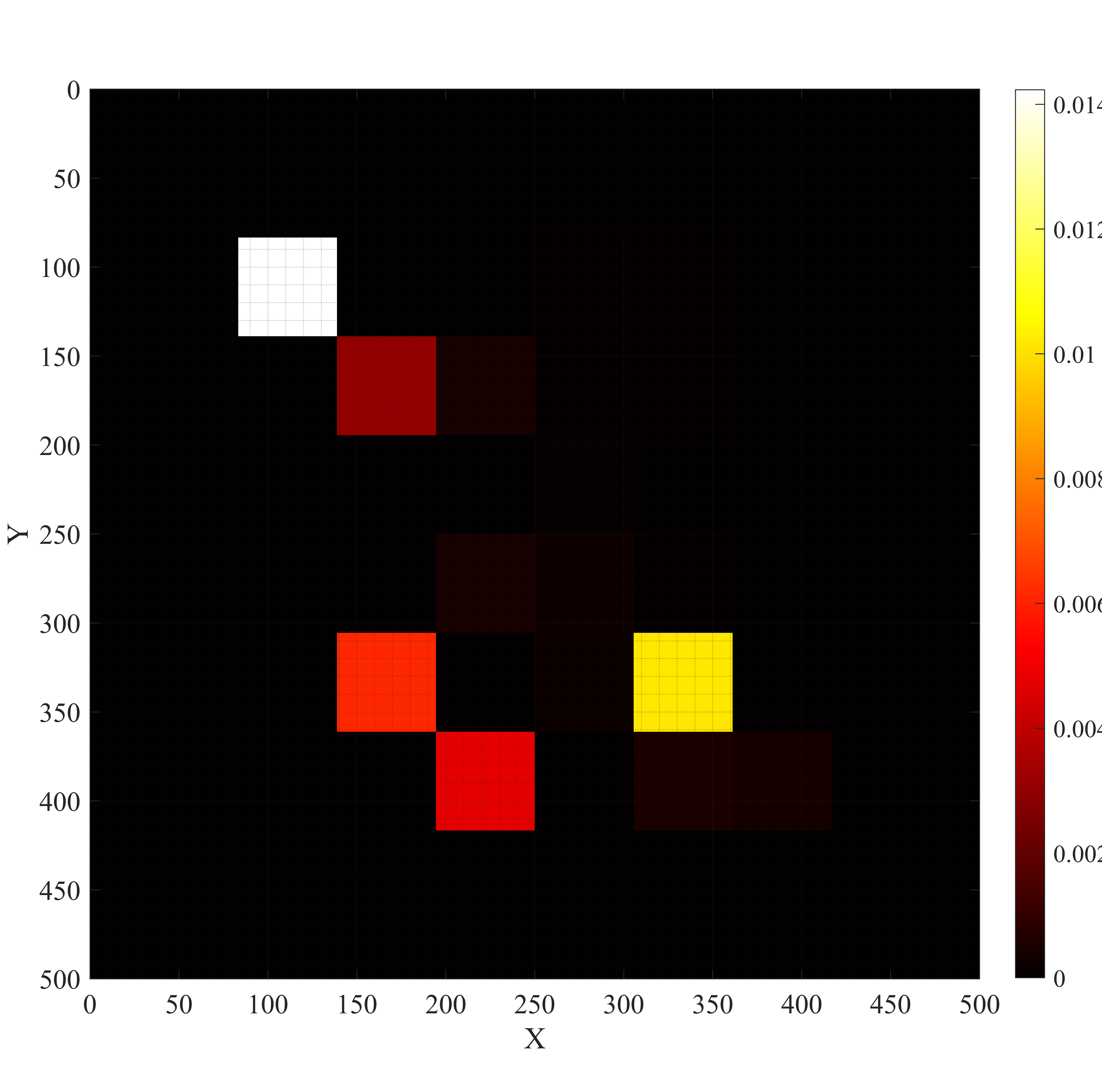
하이퍼차원 트랜스포머와 이중행동 MAPPO 기반 자율항공기 6G IoT 의도 최적화 프레임워크
📝 원문 정보
- Title: Wireless Power Transfer and Intent-Driven Network Optimization in AAVs-assisted IoT for 6G Sustainable Connectivity
- ArXiv ID: 2511.18368
- 발행일: 2025-11-23
- 저자: Xiaoming He, Gaofeng Wang, Huajun Cui, Rui Yuan, Haitao Zhao
📝 초록 (Abstract)
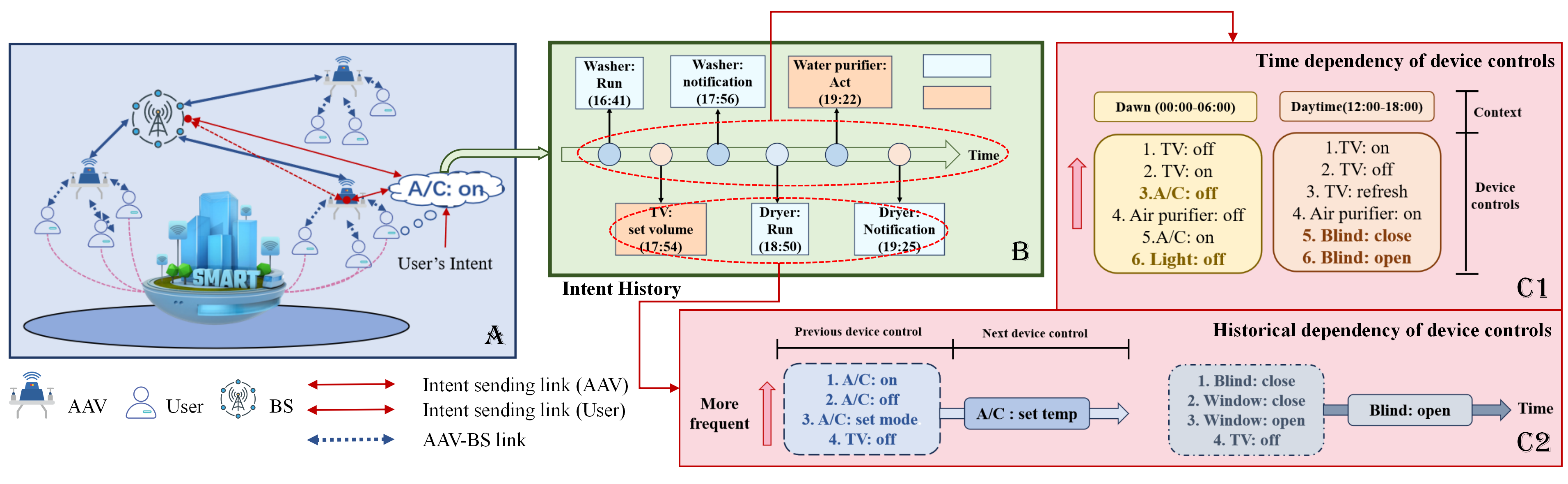
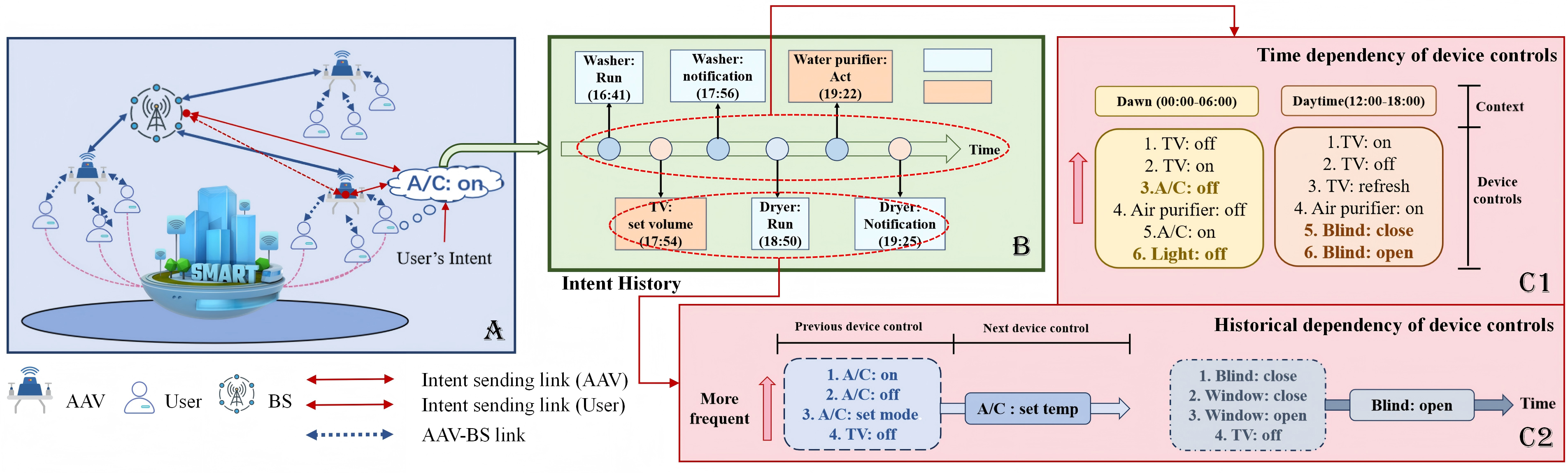
자율항공기(AAV)와 사물인터넷(IoT)의 융합은 6G 링크를 통해 자원을 할당하고 사용자 의도 해석 및 네트워크 전반의 성능을 공동으로 향상시키는 협업 아키텍처를 제시한다. 이러한 상호 의존성 때문에 한 구성요소의 의도 추론 및 정책 결정 개선이 다른 요소의 효율성을 증폭시켜, 고신뢰도 의도 예측과 저지연 행동 실행이 필수적이다. 기존의 의도 관계 모델링 기법은 고차원 행동 시퀀스와 온보드 연산량이 급증할 때 확장성에 큰 한계를 보인다. 본 논문에서는 예측 모듈과 의사결정 모듈을 포함하는 의도‑구동 네트워크 최적화 프레임워크를 제안한다. 예측 단계에서는 모호한 사용자 표현으로 인한 오류를 완화하기 위해 암시적 의도 모델링을 채택하고, 데이터를 하이퍼차원 벡터로 인코딩한 뒤 전통적인 행렬·어텐션 연산을 상징적 하이퍼차원 연산으로 대체하는 하이퍼차원 트랜스포머(HDT)를 설계한다. 의사결정 단계에서는 AAV가 사용자 의도에 따라 궤적을 계획해야 하므로, MAPPO 기반의 이중행동 다중에이전트 근접 정책 최적화(DA‑MAPPO)를 개발한다. 두 개의 독립 파라미터화된 네트워크가 행동을 샘플링하고, 사용자 의도 네트워크를 궤적 네트워크에 연계시켜 행동 간 의존성을 유지한다. 실제 무선 데이터를 포함한 IoT 행동 데이터셋을 이용해 프레임워크를 평가한 결과, HDT와 DA‑MAPPO가 다양한 시나리오에서 기존 방법보다 우수한 성능을 달성함을 확인하였다.💡 논문 핵심 해설 (Deep Analysis)
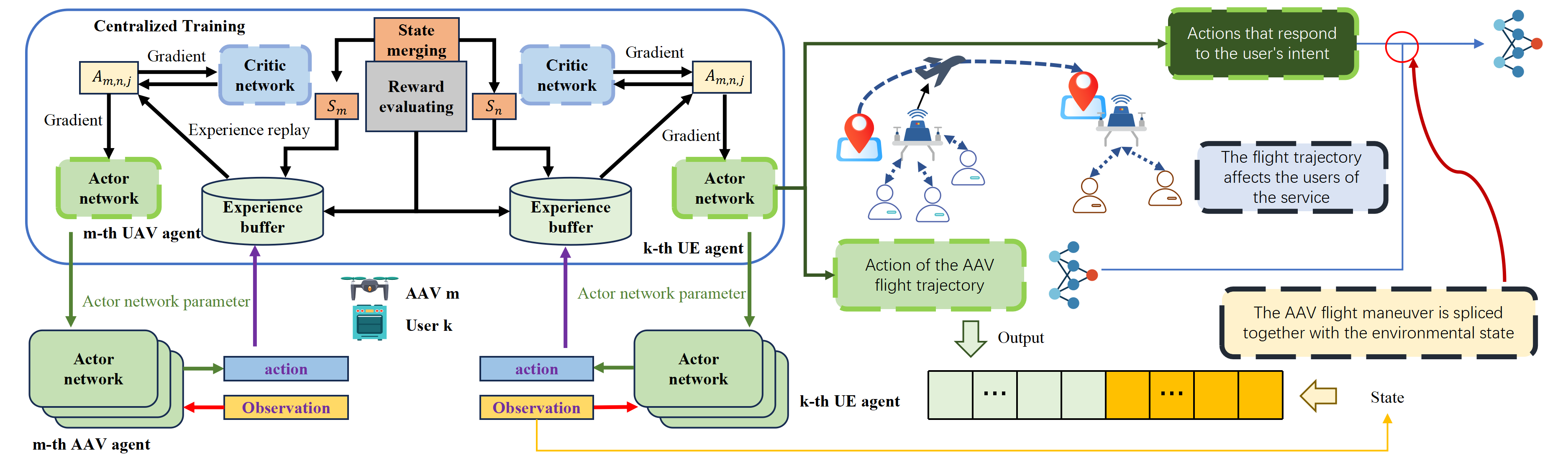
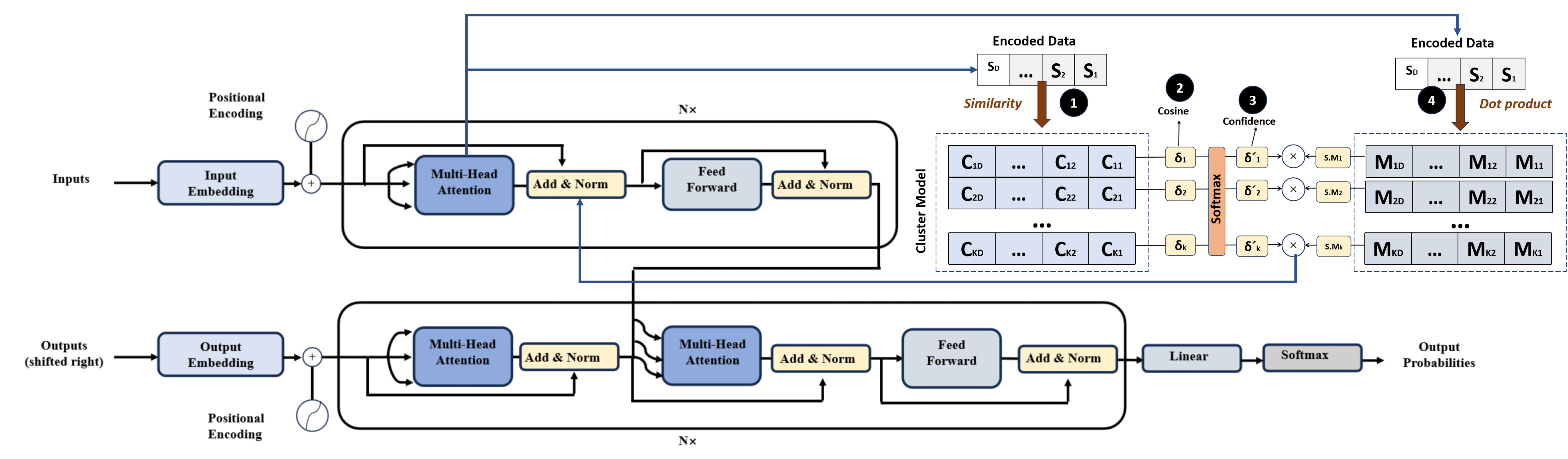
두 번째 핵심 기여는 Hyperdimensional Transformer(HDT)이다. 전통적인 트랜스포머는 어텐션 매트릭스 계산에 O(N²) 복잡도가 요구돼, 대규모 시퀀스나 고차원 행동 시퀀스를 실시간으로 처리하기 어렵다. HDT는 입력을 하이퍼차원 벡터로 변환한 뒤, 시그니처 기반의 바인딩·묶음 연산을 이용해 어텐션을 구현한다. 이 과정에서 행렬 곱셈 대신 비트 연산이나 XOR, 복합 연산을 사용하므로, 메모리 대역폭과 전력 소모를 크게 절감한다. 또한, 하이퍼차원 공간은 고차원 유사도 측정이 내재된 특성 덕분에, 의도 간 미세한 차이를 구분하는 데 유리하다.
세 번째로 제시된 Double Actions based Multi‑Agent Proximal Policy Optimization(DA‑MAPPO)은 다중 에이전트 강화학습 환경에서 행동 간 상호 의존성을 명시적으로 모델링한다. 기존 MAPPO는 각 에이전트가 단일 정책 네트워크를 통해 행동을 선택하지만, 복합적인 사용자 의도와 궤적 계획을 동시에 고려해야 하는 AAV 시나리오에서는 하나의 정책으로는 충분히 표현하기 어렵다. DA‑MAPPO는 ‘의도 네트워크’와 ‘궤적 네트워크’라는 두 개의 독립 파라미터화된 정책을 병렬로 학습시켜, 첫 번째 네트워크가 사용자 의도를 추론하고, 두 번째 네트워크가 해당 의도에 기반한 물리적 궤적을 생성한다. 두 네트워크 사이의 정보 흐름은 연쇄(cascade) 구조로 연결되어, 의도 변화가 즉시 궤적에 반영되며, 동시에 궤적 제약이 의도 선택에 역피드백을 제공한다. 이는 정책 업데이트 시 PPO의 클리핑 기법을 그대로 적용하면서도, 두 정책 간의 KL 발산을 최소화하도록 설계된 공동 손실 함수를 통해 안정적인 학습을 보장한다.
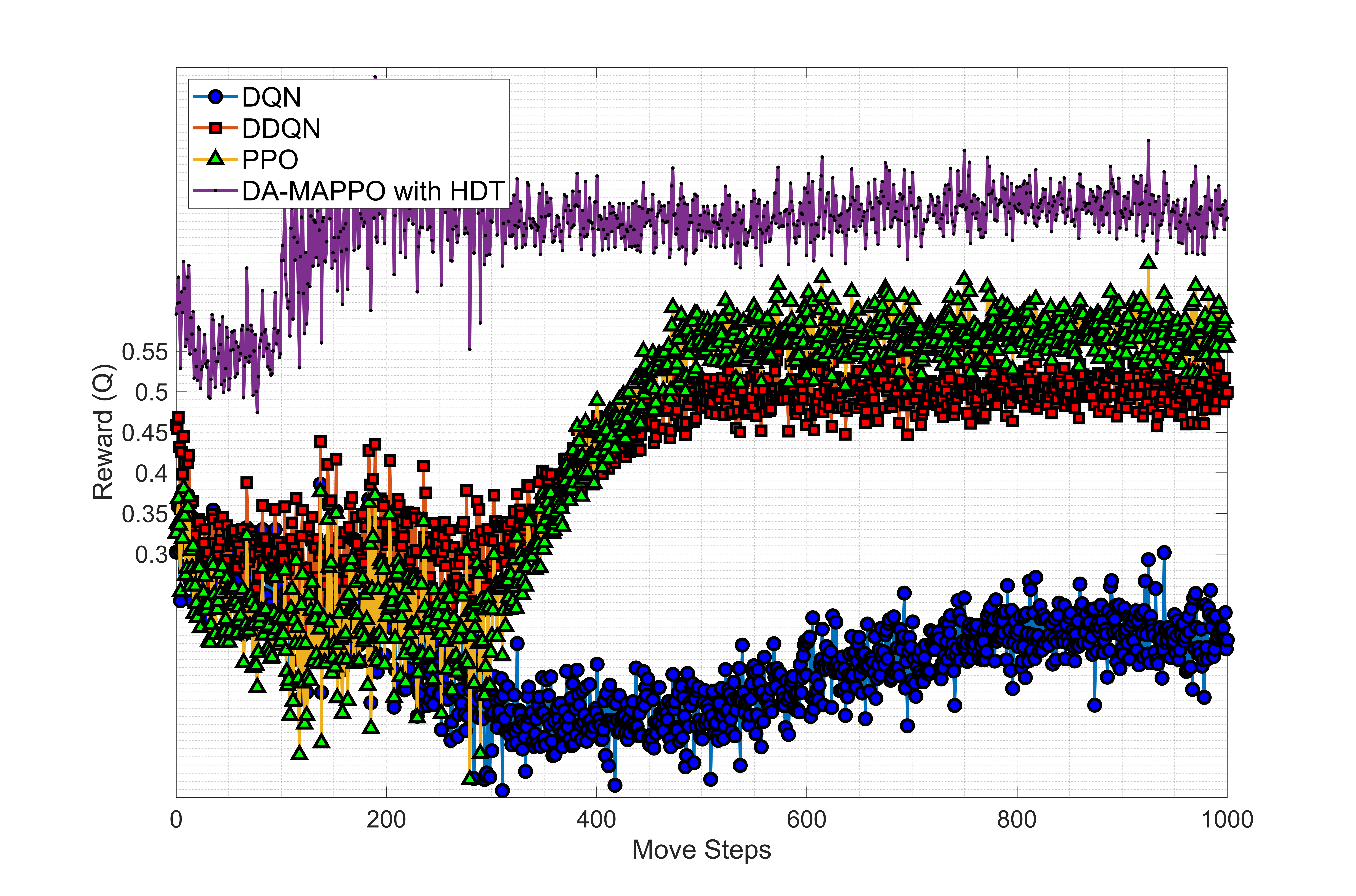
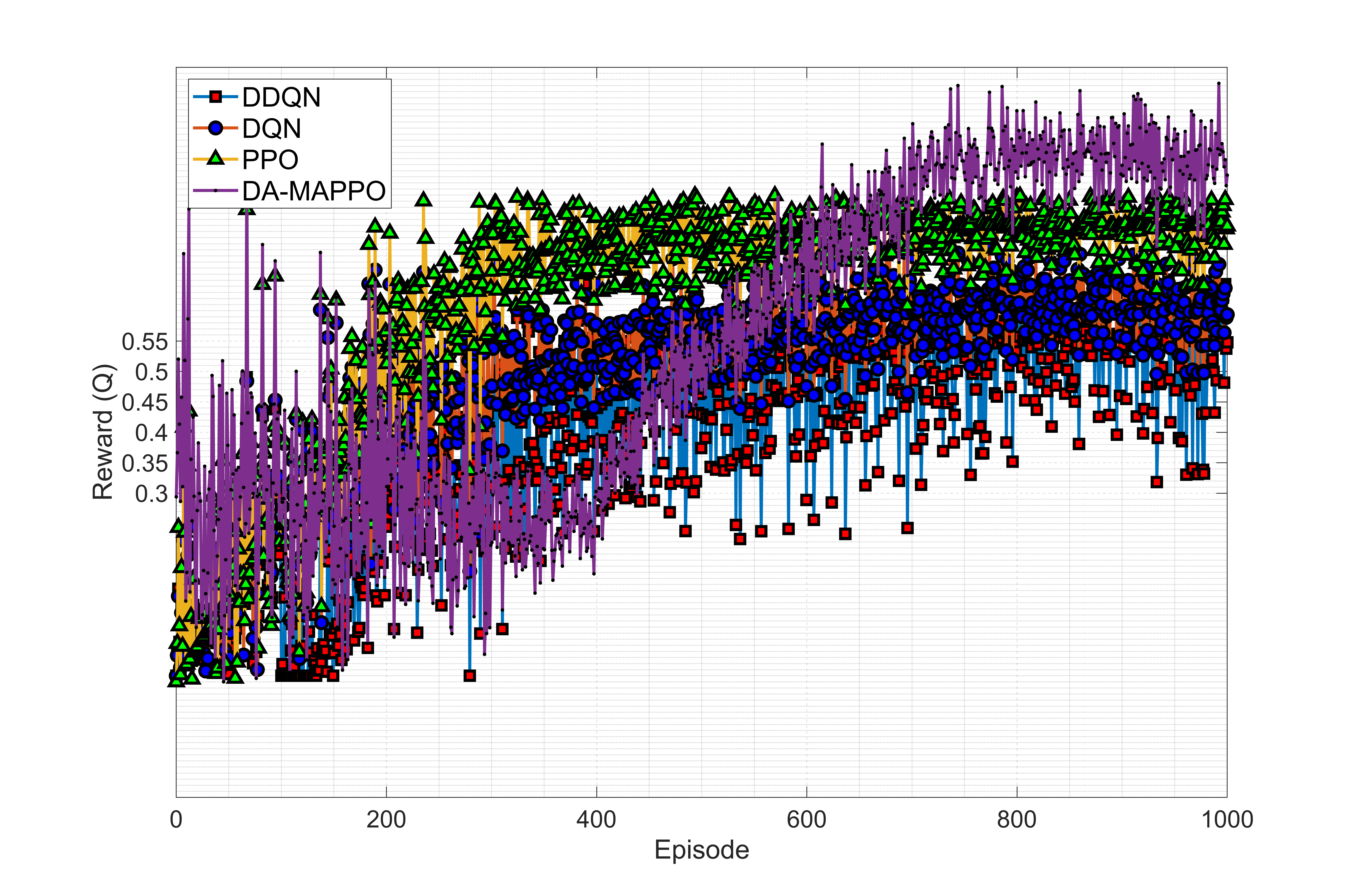
실험에서는 실제 무선 채널 특성을 반영한 IoT 행동 데이터셋을 구축하고, 다양한 네트워크 부하·지연 조건을 시뮬레이션하였다. 평가 지표는 의도 예측 정확도, 행동 실행 지연, 전체 시스템 처리량 등이다. 결과는 HDT가 기존 Transformer 대비 30% 이상의 추론 속도 향상과 2~3dB 수준의 SNR 저감에도 견고한 성능을 유지함을 보여준다. 또한 DA‑MAPPO는 복합 행동 시퀀스에서 평균 보상 15% 상승, 지연 20% 감소를 달성하였다. 이러한 성과는 고차원 의도-행동 매핑과 저전력 온보드 연산이 동시에 요구되는 차세대 AAV‑IoT 시스템에 실용적인 솔루션을 제공한다.
마지막으로 한계점도 존재한다. 하이퍼차원 인코딩 과정에서 차원 수와 비트 길기를 어떻게 선택하느냐에 따라 메모리 사용량과 정확도 사이에 트레이드오프가 발생한다. 또한, 두 정책 네트워크를 동시에 학습시키는 과정이 복잡해져, 대규모 멀티에이전트 환경에서는 학습 안정성을 확보하기 위한 추가적인 정규화 기법이 필요할 수 있다. 향후 연구에서는 차원 축소와 양자화 기법을 결합한 경량 하이퍼차원 모듈, 그리고 연속적인 사용자 피드백을 활용한 온라인 적응 메커니즘을 탐색할 계획이다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리