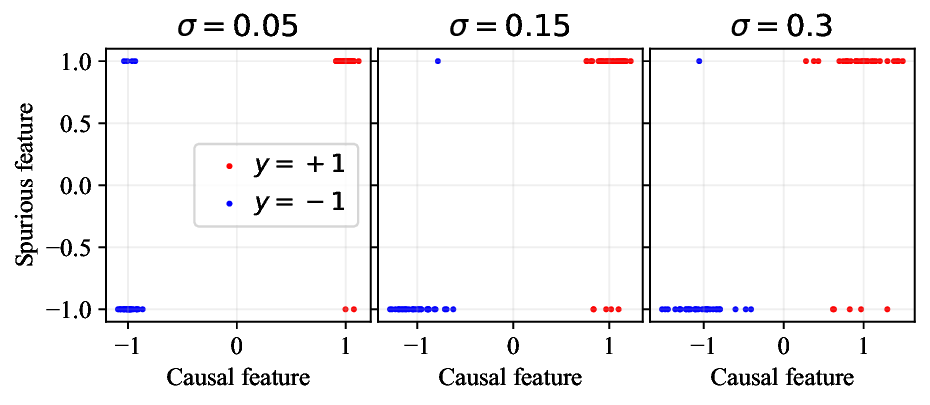
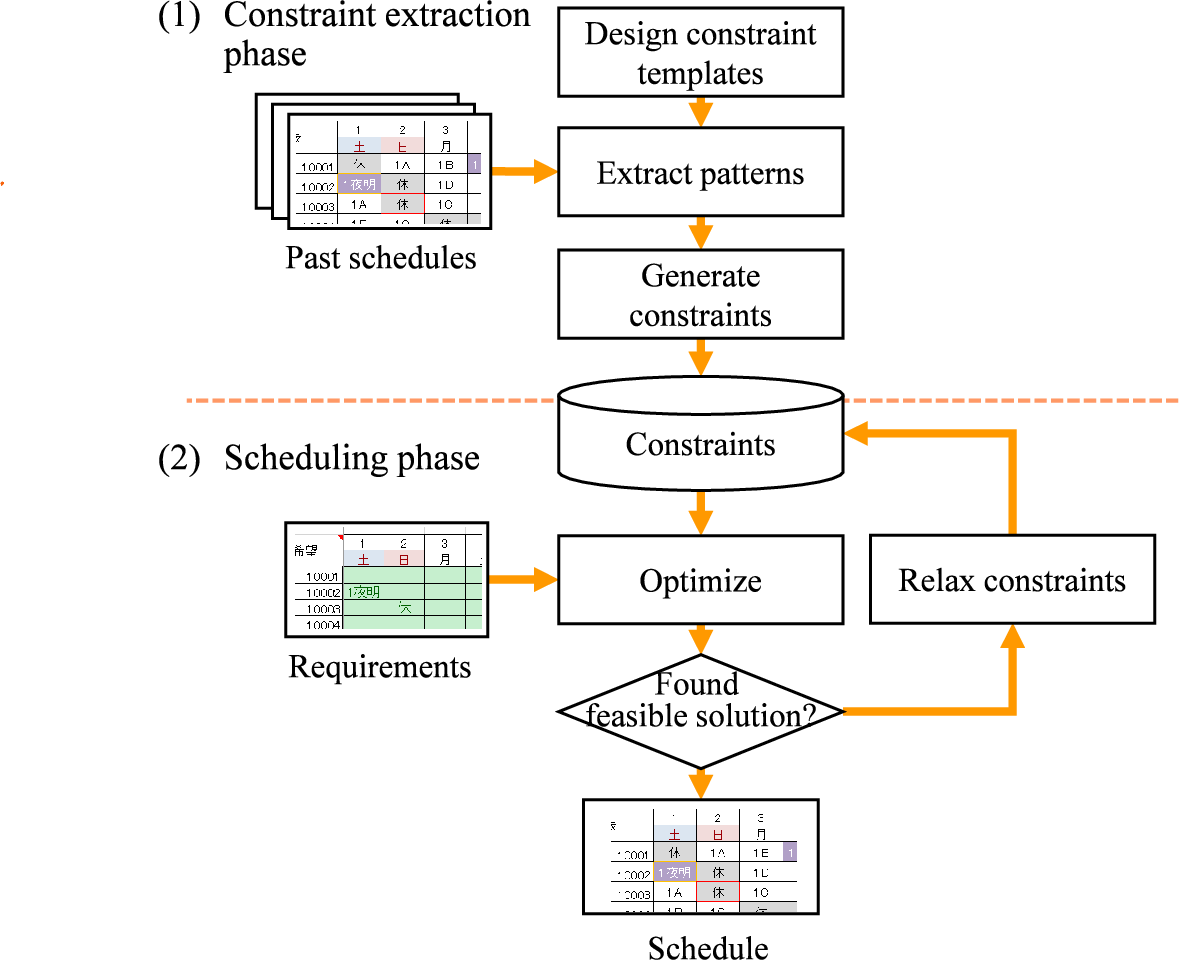
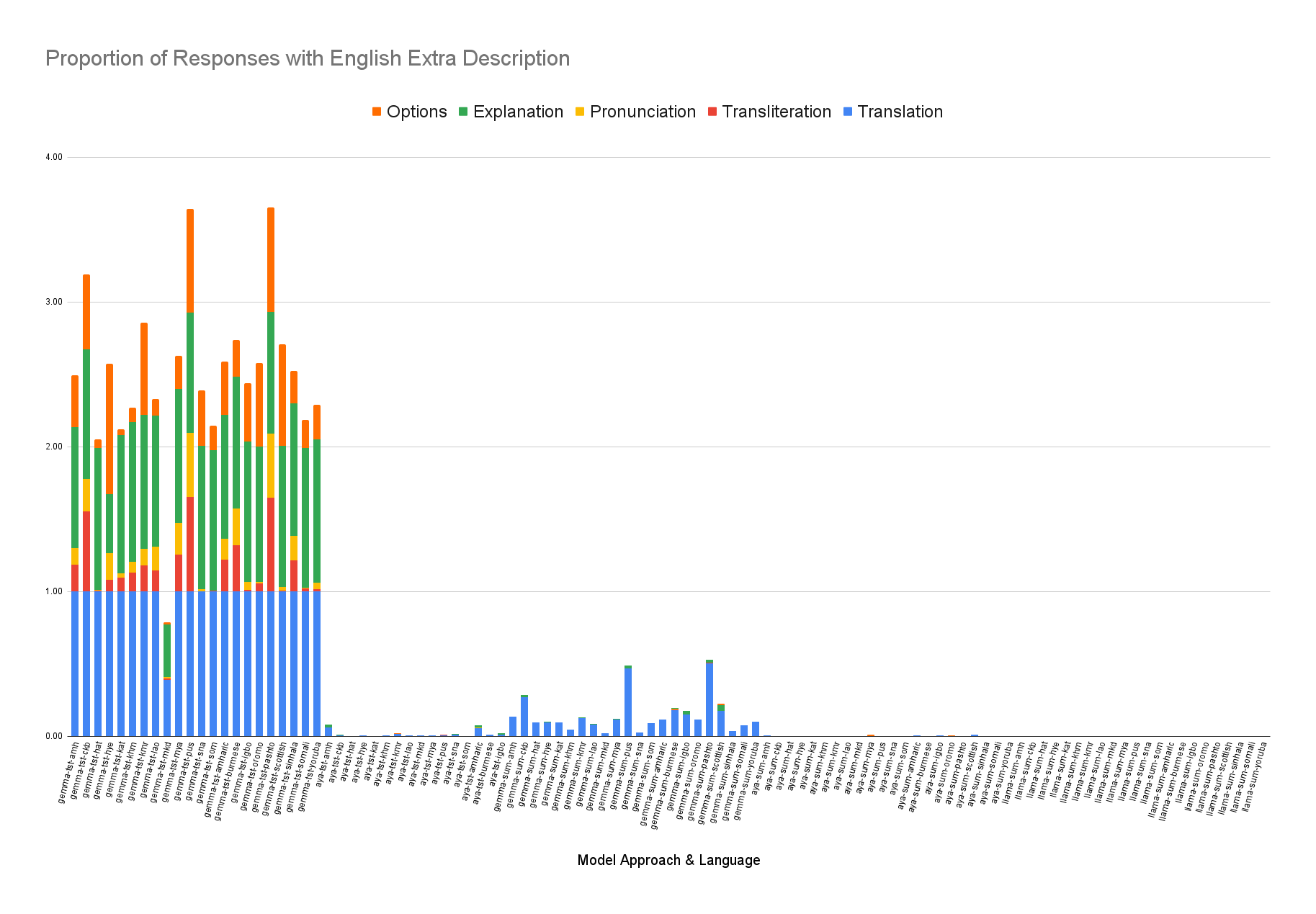
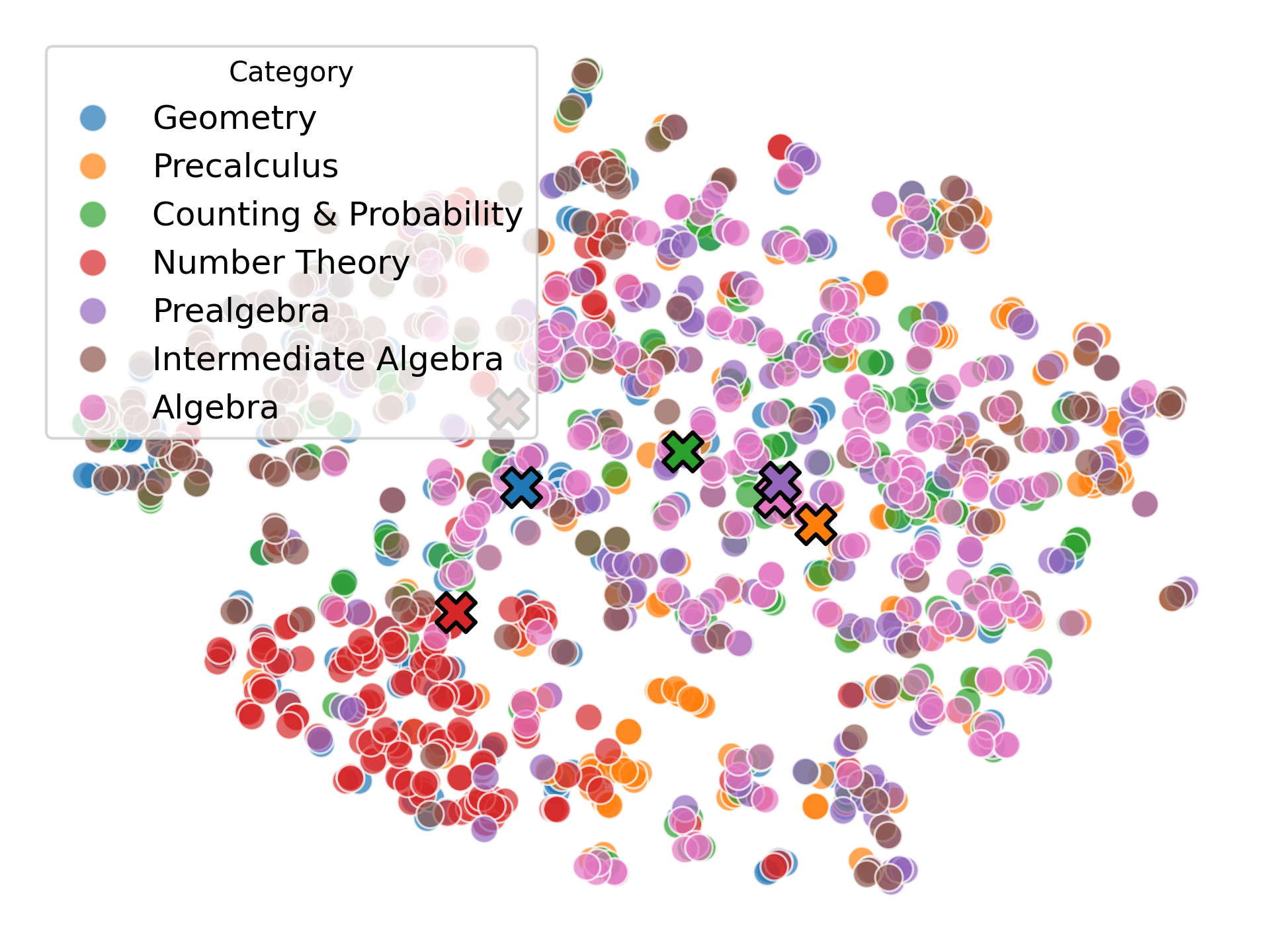
AI 코딩 도우미 시대 ML 프로젝트 성공을 이끄는 네 가지 핵심 요소
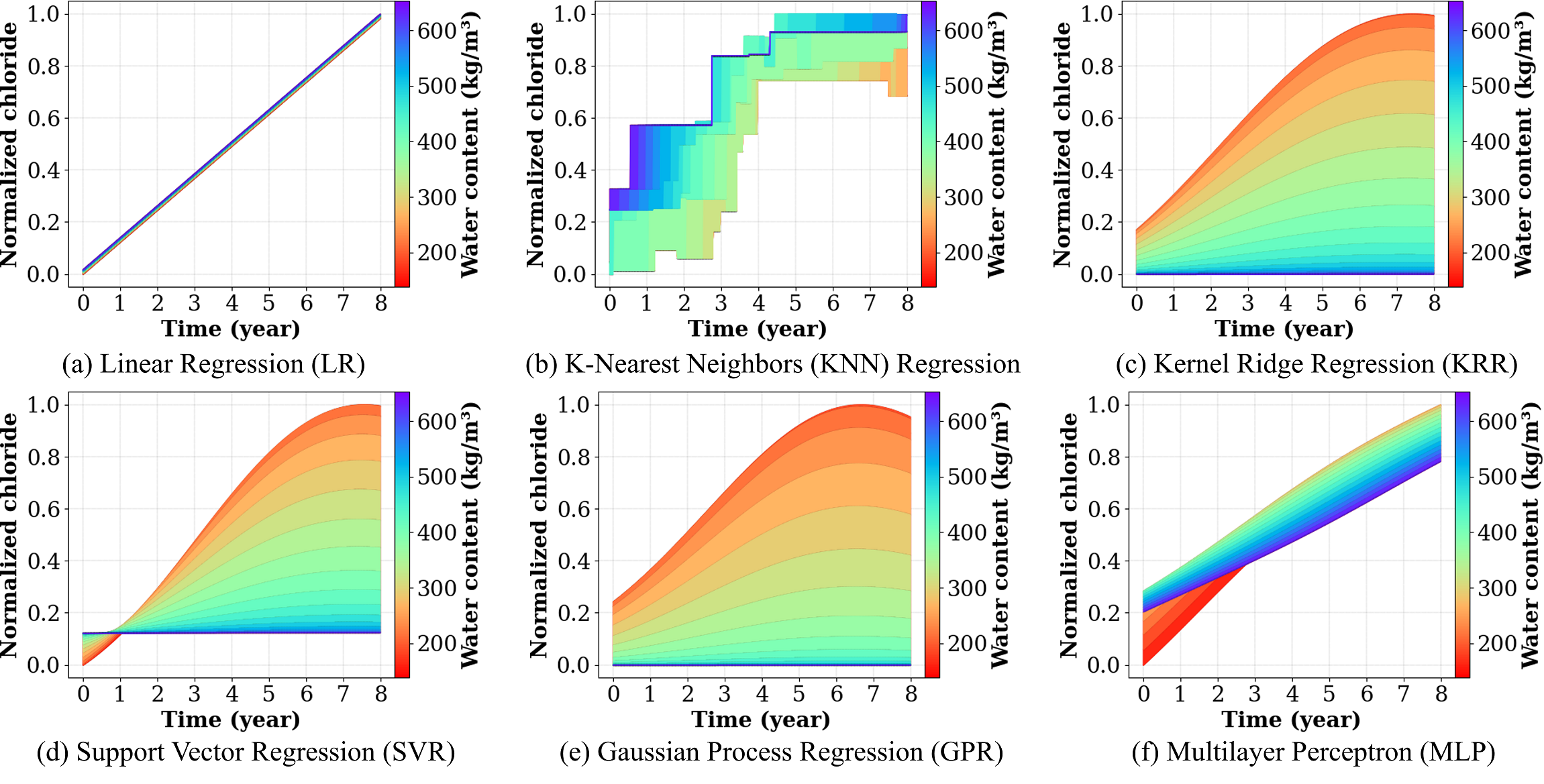
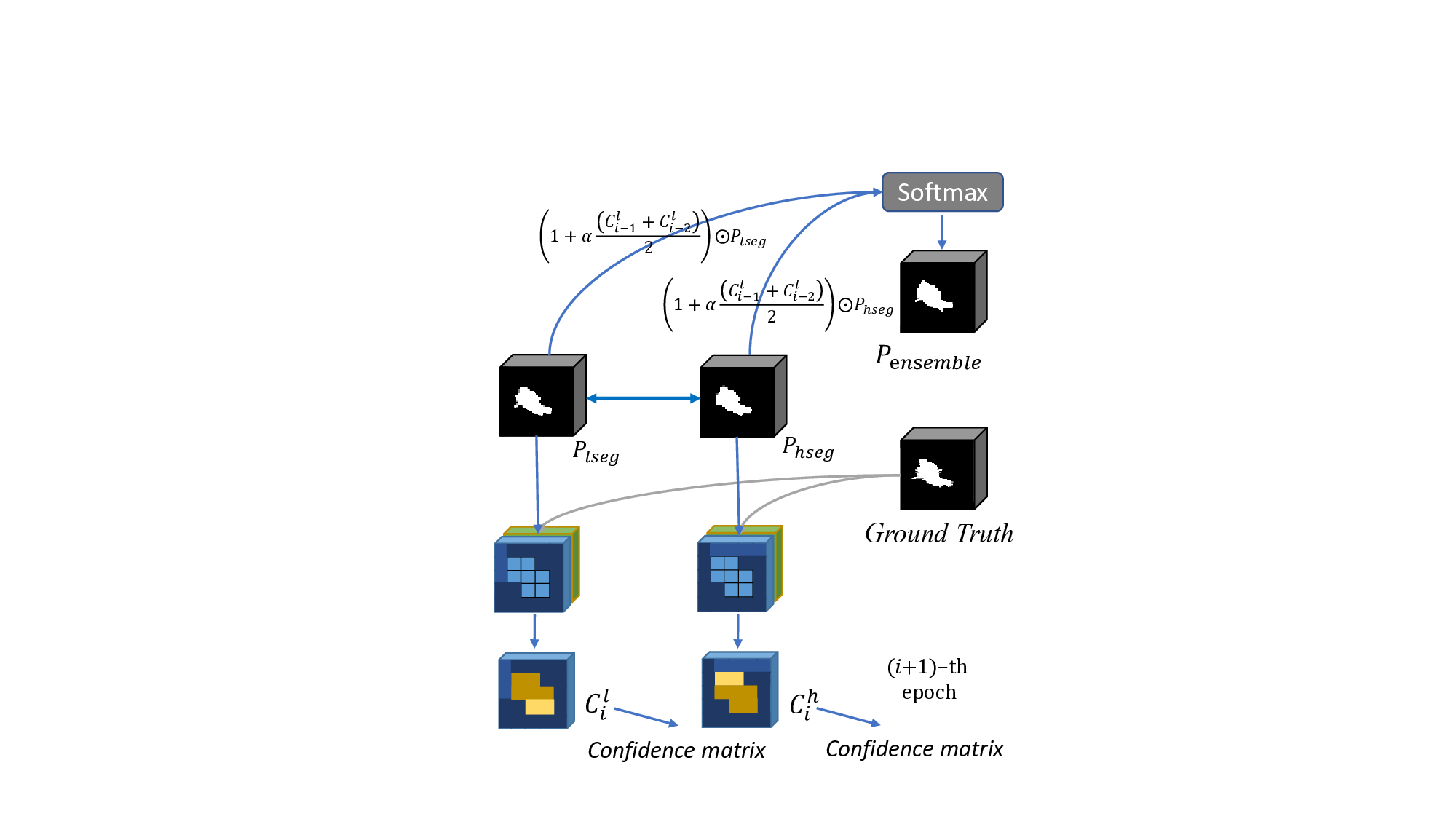
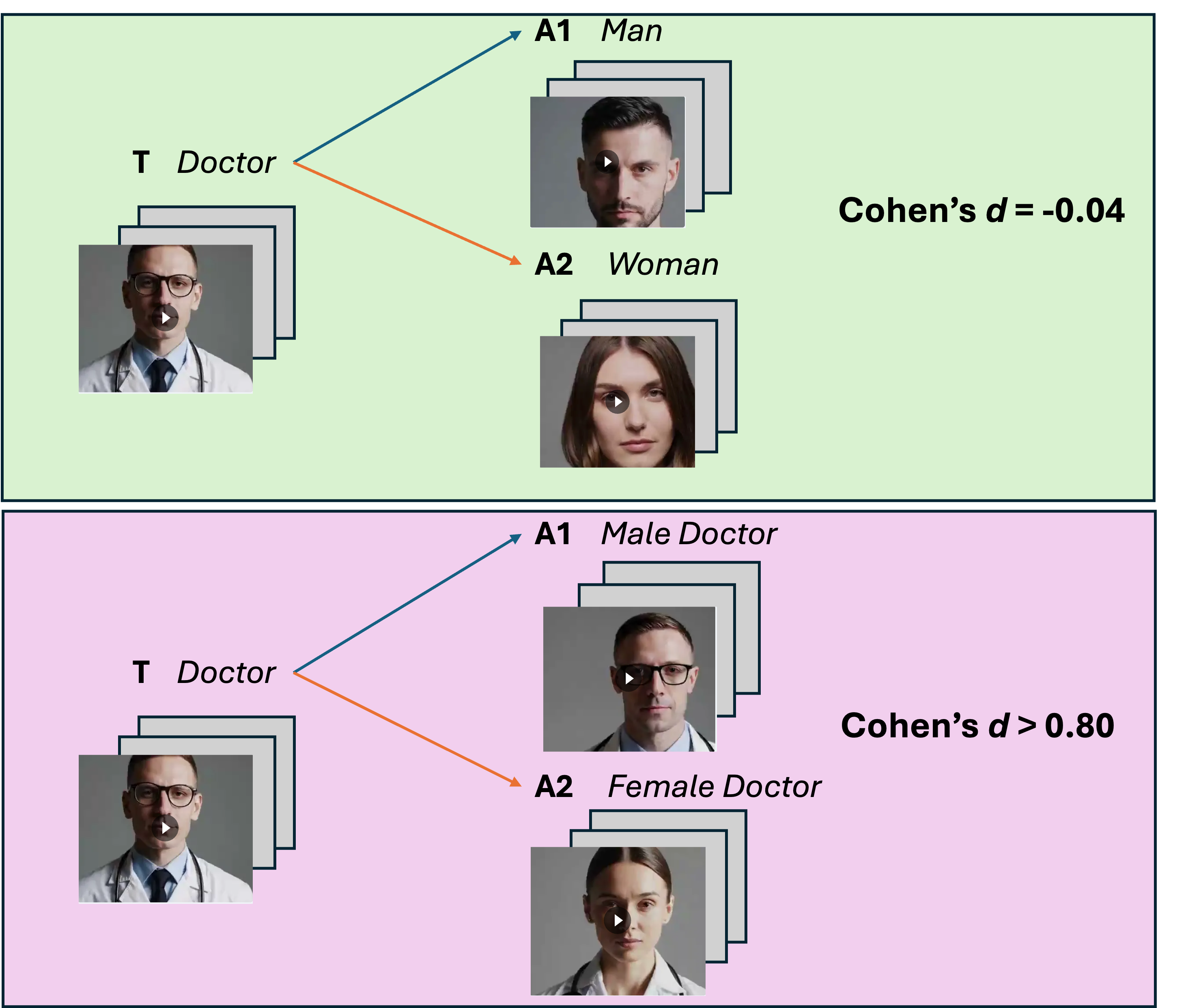
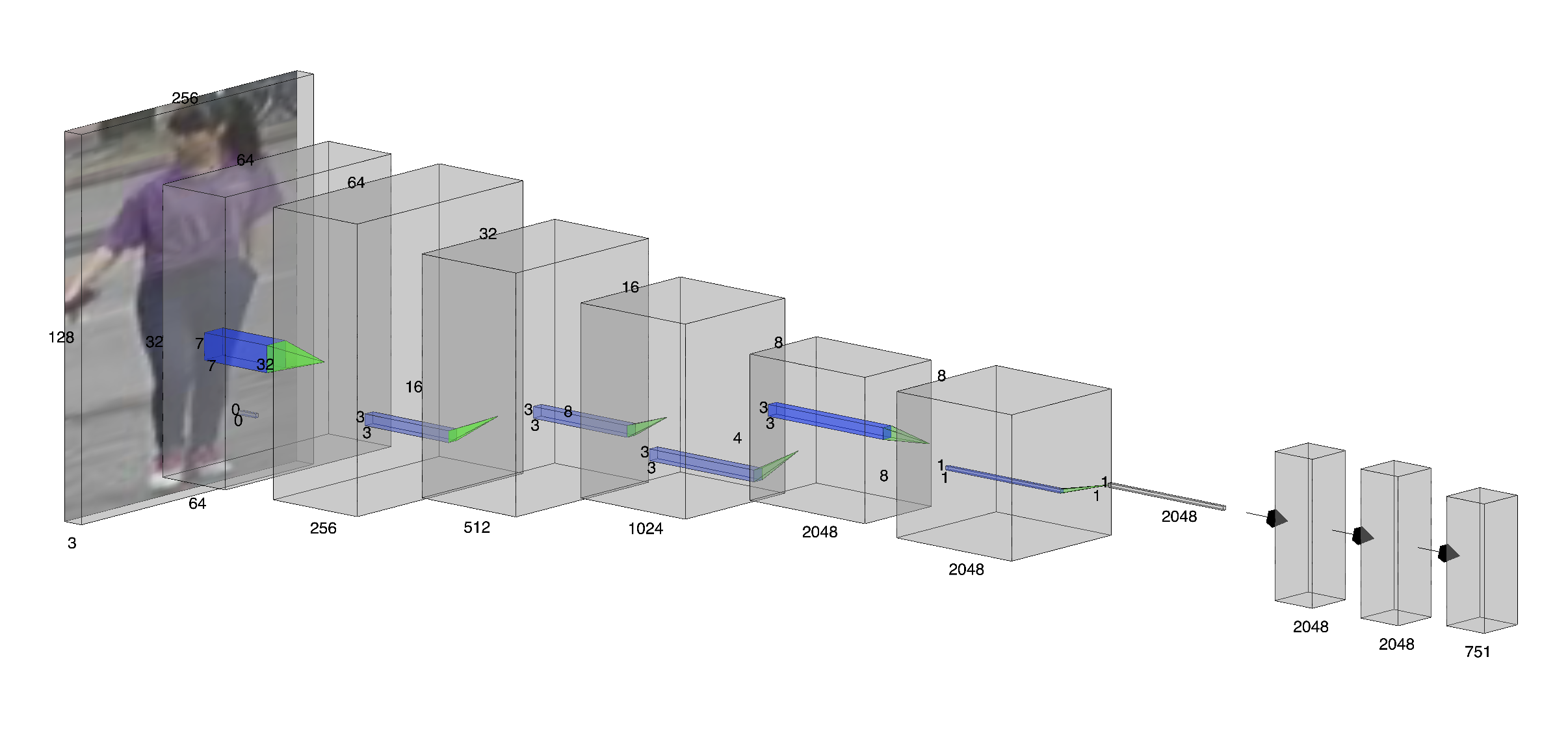
본 논문은 현재 AI 기반 코딩 어시스턴트가 개발 현장에서 널리 활용되는 상황에서, 왜 여전히 ML 프로젝트의 성공률이 낮은지를 체계적으로 탐구한다. 연구자는 먼저 기존 문헌을 검토하여 성공 요인을 전략, 프로세스, 생태계, 지원 네 가지 차원으로 구분하고, 이를 시각화한 ‘머신러닝 캔버스’를 제안한다. 설문 설계는 각 차원을 정량화할 수 있는 항목들을 포함했으며, 150명의 데이터 과학자를 대상으로 6개월에 걸쳐 데이터를 수집하였다. 통계 분석에는 구조방정식 모델링(SEM)을 활용해 요인 간 인과관계를 검증했으며, β값과 p값을
Learning