텍스트 기반 훈련을 위한 텍스트 인쇄 이미지 활용 저비용 LVLM 데이터 생성 전략
📝 원문 정보
- Title: Text-Printed Image: Bridging the Image-Text Modality Gap for Text-centric Training of Large Vision-Language Models
- ArXiv ID: 2512.03463
- 발행일: 2025-12-03
- 저자: Shojiro Yamabe, Futa Waseda, Daiki Shiono, Tsubasa Takahashi
📝 초록 (Abstract)
** 최근 대형 비전‑언어 모델(LVLM)은 다양한 VQA 과제에 적용되고 있다. 그러나 실용적인 성능을 얻기 위해서는 수많은 이미지‑텍스트 쌍을 필요로 하는 과제별 파인튜닝이 필수이며, 이는 데이터 수집 비용이 크게 든다. 본 연구에서는 실제 이미지 없이 텍스트 설명만을 이용하는 ‘텍스트 중심 훈련’ 설정을 저비용 데이터 확장의 패러다임으로 탐구한다. 이미지 수집은 개인정보 보호와 도메인 희소성 등 제약이 많지만, 텍스트는 풍부하고 편집이 쉬워 LLM을 활용한 자동 다양화가 최소한의 인적 노력으로 가능하다. 그러나 순수 텍스트만으로 LVLM을 학습하면 이미지‑텍스트 모달리티 간 격차로 인해 VQA 성능 향상이 제한적이다. 이를 극복하기 위해 텍스트 인쇄 이미지(TPI)를 제안한다. TPI는 주어진 텍스트 설명을 흰 캔버스에 직접 렌더링해 합성 이미지를 생성한다. 이 간단한 렌더링은 텍스트를 이미지 모달리티로 투사하면서도 의미를 그대로 보존한다. TPI는 기존 LVLM 학습 파이프라인에 저비용으로 통합될 수 있으며, 텍스트‑투‑이미지 생성 모델이 종종 의미를 손상시키는 문제를 회피한다. 네 모델과 일곱 벤치마크에 대한 체계적 실험 결과, TPI가 확산 모델 기반 합성 이미지보다 텍스트 중심 훈련에 더 효과적임을 확인했다. 또한 TPI를 저비용 데이터 증강 전략으로 활용하면 실용적인 이점을 얻을 수 있다. 전반적으로 본 연구는 텍스트 중심 훈련의 큰 잠재력을 강조하고, LVLM을 위한 완전 자동 데이터 생성 방향을 제시한다.**
💡 논문 핵심 해설 (Deep Analysis)
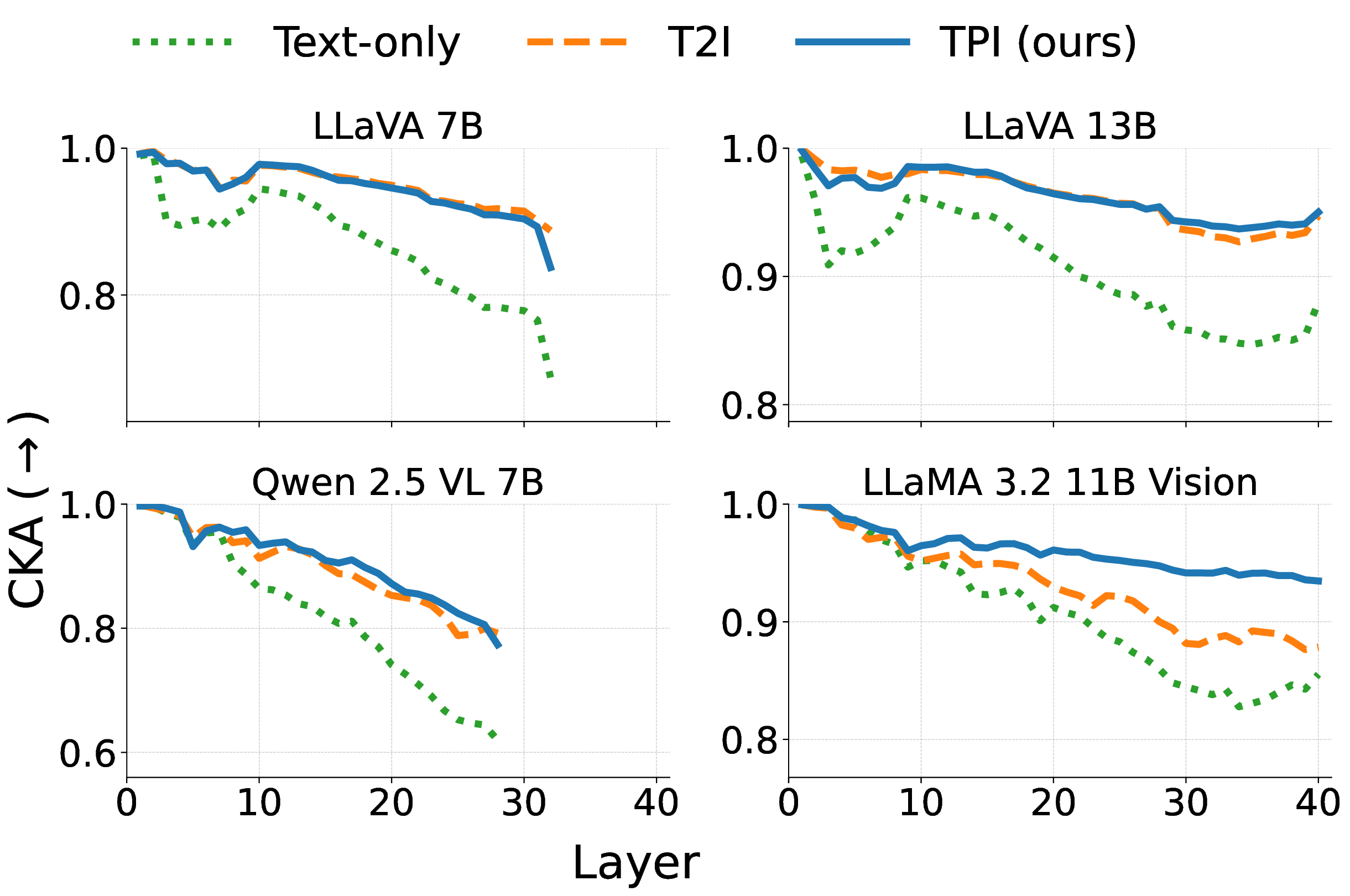
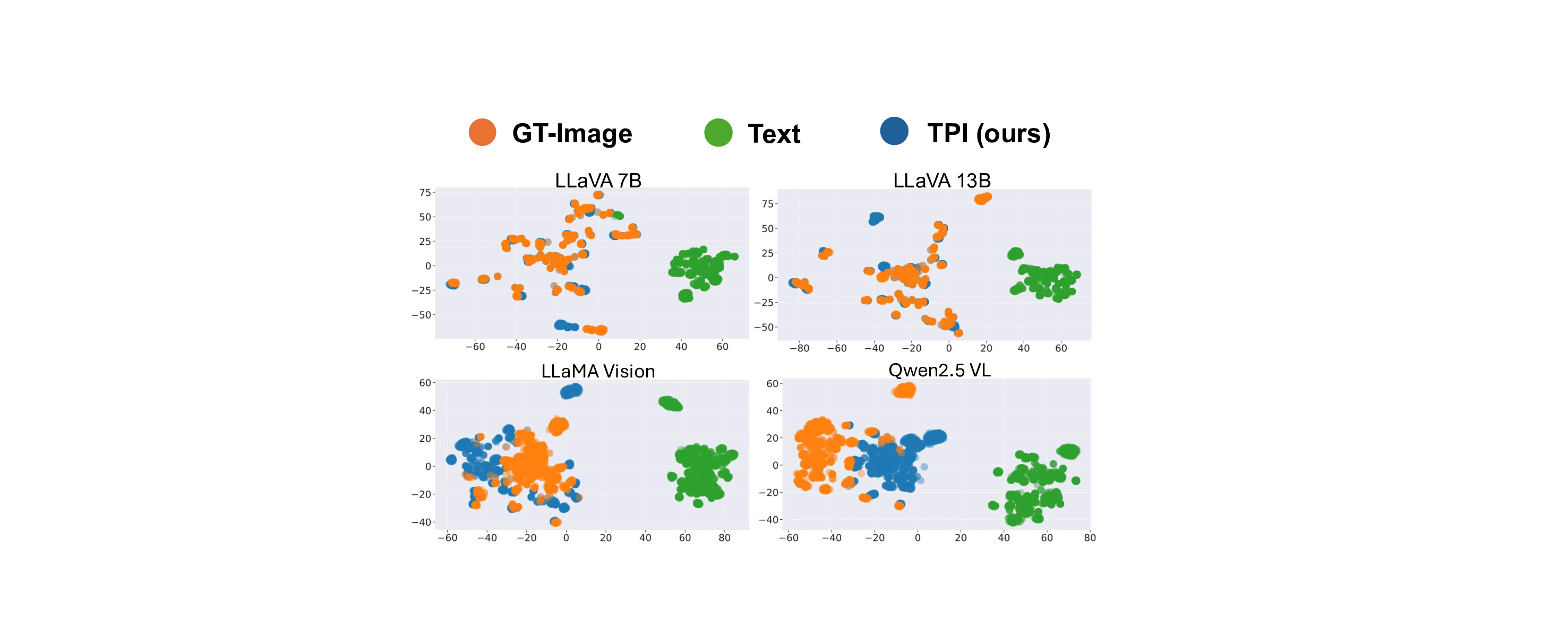
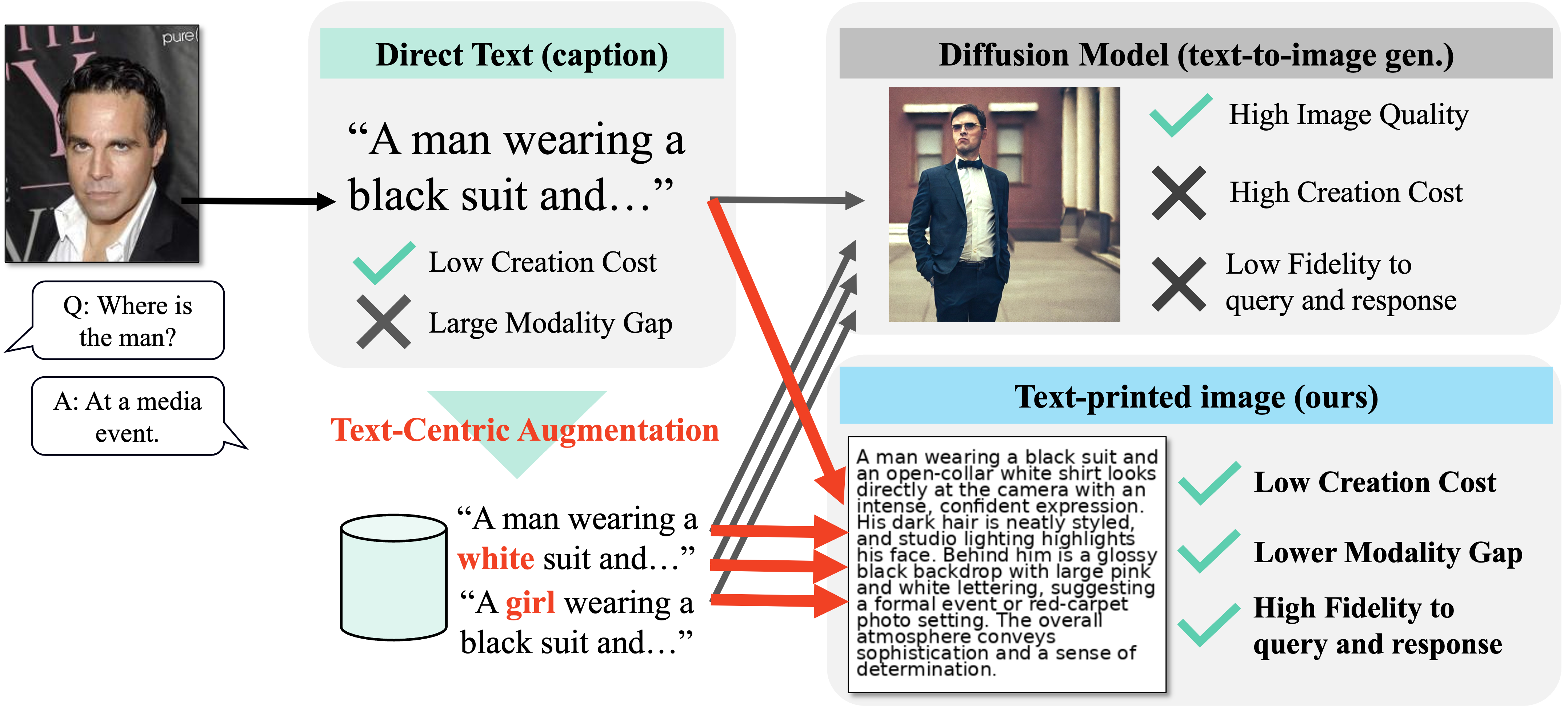
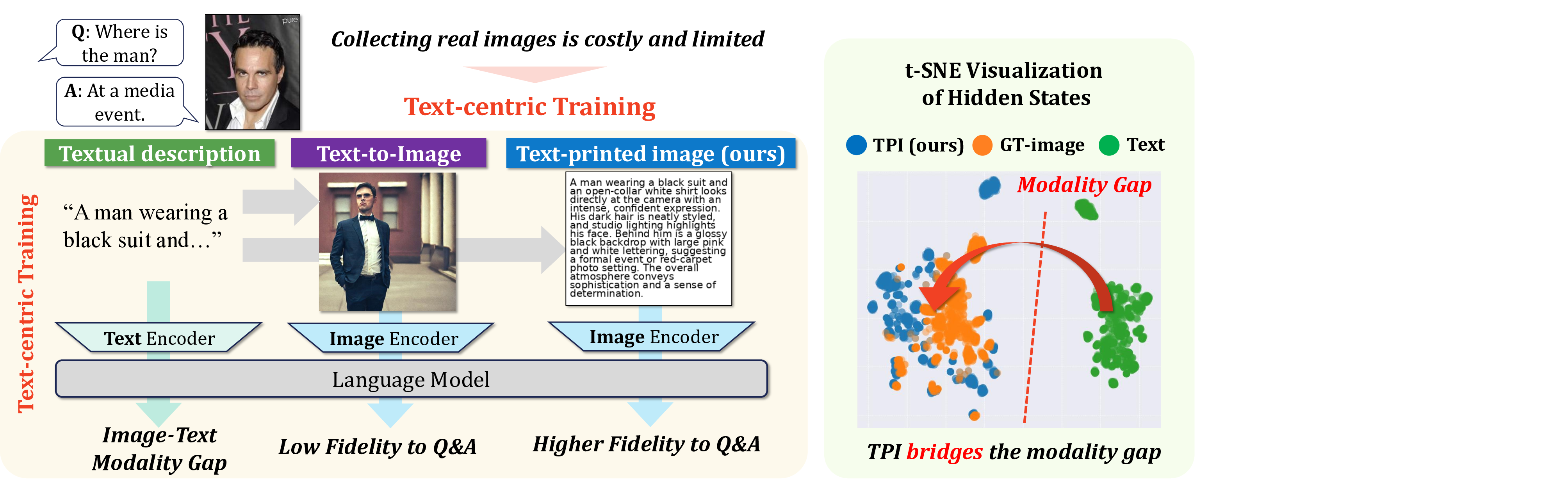
본 논문은 대형 비전‑언어 모델(LVLM)의 학습 비용을 크게 낮출 수 있는 새로운 데이터 생성 방식을 제시한다는 점에서 의미가 크다. 기존 LVLM은 이미지‑텍스트 쌍을 대규모로 수집해야 하는데, 이는 촬영·저작권·프라이버시 등 여러 제약으로 인해 특히 의료·법률·산업 현장 등 특수 도메인에서 어려움을 겪는다. 반면 텍스트는 웹·논문·보고서 등에서 손쉽게 확보할 수 있으며, 대형 언어 모델(LLM)을 이용해 자동으로 변형·확장할 수 있다. 그러나 텍스트만으로 LVLM을 학습하면 ‘모달리티 격차(modality gap)’가 발생한다. 이미지와 텍스트는 각각 고유한 시각·언어적 특성을 가지고 있어, 텍스트만으로는 시각적 추론 능력을 충분히 길러낼 수 없다.
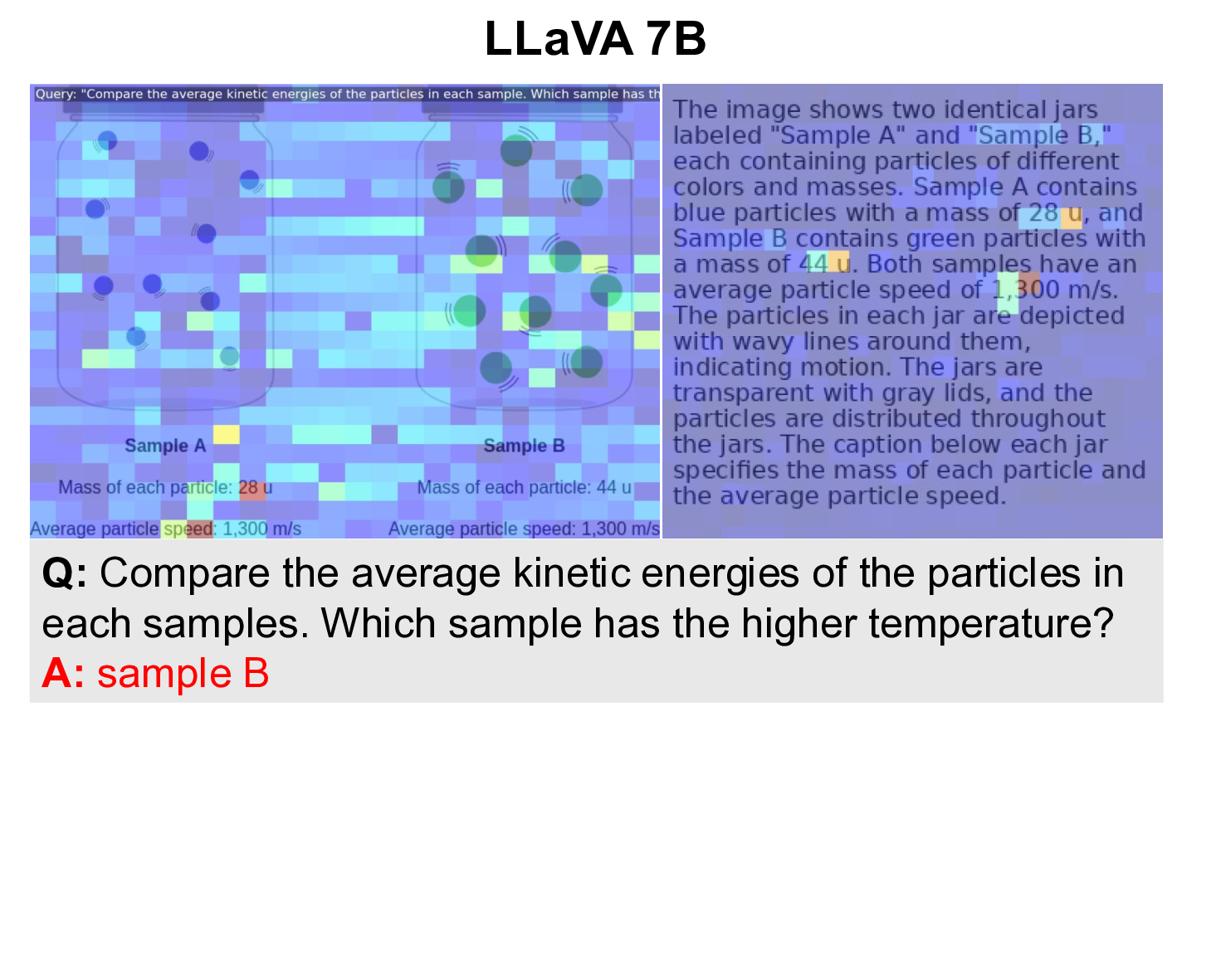
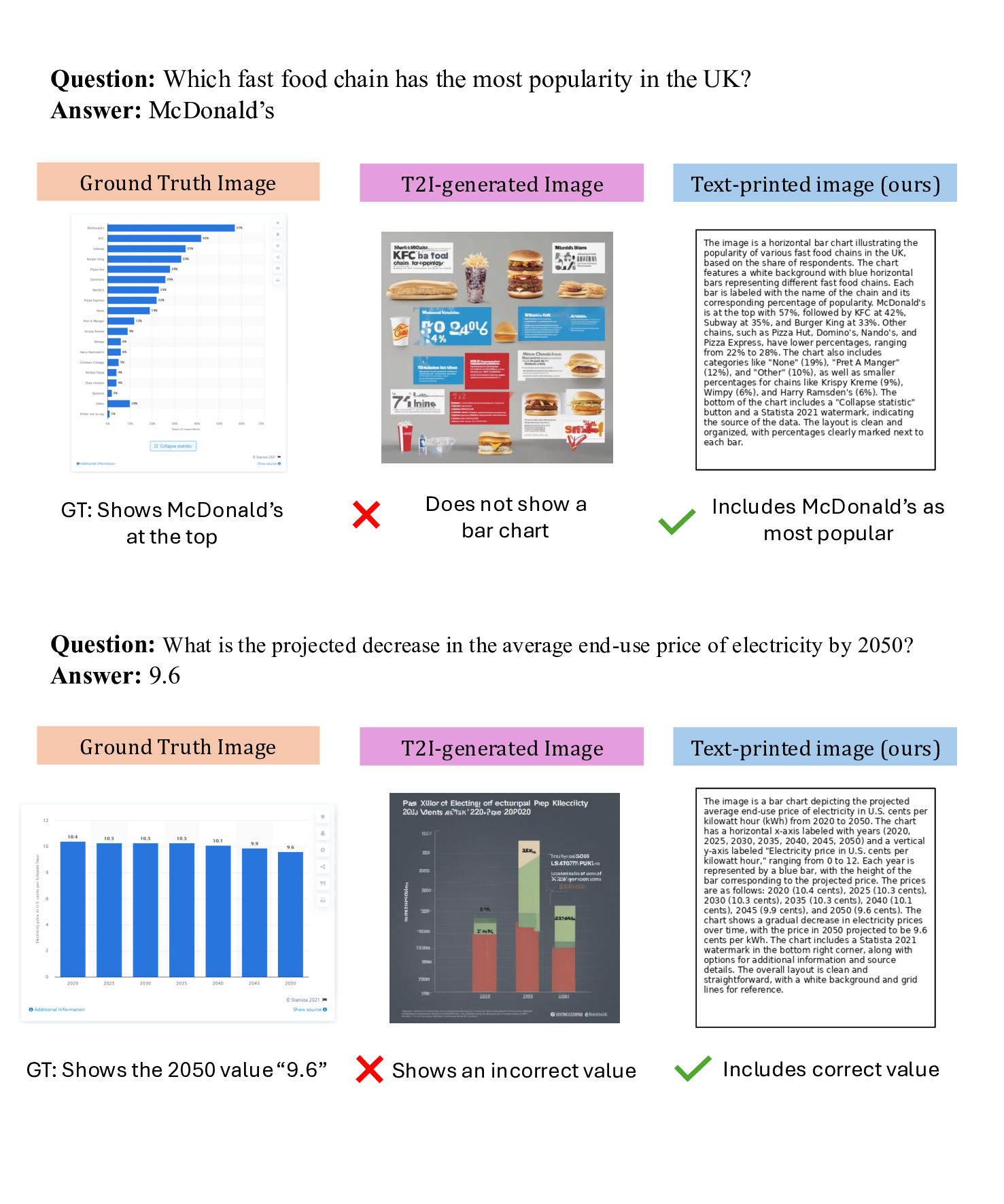
이를 해결하기 위해 저자들은 ‘텍스트 인쇄 이미지(Text‑Printed Image, TPI)’라는 아주 단순하지만 효과적인 방식을 고안했다. TPI는 텍스트를 흰 배경에 그대로 렌더링해 이미지 형태로 변환한다. 이 과정에서 이미지의 픽셀 구조는 존재하지만, 시각적 복잡도는 최소화된다. 따라서 모델은 ‘이미지’라는 입력 형태에 익숙해지면서도, 텍스트의 의미는 그대로 유지된다. 기존에 많이 사용되는 텍스트‑투‑이미지(diffusion) 모델은 텍스트를 시각적 장면으로 변환하려다 보니 의미 왜곡, 스타일 편향, 생성 오류가 빈번히 발생한다. TPI는 이러한 위험을 회피하고, 데이터 생성 비용도 거의 들지 않는다(단순 렌더링만 수행).
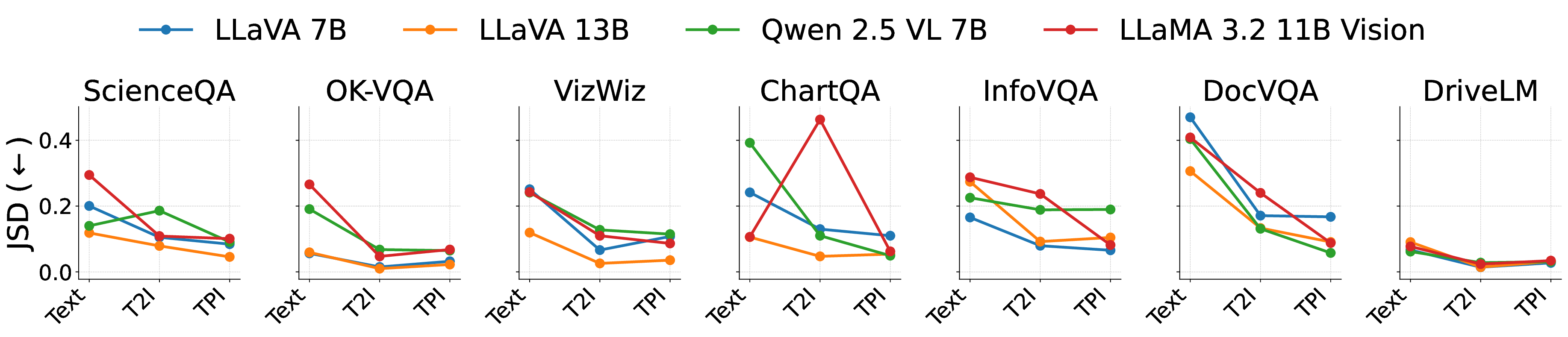
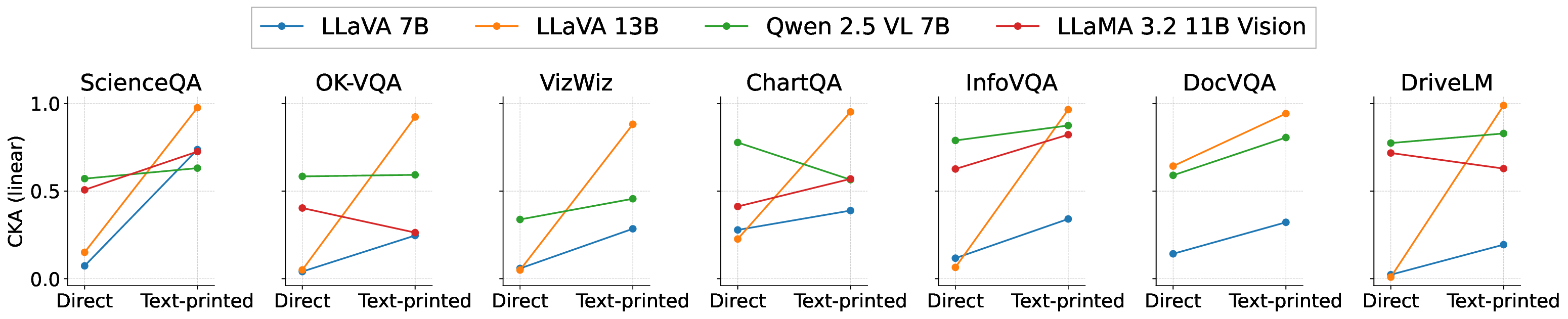
실험에서는 4가지 LVLM(예: BLIP‑2, LLaVA 등)과 7개의 VQA 벤치마크(예: VQAv2, GQA, OK‑VQA 등)를 대상으로 TPI와 확산 모델 기반 합성 이미지를 비교했다. 결과는 TPI가 전반적으로 높은 정확도와 안정성을 보였으며, 특히 텍스트 중심 훈련이 강조된 상황에서 그 차이가 두드러졌다. 또한 TPI를 데이터 증강에 활용하면 기존 데이터셋에 비해 소량의 추가 비용만으로도 성능 향상이 가능함을 확인했다.
하지만 몇 가지 한계도 존재한다. 첫째, TPI는 텍스트를 그대로 이미지에 옮기기 때문에 시각적 다양성이 부족하다. 복잡한 장면 이해가 요구되는 고난이도 VQA에서는 여전히 실제 이미지가 필요할 수 있다. 둘째, 텍스트가 길거나 구조가 복잡하면 렌더링된 이미지가 가독성이 떨어져 모델이 학습에 활용하기 어려울 수 있다. 셋째, 현재 실험은 주로 영어 텍스트와 서구권 데이터셋에 국한돼 있어, 비라틴 문자나 다국어 환경에서의 적용 가능성은 추가 검증이 필요하다.
향후 연구 방향으로는 TPI와 텍스트‑투‑이미지 생성 모델을 혼합해 시각적 다양성을 보강하거나, OCR‑기반 사전처리를 통해 텍스트 레이아웃을 최적화하는 방법이 고려될 수 있다. 또한 도메인‑특화 텍스트(예: 의료 기록, 법률 문서)를 활용해 해당 분야 전용 LVLM을 저비용으로 구축하는 시나리오도 기대된다. 궁극적으로는 ‘텍스트만으로도 충분히 이미지 모달리티를 학습하게 하는’ 완전 자동 데이터 파이프라인이 구축되어, LVLM 개발 비용을 획기적으로 낮추는 것이 목표가 된다.
**
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리