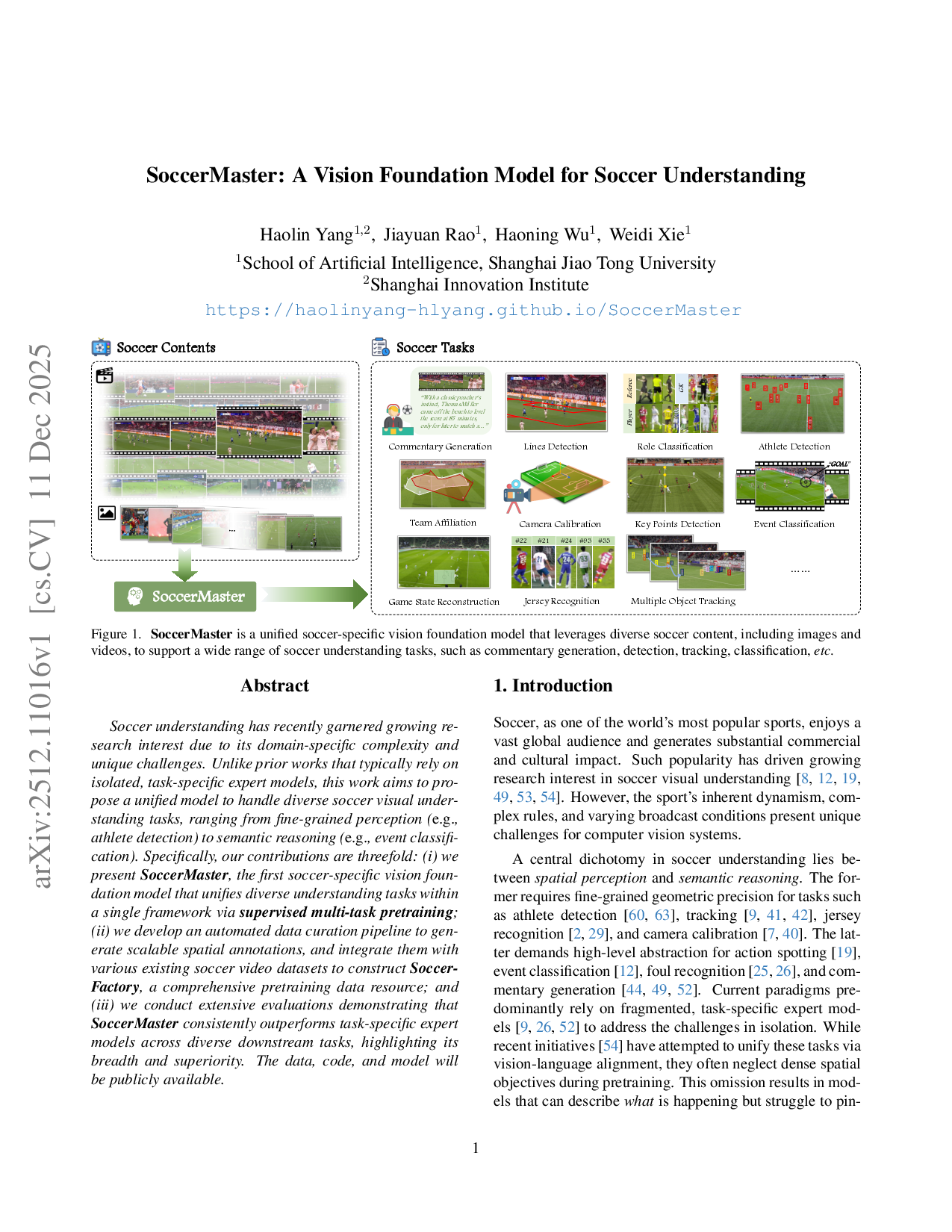
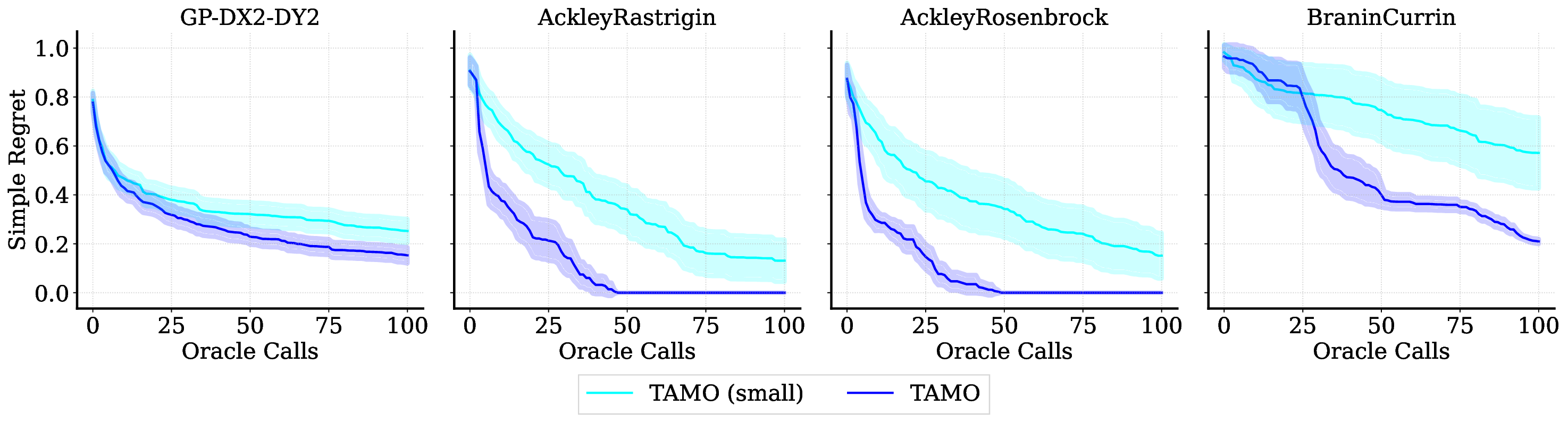
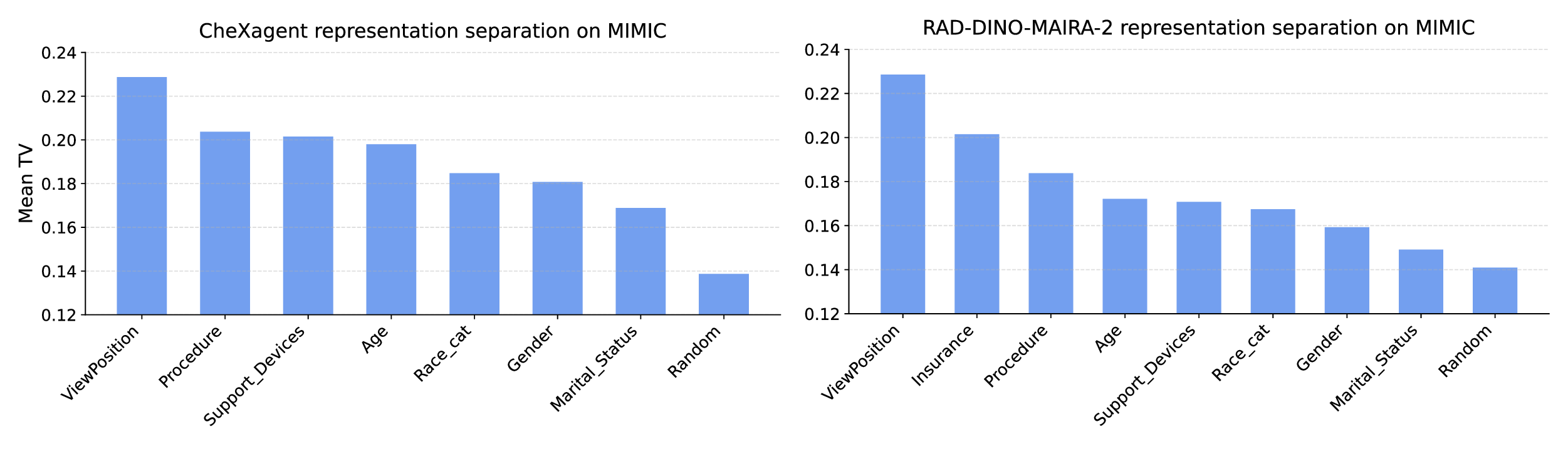
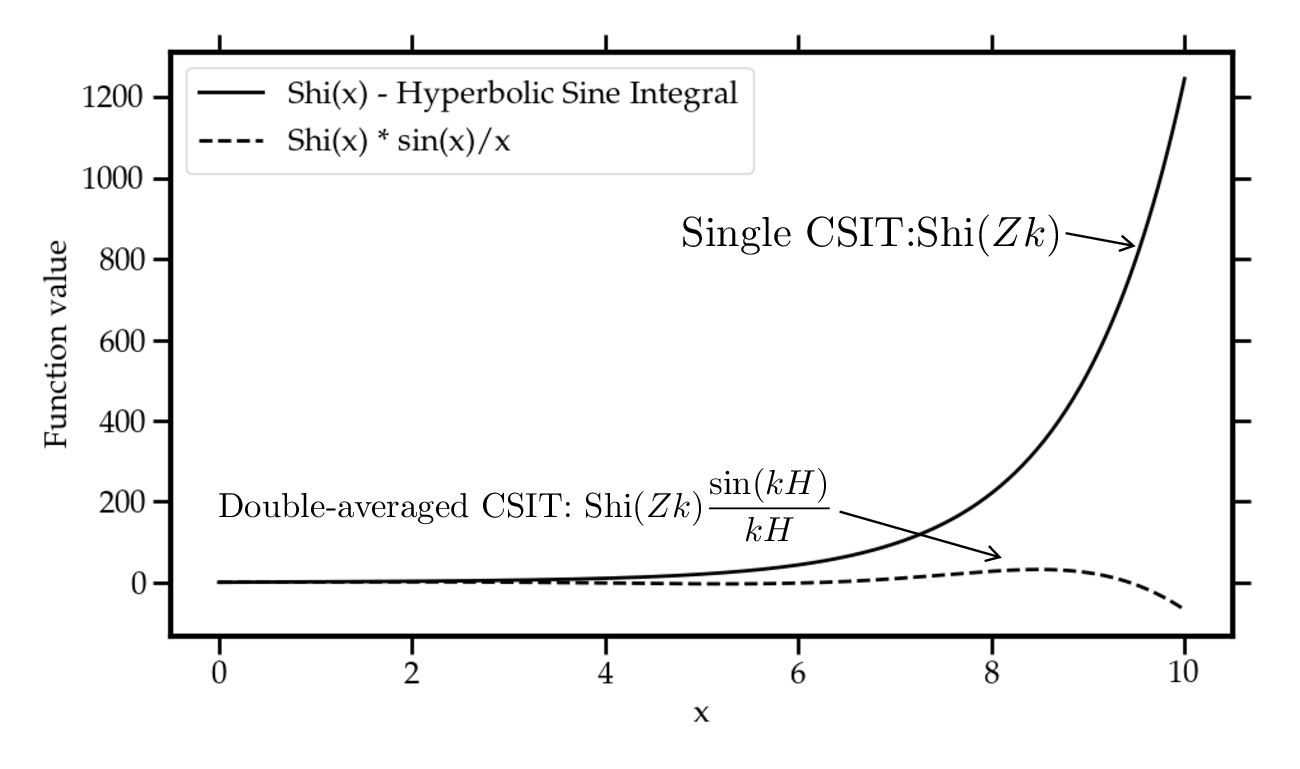
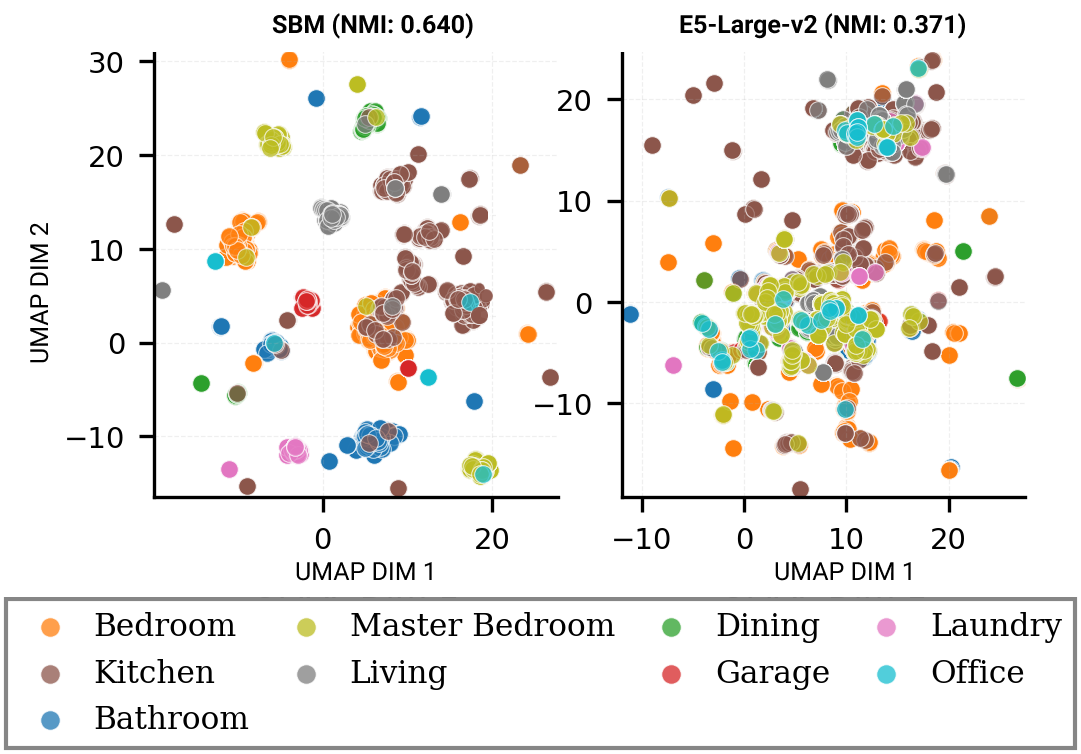
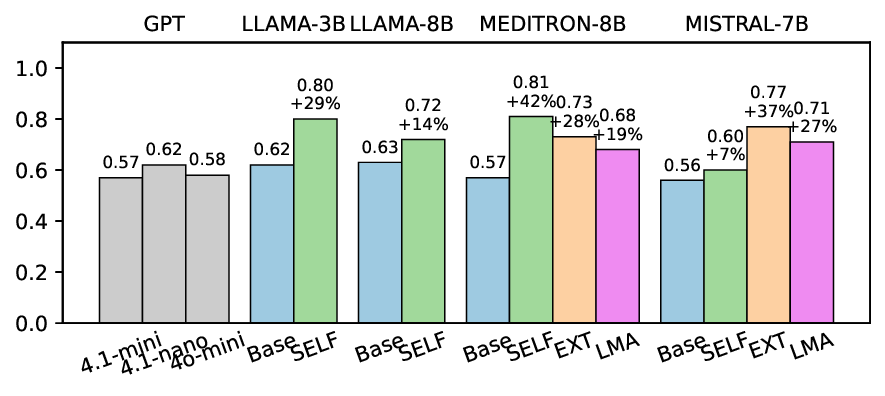
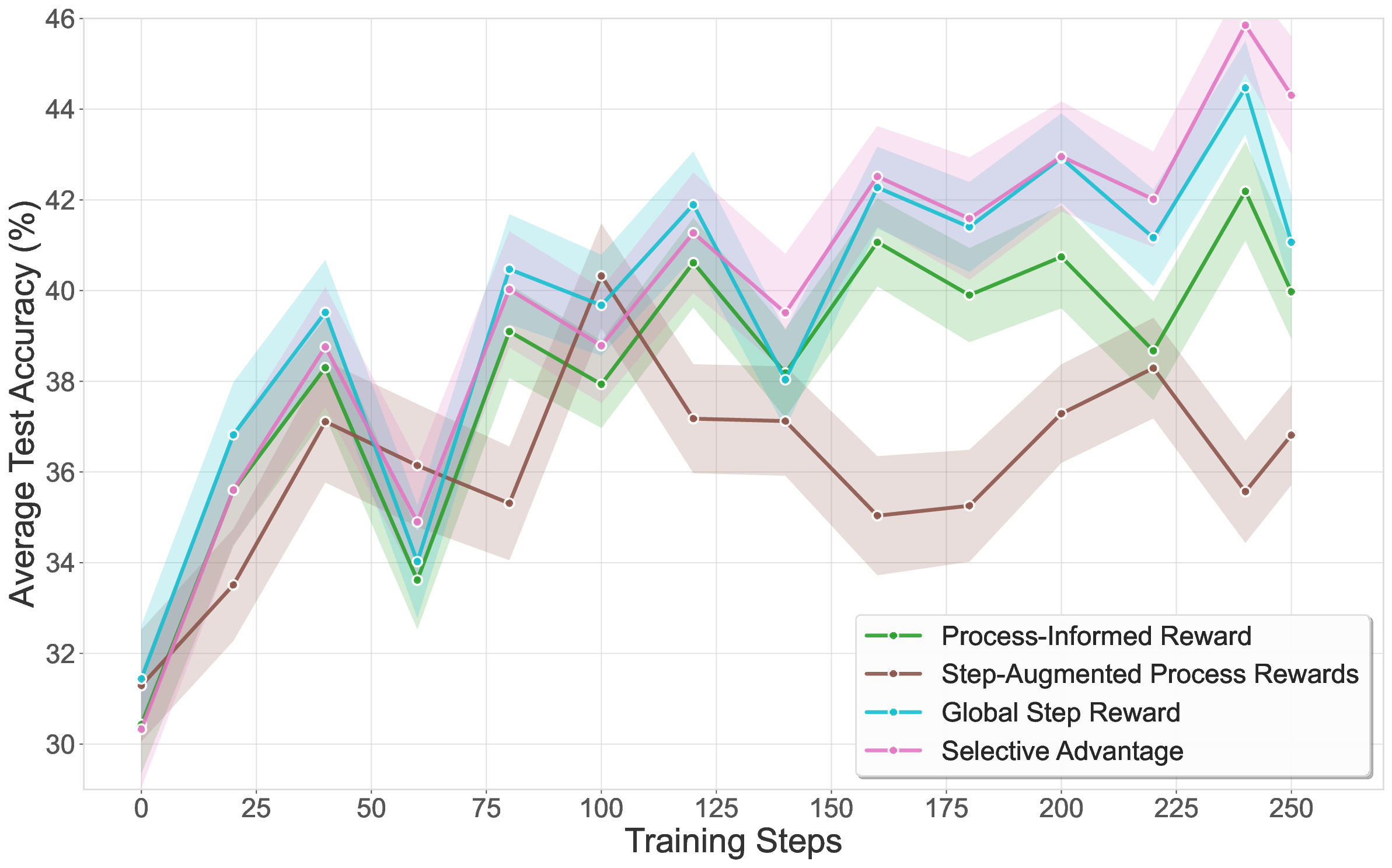
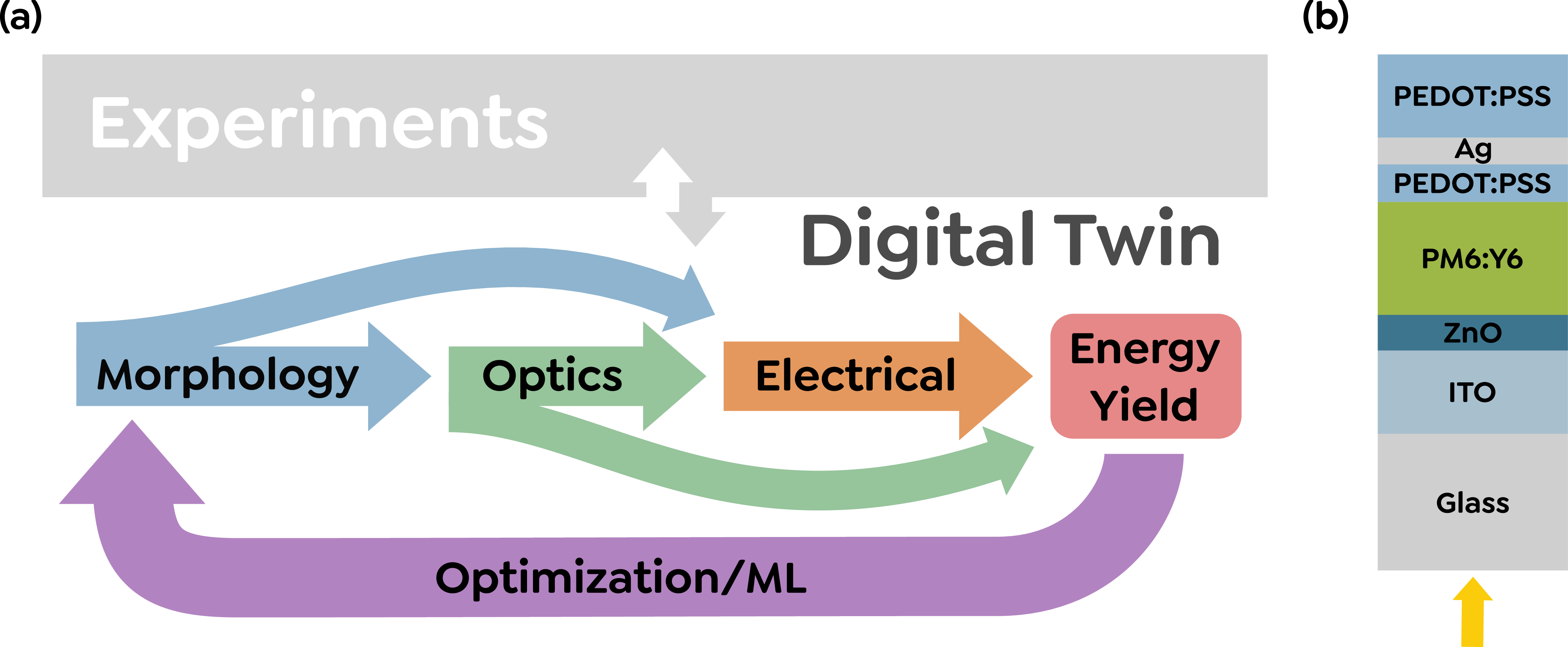
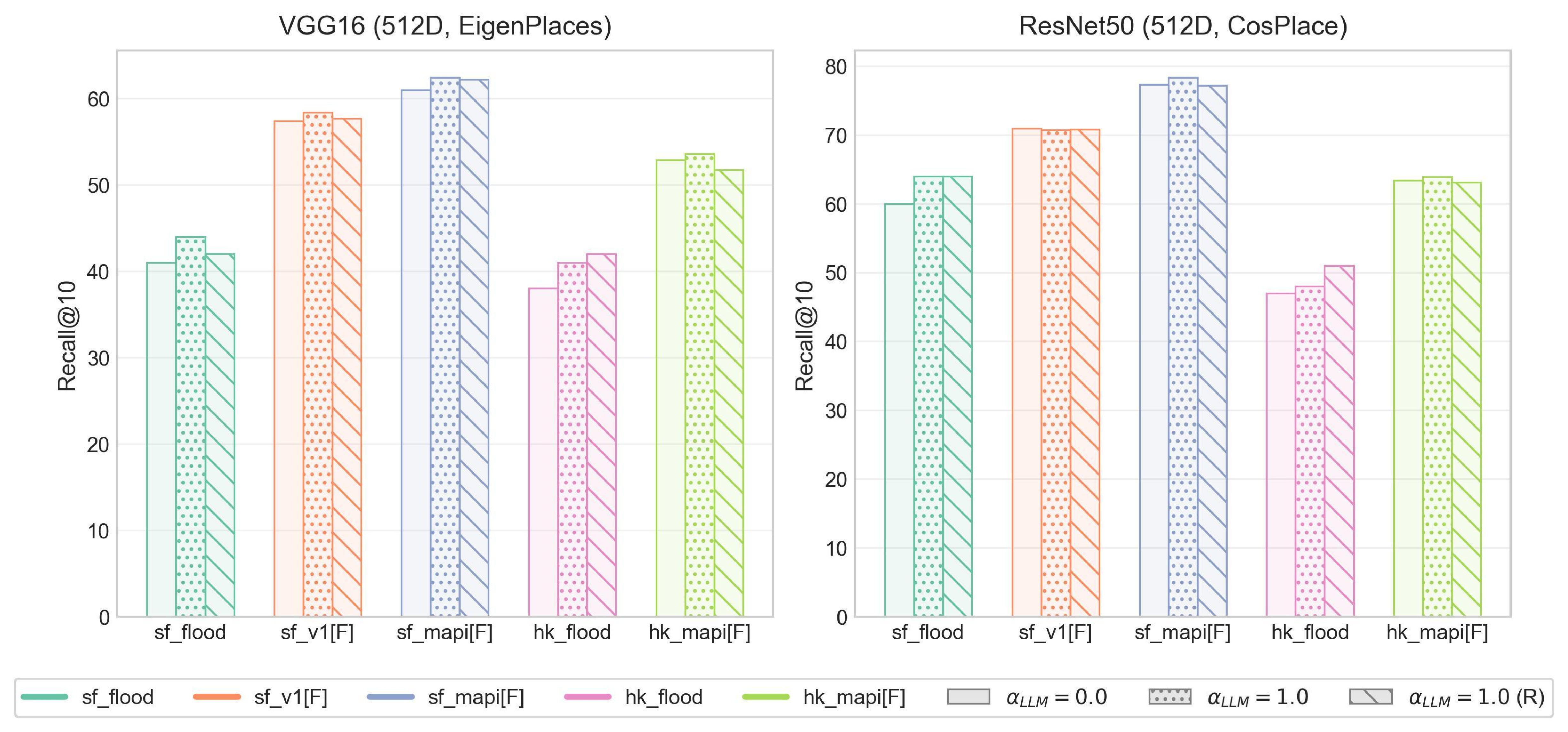
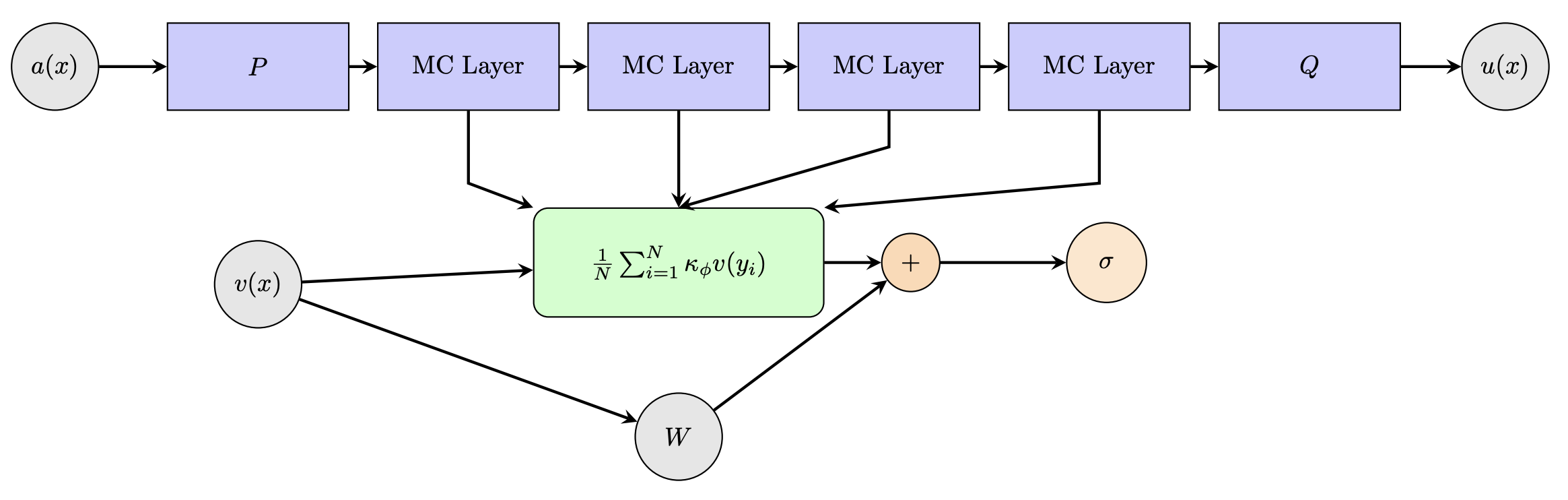
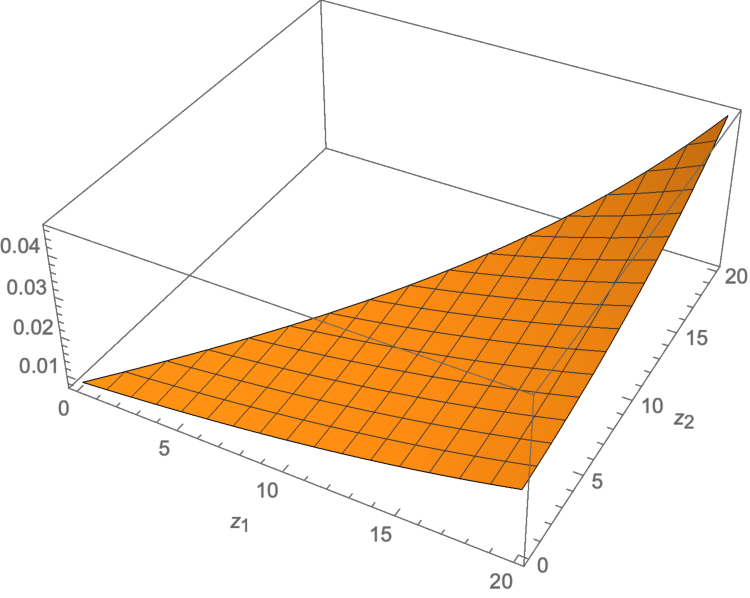
No Image
인공지능 시스템의 신뢰성 보장: 통합 관리 아키텍처로 향상된 책임성
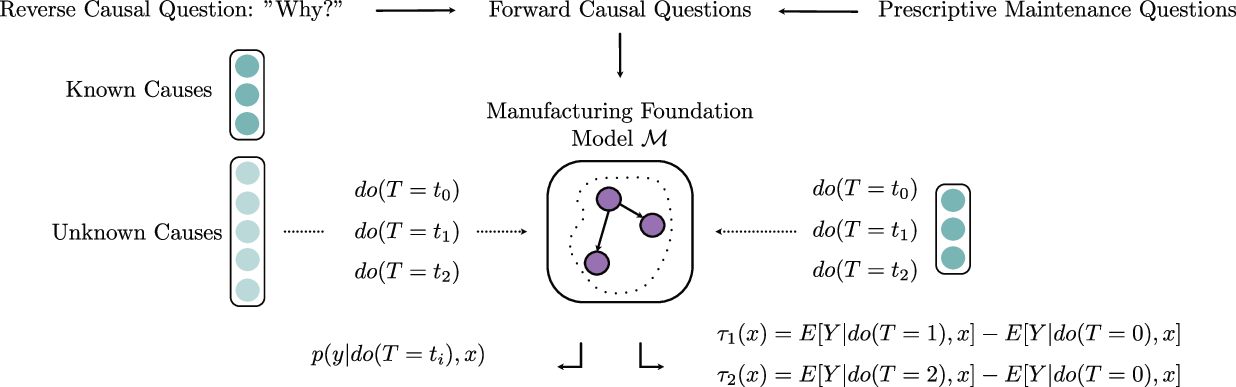
본 논문은 AI 시스템의 책임성과 신뢰성을 높이기 위한 통합 관리 아키텍처를 제시한다. 기존의 AI는 주로 AI 간 조정에 초점을 맞추었지만, 이 연구에서는 전체 AI 구성 요소와 인간 참여자를 포괄하는 보다 포괄적인 접근 방식을 제안하고 있다. 특히 '신뢰할 수 있는 조정 AI를 위한 10개 기준'은 이러한 목표를 달성하기 위해 중요한 역할을 한다. 이 논문의 핵심 개념 중 하나는 '통합 관리 아키텍처'이다. 이는 인간 입력, 의미론적 일관성, 감사 및 증거의 정합성을 통합한 단일 관리 패널로 구성되어 있다. 이러한 접근 방식은