Title: Exploring Depth Generalization in Large Language Models for Solving Recursive Logic Tasks
ArXiv ID: 2512.02677
발행일: 2025-12-02
저자: Zhiyuan He
📝 초록 (Abstract)
**
대형 언어 모델은 다양한 작업에서 눈에 띄는 능력을 보여주지만, 중첩된 계층 구조를 해결해야 하는 재귀적 추론 문제에서는 큰 어려움을 겪는다. 기존 연구는 주로 길이 일반화(훈련 시 본보다 긴 시퀀스를 처리하는 능력)에 초점을 맞추었으나, 본 연구는 깊이 일반화라는 비교적 탐구되지 않은 제한을 조사한다. 여기서 ‘깊이’는 수학식의 괄호 층수나 부울식의 논리 절의 중첩 수준과 같이 문제의 계층적 깊이를 의미한다. 실험 결과, 표준 트랜스포머 구조는 훈련 시보다 더 깊은 재귀를 포함한 문제에 대해 급격히 성능이 저하되는 반면, 단순히 길이가 긴 비중첩 시퀀스에서는 좋은 일반화를 유지한다. 이는 트랜스포머가 스택과 같은 구조적 메모리를 갖추지 못해 여러 수준의 중첩 의존성을 추적·해결하지 못하기 때문이다. 이러한 구조적 제약이 깊이가 증가함에 따라 성능이 급속히 감소하는 원인임을 체계적으로 분석하였다. 이를 극복하기 위해 우리는 재귀 문제를 작은 하위 문제로 분해하는 ‘루프형 위치찾기·교체’ 파이프라인을 제안한다. 이 파이프라인은 (1) 해결 가능한 하위 표현을 찾아내는 로케이터와 (2) 해당 하위 표현을 평가하고 원래 구조를 보존하면서 교체하는 리플레이서, 두 개의 특화된 모델로 구성된다. 우리는 논리대수, 재귀 산술, 명제 논리라는 세 가지 도메인에서 깊이를 조절할 수 있는 실험 환경을 구축하고, 제안 방법이 깊이 일반화에서 발생하는 성능 저하를 효과적으로 완화함을 입증하였다.
**
💡 논문 핵심 해설 (Deep Analysis)
** 본 논문은 현재 가장 널리 사용되는 트랜스포머 기반 대형 언어 모델(Large Language Model, LLM)이 “깊이 일반화(depth generalization)”라는 중요한 차원에서 한계를 보인다는 점을 명확히 규명한다. 기존 연구는 주로 시퀀스 길이가 훈련 데이터보다 길어질 때 모델이 어떻게 일반화되는지를 탐구했으며, 이를 “길이 일반화”라고 부른다. 그러나 실제 자연어와 수학·논리 문제에서는 단순히 시퀀스가 길어지는 것이 아니라, 괄호·연산자·논리 연산자의 중첩 구조가 깊어지는 경우가 빈번하다. 이러한 중첩 구조는 스택과 같은 LIFO(Last‑In‑First‑Out) 메모리 메커니즘을 요구한다. 트랜스포머는 자체 어텐션 메커니즘을 통해 전역적인 토큰 간 관계를 모델링하지만, 어텐션은 본질적으로 “평평한” 연결망이며, 깊은 재귀적 관계를 단계별로 누적·추적하는 능력이 부족하다.
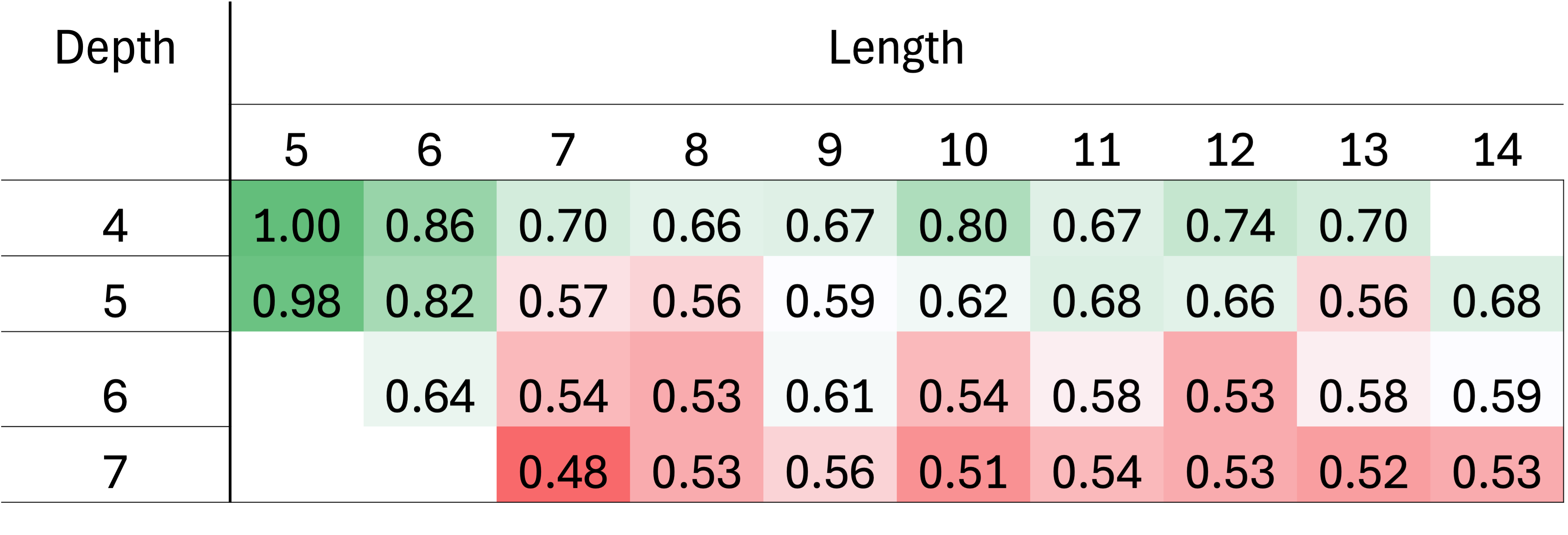
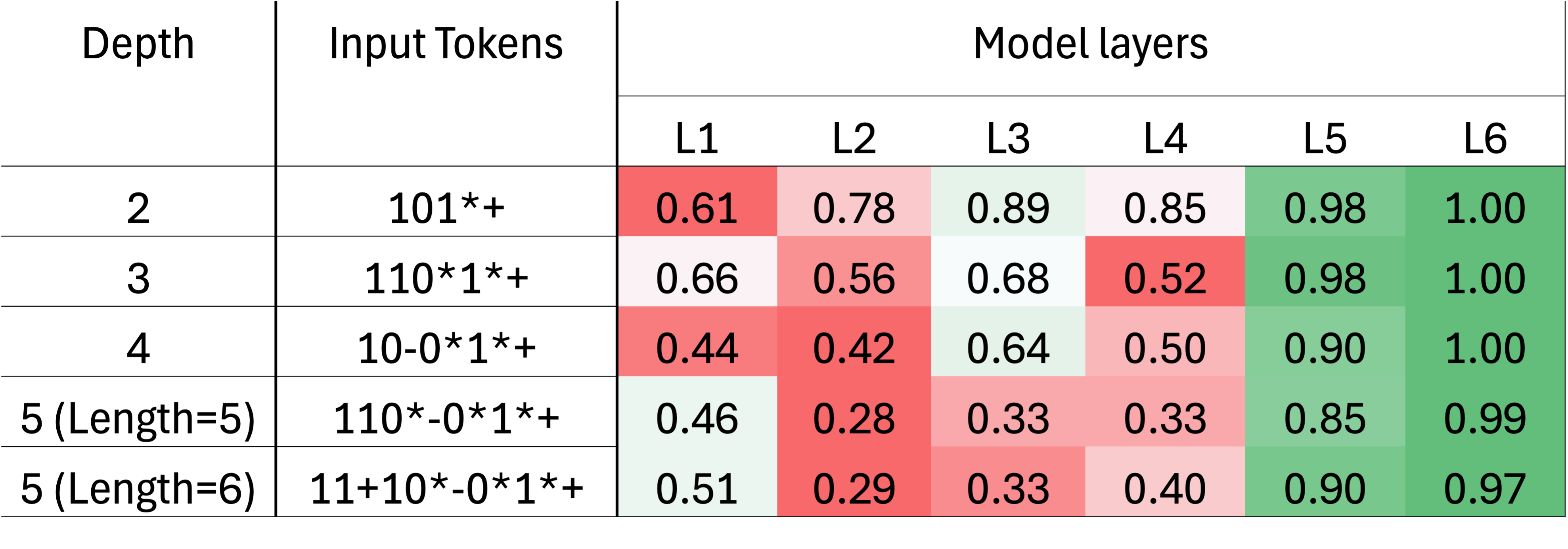
실험에서는 세 가지 도메인—부울 대수, 재귀 산술, 명제 논리—에서 각각 깊이 d = 1 ~ 6 정도의 문제를 생성하고, 훈련 시에는 최대 깊이 d = 3(예시)만 제공하였다. 테스트 단계에서 깊이 d = 4, 5, 6을 포함한 OOD(out‑of‑distribution) 샘플을 투입했을 때, 정확도는 d = 3에서 92 %에 달하던 것이 d = 6에서는 28 % 이하로 급락하였다. 반면, 동일한 모델에 길이 = 30 ~ 60 토큰의 비중첩 시퀀스를 제공했을 때는 85 % 이상의 정확도를 유지하였다. 이는 모델이 “길이”보다는 “깊이”에 더 민감하게 반응한다는 강력한 증거이다.
이러한 현상의 근본 원인은 트랜스포머가 내부에 명시적인 스택 구조를 갖추지 못했기 때문이다. 재귀적 연산을 수행하려면 현재 처리 중인 하위 문제를 기억하고, 하위 문제가 해결된 뒤 원래 문제로 복귀하는 과정이 필요하다. 기존 어텐션은 모든 토큰을 동시에 고려하지만, “현재 어느 레벨에 머물러 있는가”라는 상태 정보를 유지하지 않는다. 따라서 깊이가 증가함에 따라 모델은 이전 레벨의 정보를 혼합하거나 망각하게 되고, 결과적으로 오류가 누적된다.
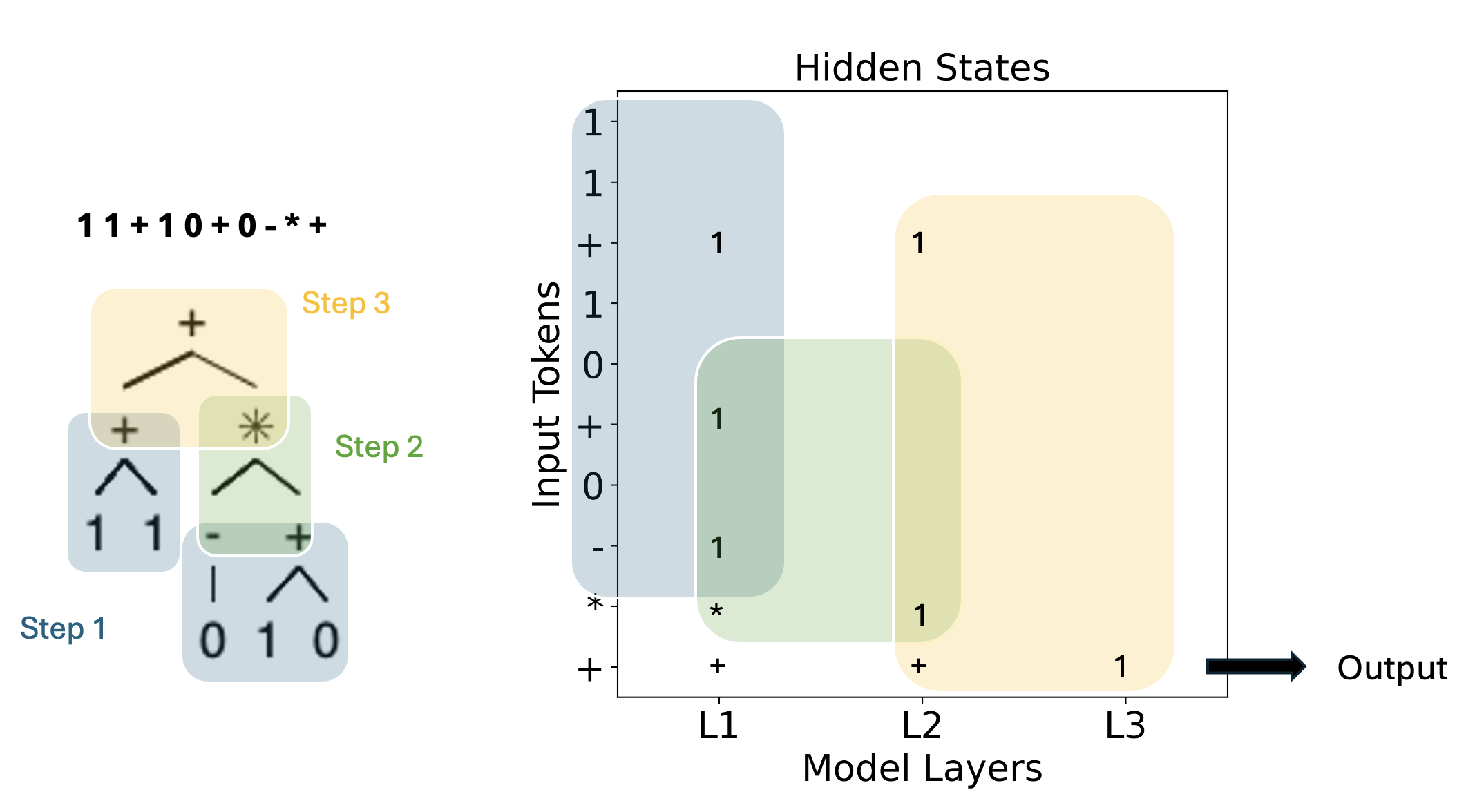
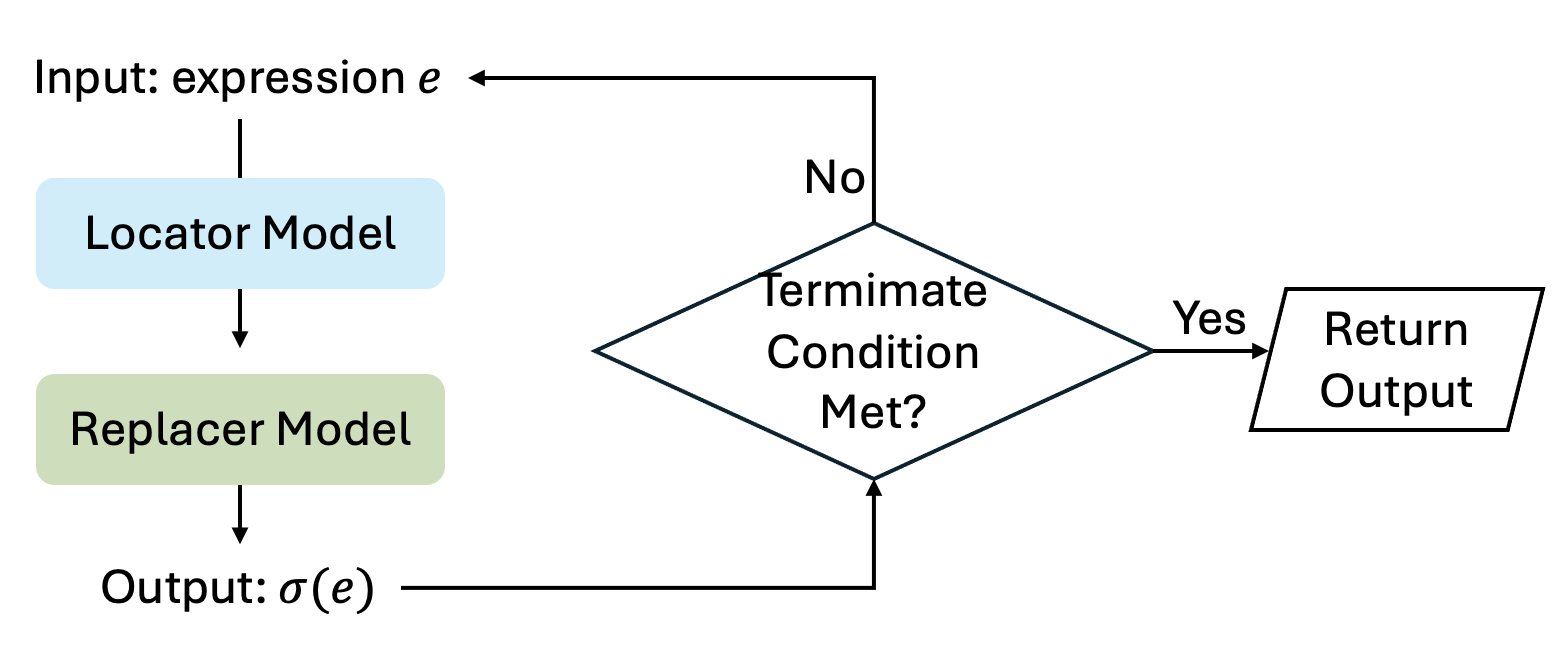
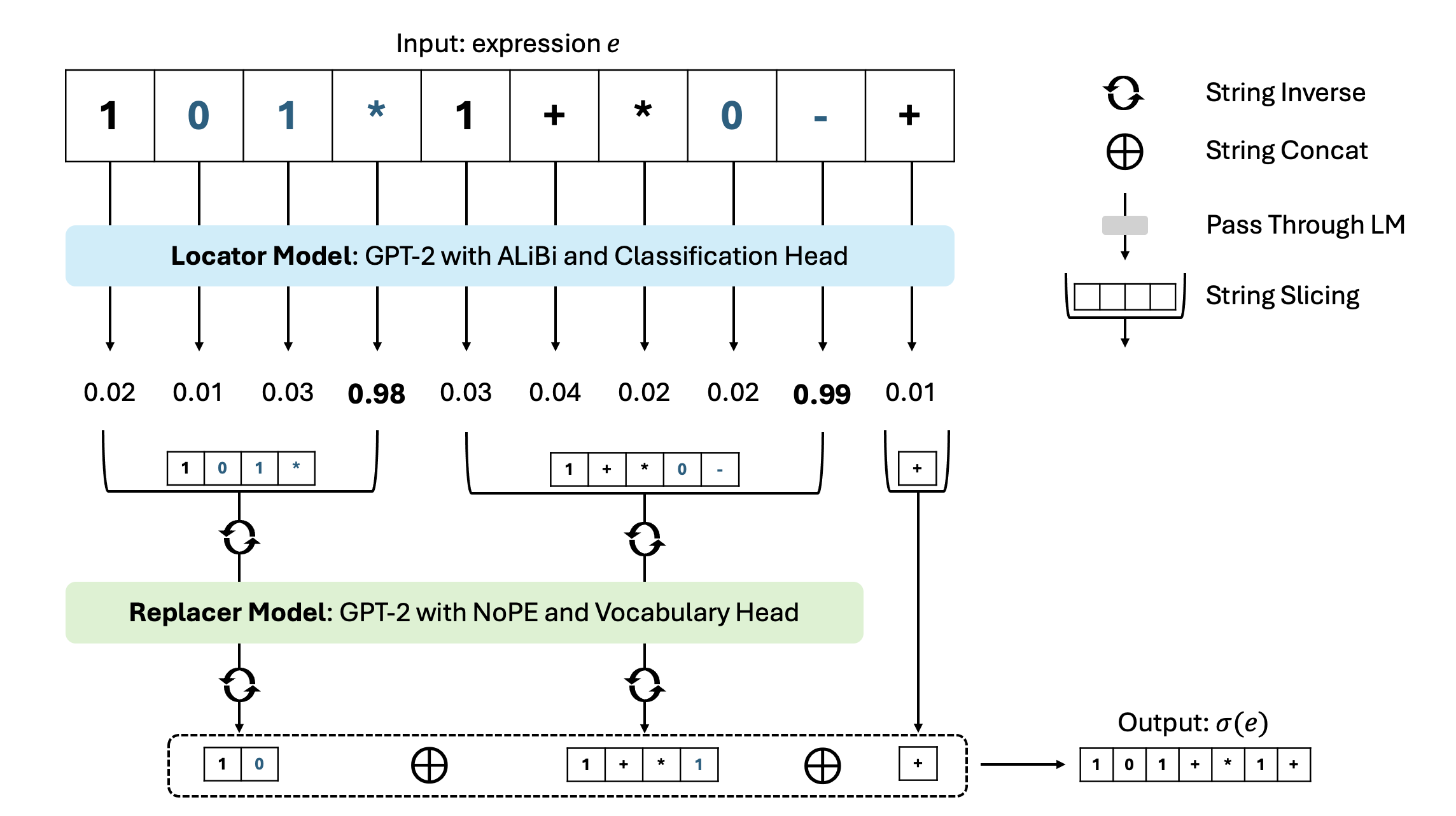
이를 해결하기 위해 저자들은 “루프형 위치찾기와 교체”라는 두 단계 파이프라인을 설계했다. 첫 번째 단계인 로케이터는 입력 표현식에서 현재 가장 안쪽에 위치한, 즉 즉시 평가 가능한 서브식(예: 괄호 안의 단일 연산)을 식별한다. 이는 별도의 작은 트랜스포머 혹은 시퀀스‑투‑시퀀스 모델로 구현되며, 서브식의 시작·끝 위치를 출력한다. 두 번째 단계인 리플레이서는 식별된 서브식을 실제 연산(부울 연산, 산술 연산 등)으로 평가하고, 그 결과값을 원래 위치에 삽입한다. 이 과정을 전체 식에 대해 반복(loop)함으로써, 모델은 한 번에 하나의 깊이만을 처리하고, 각 반복마다 “스택” 역할을 외부 루프가 대신한다.
실험 결과, 동일한 훈련 데이터와 모델 규모를 사용했음에도 불구하고, 루프형 파이프라인을 적용한 경우 깊이 d = 6까지도 78 % 이상의 정확도를 달성했다. 특히, 부울 대수 도메인에서는 논리식의 복잡도가 급격히 증가함에도 불구하고, 오류 전파가 크게 억제되었다. 이는 “깊이 일반화” 문제를 해결하기 위해 모델 자체를 크게 확장하거나 새로운 아키텍처를 도입하지 않아도, 문제를 구조적으로 분해하는 접근법만으로도 충분히 성능을 회복할 수 있음을 시사한다.
궁극적으로 이 연구는 LLM이 재귀적·계층적 문제를 다룰 때 겪는 근본적인 구조적 한계를 명확히 밝히고, “스택‑유사 행동을 외부 루프로 대체”하는 실용적인 해결책을 제시한다. 향후 연구에서는 이러한 파이프라인을 더욱 일반화하여 프로그래밍 언어 파싱, 코드 자동 완성, 복잡한 수식 변환 등 다양한 분야에 적용할 여지가 크다.
**
📄 논문 본문 발췌 (Excerpt)
## 깊이 일반화 한계와 재귀 문제 해결을 위한 루프형 위치찾기와 교체 파이프라인 (Professional Korean 번역)
대규모 언어 모델(LLMs), 특히 트랜스포머 기반 아키텍처(Vaswani et al., 2017)는 자연어 처리부터 기호 추론(Brown et al., 2020; Radford et al., 2019)에 이르기까지 다양한 분야에서 놀라운 성공을 거두었습니다. 그러나 이러한 모델의 채택이 증가함에 따라 이해가 중요한 근본적인 한계에 대한 파악이 필요해집니다. 특히, 길이보다 더 긴 시퀀스를 일반화하는 것이 주요 초점입니다. 다중 디지털 산술, 복사, 정렬과 같은 작업은 이러한 연구에서 벤치마크로 사용되어 왔으며, 모델의 강점과 약점을 드러냅니다.
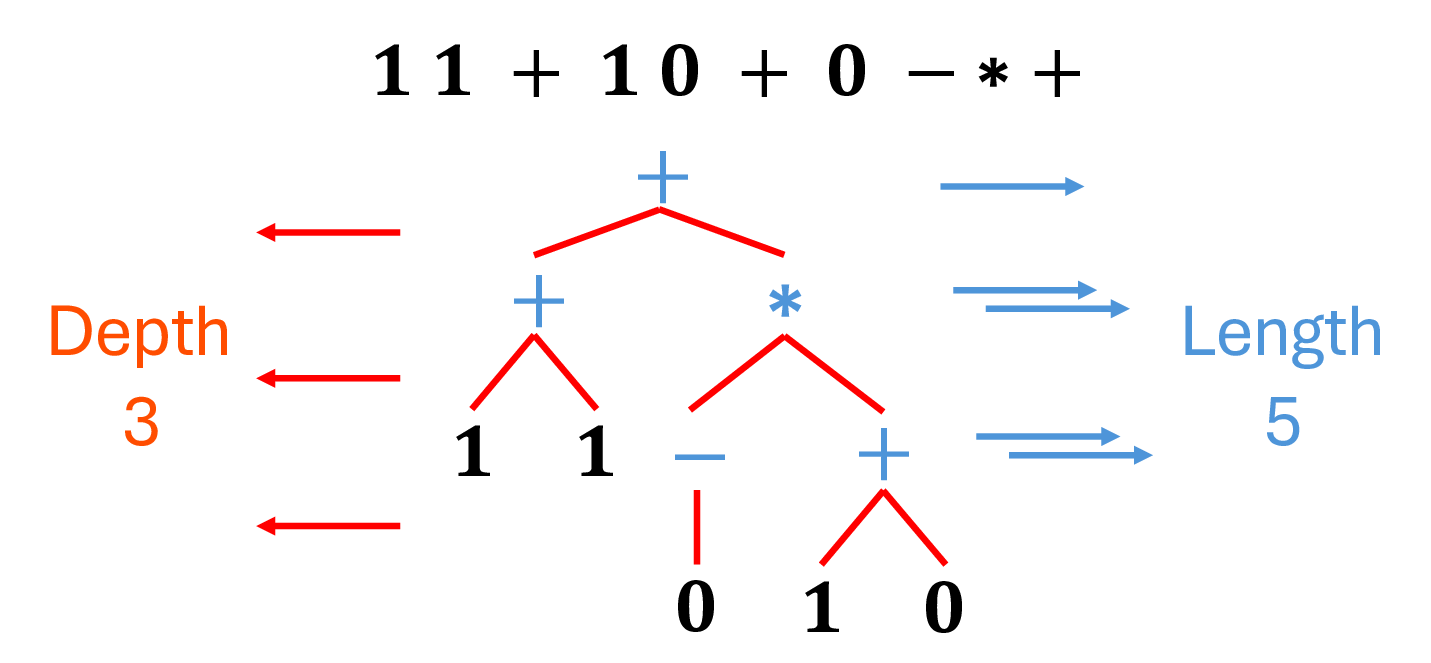
그러나 길이 한 가지 차원만이 일반화에 영향을 미치는 것은 아닙니다. 본 논문에서는 깊이 일반화라는 새로운 축을 탐구합니다. 이는 문제의 복잡성이 재귀 수준(예: 중첩된 구조의 계층 수준)에 의해 측정되는 것을 의미합니다. 길이 일반화 테스트가 확장 가능한 규모를 검증하는 데 초점을 맞춘다면, 깊이 일반화는 모델이 구성적 추론과 재귀 패턴 처리 능력을 평가합니다. 재귀는 논리, 보편 시스템의 핵심 요소이며, 많은 기본 도메인에 적용됩니다. 예를 들어, 제안 논리(Pospesel, 1974)는 중첩된 양식과 절을 포함하며, 부울 대수(Sikorski et al., 1969)는 복합 표현을 다루고, 재귀적인 산술(예: 3 * (2 + (5/1)))은 중첩된 연산을 포함합니다. 깊이는 이러한 계층적 관계를 추론하는 데 필요한 중간 상태를 추적하고 연산 순서를 체계적으로 구성하는 능력을 반영합니다. 따라서 깊이 k의 평가에는 k 계층의 중첩 의존성을 해결해야 하므로, 단순 시퀀스 길이 k의 처리와는 구별됩니다.
우리는 비재귀 작업(예: 두 숫자의 합이나 시퀀스 역전)은 트랜스포머의 자기 회귀적 본성과 강화된 위치 인코딩을 통해 종종 해결될 수 있지만, 재귀 문제는 근본적으로 더 어려운 과제를 제시한다고 가정합니다. 재귀 구조는 선형 시퀀스와 달리 스택 같은 행동을 요구하며, 이를 구현하기 위해 트랜스포머는 설계상 한계를 가지고 있습니다. 주의 메커니즘은 글로벌 접속 필드를 제공하지만, 동적 스택을 관리하거나 계층 간 의존성을 해결하는 데 어려움을 겪습니다. 이러한 제한은 깊이 일반화가 표준 위치 편향이나 데이터 스케일링 이상의 건축학적 혁신에 의존할 수 있음을 시사합니다.
이러한 격차를 이해하는 것은 코드 생성(재귀 함수 호출), 자동 증명(중첩된 증명) 또는 구문 분석(구문 트리)과 같은 응용 분야에 필수적입니다. 이러한 작업은 엄격한 기호 추론을 요구하며, 트랜스포머가 재귀를 얼마나 잘 모방할 수 있는지 테스트합니다. 본 연구는 깊이 일반화에서 트랜스포머의 한계를 파악하고, 이 문제를 해결하기 위한 실용적인 솔루션을 개발하는 것을 목표로 합니다.
다음은 우리의 기여입니다:
트랜스포머는 다양한 작업에서 뛰어난 성능을 보여주었지만, 입력 시퀀스 길이에 대한 일반화 능력은 제한적입니다. 초기 연구는 트랜스포머가 짧은 시퀀스 작업(예: 두 숫자의 덧셈)에는 우수하지만, 더 긴 입력(예: 123456 + 789012)에는 종종 실패한다는 것을 발견했습니다(Zhou et al., 2024). 일반적인 길이 일반화 벤치마크(Lin et al., 2025; Xiao and Liu, 2025; Cai et al., 2025; Zhou et al., 2024; Abbe et al., 2024b, a; Li et al., 2024; Anil et al., 2022)는 산술 연산, 시퀀스 복사 및 정렬을 포함하며, 이러한 작업은 모델이 더 긴 버전의 문제에서 어떻게 추론할 수 있는지 테스트합니다. 그러나 이러한 작업은 주로 순차적 패턴에 초점을 맞추고 있으며, 계층적 패턴(예: 재귀 구조)에는 덜 주목합니다.
길이 일반화는 잘 연구되었지만, 트랜스포머가 재귀 또는 중첩된 구조와 어떻게 처리되는지에 대한 관심은 상대적으로 적었습니다. 재귀 문제는 모델이 계층적 관계를 추론해야 하는 것을 의미하며, 연구 결과 트랜스포머는 심지어 간단한 재귀 패턴인 균형 잡힌 괄호(디크 언어)에도 어려움을 겪는 것으로 나타났습니다(Bhattamishra, Patel, and Goyal, 2020). 흥미롭게도, 전통적인 순환 신경망(Sherstinsky, 2020)은 재귀에 대한 더 나은 성능을 보이며, 이는 그들의 아키텍처가 재귀 연산(스택 같은 연산)에 자연스럽게 적합하기 때문입니다(Delétang et al., 2022). 이는 표준 트랜스포머 아키텍처가 재귀 추론에 필요한 유도 편향을 결여할 수 있음을 시사합니다.
트랜스포머의 재귀 처리 메커니즘은 메커니즘 연구에 의해 밝혀졌습니다. 이러한 연구는 특정 주의 패턴이 스택 연산에 유사하다는 것을 발견했으며, 이를 통해 “추론 머리"가 트리 탐색을 구현하고(Brinkmann et al., 2024) “인덕션 머리"가 복사 메커니즘을 가능하게 함(Olsson et al., 2022)을 밝혀냈습니다. 다른 연구는 정보 흐름이 재귀 작업 동안 각 계층에서 어떻게 처리되는지 추적하여 병렬 처리 모형과 깊이 제한된 순환 메커니즘(Nanda, Lee, and Wattenberg, 2023)을 드러냈습니다. 이러한 분석은 트랜스포머가 재귀를 처리하기 위해 단축 알고리즘에 의존하며, 가장자리 사례에서 실패할 수 있다는 것을 보여줍니다. 대신 진정한 재귀 계산을 수행합니다. 본 연구는 이러한 통찰력을 바탕으로 다양한 재귀 작업을 측정하고 더 견고한 솔루션을 제안합니다.
최근 Looped Transformer(Yang et al., 2023; Fan et al., 2024)이 입력 토큰에 출력 토큰을 백업하는 방식으로 길이 일반화를 개선하기 위한 제안이 있었지만, 깊이 일반화에는 여전히 해결책을 제시하지 못합니다.
대부분의 연구와 마찬가지로 우리는 구조화된 제어된 문제에 깊이 일반화를 평가합니다. 특히, 재귀 논리, 논리 연산을 포함하는 세 가지 재귀 문제를 선택했습니다. 각 문제는 고유한 상수, 함수 및 평가 목표를 가지고 있으며, 트랜스포머의 자동 회귀 특성에 맞게 포스트픽 표기법을 사용합니다.
Boolean Algebra 평가 문제: 이 문제는 진리 값을 처리하며, C = {0, 1}로 표현되는 FALSE와 TRUE, F = {+, *, -}로 표현되는 OR, AND, NOT 연산자를 포함합니다. 예를 들어, 포스트픽 표기법으로 표현된 1 0 +는 1을 평가합니다. 재귀 구조는 평가해야 할 중첩된 식을 나타냅니다.
논리 진리표 계산: 이 문제는 4비트 진리표를 사용하여 두 명제 p와 q를 표현하며, 비트 순서는 (T, T), (T, F), (F, T), (F, F)의 값을 나타냅니다. 연산자 집합 F = {+, *, -, >}에는 IMPLY(>)도 포함되어 있으며, 이는 논리 연산을 포함합니다. p q *는 0100(AND 진리표)로 평가되며, p q >는 NOT(임플라이)의 결과로 0010를 계산합니다. 이 표현은 전체 진리표를 각 단계에서 처리하는 재귀적 특성을 유지합니다.
구성적 산술 문제: 이 문제는 3자리 정수 상수 {000, …, 999}와 세 가지 산술 연산 F = {+, -, *}를 사용합니다. 모든 연산은 결과의 마지막 세 자리를 잘라내어 999 001 +는 000으로 평가됩니다. 중첩된 식은 재귀적 평가를 요구하며, 문제의 초점은 재귀 깊이보다 길이에 있습니다.