스파크 단계별 검증을 활용한 참조 없는 프로세스 보상 모델 학습
📝 원문 정보
- Title: SPARK: Stepwise Process-Aware Rewards for Reference-Free Reinforcement Learning
- ArXiv ID: 2512.03244
- 발행일: 2025-12-02
- 저자: Salman Rahman, Sruthi Gorantla, Arpit Gupta, Swastik Roy, Nanyun Peng, Yang Liu
📝 초록 (Abstract)
프로세스 보상 모델(PRM)은 단계별 밀집 피드백을 제공해 강화학습에 유망하지만, 단계별 주석이나 정답 레퍼런스가 필요해 적용이 제한돼 왔다. 우리는 SPARK라는 세 단계 프레임워크를 제안한다. 첫 단계에서는 생성기 모델이 다양한 해결책을 만들고, 검증기 모델이 병렬 스케일링(자기 일관성)과 순차 스케일링(메타 비평)을 통해 이를 평가한다. 두 번째 단계에서는 검증 결과를 합성 학습 데이터로 활용해 생성형 프로세스 보상 모델을 미세조정하고, 이를 강화학습의 보상 신호로 사용한다. 우리는 단계별 독립 검증을 다수 결합하면 ProcessBench(수학 추론 단계 오류 식별 벤치마크)에서 67.5 F1를 달성해, 레퍼런스 기반 학습(66.4 F1)과 GPT‑4o(61.9 F1)를 능가한다는 것을 보였다. 마지막 단계에서는 체인‑오브‑생각 검증(PRM‑CoT)을 보상 모델로 적용하고, 보상 해킹을 방지하기 위해 형식 제약을 도입했다. Qwen2.5‑Math‑7B를 사용한 수학 추론 RL 실험에서 평균 정확도 47.4 %를 기록했으며, 이는 정답 기반 RLVR(43.9 %)보다 높은 성과다. 우리의 연구는 정답이 없는 영역에서도 정답 기반 방법을 뛰어넘는 참조‑무료 RL 훈련을 가능하게 한다.💡 논문 핵심 해설 (Deep Analysis)
첫 번째 단계에서 생성기 모델은 프롬프트에 따라 다채로운 풀이 경로를 생성한다. 여기서 중요한 점은 다양성을 확보하기 위해 온도 조절, 샘플링 기법 등을 활용해 다수의 후보 풀이를 만든다는 것이다. 검증기 모델은 두 가지 축으로 평가한다. 병렬 스케일링은 동일 단계에 대해 여러 독립 검증을 수행해 자기 일관성을 측정한다. 예를 들어, 같은 수식 단계에 대해 서로 다른 검증기가 동일한 결론을 내리면 신뢰도가 상승한다. 순차 스케일링은 이전 단계의 검증 결과를 메타‑비평 형태로 활용해 현재 단계의 논리적 타당성을 판단한다. 이 두 축을 결합하면 인간 주석 없이도 “정답에 가까운” 신호를 얻을 수 있다.
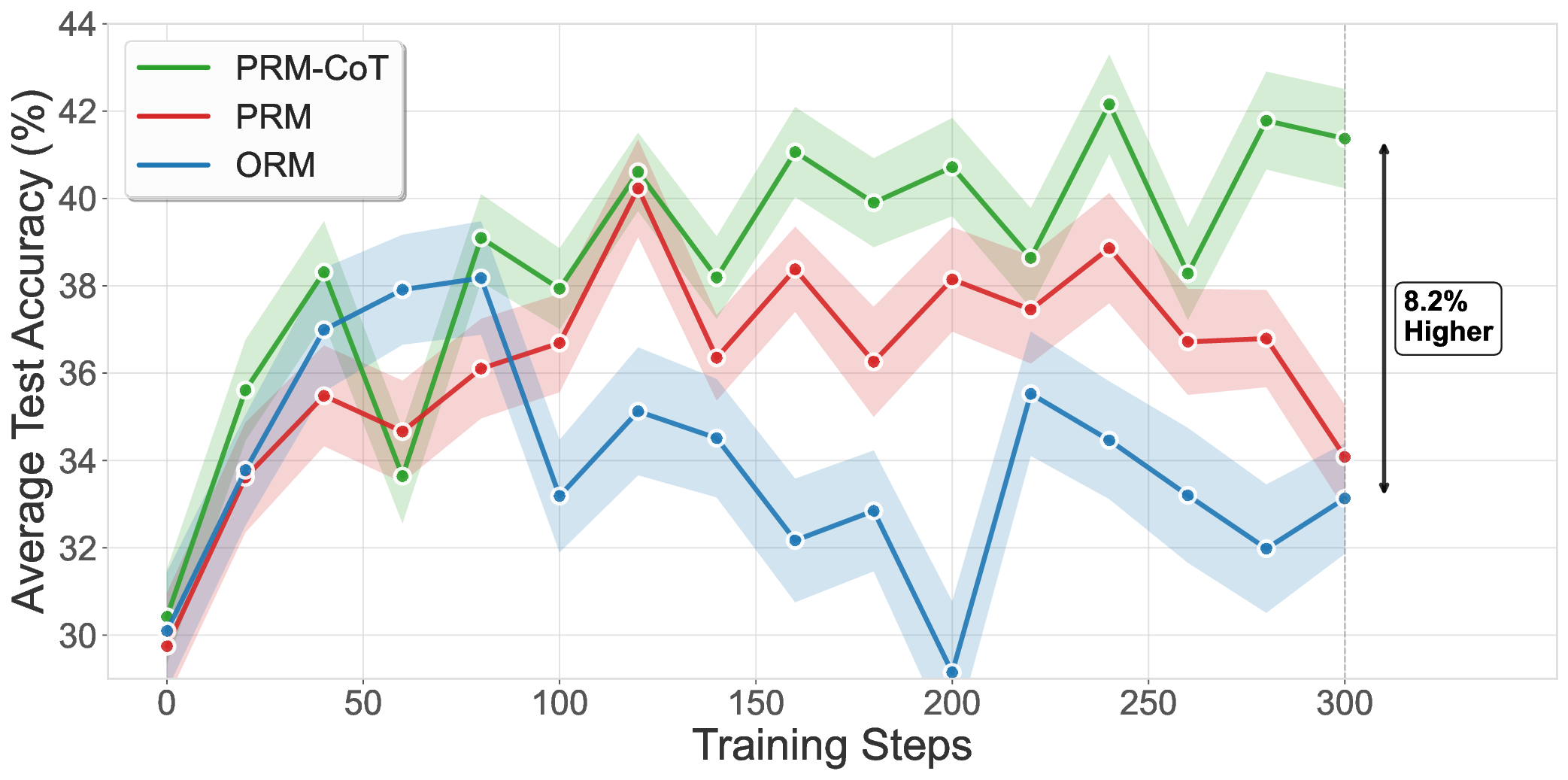
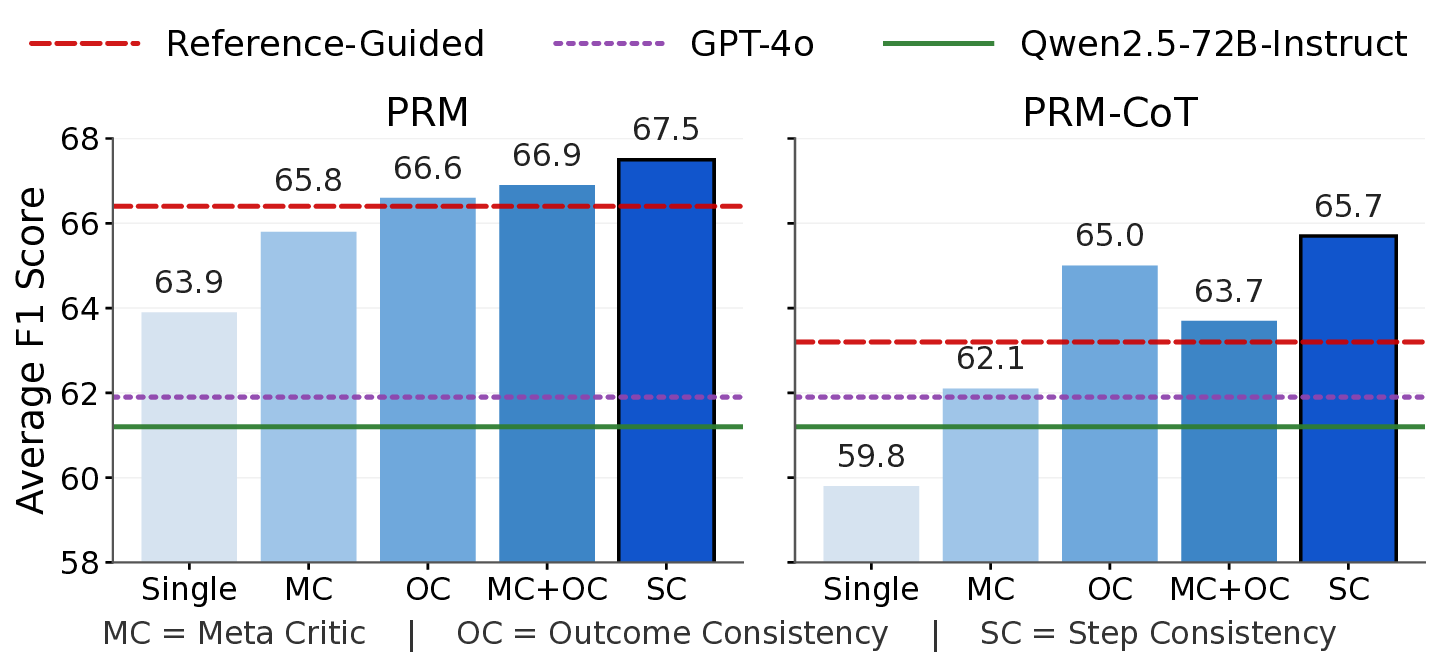
두 번째 단계에서는 검증기의 출력(예: “올바른 단계”, “오류 유형”)을 라벨링된 학습 데이터로 전환한다. 이를 통해 생성형 PRM을 미세조정하면, 실제 정답 레퍼런스를 사용하지 않아도 단계별 보상 함수를 학습할 수 있다. 실험 결과는 ProcessBench에서 67.5 F1를 기록했으며, 이는 동일 모델을 레퍼런스 기반으로 학습했을 때의 66.4 F1보다 약 1.1 포인트, GPT‑4o의 61.9 F1보다 현저히 높은 수치다.
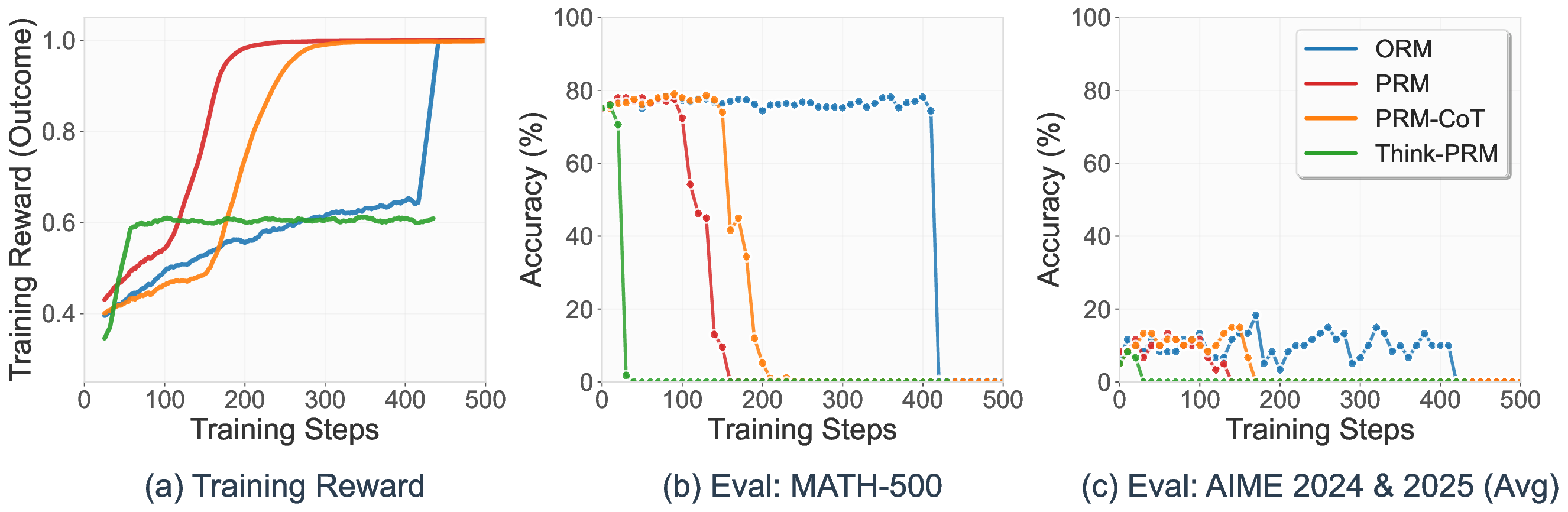
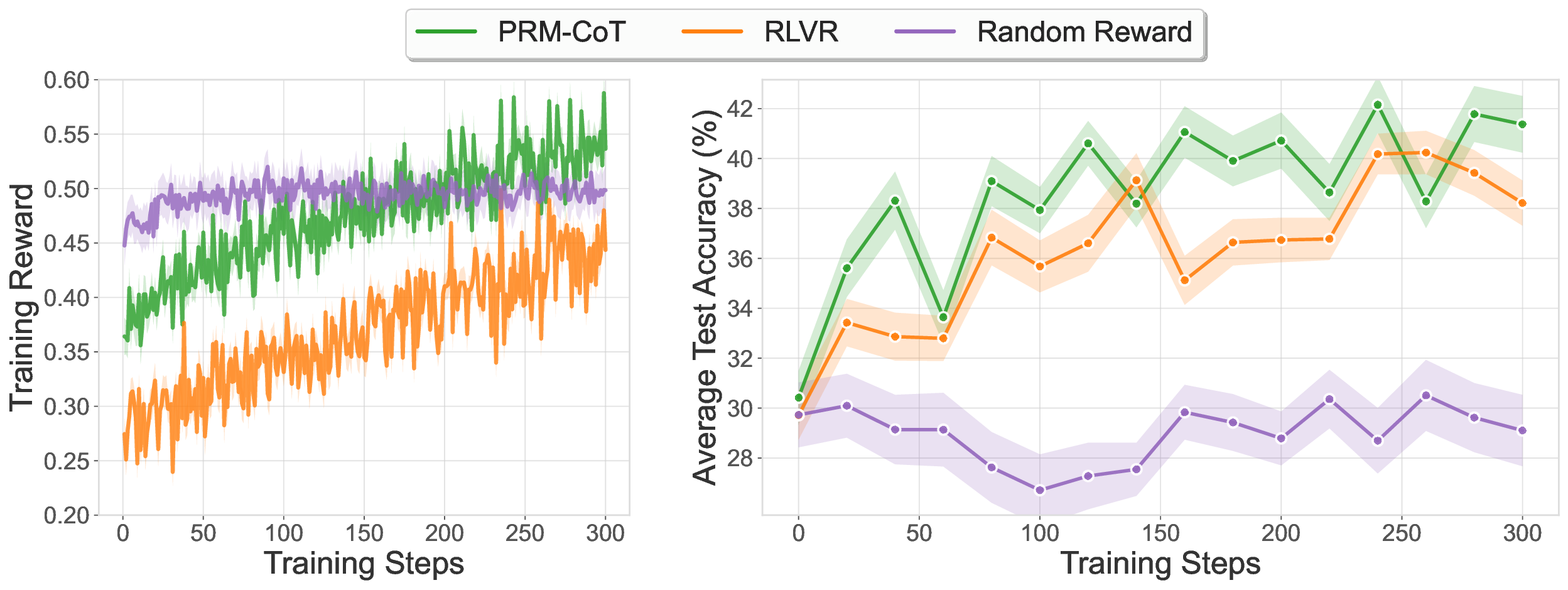
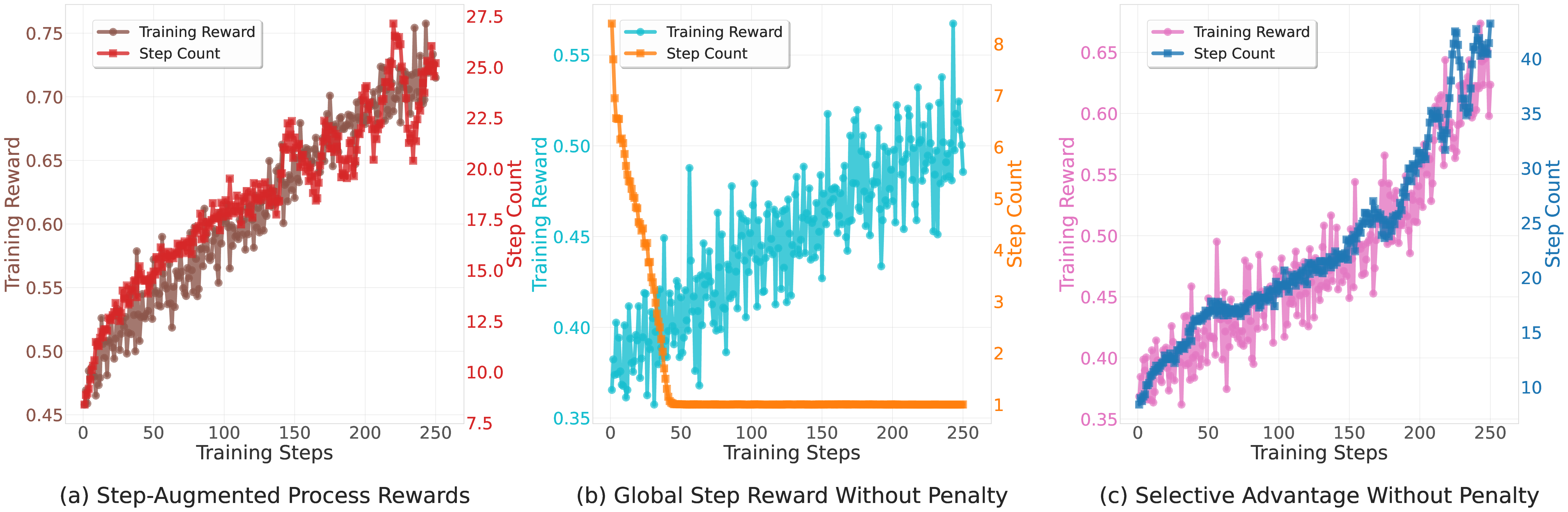
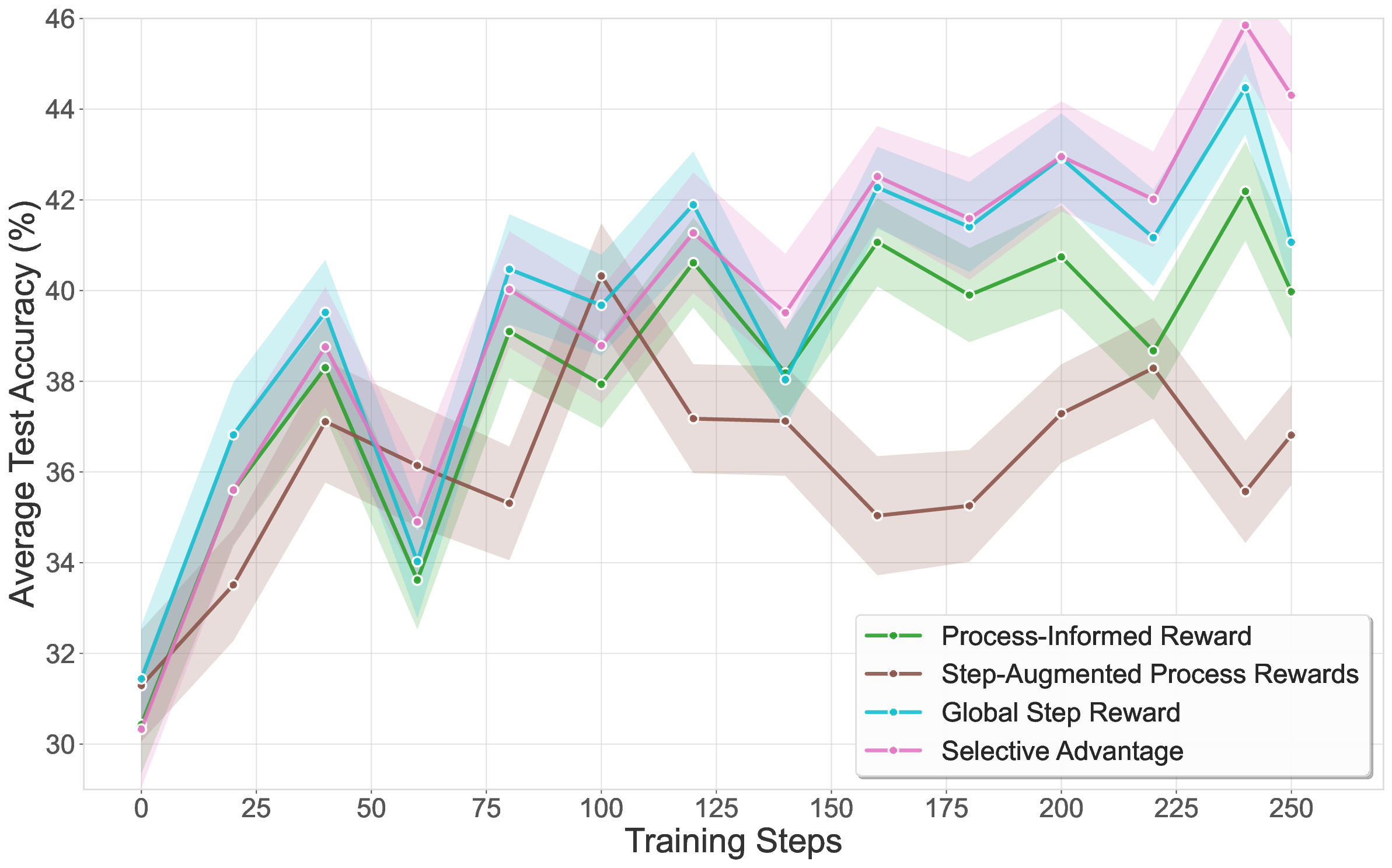
세 번째 단계에서는 이렇게 만든 PRM‑CoT를 RL 에이전트의 보상으로 사용한다. 여기서 저자들은 “보상 해킹”을 방지하기 위해 출력 형식을 엄격히 제한한다. 예를 들어, 에이전트가 보상을 높이기 위해 무의미한 텍스트를 삽입하거나 단계 수를 인위적으로 늘리는 것을 방지한다. Qwen2.5‑Math‑7B를 기반으로 한 실험에서 평균 정확도 47.4 %를 달성했으며, 이는 정답 기반 RLVR(43.9 %)보다 3.5 포인트 상승한 결과다.
이 연구의 의의는 두 가지이다. 첫째, 정답이 없는 혹은 구하기 어려운 도메인에서도 고품질 보상 모델을 자동으로 생성할 수 있다는 점이다. 둘째, 검증기 자체가 “메타‑비평” 역할을 수행함으로써 인간 주석 비용을 크게 절감한다. 다만 몇 가지 한계도 존재한다. 검증기의 품질에 크게 의존하므로, 검증기가 편향되거나 오류를 범하면 전체 파이프라인이 오염된다. 또한 현재 실험은 주로 수학 추론에 국한돼 있어, 자연어 이해, 코드 생성 등 다른 영역에 대한 일반화 가능성은 추가 연구가 필요하다. 마지막으로, 병렬·순차 스케일링을 위한 검증기 수가 많아질수록 계산 비용이 급증하므로, 효율적인 샘플링 전략이 요구된다.
전반적으로 SPARK는 “생성‑검증‑학습” 순환을 통해 PRM 학습의 비용 구조를 근본적으로 바꾸는 혁신적 접근이다. 향후 다양한 분야에 적용해 정답 기반 학습이 어려운 상황에서도 강력한 RL 시스템을 구축할 수 있을 것으로 기대된다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리