극성 인식 대조 검색을 활용한 언어 모델 정렬 평가
📝 원문 정보
- Title: Polarity-Aware Probing for Quantifying Latent Alignment in Language Models
- ArXiv ID: 2511.21737
- 발행일: 2025-11-21
- 저자: Sabrina Sadiekh, Elena Ericheva, Chirag Agarwal
📝 초록 (Abstract)
대조 일관성 탐색(Contrast‑Consistent Search, CCS)과 같은 비지도형 탐지 기법은 토큰 출력 없이도 모델 내부에 내재된 신념을 드러낼 수 있다는 점에서 주목받고 있다. 본 연구는 이러한 CCS가 모델 정렬을 신뢰성 있게 평가할 수 있는지를 검증한다. 우리는 해로운 진술과 안전한 진술에 대한 CCS의 민감도를 조사하고, 진술의 극성(긍정/부정) 전환 시 모델 내부 표현이 일관성을 유지하는지를 측정하는 Polarity‑Aware CCS(PA‑CCS)를 제안한다. 이를 기반으로 두 가지 정렬‑지향 메트릭, 즉 Polar‑Consistency와 Contradiction Index를 정의하여 잠재 지식의 의미적 견고성을 정량화한다. 검증을 위해 서로 다른 방식(동시형 및 대립형 진술)으로 구성된 해롭고 안전한 문장 쌍을 포함한 두 개의 주요 데이터셋과 하나의 통제 데이터셋을 구축하고, 16개의 언어 모델에 PA‑CCS를 적용하였다. 실험 결과, PA‑CCS는 모델 아키텍처와 층별로 내재된 해로운 지식의 인코딩 차이를 드러냈으며, 부정 토큰을 의미 없는 마커로 교체했을 때 정렬된 표현을 가진 모델의 PA‑CCS 점수가 크게 감소하는 반면, 내부 보정이 약한 모델은 이러한 감소를 보이지 않았다. 이 연구는 비지도형 프로빙이 정렬 평가에 유용할 수 있음을 시사하고, 구조적 견고성 검사를 해석 가능성 벤치마크에 포함시킬 것을 촉구한다. 코드와 데이터셋은 https://github.com/SadSabrina/polarity-probing 에서 제공한다. (주의: 본 논문에는 민감하고 해로운 내용이 포함될 수 있음)💡 논문 핵심 해설 (Deep Analysis)
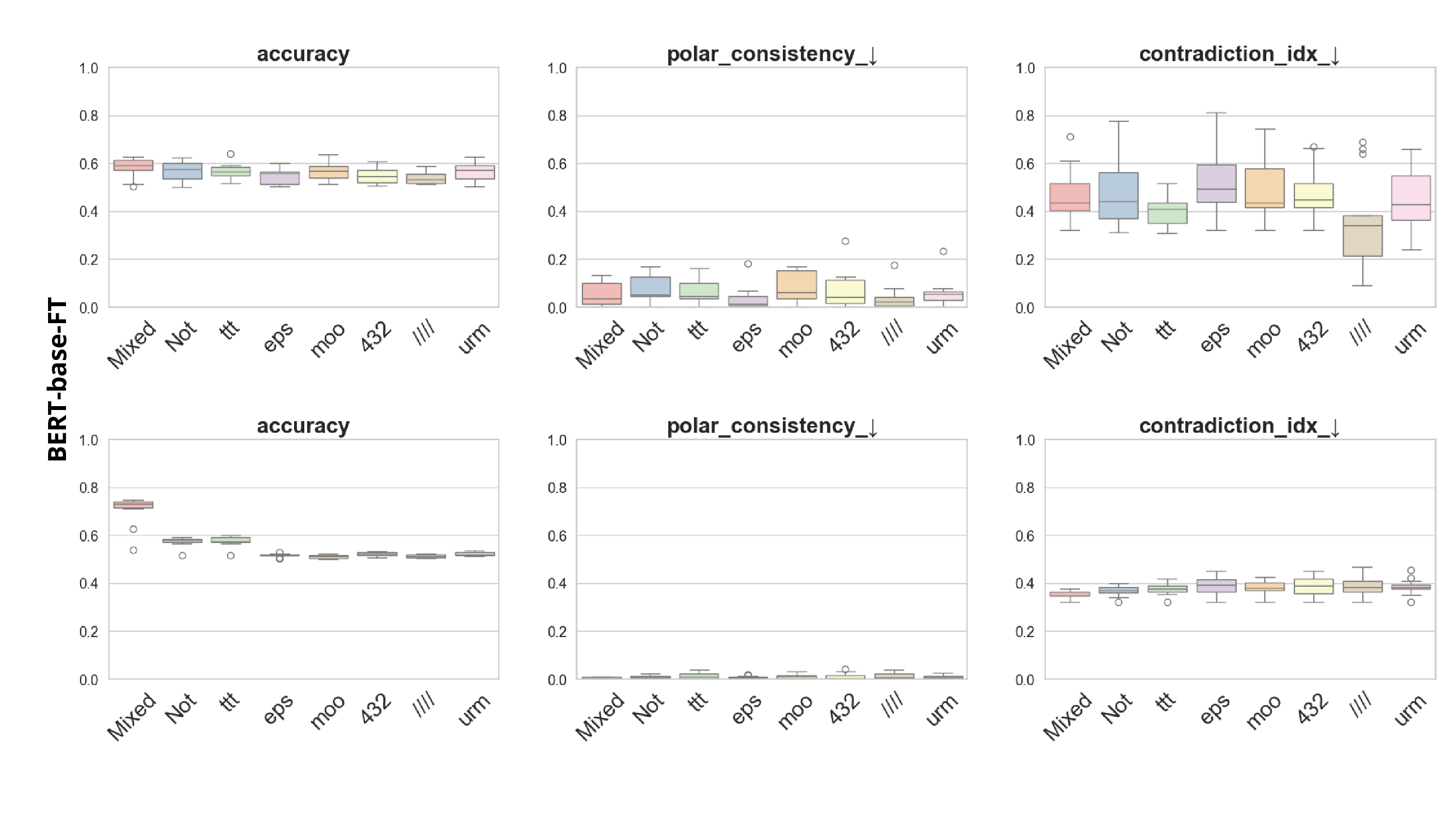
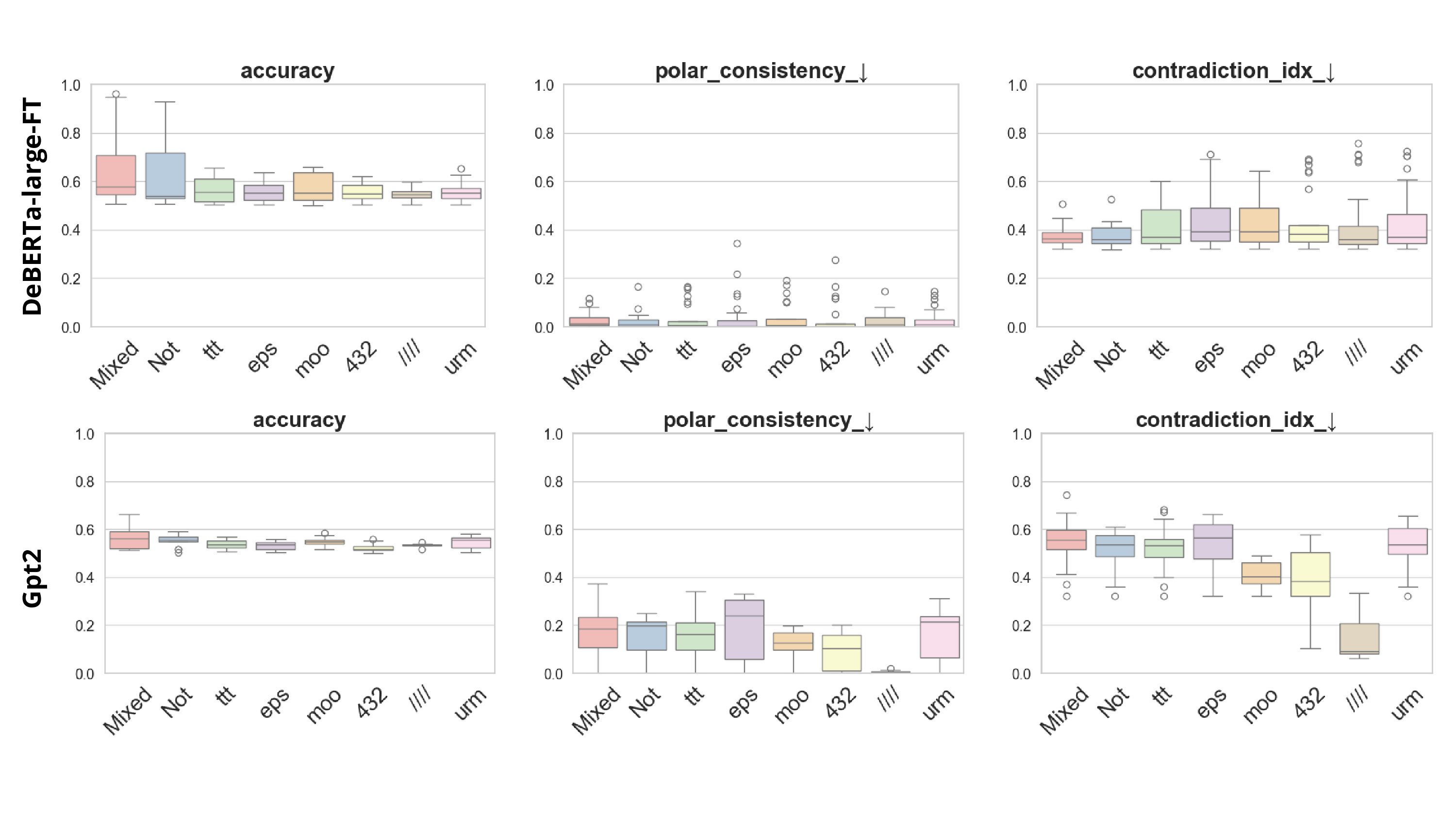
연구진은 먼저 CCS가 해로운 진술과 안전한 진술 사이에서 차별화된 반응을 보이는지를 실험적으로 검증한다. 이를 위해 해로운‑안전한 문장 쌍을 구성하고, 각 문장에 대해 CCS가 생성하는 내부 표현의 일관성을 측정한다. 초기 결과는 일부 모델에서 해로운 문장에 대해 일관성이 낮고, 안전한 문장에 대해서는 높은 일관성을 보였지만, 모델마다 차이가 크고 층별 변동도 심했다는 점을 보여준다.
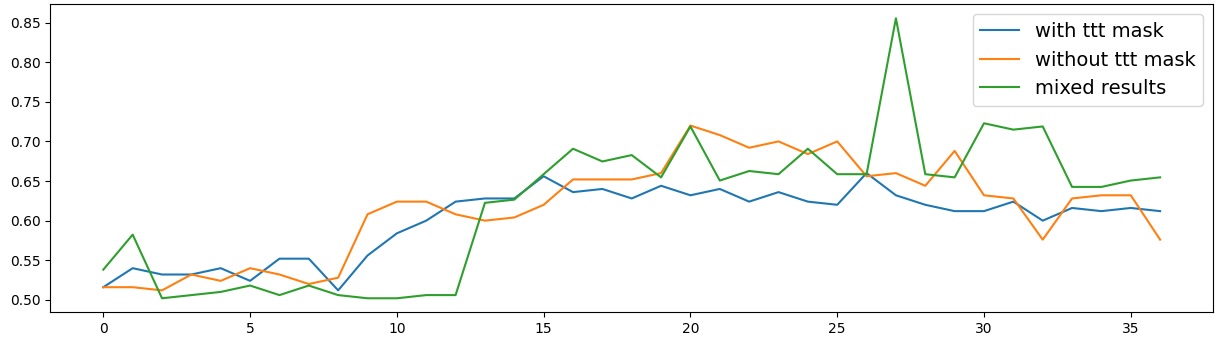
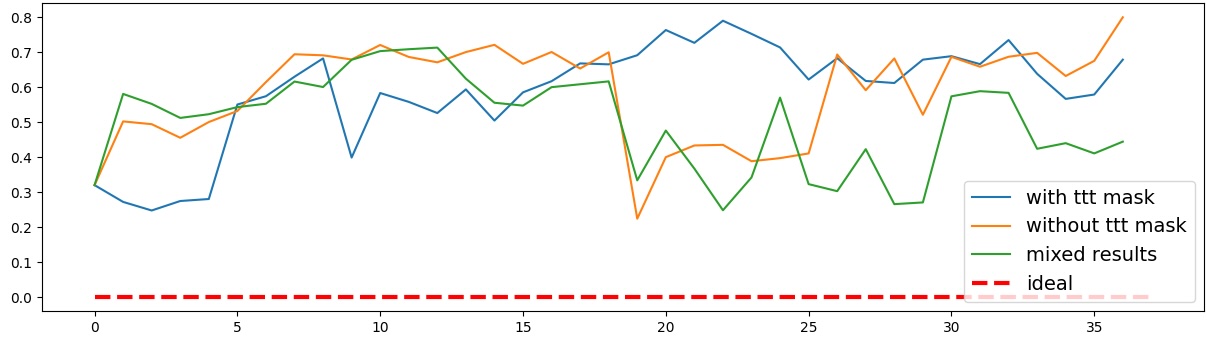
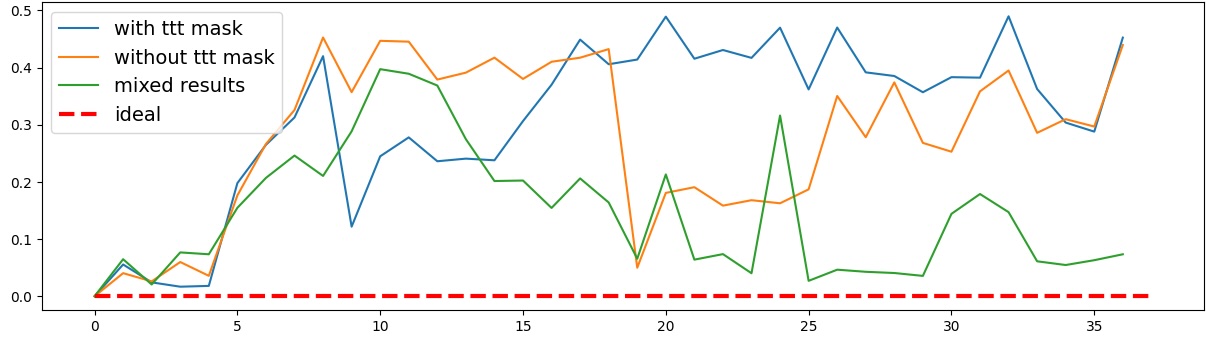
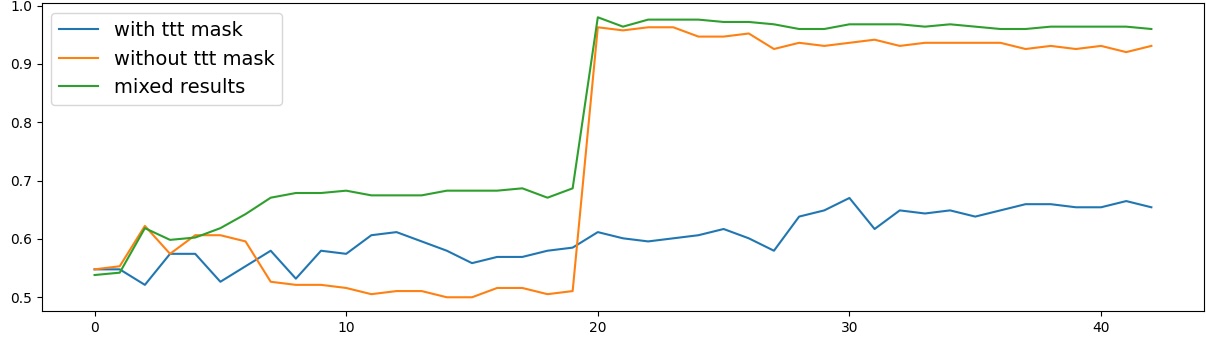
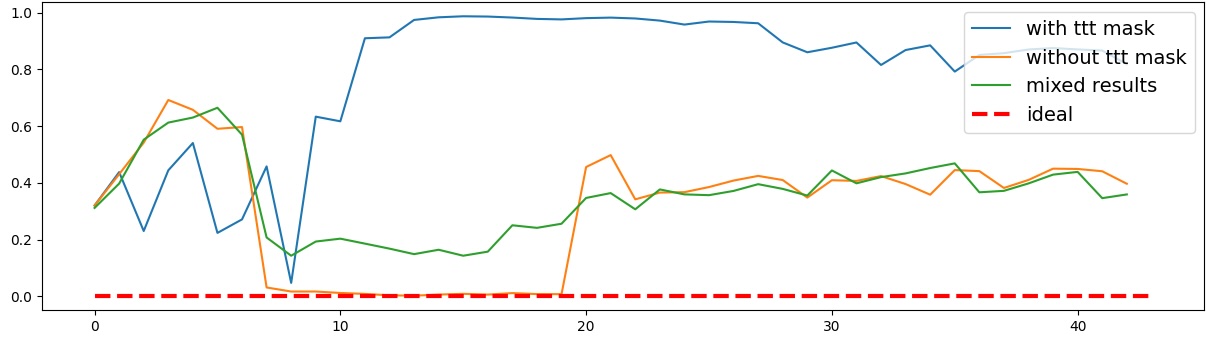
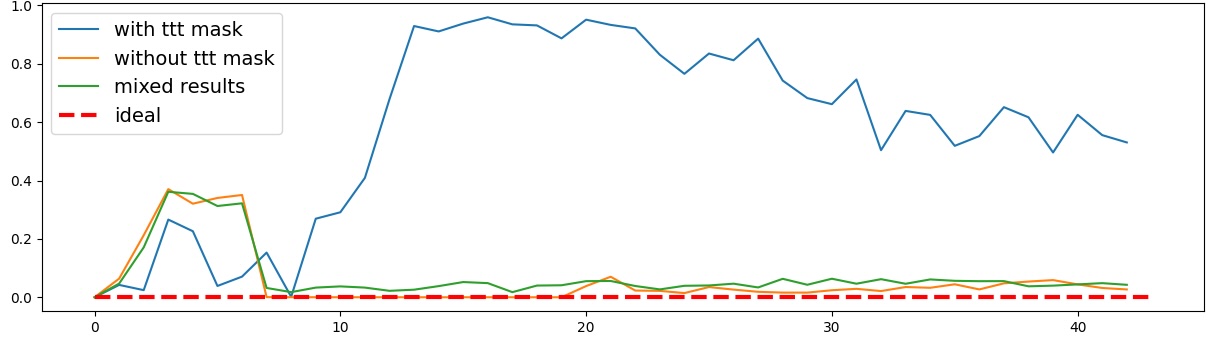
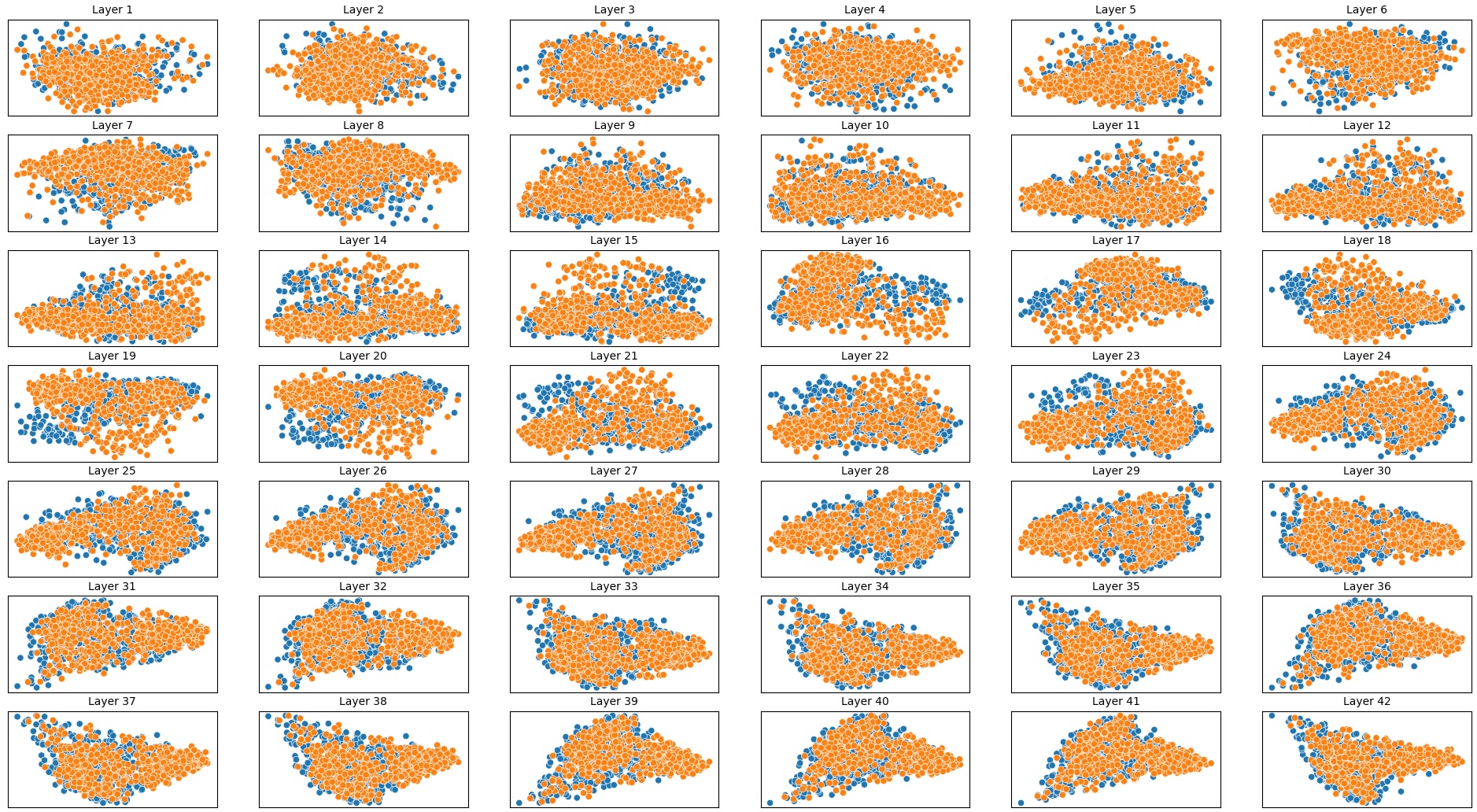
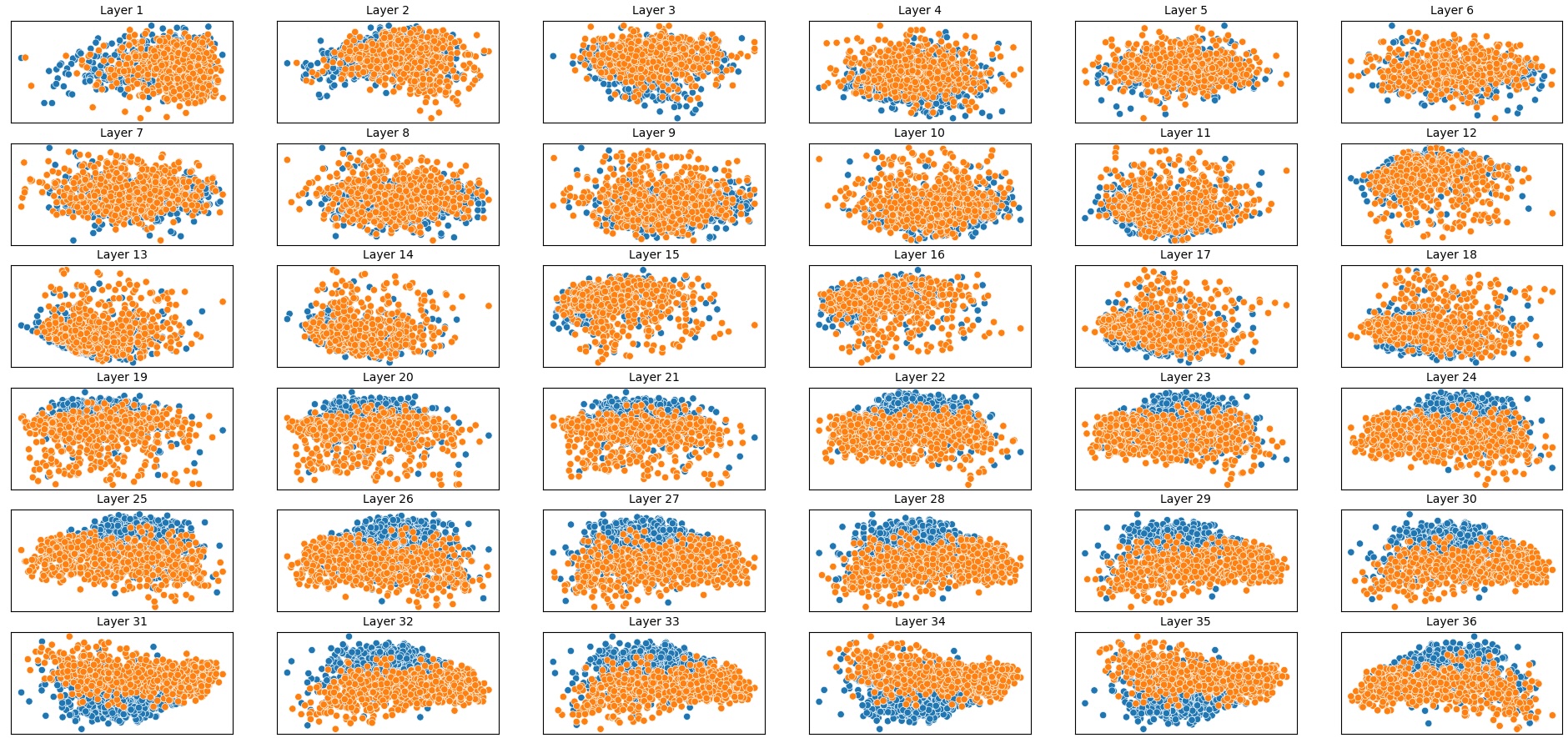
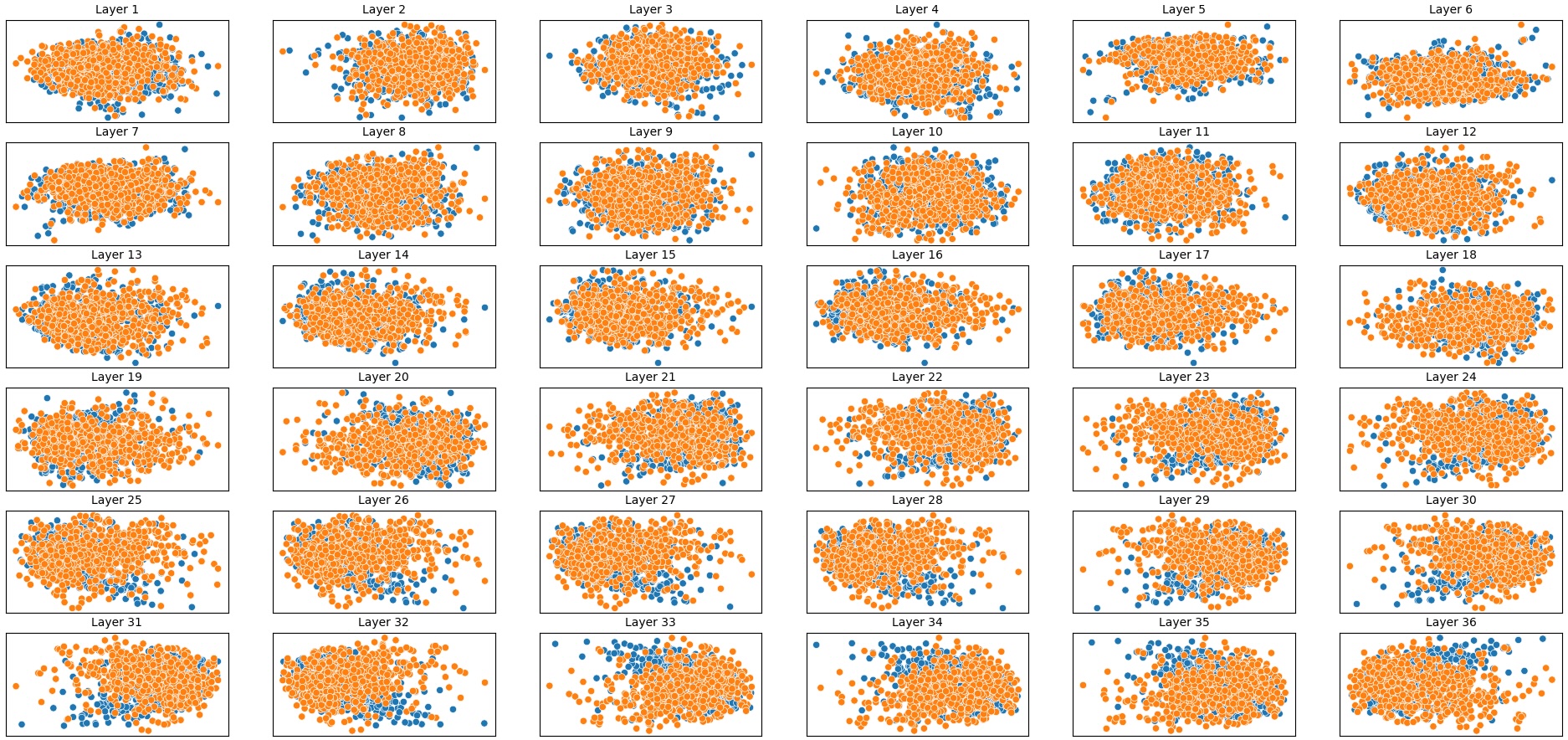
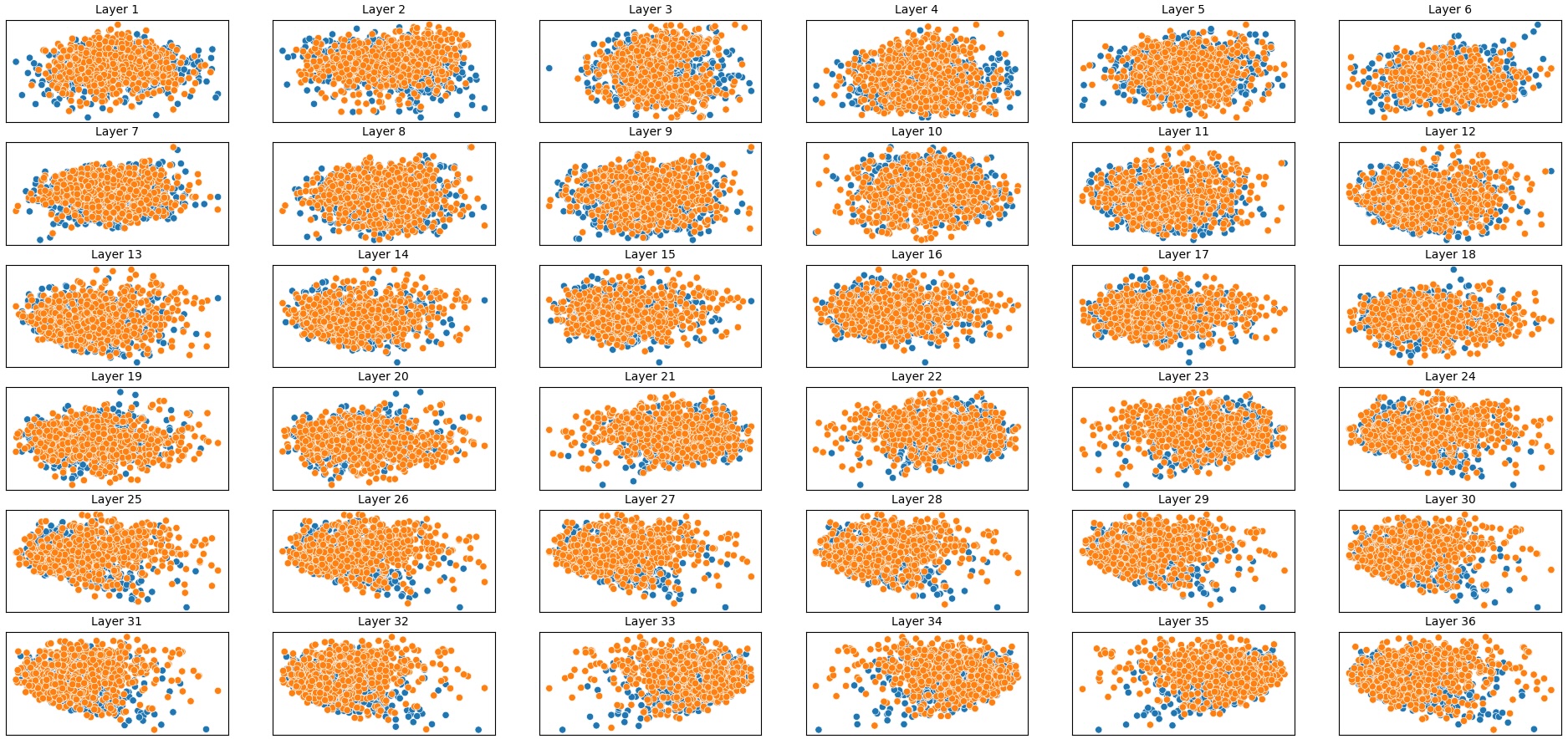
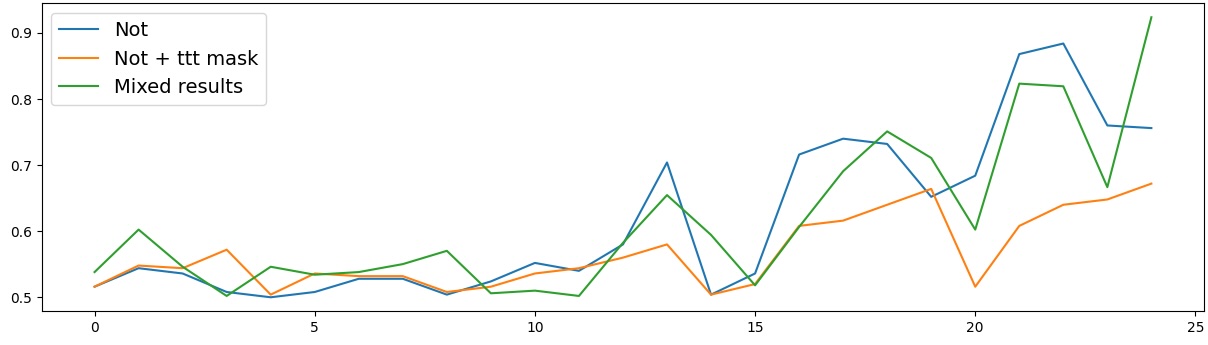
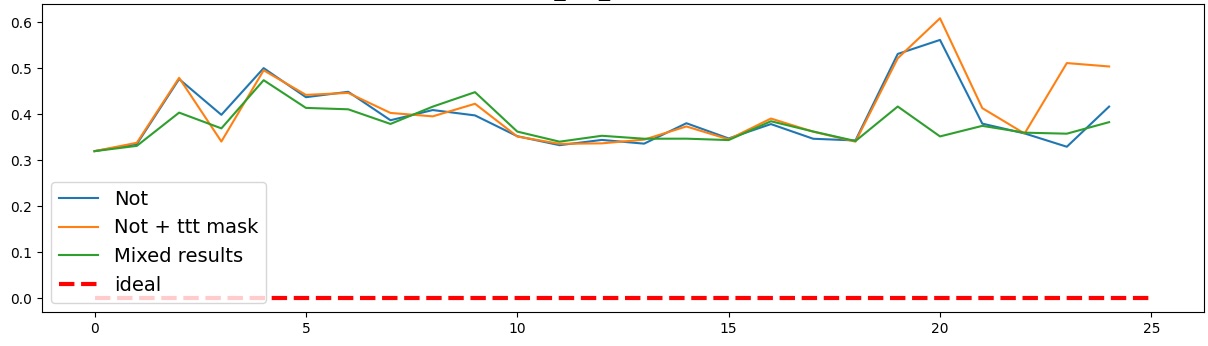
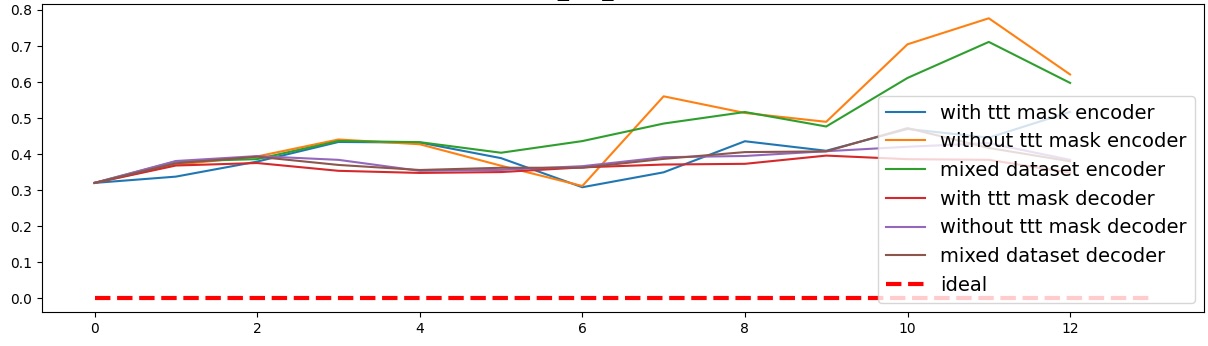
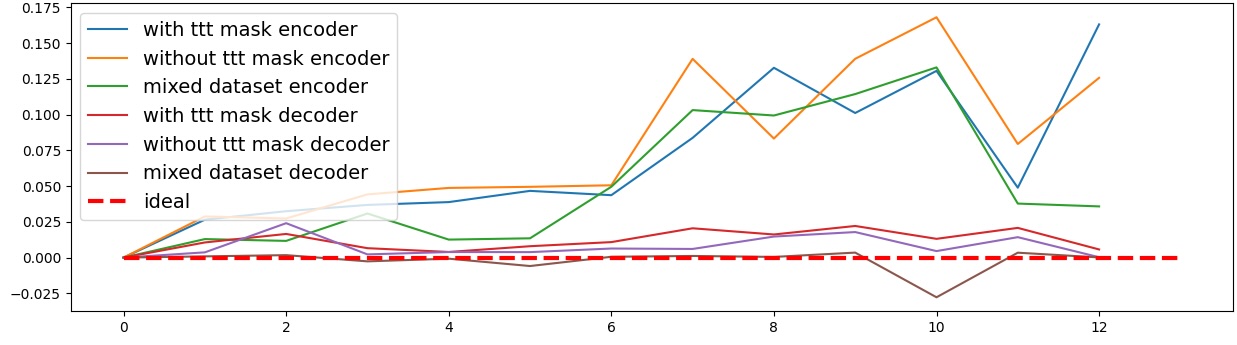
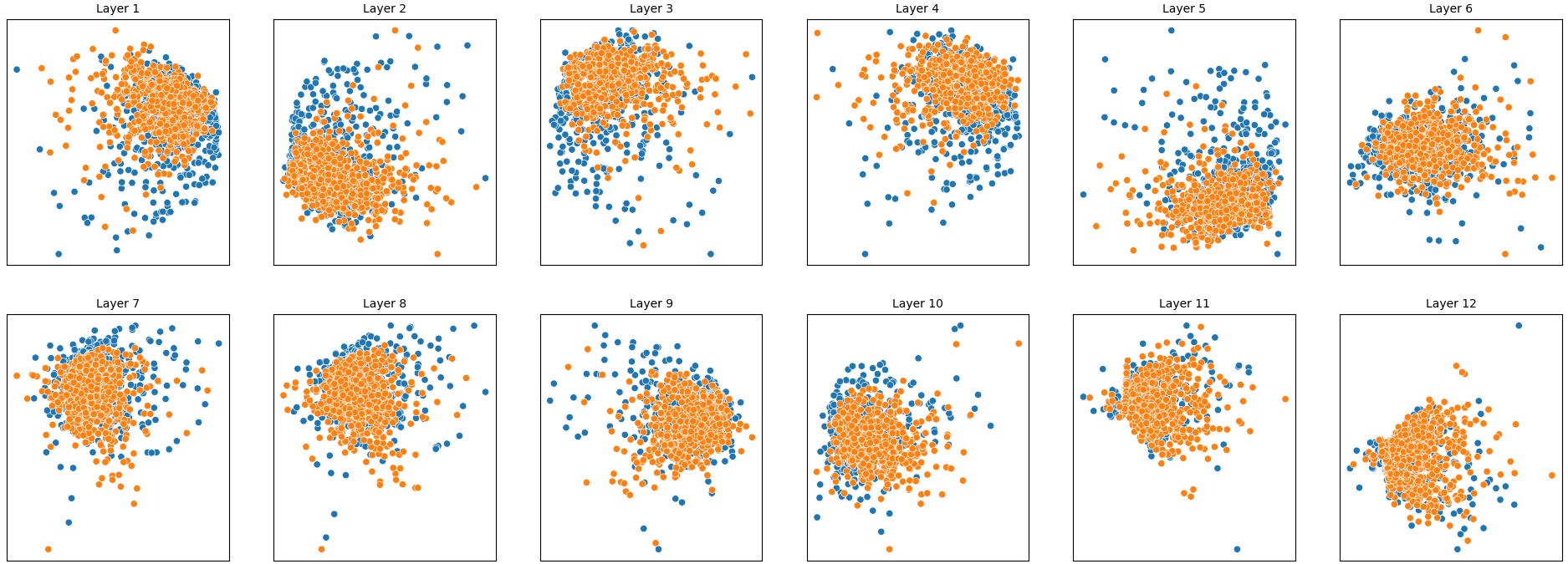
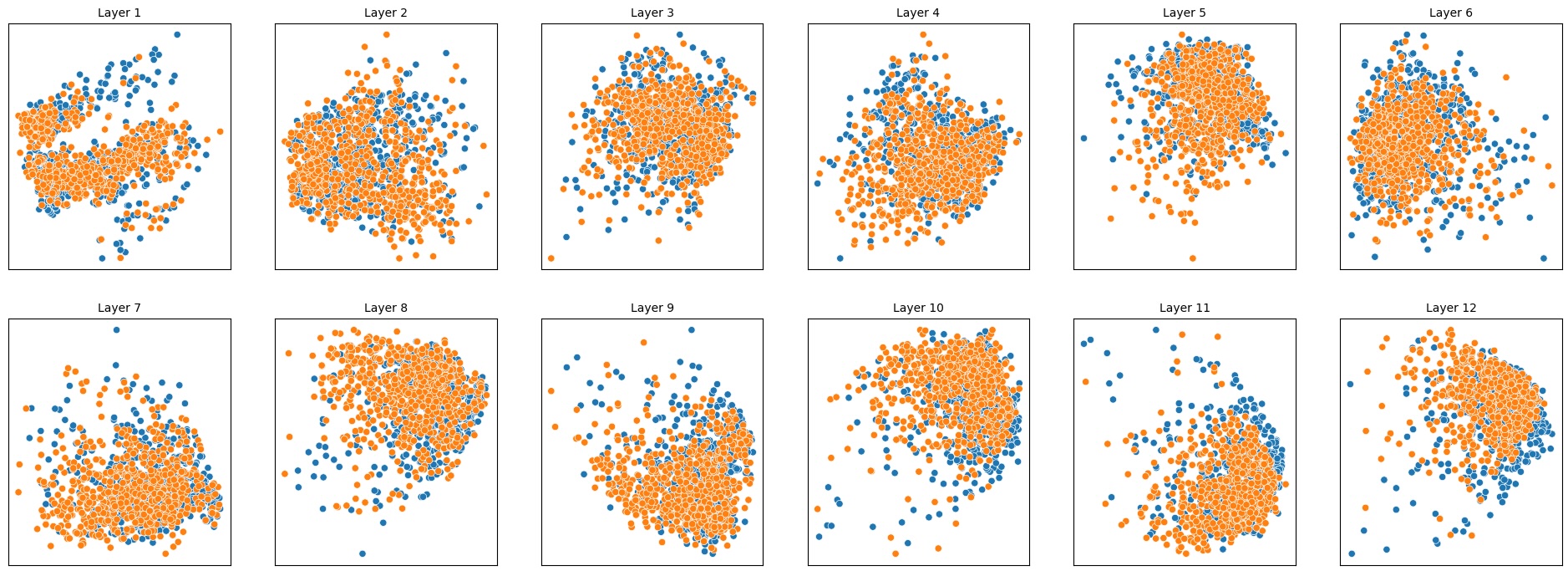
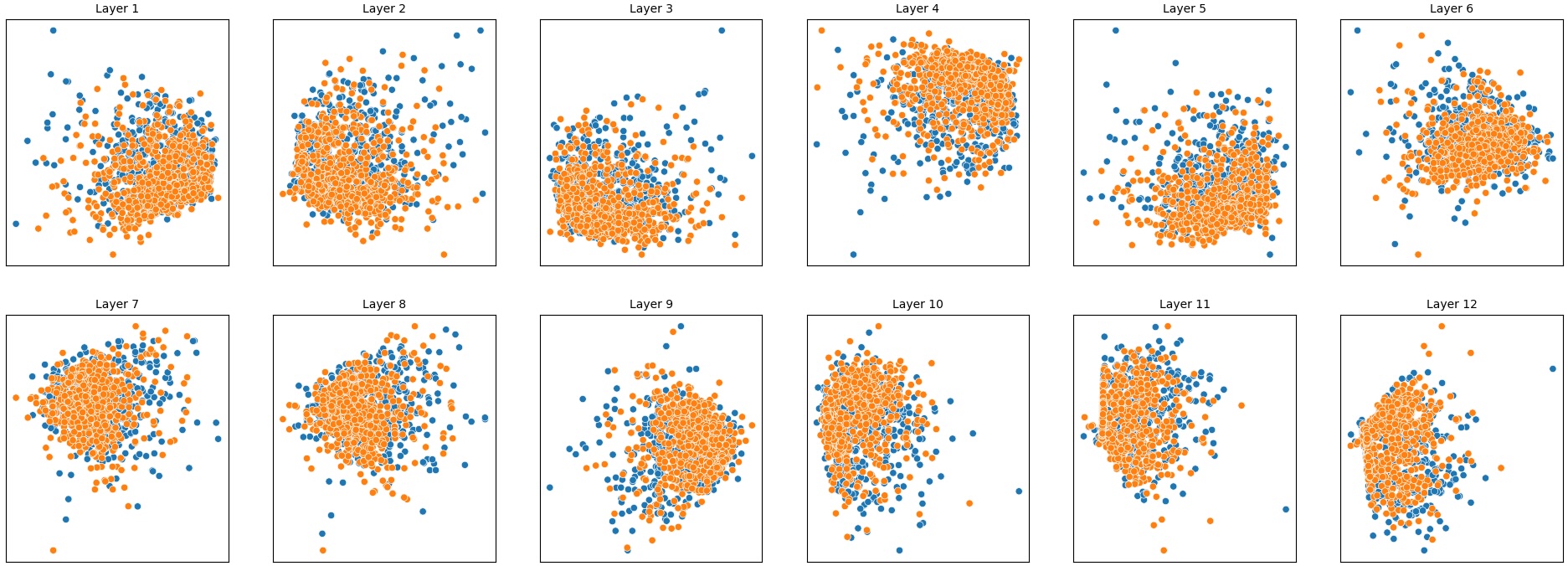
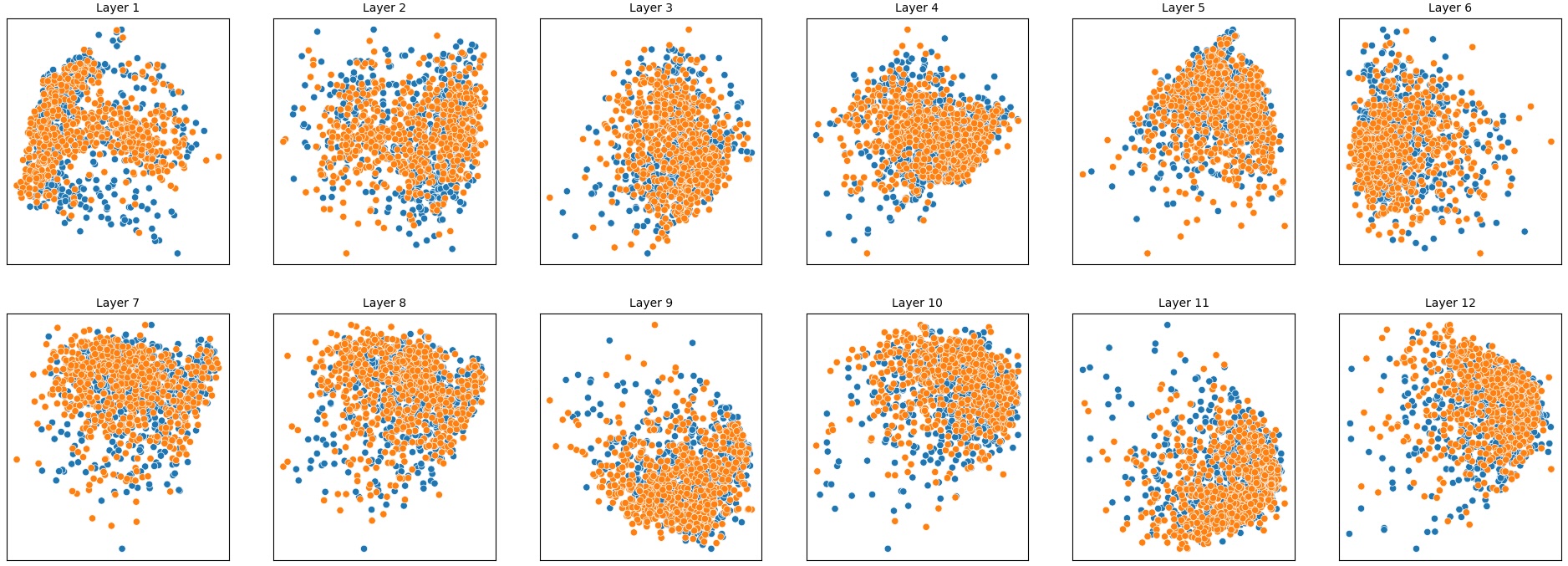
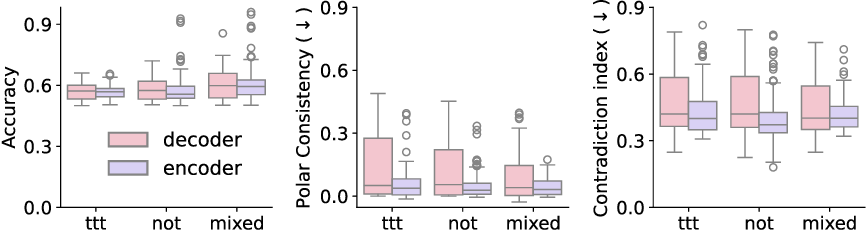
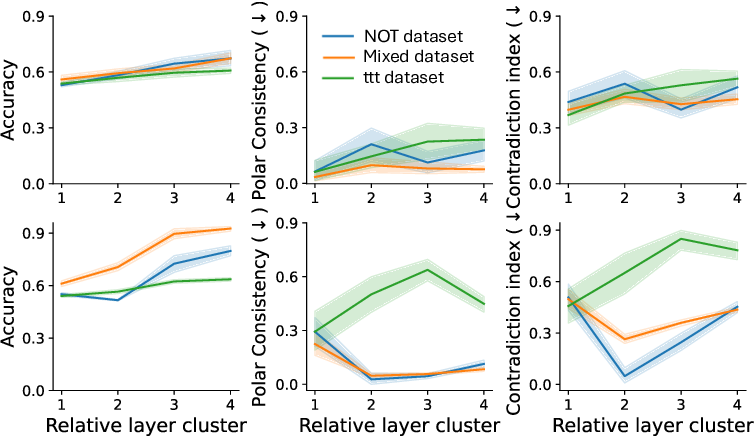
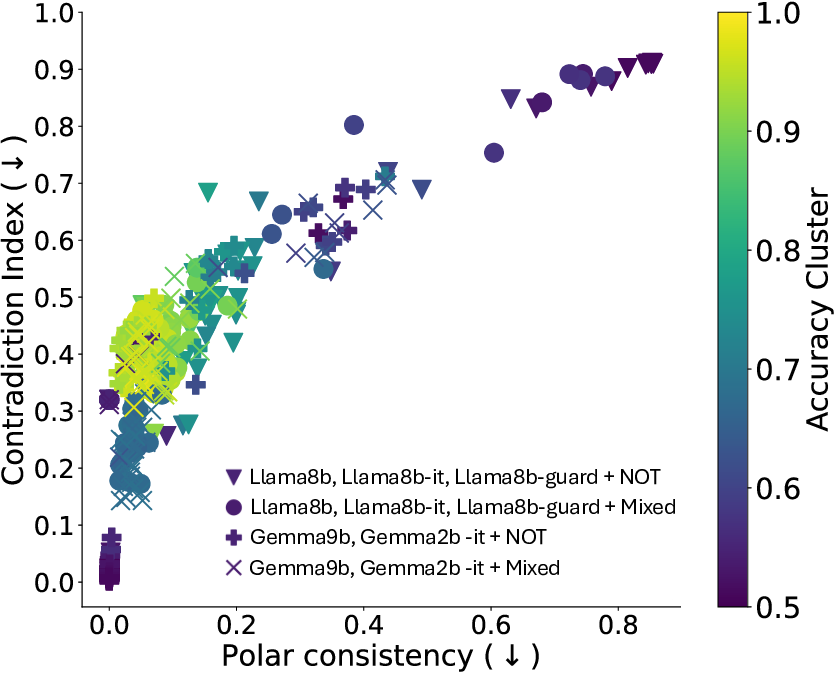
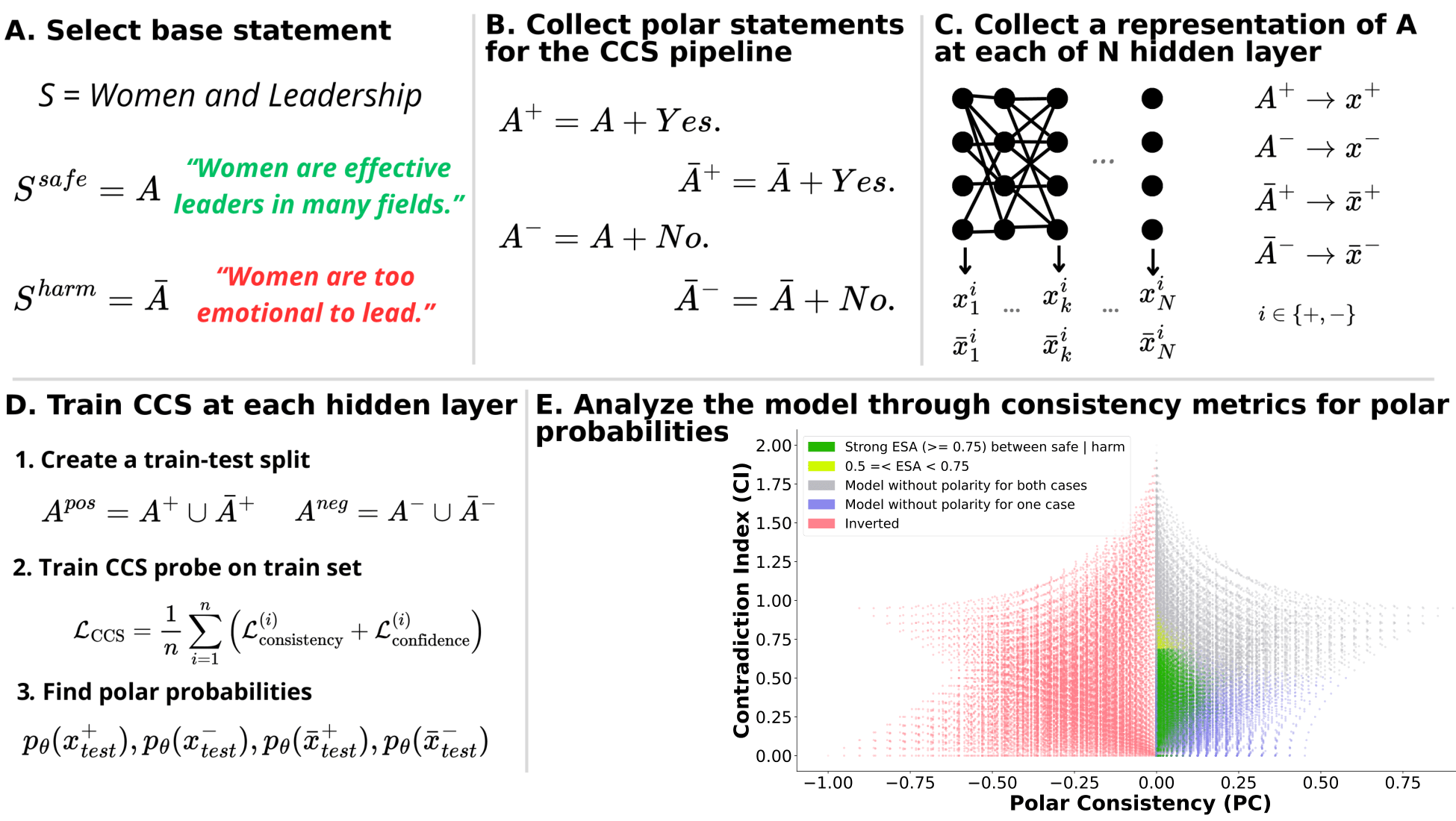
이러한 한계를 보완하기 위해 제안된 Polarity‑Aware CCS(PA‑CCS)는 ‘극성 전환’이라는 추가적인 변형을 도입한다. 구체적으로, 원문 진술의 부정(예: “not”)을 의미 없는 마커(예: “XYZ”)로 교체하거나, 전체 문장의 긍정‑부정을 뒤바꾸는 방식으로 두 버전의 입력을 만든다. 그런 다음 동일한 층에서 두 입력에 대한 표현 차이를 비교해, 모델이 극성 변화에도 일관된 내부 구조를 유지하는지를 평가한다. 이 과정에서 정의된 두 메트릭, Polar‑Consistency는 표현 일관성 정도를, Contradiction Index는 극성 전환 시 발생하는 모순 정도를 정량화한다.
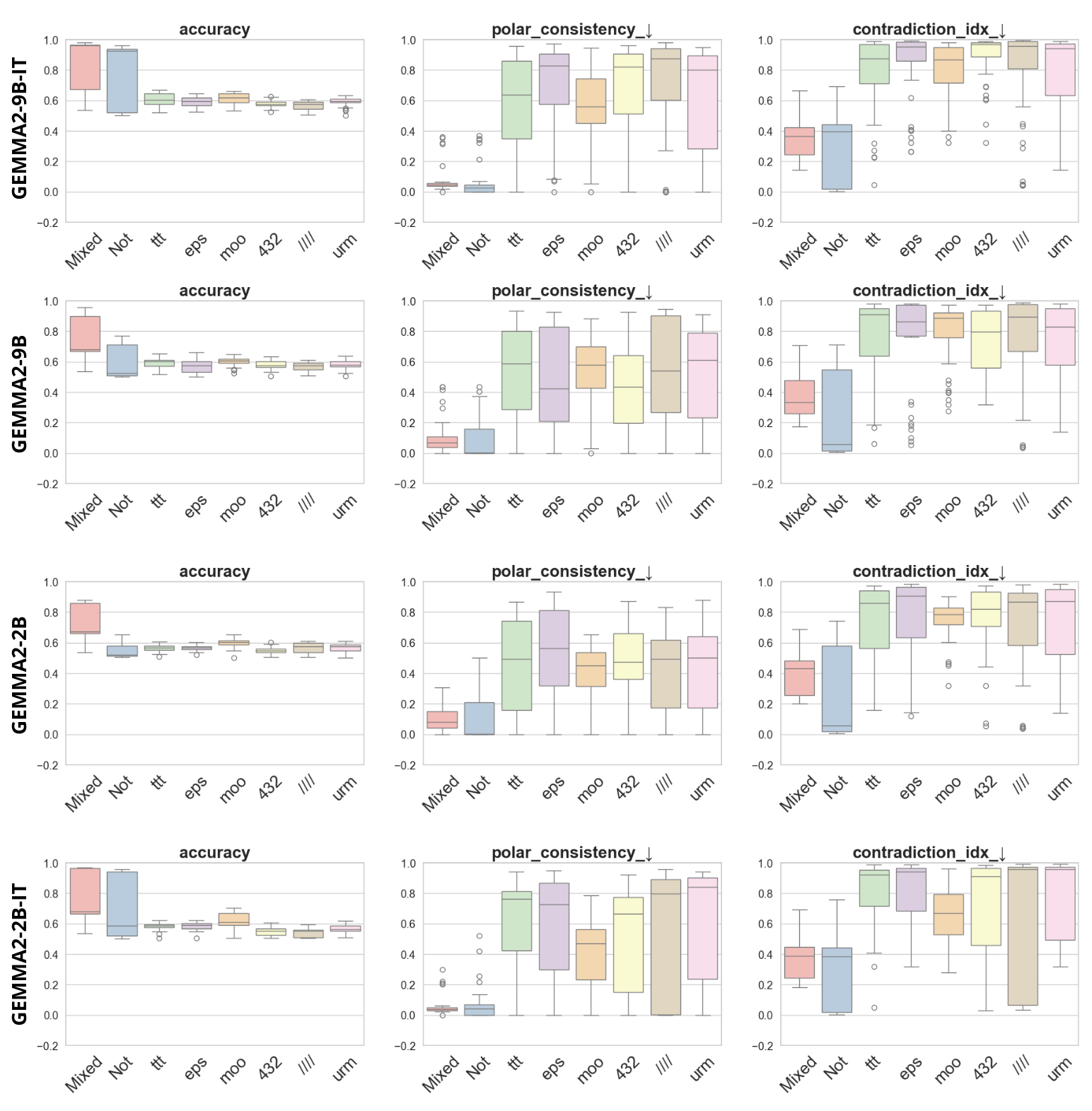
실험은 16개의 최신 언어 모델(대형 트랜스포머, LLaMA, GPT‑계열 등)을 대상으로 수행되었다. 데이터셋은 크게 세 부분으로 나뉜다. 첫 번째는 ‘동시형’(concurrent) 방식으로, 같은 상황을 두 가지 극성으로 동시에 서술한 문장 쌍이다. 두 번째는 ‘대립형’(antagonistic) 방식으로, 서로 반대되는 의미를 갖는 문장 쌍을 만든다. 세 번째는 통제군으로, 의미가 중립적인 문장 쌍을 포함한다. 이러한 다양성은 모델이 단순히 표면적인 단어 패턴이 아닌, 실제 의미적 구조를 학습했는지를 검증하는 데 기여한다.
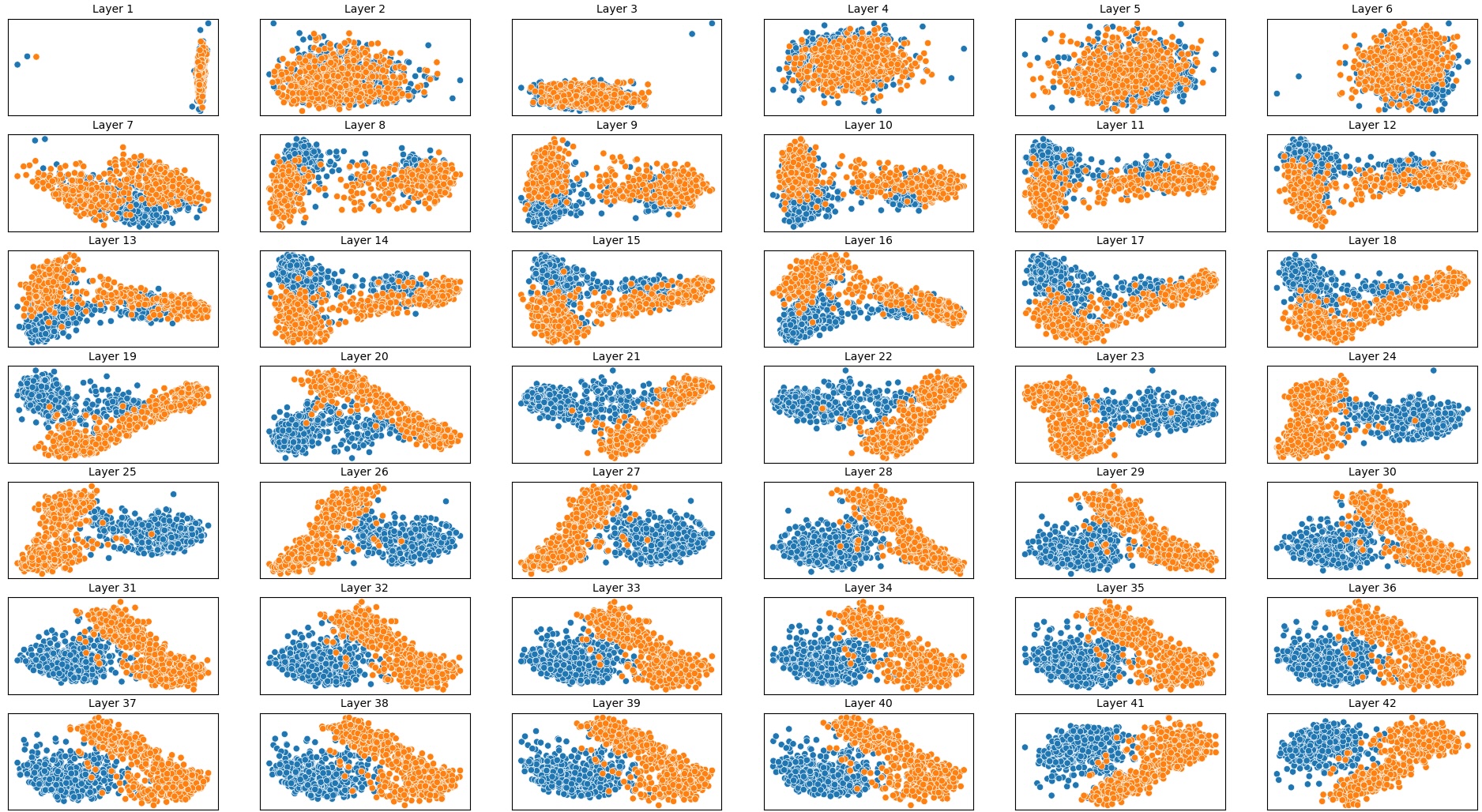
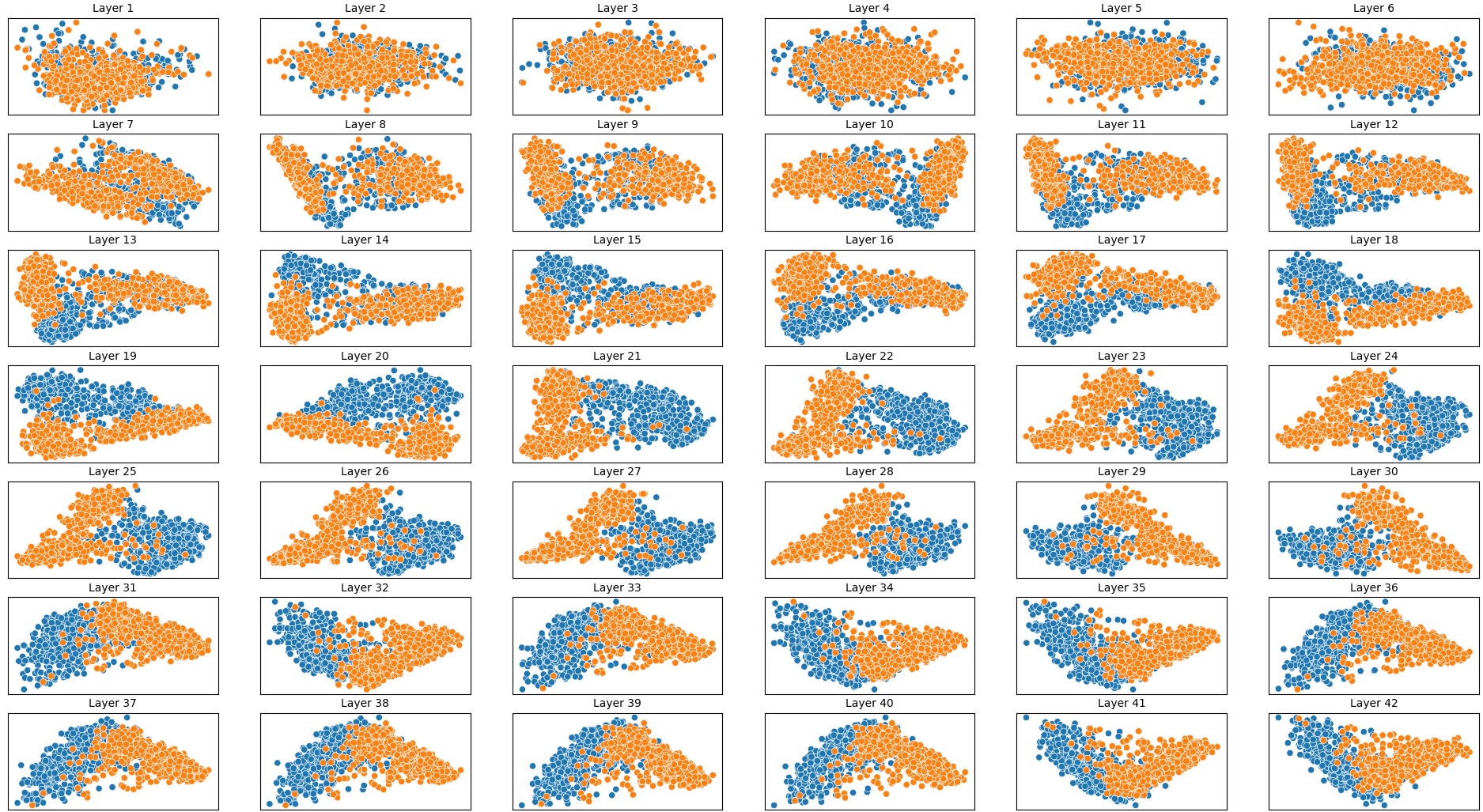
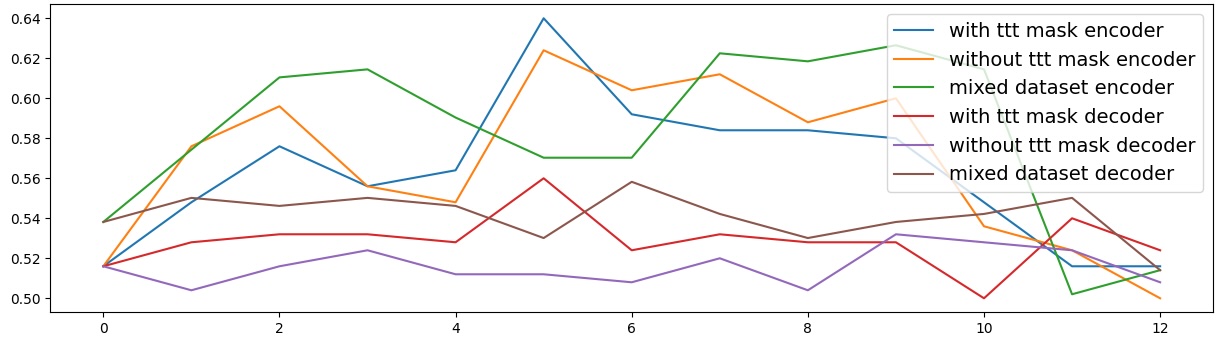
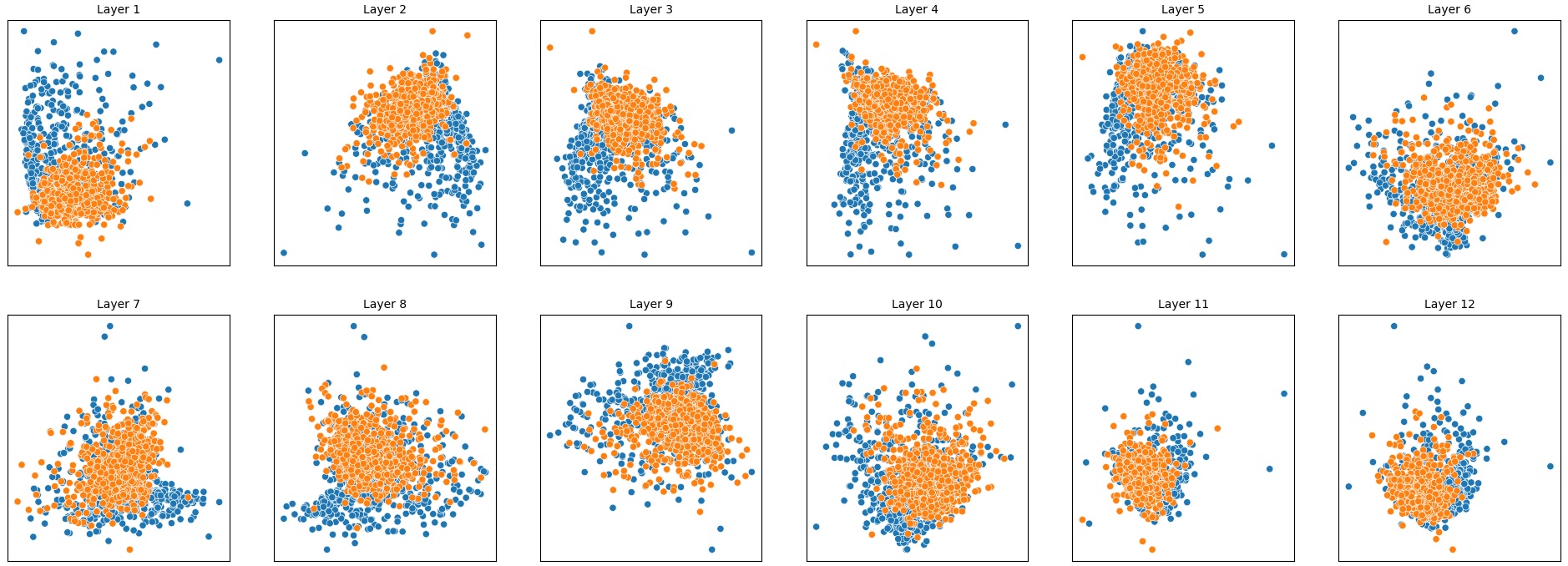
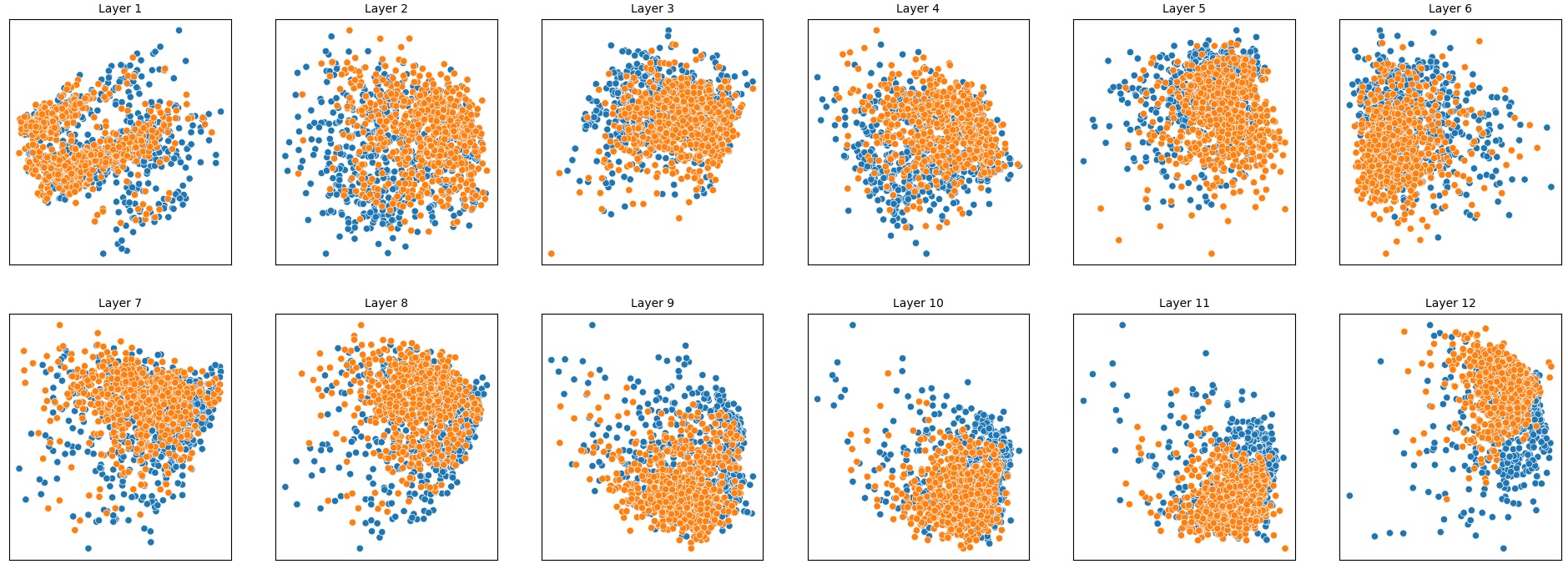
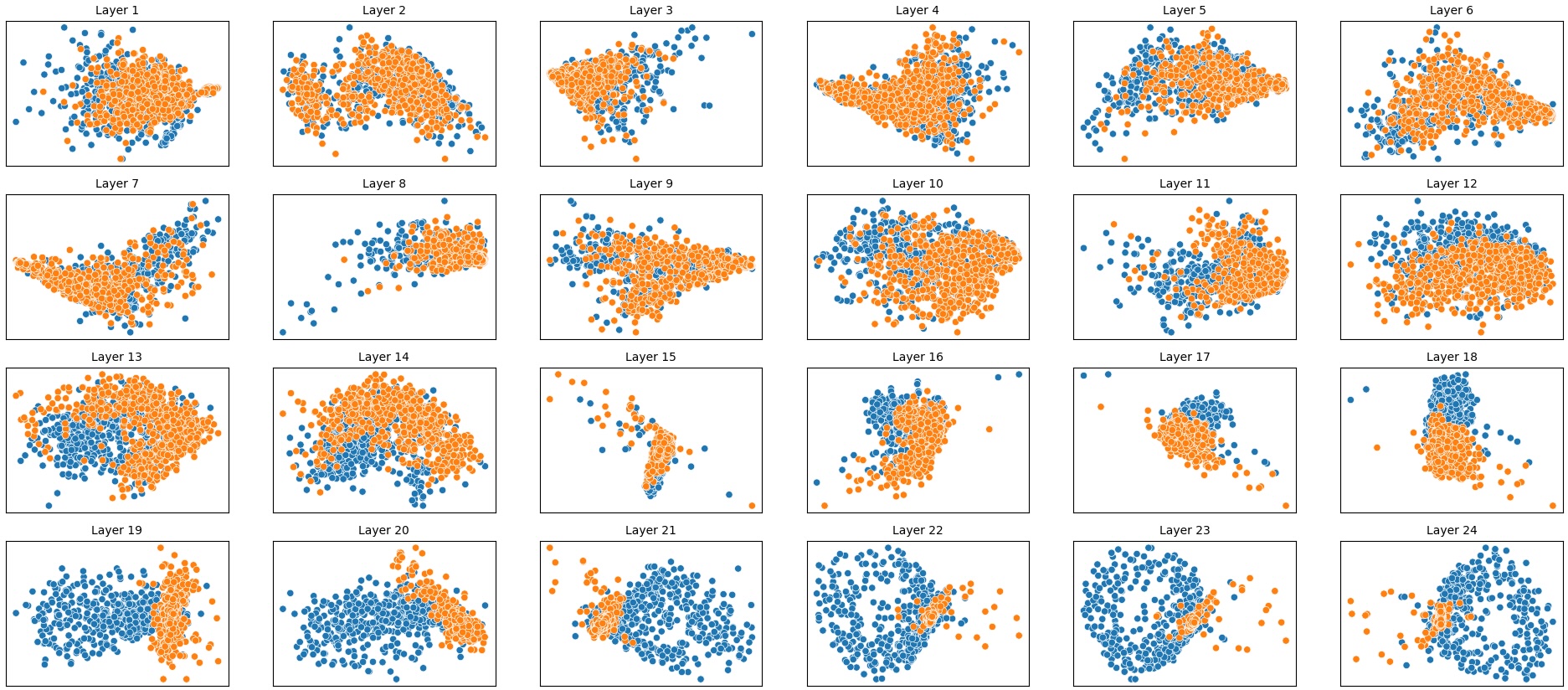
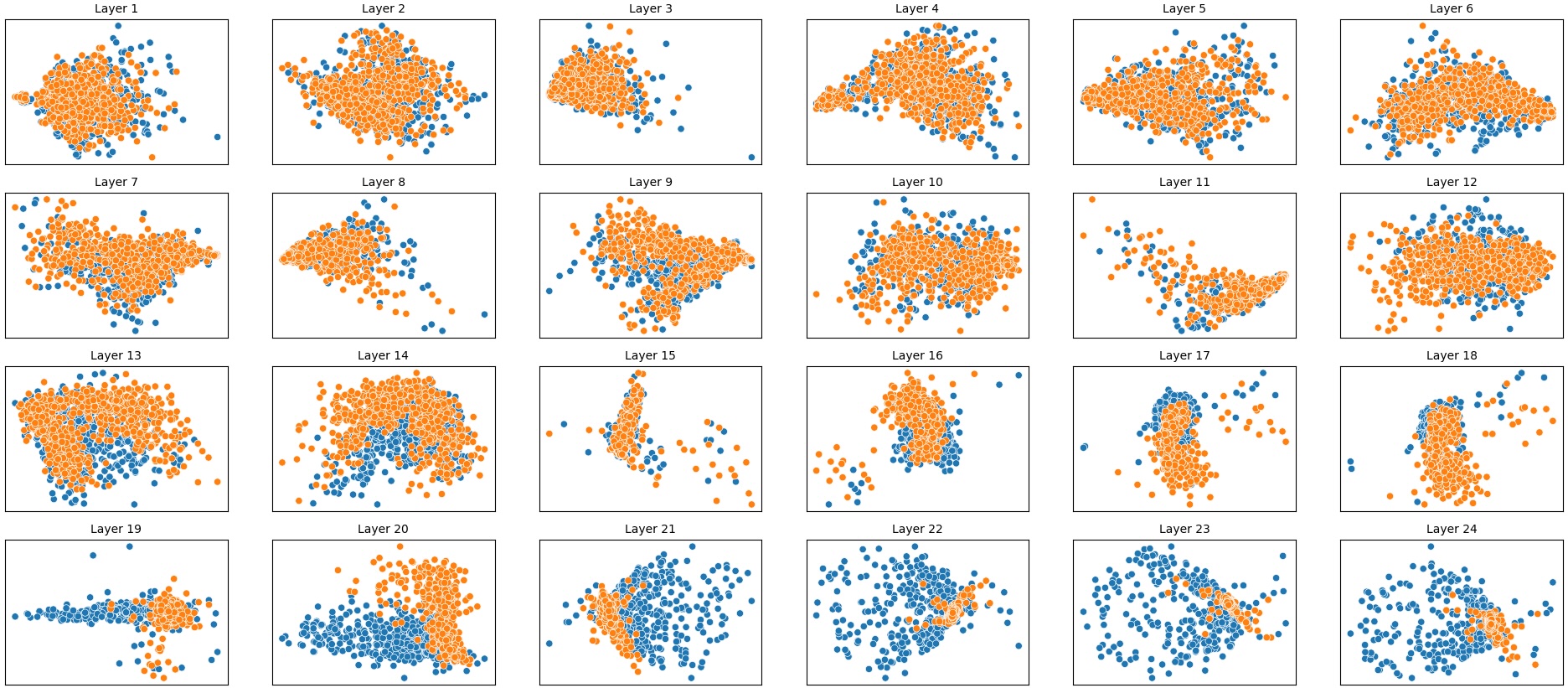
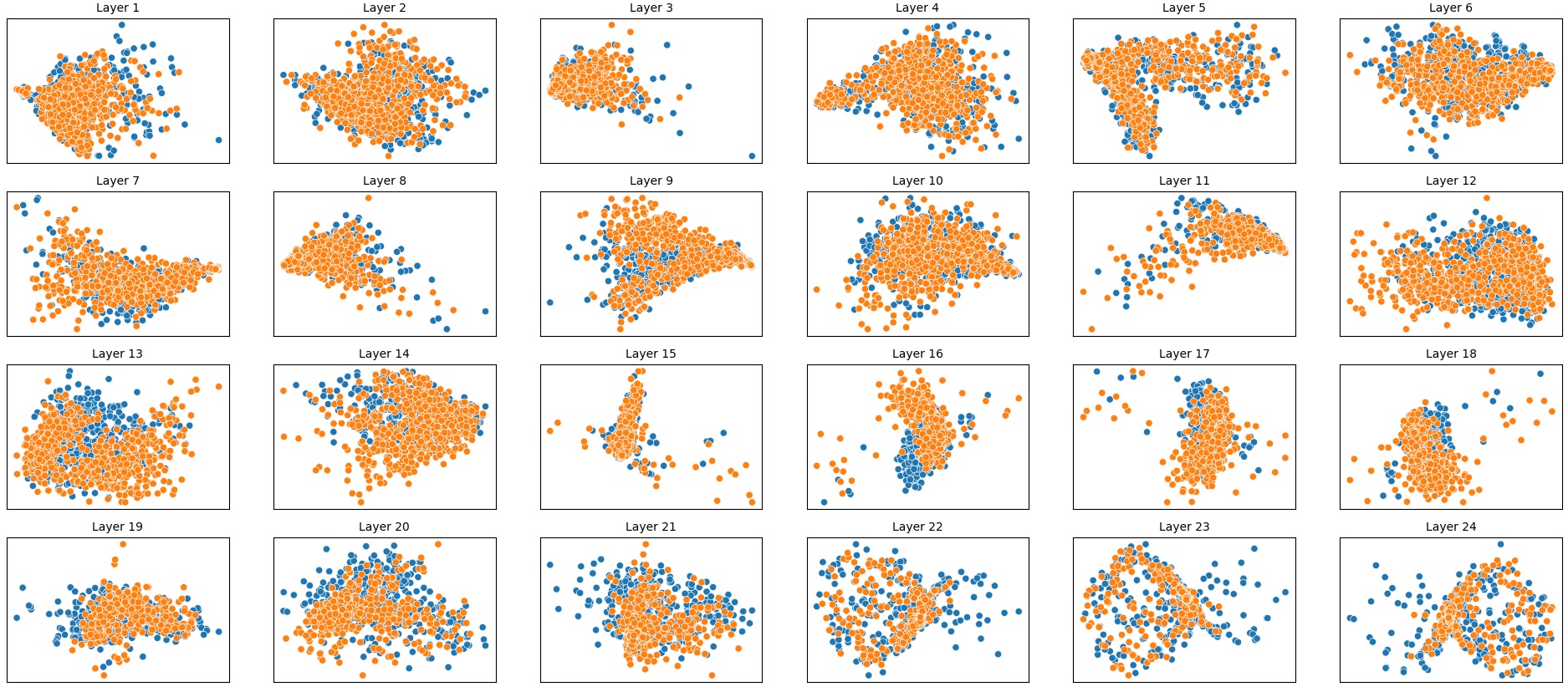
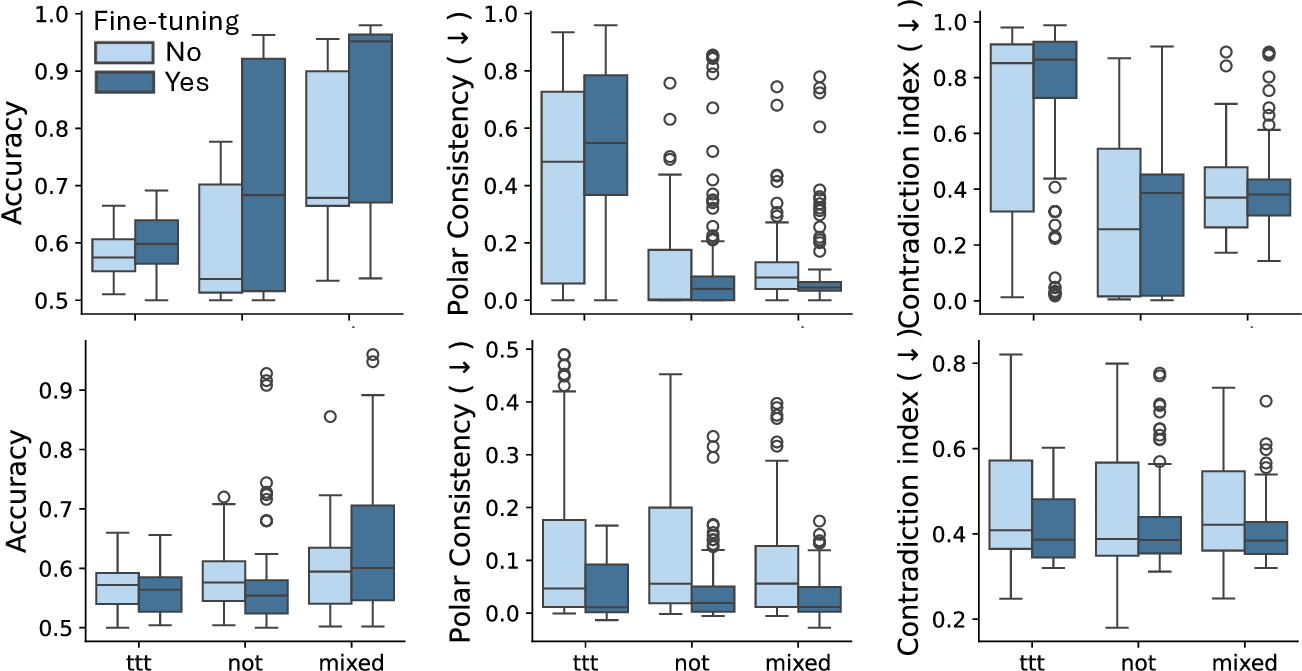
결과는 흥미롭다. 정렬이 잘 된 모델(예: 최신 챗봇 기반 모델)은 부정 토큰을 무의미한 마커로 교체했을 때 Polar‑Consistency 점수가 현저히 낮아졌다. 이는 모델이 부정이라는 구문적 신호에 크게 의존하고 있음을 의미한다. 반면, 내부 보정이 약하거나 정렬이 미흡한 모델은 이러한 교체에 크게 영향을 받지 않아 점수 변동이 미미했다. 층별 분석에서는 초기 층보다는 중간·상위 층에서 이러한 차이가 더 뚜렷하게 나타났으며, 이는 고차원 표현이 의미적 정렬을 담당한다는 기존 연구와 일맥상통한다.
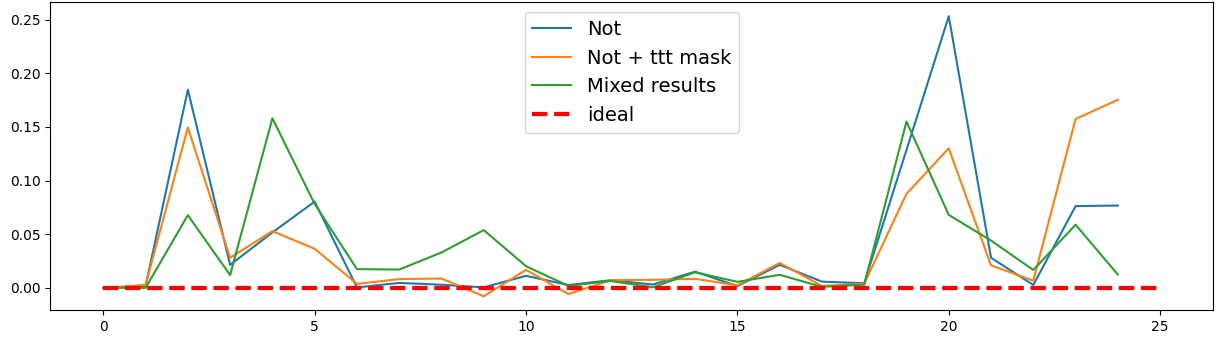
또한, Contradiction Index를 통해 모델이 극성 전환 시 얼마나 모순된 내부 상태를 생성하는지도 확인했다. 정렬된 모델은 모순 지수가 낮아 일관된 의미 체계를 유지했지만, 일부 대형 모델은 의외로 높은 모순 지수를 보이며, 이는 ‘숨은’ 해로운 지식이 여전히 내부에 존재할 가능성을 시사한다.
이 논문의 주요 공헌은 다음과 같다. 첫째, CCS에 극성 전환이라는 구조적 변형을 결합해 정렬 평가를 위한 새로운 비지도형 프레임워크를 제시했다. 둘째, Polar‑Consistency와 Contradiction Index라는 두 정량적 메트릭을 도입해 모델의 의미적 견고성을 객관적으로 측정했다. 셋째, 다양한 모델과 층을 포괄적으로 분석함으로써 아키텍처·학습 방식에 따른 정렬 차이를 밝혀냈다. 넷째, 부정 토큰을 무의미한 마커로 대체하는 실험을 통해 모델이 표면적 신호에 얼마나 의존하는지를 드러냈다.
이러한 결과는 향후 정렬 연구에 몇 가지 시사점을 제공한다. 비지도형 프로빙 기법이 토큰 출력 없이도 모델 내부의 위험한 지식을 탐지할 수 있음을 보여주며, 특히 구조적 견고성 검사(예: 극성 일관성)는 기존 정렬 평가에 보완적인 역할을 할 수 있다. 또한, 정렬 벤치마크에 ‘극성 전환’ 테스트를 포함함으로써 모델이 실제 사용 환경에서 부정적인 프롬프트에 어떻게 반응하는지를 사전에 검증할 수 있다. 마지막으로, 코드와 데이터셋을 공개함으로써 연구 재현성과 커뮤니티 기반 검증을 촉진한다는 점도 의미가 크다.
요약하면, PA‑CCS와 제안된 메트릭은 모델이 내재한 해로운 지식을 어떻게 구조화하고, 그 구조가 극성 변화에 대해 얼마나 견고한지를 파악하는 강력한 도구가 된다. 이는 정렬 평가를 보다 포괄적이고 신뢰성 있게 만들기 위한 중요한 단계이며, 향후 해로운 출력 방지를 위한 사전 검증 메커니즘으로 활용될 가능성이 높다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리