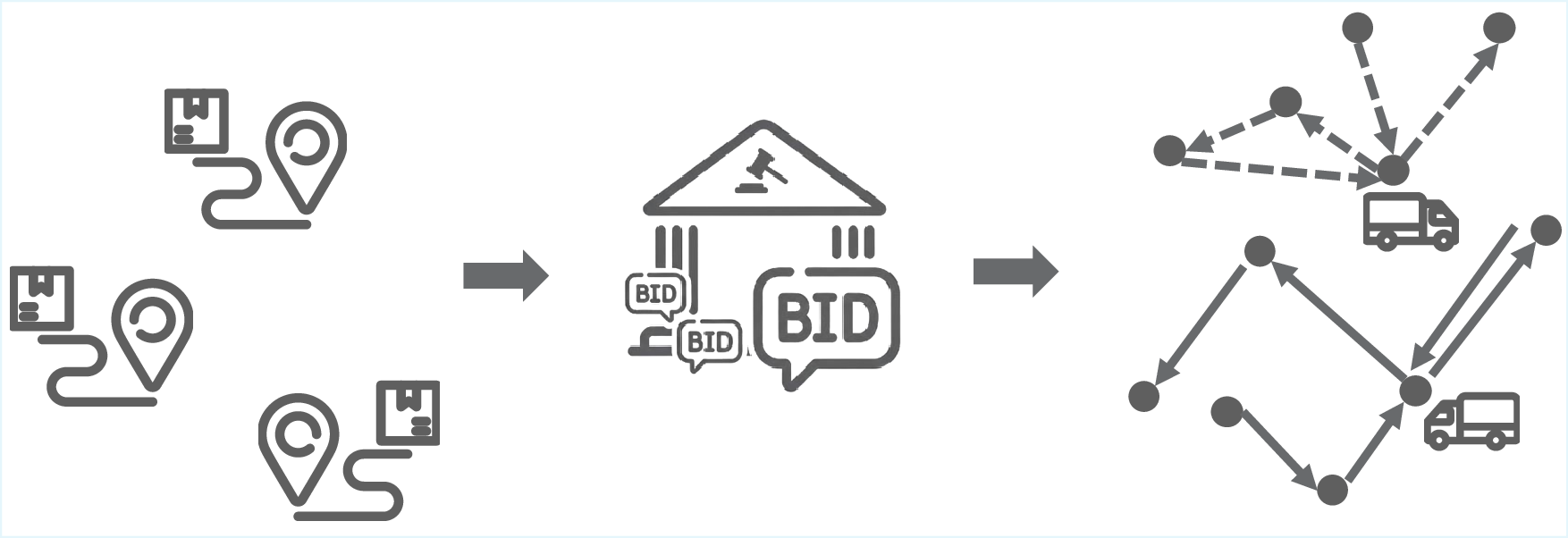
실제 물류 최적화 문제 기반 다중 에이전트 LLM 벤치마크
📝 원문 정보
- Title: Can Vibe Coding Beat Graduate CS Students? An LLM vs. Human Coding Tournament on Market-driven Strategic Planning
- ArXiv ID: 2511.20613
- 발행일: 2025-11-25
- 저자: Panayiotis Danassis, Naman Goel
📝 초록 (Abstract)
대형 언어 모델(LLM)의 급속한 확산은 AI 기반 코드 생성에 혁신을 가져왔지만, 벤치마크 구축은 이를 따라가지 못하고 있다. 기존 벤치마크는 주로 단위 테스트 통과율과 구문적 정확성에 초점을 맞추어 실제 현장에서 요구되는 계획, 최적화, 전략적 상호작용과 같은 복잡성을 충분히 반영하지 못한다. 본 연구는 경쟁 입찰과 용량 제한 라우팅을 결합한 실제 물류 최적화 문제인 Auction‑Pickup‑Delivery Problem(APDP)을 기반으로 다중 에이전트 추론 중심 벤치마크를 제안한다. 이 벤치마크는 (i) 불확실성 하에서 전략적으로 입찰하는 에이전트와 (ii) 이익을 극대화하면서 작업을 수행하는 최적화 플래너를 구축하도록 요구한다. 우리는 다양한 최신 LLM과 여러 프롬프트 기법(예: vibe coding)을 활용해 40개의 LLM‑코드 에이전트를 개발하고, LLM 등장 이전에 인간(대학원생)들이 만든 17개의 인간‑코드 에이전트와 비교하였다. 12개의 이중 전 경기 토너먼트와 약 4만 경기 결과, (i) 인간‑코드 에이전트가 일관적으로 상위 5위를 차지하며 명확히 우수함을 확인했으며, (ii) 40개 LLM‑코드 에이전트 중 33개는 매우 단순한 베이스라인에 의해 쉽게 제압되었고, (iii) 최고의 인간 솔루션을 입력으로 제공하고 개선을 요청했을 때, 최상위 LLM은 오히려 성능을 저하시켰다. 이 결과는 LLM이 실제 경쟁력 있는 코드를 생성하는 능력에 한계가 있음을 보여주며, 실제 시나리오에서 추론 중심 코드 합성을 강조하는 새로운 평가 방법의 필요성을 제시한다.💡 논문 핵심 해설 (Deep Analysis)
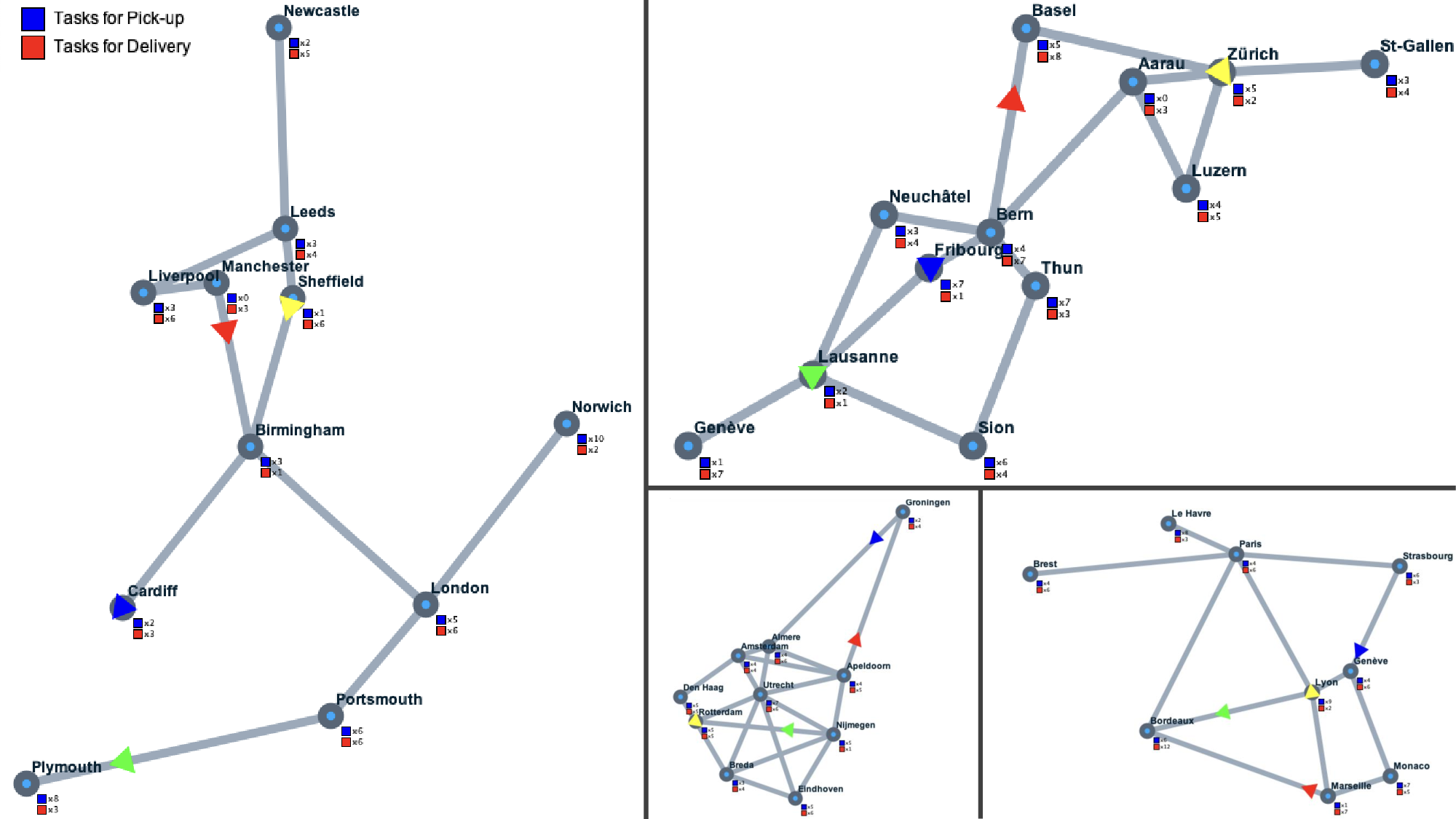
실험 설계는 매우 포괄적이다. 연구팀은 최신 GPT‑4, Claude, Llama 2 등 10여 종의 LLM을 활용해 40개의 코드 에이전트를 생성했으며, 프롬프트 엔지니어링, 체인‑오브‑씽크, vibe coding 등 다양한 방법론을 적용했다. 이와 대조적으로, 인간 참가자는 물류 최적화와 게임 이론에 익숙한 대학원생 17명을 모집해 직접 코드를 작성하도록 했다. 모든 에이전트는 12개의 이중 전(all‑play‑all) 토너먼트와 약 4만 번의 매치를 통해 성능을 평가받았다. 결과는 인간 코딩이 여전히 우위를 점한다는 점을 명확히 보여준다. 특히, 상위 5위는 모두 인간이 만든 에이전트였으며, LLM 에이전트 중 33개는 단순한 무작위 입찰 혹은 그리디 라우팅 베이스라인에 의해 쉽게 제압되었다. 더 놀라운 점은 최고의 인간 솔루션을 LLM에 입력하고 “개선해라”는 프롬프트를 주었을 때, 최상위 LLM조차도 성능을 악화시켰다는 것이다. 이는 LLM이 기존 코드를 이해하고 체계적으로 개선하는 능력이 아직 미흡함을 시사한다.
이 논문의 의의는 두 가지 측면에서 강조된다. 첫째, 실제 비즈니스 문제를 그대로 모델링한 벤치마크를 제시함으로써, 코드 생성 연구가 단순 문법·테스트 통과를 넘어 전략적·최적화 능력을 평가하도록 촉구한다. 둘째, 인간‑코드와 LLM‑코드의 격차를 정량적으로 보여줌으로써, 현재 LLM이 “코드 자동화” 단계에 머물러 있음을 밝힌다. 향후 연구는 (1) LLM이 복합 최적화 문제를 풀기 위한 내부 추론 과정을 명시적으로 모델링하도록 프롬프트를 설계하고, (2) 인간‑LLM 협업 하이브리드 시스템을 구축해 인간의 도메인 지식과 LLM의 대규모 패턴 학습을 결합하는 방향으로 나아가야 할 것이다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리