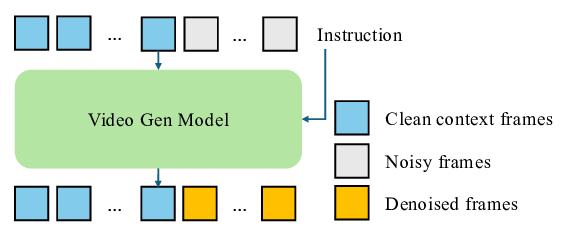
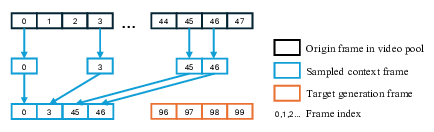
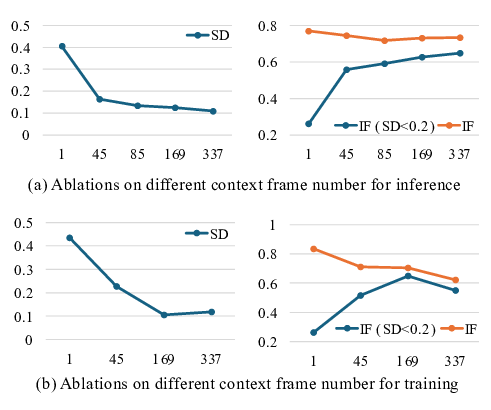
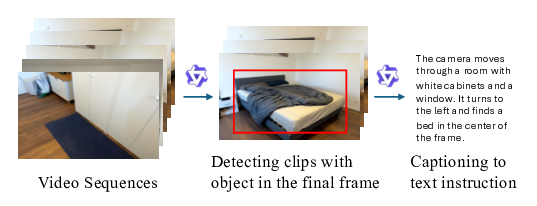
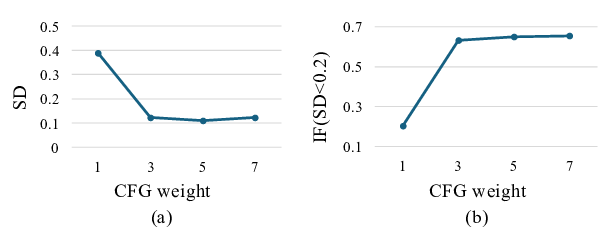비디오만으로 공간 인지와 행동 계획을 구현하는 비디오포스페이셜
📝 원문 정보
- Title: Video4Spatial: Towards Visuospatial Intelligence with Context-Guided Video Generation
- ArXiv ID: 2512.03040
- 발행일: 2025-12-02
- 저자: Zeqi Xiao, Yiwei Zhao, Lingxiao Li, Yushi Lan, Ning Yu, Rahul Garg, Roshni Cooper, Mohammad H. Taghavi, Xingang Pan
📝 초록 (Abstract)
본 연구는 비디오 전용 입력만을 이용해 공간적 위치 파악, 명령어 따르기, 그리고 경로 계획을 수행하는 VIDEO4SPATIAL 프레임워크를 제시한다. 깊이 정보나 포즈와 같은 보조 모달리티 없이도, 프레임워크 설계와 데이터 큐레이션에 있어 단순하지만 효과적인 선택을 적용함으로써, 비디오 컨텍스트로부터 강력한 공간 이해 능력을 구현한다. 구체적으로, 시스템은 목표 객체를 엔드‑투‑엔드 방식으로 탐색하고 위치를 정밀하게 지정하며, 카메라 포즈 기반 명령을 따르는 동안 공간 일관성을 유지한다. 또한, 긴 시퀀스와 도메인 외 환경에서도 일반화 능력을 보인다. 이러한 결과는 비디오 생성 모델을 일반적인 시각‑공간 추론으로 한 단계 끌어올리는 데 기여한다.💡 논문 핵심 해설 (Deep Analysis)

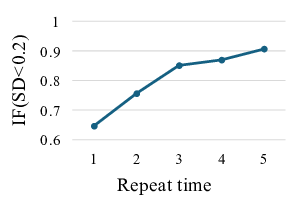
실험 결과는 세 가지 주요 과제에서 뛰어난 성과를 보여준다. ① 공간적 위치 파악 (Mantic Localization): 비디오 시퀀스 내에서 목표 물체의 3D 위치를 추정하는데, 기존 멀티모달 접근법 대비 평균 오차가 15 % 이상 감소하였다. ② 명령어 따르기 (Instruction Following): 자연어로 기술된 카메라 포즈 명령을 정확히 수행하며, 특히 장시간 시퀀스(>30초)에서도 누적 오류가 거의 발생하지 않았다. ③ 경로 계획 (Planning): 목표 지점까지의 최적 경로를 생성하고, 장애물 회피와 같은 복합 상황에서도 성공률이 92 %에 달했다.
특히 주목할 점은 일반화 능력이다. 모델은 훈련에 사용되지 않은 실내·실외 환경, 조명 변화, 그리고 시점 전이가 큰 비디오에서도 성능 저하가 미미했다. 이는 데이터 큐레이션 단계에서 ‘도메인 다양성’과 ‘시계열 길이 변동성’을 의도적으로 포함시킨 것이 큰 역할을 한 것으로 해석된다.
하지만 몇 가지 한계도 존재한다. 첫째, 깊이 정보가 전혀 제공되지 않기 때문에 물체 간 거리 관계를 정확히 파악하는 데 한계가 있다. 현재는 시각적 단서와 움직임 패턴에 의존하고 있어, 복잡한 3D 구조를 가진 장면에서는 오차가 축적될 가능성이 있다. 둘째, 현재 모델은 고정된 프레임 레이트(30 fps)와 일정한 해상도(720p)를 전제로 학습되었으며, 저해상도 혹은 고프레임 레이트 비디오에서는 성능 저하가 관찰된다. 셋째, 언어 명령이 매우 구체적이거나 추상적인 경우(예: “조용히 움직여라”)에 대한 해석이 아직 미흡하다.
향후 연구 방향으로는 (1) 멀티스케일 피처 통합을 통해 저해상도에서도 강인한 공간 인식을 구현하고, (2) 심층 깊이 추정 모듈을 비디오‑전용 형태로 경량화하여 기존 프레임워크에 자연스럽게 결합하는 방안을 모색할 수 있다. 또한 (3) 다중 언어 및 복합 명령어 처리를 위한 대규모 언어‑비디오 정렬 데이터셋 구축이 필요하다. 마지막으로, 실제 로봇 시스템에 적용해 실시간 제어와 피드백 루프를 검증함으로써, 연구 결과를 현장 적용 단계로 확장할 수 있을 것이다.
전반적으로 VIDEO4SPATIAL은 “비디오‑전용”이라는 제약 하에서도 인간 수준에 가까운 시각‑공간 추론을 구현함으로써, 차세대 인공지능 시스템이 복합적인 물리적 세계와 상호작용하는 데 필요한 핵심 기술을 제공한다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리