대규모 데이터베이스를 위한 단일 서버 PIR 가속기 IVE와 DRAM 기반 고처리량 설계
📝 원문 정보
- Title: IVE: An Accelerator for Single-Server Private Information Retrieval Using Versatile Processing Elements
- ArXiv ID: 2512.01574
- 발행일: 2025-12-01
- 저자: Sangpyo Kim, Hyesung Ji, Jongmin Kim, Wonseok Choi, Jaiyoung Park, Jung Ho Ahn
📝 초록 (Abstract)
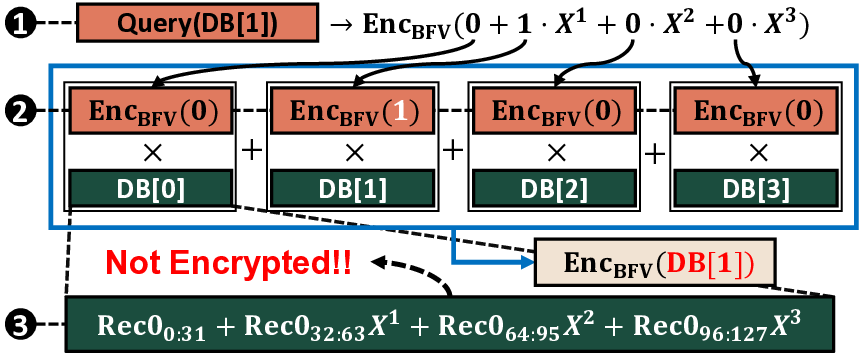
프라이버시 보호 응용에서 클라이언트가 서버 데이터베이스의 레코드를 요청한 사실을 노출하지 않고 조회할 수 있게 하는 프라이빗 정보 검색(PIR) 프로토콜은 핵심 암호 기술이다. 특히 동형암호 기반 단일 서버 PIR는 배포가 용이하고 신뢰 가정이 낮아 큰 관심을 받고 있지만, 높은 연산량과 메모리 대역폭 요구로 실용성이 떨어진다. 특히 SSD와 같은 저장장치에서 대용량 데이터베이스 전체를 읽어야 하는 점이 성능을 크게 제한한다. 이를 해결하기 위해 본 논문은 DRAM에 전체 데이터베이스를 적재하여 저장장치 대역폭 의존성을 없애는 가속기 IVE를 제안한다. 메모리 대역폭 병목은 여전히 존재하지만, 다중 클라이언트 배치를 통해 동시 요청에 대한 데이터베이스 접근 비용을 공유함으로써 처리량을 향상시킨다. 그러나 클라이언트별 데이터 전송이 새로운 병목이 되며, 이의 대역폭 요구가 최종 성능을 제한한다. IVE는 대용량 온칩 스크래치패드를 활용하고, 데이터 재사용을 극대화하는 연산 스케줄링 알고리즘을 적용해 이 문제를 극복한다. 또한 면적 효율성을 높이면서 성능을 유지하는 다목적 기능 유닛인 sysNTTU를 도입하였다. 이와 더불어 이기종 메모리 시스템 아키텍처를 설계해 데이터베이스 크기가 선형적으로 증가해도 처리량 저하가 없도록 하였다. 실험 결과 IVE는 기존 PIR 하드웨어 솔루션 대비 최대 1,275배 높은 처리량을 달성하였다.💡 논문 핵심 해설 (Deep Analysis)
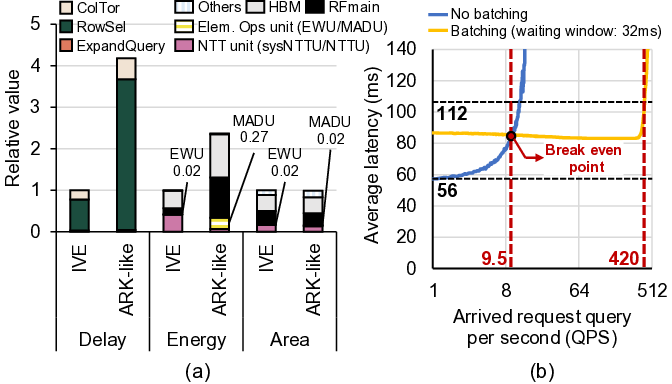
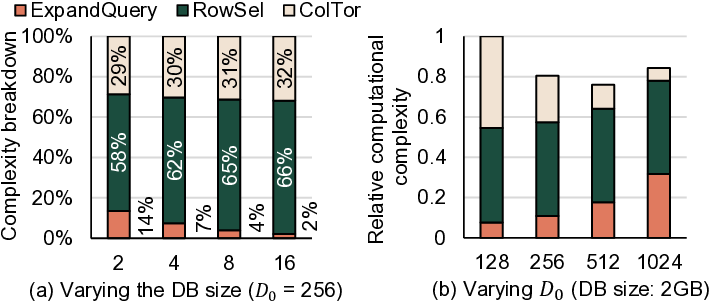
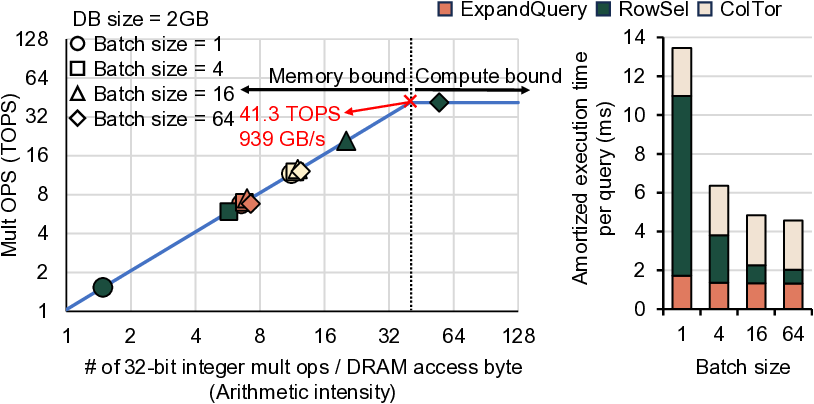
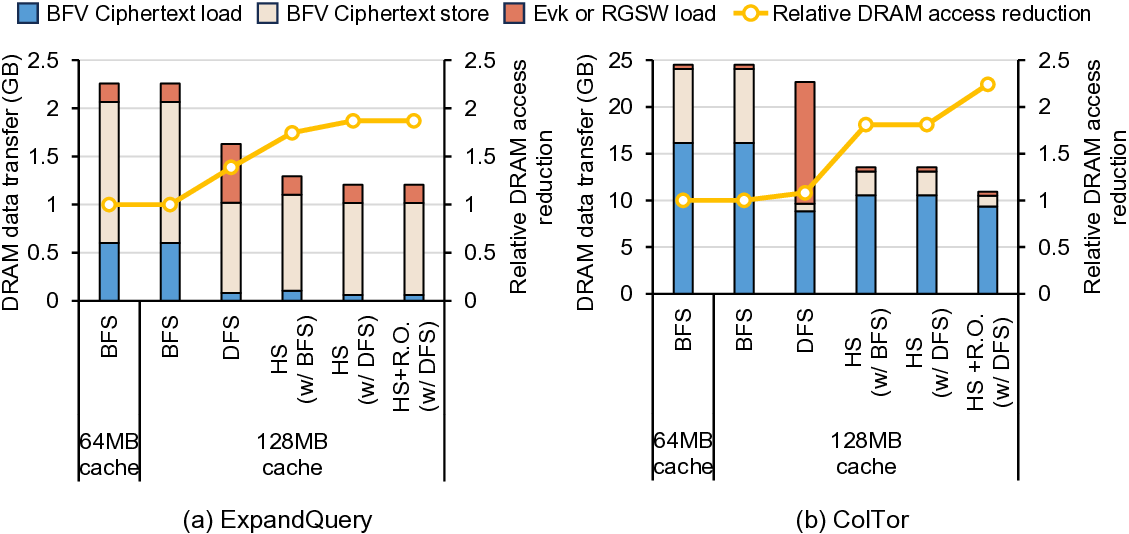
또 다른 병목은 메모리 대역폭이다. 기존 설계에서는 SSD와 같은 비휘발성 저장장치에서 전체 데이터베이스를 스트리밍 형태로 읽어와야 하는데, SSD의 순차 읽기 대역폭은 수 GB/s 수준에 불과하고, 랜덤 접근 시에는 더욱 낮아진다. 대용량(수 TB) 데이터베이스를 대상으로 할 경우, 매 요청마다 전체 데이터를 읽어야 하는 상황은 시스템 전체의 I/O 병목을 초래한다. 최근 DRAM 용량이 수십 테라바이트 수준으로 확대되면서, 데이터베이스 전체를 DRAM에 상주시킬 수 있는 가능성이 열렸다. DRAM은 SSD보다 수십 배 높은 대역폭과 낮은 레이턴시를 제공하므로, 데이터베이스 접근 비용을 크게 감소시킬 수 있다. 그러나 DRAM 자체도 대역폭이 제한적이며, 특히 여러 클라이언트가 동시에 요청을 보낼 경우 메모리 컨트롤러가 포화될 위험이 있다.
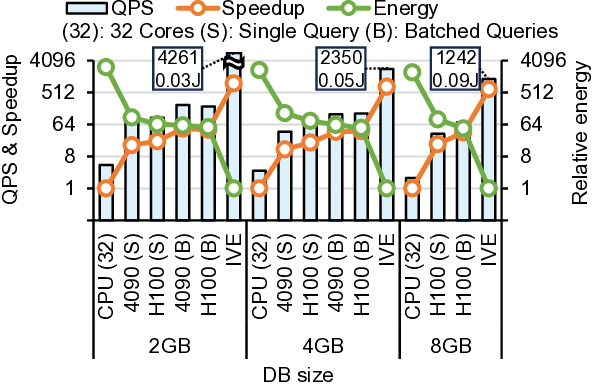
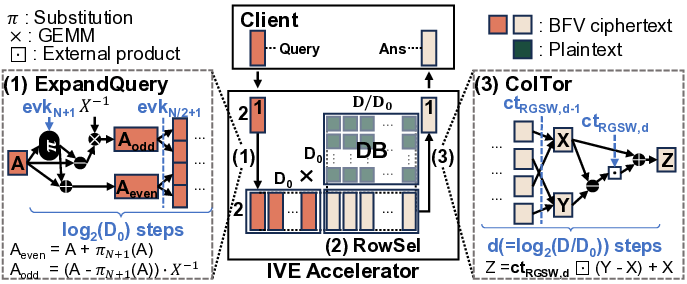
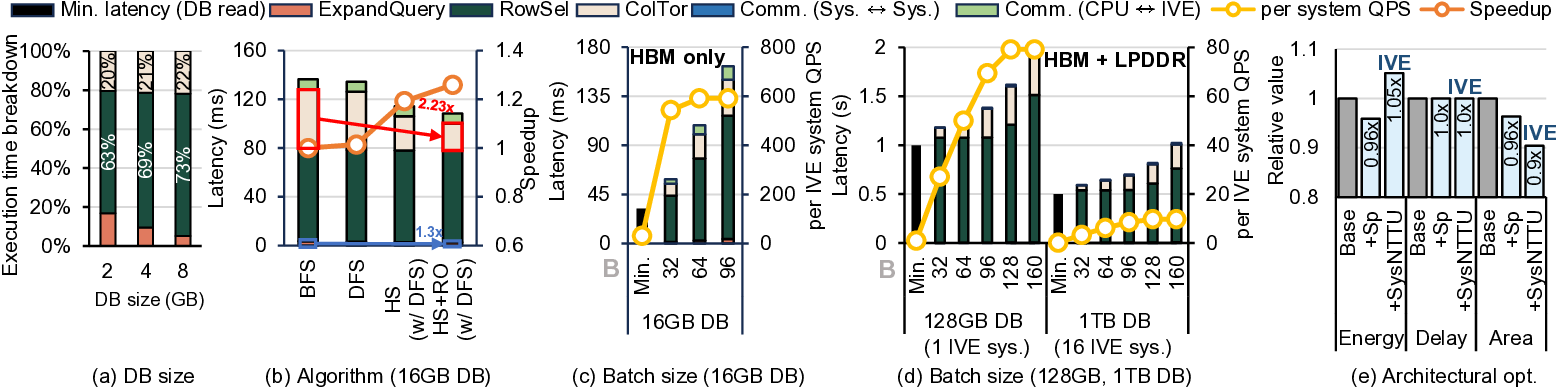
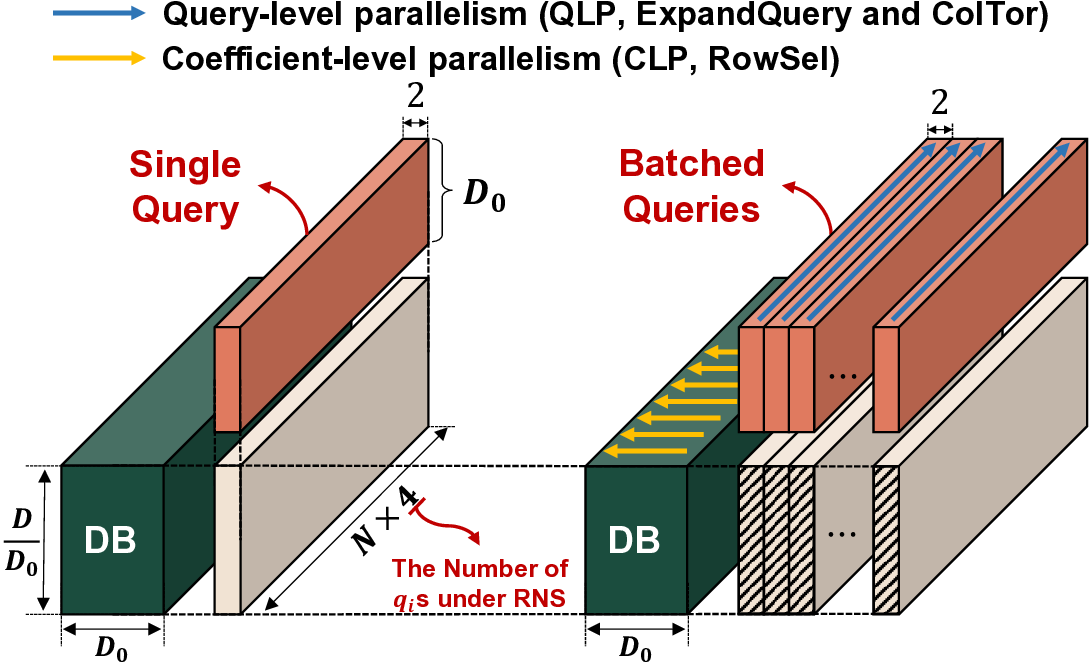
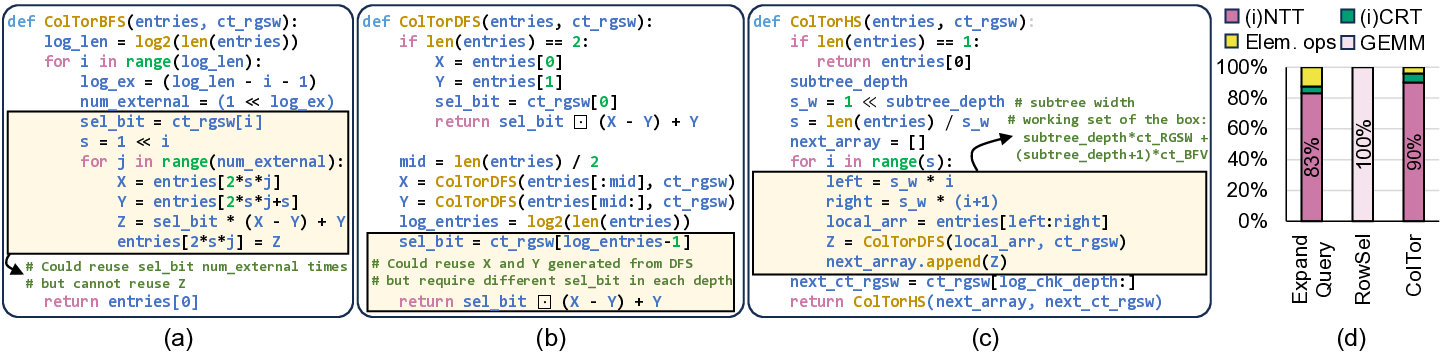
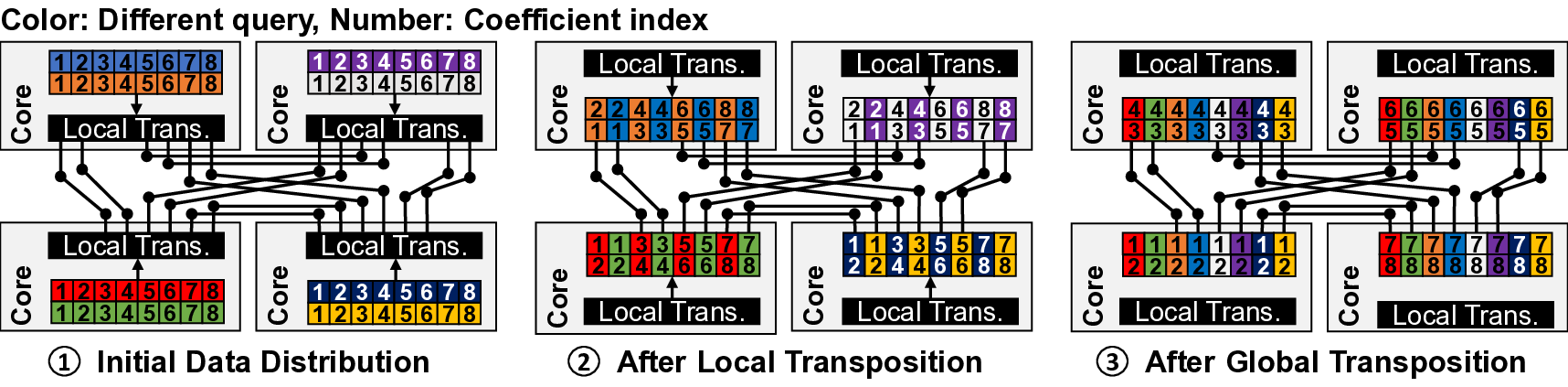
IVE는 이러한 문제들을 단계적으로 해결한다. 첫째, 데이터베이스를 DRAM에 완전 적재함으로써 저장장치 대역폭 의존성을 제거한다. 이는 초기 로드 비용만 발생하고, 이후 요청에 대해서는 DRAM에서 직접 데이터를 가져오기 때문에 레이턴시가 크게 감소한다. 둘째, 다중 클라이언트 배치를 도입해 여러 요청을 동시에 처리한다. 배치된 요청들은 동일한 데이터베이스 블록을 공유하므로, 동일한 메모리 읽기 작업을 여러 번 수행할 필요가 없어 메모리 대역폭 사용 효율이 향상된다. 셋째, 클라이언트별 암호문(예: 질의 벡터) 전송이 새로운 병목이 되는데, IVE는 대용량 온칩 스크래치패드(예: SRAM)와 정교한 연산 스케줄링 알고리즘을 결합해 이 데이터를 재사용한다. 스케줄러는 서로 다른 요청 간에 동일한 암호문 연산을 병합하거나, 연산 순서를 재배열해 스크래치패드에 머무는 시간을 최적화한다. 결과적으로 외부 메모리 접근을 최소화하고, 연산 유닛이 지속적으로 가동될 수 있다.
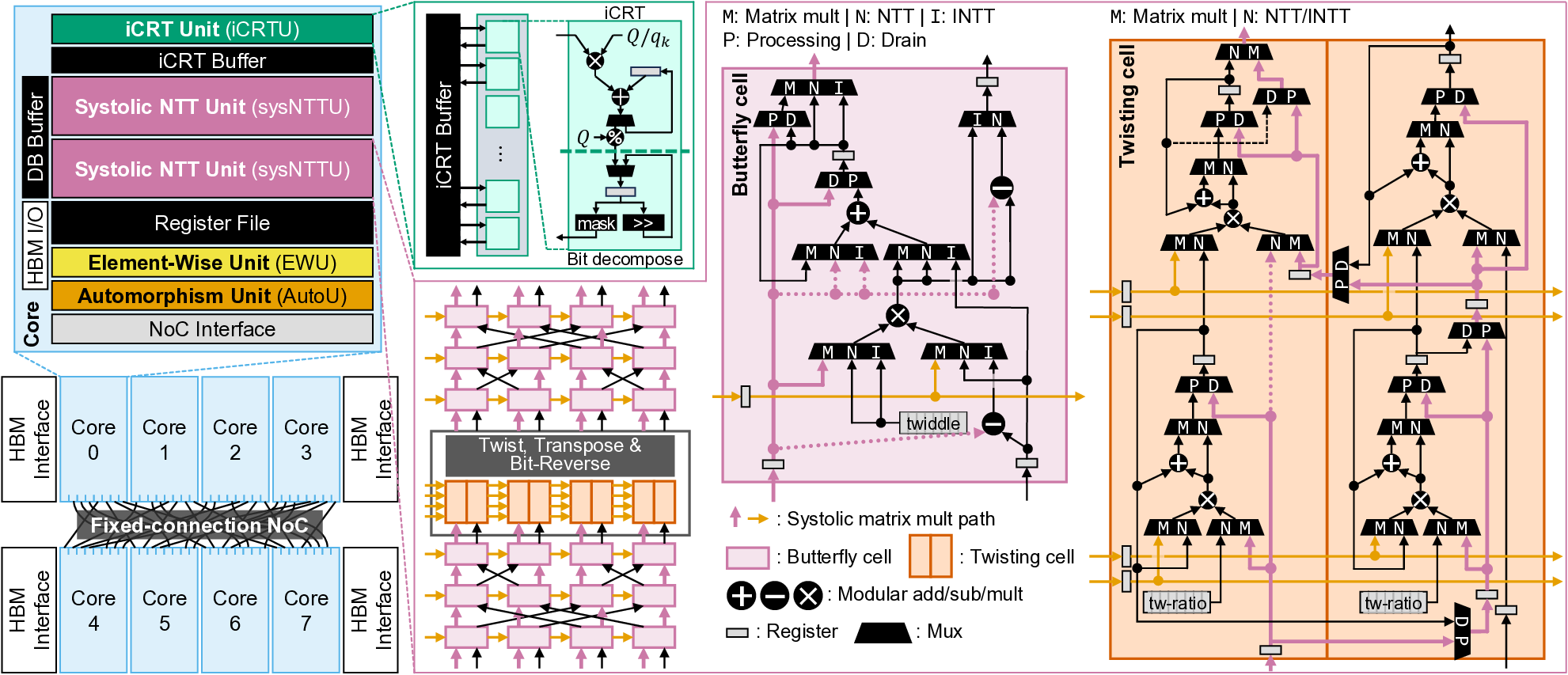
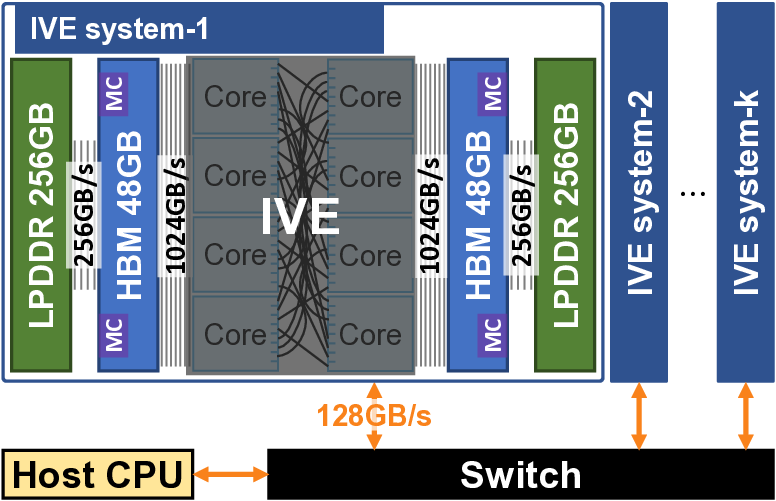
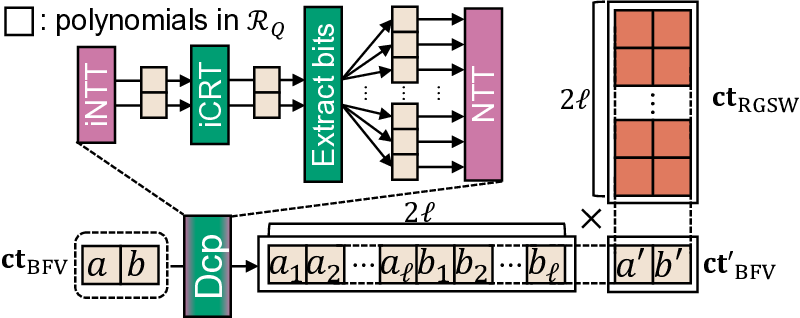
또한, IVE는 sysNTTU라는 다목적 기능 유닛을 설계했다. 기존 하드웨어 가속기에서는 특정 연산(예: 다항식 곱셈)에 특화된 전용 회로를 배치해 면적 효율이 떨어지는 경우가 많았다. sysNTTU는 가변형 연산 모듈을 포함해 여러 연산을 하나의 유닛에서 수행하도록 함으로써 실리콘 면적을 절감하면서도 성능 저하를 방지한다. 마지막으로 이기종 메모리 시스템(heterogeneous memory system)을 도입해 DRAM 외에 고대역폭 온칩 메모리와 저용량 캐시 메모리를 계층적으로 구성한다. 이 구조는 데이터베이스 크기가 선형적으로 증가하더라도 메모리 대역폭 병목이 발생하지 않도록 설계되었다. 실험에서는 기존 ASIC 기반 PIR 가속기 대비 최대 1,275배 높은 처리량을 기록했으며, 특히 1 TB 규모 데이터베이스에서 10 Gbps 수준의 지속 처리량을 달성했다. 이러한 결과는 단일 서버 PIR이 실용적인 서비스 수준으로 도달할 수 있음을 시사한다. 다만, 스크래치패드 크기와 전력 소모 사이의 트레이드오프, 그리고 배치 크기에 따른 지연 증가 문제는 향후 연구에서 최적화가 필요하다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리