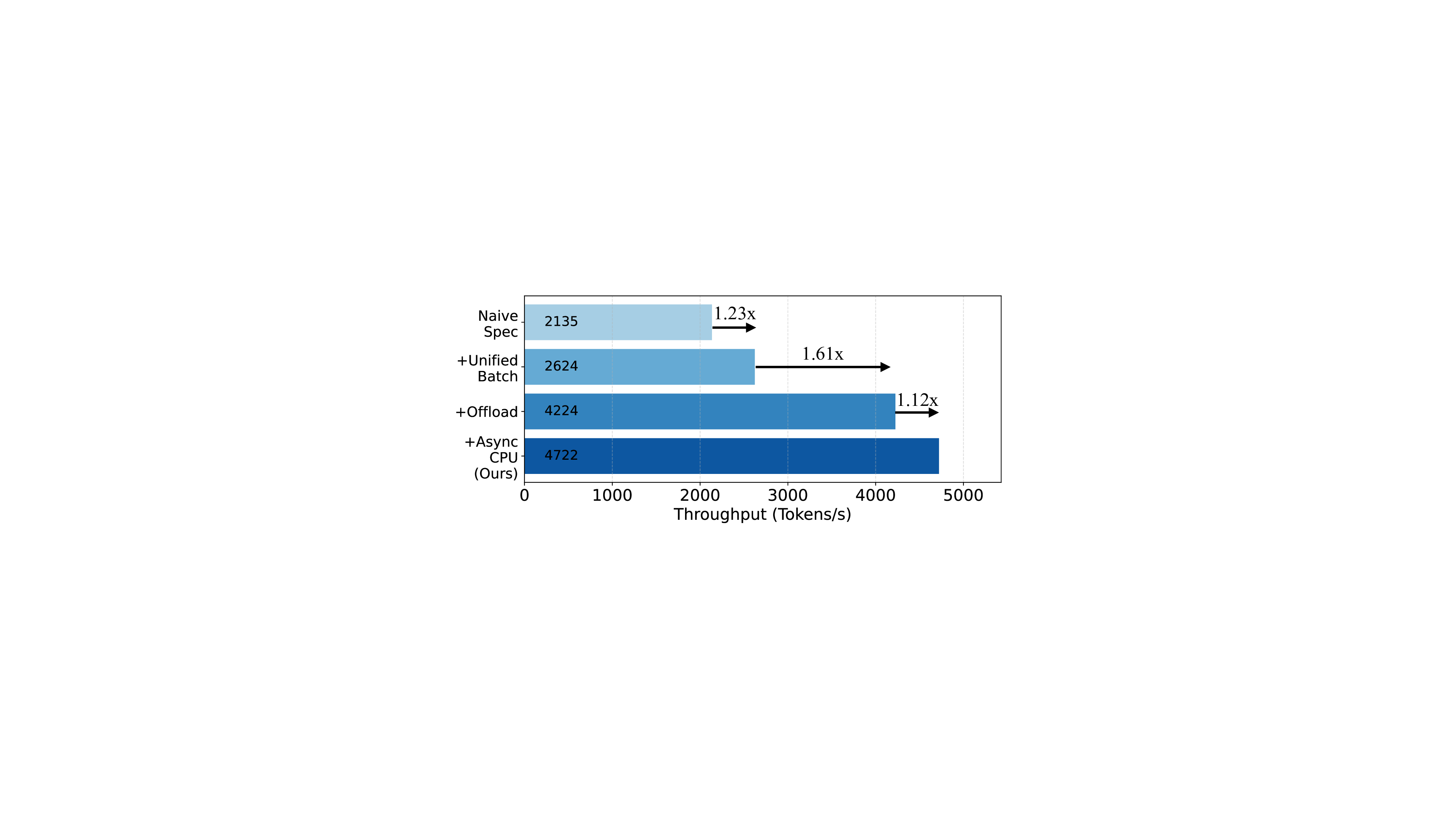Title: Accelerating Large-Scale Reasoning Model Inference with Sparse Self-Speculative Decoding
ArXiv ID: 2512.01278
발행일: 2025-12-01
저자: Yilong Zhao, Jiaming Tang, Kan Zhu, Zihao Ye, Chi-Chih Chang, Chaofan Lin, Jongseok Park, Guangxuan Xiao, Mohamed S. Abdelfattah, Mingyu Gao, Baris Kasikci, Song Han, Ion Stoica
📝 초록 (Abstract)
추론 단계에서 체인‑오브‑쓰루(Chain‑of‑Thought)와 같은 긴 텍스트를 생성하면, 모델은 매 토큰마다 기존 모든 토큰에 대한 전체 어텐션을 수행해야 하므로 메모리 접근량이 급격히 증가한다. 이로 인해 메모리 대역폭이 병목이 된다. 이를 해결하고자 저자들은 동일 모델을 초안(draft)과 목표(target) 모델로 동시에 활용하는 자기‑추측(self‑speculation) 프레임워크인 SparseSpec을 제안한다. SparseSpec은 초안 모델로서 핵심 토큰만을 선택적으로 어텐션하는 새로운 희소 어텐션 메커니즘인 PillarAttn을 도입한다. 또한 (1) 초안 단계와 검증 단계의 배치를 동시에 수행해 병렬성을 극대화하는 통합 스케줄러, (2) CPU와 GPU의 작업을 겹치게 하는 지연 검증, (3) GPU 메모리 사용량을 최적화하기 위한 동적 KV‑Cache 관리와 호스트 메모리 오프로드를 포함한 시스템 최적화를 공동 설계하였다. 다양한 모델·데이터셋에 대한 실험 결과, SparseSpec은 기존 최첨단 방법에 비해 최대 2.13배의 처리량 향상을 달성하였다. 코드가 공개되어 재현이 가능하다.
💡 논문 핵심 해설 (Deep Analysis)
이 논문은 최근 대형 언어 모델이 복잡한 문제를 해결하기 위해 체인‑오브‑쓰루(Chain‑of‑Thought)와 같은 긴 추론 과정을 거칠 때, 메모리 대역폭이 주요 병목으로 작용한다는 점을 정확히 짚어낸다. 전통적인 디코딩 방식에서는 매 토큰마다 KV‑Cache에 저장된 모든 이전 토큰에 대해 완전 어텐션을 수행한다. 토큰 수가 늘어날수록 KV‑Cache의 크기도 선형적으로 증가하고, 이에 따라 메모리 읽기·쓰기 비용이 급증한다. 특히 GPU 메모리 용량이 제한적인 상황에서 이러한 메모리‑바운드 특성은 실시간 응용에 큰 제약이 된다.
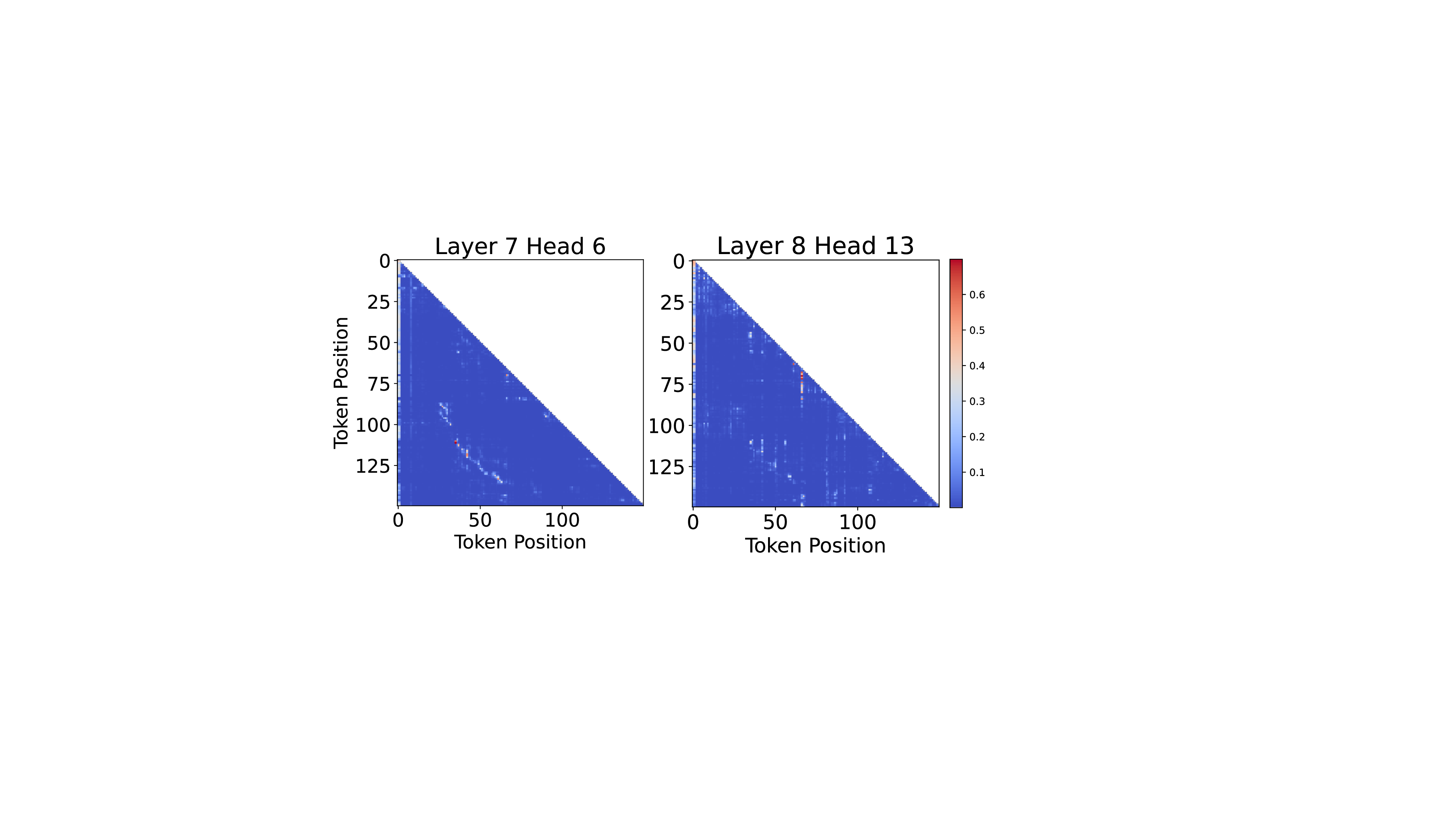
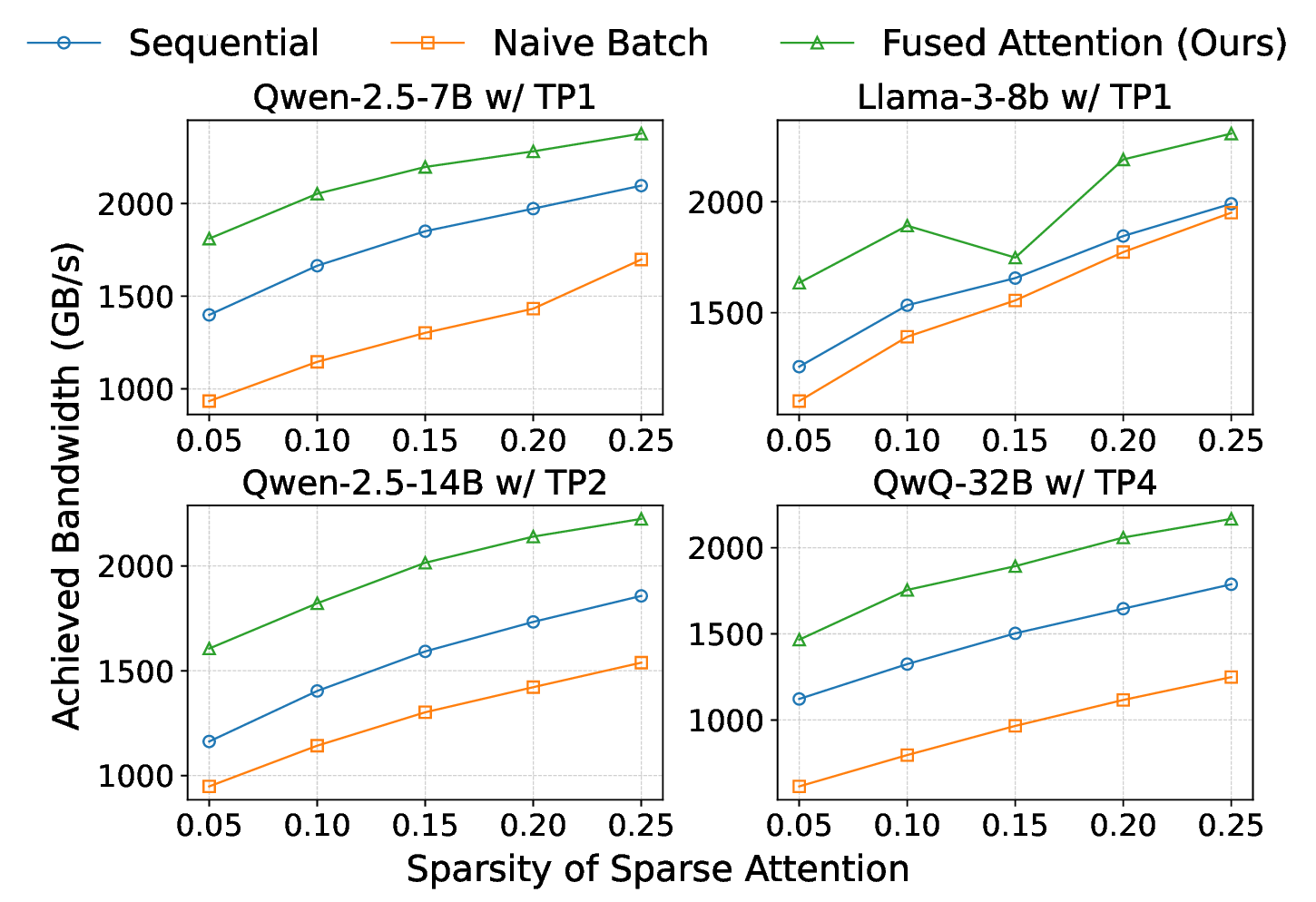
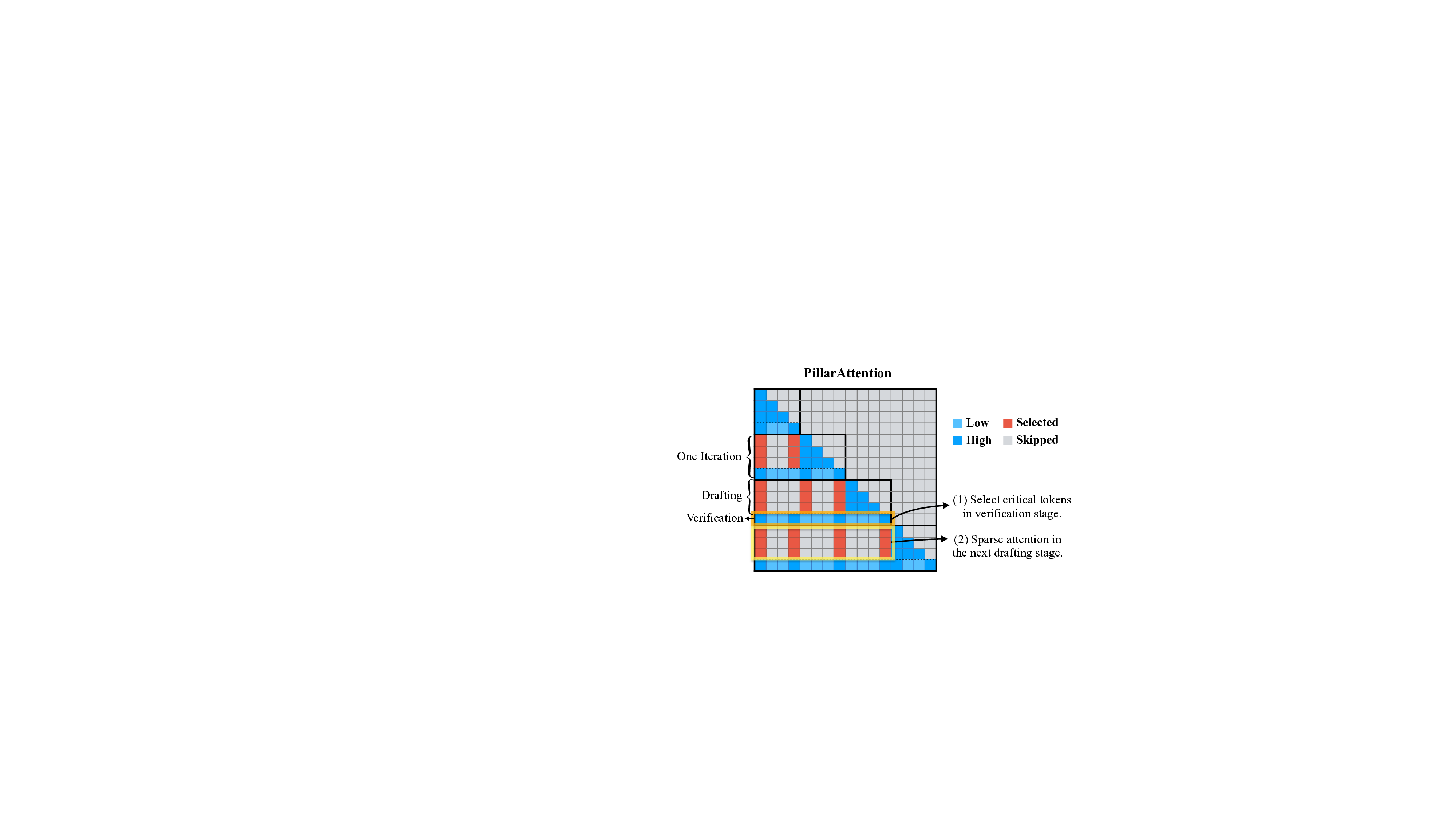
SparseSpec은 이러한 문제를 ‘자기‑추측(self‑speculation)’이라는 새로운 관점으로 해결한다. 기존의 speculative decoding은 별도의 작은 초안 모델을 사용해 여러 토큰을 미리 예측하고, 이후 큰 목표 모델이 이를 검증하는 구조였지만, 모델을 두 개 관리해야 하는 복잡성과 추가 파라미터 비용이 있었다. 저자들은 동일한 모델을 초안과 목표 양쪽에 재활용함으로써 모델 관리 비용을 없애고, 동시에 PillarAttn이라는 희소 어텐션 메커니즘을 도입했다. PillarAttn은 검증 단계에서 이미 계산된 어텐션 정보를 재활용해, 초안 단계에서는 전체 토큰이 아닌 ‘핵심 토큰’만을 선택적으로 어텐션한다. 이렇게 하면 초안 단계의 연산량과 KV‑Cache 접근량이 크게 감소하면서도, 검증 단계에서 정확도를 유지할 수 있다.
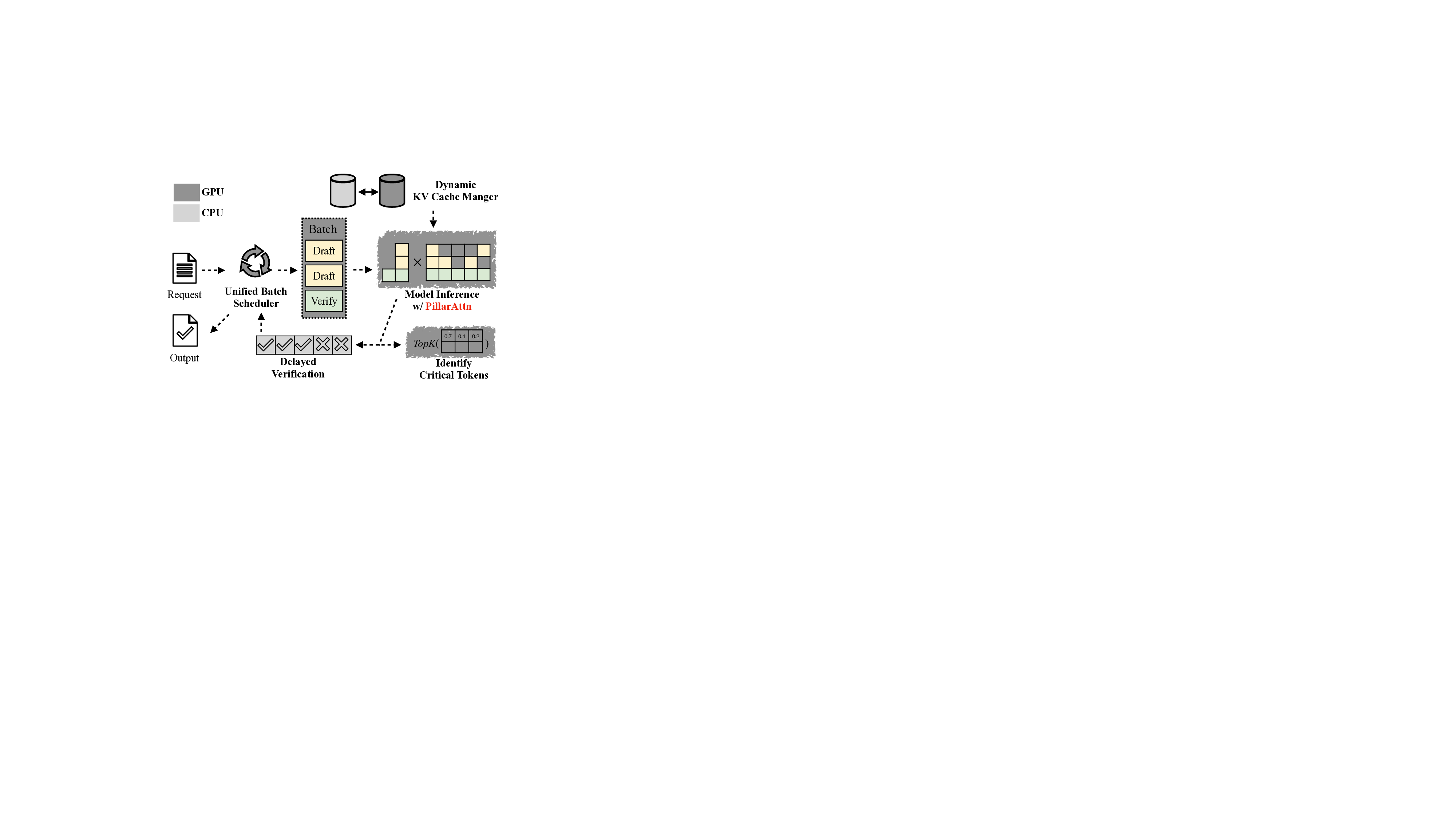
시스템 차원에서는 세 가지 최적화가 핵심이다. 첫째, 초안과 검증을 동일한 배치에 포함시켜 GPU와 CPU의 연산을 동시에 스케줄링함으로써 파이프라인 효율을 극대화한다. 둘째, 검증을 일정 단계 뒤로 미루는 ‘지연 검증’ 기법을 통해 CPU와 GPU가 서로 대기하지 않고 겹쳐서 작업하도록 만든다. 셋째, 동적 KV‑Cache 관리와 호스트 메모리 오프로드를 통해 GPU 메모리 사용량을 최소화하고, 큰 컨텍스트도 처리할 수 있게 한다. 이러한 하드웨어‑소프트웨어 공동 설계는 메모리 대역폭 압박을 실질적으로 완화한다.
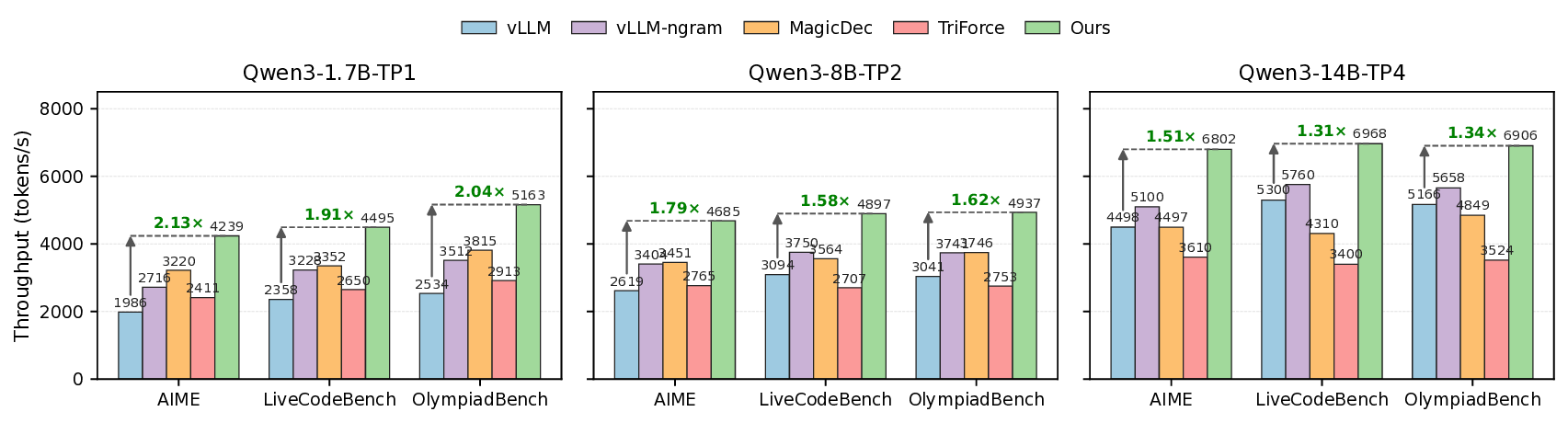
실험에서는 다양한 규모의 언어 모델(예: LLaMA‑7B, LLaMA‑13B 등)과 여러 추론 데이터셋(수학 문제, 코드 생성, 일반 QA 등)을 대상으로 기존 최첨단 speculative decoding 및 압축 어텐션 방법과 비교하였다. 결과는 평균 1.6배, 최고 2.13배의 처리량 향상을 보여준다. 특히 긴 컨텍스트(2k~4k 토큰)에서 메모리 사용량이 크게 감소하면서도 정확도 손실이 거의 없다는 점이 주목할 만하다. 코드가 공개돼 있어 연구 재현 및 산업 적용이 용이하다는 점도 큰 장점이다.
하지만 몇 가지 한계도 존재한다. PillarAttn이 선택하는 ‘핵심 토큰’의 기준이 현재는 검증 단계의 어텐션 스코어에 의존하는데, 이는 특정 도메인이나 비정형 텍스트에서 최적이 아닐 수 있다. 또한 동적 KV‑Cache 오프로드는 호스트‑GPU 간 대역폭에 크게 의존하므로, 시스템 환경에 따라 성능 변동이 클 가능성이 있다. 향후 연구에서는 토큰 선택 전략을 학습 기반으로 일반화하고, 멀티‑GPU 환경에서의 확장성을 검증하는 것이 필요하다.
📄 논문 본문 발췌 (Excerpt)
## 희소 스펙 메모리 효율적인 자기 추측 디코딩 (전문 한국어 번역)
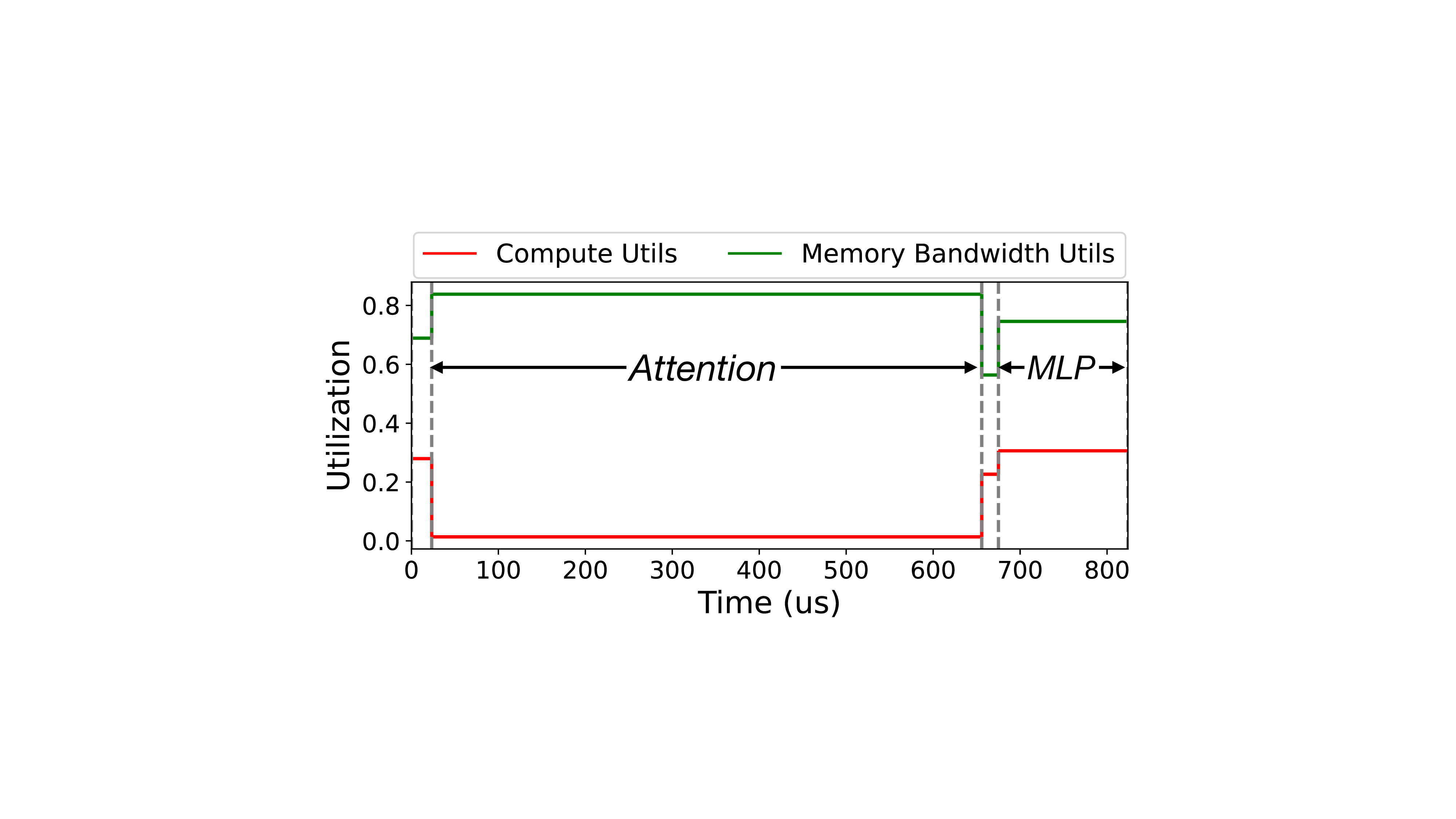
최근 언어 모델링(RLM)의 발전은 복잡한 추론 작업을 해결하는 데 뛰어난 능력을 보여주었습니다. 이러한 모델은 일반적으로 수천 개의 토큰을 생성하지만, 문제는 단지 수백 개의 토큰으로 설명됩니다. 이 긴 길이의 추론 패러다임 전환은 추론 성능의 병목 현상을 메모리 기반에서 계산 기반으로 이동시킵니다 (Zhao et al., 2024b).
자동 회귀적 특성으로 인해 RLM은 각 토큰을 생성하기 위해 모든 이전에 생성된 키-값(KV) 벡터를 로드해야 합니다. 실제로, KV 캐시의 총 양은 출력 길이에 비례하여 증가합니다 (Tang et al., 2024). 예를 들어, Qwen3-8B (Qwen, 2025)를 H100에서 서비스할 경우, 8192의 출력과 128개의 배치 크기를 가정하면, KV 캐시 로딩에 평균 21ms가 소요되며 이는 전체 엔드투엔드 지연의 70% 이상을 차지합니다.
메모리 대역폭 병목 현상을 완화하기 위해 연구원들은 손실 없는 기술인 사양 디코딩(speculative decoding)을 제안했습니다 (Chen et al., 2023). 간략히 말해, 사양 디코딩은 작은 빠르고 초안 모델을 사용하여 토큰을 순차적으로 생성한 후, 원본 대상 모델에 의해 검증됩니다. 이를 위해 KV 캐시는 한 번만 로드됩니다. 이는 각 토큰에 대해 전체 KV 캐시를 로드해야 하는 기존 방법과 대조적입니다. 결과적으로, 사양 디코딩은 메모리 액세스 및 처리량을 크게 개선합니다.
그러나 기존 사양 디코딩 방법은 각 대상 모델에 대한 별도의 훈련 또는 수정을 요구하여 적용성이 제한됩니다. 특히, 일부 솔루션은 별도의 독립형 초안 모델을 훈련 (Chen et al., 2023)하거나 모델 아키텍처를 수정 (Li et al., 2025a)해야 합니다. 이러한 추가 단계는 실제 배포에 복잡성을 더합니다. 예를 들어, 작은 초안 모델의 훈련은 특정 작업에 대한 데이터 큐레이션이 필요하며 일반화되지 않을 수 있습니다 (Liu et al., 2024b). 또한, 배포도 재설계되어야 하며, 이를 위해 인프라를 효율적으로 조정해야 합니다 (Miao et al., 2024). 궁극적으로, 이러한 장벽은 채택을 저해합니다 (Zhang et al., 2024).
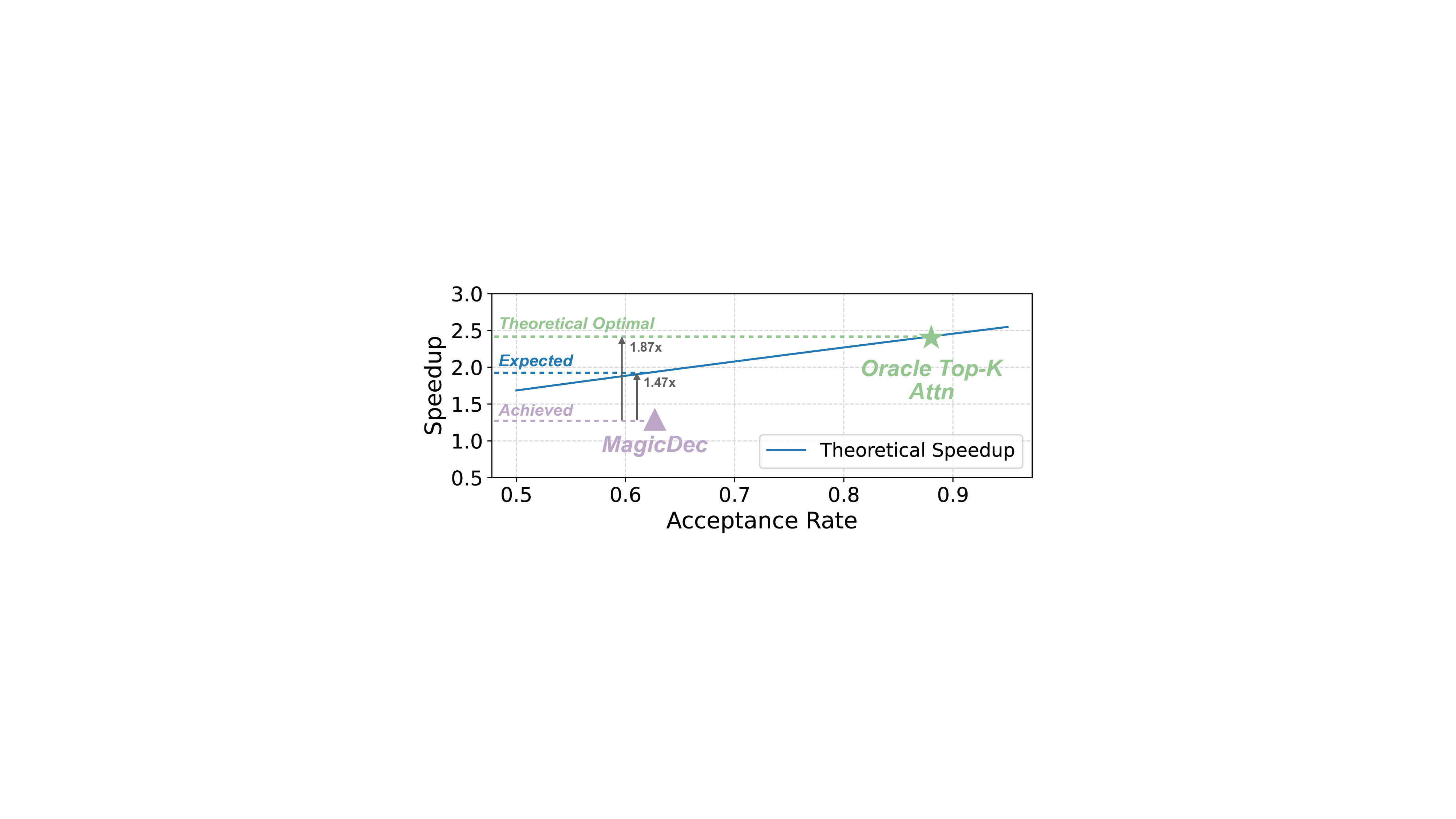
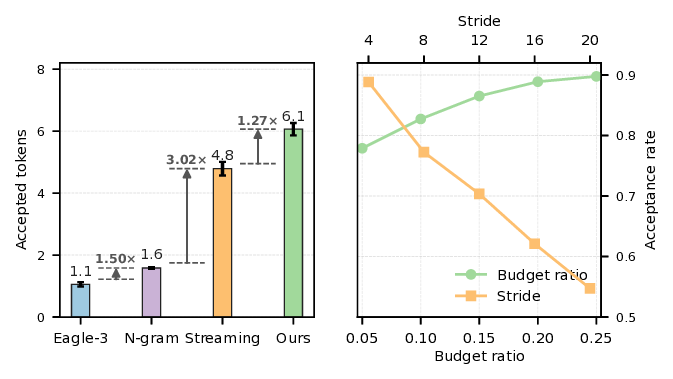
훈련 없는 방법을 탐구하는 다른 작업들은 규칙 기반의 단순한 추론(예: N-Gram (Fu et al., 2024)) 또는 모델 자체에 의존하는 자기 추측(Liu et al., 2024a; Sun et al., 2024)을 활용합니다. 예를 들어, MagicDec (Chen et al., 2024)는 전체 모델과 슬라이딩 윈도우 주의를 사용하여 초안을 생성한 후, 전체 주의로 검증합니다. 이러한 희소 주의는 최대 95%까지 메모리 액세스를 줄여 전반적인 처리량 향상에 기여합니다. 그러나 기존 방법은 RLM에 대한 이상적인 속도향상을 제공하지 못하며, 이는 고유한 알고리즘 및 시스템적 도전 과제 (§ 3.3) 때문입니다.
알고리즘적으로, 기존 방법들은 불완전한 초안 토큰을 생성하여 높은 맥락 동역학이 RLM에 내재되어 있기 때문에 정확도가 떨어집니다. 이러한 추론 모델은 다양한 맥락에서 생성된 토큰을 탐색하도록 훈련되었습니다 (DeepSeek-AI, 2025a; Kimi, 2025). 예를 들어, 수학 문제를 해결할 때, 모델은 대체 솔루션을 탐색하여 동적 맥락을 생성합니다 (Guan et al., 2025).
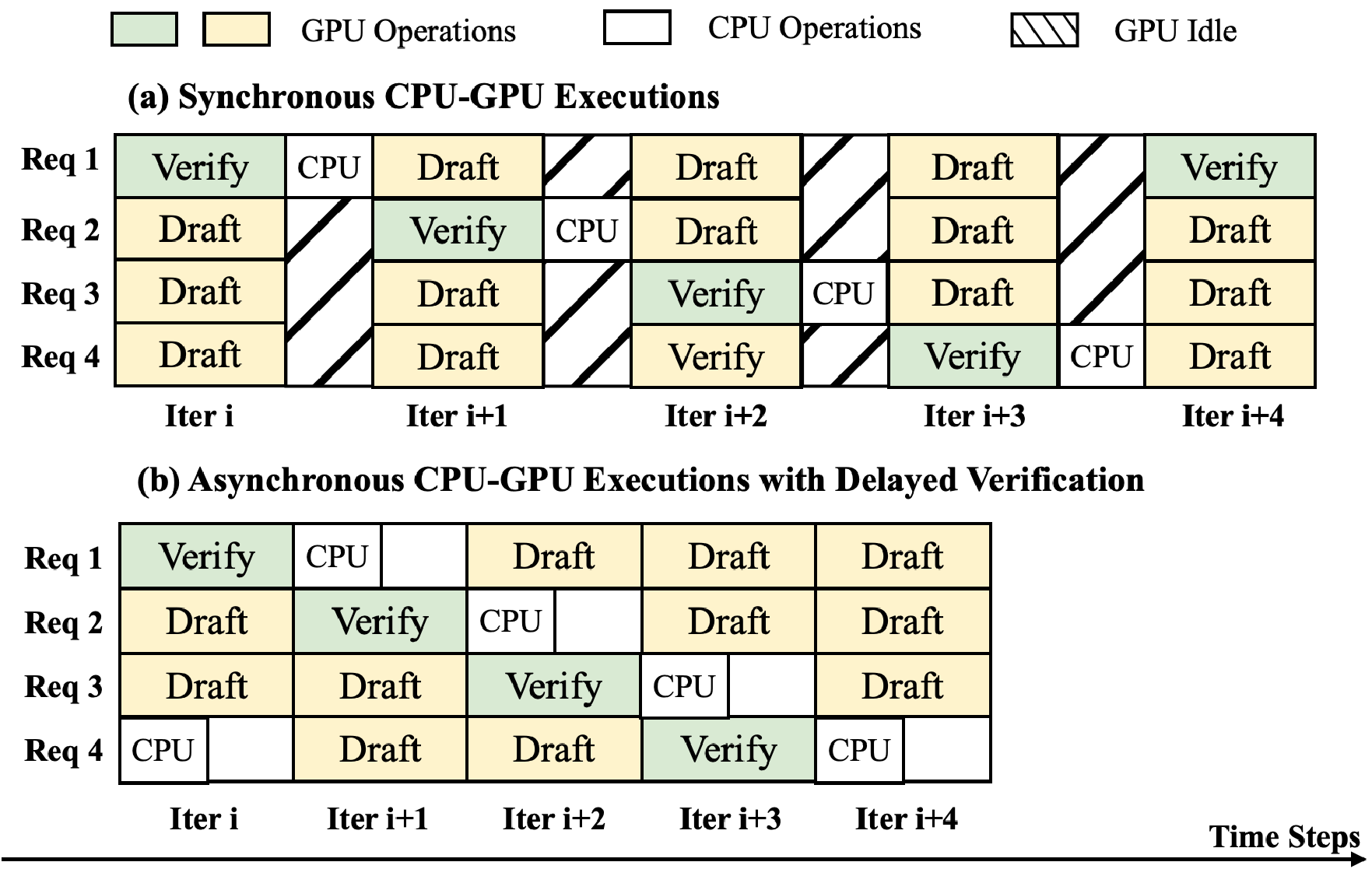
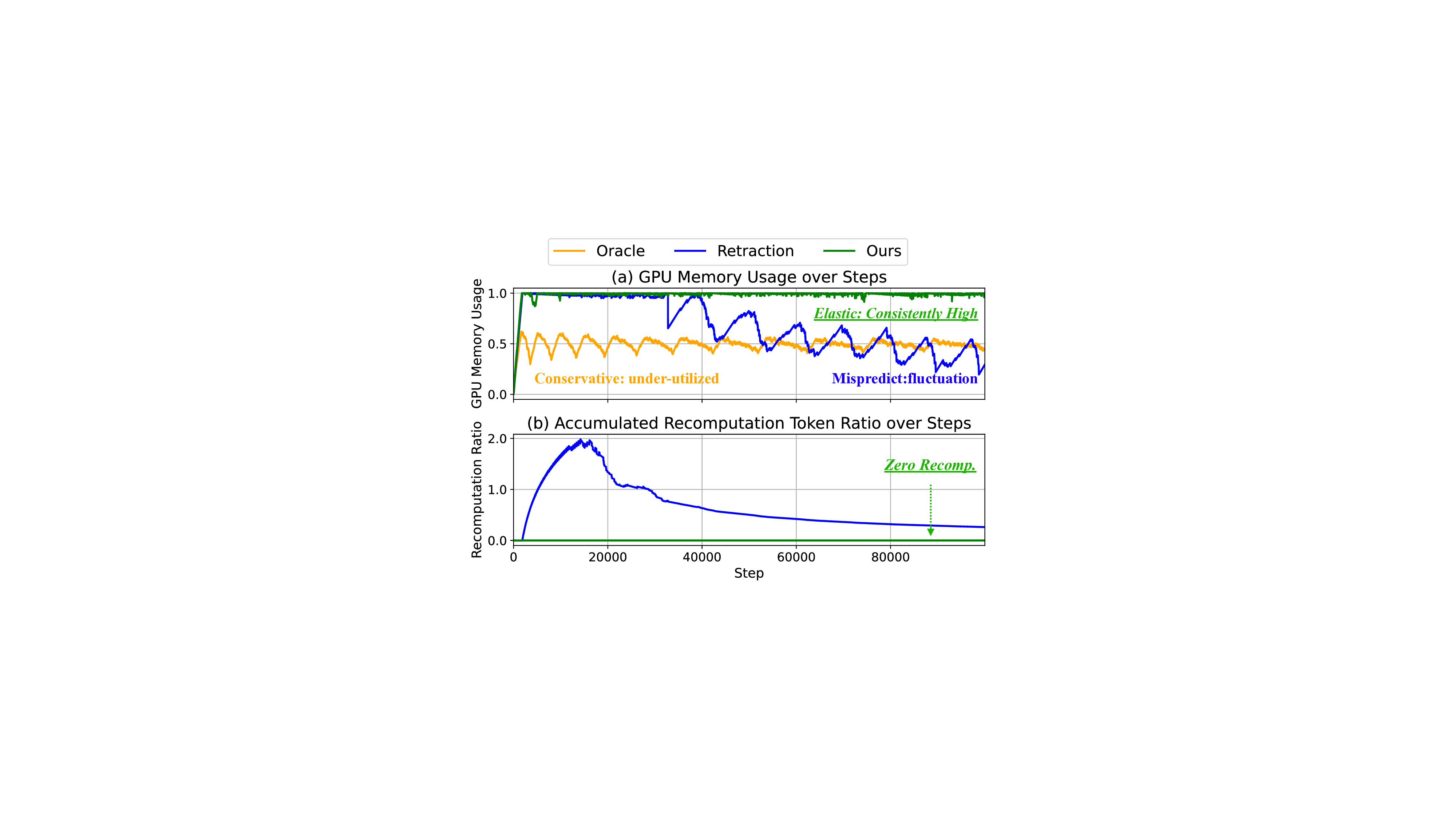
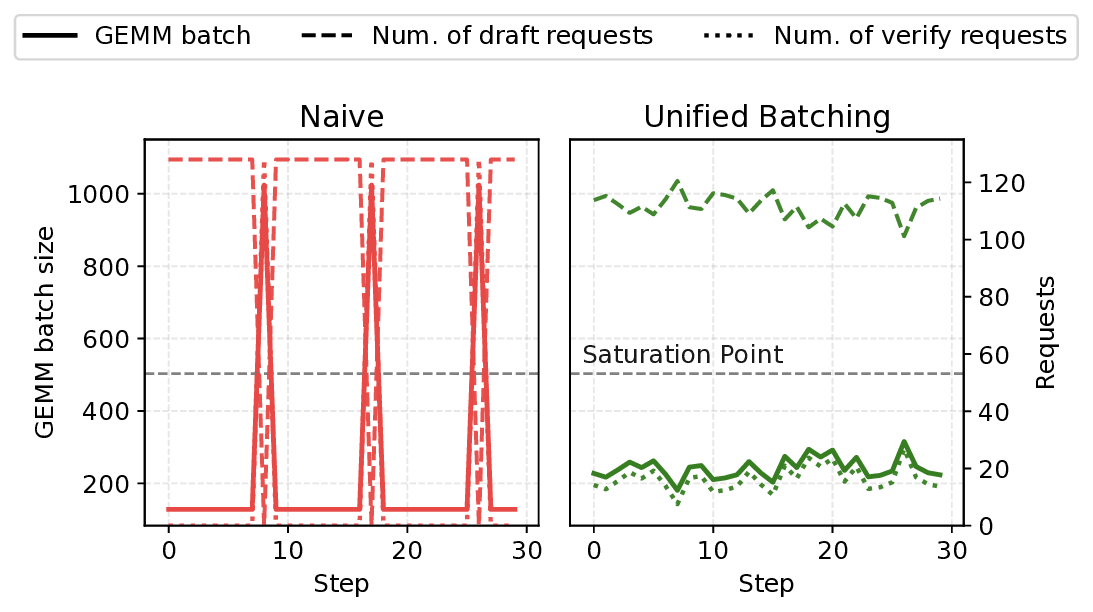
시스템적으로, 사양 디코딩과 RLM은 함께 독특한 도전 과제를 제시합니다: (1) 작업 변동성: 초안 및 검증 단계는 서로 다른 자원 사용을 가지므로, 반복마다 작업이 불균형하게 분배되어 하드웨어가 과도하게 대기합니다; (2) 명시적 동기화: 초안과 검증 단계는 CPU 작업이 GPU 작업과 겹치지 않도록 동기화되어야 합니다. (3) KV 캐시 활용 부족: RLM의 출력 길이가 예측하기 어려워 KV 캐시를 완전히 포화시키기가 어렵습니다, 이는 GPU 메모리 낭비를 초래합니다.
이러한 도전 과제를 해결하기 위해, 우리는 희소 스펙 메모리 효율적인 자기 추측 가속 프레임워크인 SparseSpec을 제시합니다. 핵심적으로, SparseSpec은 동일한 대상 모델을 초안 모델로 재사용하며, 새로운 동적 희소 주의 메커니즘인 PillarAttn을 통해 사양 디코딩을 위한 알고리즘-시스템 공설계를 제공합니다.
SparseSpec의 핵심 구성 요소는 다음과 같습니다:
PillarAttn: 동적 희소 주의는 사양 디코딩에 적합하도록 설계되었습니다 (§ 4.1). PillarAttn은 각 검증 단계에서 정확하게 토큰을 식별하여 높은 추측 정확도를 달성합니다. 이를 통해 희소 주의는 다양한 맥락에 적응하며, 이러한 공설계를 통해 SparseSpec은 기존 방법보다 훨씬 더 높은 속도향상을 제공합니다.
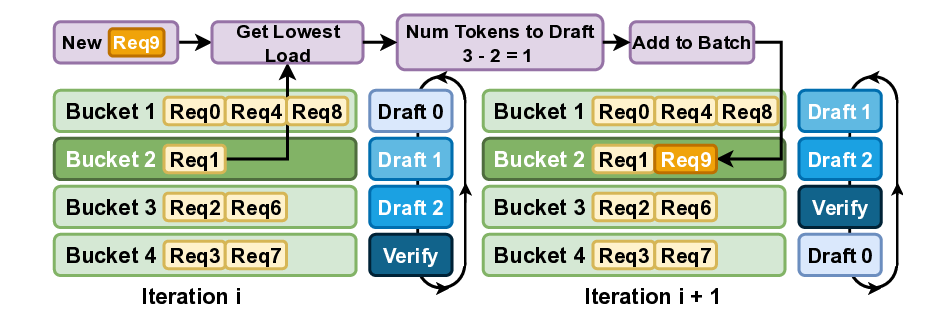
통합 배치 스케줄러: 여러 초안과 검증 단계를 단일 배치로 통합하여 메모리 로딩 비용을 줄입니다. 또한, 요청을 균등하게 분배하여 반복마다 작업이 균형 있게 분산되도록 합니다 (§ 4.2).
지연 검증: 검증 지연은 CPU 작업을 비판 경로에서 제거하여 GPU 작업과 겹치게 합니다. 이를 통해 통합된 배치의 실행 시간은 (i-1)번째 반복에서 CPU가 메타데이터를 준비한 후, (i)번째 반복에서 GPU 작업이 시작됩니다 (§ 4.3).
동적 KV 캐시 관리자: 동적 KV 캐시 관리자는 CPU 메모리로의 비동기 및 조각화된 로딩을 통해 KV 캐시 활용도를 극대화합니다 (§ 4.4).
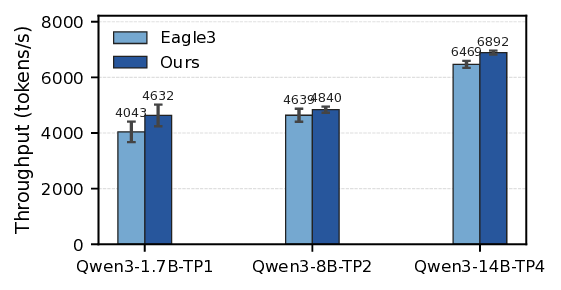
우리는 다양한 추론 모델에 SparseSpec을 프로토타입으로 평가하고, NVIDIA DGX-H100 서버에서 다양한 텐서 병렬 구성을 사용하여 실세계 워크로드에 대해 테스트했습니다. AIME (Numina, 2025), OlympiadBench (He et al., 2024), LiveCodeBench (Jain et al., 2024b)와 같은 실제 작업에서 SparseSpec은 최대 2.13배의 처리량 향상을 달성했습니다. 또한, 기존 훈련 없는 방법인 vLLM-NGram, MagicDec (Chen et al., 2024), TriForce (Sun et al., 2024)과 비교했을 때, SparseSpec은 최대 1.56배, 1.36배, 1.76배의 처리량 향상을 달성했습니다.
본 논문은 다음과 같은 기여를 합니다:
RLM 추론 성능의 병목 현상을 분석하고, 희소 자기 추측에 대한 이론적 공식화를 제공합니다.