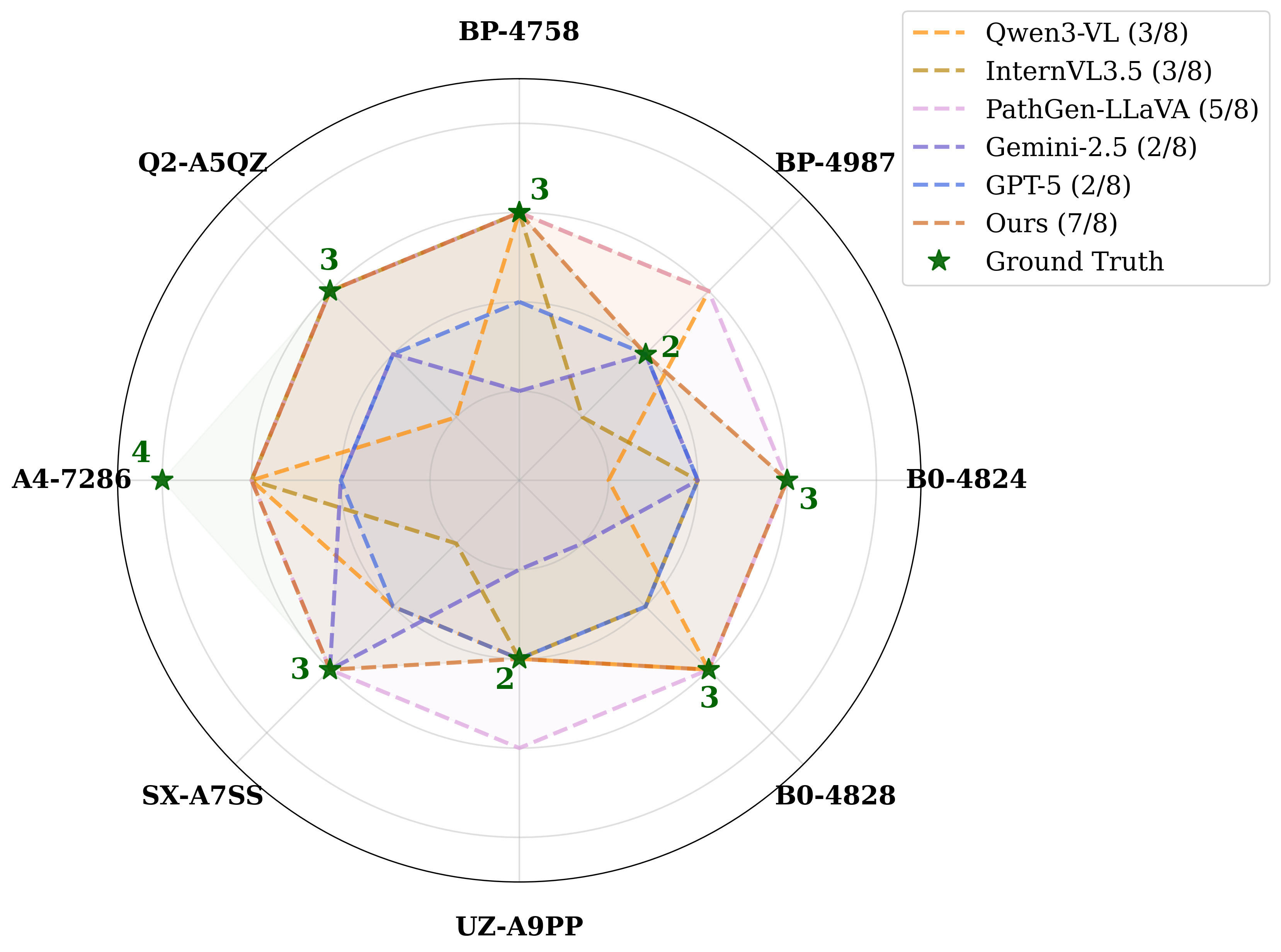
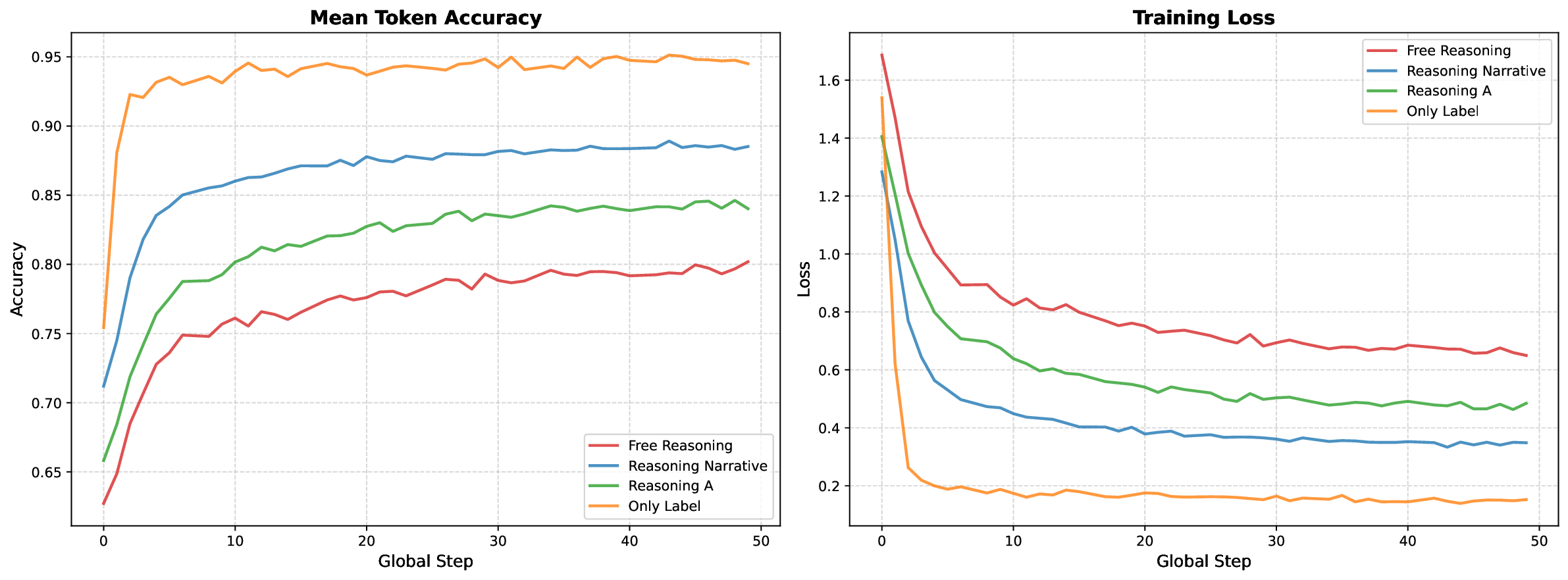
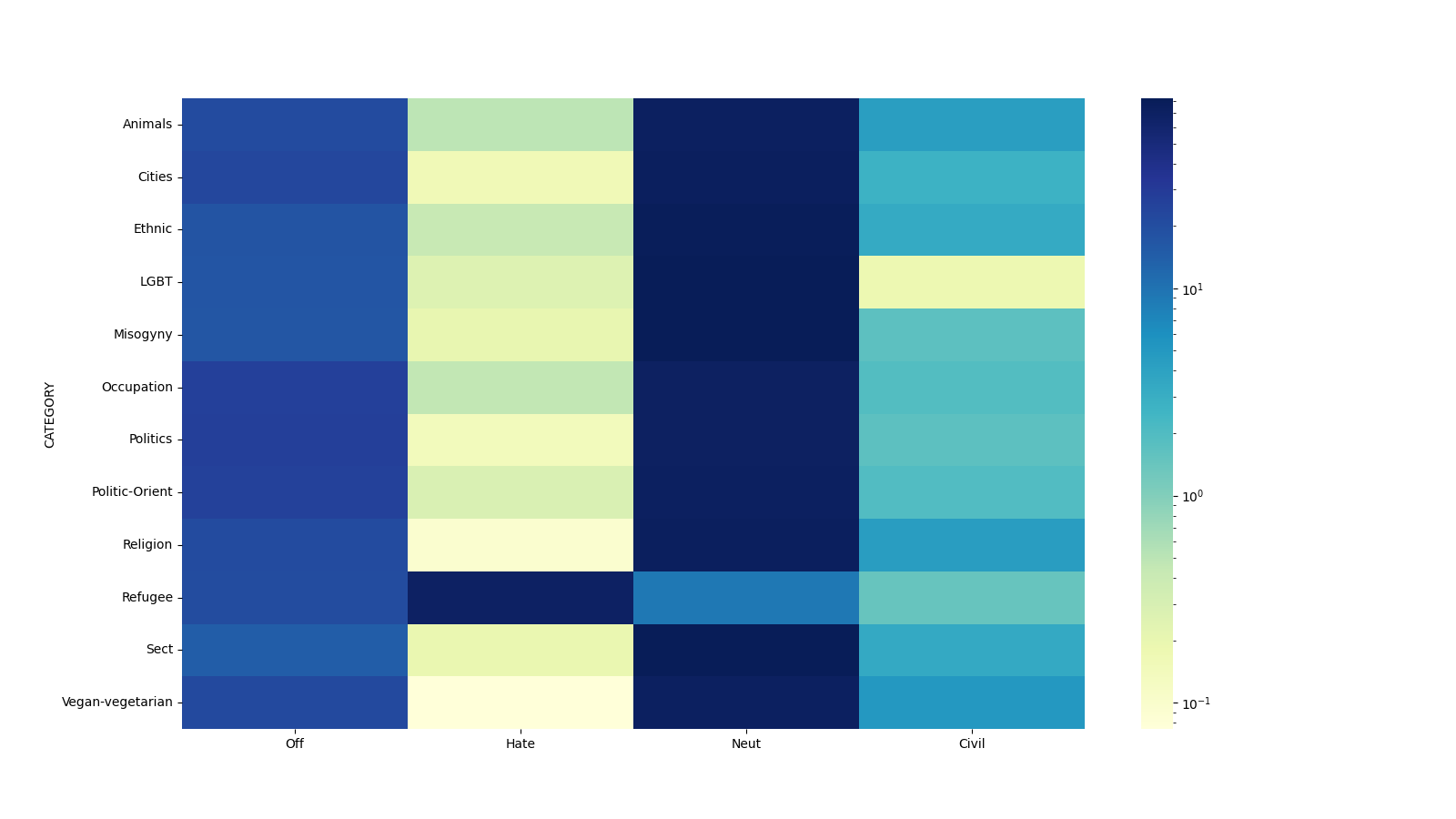
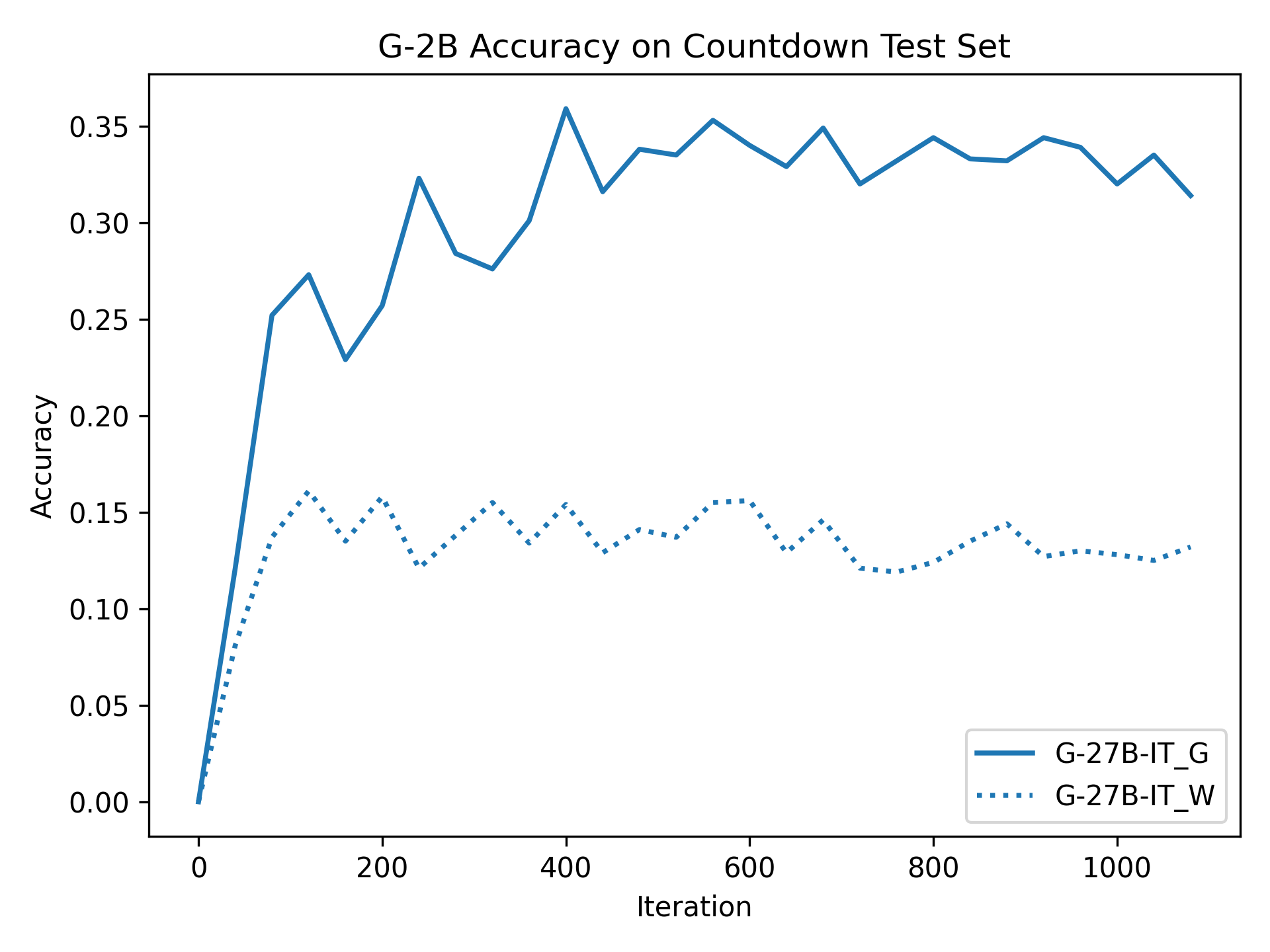
GNU 데이터 언어(GDL)의 현황과 미래
: GDL은 천문학 분야에서 IDL의 무료 대체 소프트웨어로 널리 사용되고 있으며, 다양한 데이터 분석과 시각화 작업에 활용됩니다. GDL의 주요 특징 중 하나는 IDL과의 완벽한 문법 호환성으로, 기존 IDL 코드를 쉽게 GDL에서 실행할 수 있다는 점입니다. 이로 인해 천문학자들은 비용 부담 없이 고급 데이터 분석 및 시각화 작업을 수행할 수 있습니다. GDL은 다양한 플랫폼에서 실행 가능하며, Linux, BSD, Mac OSX, OpenSolaris 등 주요 운영 체제를 지원합니다. 또한, 여러 운영 체제에 대한 사전 컴파일
Computer Science
Data
Computational Engineering
Astrophysics