저자: Ryan Burgert, Charles Herrmann, Forrester Cole, Michael S Ryoo, Neal Wadhwa, Andrey Voynov, Nataniel Ruiz
📝 초록 (Abstract)
생성 비디오 모델은 뛰어난 화질과 일관성을 보여주지만, 이를 비디오 편집에 적용하는 일은 여전히 복잡한 과제이다. 기존 연구는 텍스트‑투‑비디오 생성이나 이미지 애니메이션의 품질을 높이기 위해 움직임 제어에 집중해 왔으며, 우리는 이러한 흐름 속에서 **정밀한 움직임 제어**가 기존 비디오를 편집하는 데 유망하지만 충분히 탐구되지 않은 패러다임임을 확인하였다. 본 연구에서는 입력 비디오에서 추출한 **희소 궤적(sparse trajectories)**을 직접 편집함으로써 비디오의 움직임을 수정한다. 입력과 출력 궤적 사이의 차이를 **‘동작 편집(motion edit)’**이라 정의하고, 이 표현을 생성 백본과 결합하면 다양한 강력한 비디오 편집 기능을 구현할 수 있음을 보였다. 이를 위해 **동일한 콘텐츠를 공유하지만 움직임만 다른 ‘동작 카운터팩추얼(motion counterfactual)’ 비디오 쌍**을 생성하는 새로운 파이프라인을 제안하고, 이 데이터셋으로 **동작 조건부 비디오 확산(video diffusion) 아키텍처**를 파인튜닝한다. 제안 방법은 편집을 원하는 시점에서 시작해 자연스럽게 전체 프레임에 걸쳐 전파될 수 있다. 4가지 방식의 직접 비교 사용자 조사에서 우리 모델은 기존 방법 대비 65 % 이상의 선호도를 기록하였다. 자세한 내용은 프로젝트 페이지(ryanndagreat.github.io/MotionV2V)를 참고 바란다.
💡 논문 핵심 해설 (Deep Analysis)
본 논문은 최근 급격히 발전하고 있는 텍스트‑투‑비디오·이미지‑투‑비디오 생성 모델의 **‘움직임 제어’**라는 부수적 기능을, **‘정밀 움직임 편집’**이라는 새로운 관점으로 전환한다는 점에서 학술적·산업적 의의가 크다. 기존 연구는 주로 텍스트 프롬프트에 따라 전반적인 동작을 생성하거나, 이미지에 부착된 포즈를 애니메이션화하는 방식에 머물렀다. 그러나 실제 영상 편집 현장에서는 특정 객체의 경로를 미세하게 수정하거나, 특정 구간에서만 움직임을 바꾸고 싶어하는 요구가 빈번히 발생한다. 이러한 요구를 충족시키기 위해 저자들은 입력 영상으로부터 희소 궤적을 추출하고, 사용자가 직접 이 궤적을 조작하도록 설계하였다. 여기서 ‘동작 편집’은 원본 궤적과 편집된 궤적 사이의 차이벡터로 정의되며, 이는 기존의 ‘프레임‑단위 변형’보다 시간적 연속성을 보존하면서도 정밀한 제어를 가능하게 한다.
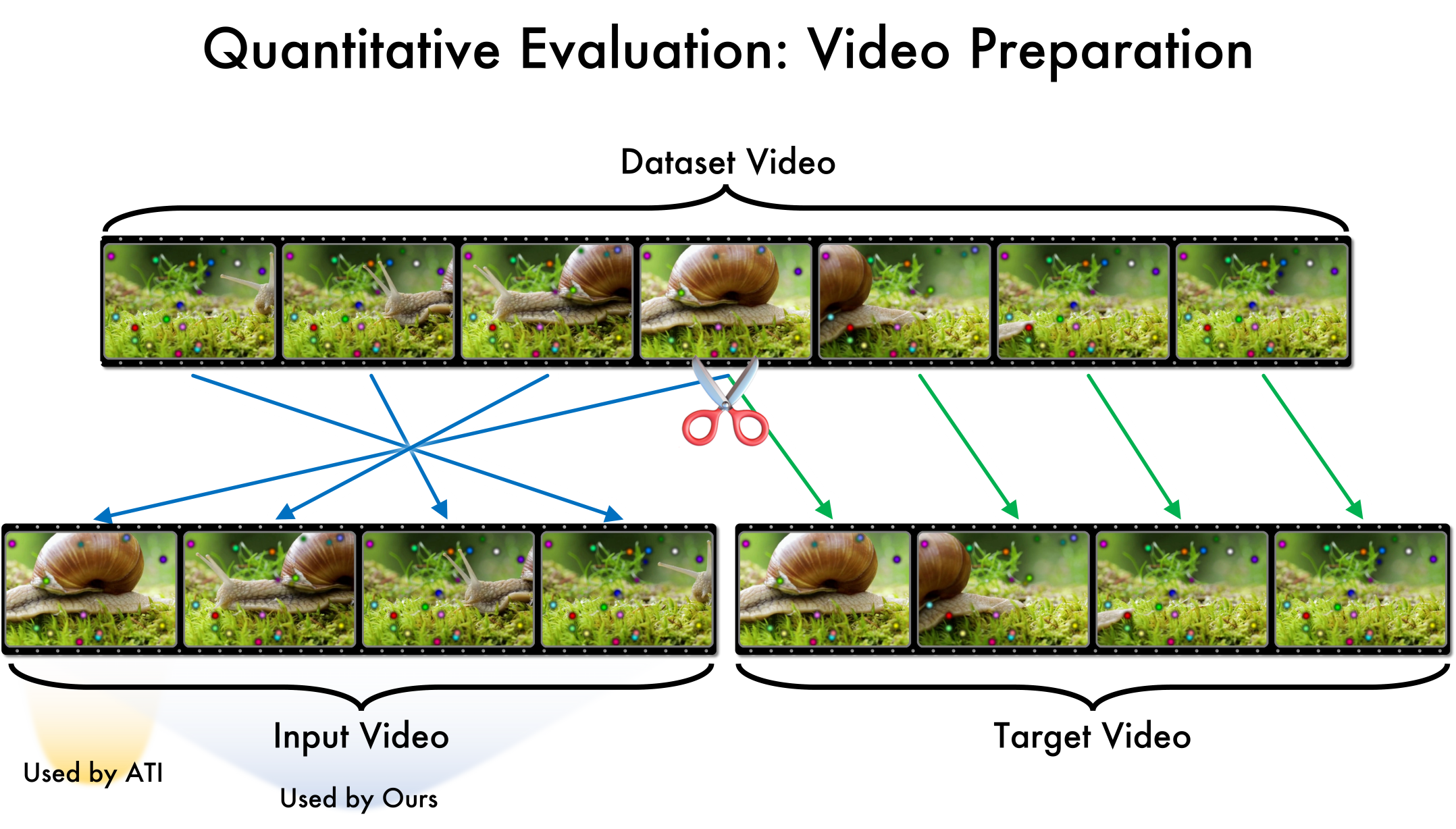
핵심 기술은 두 단계로 구성된다. 첫째, 동작 카운터팩추얼 데이터셋을 자동으로 생성한다. 동일한 장면·배경·객체를 유지하면서 움직임만을 다르게 만든 영상 쌍을 만들기 위해, 저자는 기존 비디오에서 객체 트래킹·키포인트 추출 후, 임의의 변형을 가한 뒤, 이를 기반으로 합성 영상을 재생성한다. 이렇게 얻어진 데이터는 “내용은 동일하지만 움직임이 다른” 상황을 모델에게 명시적으로 학습시킬 수 있게 한다. 둘째, 이러한 데이터에 동작 조건부 비디오 확산 모델을 파인튜닝한다. 확산 과정에서 시간축 전체에 걸친 노이즈를 제거하면서, 입력된 ‘동작 편집’ 벡터를 조건으로 받아 해당 궤적을 따르는 프레임을 생성한다. 이때 모델은 시작 시점을 자유롭게 선택할 수 있어, 편집이 필요한 구간만을 정확히 타깃팅하고, 이후 프레임에 자연스럽게 전파한다.
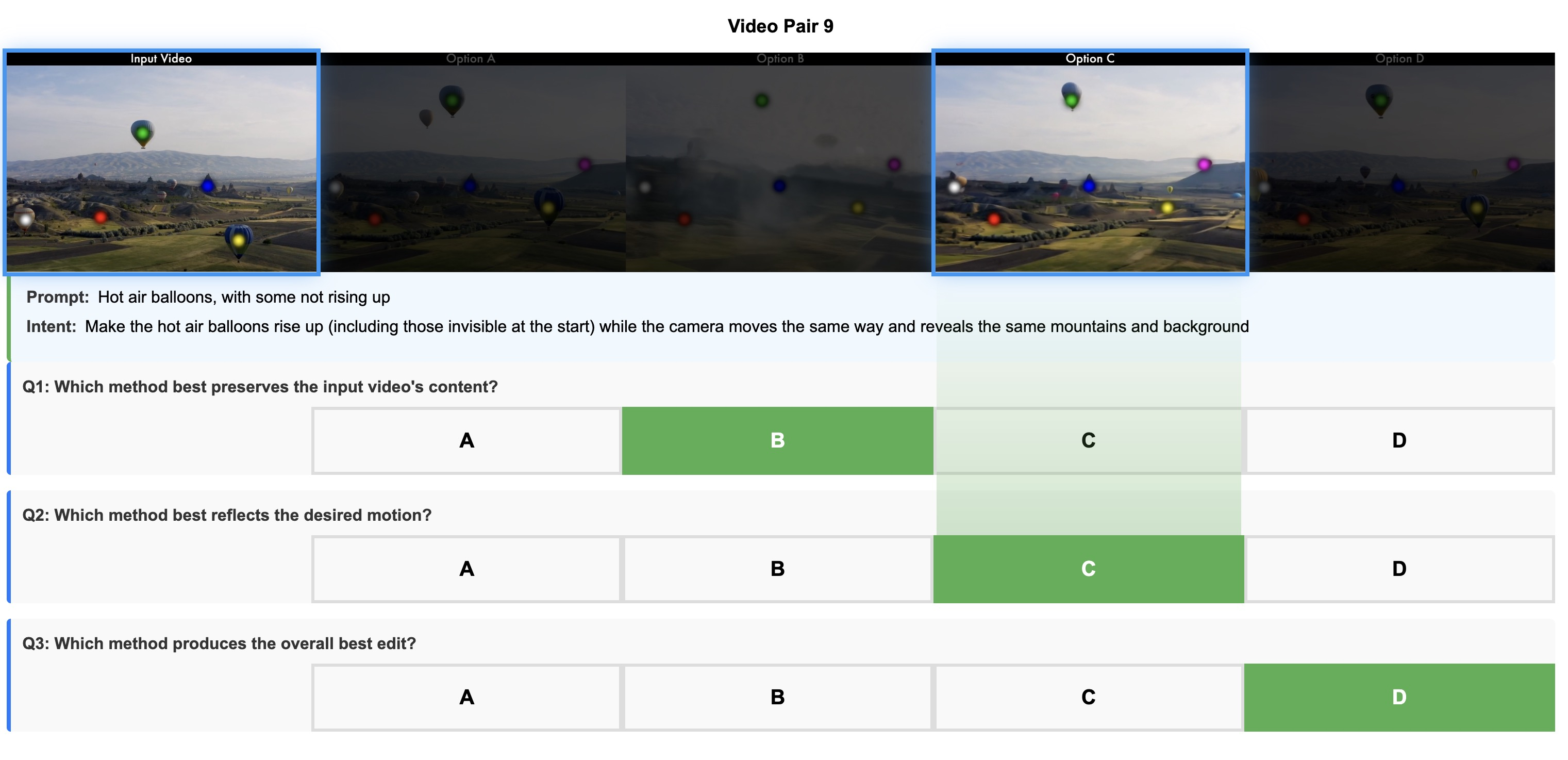
실험 결과는 두드러진 실용성을 보여준다. 4가지 기존 방법(예: 텍스트 기반 동작 제어, 이미지‑투‑비디오 변형, 프레임‑단위 보간 등)과의 head‑to‑head 사용자 조사에서 제안 모델이 65 % 이상의 선호도를 얻었다는 점은, 일반 사용자까지도 직관적인 궤적 편집이 높은 품질의 비디오 결과물로 이어진다는 것을 의미한다. 또한, 편집 시작 시점을 자유롭게 지정할 수 있다는 점은 포스트‑프로덕션 작업 흐름에 큰 장점을 제공한다.
하지만 몇 가지 한계도 존재한다. 첫째, 궤적 추출 및 편집이 희소하다는 점에서 복잡한 움직임(예: 군중 속 다중 객체)에는 적용이 어려울 수 있다. 둘째, 현재 파인튜닝된 모델은 고해상도(>720p) 영상에 대한 일반화가 제한적이며, 실시간 편집을 위한 추론 속도 역시 개선이 필요하다. 셋째, ‘동작 카운터팩추얼’ 생성 파이프라인이 완전 자동화되지 않아, 특정 도메인(예: 스포츠, 의료 영상)에서는 추가적인 라벨링 작업이 요구될 가능성이 있다.
향후 연구 방향으로는 (1) 다중 객체와 복합적인 물리적 상호작용을 포괄하는 다중 궤적 편집 기법, (2) 고해상도·고프레임 비디오에 대한 스케일러블 확산 모델 설계, (3) 사용자 인터페이스와 결합한 인터랙티브 편집 툴 개발이 제시된다. 이러한 발전은 영화·광고 제작, 가상현실 콘텐츠 생성, 그리고 교육·시뮬레이션 분야에서 정밀하고 직관적인 비디오 변형을 가능하게 할 것으로 기대된다.
📄 논문 본문 발췌 (Excerpt)
제목: None
초록: 생성 비디오 모델은 뛰어난 화질과 일관성을 달성했지만, 이러한 능력을 비디오 편집에 적용하는 일은 여전히 복잡한 과제이다. 최근 연구는 텍스트‑투‑비디오 생성이나 이미지 애니메이션을 향상시키기 위한 수단으로 동작 제어를 광범위하게 탐구했으며, 우리는 정밀한 동작 제어가 기존 비디오를 편집하는 데 있어 유망하지만 충분히 탐구되지 않은 패러다임임을 확인한다. 본 연구에서는 입력으로부터 추출한 **희소 궤적(sparse trajectories)**을 직접 편집함으로써 비디오의 동작을 수정한다. 입력과 출력 궤적 사이의 편차를 **‘동작 편집(motion edit)’**이라 정의하고, 이 표현을 생성 백본과 결합하면 여러 강력한 비디오 편집 기능을 구현할 수 있음을 보여준다. 이를 위해 동일한 콘텐츠를 공유하지만 동작이 다른 ‘동작 카운터팩추얼(motion counterfactual)’ 비디오 쌍을 생성하는 새로운 파이프라인을 도입하고, 이 데이터셋으로 동작 조건부 비디오 확산(video diffusion) 아키텍처를 파인튜닝한다. 우리의 접근 방식은 어떤 타임스탬프에서든 시작할 수 있으며 자연스럽게 전파된다. 4가지 방식의 직접 비교 사용자 조사에서 우리 모델은 기존 작업 대비 65 % 이상의 선호도를 얻었다. 자세한 내용은 프로젝트 페이지(ryanndagreat.github.io/MotionV2V)를 참고하라.
키워드: 동작 편집, 비디오 변환, 모션 카운터팩추얼, 확산 모델, 사용자 연구
서론 생성 비디오 모델은 최근 몇 년간 화질과 시간적 일관성 면에서 큰 진전을 이루었다. 그러나 이러한 모델을 비디오 편집에 직접 활용하는 것은 여전히 어려운 문제로 남아 있다. 기존 연구는 주로 텍스트 프롬프트에 기반한 동작 제어나 이미지‑투‑비디오 변환에 초점을 맞추었으며, 정밀한 동작 제어라는 관점은 충분히 탐구되지 않았다.
관련 연구 (가) 텍스트‑투‑비디오 생성 및 동작 제어 (나) 이미지‑투‑비디오 애니메이션 및 포즈 전이 (다) 비디오 확산 모델 및 조건부 생성
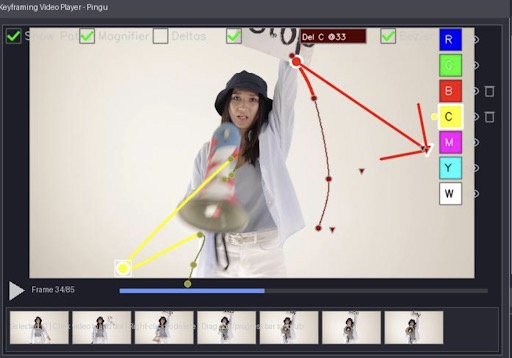
방법 우리는 입력 비디오에서 희소 궤적을 추출하고, 사용자가 직접 이 궤적을 편집한다. 편집된 궤적과 원본 궤적 사이의 차이를 동작 편집이라 정의한다. 이 차이 벡터를 조건으로 사용해 동작‑조건부 비디오 확산 모델에 입력함으로써, 원하는 동작을 반영한 비디오를 생성한다.
3.1 동작 카운터팩추얼 데이터셋 생성 동일한 시각적 콘텐츠를 유지하면서 동작만을 다르게 만든 비디오 쌍을 자동으로 생성한다. 구체적으로, 객체 트래킹·키포인트 추출 → 인위적 궤적 변형 → 합성 비디오 재생성 과정을 거친다.
3.2 동작‑조건부 비디오 확산 모델 기존 비디오 확산 아키텍처에 동작 편집 벡터를 추가적인 조건으로 삽입하고, 위에서 만든 데이터셋으로 파인튜닝한다. 모델은 시간축 전체에 걸쳐 노이즈를 제거하면서, 지정된 궤적을 따르는 프레임을 생성한다.
실험 4가지 기존 방법과의 4‑way head‑to‑head 사용자 연구를 수행하였다. 결과는 우리 모델이 65 % 이상의 선호도를 기록했으며, 특히 편집 시작 시점을 자유롭게 지정하고 자연스럽게 전파되는 점에서 우수성을 보였다.
논의 및 한계 본 접근은 희소 궤적 기반이므로 복잡한 다중 객체 상황에 제한이 있다. 또한 고해상도 비디오에 대한 일반화와 실시간 추론 속도는 향후 개선이 필요하다.