색채 위장 이미지 이해를 위한 대규모 멀티태스크 벤치마크
📝 원문 정보
- Title: ChromouVQA: Benchmarking Vision-Language Models under Chromatic Camouflaged Images
- ArXiv ID: 2512.05137
- 발행일: 2025-11-30
- 저자: Yunfei Zhang, Yizhuo He, Yuanxun Shao, Zhengtao Yao, Haoyan Xu, Junhao Dong, Zhen Yao, Zhikang Dong
📝 초록 (Abstract)
Vision‑Language Model(VLM)은 멀티모달 이해에서 큰 진전을 이루었지만, 복잡한 배경에 섞여 있는 대상, 즉 피겨‑그라운드 구분이 필요한 경우 여전히 어려움을 겪는다. 이를 해결하고자 우리는 이시하라식 색채 위장 이미지에 기반한 대규모 다중 과제 벤치마크인 ChromouVQA를 제안한다. 기존의 점 플레이트를 다중 채우기 형태로 확장하고, 색 차이, 밀도, 크기, 가림, 회전 등을 다양하게 조절하여 재현성을 위한 메타데이터를 전부 기록하였다. 이 벤치마크는 인식, 개수 세기, 비교, 공간 추론 등 아홉 가지 비전‑질문‑답변 과제를 포함한다. 인간과 VLM을 평가한 결과, 특히 미세한 색 대비나 방해가 되는 기하학적 채우기 상황에서 큰 성능 격차가 나타났다. 또한 우리는 실루엣과 위장된 이미지 사이를 정렬하는 모델‑불가지론적 대비 학습 방식을 제안하여 전역 형태 복원 능력을 향상시켰다. ChromouVQA는 재현 가능하고 확장 가능한 컴팩트 벤치마크를 제공한다. 코드와 데이터셋은 https://github.com/Chromou-VQA-Benchmark/Chromou-VQA 에서 확인할 수 있다.💡 논문 핵심 해설 (Deep Analysis)
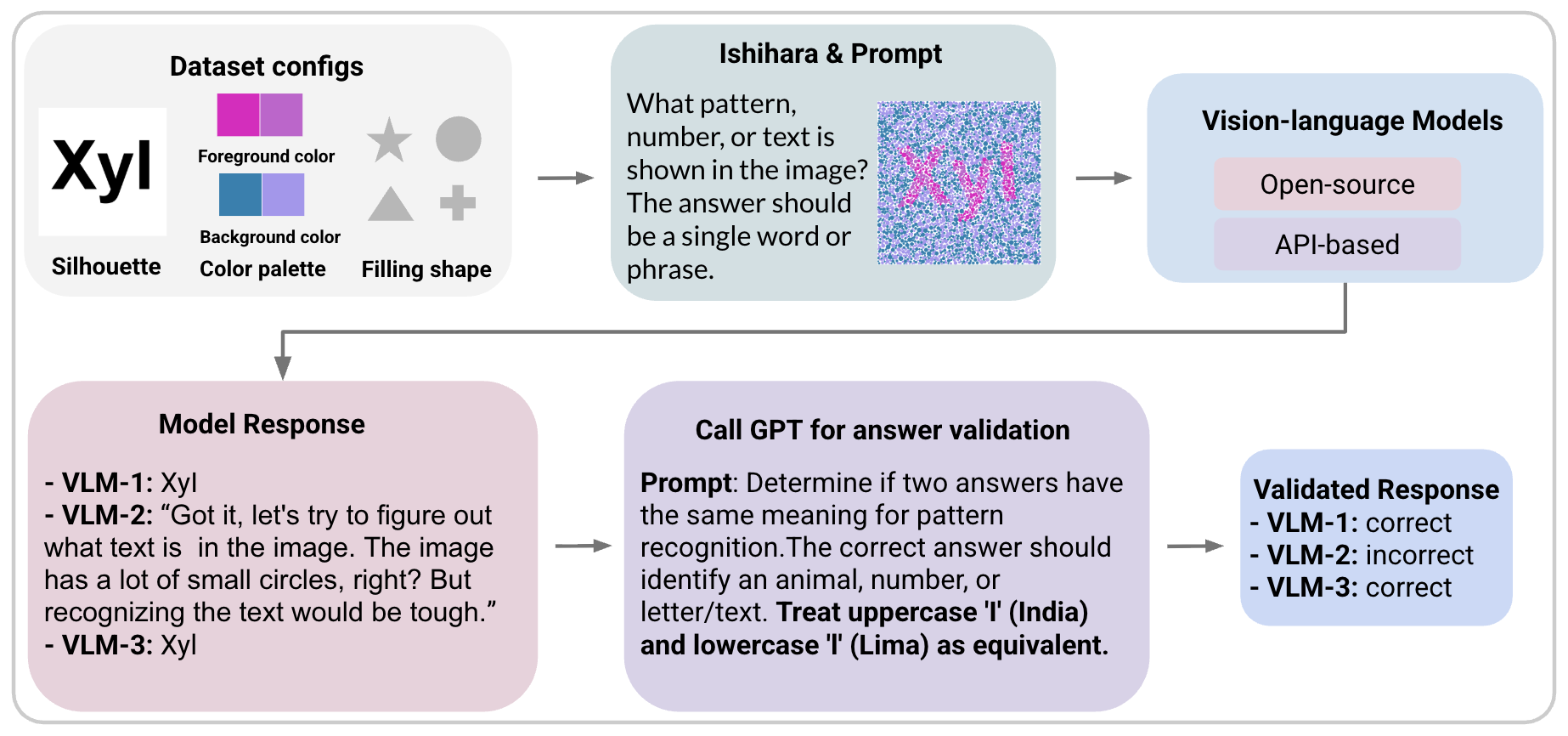
구성 요소를 살펴보면, (1) 채우기 기하학(geometry) 를 원형, 사각형, 삼각형 등 다변형으로 확장함으로써 동일한 색 대비라도 형태 복잡도에 따라 인지 난이도가 달라지도록 설계했다. (2) 색 차이(chromatic separation) 를 미세한 ΔE부터 뚜렷한 차이까지 연속적으로 변조해 인간과 모델의 색 구분 한계를 탐색한다. (3) 밀도와 크기(density, size) 를 조절해 점들의 집합이 전체 실루엣을 형성하는 정도를 조절함으로써 전역 형태 인식 능력을 테스트한다. (4) 가림(occlusion) 과 회전(rotation) 은 실제 환경에서 물체가 부분적으로 가려지거나 다양한 각도로 나타나는 상황을 모사한다. 이러한 변수들을 메타데이터로 모두 기록해 재현성을 확보했으며, 이는 향후 연구자가 동일 조건을 그대로 재현하거나 새로운 변수를 추가하기에 용이하도록 만든다.
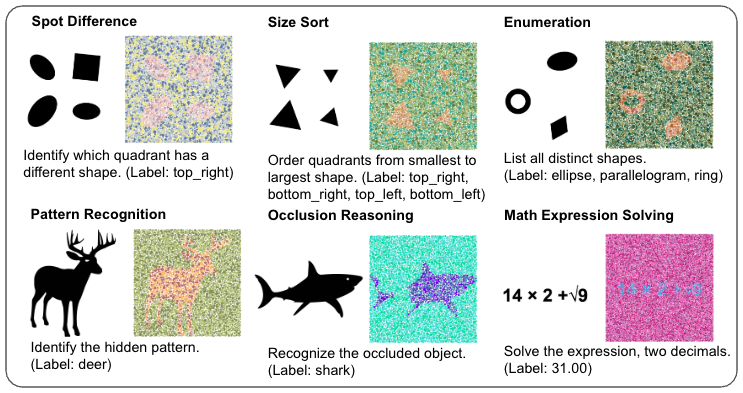
벤치마크가 포함하는 아홉 가지 VQA 과제는 단순 인식(“이 이미지에 어떤 숫자가 보이는가?”)부터 개수 세기(“빨간 점은 몇 개인가?”), 비교(“두 영역 중 어느 쪽이 더 밝은가?”), 공간 추론(“점들이 형성하는 도형의 중심은 어디인가?”)까지 다양하다. 이는 VLM이 단일 이미지 인식 수준을 넘어, 언어적 질문에 대한 논리적·수리적 추론 능력을 평가하도록 설계된 것이다.
실험 결과는 두드러진 통찰을 제공한다. 인간 피험자는 색 대비가 5 ΔE 이하인 경우에도 비교적 높은 정확도를 유지했지만, VLM은 10 ΔE 이하에서 급격히 성능이 저하되었다. 특히 기하학적 채우기가 복잡할수록(예: 다각형 혼합) 모델의 오류율이 급증했으며, 이는 현재 VLM이 전역 형태 정보를 효과적으로 통합하지 못한다는 증거이다.
이를 보완하기 위해 제안된 대조 학습(contrastive) 레시피는 원본 실루엣과 위장된 렌더링을 쌍으로 입력해, 두 이미지 간의 임베딩 거리를 최소화하도록 학습한다. 모델‑불가지론적이라는 점에서 기존의 VLM 아키텍처에 별도의 파인튜닝 없이 적용 가능하며, 실험에서는 전역 형태 복원 정확도가 평균 12 % 상승하는 효과를 보였다. 이는 VLM이 ‘전역 구조’를 학습하도록 유도하는 간단하지만 강력한 방법으로, 향후 다양한 위장·노이즈 상황에 적용될 가능성을 시사한다.
전체적으로 ChromouVQA는 (1) 통제된 변수 설계, (2) 다양한 인지 과제, (3) 재현 가능한 메타데이터라는 세 축을 갖춘 벤치마크로, VLM 연구 커뮤니티가 인간 수준의 시각적 구분 능력에 한 걸음 더 다가갈 수 있는 기반을 제공한다. 향후 연구에서는 (가) 색채 위장의 동적(비디오) 버전, (나) 다중 모달(음성·촉각) 통합, (다) 인간-모델 협업 인터페이스 등으로 확장될 여지가 크다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리