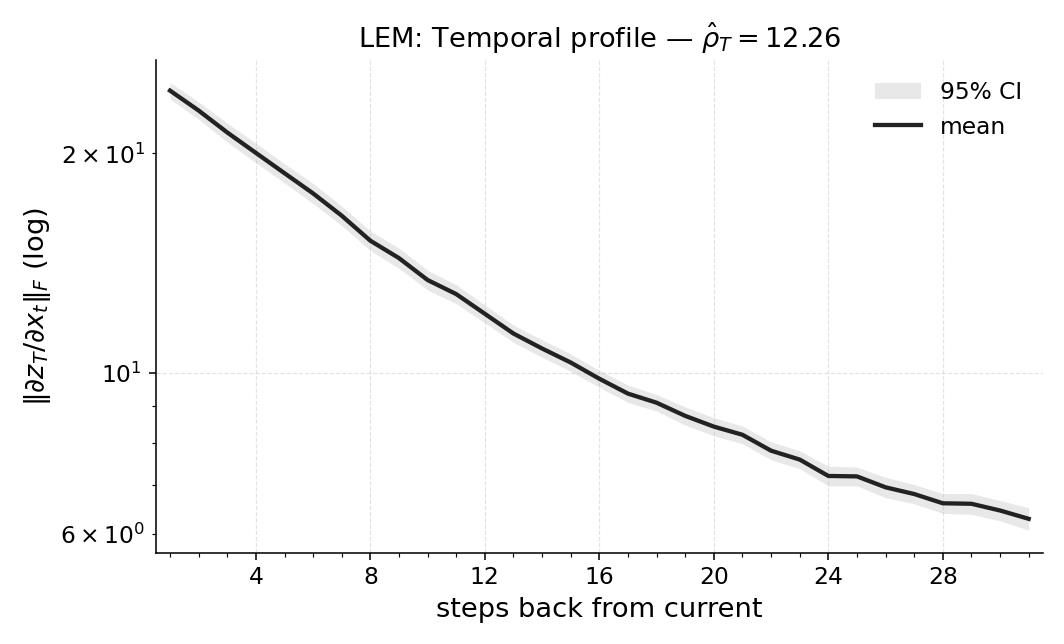
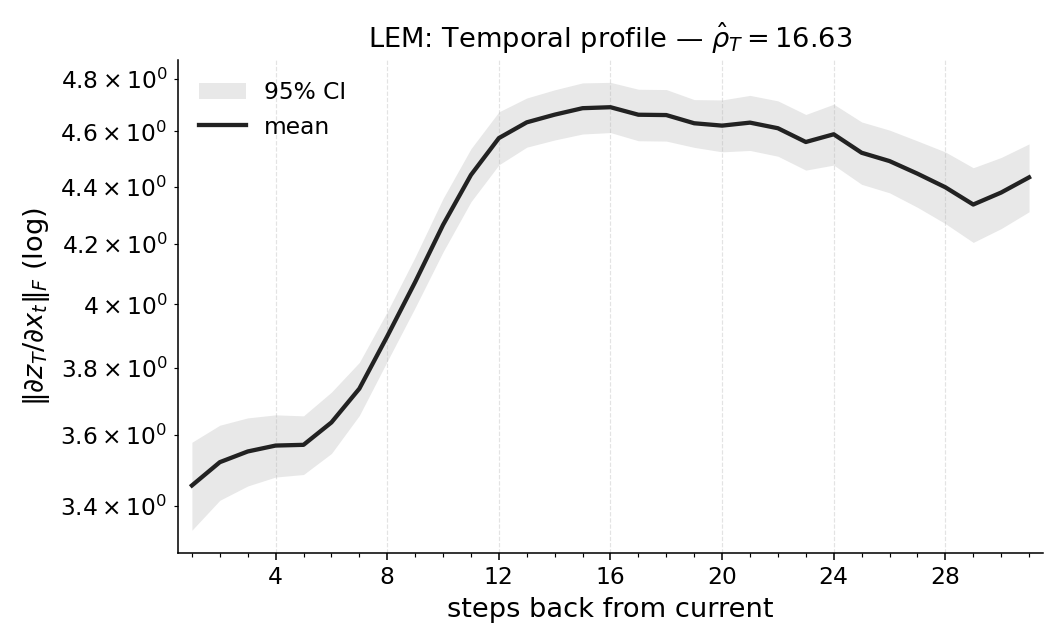
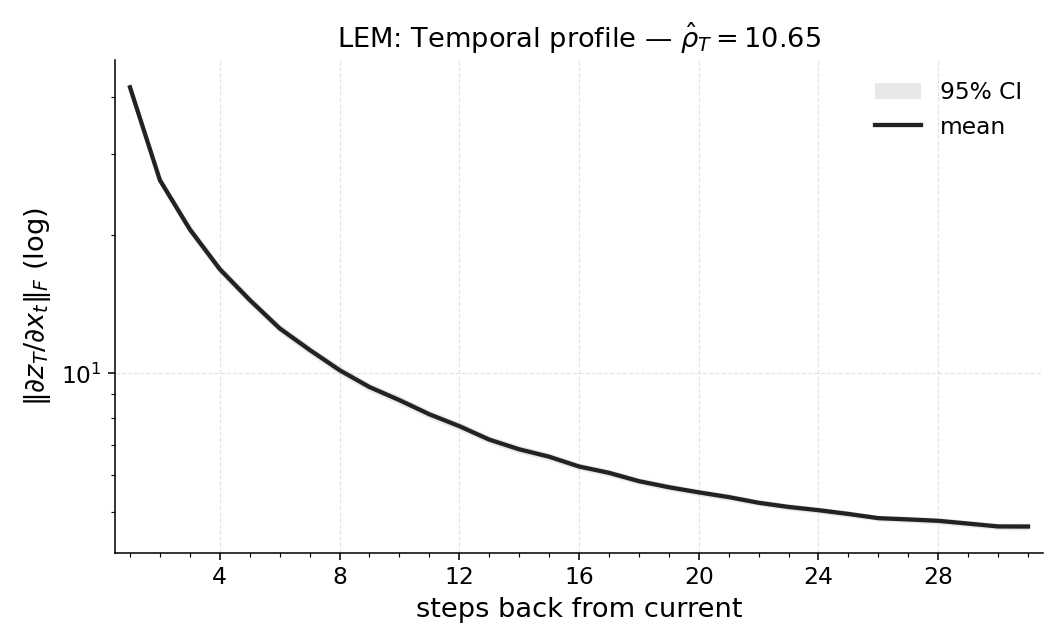
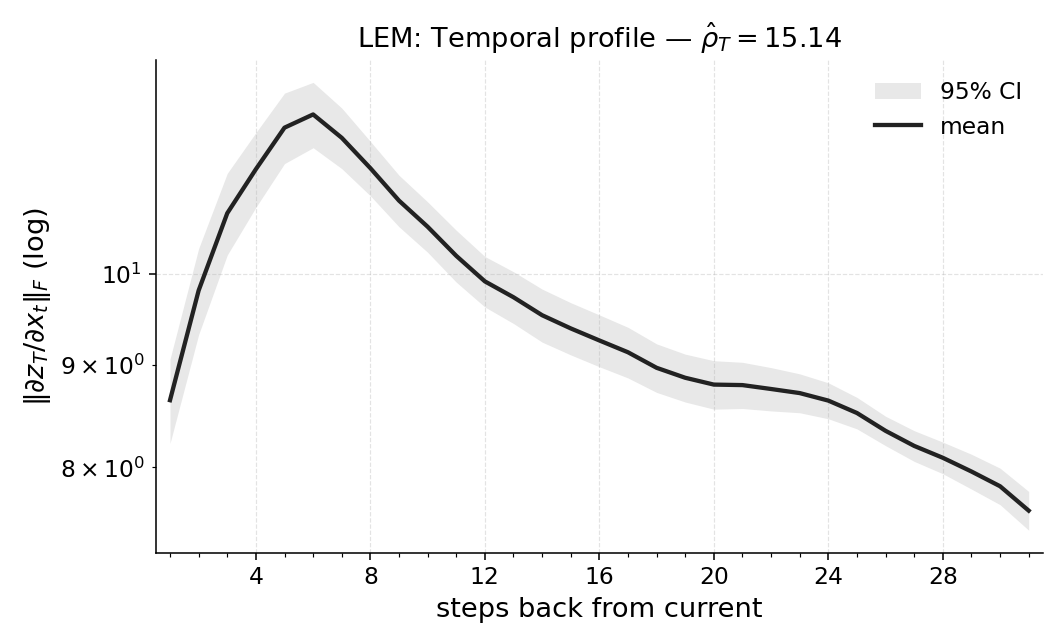
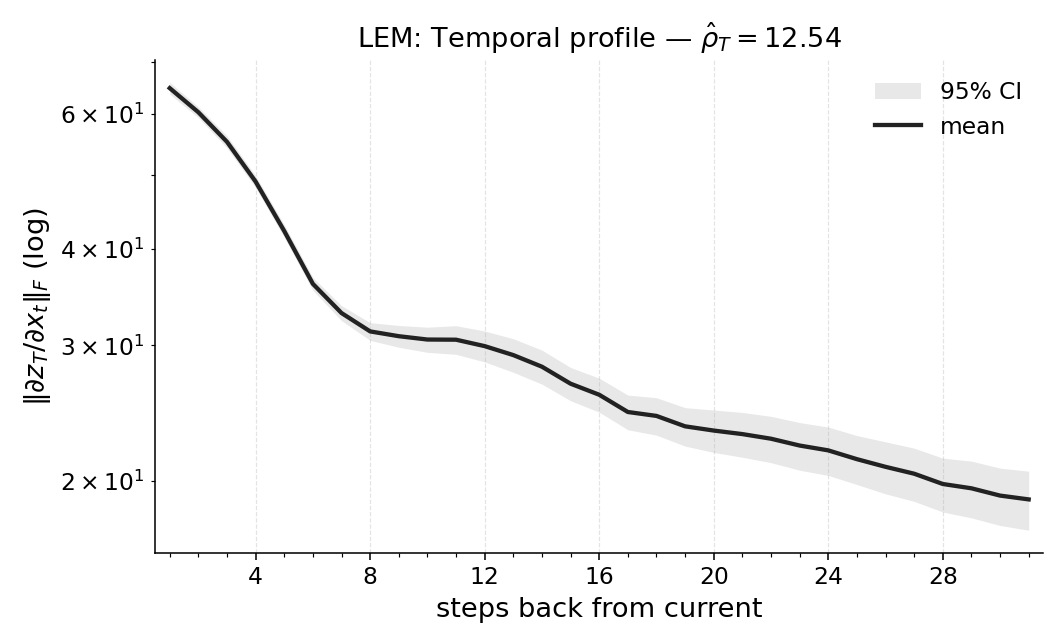
마지막으로 LEM(Long Expressive Memory) 정책에 Temporal Range를 적용해 “프록시 메모리 읽기”로 활용한다. LEM은 압축된 메모리 모듈을 갖지만, Temporal Range가 과제의 실제 지연과 일치한다면 해당 정책이 충분히 효율적인 메모리 사용을 하고 있음을 의미한다. 이러한 결과는 연구자들이 환경별 최소 히스토리 윈도우를 사전에 결정하거나, 메모리 효율성을 목표로 모델을 설계할 때 실용적인 지표로 활용될 수 있다. 전체적으로 Temporal Range는 모델‑불변, 해석 가능, 그리고 실험적으로 검증된 메모리 의존성 측정 도구로서 강화학습 분야에 새로운 평가 기준을 제시한다.
📄 논문 본문 발췌 (Excerpt)
## 시계열 범위 강화학습 정책의 기억 사용량 측정 번역
요약: 본 논문은 강화 학습(RL)에서 기억 활용 정도를 측정하는 새로운 방법인 “시계열 범위(Temporal Range)“를 소개합니다. RL은 복잡한 환경에서 성능을 향상시키기 위해 기억을 활용하는 오랜 역사를 가지고 있습니다 (Hausknecht & Stone, 2015; Berner et al., 2019; Chen et al., 2021; Lu et al., 2023). 기계 학습 모델 중에는 순환 신경망(RNN)과 트랜스포머(Transformer), 최근에 상태 공간 모델(SSM) 등이 포함됩니다 (Gu et al., 2021; Gu & Dao, 2023). 그러나 훈련된 정책이 역사 정보를 얼마나 활용하는지에 대한 엄격한 분석과 정량적 측정은 부족했습니다. 이는 부분적으로 관찰되는 환경에서 특히 중요합니다: 효과적인 역사 의존성이 짧으면 단순한 구조가 충분하지만, 길면 학습된 정책에서 직접 추론해야 합니다. 현재 관행은 간접 신호를 의존하며, 모델 클래스 비교, 환경별 탐침 또는 샘플 복잡성 경계와 같은 방법이 포함됩니다 (Williams, 2009; Efroni et al., 2022; Morad et al., 2023). 이러한 방법들은 최적화, 유도 편향, 실제 기억 수요를 혼동할 수 있습니다.
본 연구에서는 다음과 같은 시계열 범위 메트릭을 공식화하여 이 문제를 해결합니다:
시계열 범위 정의: 각 시간 t에 대해, 우리는 모든 후속 최종 타임스텝 s ∈ {t + 1, …, T}에 대한 벡터 출력 자가 회귀의 노름 평균인 가중 평균 후퇴를 계산합니다. 이 메트릭은 고유성 및 일관성을 보장하기 위해 범위 축에 대한 독특한 객체를 제공합니다.
이론적 기반: 우리의 접근 방식은 범위 함수에 대한 기존 이론을 기반으로 하며, 시간 지연과 벡터 출력에 대한 행렬 노름에 맞게 조정됩니다. 이 이론적 시작점은 Bamberger et al. (2025)의 축 범위 함수의 정의를 활용합니다.
계산 효율성: 시계열 범위는 정책의 역모드를 통해 계산할 수 있는 저비용 연산입니다. 필요한 자가 회귀 블록은 정책의 관점에 대한 입력 관찰에 대한 미분으로 얻을 수 있습니다.
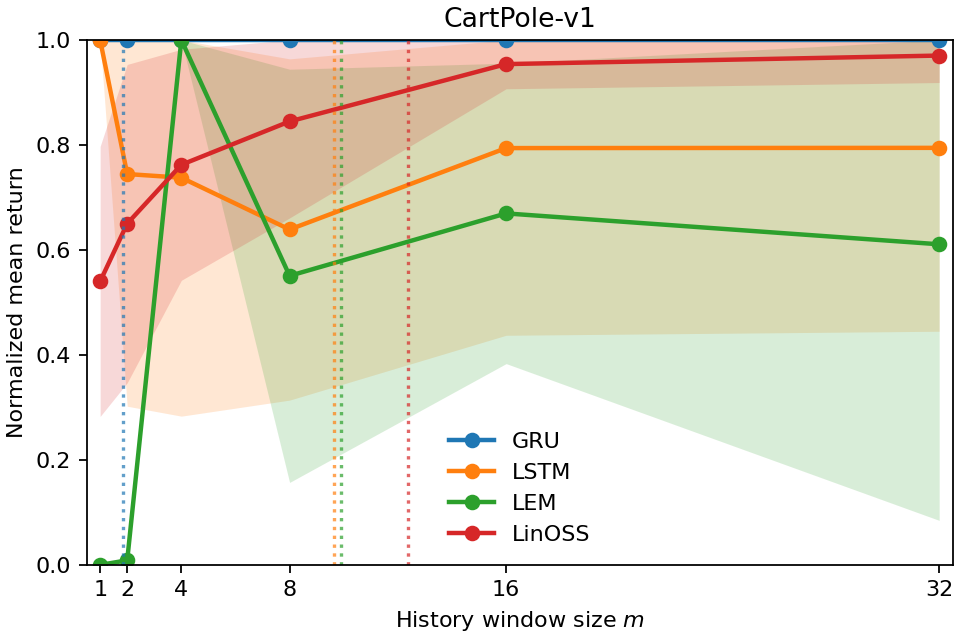
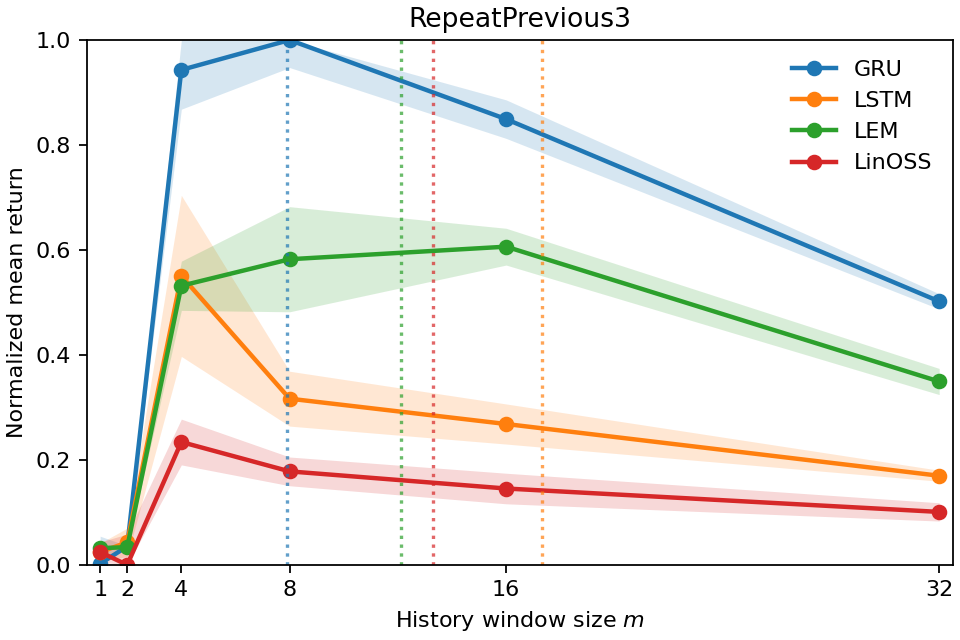
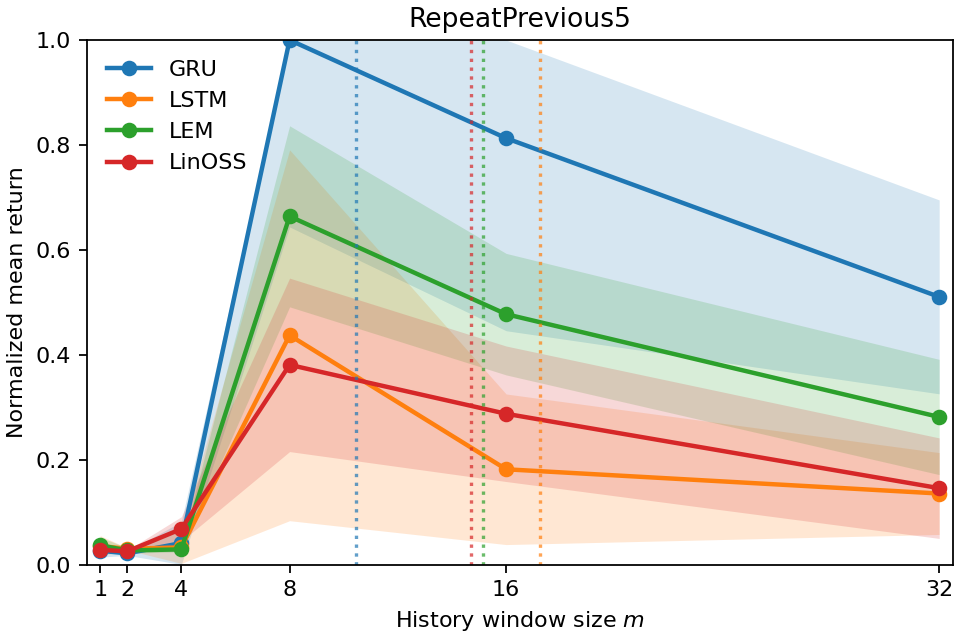
실험적 유효성: 우리는 다양한 POPGym(Morad et al., 2023) 진단 및 제어 환경에서 시계열 범위를 검증합니다. 결과는 시계열 범위가 부분적으로 관찰되는 환경에서 정책이 얼마나 멀리 과거를 참조하는지 정확하게 포착함을 보여줍니다. 또한, 이는 가장 높은 보상을 달성하기 위해 필요한 최소 역사 창을 확인하는 데 사용될 수 있음을 보여줍니다.
주요 기여:
시계열 범위 메트릭: 시계열 범위는 훈련된 정책이 과거 관찰에 얼마나 의존하는지를 측정하는 모델-독립적인 수치입니다. 이는 시간적 의존성과 공간적 주의를 보완하는 설명으로 사용될 수 있습니다.
행렬 노름 기반: 시계열 범위는 행렬 노름을 사용하여 정책의 입력 역사에 대한 민감도를 포착합니다. 이는 표준 주의 문헌의 주의 지표와 관련되어 있으며, 표준 주의 경고들을 재현합니다.
이미지 및 복잡성 제어: 시계열 범위는 훈련된 정책의 기억 사용량을 정량화하고, 이를 통해 더 효율적인 모델을 설계하거나 제한된 메모리 환경에서 성능을 최적화할 수 있습니다.
연구 개요:
강화 학습 연구는 종종 메모리를 구현하는 메커니즘(RNN, 트랜스포머, 메모리 버퍼)에 초점을 맞추었지만, 실제 기억 사용량을 직접 측정하는 연구는 드뭅니다. 본 논문에서는 이론적 기초와 시계열 범위 메트릭을 사용하여 강화 학습 에이전트가 과거 정보를 얼마나 활용하는지 정량적으로 분석합니다.
기본 맥락:
장기 의존성을 학습하는 것은 비폭발적/감소 편향과 잘라낸 역전파(Pascanu et al., 2013; Tallec & Ollivier, 2018)로 인해 어려울 수 있습니다. 우리의 초점은 고전적인 관점인 부분적으로 관찰 가능한 요구 사항이 기억을 필요로 한다는 것에 기반합니다 (Kaelbling et al., 1998). 또한, 시계열 범위는 강화 학습에서 시간적 신용 할당 기초를 제공합니다 (Sutton & Barto, 2018). 계산적으로는, 우리의 역모드 계산은 백프로파게이션을 통해 시간을 직접 연결합니다.
비교 및 관련 작업:
시계열 범위는 POPGym(Morad et al., 2023)과 같은 진단 및 제어 환경에 대한 비교를 위한 표준 벤치마크로 사용될 수 있습니다. 환경별 연구는 수정된 CartPole (Koffi et al., 2020), Pacman (Fallas-Moya et al., 2021), 다중 로봇 배송 (Omidshafiei et al., 2017)과 같은 작업에 초점을 맞춥니다.