인과 머신러닝 기반 사전 유지보수 원인 규명과 최적 개입
📝 원문 정보
- Title: Integrating Causal Foundation Model in Prescriptive Maintenance Framework for Optimizing Production Line OEE
- ArXiv ID: 2512.00969
- 발행일: 2025-11-30
- 저자: Felix Saretzky, Lucas Andersen, Thomas Engel, Fazel Ansari
📝 초록 (Abstract)
제조 현장의 사전 유지보수 전환은 예측 모델에 크게 의존한다는 점에서 근본적인 제약을 받는다. 기존 예측 모델은 실제 고장의 근본 원인이라기보다 우연히 나타나는 상관관계에 의존하는 경우가 많아, 비용이 많이 드는 오진과 비효율적인 개입을 초래한다. 이러한 한계는 “고장이 발생할 가능성을 예측할 수는 있지만, 왜 발생하는지 체계적으로 이해하지 못한다”는 핵심 과제로 이어진다. 본 논문은 인과 머신러닝을 활용한 모델을 제안하여 이 격차를 메운다. 사전 학습된 인과 기반 대형 모델을 “what‑if” 시뮬레이션 도구로 활용해 잠재적 개선 조치의 효과를 추정한다. 각 개입이 전체 설비 효율(OEE) 등 시스템 수준 KPI에 미치는 인과 효과를 측정함으로써, 현장에 적용할 행동을 데이터 기반으로 순위화한다. 이 과정은 근본 원인 식별뿐 아니라 운영적 영향을 정량화한다. 제안 모델은 반실제(semisynthetic) 제조 데이터를 이용해 평가했으며, 기존 머신러닝 베이스라인과 비교하였다. 연구 결과는 엔지니어가 인과 환경에서 잠재적 해결책을 시험해 보다 효과적인 운영 결정을 내리고, 다운타임 비용을 감소시킬 수 있는 견고한 사전 유지보수 프레임워크의 기술적 기반을 제시한다.💡 논문 핵심 해설 (Deep Analysis)
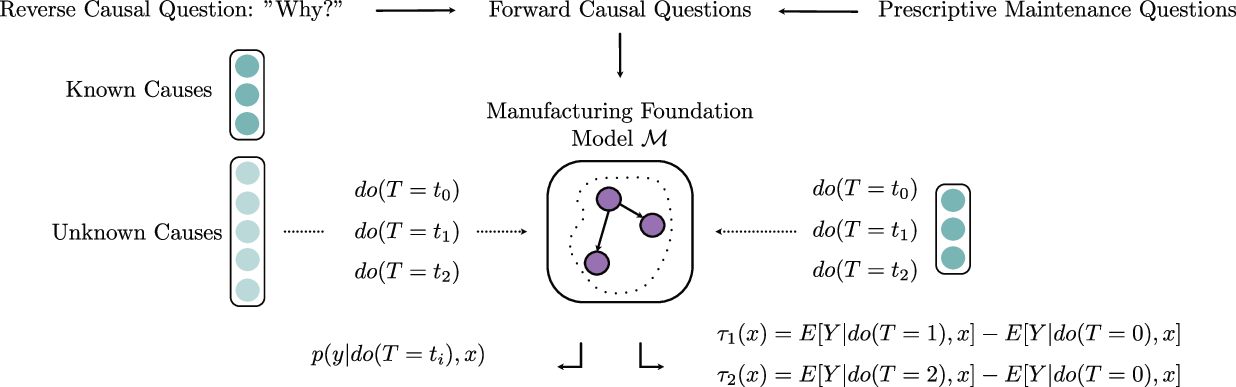
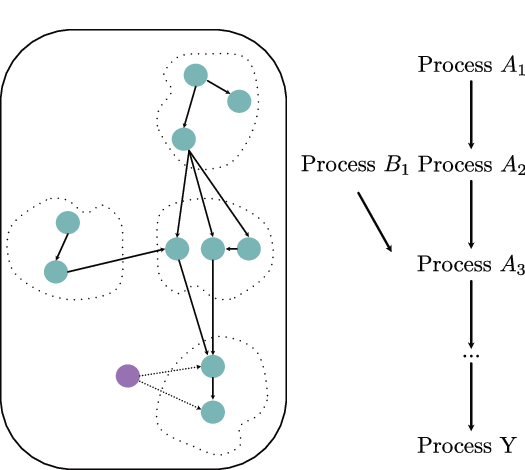
논문은 이를 해결하기 위해 인과 머신러닝, 특히 ‘인과 기반 대형 모델(causal foundation model)’을 활용한다는 점에서 혁신적이다. 사전 학습된 모델을 what‑if 시뮬레이터로 사용함으로써, 특정 변수(예: 부품 교체, 공정 파라미터 조정)의 인위적 변화를 가정하고 그 변화가 KPI에 미치는 인과 효과를 추정한다. 이 접근법은 전통적인 ‘잠재 변수(latent variable)’ 추정이나 ‘반사학습(counterfactual inference)’보다 더 직관적이며, 실제 운영 환경에 바로 적용 가능한 정책 제안을 가능하게 한다.
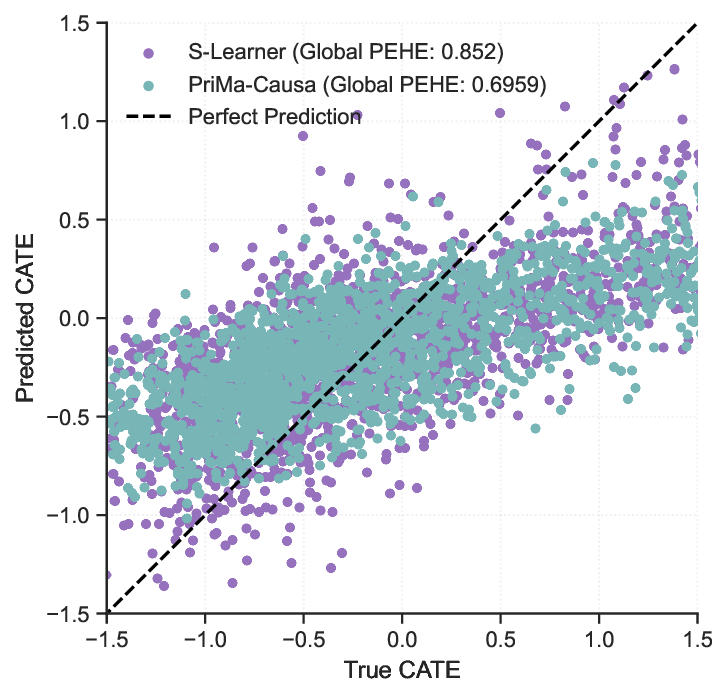
실험 설계는 반실제 데이터(실제 데이터에 인위적 개입을 삽입한 시뮬레이션)를 이용해 모델의 인과 추정 정확도를 검증한다. 베이스라인으로 사용된 전통적인 머신러닝 모델은 단순히 고장 확률을 예측하지만, 인과 모델은 개입 후 KPI 변화량을 직접 제공한다. 결과는 인과 모델이 동일한 예측 정확도를 유지하면서도 개입 효과를 정량화하는 데 있어 현저히 우수함을 보여준다.
하지만 몇 가지 한계도 존재한다. 첫째, 인과 대형 모델의 사전 학습 과정에서 사용된 데이터와 도메인이 제조 현장과 얼마나 일치하는가에 따라 전이 학습 성능이 크게 달라질 수 있다. 둘째, 반실제 데이터는 실제 고장 메커니즘을 완벽히 재현하지 못할 가능성이 있어, 실증 검증 단계에서 실제 설비에 대한 파일럿 테스트가 필요하다. 셋째, KPI로 OEE만을 사용한 점은 다변량 목표(예: 에너지 효율, 품질 결함률 등)를 동시에 고려해야 하는 복합 환경에서는 제한적일 수 있다.
향후 연구 방향으로는 (1) 도메인 특화 인과 사전 학습 모델 구축, (2) 다목표 최적화를 위한 다중 KPI 인과 추정, (3) 실시간 스트리밍 데이터와 연계한 온라인 what‑if 시뮬레이션 프레임워크 개발, (4) 인간‑AI 협업 인터페이스를 통해 엔지니어가 인과 결과를 직관적으로 이해하고 조정할 수 있는 시각화 도구 설계 등을 제안한다. 이러한 확장은 논문의 핵심 아이디어를 실제 스마트 팩토리 현장에 적용하는 데 필수적인 단계가 될 것이다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리