LLM으로 자동 보상 함수 설계하는 LEARN Opt 프레임워크
📝 원문 정보
- Title: Leveraging LLMs for reward function design in reinforcement learning control tasks
- ArXiv ID: 2511.19355
- 발행일: 2025-11-24
- 저자: Franklin Cardenoso, Wouter Caarls
📝 초록 (Abstract)
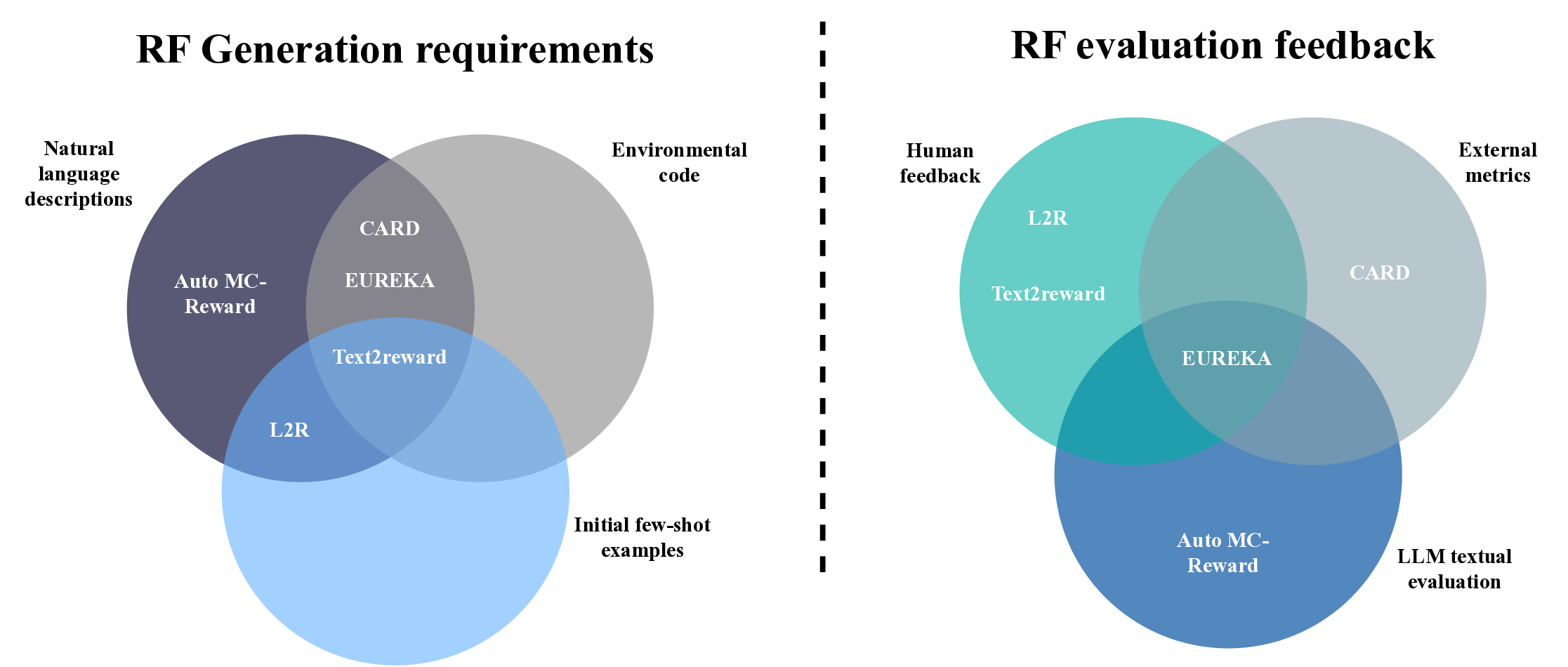
보상 함수 설계는 강화학습(RL)에서 큰 병목 현상으로, 풍부한 인간 전문지식과 많은 시간 투자가 필요하다. 기존 연구와 최근 대형 언어 모델(LLM)의 발전은 보상 함수 자동 생성 가능성을 보여주었지만, 대부분 사전 평가 지표, 인간이 만든 피드백, 혹은 환경 소스 코드를 컨텍스트로 요구한다. 이러한 제약을 극복하고자 본 논문은 LEARN‑Opt(LLM‑based Evaluator and Analyzer for Reward functioN Optimization)를 제안한다. LEARN‑Opt는 LLM 기반이며 완전 자동·모델에 독립적인 프레임워크로, 시스템 설명과 과제 목표만으로 보상 함수 후보를 생성·실행·평가한다. 핵심 기여는 시스템·목표 서술에서 직접 성능 지표를 도출해 사전 인간 정의 지표 없이도 보상 함수를 무감독으로 평가·선택할 수 있다는 점이다. 실험 결과 LEARN‑Opt는 최신 방법인 EUREKA와 동등하거나 더 나은 성능을 보이며, 사전 지식 요구량이 적다. 자동 보상 설계는 변동성이 큰 문제이며 평균 후보는 실패하지만 다중 실행을 통해 최적 후보를 찾을 수 있다. 또한 저비용 LLM도 고성능 후보를 찾아 대형 모델에 필적하거나 능가함을 확인했다. 이러한 결과는 사전 인간 정의 지표 없이도 고품질 보상 함수를 생성해 엔지니어링 비용을 크게 낮추고 일반성을 향상시킬 수 있음을 시사한다.💡 논문 핵심 해설 (Deep Analysis)
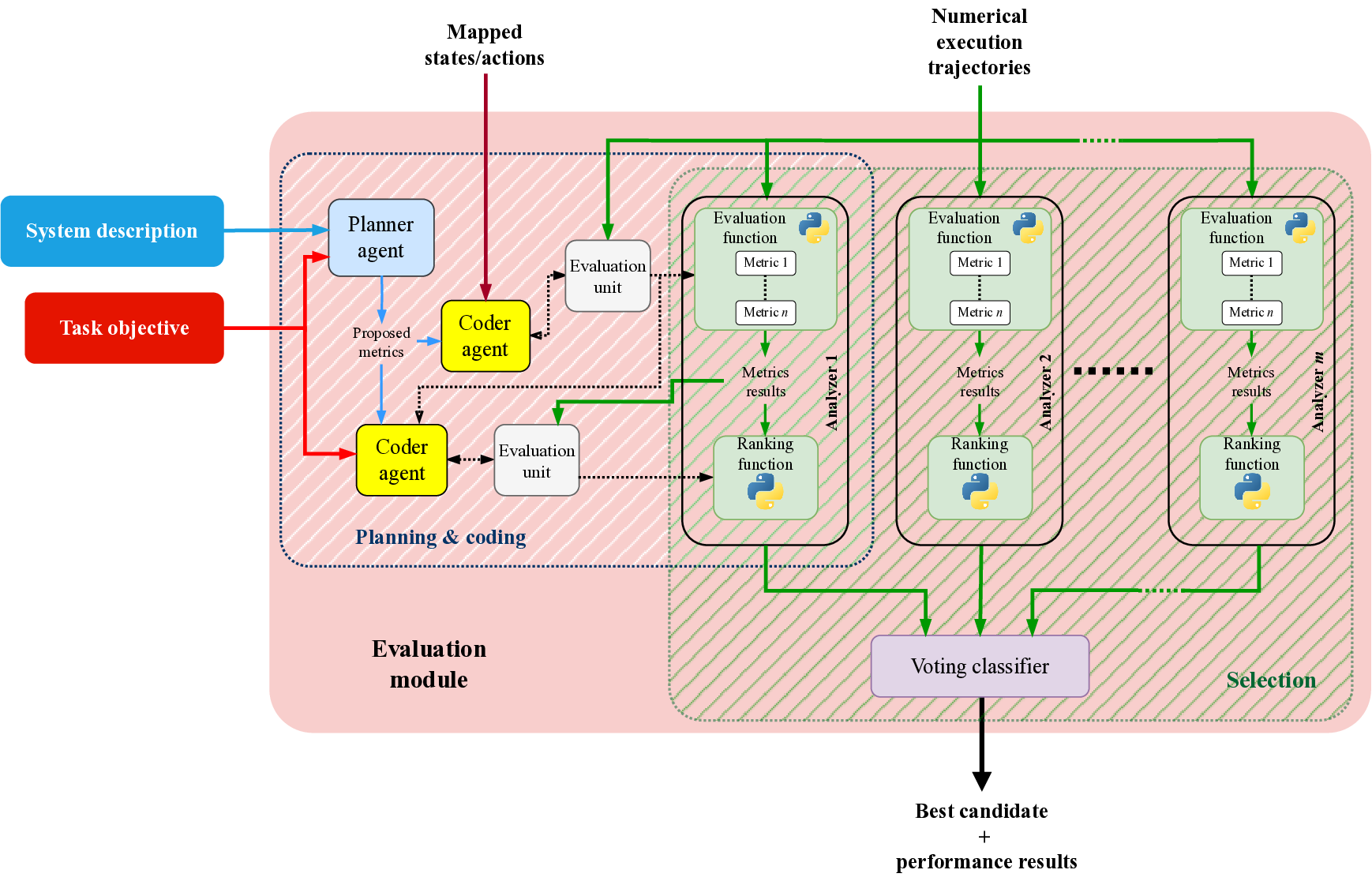
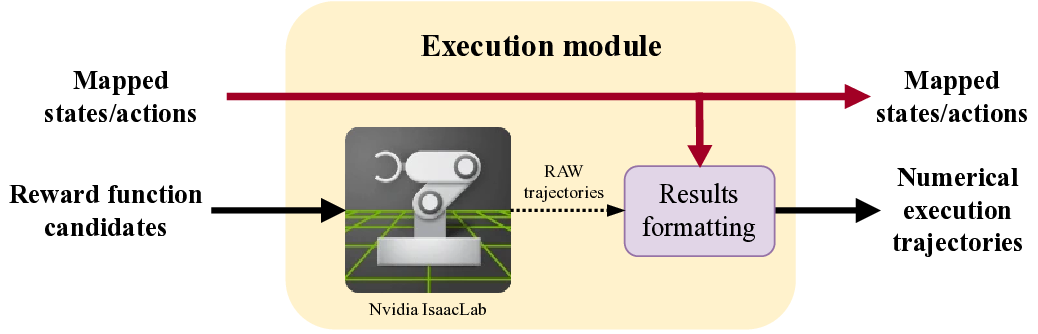
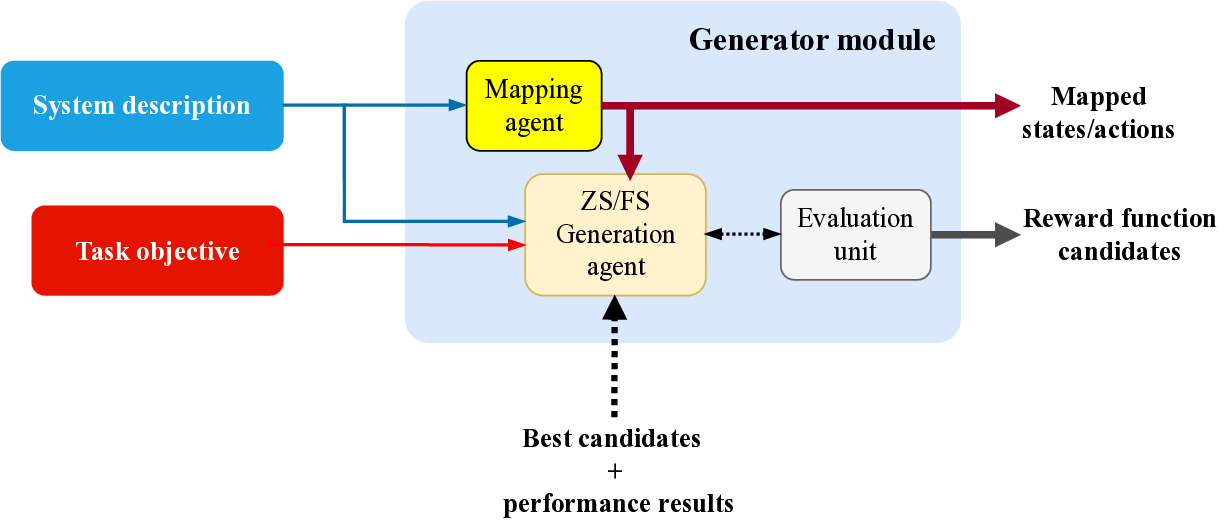
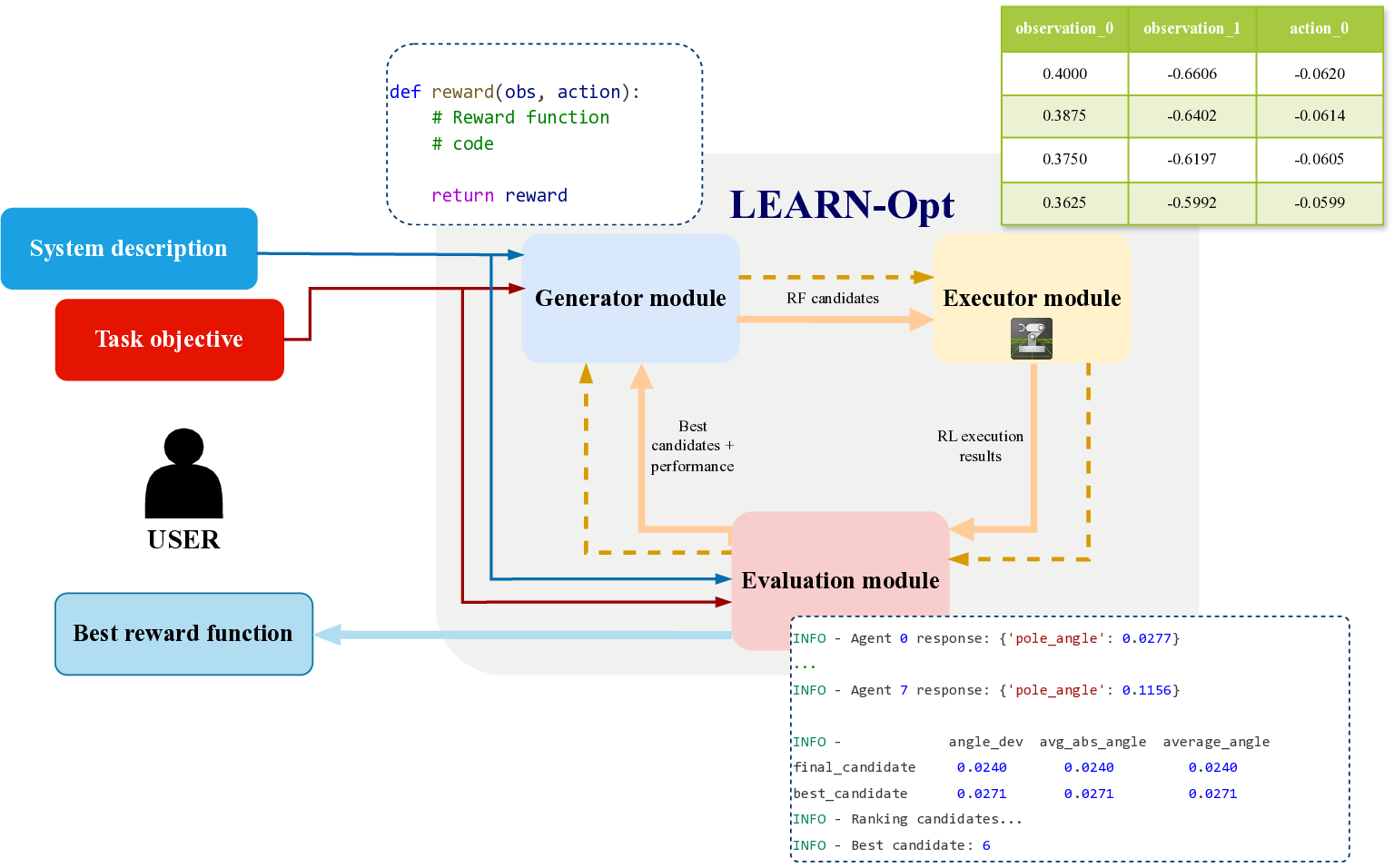
방법론적으로는 (i) 텍스트 기반 시스템·목표 파싱, (ii) 파싱된 정보를 바탕으로 후보 보상 함수를 생성, (iii) 생성된 함수를 실제 환경에 적용해 시뮬레이션 실행, (iv) 실행 결과를 LLM이 다시 해석해 성능 지표를 도출하고, (v) 이 지표를 기반으로 후보를 순위 매기는 순환 구조를 갖는다. 특히 “환경 소스 코드 없이” 실행한다는 점은 프레임워크의 모델‑에그노스틱 특성을 강조한다. 이는 다양한 RL 환경에 대한 범용 적용성을 의미한다.
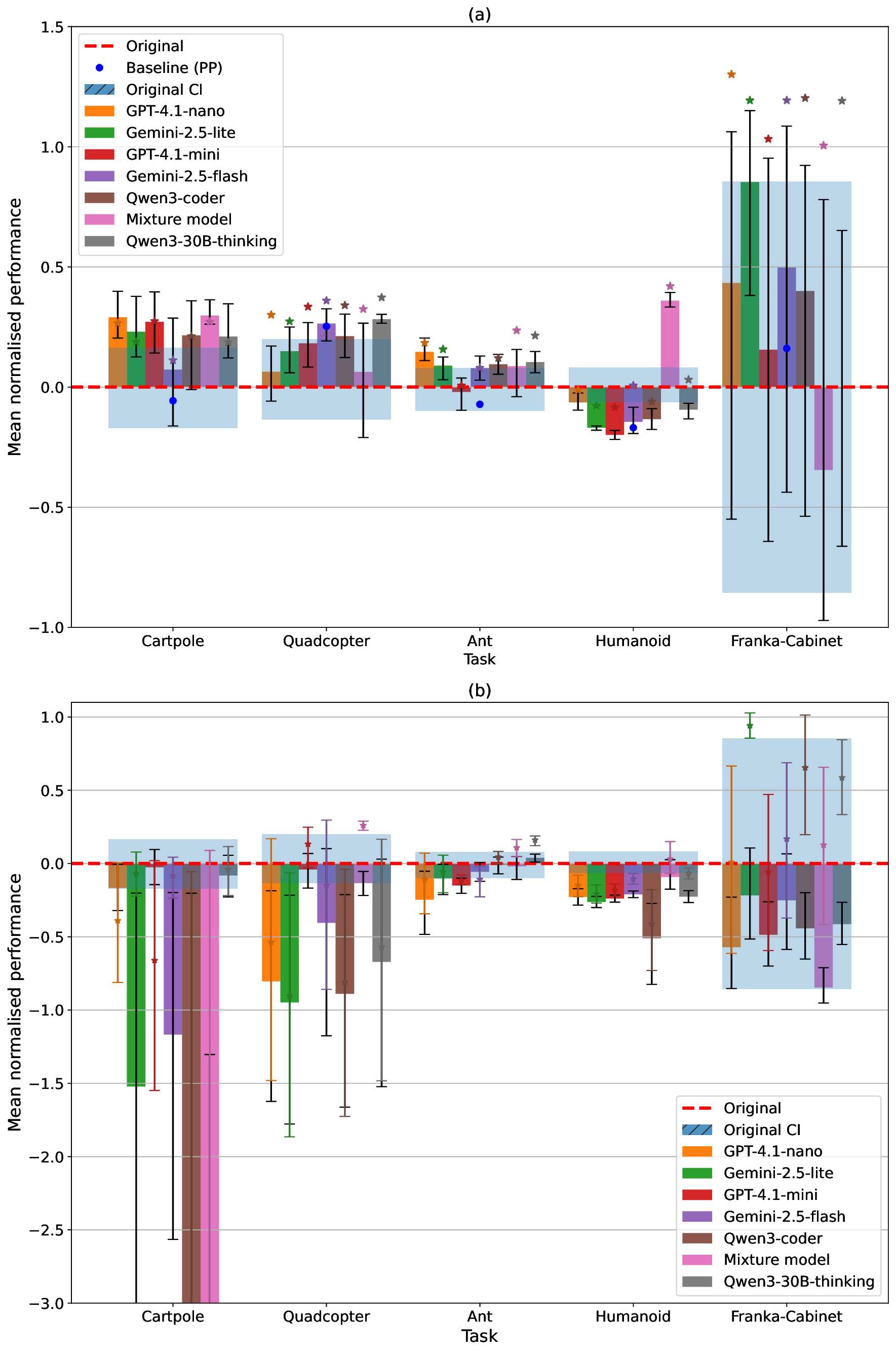
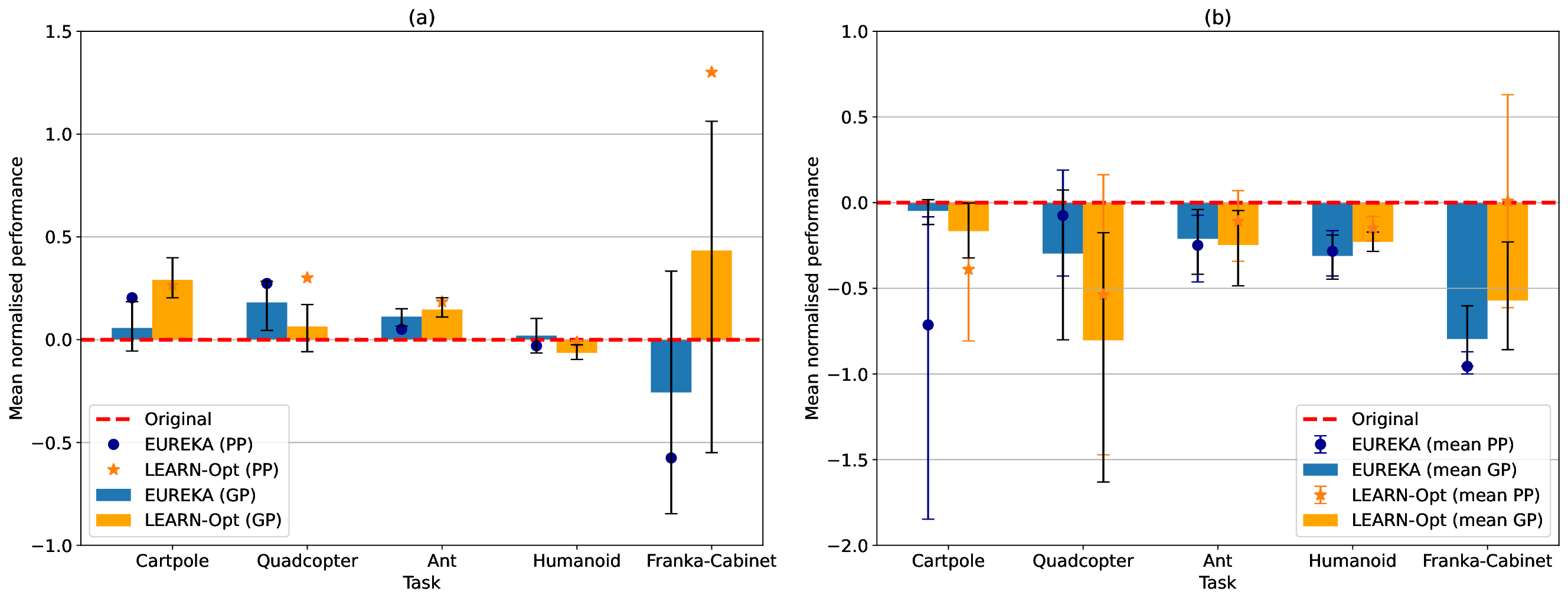
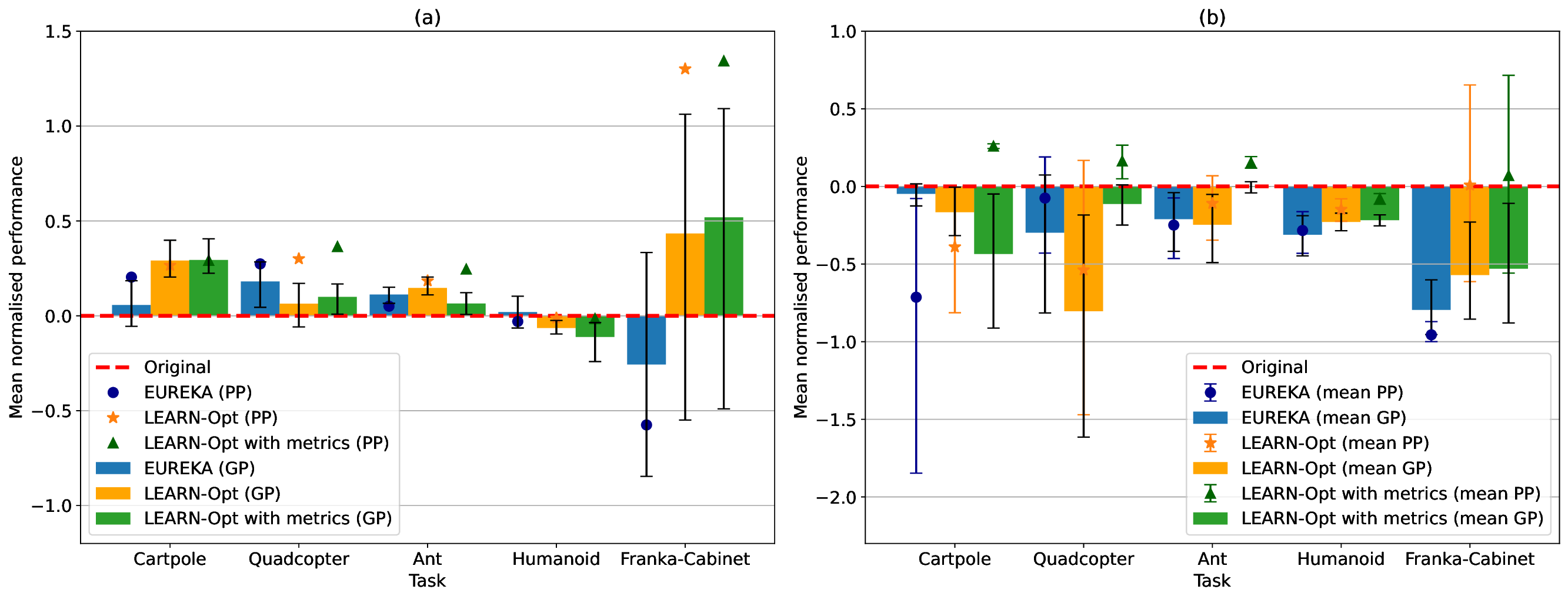
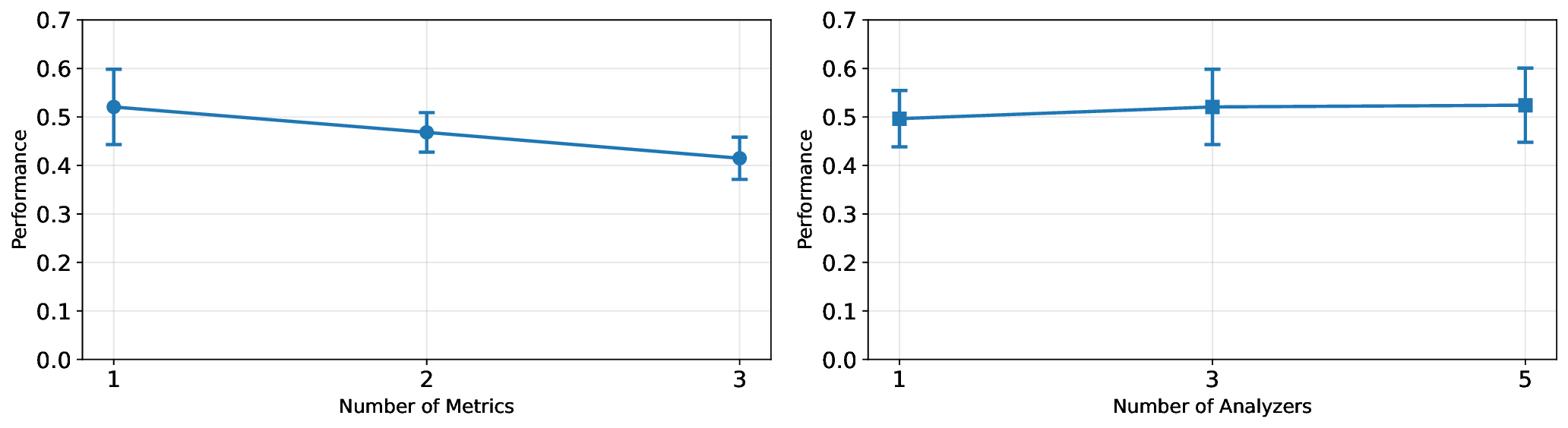
실험에서는 LEARN‑Opt를 최신 자동 보상 설계 시스템인 EUREKA와 비교했으며, 동일하거나 더 나은 성능을 보였다. 흥미로운 점은 저비용 LLM(예: 7B 파라미터 모델)도 고비용 대형 모델에 필적하는 후보를 찾아냈다는 것이다. 이는 비용 효율적인 연구·산업 현장에서 LLM 선택의 폭을 넓힌다. 또한 저자들은 자동 설계가 “고변동성(high‑variance)” 문제임을 강조하며, 단일 실행보다 다중 실행을 통해 최적 후보를 탐색할 필요성을 제시한다. 이는 메타‑최적화 레벨에서의 전략적 접근을 요구한다는 점에서 향후 연구 방향을 제시한다.
한계점으로는 (1) LLM이 파생한 성능 지표의 신뢰성 검증이 필요하고, (2) 복잡한 연속 제어 환경에서 텍스트만으로 충분히 정교한 보상 함수를 도출할 수 있는지에 대한 추가 검증이 요구된다. 또한 “무감독 평가”가 인간 전문가의 직관적 판단을 완전히 대체할 수 있는지는 아직 논쟁의 여지가 있다. 그럼에도 불구하고, LEARN‑Opt는 보상 함수 설계의 인간 의존도를 크게 낮추고, 다양한 도메인에 빠르게 적용할 수 있는 강력한 도구로 평가된다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리