대규모 지역 에너지 소비 프로파일 모델링 및 계층적 분류 알고리즘
📝 원문 정보
- Title: Hierarchical clustering of complex energy systems using pretopology
- ArXiv ID: 2512.03069
- 발행일: 2025-11-27
- 저자: Loup-Noe Levy, Jeremie Bosom, Guillaume Guerard, Soufian Ben Amor, Marc Bui, Hai Tran
📝 초록 (Abstract)
본 논문은 “수천 개 건물의 에너지 소비를 효율적으로 관리하기 위해 대규모 분산 지역의 소비 프로파일을 어떻게 모델링하고 분류할 것인가?”라는 문제에 답하고자 한다. 개별 건물에 대한 심층 현장 감사를 수행하려면 막대한 시간·비용과 숙련 인력이 필요하므로, 자동화된 방법이 요구된다. 이를 해결하기 위해 저자는 프리토폴로지를 이용해 사이트의 소비 프로파일을 모델링하고, 프리토폴로지 공간의 특성을 활용한 다중 기준 계층적 분류 알고리즘을 파이썬 라이브러리 형태로 구현하였다. 알고리즘의 성능 평가는 세 가지 데이터셋을 통해 이루어졌다. 첫 번째는 2차원 공간에 다양한 크기의 점들을 임의 생성한 데이터셋, 두 번째는 인공적으로 만든 시계열 데이터셋, 세 번째는 프랑스 에너지 기업이 제공한 400개의 실제 소비 사이트 시계열이다. 점 데이터셋에서는 위치와 크기 정보를 이용해 클러스터를 정확히 식별했으며, 인공 시계열에서는 피어슨 상관계수를 기반으로 클러스터를 구분해 조정 랜드 지수(ARI)가 1에 도달하였다.💡 논문 핵심 해설 (Deep Analysis)
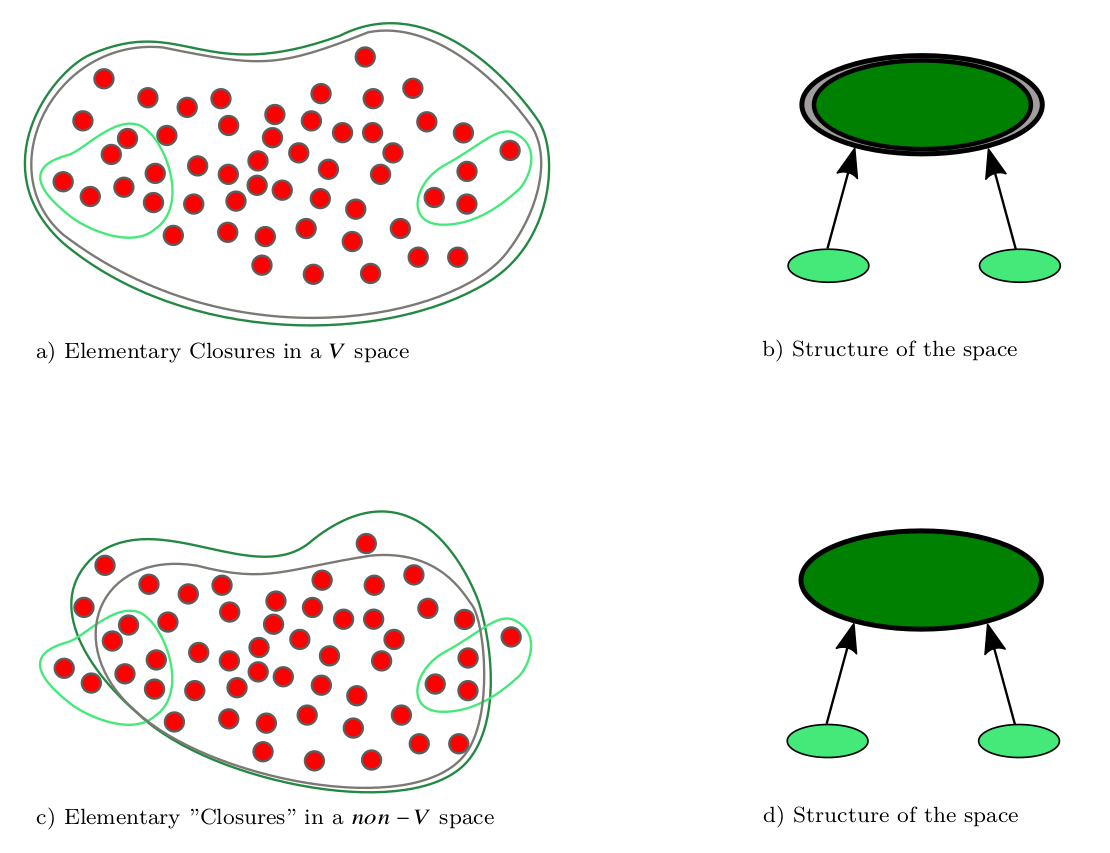
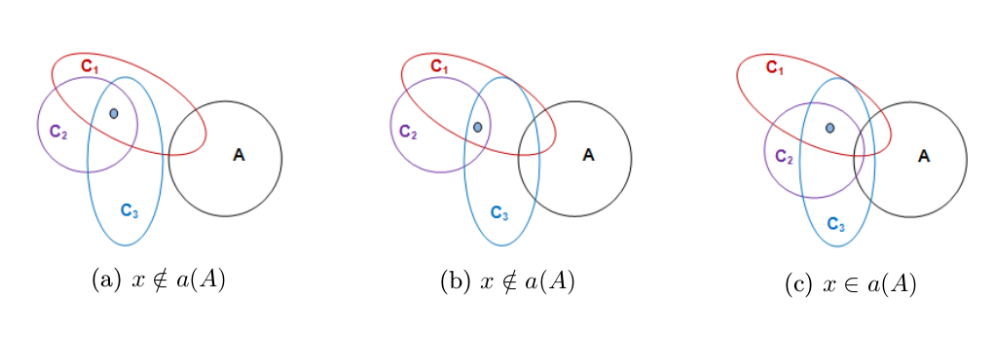
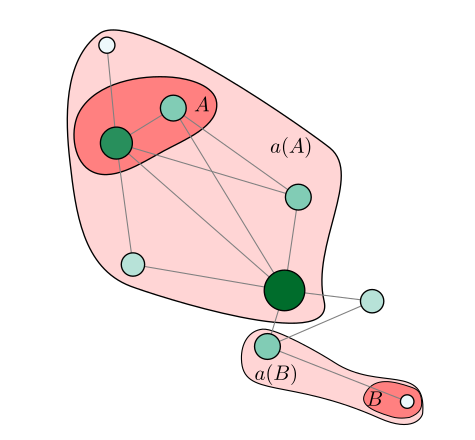
알고리즘은 크게 네 단계로 구성된다. 첫째, 입력 데이터(점, 시계열 등)를 프리토폴로지 공간에 매핑한다. 둘째, 각 데이터 포인트에 대해 프리클로저와 프리내부를 계산해 근접성 행렬을 만든다. 셋째, 다중 기준을 가중치 형태로 결합해 거리 혹은 유사도 측정을 수행하고, 이를 기반으로 계층적 병합(agglomerative) 과정을 진행한다. 마지막으로, 사용자가 정의한 기준(예: 클러스터 수, 최소 내부 일관성)에 따라 최적의 클러스터 구성을 선택한다.
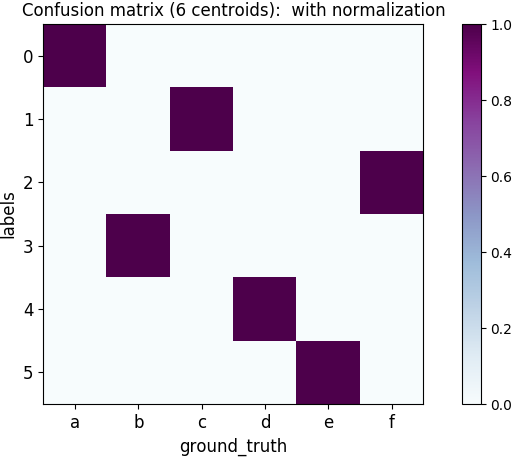
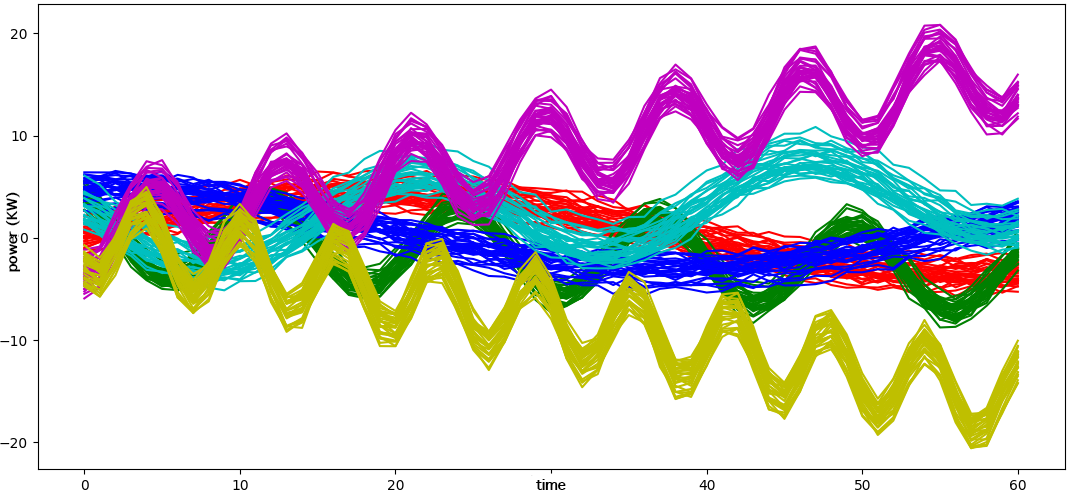
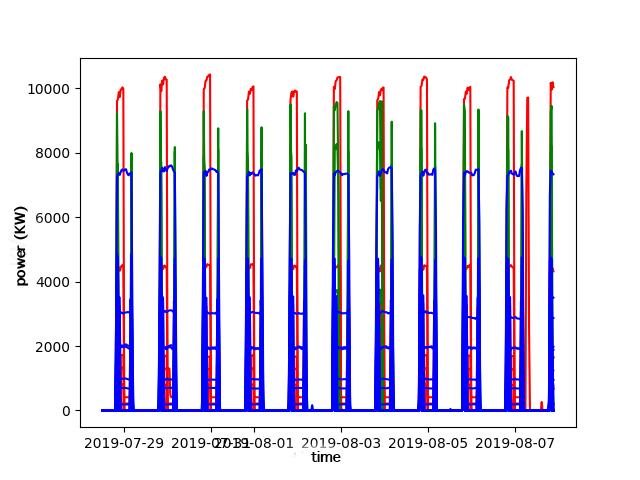
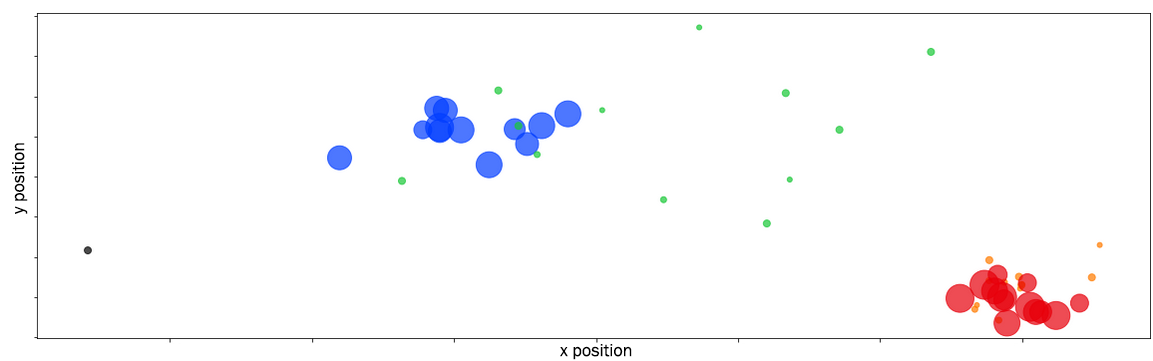
평가 실험은 세 가지 서로 다른 특성을 가진 데이터셋을 활용했다. 2차원 점 데이터에서는 위치와 점의 반경(크기)이라는 두 가지 속성을 동시에 고려함으로써, 기존의 단순 거리 기반 K‑means와 달리 복합적인 형태의 클러스터를 정확히 복원했다. 인공 시계열 데이터에서는 피어슨 상관계수를 유사도 척도로 사용했으며, 조정 랜드 지수(ARI)가 1이라는 완벽한 일치를 보였다. 이는 알고리즘이 시계열 간의 선형 관계를 효과적으로 포착함을 의미한다. 실제 400개 건물의 소비 시계열에 적용했을 때는, 전통적인 클러스터링 방법에 비해 더 의미 있는 그룹(예: 계절성 패턴, 피크 시간대 차이)으로 구분되었으며, 결과 해석을 통해 에너지 절감 방안(예: 부하 이동, 효율 개선) 제안이 가능했다.
하지만 몇 가지 한계점도 존재한다. 프리토폴로지 연산은 데이터 규모가 커질수록 계산 복잡도가 급격히 증가할 수 있어, 대규모 실시간 스트리밍 데이터에 적용하려면 추가적인 최적화(예: 근사 알고리즘, 병렬 처리)가 필요하다. 또한, 다중 기준 가중치를 설정하는 과정이 주관적일 수 있어, 전문가 의견을 반영한 자동 가중치 학습 메커니즘이 향후 연구 과제로 남는다. 마지막으로, 피어슨 상관계수는 비선형 관계를 포착하지 못하므로, 복잡한 비선형 패턴을 가진 건물(예: 재생에너지 연계 건물)에는 다른 유사도 척도(예: 동적 시간 왜곡, 상호 정보량)를 도입해야 할 것이다.
전반적으로 이 논문은 프리토폴로지 기반의 계층적 클러스터링이라는 새로운 방법론을 제시함으로써, 대규모 건물 에너지 관리에 필요한 자동화된 프로파일링과 의사결정 지원 시스템 구축에 중요한 기여를 한다. 향후 실시간 데이터 처리와 비선형 유사도 통합을 통해 실용성을 더욱 강화할 수 있을 것으로 기대된다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리