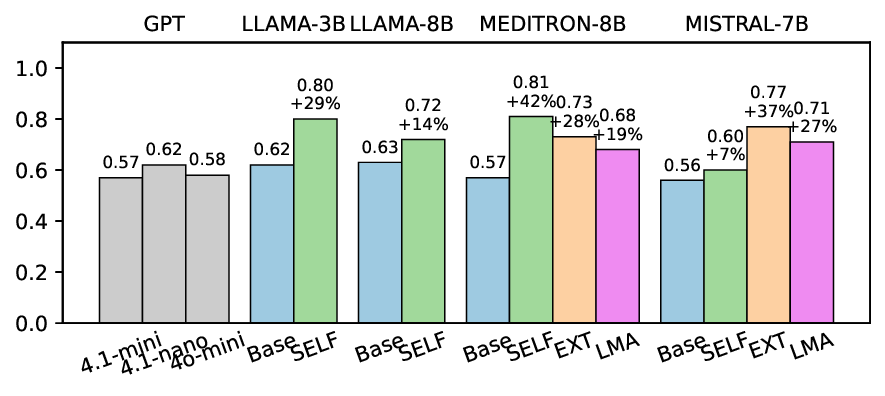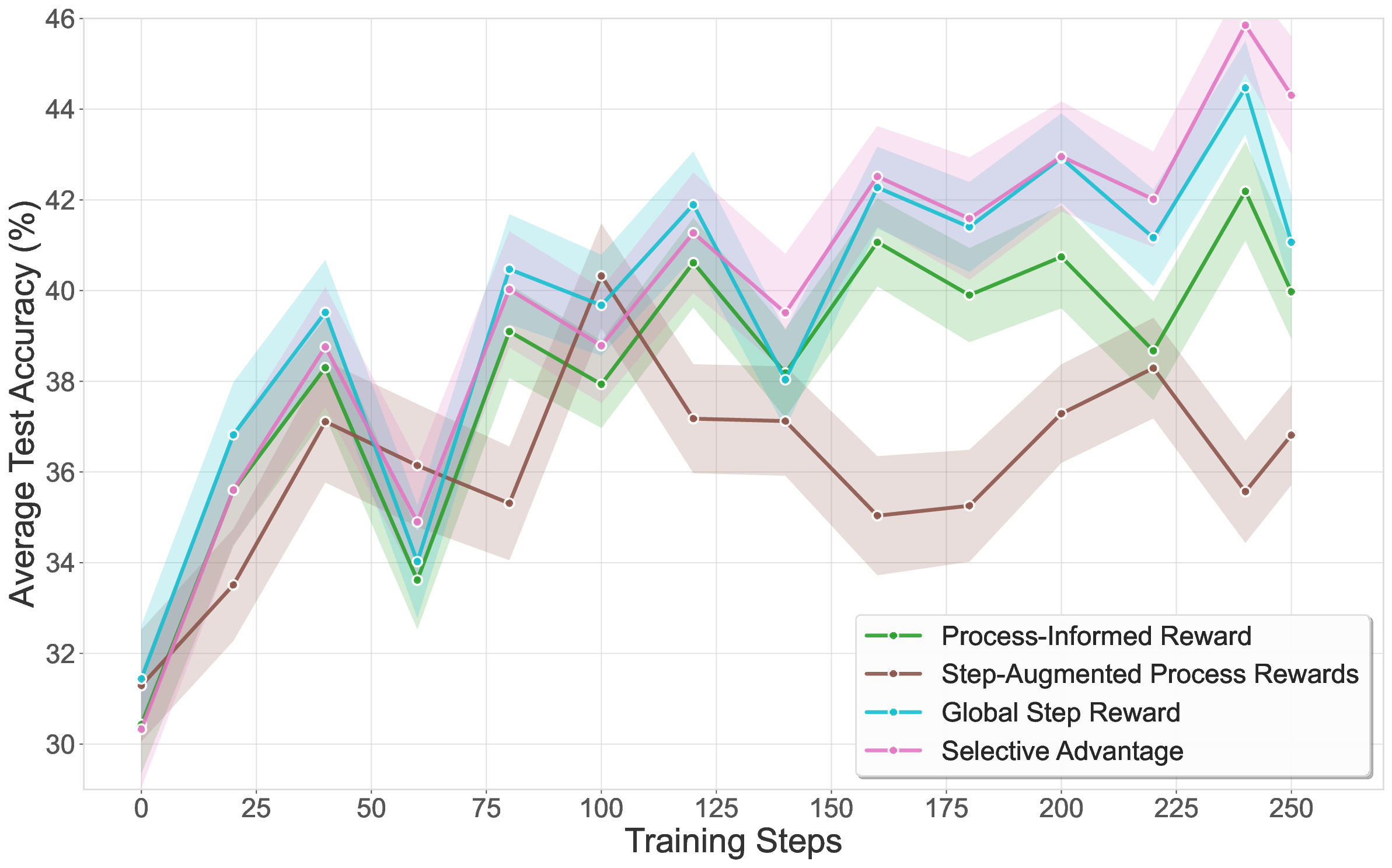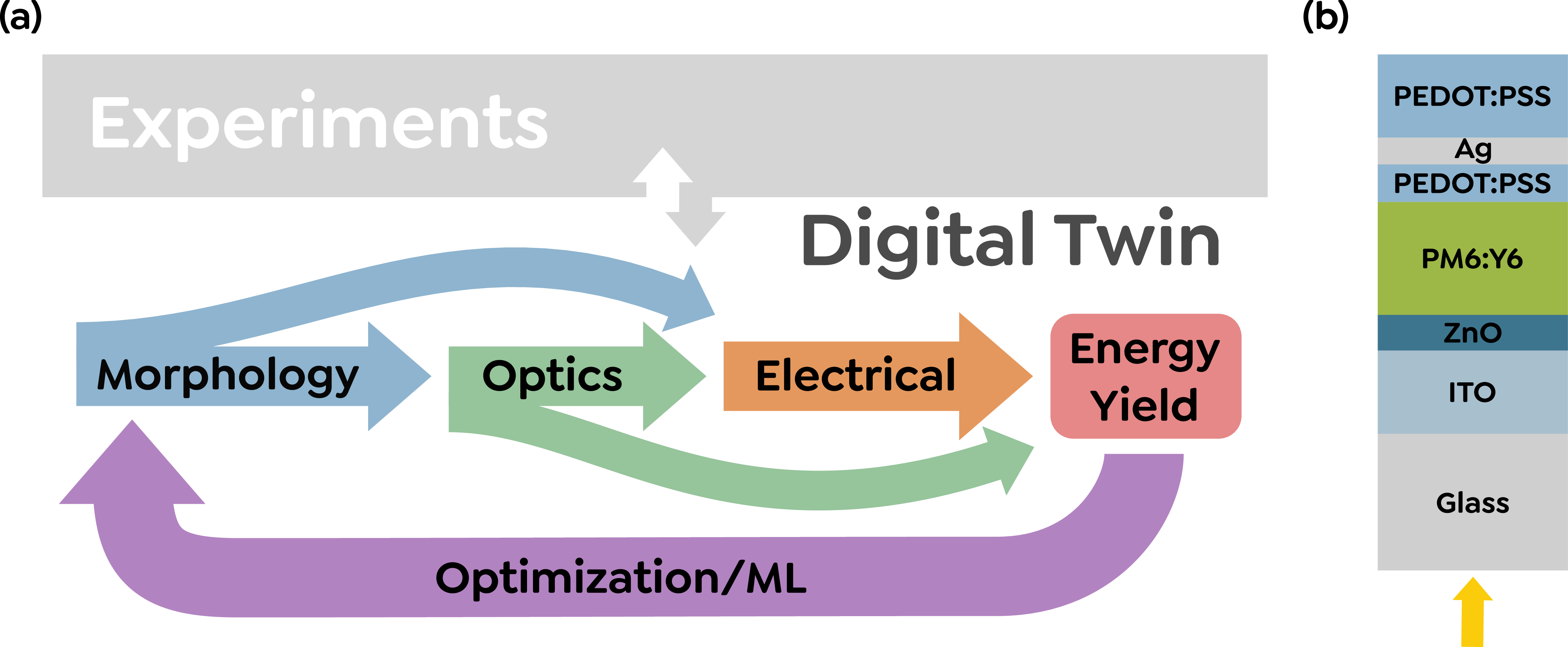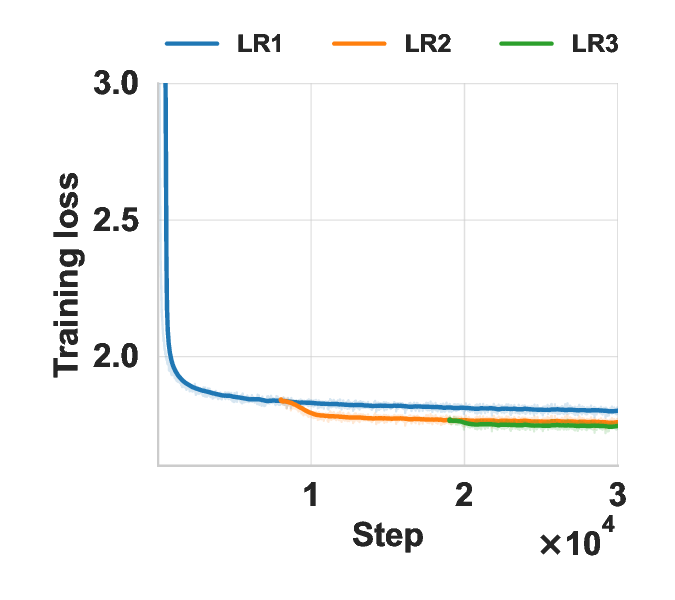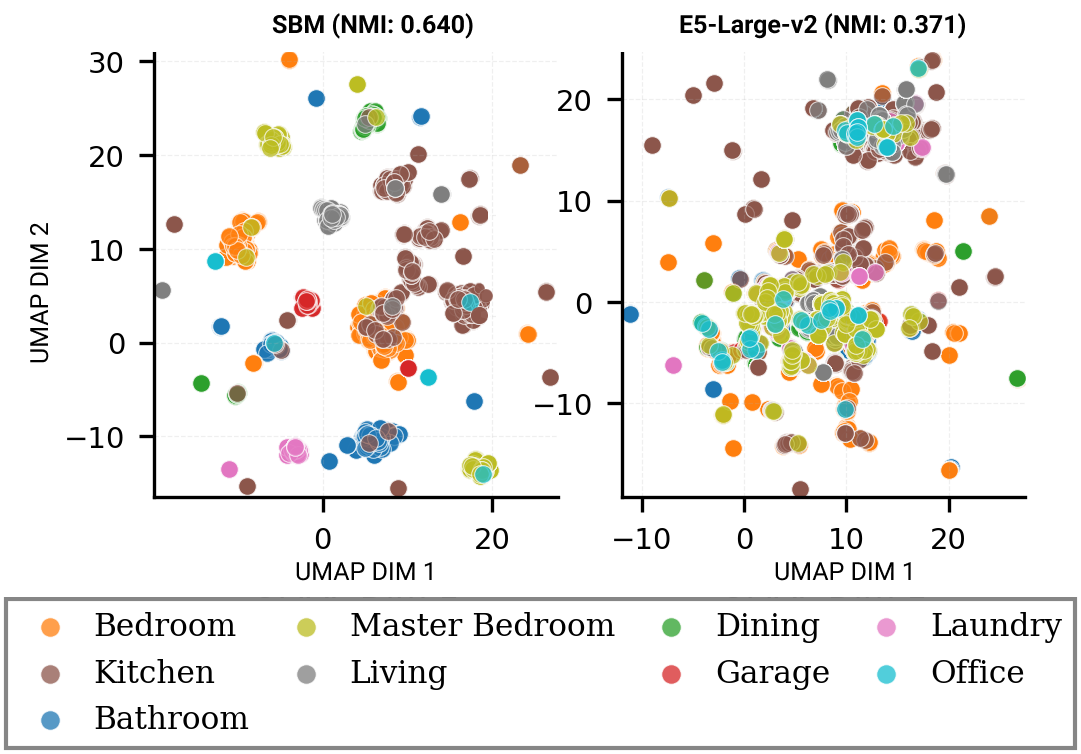
작은 건물 모델을 활용한 방 레이아웃 자동 생성 혁신
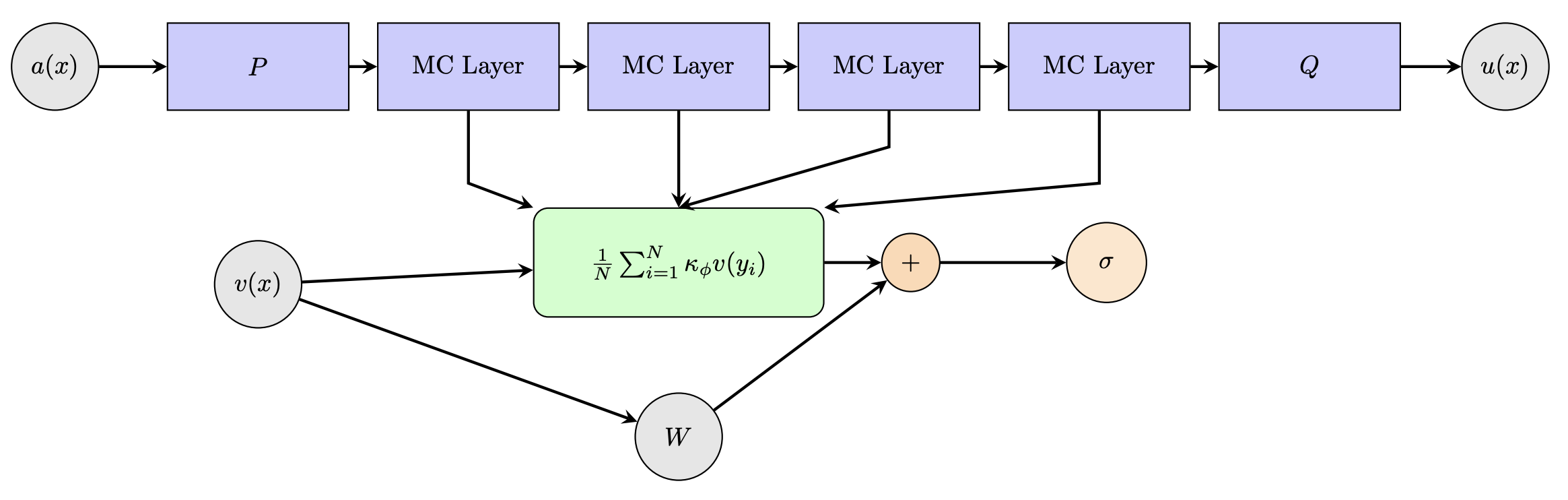
본 논문은 건축 설계 자동화라는 실용적 과제에 트랜스포머 기반의 시퀀스‑투‑시퀀스 모델을 적용한 점에서 의미가 크다. 기존 연구들은 주로 2D 평면도나 3D 모델을 직접 입력으로 사용하거나, 규칙 기반 시스템에 의존해 레이아웃을 생성하였다. 그러나 이러한 방식은 복잡한 공간 제약을 충분히 반영하기 어렵고, 데이터 요구량이 높으며, 일반화 능력이 제한적이다. SBM은 ‘룸 엔벨로프’라는 최소한의 입력만으로도 방 내부의 가구 배치, 동선, 기능 구역을 동시에 고려한 레이아웃을 생성한다는 점에서 입력 효율성이 뛰어나다. 모델 아키텍처는