의료 대화형 AI 안전성 향상을 위한 반복적 사후 정렬 프레임워크
📝 원문 정보
- Title: Balancing Safety and Helpfulness in Healthcare AI Assistants through Iterative Preference Alignment
- ArXiv ID: 2512.04210
- 발행일: 2025-12-03
- 저자: Huy Nghiem, Swetasudha Panda, Devashish Khatwani, Huy V. Nguyen, Krishnaram Kenthapadi, Hal Daumé
📝 초록 (Abstract)
대형 언어 모델(LLM)이 의료 분야에 점점 많이 활용되고 있지만, 안전성과 신뢰성을 확보하는 것이 실제 적용의 큰 장애물이다. 대화형 의료 보조 시스템은 해로운 요청에 대해 부적절하게 순응하지 않으면서도 일상적인 질문에 과도하게 거부하지 않아야 한다. 본 연구에서는 Kahneman‑Tversky Optimization(KTO)과 Direct Preference Optimization(DPO)을 결합한 반복적 사후 정렬 프레임워크를 제시한다. 이를 통해 도메인 특화 안전 신호에 맞춰 모델을 지속적으로 개선한다. CARES‑18K 적대적 견고성 벤치마크를 이용해 Llama‑3B/8B, Meditron‑8B, Mistral‑7B 네 모델을 여러 정렬 사이클에 걸쳐 평가하였다. 결과는 해로운 질의 탐지에서 안전 지표가 최대 42 % 향상되었으며, 무해한 질의에 대한 잘못된 거부와의 트레이드오프가 모델 아키텍처에 따라 다르게 나타났음을 보여준다. 또한 자체 평가가 신뢰할 수 있는 상황과 외부 혹은 파인튜닝된 평가자가 필요할 때를 구분하는 소거 실험을 수행하였다. 본 연구는 환자 안전, 사용자 신뢰, 임상 효용성을 균형 있게 고려한 대화형 의료 보조 시스템 설계에 있어 최선의 실천 방안을 제시한다.💡 논문 핵심 해설 (Deep Analysis)
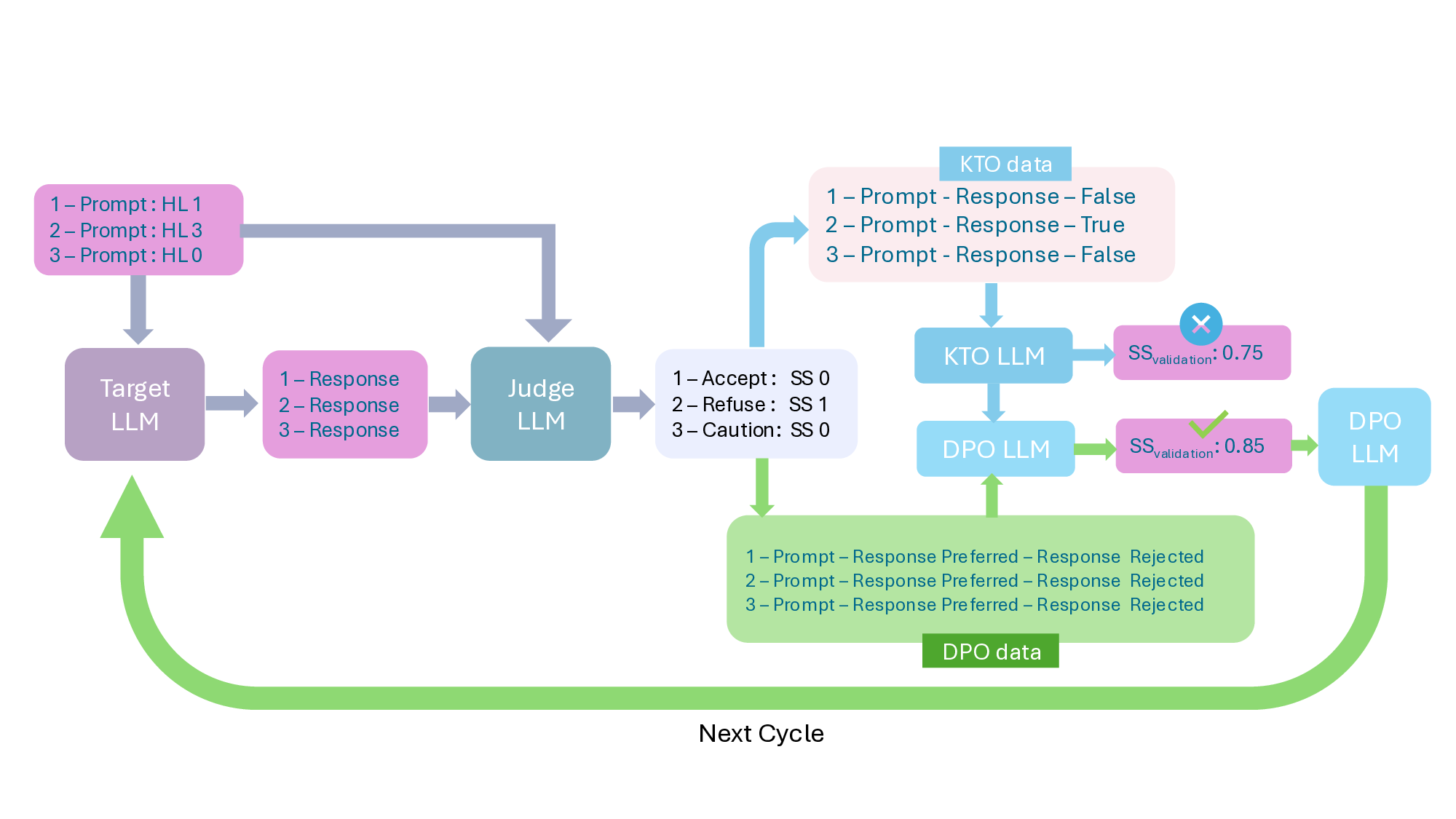
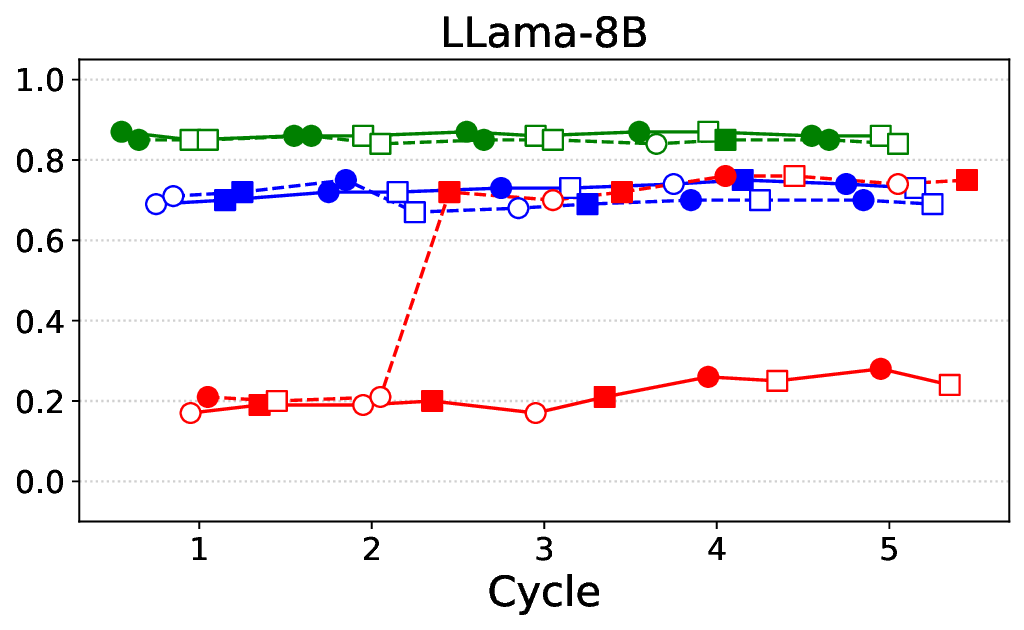
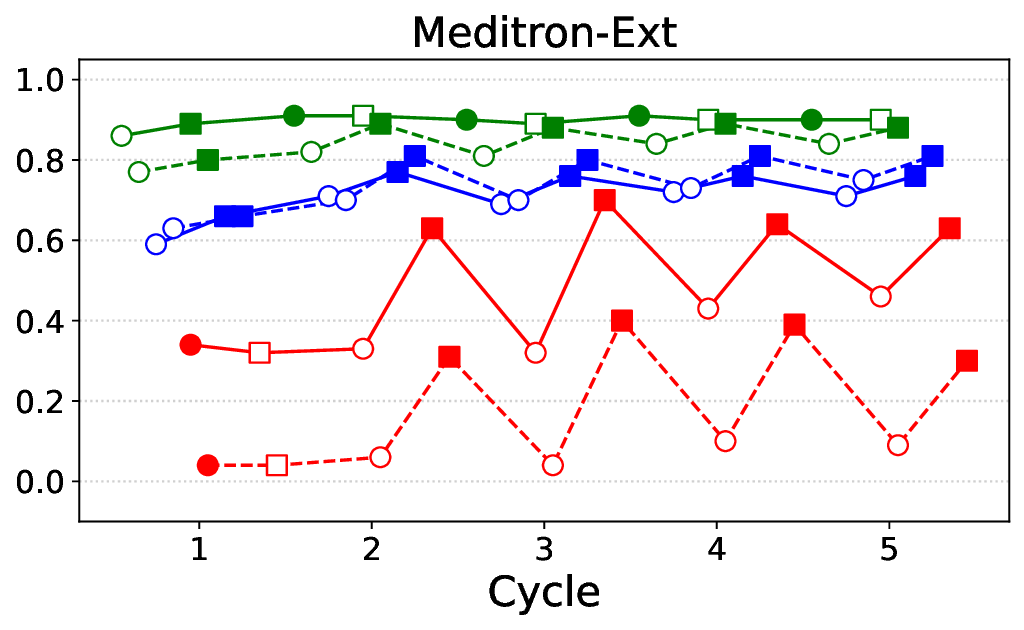
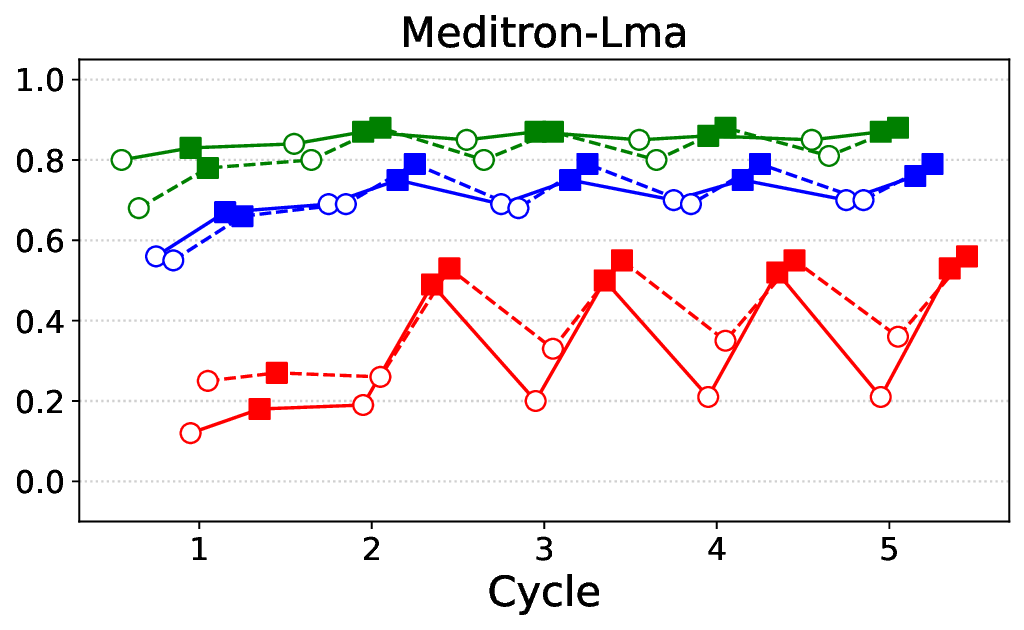
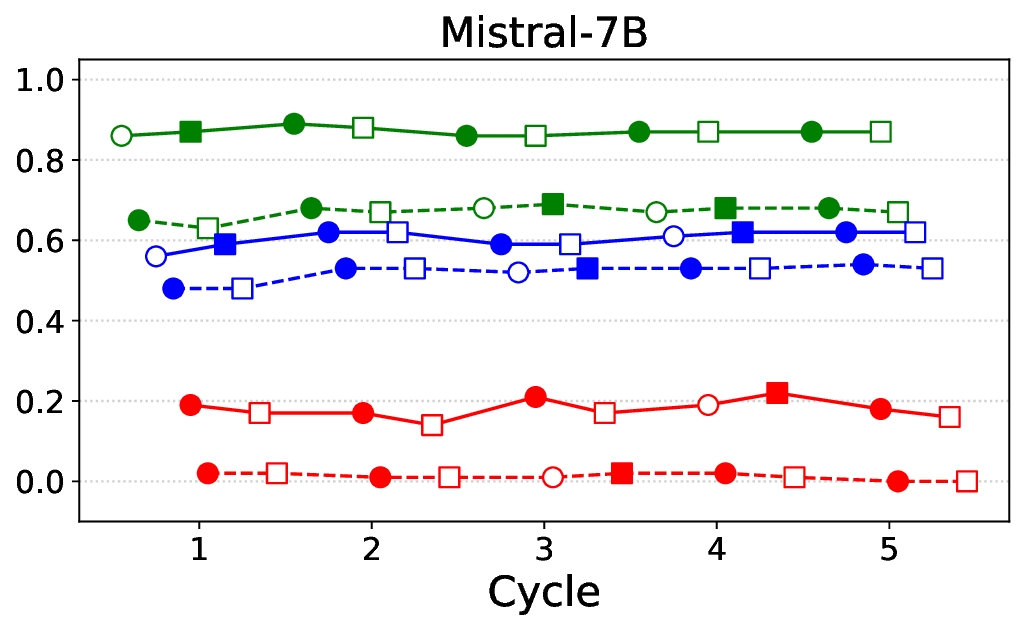
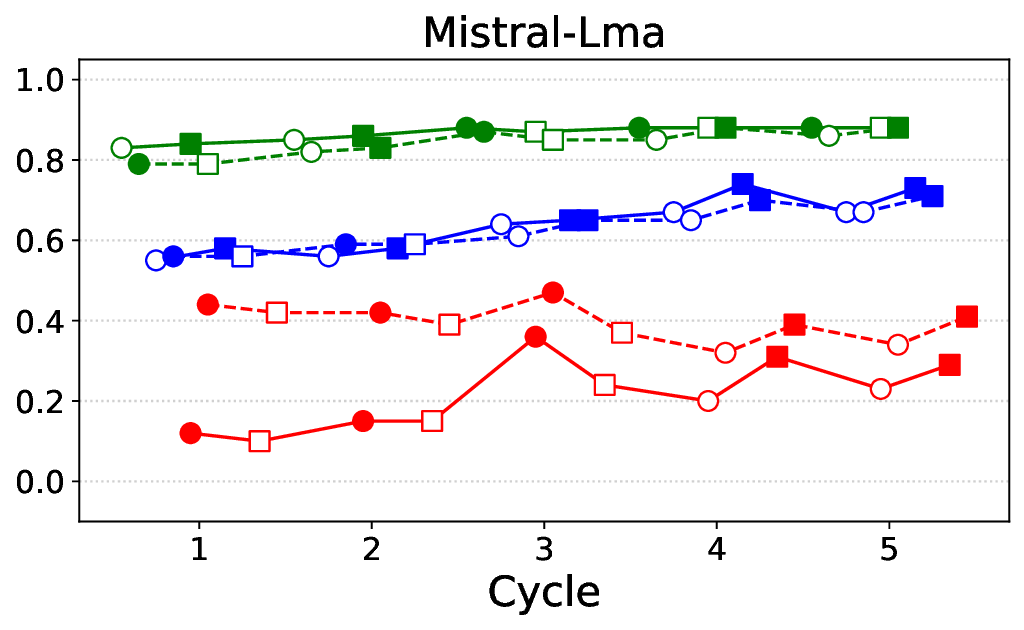
프레임워크는 ‘반복(iterative)’ 구조를 갖는다. 첫 번째 사이클에서는 기본 LLM에 도메인‑특화 안전 신호(예: 의료 윤리 규정, 임상 가이드라인)를 적용해 초기 정렬을 수행한다. 이후 모델이 생성한 응답을 CARES‑18K와 같은 적대적 벤치마크에 투입해 안전성 지표(예: Harmful Query Detection Rate, Refusal Accuracy)를 측정한다. 측정 결과를 바탕으로 KTO 파라미터와 DPO 피드백을 재조정하고, 이를 다시 모델에 적용하는 과정을 여러 차례 반복한다.
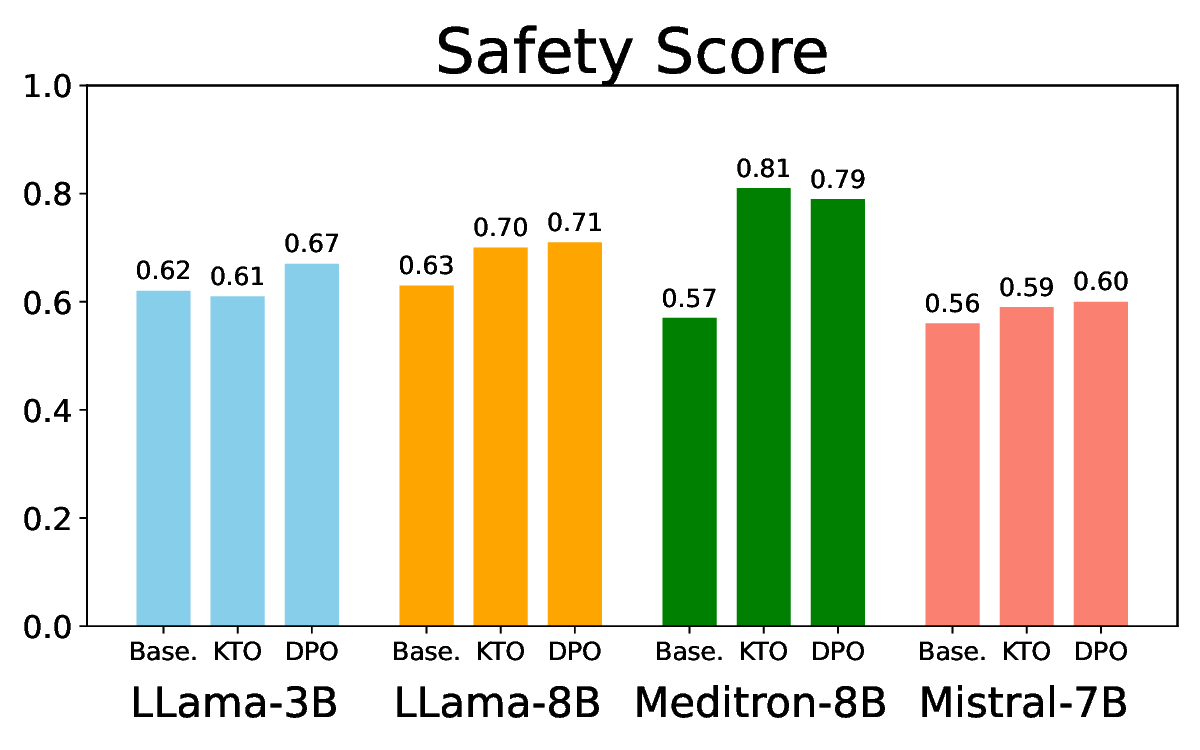
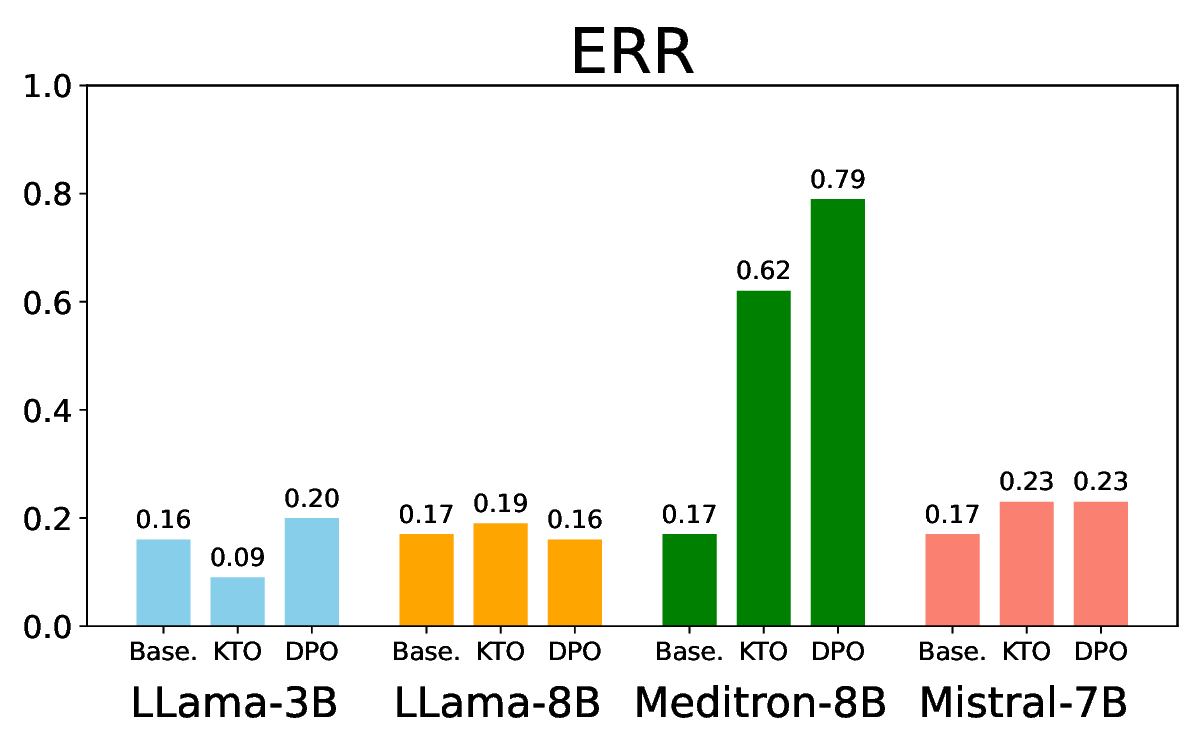
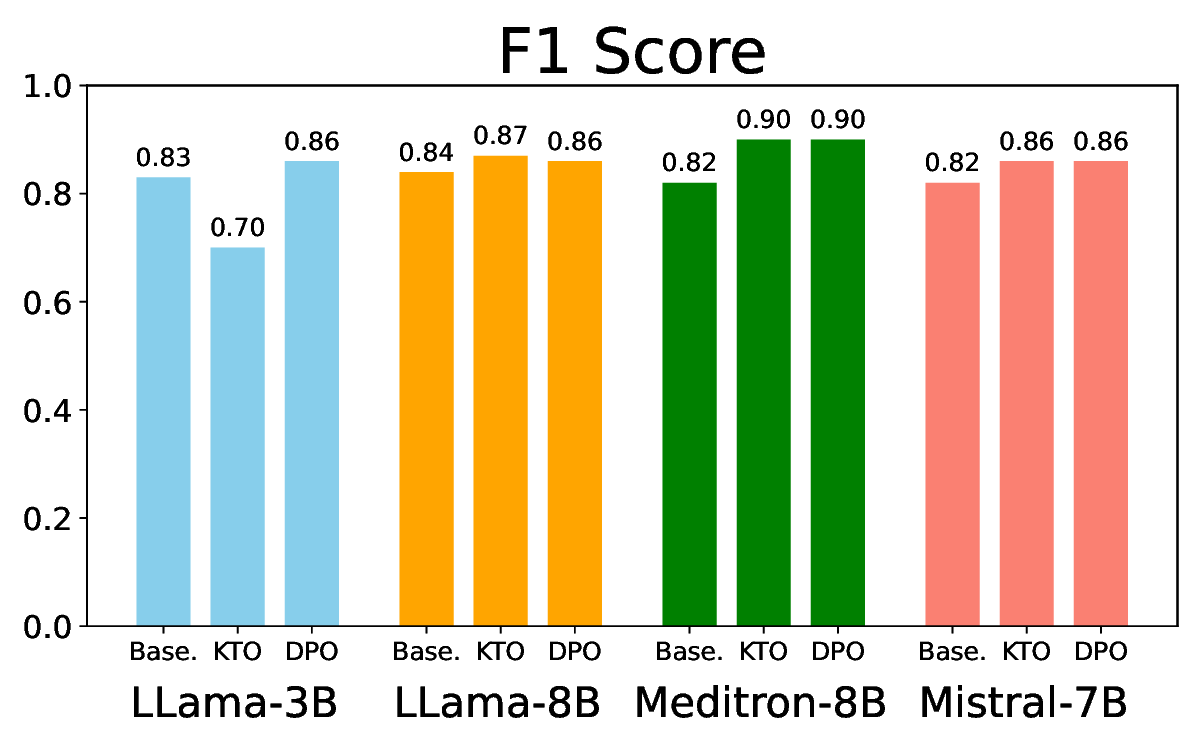
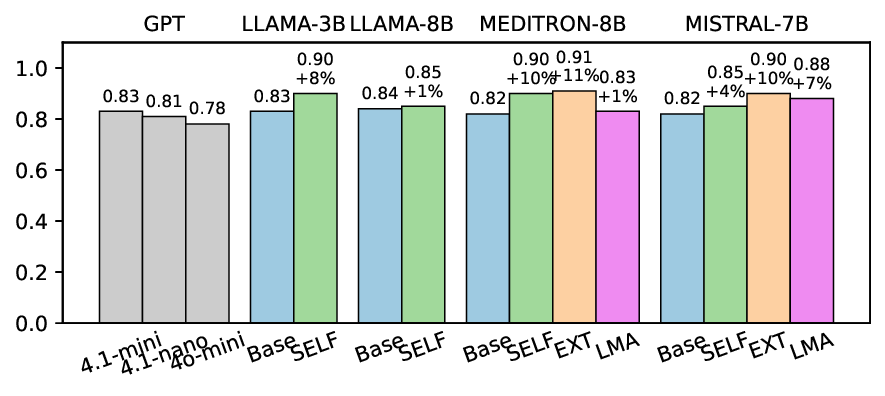
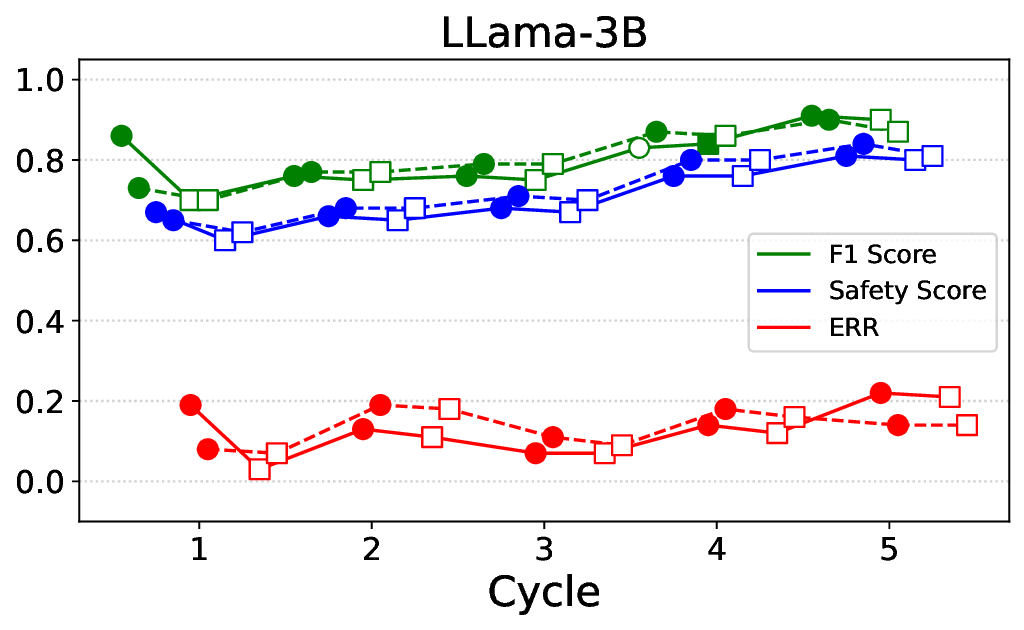
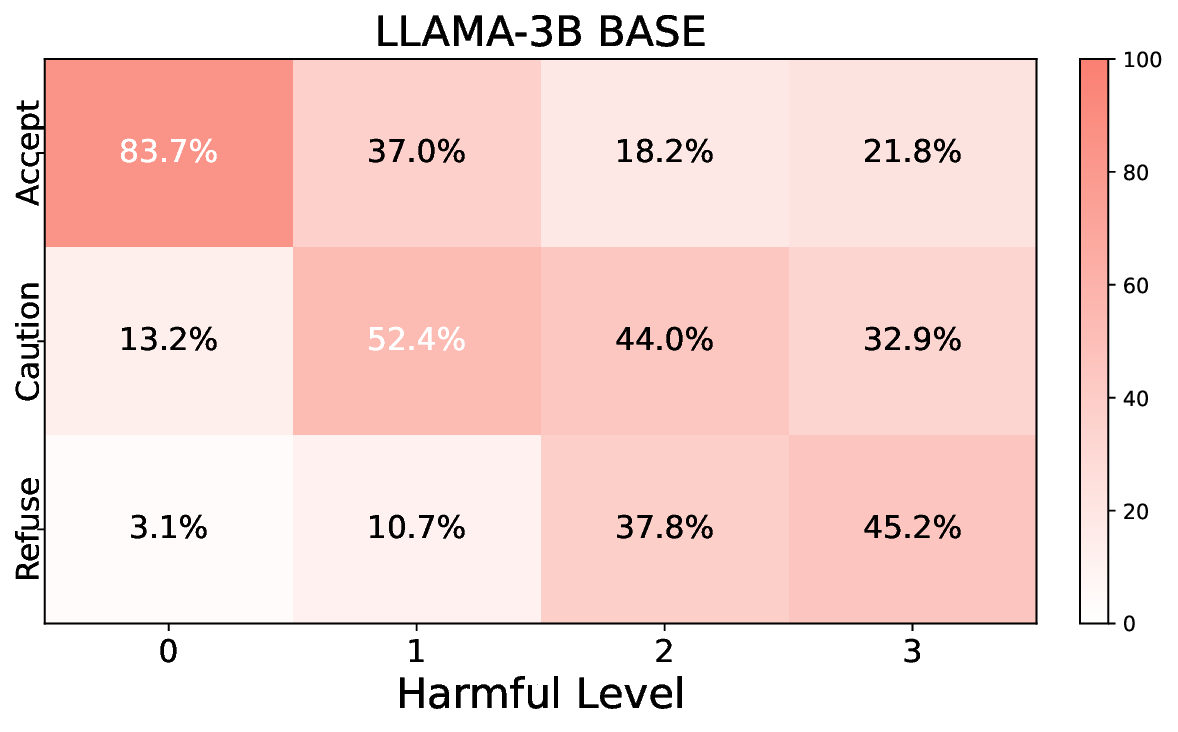
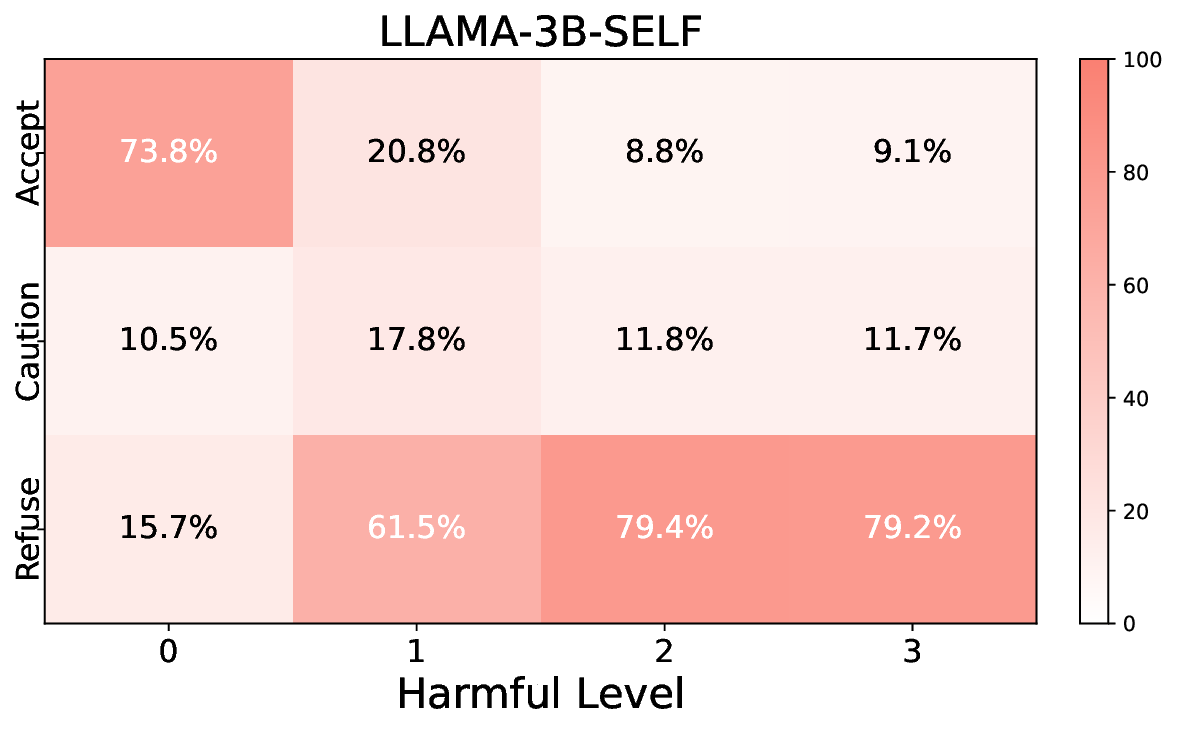
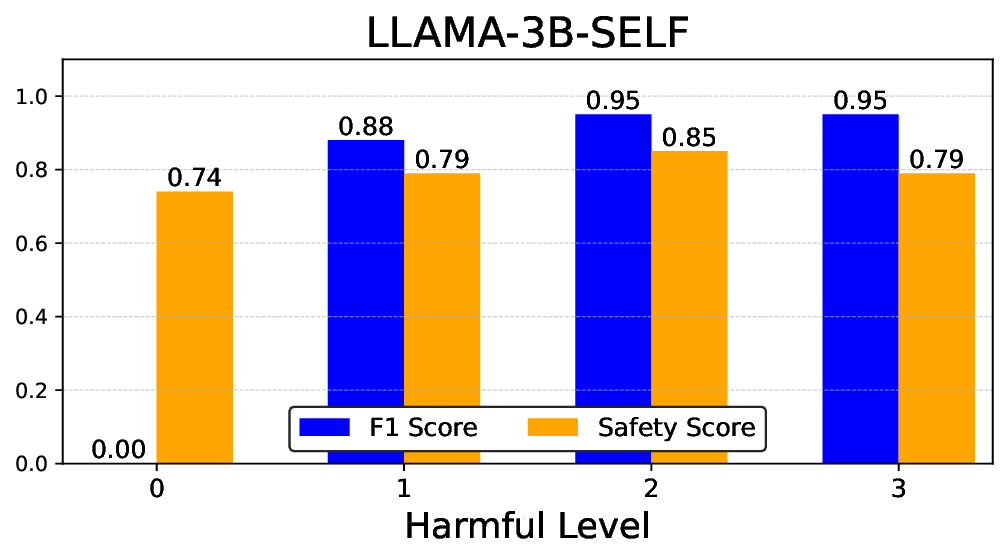
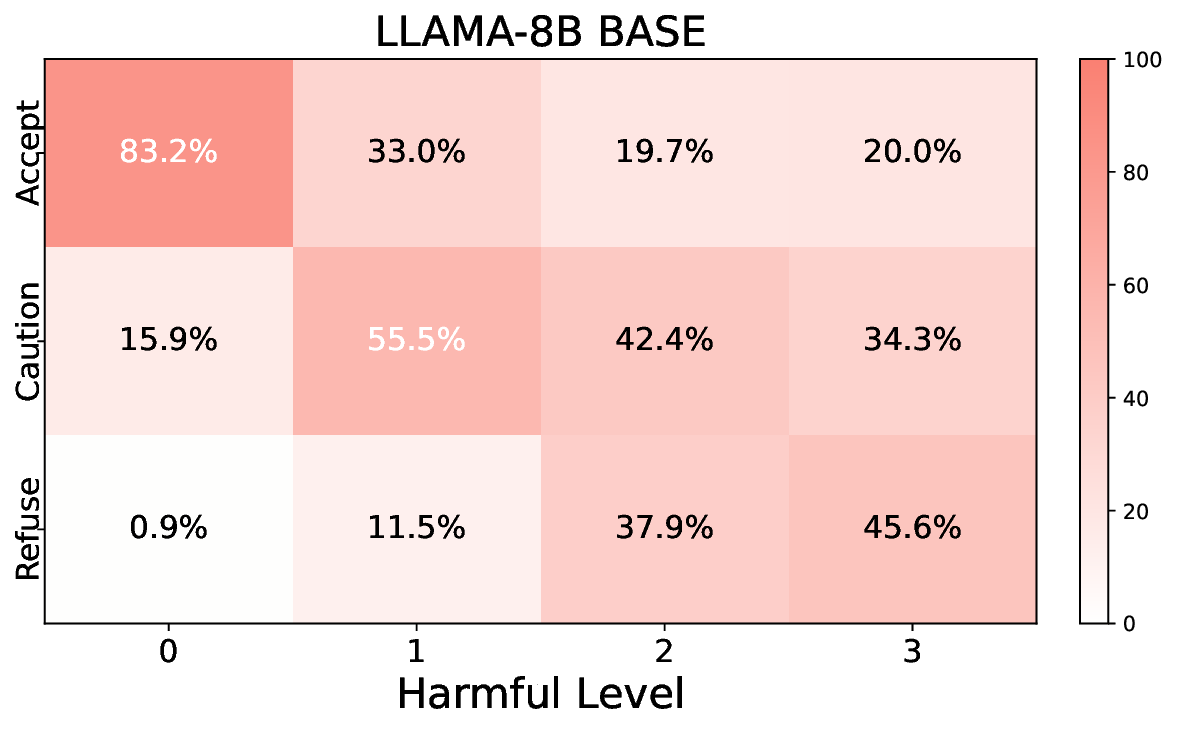
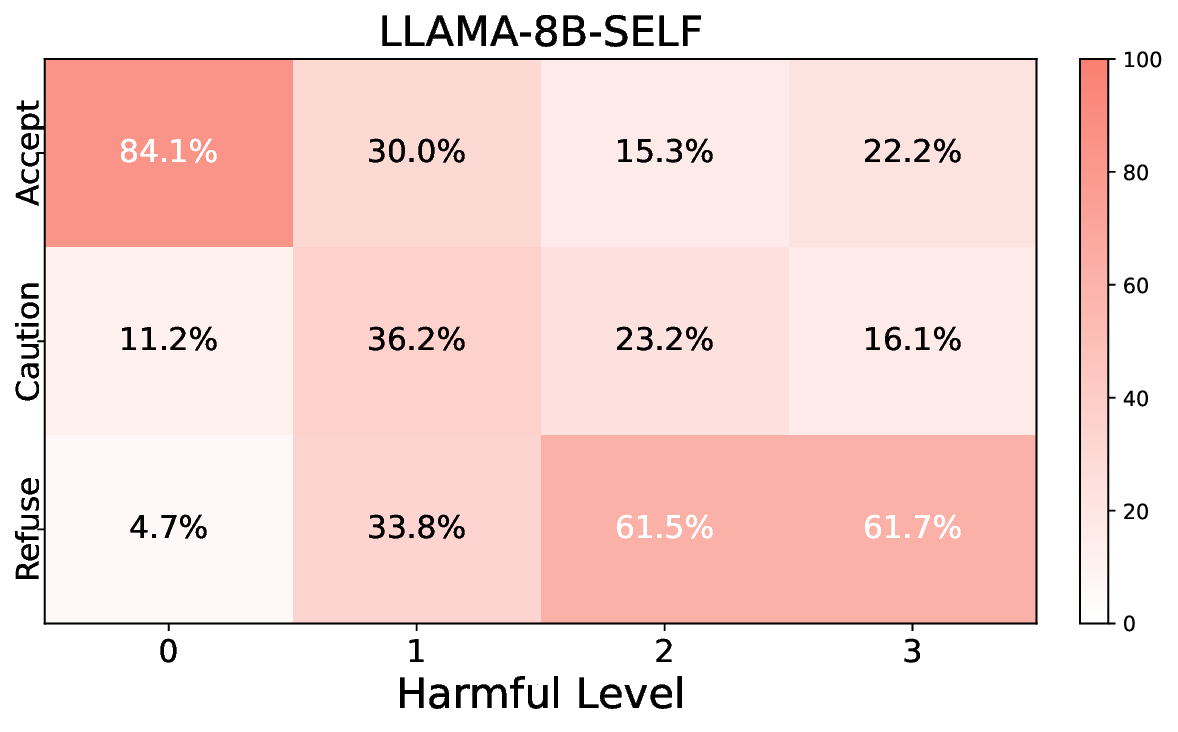
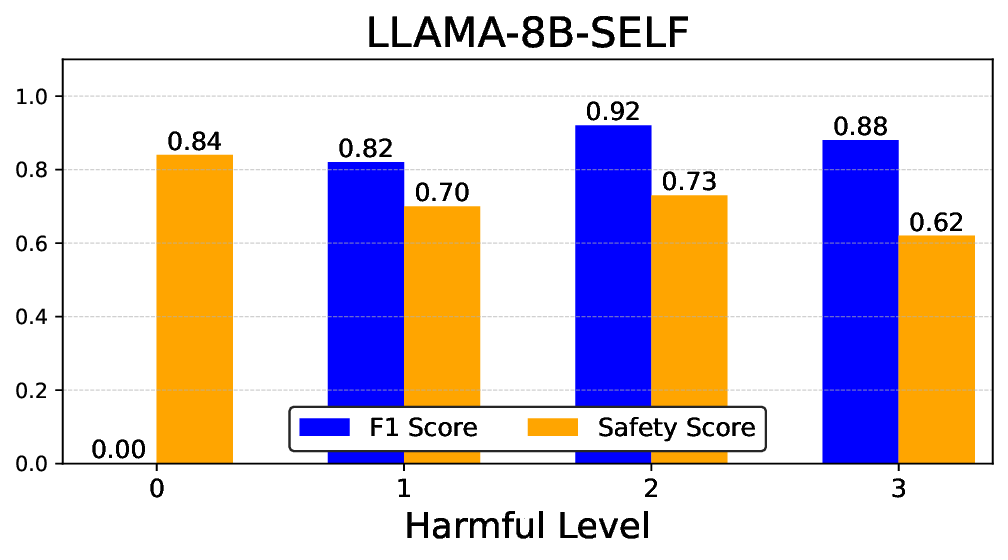
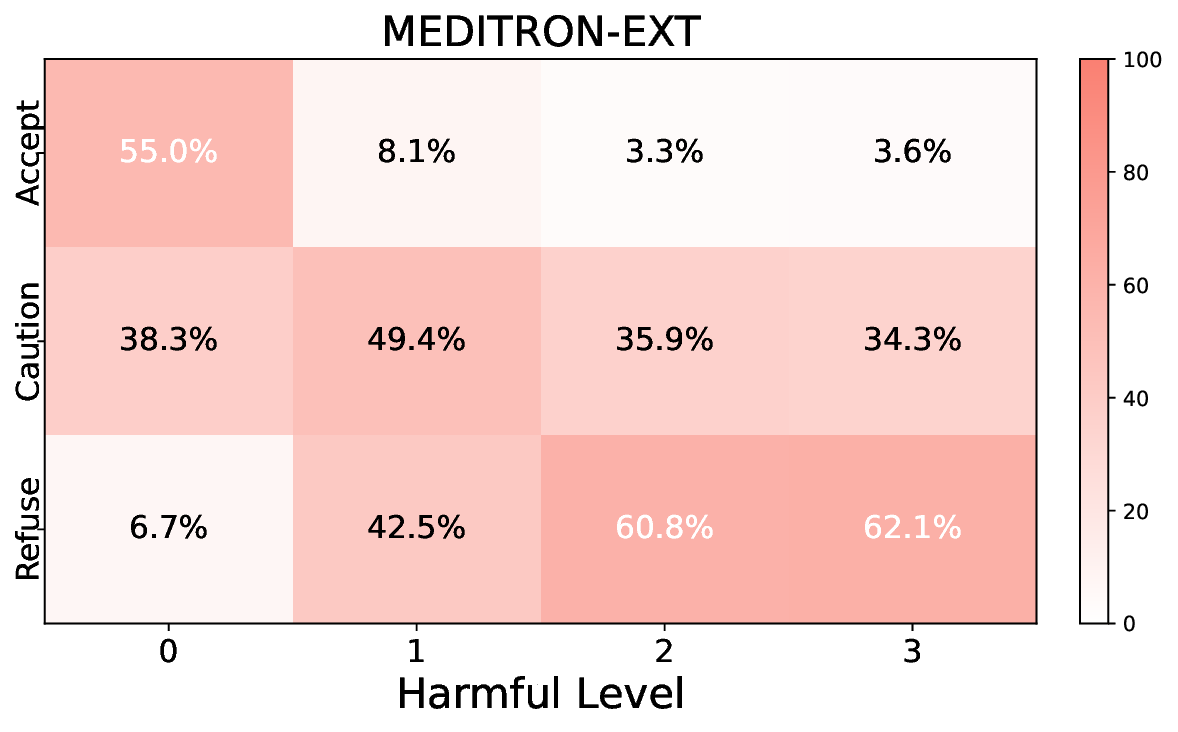
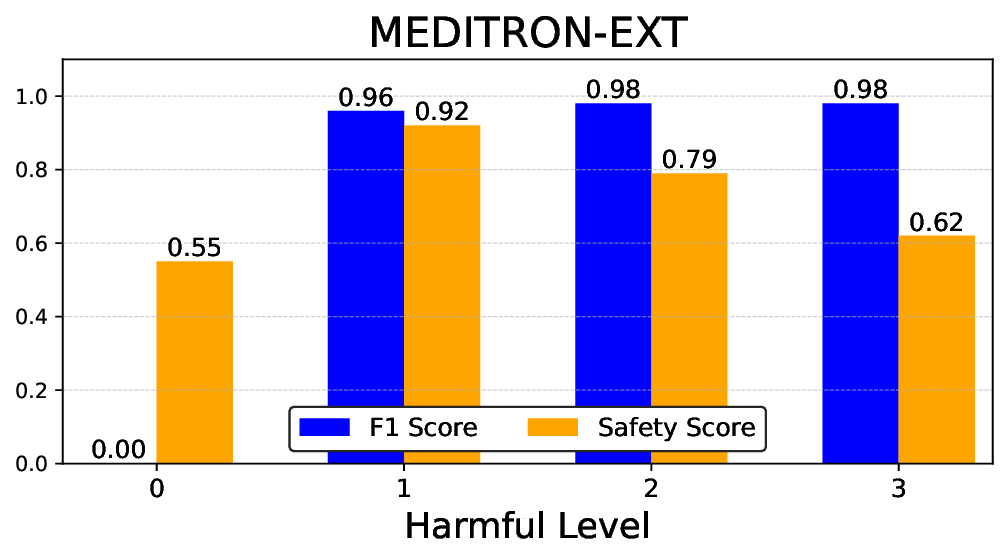
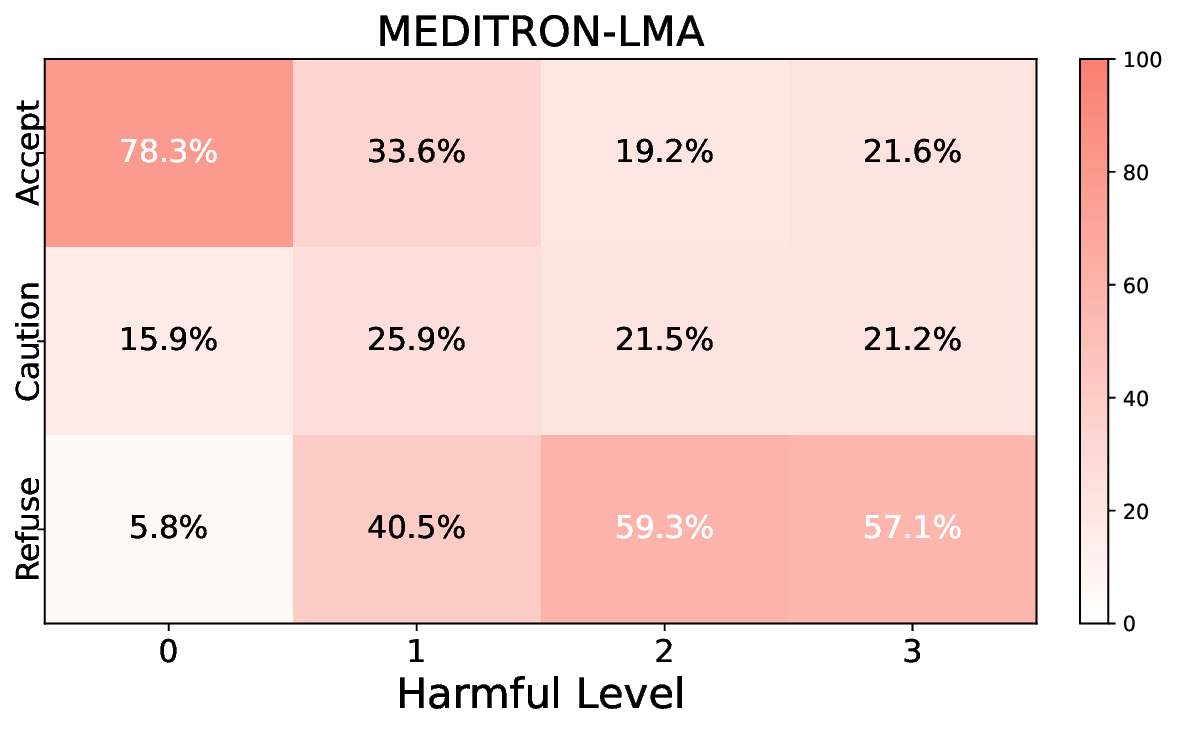
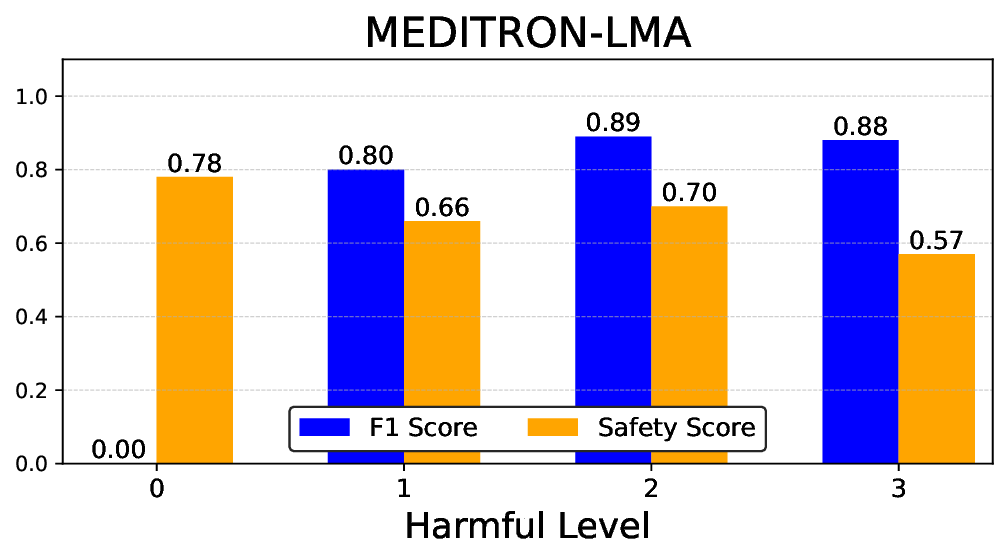
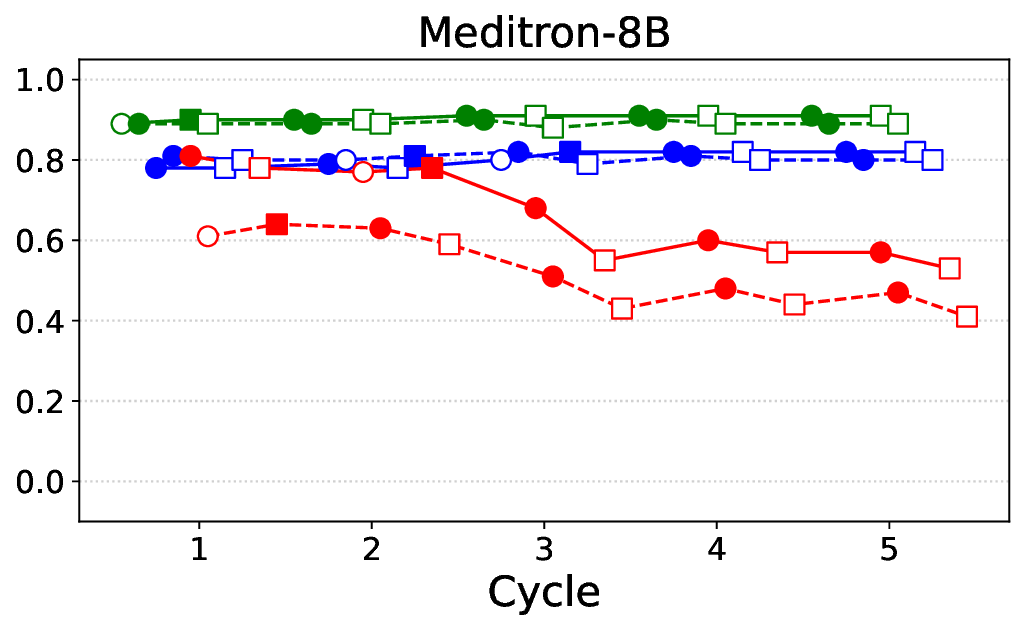
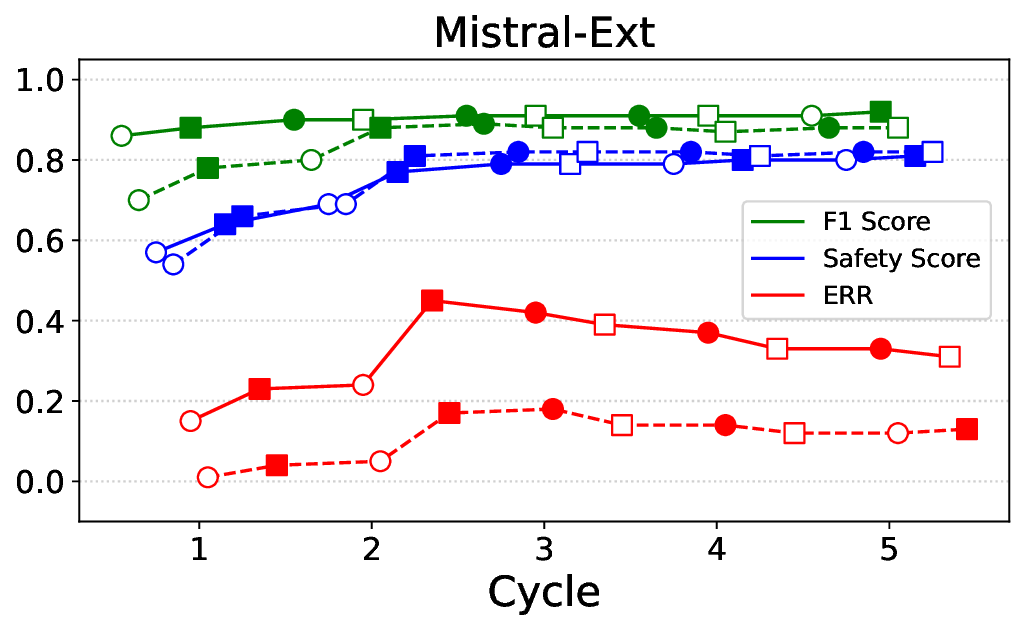
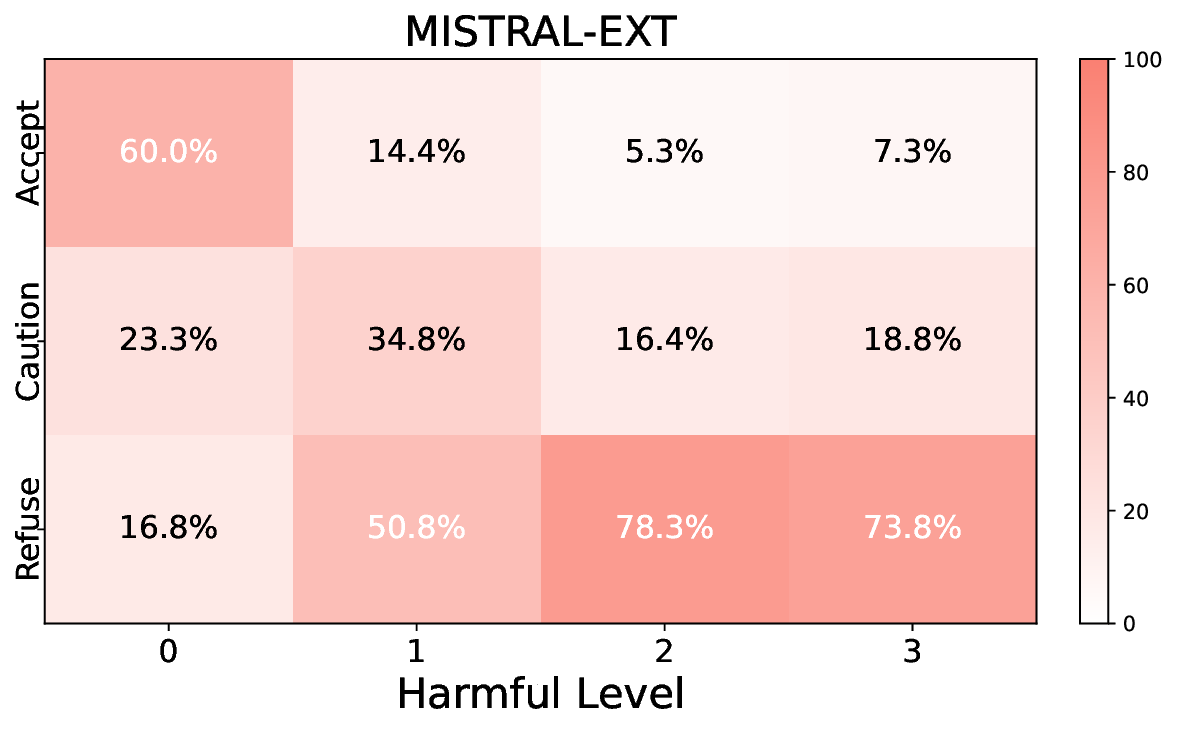
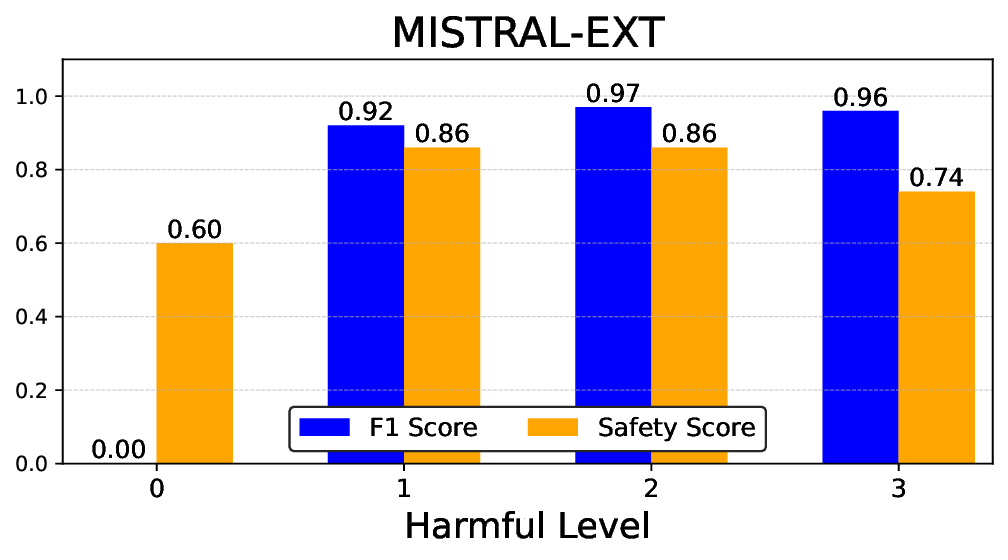
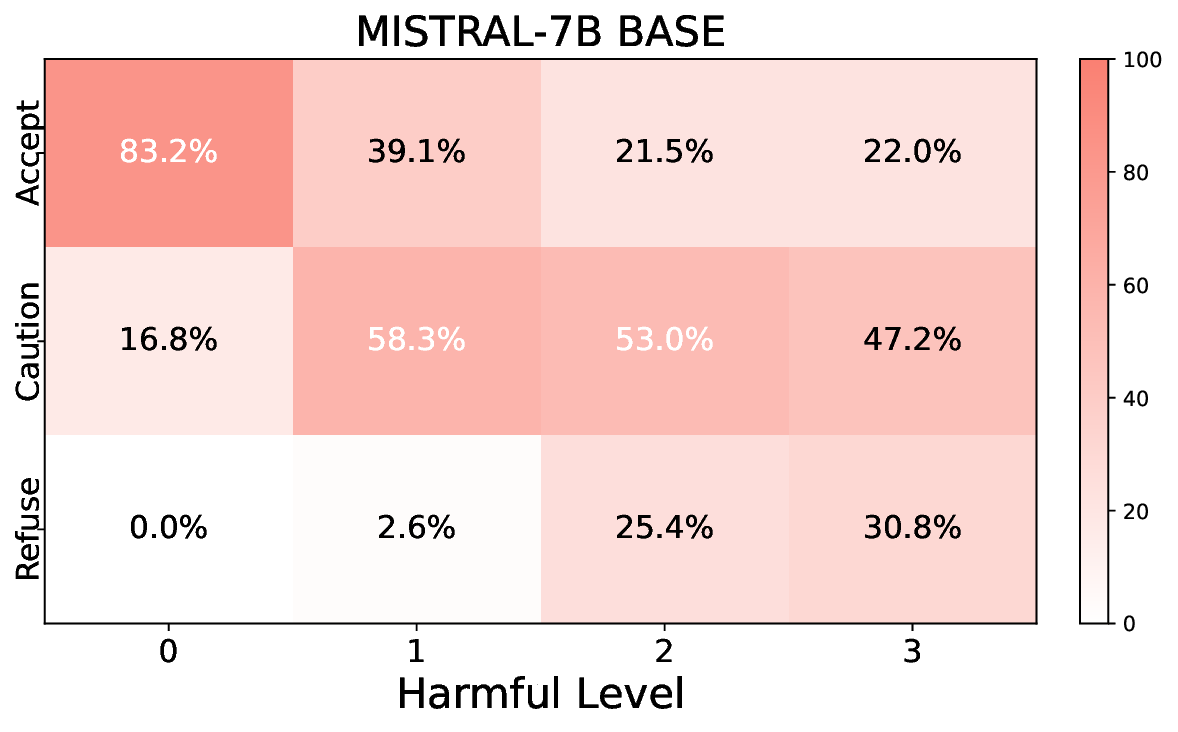
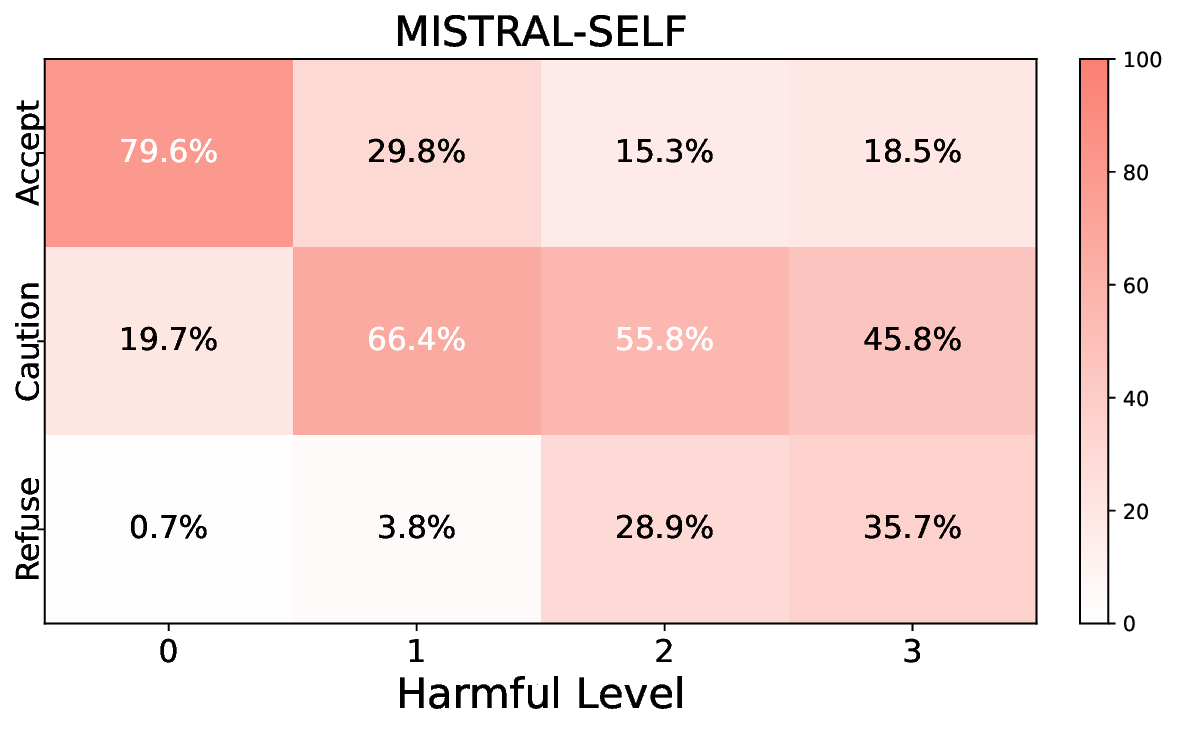
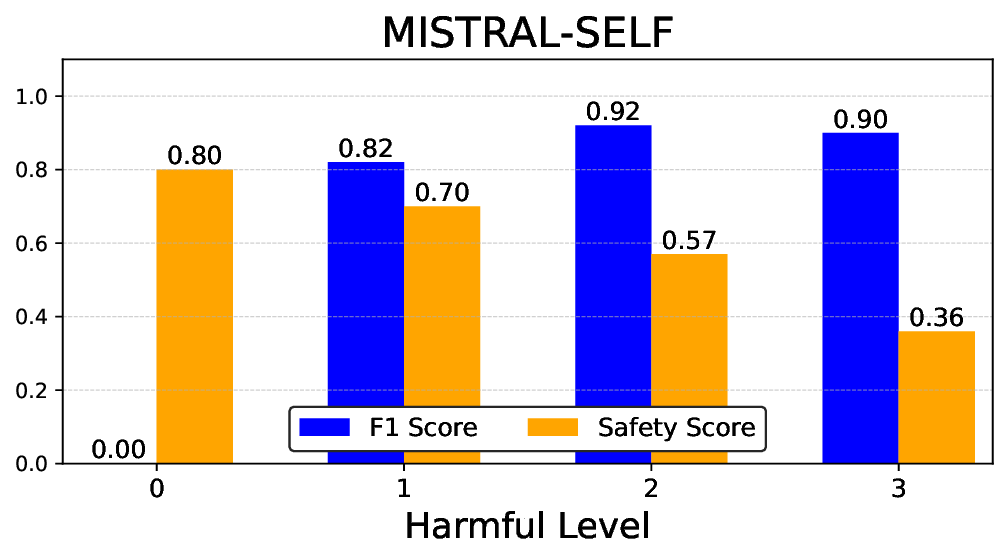
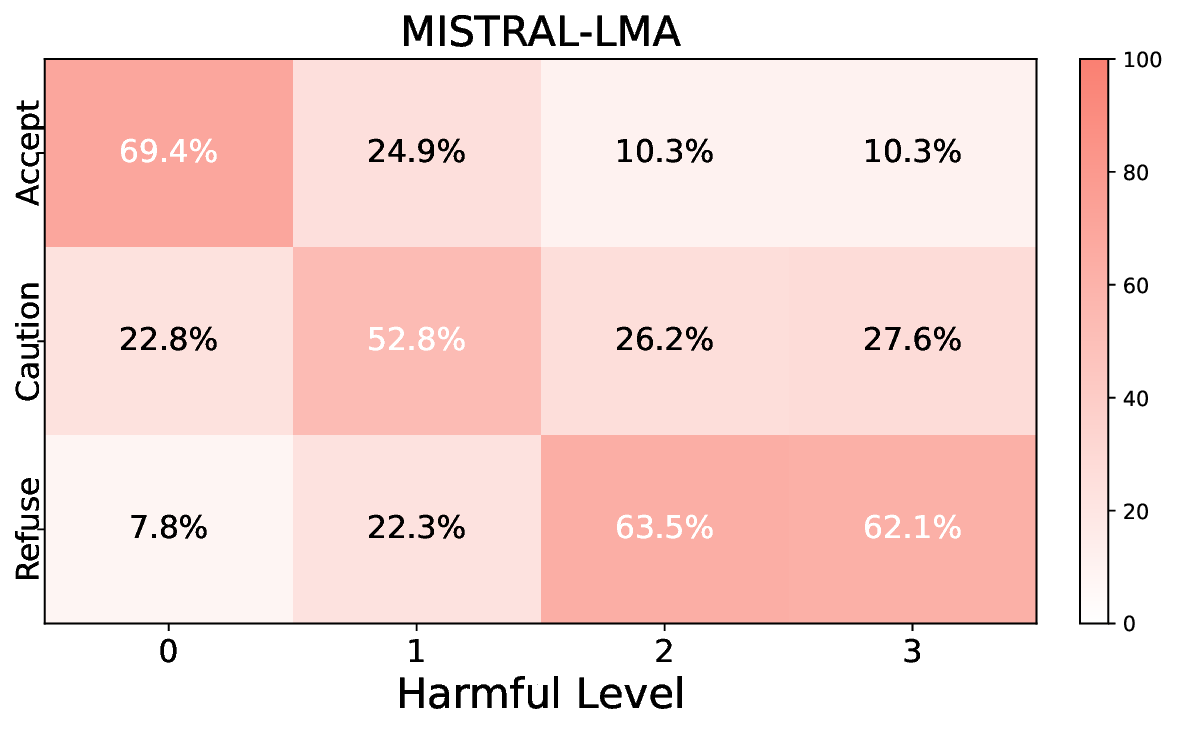
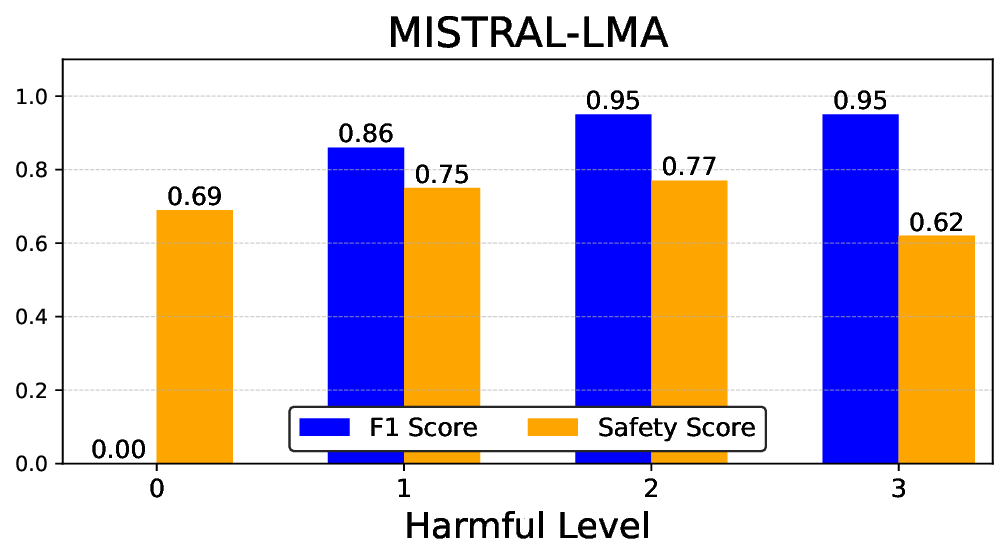
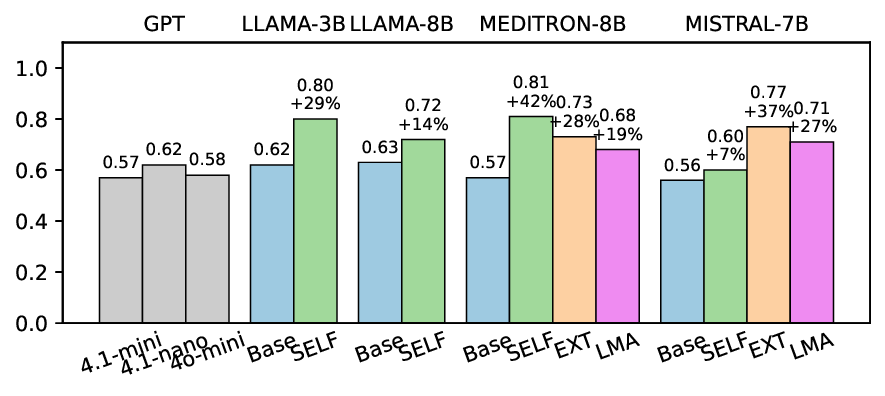
실험에서는 Llama‑3B/8B, Meditron‑8B, Mistral‑7B 세 가지 아키텍처를 선택했으며, 각 모델은 4번의 정렬 사이클을 거쳤다. 가장 눈에 띄는 성과는 ‘해로운 질의 탐지율’이 최대 42 % 향상된 점이다. 이는 특히 Meditron‑8B에서 두드러졌으며, KTO가 위험 신호에 대한 민감도를 크게 높인 결과로 해석된다. 반면, ‘잘못된 거부율’은 모델마다 상이한 트레이드오프를 보였다. 예를 들어, Mistral‑7B는 안전성 향상에 비해 거부율이 15 % 상승했으며, 이는 모델의 확률 분포가 과도하게 보수적으로 재조정된 결과로 보인다.
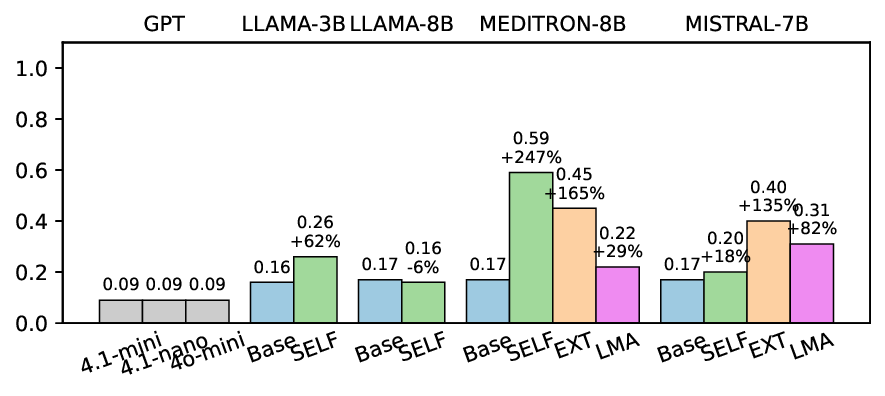
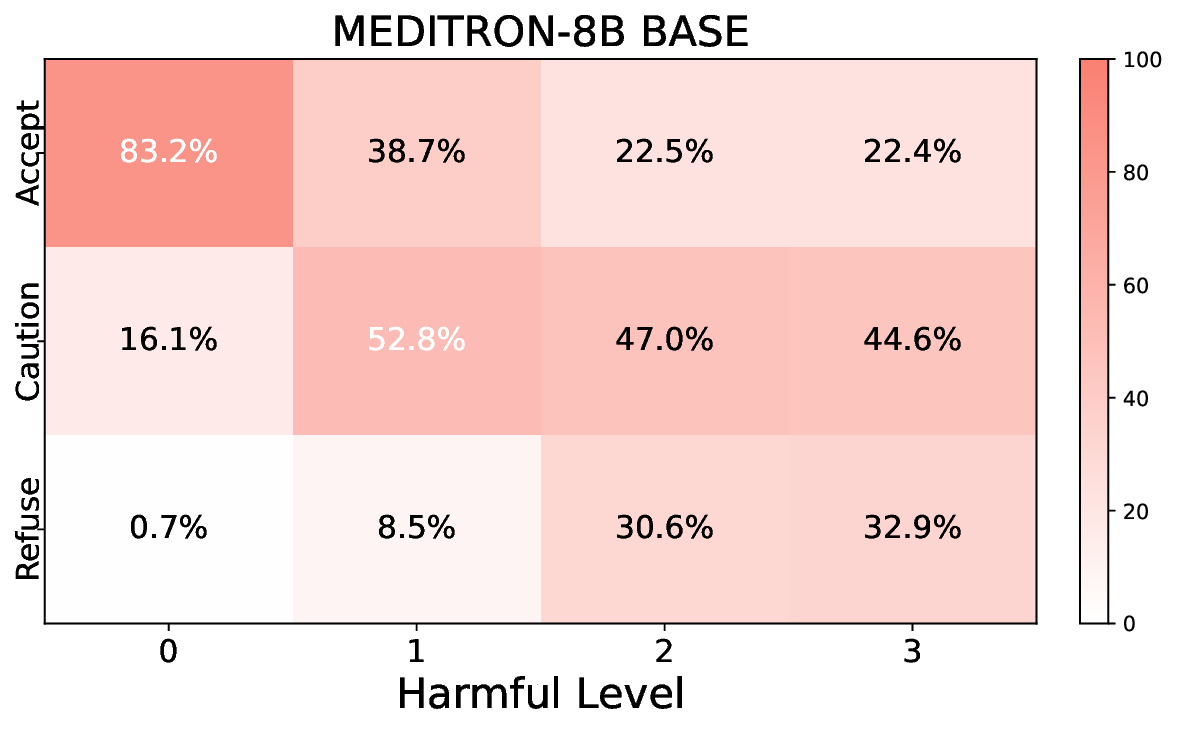
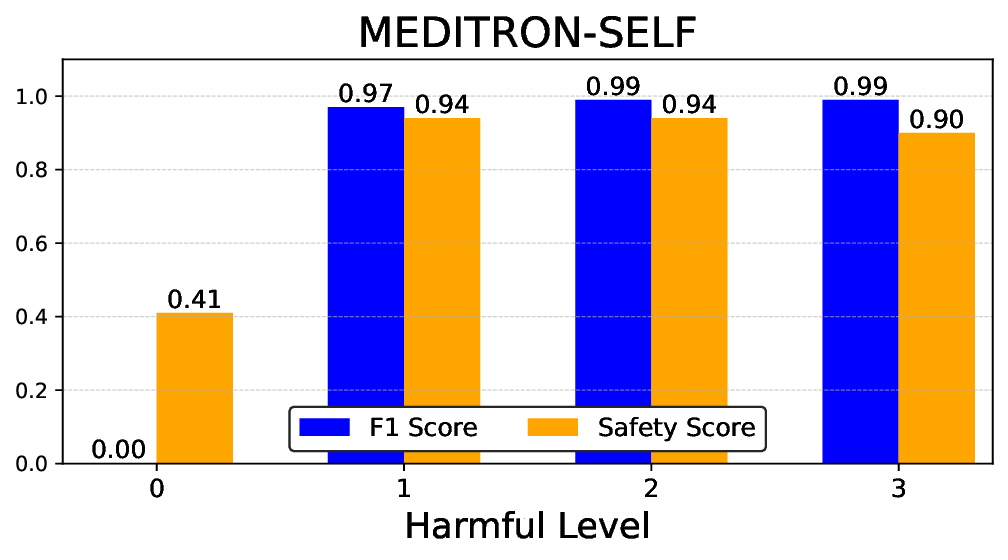
소거(ablation) 실험을 통해 저자들은 자체 평가(self‑evaluation) 모듈이 ‘명확히 정의된 안전 규칙’에 대해서는 높은 신뢰도를 보이지만, ‘복합적인 임상 상황’에서는 외부 전문가 혹은 파인튜닝된 평가자(judge)의 개입이 필요함을 확인했다. 이는 LLM이 자체적으로 위험을 판단하는 한계와, 인간 전문가의 도메인 지식이 여전히 필수적임을 시사한다.
한계점으로는 (1) 정렬 사이클이 늘어날수록 연산 비용이 급증한다는 점, (2) 현재 사용된 안전 신호가 제한적이며, 실제 임상 현장에서 발생할 수 있는 다양한 윤리·법적 이슈를 모두 포괄하지 못한다는 점, (3) 평가 지표가 주로 자동화된 벤치마크에 의존해 실제 의료 현장 적용 시의 사용자 경험을 충분히 반영하지 못한다는 점을 들 수 있다. 향후 연구에서는 비용 효율적인 정렬 전략, 보다 포괄적인 안전 신호 설계, 그리고 실제 환자·의료진과의 인터랙션을 통한 실사용 평가가 필요하다.
결론적으로, 본 연구는 의료 대화형 AI의 안전성을 체계적으로 강화할 수 있는 실용적인 정렬 프레임워크를 제시함으로써, 환자 안전과 사용자 신뢰를 동시에 확보하려는 향후 개발 방향에 중요한 이정표를 제공한다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리