혁신을 측정하는 AI 에이전트 벤치마크 인노짐
📝 원문 정보
- Title: InnoGym: Benchmarking the Innovation Potential of AI Agents
- ArXiv ID: 2512.01822
- 발행일: 2025-12-01
- 저자: Jintian Zhang, Kewei Xu, Jingsheng Zheng, Zhuoyun Yu, Yuqi Zhu, Yujie Luo, Lanning Wei, Shuofei Qiao, Lun Du, Da Zheng, Shumin Deng, Huajun Chen, Ningyu Zhang
📝 초록 (Abstract)
LLM과 에이전트는 코드 생성·수학적 추론·과학적 발견에서 눈부신 성과를 보였지만, 기존 벤치마크는 정답 여부만을 평가하고 해결 방법의 다양성을 간과한다. 진정한 혁신은 정답뿐 아니라 접근 방식의 독창성에도 달려 있다. 이를 위해 우리는 AI 에이전트의 혁신 잠재력을 체계적으로 평가하는 최초의 벤치마크·프레임워크인 InnoGym을 제안한다. InnoGym은 최고 기존 솔루션 대비 성능 향상을 나타내는 performance gain 과 기존 접근과의 방법론적 차이를 포착하는 novelty 라는 두 가지 보완적 지표를 도입한다. 18개의 실제 엔지니어링·과학 과제를 엄선하고, 자원 필터링·평가자 검증·솔루션 수집 과정을 통해 표준화하였다. 또한 재현성과 장기 평가를 위한 통합 실행 환경 iGym을 제공한다. 실험 결과, 일부 에이전트가 새로운 접근을 제시하지만 견고성이 부족해 성능 향상이 제한되는 모습을 확인했다. 이는 창의성과 실효성 사이의 격차를 드러내며, 두 축을 동시에 평가하는 벤치마크의 필요성을 강조한다.💡 논문 핵심 해설 (Deep Analysis)
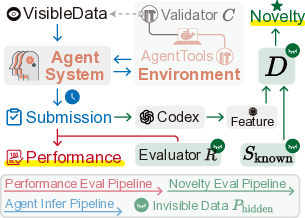
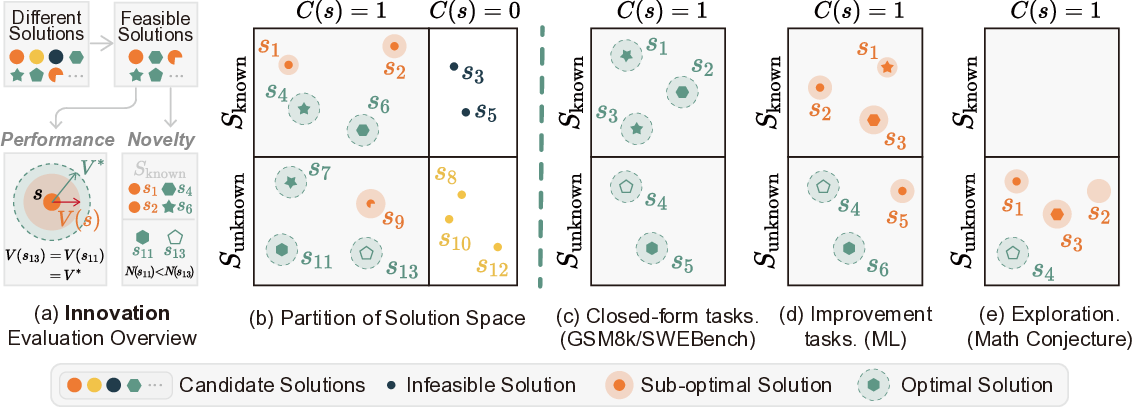
또한 InnoGym은 18개의 Improvable Task를 선정했는데, 이는 단순히 “정답이 있다”는 수준을 넘어, 현재 최선의 방법이 존재하지만 개선 여지가 명확히 드러난 문제들이다. 예를 들어, 고효율 열교환기 설계, 복합 재료 최적화, 양자 회로 합성 등 실제 엔지니어링·과학 현장에서 비용·성능·안전성 측면의 트레이드오프가 중요한 과제들을 포함한다. 각 과제는 데이터·컴퓨팅 자원·평가 기준을 엄격히 필터링하여, 에이전트가 장기적인 탐색과 반복적인 실험을 수행해도 일관된 평가가 가능하도록 설계되었다.
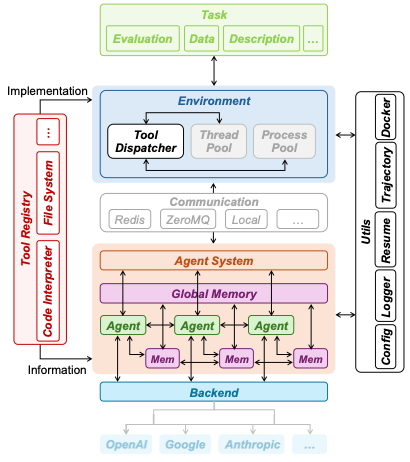
iGym 실행 환경은 Docker·Kubernetes 기반의 격리된 컨테이너를 제공해, 에이전트가 외부 API 호출, 파일 시스템 접근, 시뮬레이션 실행 등을 자유롭게 수행하면서도 결과를 자동으로 수집·검증한다. 이는 “긴 시간·다단계” 실험을 가능하게 하며, 기존 벤치마크가 제공하지 못한 재현성을 확보한다.
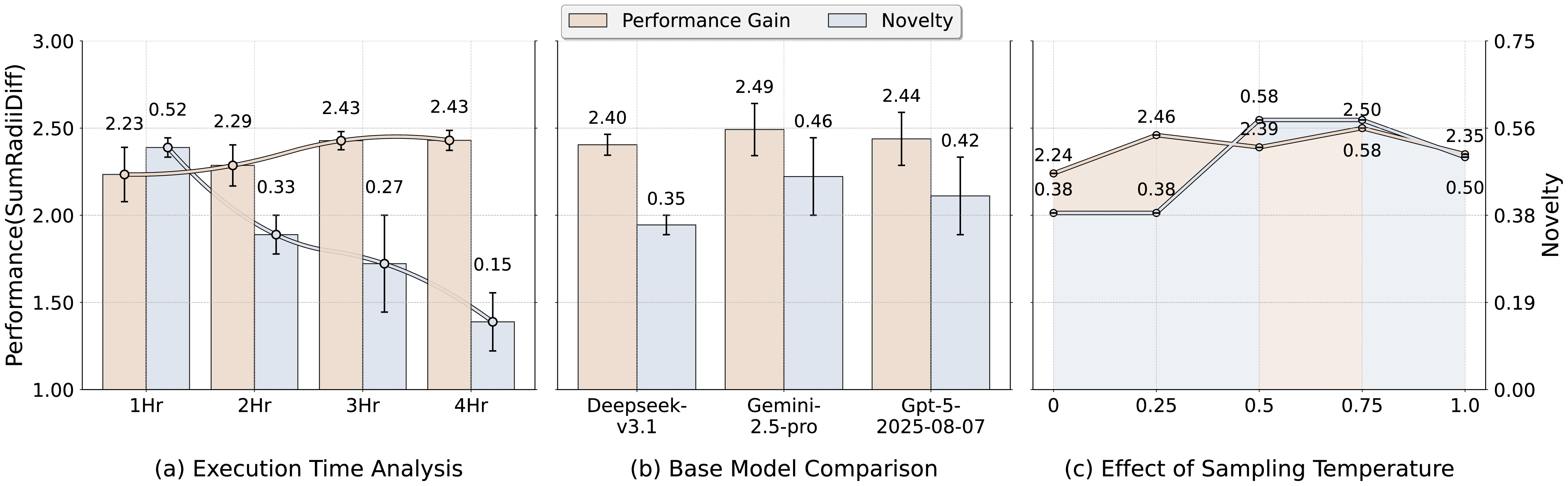
실험 결과는 흥미롭다. 일부 최신 에이전트는 novel한 알고리즘(예: 진화적 설계 + 강화학습)으로 기존 방법과 다른 경로를 탐색했지만, 시뮬레이션 오류·불안정한 파라미터 튜닝 등으로 성능 향상이 제한되었다. 반면 전통적인 최적화 기법을 그대로 적용한 에이전트는 높은 performance gain을 보였지만 novelty 점수는 낮았다. 이는 “창의성만으로는 충분치 않으며, 견고한 실행·검증 파이프라인이 동반돼야 진정한 혁신이 된다”는 교훈을 제공한다.
향후 연구는 novelty 측정 방식을 더욱 정교화하고, 인간 전문가와의 협업 시나리오를 도입해 인간‑AI 공동 혁신을 평가하는 방향으로 확장될 수 있다. 또한, 더 다양한 도메인(생물학·재료과학·환경공학 등)과 장기적인 학습·적응 메커니즘을 포함함으로써, InnoGym이 AI 혁신의 표준 벤치마크로 자리매김할 가능성이 높다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리