지시와 정책의 공동 진화 기반 강화학습
📝 원문 정보
- Title: Agentic Policy Optimization via Instruction-Policy Co-Evolution
- ArXiv ID: 2512.01945
- 발행일: 2025-12-01
- 저자: Han Zhou, Xingchen Wan, Ivan Vulić, Anna Korhonen
📝 초록 (Abstract)
강화학습 기반 검증 보상(RLVR)은 대형 언어 모델(LLM)의 추론 능력을 크게 향상시켜, 다중 턴 및 도구 통합 추론을 수행할 수 있는 자율 에이전트를 가능하게 한다. 기존 RLVR은 정적이고 수동 설계된 지시문에 의존하지만, 이러한 지시문은 기본 모델에 최적이 아닐 수 있으며, 정책이 향상되고 환경과의 상호작용이 진행됨에 따라 최적의 지시문도 변한다. 이를 해결하기 위해 우리는 INSPO라는 새로운 지시‑정책 공동 진화 프레임워크를 제안한다. INSPO는 질문과 함께 샘플링되는 동적 지시문 후보군을 유지하고, 강화학습 루프에서 얻은 보상을 각 지시문에 자동으로 할당한다. 성능이 낮은 후보는 주기적으로 제거되고, 온‑정책 반성 메커니즘을 통해 LLM 기반 최적화기가 리플레이 버퍼의 과거 경험을 분석해 현재 정책에 맞는 더 효과적인 지시문을 생성·검증한다. 다중 턴 검색 및 추론 과제에 대한 광범위한 실험 결과, INSPO는 정적 지시문에 의존하는 강력한 베이스라인보다 크게 우수한 성능을 보이며, 전략적 추론 경로를 유도하는 혁신적인 지시문을 발견한다. 계산 비용은 미미하게 증가한다.💡 논문 핵심 해설 (Deep Analysis)

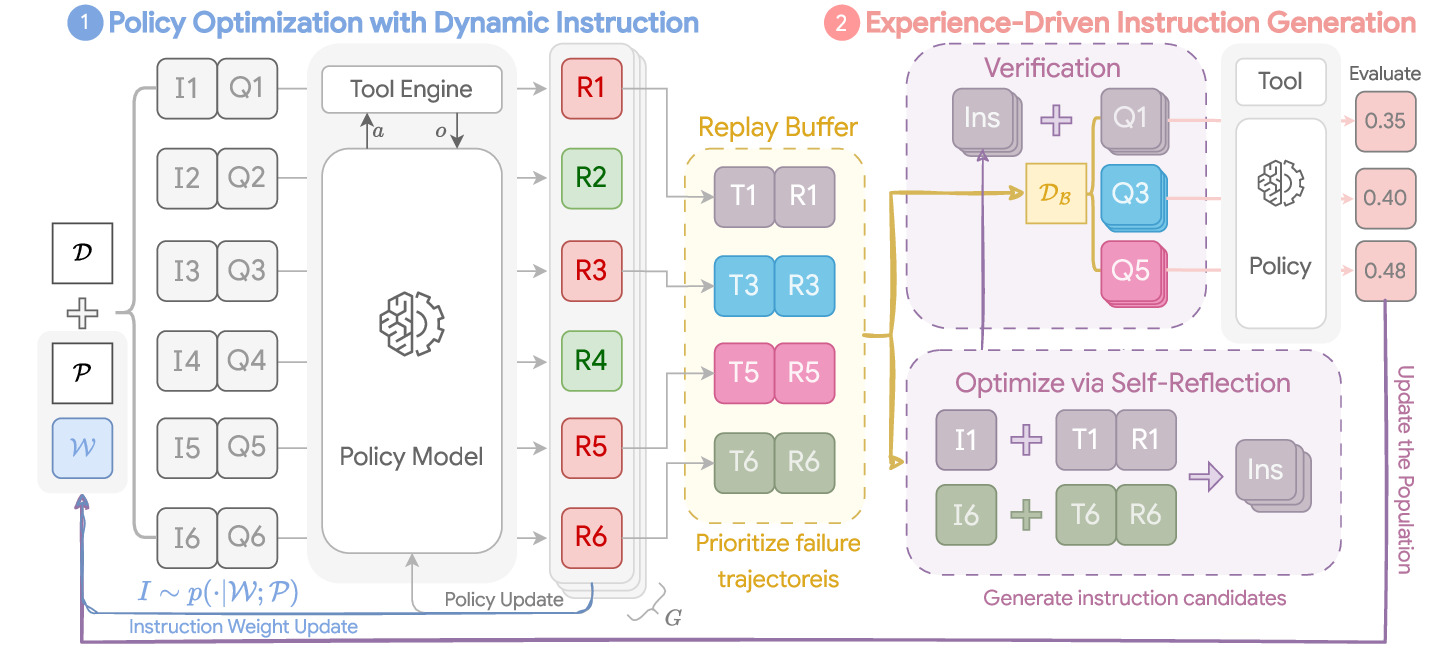
구현 측면에서 INSPO는 두 단계의 메커니즘을 사용한다. 첫째, ‘보상 귀속 단계’에서는 현재 정책이 수행한 여러 에피소드에 대해 각 질문에 매칭된 지시문별 보상을 계산한다. 이는 질문‑지시문 매핑을 유지함으로써 가능해지며, 보상 신호가 지시문의 질을 직접 평가한다. 둘째, ‘반성·생성 단계’에서는 LLM 기반 옵티마이저가 리플레이 버퍼에 저장된 경험을 분석한다. 여기서 옵티마이저는 메타‑프롬프트를 활용해 “현재 정책이 어려워하는 상황은 무엇인가”, “어떤 지시가 더 구체적·전략적일 수 있는가” 등을 스스로 질문하고, 새로운 지시문 후보를 생성한다. 생성된 후보는 검증 과정을 거쳐 기존 후보군에 추가되며, 성능이 낮은 후보는 주기적으로 프루닝된다.
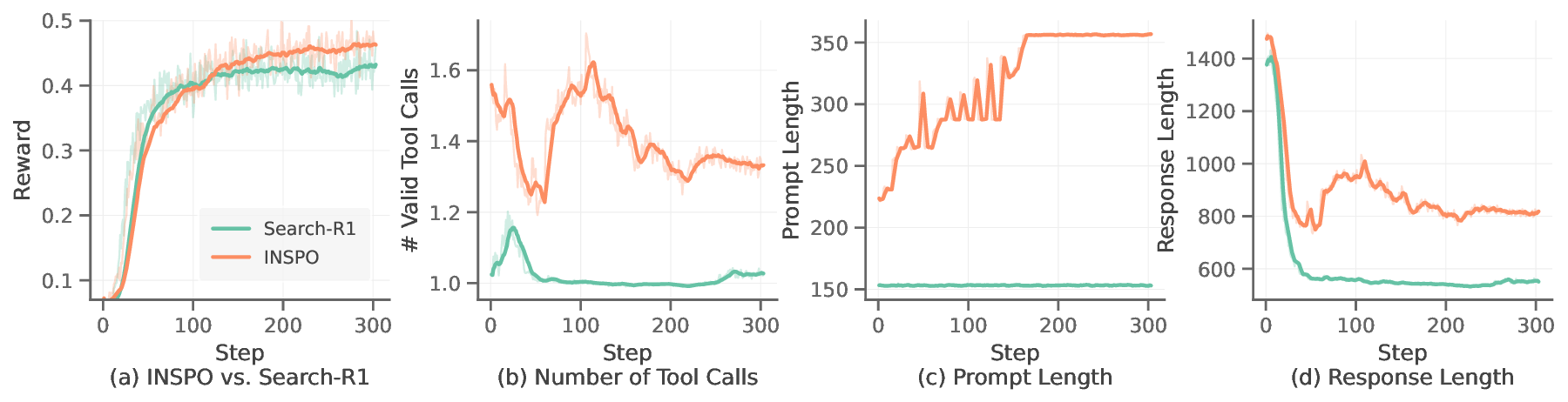
실험에서는 다중 턴 검색(Multi‑turn Retrieval)과 복합 추론(Multi‑step Reasoning) 두 가지 벤치마크를 사용하였다. 정적 지시문을 사용한 최신 RLVR 베이스라인과 비교했을 때, INSPO는 평균 정확도/성공률에서 47%p 상승을 기록했다. 특히 복잡한 논리 추론 과제에서 ‘전략적 질문 전환’과 같은 혁신적인 지시문을 스스로 발견해, 에이전트가 불필요한 탐색을 줄이고 핵심 단서에 집중하도록 만들었다. 계산 비용 측면에서는 지시문 집단 관리와 옵티마이저 호출이 전체 학습 시간에 510% 정도만 추가되어, 실용적인 수준으로 유지되었다.
강점으로는 (1) 지시문을 동적으로 최적화함으로써 정책‑환경 상호작용을 보다 효율적으로 만들었다는 점, (2) LLM 자체를 메타‑옵티마이저로 활용해 인간 개입 없이도 지시문을 진화시켰다는 점, (3) 기존 RLVR 프레임워크와 손쉽게 통합될 수 있다는 점을 들 수 있다. 반면 약점은 (1) 지시문 집단 규모가 커질 경우 메모리·연산 부담이 선형적으로 증가할 가능성, (2) 보상 귀속이 질문‑지시문 매핑에 크게 의존하므로, 매핑 오류가 전체 학습에 악영향을 미칠 위험, (3) 현재 실험이 제한된 도메인에만 적용돼 일반화 여부가 아직 검증되지 않았다는 점이다. 향후 연구에서는 (a) 지시문 후보군을 압축·클러스터링하는 방법, (b) 다중 에이전트 환경에서 공동 지시문 진화를 탐색, (c) 인간 피드백을 최소화하면서도 안전성을 보장하는 검증 메커니즘 구축 등이 기대된다. 전반적으로 INSPO는 LLM 기반 에이전트가 스스로 학습 목표와 행동 지침을 동시에 진화시킬 수 있는 새로운 패러다임을 제시하며, 향후 자율 AI 시스템 설계에 중요한 이정표가 될 것으로 판단된다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리