단답형 구성형 질문 자동 채점 근접 데이터 활용 프레임워크
📝 원문 정보
- Title: AI-Enabled grading with near-domain data for scaling feedback with human-level accuracy
- ArXiv ID: 2512.04113
- 발행일: 2025-12-01
- 저자: Shyam Agarwal, Ali Moghimi, Kevin C. Haudek
📝 초록 (Abstract)
구성형 질문은 학습자의 핵심 개념 이해를 촉진하고 생성적 사고를 유도하는 데 필수적이다. 그러나 강사의 시간 부족, 대규모 학급, 기타 자원 제약으로 인해 시기적절하고 상세한 평가를 제공하기가 어렵다. 수동 채점은 노동 집약적이며, 자동 채점은 모든 가능한 응답 시나리오에 일반화하기 복잡하다. 본 논문은 짧은 답변 구성형 질문을 채점하기 위한 새로운 실용적 접근법을 제안한다. 문제의 난이도를 논의하고, 우리 방법이 적용 가능한 질문 유형을 정의한 뒤, 이전 연도에 유사 질문으로부터 수집된 근접 데이터를 활용하는 프레임워크를 제시한다. 제안된 방법은 최신 머신러닝 모델 및 GPT‑3.5, GPT‑4, GPT‑4o와 같은 비미세조정 대형 언어 모델에 비해 10~20% 이상의 성능 향상을 보이며, 모델 정답을 제공하더라도 우수한 결과를 유지한다. 또한 사전 작성된 채점 루브릭이 필요 없으며, 실제 교실 환경에 맞게 설계되었다.💡 논문 핵심 해설 (Deep Analysis)
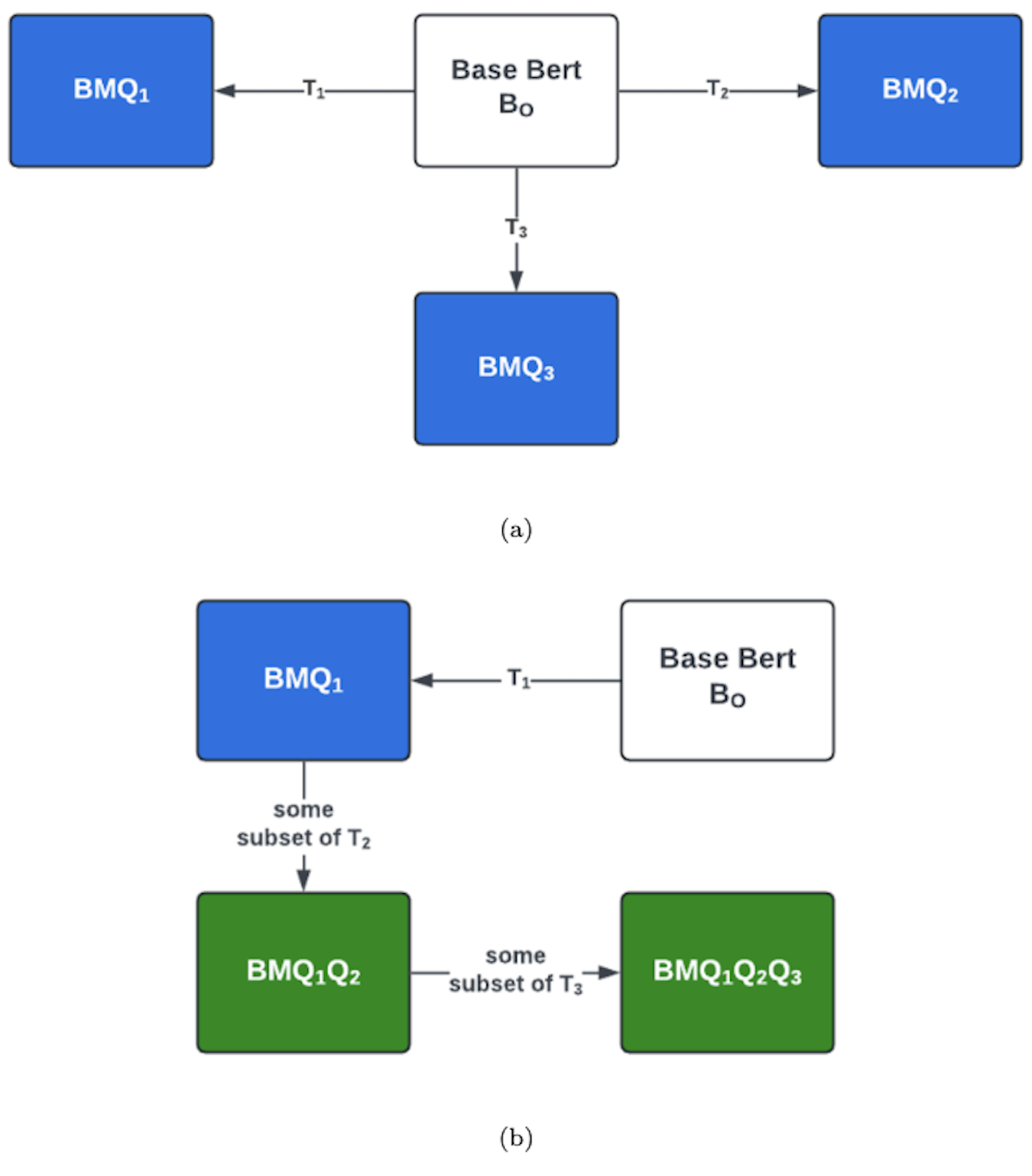
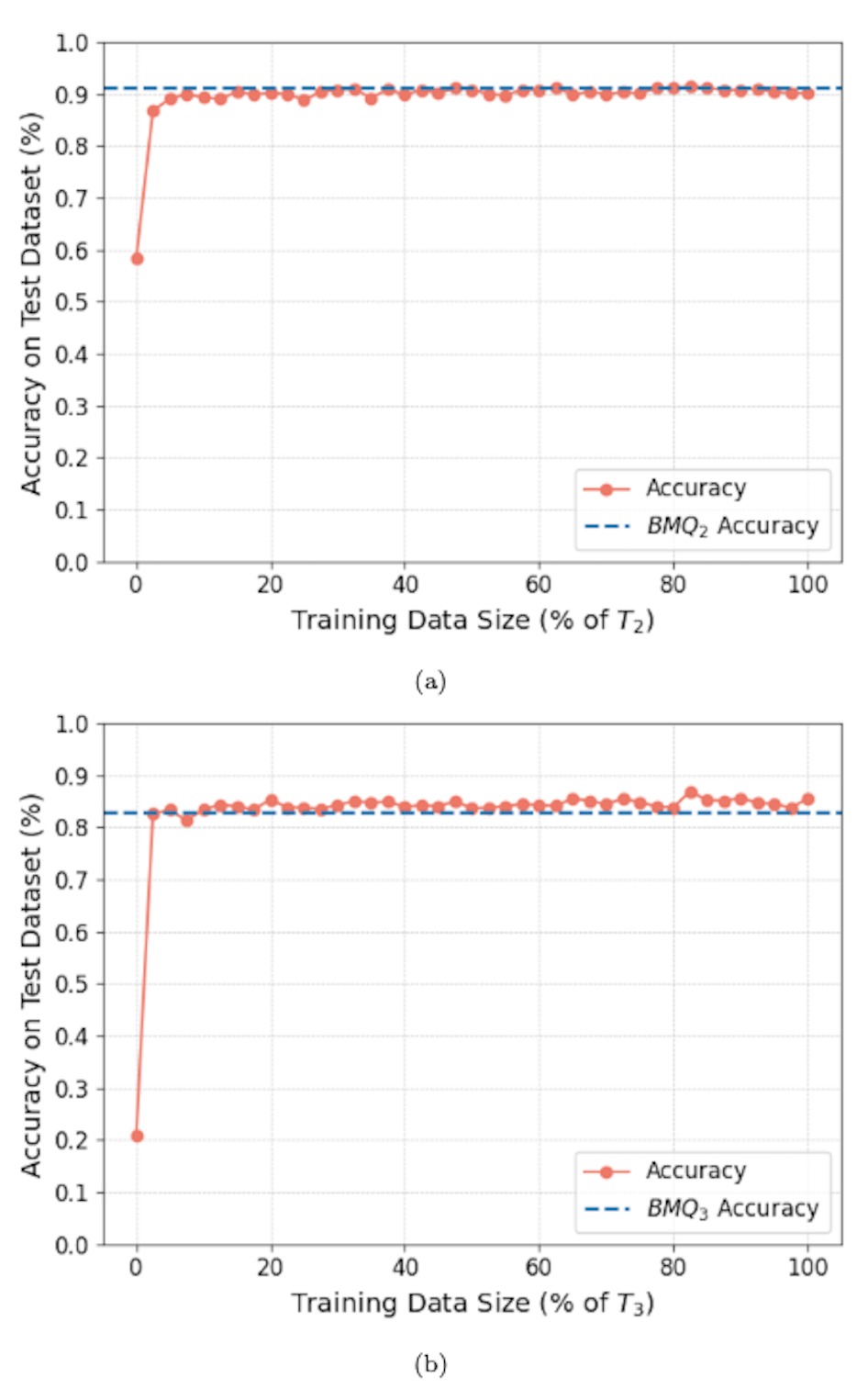
실험 설계는 최신 머신러닝 기반 채점 모델과 OpenAI의 GPT‑3.5, GPT‑4, GPT‑4o를 비교 대상으로 삼았다. 특히 LLM에게는 정답 모델을 제공한 ‘프롬프트 엔지니어링’ 조건을 추가했음에도 불구하고, 제안 프레임워크가 10~20% 높은 정확도를 기록한 점은 주목할 만하다. 이는 근접 데이터가 단순 텍스트 매칭을 넘어, 의미적 유사성을 정량화하고, 채점 기준을 동적으로 조정하는 데 효과적임을 시사한다.
하지만 몇 가지 제한점도 존재한다. 첫째, 근접 데이터의 품질과 양에 크게 의존한다는 점이다. 과거 시험이 충분히 다양하고, 채점이 일관되게 이루어졌을 경우에만 모델이 안정적인 성능을 보인다. 둘째, 새로운 주제나 급변하는 교육 커리큘럼에 대해서는 데이터 부족 문제가 발생할 수 있다. 셋째, 현재 프레임워크는 ‘짧은 답변’에 초점을 맞추고 있어, 장문 서술형이나 복합적인 문제 해결 과정을 평가하는 데는 추가 연구가 필요하다.
향후 연구 방향으로는 (1) 데이터 증강 기법을 도입해 근접 데이터가 부족한 영역을 보완하고, (2) 다중 모달(텍스트·이미지·수식) 정보를 통합해 보다 복합적인 구성형 질문에 적용하며, (3) 교사와 학생에게 실시간 피드백을 제공할 수 있는 인터페이스를 개발하는 것이 제안된다. 이러한 확장은 자동 채점 기술을 단순 평가 도구를 넘어, 학습 분석 및 맞춤형 교육 지원 시스템으로 발전시키는 기반이 될 것이다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리