신호 SGN++: 에너지 효율적인 동작 인식을 위한 위상 인식 스팽킹 그래프 프레임워크
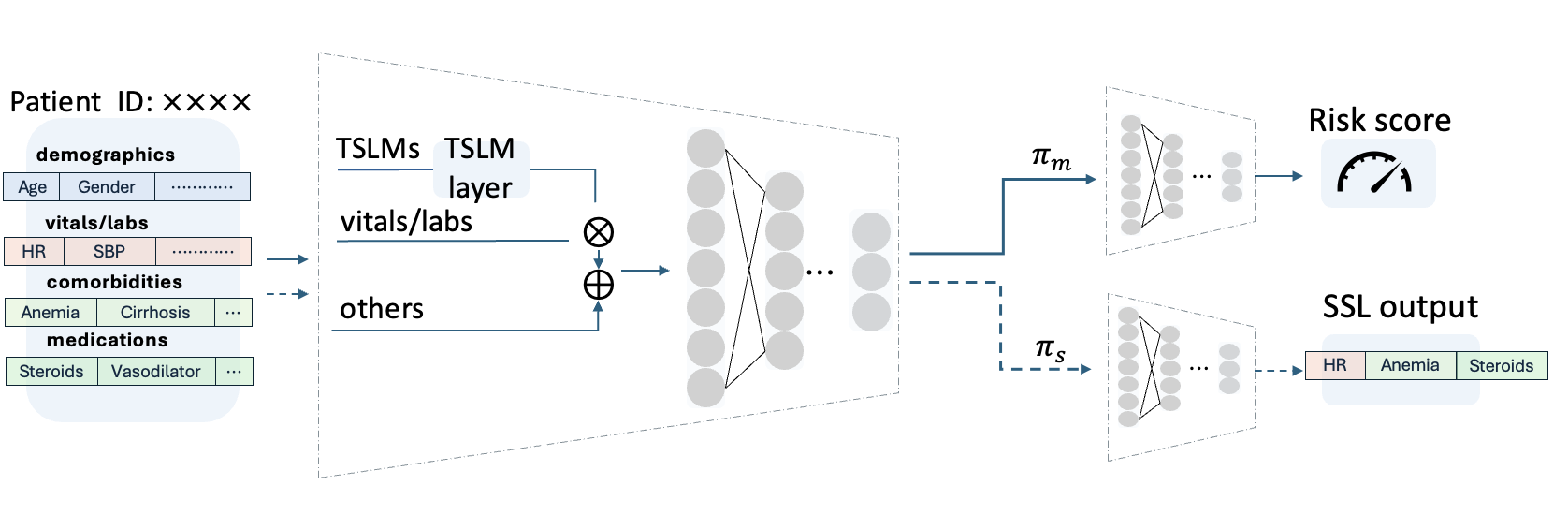
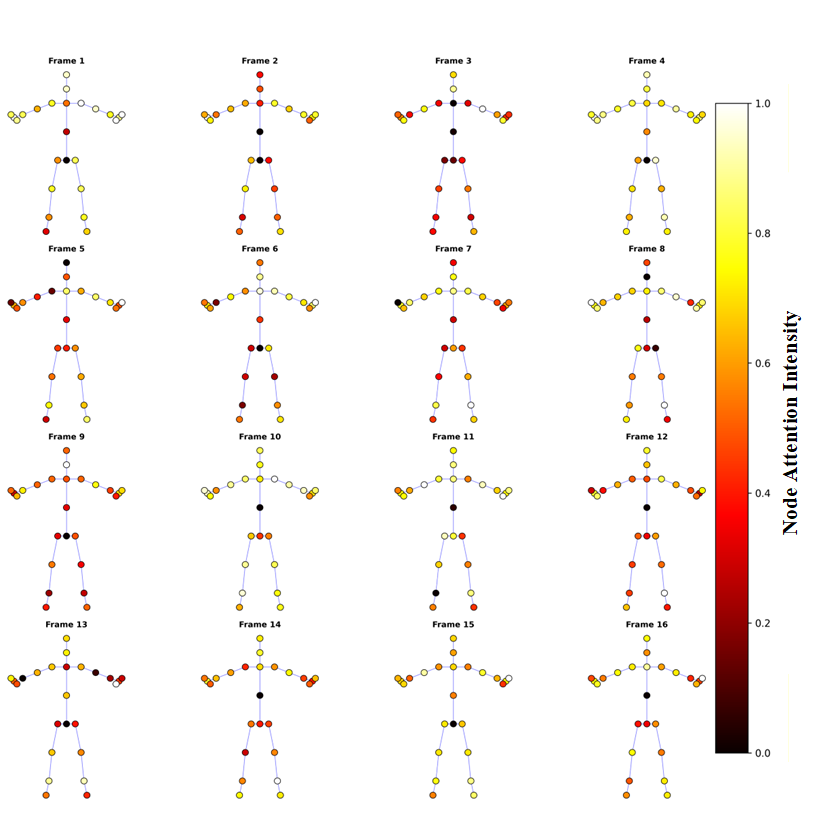
이 논문은 신호 SGN++라는 새로운 프레임워크를 제안하여 그래프 컨볼루션 네트워크(GCNs)와 스팽킹 신경망(SNNs)의 장점을 결합하고자 합니다. GCNs는 관절 구조를 효과적으로 모델링할 수 있지만, 실수 계산에 따른 에너지 소비가 높은 반면, SNNs는 에너지 효율적이지만 인간 동작의 복잡한 시간 주파수 및 위상 의존성을 포착하는 데 한계가 있습니다. 신호 SGN++은 이러한 문제를 해결하기 위해 1D Spiking Graph Convolution(1D SGC)과 Frequency Spiking Convolution(FSC)
Network