KH FUNSD: 캄보디아어 비즈니스 문서 이해를 위한 계층형 데이터셋
📝 원문 정보
- Title: KH-FUNSD: A Hierarchical and Fine-Grained Layout Analysis Dataset for Low-Resource Khmer Business Document
- ArXiv ID: 2512.11849
- 발행일: 2025-12-04
- 저자: Nimol Thuon, Jun Du
📝 초록 (Abstract)
자동 문서 레이아웃 분석은 저자원, 비라틴 스크립트에 대한 주요 과제로 남아 있습니다. 캄보디아에서 매일 1700만 명 이상의 사람들이 사용하는 언어인 Khmer는 문서 AI 도구 개발에서 거의 주목받지 못했습니다. 특히 공공 행정과 사기업 모두에게 중요한 비즈니스 문서에 대한 전문 자원 부족이 심각한 문제입니다. 이 간극을 해결하기 위해, 우리는 캄보디아어 양식 문서 이해를 위한 첫 번째 공개 계층형 데이터셋인 KH-FUNSD를 제시합니다. 이 데이터셋은 영수증, 발행서 및 견적서를 포함하고 있습니다. 우리의 주석 프레임워크는 세 가지 수준의 설계를 특징으로 합니다: (1) 헤더, 양식 필드, 바닥글 등의 핵심 존을 나누는 영역 탐지; (2) 질문, 답변, 헤더 등과 같은 주요 엔티티와 그 관계를 구분하는 FUNSD 스타일의 주석; 그리고 (3) 필드 레이블, 값, 헤더, 바닥글 및 기호와 같은 특정 세미어틱 역할을 할당하는 미세한 분류. 이 다수준 접근 방식은 포괄적인 레이아웃 분석과 정확한 정보 추출을 지원합니다. 우리는 몇 가지 선두 모델을 벤치마킹하여 캄보디아어 비즈니스 문서에 대한 첫 번째 기초 결과를 제공하고, 비라틴 저자원 스크립트가 제기하는 고유한 과제에 대해 논의합니다. KH-FUNSD 데이터셋과 문서는 https://github.com/back-kh/KH-FUNSD에서 이용 가능합니다.💡 논문 핵심 해설 (Deep Analysis)
Paper Analysis: KH-FUNSD
Introduction and Background
The paper introduces KH-FUNSD, the first publicly available hierarchical dataset for understanding Cambodian business documents. The authors highlight that structured information extraction is crucial for digitizing form-like documents, which can enhance data entry efficiency, large-scale digitalization, business analytics, and regulatory compliance. However, existing deep learning models like LayoutLM and its successors have primarily been developed for high-resource languages (Latin script), leaving non-Latin and low-resource scripts underrepresented.
Cambodian is the official language of Cambodia and is widely used by over 17 million people. With rapid digitalization in Cambodia, there is an increasing demand for Cambodian AI tools and resources. Business documents such as receipts, invoices, and citations play a critical role in commerce, public administration, taxation, and record-keeping systems but are currently lacking advanced document analysis technologies.
Dataset Creation
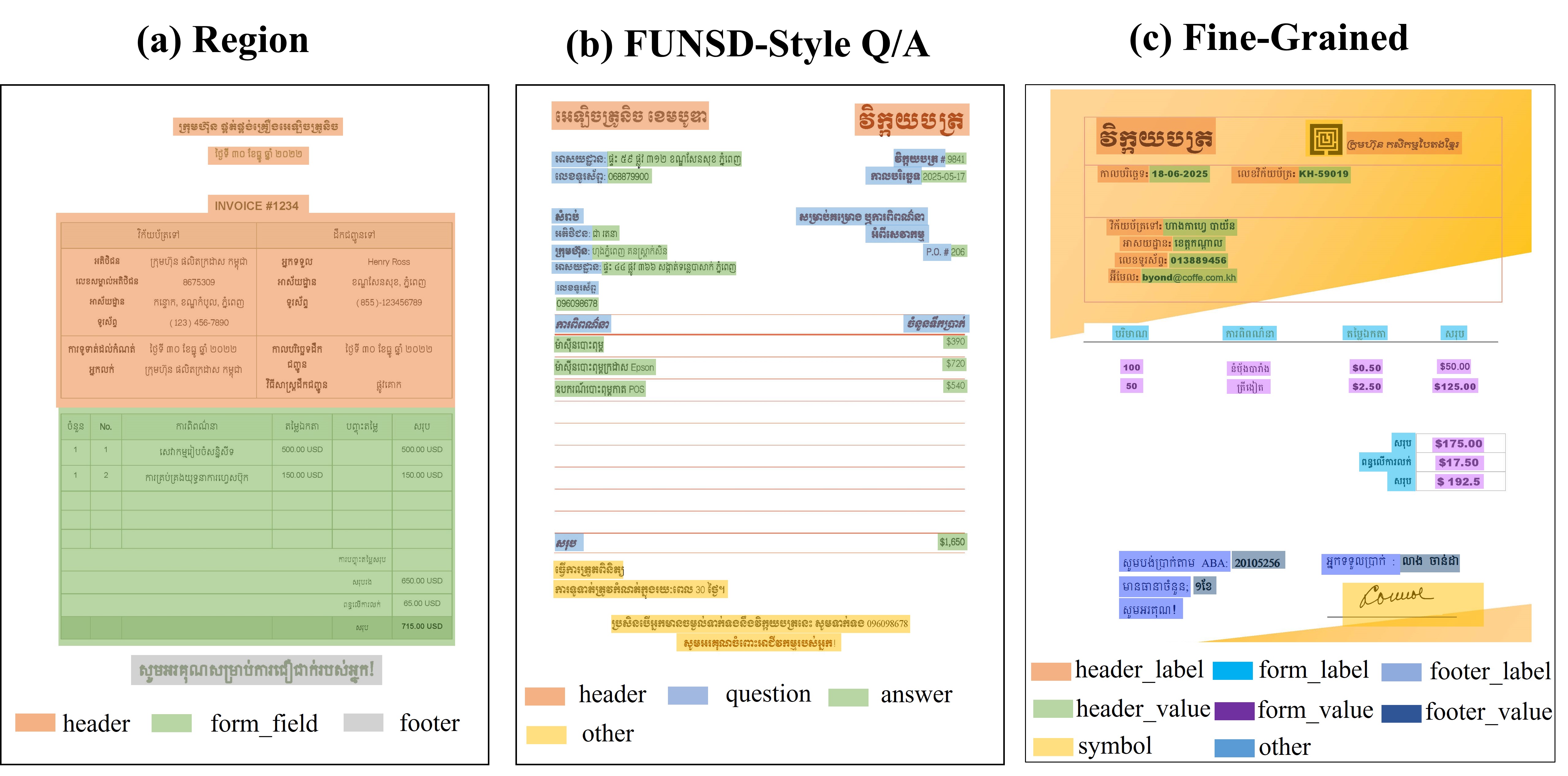
The authors address these challenges by introducing KH-FUNSD, the first open hierarchical dataset for understanding Cambodian business documents. The annotation framework consists of three levels: region-level detection, FUNSD-style entity linking, and fine-grained classification, capturing both structural and semantic aspects of business documents.
Key contributions include:
- KH-FUNSD Introduction: A comprehensive annotated dataset with region annotations, FUNSD-style Q&A, and hierarchical annotations.
- Baseline Evaluation: Provides baseline evaluations using state-of-the-art models (YOLO, DETR, LayoutLM) for region detection and semantic role prediction.
- Open Access: The dataset and guidelines are made publicly available to support further research and development.
Methodology
The creation process of KH-FUNSD involves collecting printed and scanned receipts, invoices, and citations from various sources. This includes open-access repositories, government or business resources, and synthetic samples replicated from true business forms. Sensitive information such as company names, addresses, phone numbers, and financial details are anonymized.
The dataset creation process consists of:
- Data Source Collection: Gathering Cambodian business documents from diverse sources.
- Preprocessing: Digitizing all documents in high-resolution image format (minimum 300dpi) with steps like distortion correction, cropping, noise reduction, and contrast enhancement to optimize document clarity.
- OCR & Annotation: Using open-source OCR tools for text extraction and manual annotation to ensure bounding box accuracy and overall text integrity.
- Annotation Protocol: A three-step hierarchical protocol is used to capture layout structure and semantic details. The first step segments documents into major meaningful areas (header, form fields, footer). The second step labels entities following the FUNSD benchmark. The third step involves fine-grained classification, assigning precise semantic roles to each text segment.
- Annotation Quality Assurance: Ensuring annotation quality through a strict multi-layer review protocol with Cambodian student researchers and Chinese collaborators for technical supervision.
Evaluation
The dataset includes structured JSON annotation files for each document, encoding layout and semantic information across all annotation levels. Three main benchmark tasks are defined:
- Region Detection: Predicting and classifying bounding boxes of major layout areas.
- FUNSD-style Q&A: Identifying and classifying entity types (header, question, answer) and modeling relationships between questions and answers.
- Fine-grained Classification: Assigning precise semantic roles to each text segment.
Models like YOLOv8, DETR, LayoutLMv1-v3 are used for evaluation. The dataset is split into training, validation, and test sets with normalization, contrast adjustment, and distortion correction applied to images. Training uses cross-entropy loss and Adam optimizer on NVIDIA RTX 3090 Ti GPUs.
Results
DETR achieves the highest performance in region detection (86.6% mAP50), while LayoutLMv3 shows superior results in entity classification and fine-grained classification, particularly for headers, questions, answers, and complex text segments.
Challenges and Future Work
The creation of KH-FUNSD involved practical and technical challenges such as strict annotation guidelines, iterative tool development, and resolving conflicts. Despite these, deep learning models still show performance gaps, especially in handling complex table areas, ambiguous or visually similar labels, and intricate Cambodian phrases.
Future work includes:
- Data Expansion: Adding more document types and layouts.
- Continuous Learning: Exploring advanced model architectures for end-to-end document segmentation.
- Visual Question Answering (VQA): Introducing VQA tasks to enhance semantic analysis.
- Relation Extraction: Identifying and modeling relationships within documents.
Conclusion
KH-FUNSD aims to promote research progress in low-resource, non-Latin document AI. The multi-level annotation scheme and comprehensive evaluation protocols provide a strong foundation for future studies. Future plans include expanding the dataset, developing end-to-end models, and applying advanced document understanding tasks like VQA and relation extraction.
This paper is significant as it addresses the gap in Cambodian business document analysis and provides a valuable resource for researchers working on low-resource languages and non-Latin scripts.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리
