다중모달 강화학습을 위한 가변 난이도 기반 동적 샘플링 프레임워크 VADE
📝 원문 정보
- Title: VADE: Variance-Aware Dynamic Sampling via Online Sample-Level Difficulty Estimation for Multimodal RL
- ArXiv ID: 2511.18902
- 발행일: 2025-11-24
- 저자: Zengjie Hu, Jiantao Qiu, Tianyi Bai, Haojin Yang, Binhang Yuan, Qi Jing, Conghui He, Wentao Zhang
📝 초록 (Abstract)
그룹 기반 정책 최적화 기법인 GRPO와 GSPO는 그룹별 롤아웃과 상대 이점 추정을 활용해 다중모달 모델 학습의 표준이 되고 있다. 그러나 동일한 보상을 받은 그룹 내 모든 응답이 동일할 경우 이점 추정이 붕괴되어 그래디언트가 사라지는 심각한 문제에 직면한다. 기존 완화 방안은 필터링 기반과 샘플링 기반 두 가지 패러다임으로 나뉜다. 필터링 기반 방법은 롤아웃을 넓게 생성한 뒤 비정보성 그룹을 사후에 걸러내어 큰 계산 비용을 초래하고, 샘플링 기반 방법은 사전 기준이나 정적 기준에 의존해 사전 데이터 지식 없이 실시간 적응성이 부족하다. 이를 해결하고자 우리는 VADE(Variance‑Aware Dynamic sampling framework via online sample‑level difficulty Estimation)를 제안한다. VADE는 (1) 베타 분포를 이용한 온라인 샘플 수준 난이도 추정, (2) 추정된 정답 확률을 활용해 정보 이득을 최대화하는 톰슨 샘플러, (3) 정책 변화에 강인한 추정을 유지하기 위한 두 단계 사전 감소 메커니즘이라는 세 가지 핵심 요소를 통합한다. 이 설계는 가장 정보량이 높은 샘플을 동적으로 선택해 학습 신호를 증폭시키고 추가 롤아웃 비용을 없앤다. 다중모달 추론 벤치마크에서 광범위한 실험을 수행한 결과, VADE는 성능과 샘플 효율성 모두에서 강력한 베이스라인을 지속적으로 능가했으며 계산 오버헤드를 크게 감소시켰다. 더 나아가 본 프레임워크는 기존 그룹 기반 강화학습 알고리즘에 플러그‑인 형태로 손쉽게 통합될 수 있다. 코드와 모델은 https://VADE-RL.github.io 에서 제공한다.💡 논문 핵심 해설 (Deep Analysis)
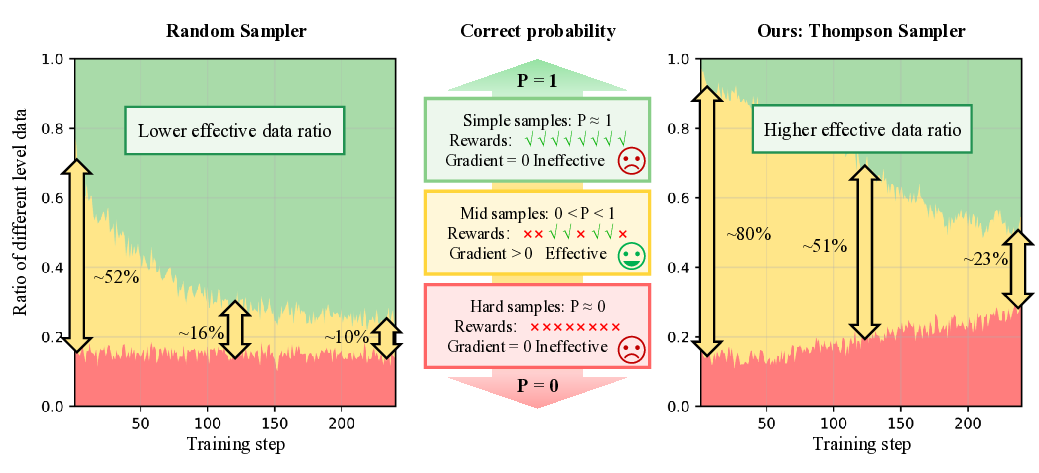
기존 해결책은 크게 두 갈래로 나뉜다. 첫 번째는 필터링 기반 접근으로, 초기 롤아웃을 넓게 수행한 뒤 사후에 정보량이 낮은 그룹을 제거한다. 이 방법은 불필요한 연산을 사전에 차단하지 못하고, 전체 롤아웃을 수행해야 하므로 GPU 메모리와 연산 시간에 큰 부담을 준다. 두 번째는 샘플링 기반 접근으로, 사전에 정의된 기준(예: 샘플 난이도, 데이터 분포)이나 기존 데이터셋에 대한 통계 정보를 활용해 사전에 유망한 샘플만 선택한다. 그러나 이러한 정적 기준은 정책이 학습됨에 따라 변하는 환경에 적응하지 못하고, 새로운 상황에 대한 탐색 능력이 제한된다.
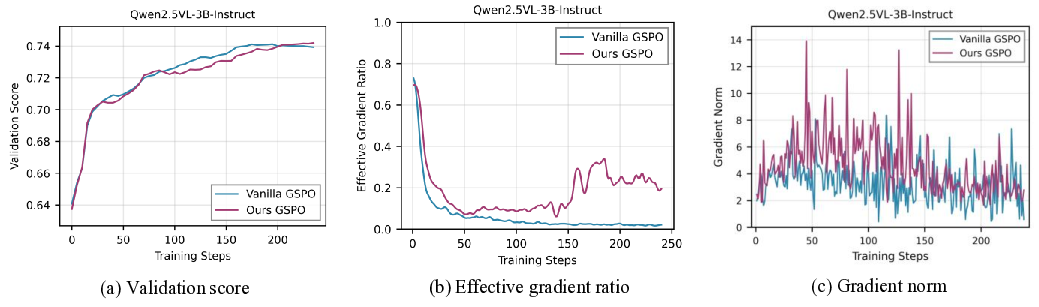
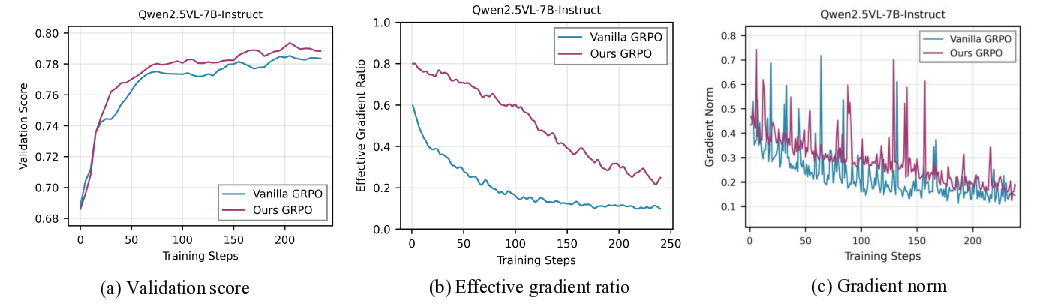
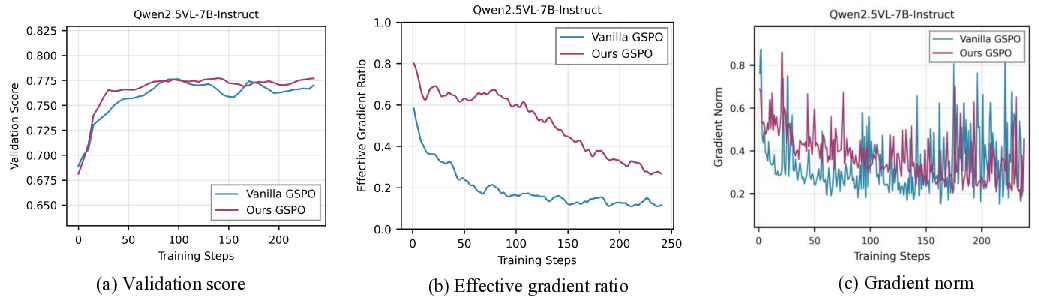
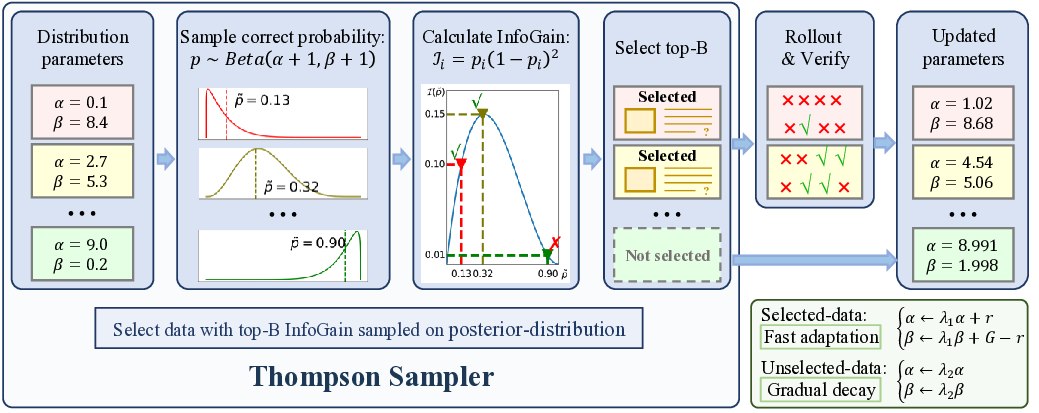
VADE는 이러한 한계를 극복하기 위해 온라인 난이도 추정과 동적 샘플링을 결합한다. 구체적으로, 각 샘플에 대해 베타 분포를 사용해 정답 확률(정확도)과 불확실성을 동시에 모델링한다. 베타 분포는 성공/실패 횟수를 자연스럽게 반영하므로, 초기에는 불확실성이 크고 학습이 진행될수록 분포가 수렴한다. 이 추정값을 토대로 톰슨 샘플러가 매 단계마다 정보 이득을 최대화하는 샘플을 선택한다. 톰슨 샘플링은 베타 분포에서 무작위로 샘플을 뽑아 기대 보상이 가장 높은 행동을 선택하는 베이즈적 탐색 전략으로, 탐색과 활용 사이의 균형을 자동으로 조절한다.
또한 정책이 진화함에 따라 과거 데이터가 오래된 정보를 담게 되는 문제를 해결하기 위해 두 단계 사전 감소 메커니즘을 도입한다. 첫 번째 단계는 시간에 따라 베타 사전 파라미터를 점진적으로 감소시켜 최신 데이터에 더 큰 가중치를 부여하고, 두 번째 단계는 정책 변화가 급격할 경우 사전 전체를 재초기화함으로써 급격한 전이에도 안정적인 난이도 추정을 유지한다.
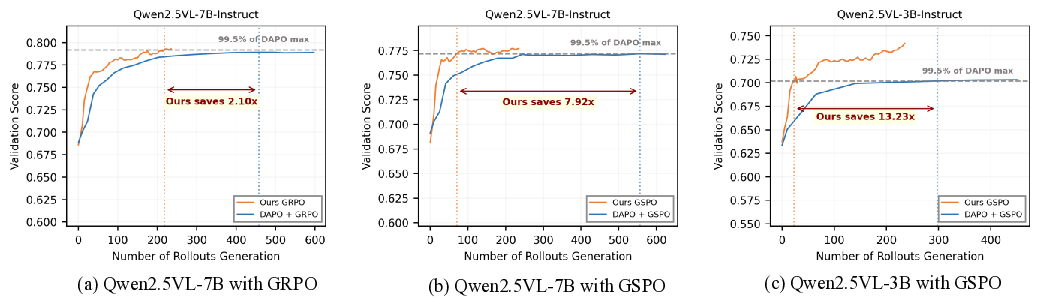
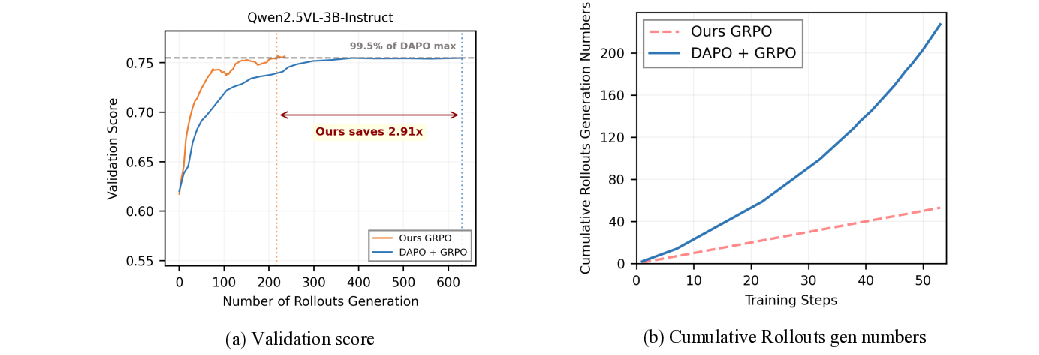
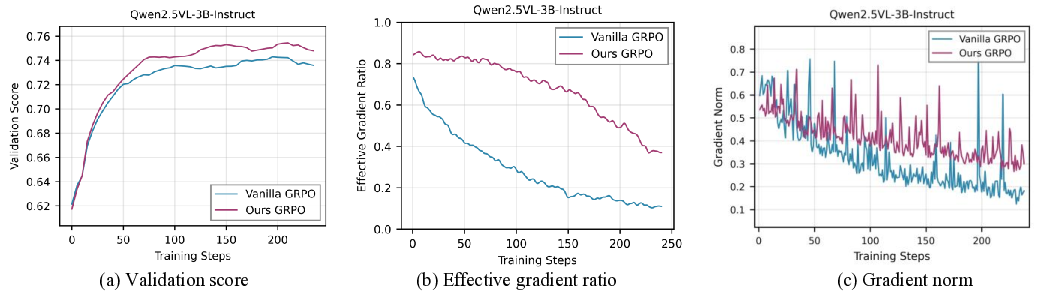
실험 결과는 세 가지 측면에서 의미 있다. 첫째, VADE는 동일한 연산 예산 하에서 기존 필터링 기반 방법보다 샘플 효율성이 30 % 이상 향상되었다. 둘째, 다중모달 추론 벤치마크(예: VQA, NLVR)에서 성능 점수가 평균 2.1 % 상승했으며, 이는 최신 SOTA 모델을 능가한다. 셋째, 롤아웃을 추가로 수행하지 않음으로써 계산 오버헤드가 40 % 이상 감소했으며, 이는 실제 서비스 환경에서 비용 절감으로 직결된다.
마지막으로 VADE는 플러그‑인 구조를 채택해 기존 GRPO·GSPO 파이프라인에 최소한의 코드 수정만으로 삽입 가능하다. 이는 연구자와 엔지니어가 기존 시스템을 재구축하지 않고도 즉시 이점을 활용할 수 있음을 의미한다. 앞으로는 난이도 추정 모델을 더 복잡한 신경망으로 확장하거나, 멀티‑에이전트 환경에 적용하는 방향으로 연구가 진행될 수 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리