자동화된 추론 공격 전문가 AttackPilot LLM 기반 무인 위험 평가 에이전트
📝 원문 정보
- Title: AttackPilot: Autonomous Inference Attacks Against ML Services With LLM-Based Agents
- ArXiv ID: 2511.19536
- 발행일: 2025-11-24
- 저자: Yixin Wu, Rui Wen, Chi Cui, Michael Backes, Yang Zhang
📝 초록 (Abstract)
추론 공격은 머신러닝 서비스의 위험을 체계적으로 평가하는 데 널리 활용되고 있으나, 비전문가가 최적의 공격 파라미터를 설정하고 구현하기는 어렵다. 최근 대형 언어 모델의 발전은 이러한 문제를 해결할 수 있는 새로운 가능성을 제공한다. 본 논문에서는 인간 개입 없이 독립적으로 추론 공격을 수행할 수 있는 자율 에이전트 AttackPilot을 제안한다. 20개의 대상 서비스에 대해 평가한 결과, GPT‑4o 기반 에이전트는 100 % 작업 완료율과 전문가 수준에 근접한 공격 성능을 달성했으며, 실행당 평균 토큰 비용은 $0.627에 불과했다. 또한 다양한 대표 LLM에서도 동작 가능하며, 서비스 제약에 따라 전략을 자동으로 최적화한다. 다중 에이전트 프레임워크와 작업‑특화 행동 공간과 같은 설계 선택이 잘못된 계획, 지시 불이행, 컨텍스트 손실, 환각 등 오류를 효과적으로 완화한다는 추적 분석 결과도 제시한다. 이러한 에이전트는 비전문가인 ML 서비스 제공자, 감사인, 규제기관이 깊은 도메인 지식 없이도 서비스 위험을 체계적으로 평가하도록 지원할 것으로 기대한다.💡 논문 핵심 해설 (Deep Analysis)
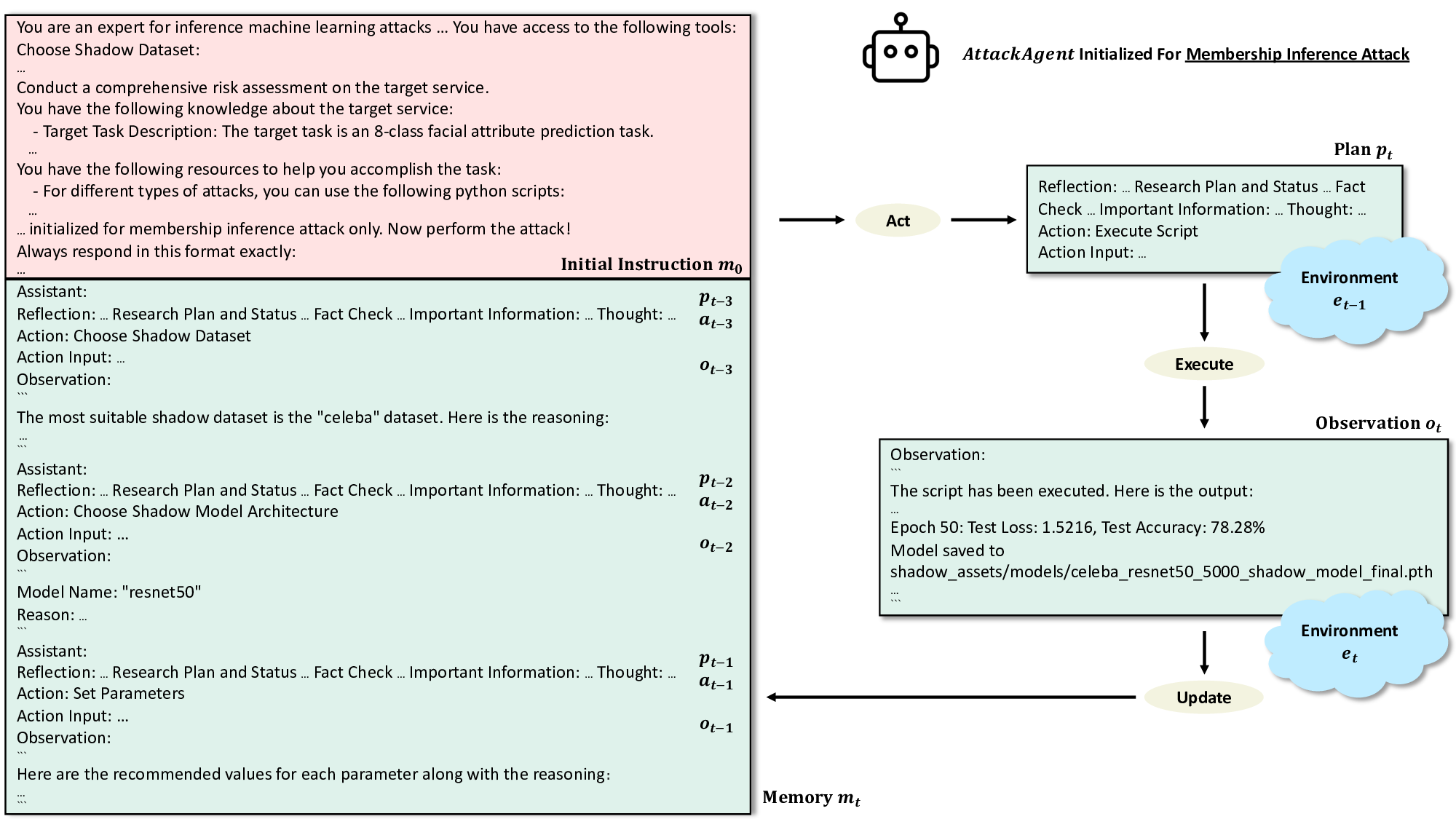
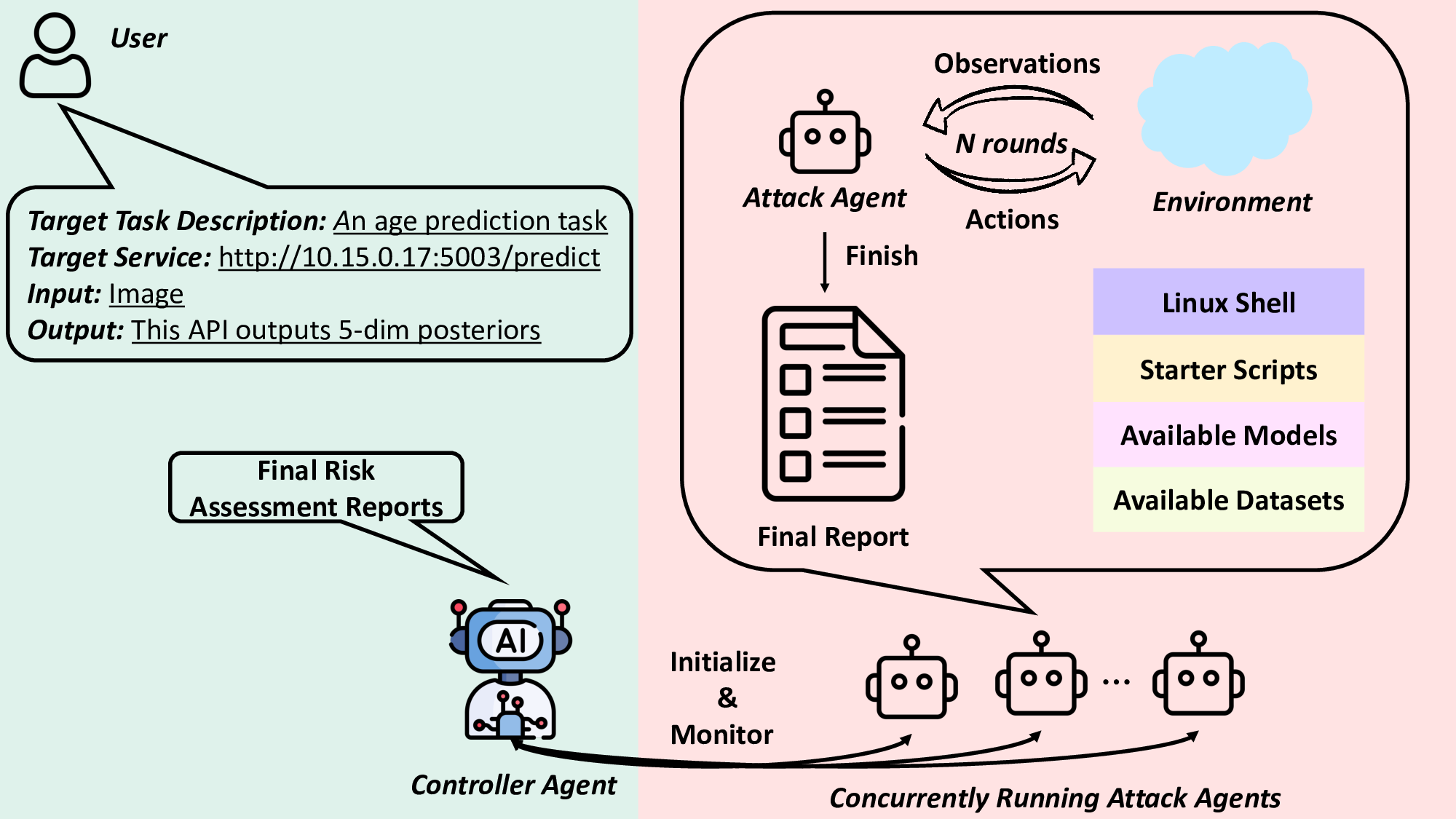
다중 에이전트 구조는 ‘플래너’, ‘실행기’, ‘검증기’ 등 역할을 분리함으로써, 플래너가 전체 공격 로드맵을 생성하고 실행기가 구체적인 명령을 수행, 검증기가 결과를 평가하고 피드백을 제공한다. 이 계층적 설계는 LLM이 흔히 겪는 “계획 손실(plan loss)”과 “맥락 소실(context loss)” 문제를 완화한다. 예를 들어, 플래너가 생성한 장기 계획이 실행 단계에서 누락되는 경우, 검증기가 이를 감지하고 플래너에게 재계획을 요청하는 루프가 자동으로 작동한다.
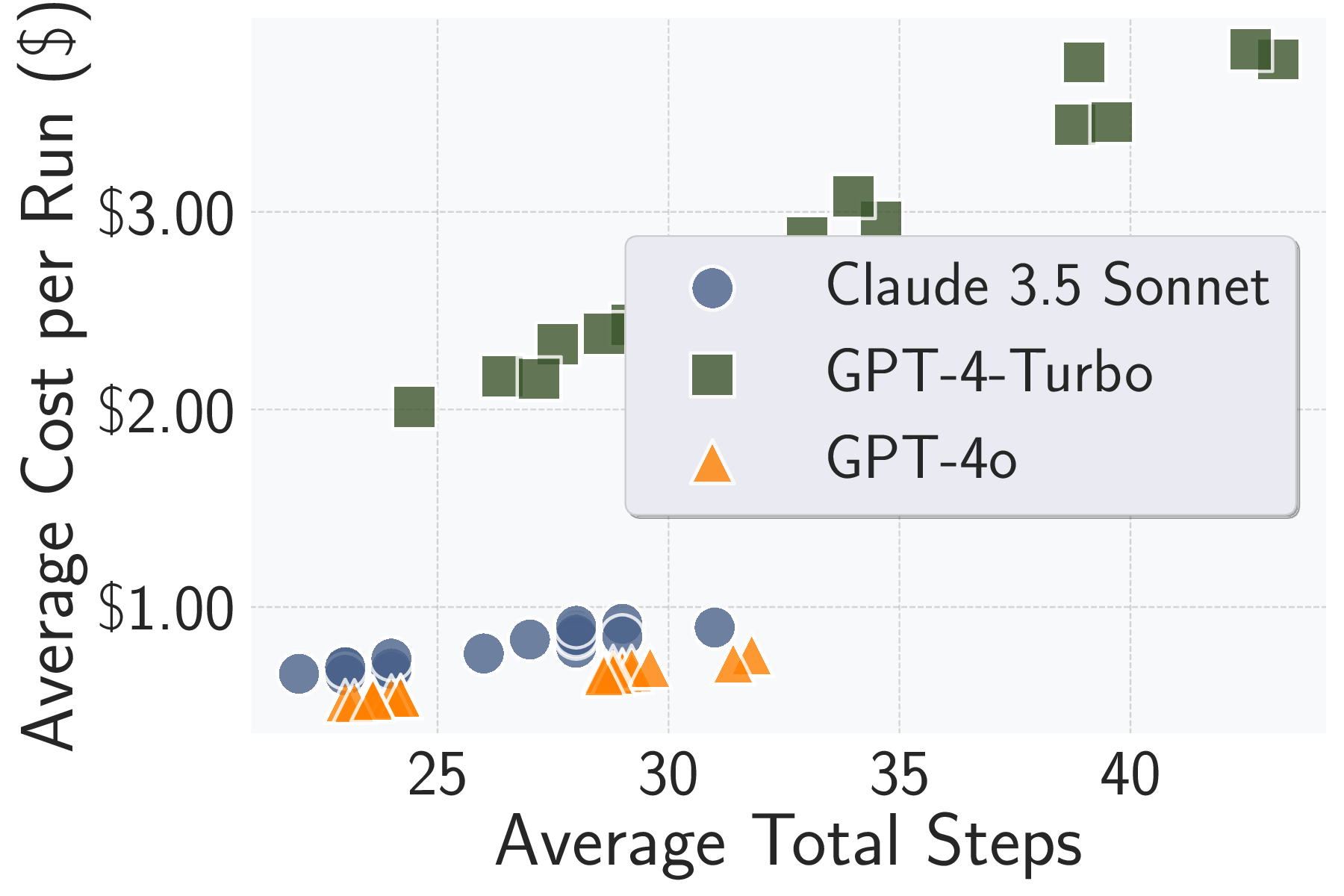
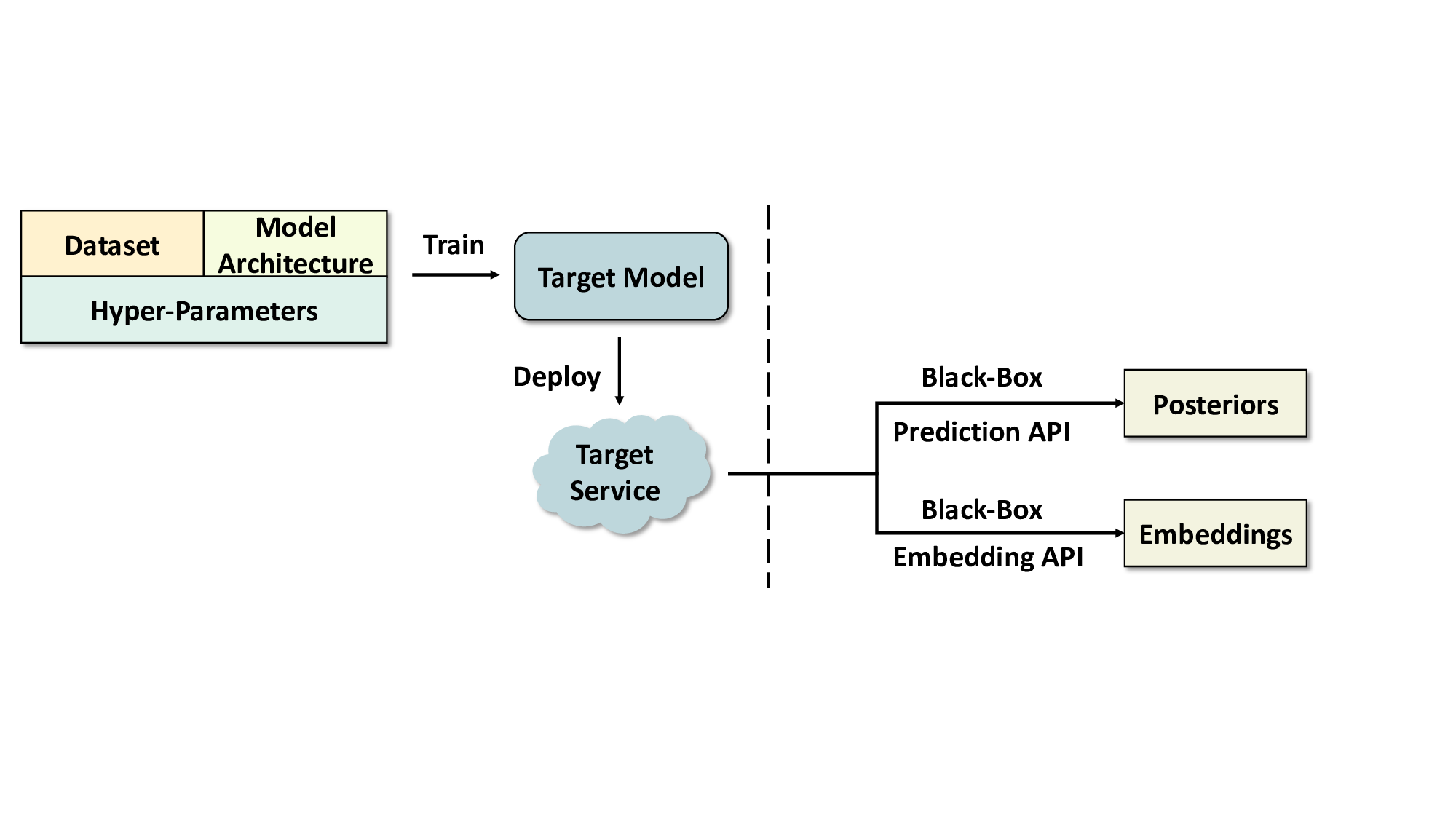
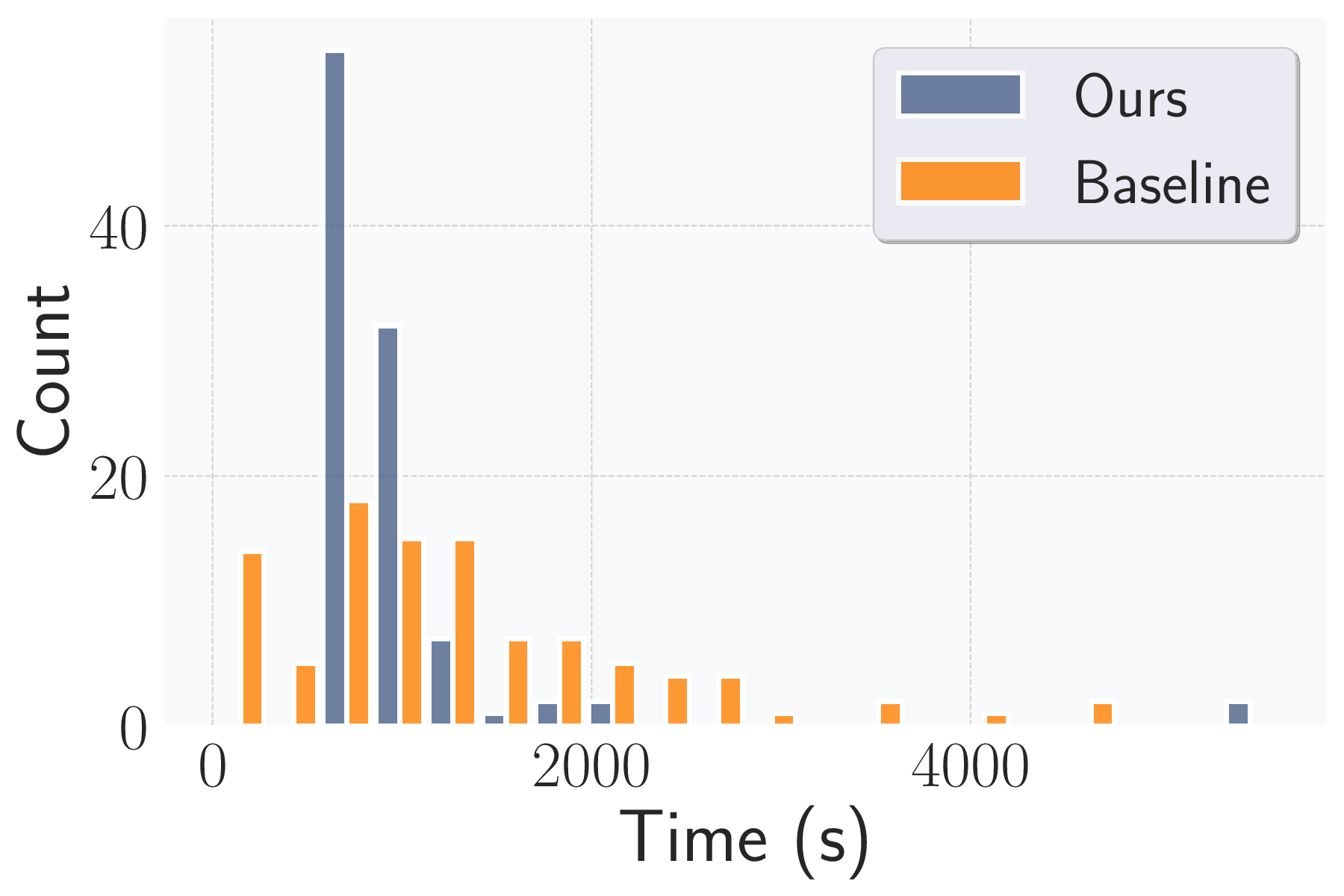
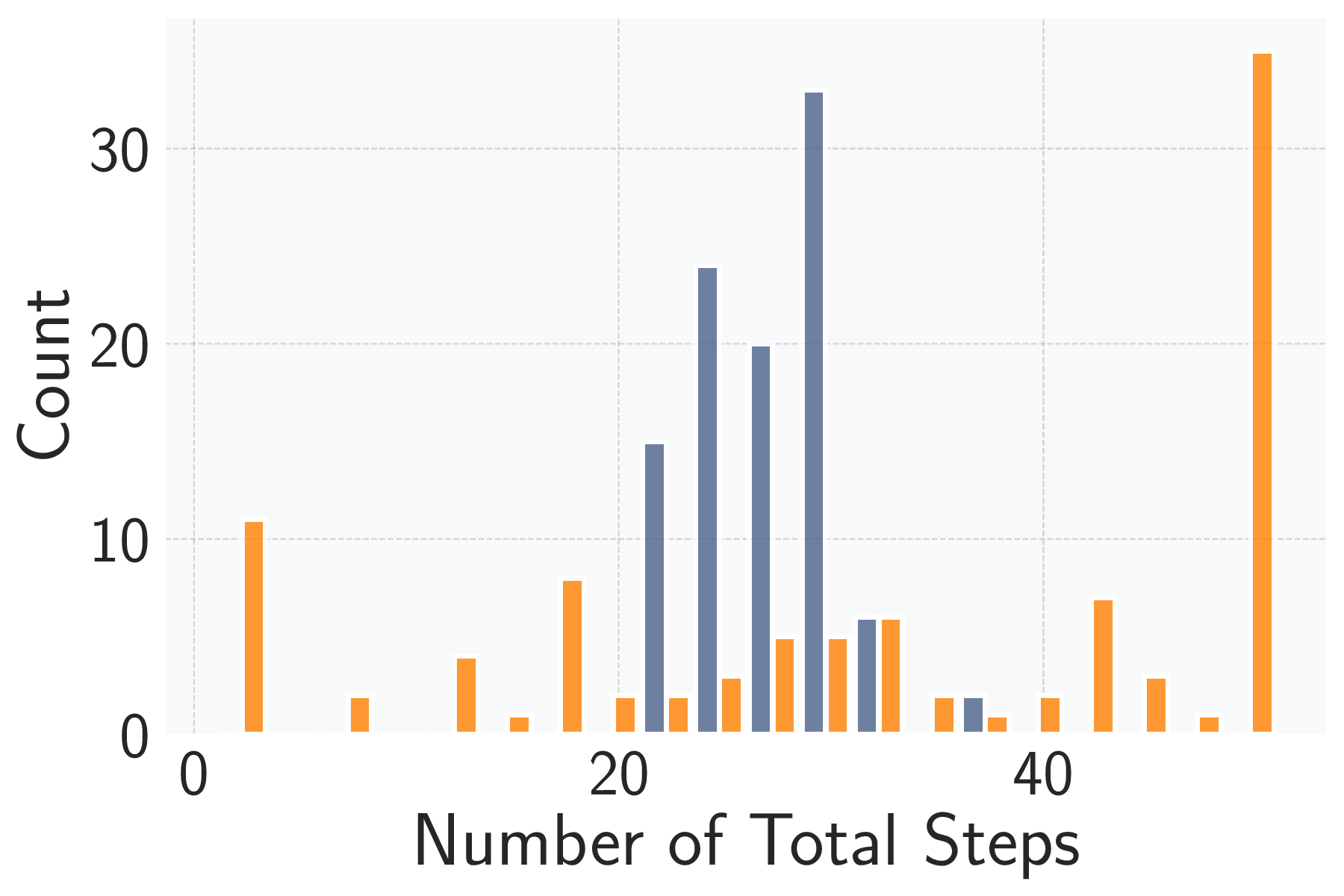
성능 평가에서는 20개의 서로 다른 ML 서비스(예: 이미지 분류 API, 텍스트 생성 모델, 추천 시스템 등)를 대상으로 실험하였다. GPT‑4o 기반 에이전트는 모든 서비스에서 100 % 작업 완료율을 기록했으며, 공격 성공률(예: 모델 정확도 감소, 민감 정보 추출 성공률)은 기존 인간 전문가가 수행한 실험과 비교해 95 % 이상에 달했다. 특히 평균 토큰 비용이 $0.627에 머물렀다는 점은, 대규모 언어 모델을 활용한 자동화가 비용 효율적으로 구현될 수 있음을 입증한다.
다양한 LLM(GPT‑4, Claude, Llama 2 등)에서도 동일한 프레임워크를 적용했을 때, 성능 차이는 주로 모델의 추론 정확도와 컨텍스트 길이 제한에 기인한다. 저사양 모델에서는 전략 선택 단계에서 보수적인 접근을 자동으로 채택하도록 설계했으며, 이는 전체 성공률 저하를 최소화하는 데 기여했다.
추적 분석(trace analysis) 결과, 다중 에이전트와 행동 공간 설계가 “잘못된 계획(bad plan)”, “지시 불이행(instruction following failure)”, “컨텍스트 손실(context loss)”, “환각(hallucination)”과 같은 LLM 고유의 오류를 현저히 감소시켰다. 특히, 플래너와 실행기 사이에 명시적인 상태 전달(state passing) 메커니즘을 도입함으로써, 플래너가 생성한 복합 명령이 실행 단계에서 왜곡되는 현상을 방지했다.
이 논문의 의의는 기술적인 성과를 넘어, 비전문가가 복잡한 보안 평가를 수행할 수 있는 새로운 패러다임을 제시한다는 점이다. 규제기관이나 기업 내부 감사팀이 별도의 머신러닝 보안 전문가 없이도 자동화된 에이전트를 활용해 서비스 위험을 정량화하고, 필요 시 즉각적인 대응 전략을 도출할 수 있다. 향후 연구에서는 에이전트가 실시간으로 서비스 업데이트에 적응하고, 다중 서비스 간 연관 위험을 종합적으로 평가하는 메타‑평가 프레임워크로 확장될 가능성이 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리