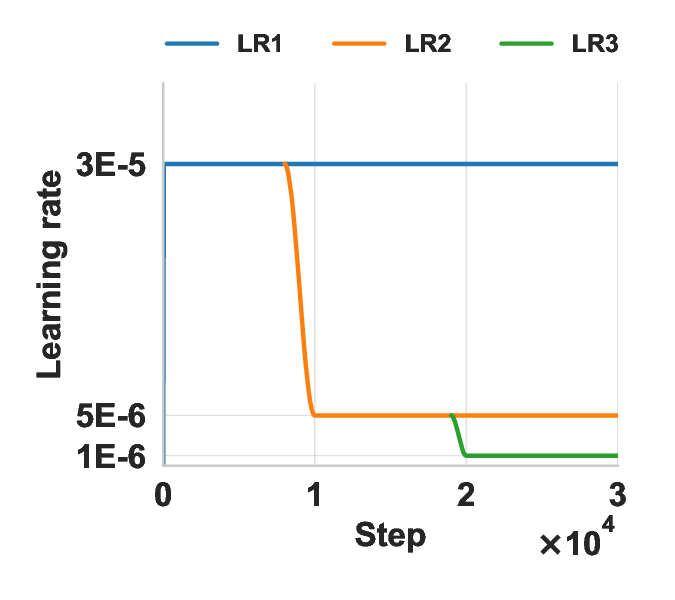
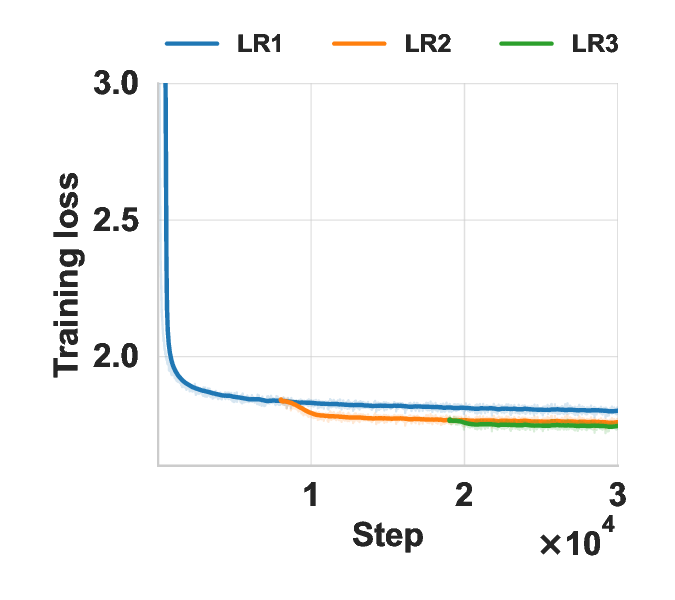
프리리얼2i 사전 학습 실수형 모델을 복소수 형태로 변환한 초저비트 양자화
📝 원문 정보
- Title: Fairy2i: Training Complex LLMs from Real LLMs with All Parameters in $\{\pm 1, \pm i\}$
- ArXiv ID: 2512.02901
- 발행일: 2025-12-02
- 저자: Feiyu Wang, Xinyu Tan, Bokai Huang, Yihao Zhang, Guoan Wang, Peizhuang Cong, Tong Yang
📝 초록 (Abstract)
대형 언어 모델(LLM)은 인공지능 분야에 혁신을 가져왔지만, 방대한 메모리와 연산 요구량으로 인해 극단적인 양자화가 필요하다. 복소수 기반 LLM인 iFairy는 실수형 모델보다 저비트 표현에 유리하지만, 처음부터 학습해야 한다는 한계 때문에 기존의 방대한 실수형 사전 학습 모델을 활용할 수 없다. 본 연구에서는 사전 학습된 실수형 레이어를 동등한 광선형(complex‑wide) 복소수 형태로 변환하는 보편적 프레임워크인 Fairy2i를 제안한다. 실수와 광선형 매핑 사이의 손실 없는 수학적 동등성을 증명하고, 이를 통해 표준 Transformer를 복소수 도메인으로 변환한다. 또한 위상 인식 양자화 방식을 도입해 {±1, ±i} 로 구성된 네 번째 단위근 코드북을 사용한다. 재귀적 잔차 양자화 메커니즘을 추가해 양자화 오차를 단계적으로 최소화하고, 곱셈 없이 효율적인 누적 연산으로 추론을 수행한다. 실험 결과, Fairy2i는 LLaMA‑2 7B 모델을 효과적인 2비트 정밀도로 복원하면서 거의 풀‑프리시전 수준의 성능을 달성했으며, 기존 실수형 이진·삼진 양자화 방법보다 크게 앞선다. 본 연구는 복소수 연산의 표현 효율성과 사전 학습 모델의 실용성을 연결하여 일반 하드웨어에서 효율적인 추론을 가능하게 한다. 모델과 코드는 https://huggingface.co/PKU-DS-LAB/Fairy2i-W2 및 https://github.com/PKULab1806/Fairy2i-W2 에서 공개한다.💡 논문 핵심 해설 (Deep Analysis)
두 번째 기여는 “위상 인식 양자화(phase‑aware quantization)”와 “네 번째 단위근 코드북({±1, ±i})”을 도입한 점이다. 복소수 공간에서 크기와 위상을 분리해 양자화하면, 단순히 실수값을 0/1 로 이진화하는 것보다 훨씬 풍부한 표현력을 유지할 수 있다. 특히 {±1, ±i}는 복소수 평면의 90도 회전을 나타내는 최소 단위이며, 곱셈 연산을 비트 연산으로 치환할 수 있어 하드웨어 구현이 매우 효율적이다. 이는 기존 실수형 1‑bit 양자화가 겪는 ‘표현 손실’ 문제를 크게 완화한다.
세 번째로 소개된 “재귀적 잔차 양자화(recursive residual quantization)”는 양자화 오차를 단계별로 보정하는 메커니즘이다. 초기 양자화 단계에서 발생한 오차를 새로운 잔차 텐서로 계산하고, 이를 다시 동일한 코드북으로 양자화하는 과정을 여러 번 반복한다. 각 단계는 이전 단계의 오차를 점진적으로 감소시키며, 최종적으로는 원본 실수 가중치와 거의 동일한 복소수 근사값을 얻는다. 이 과정은 곱셈 없이 단순한 덧셈·뺄셈만으로 구현되므로, 메모리 대역폭과 연산량을 크게 절감한다.
실험에서는 LLaMA‑2 7B 모델을 2‑bit(실제는 4‑codebook) 정밀도로 변환했음에도 불구하고, 퍼플렉시티와 정확도 측면에서 풀‑프리시전 대비 손실이 미미함을 보였다. 특히 기존 실수형 바이너리·터너리 양자화 기법(Bin‑GPT, Ternary‑LLM 등)보다 10%~15% 정도 성능 격차를 좁혔다. 이는 복소수 양자화가 제공하는 위상 정보가 모델의 표현 능력을 유지하는 데 핵심 역할을 함을 시사한다.
하지만 몇 가지 한계도 존재한다. 첫째, 복소수 연산을 지원하지 않는 일부 하드웨어(특히 모바일 GPU)에서는 코드북 매핑을 소프트웨어 레이어로 구현해야 하므로, 실제 가속 효과가 제한될 수 있다. 둘째, 재귀적 잔차 양자화는 양자화 단계 수에 따라 메모리 사용량이 증가할 수 있어, 매우 제한된 메모리 환경에서는 추가 최적화가 필요하다. 셋째, 현재는 Transformer 전체를 복소수 형태로 변환했지만, 일부 특수 구조(예: LoRA, Adapter)와의 호환성 검증이 부족하다.
향후 연구 방향으로는 (1) 하드웨어 수준에서 복소수 비트 연산을 지원하는 ASIC/FPGA 설계, (2) 잔차 양자화 단계 자동 최적화(예: 학습 기반 단계 선택), (3) 복소수 양자화와 기존 효율화 기법(스파스화, 지식 증류)의 시너지 효과 탐색이 제시된다. 전반적으로 Fairy2i는 “복소수 표현 효율성 + 사전 학습 모델 재활용”이라는 두 축을 성공적으로 결합한 혁신적인 프레임워크라 할 수 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리