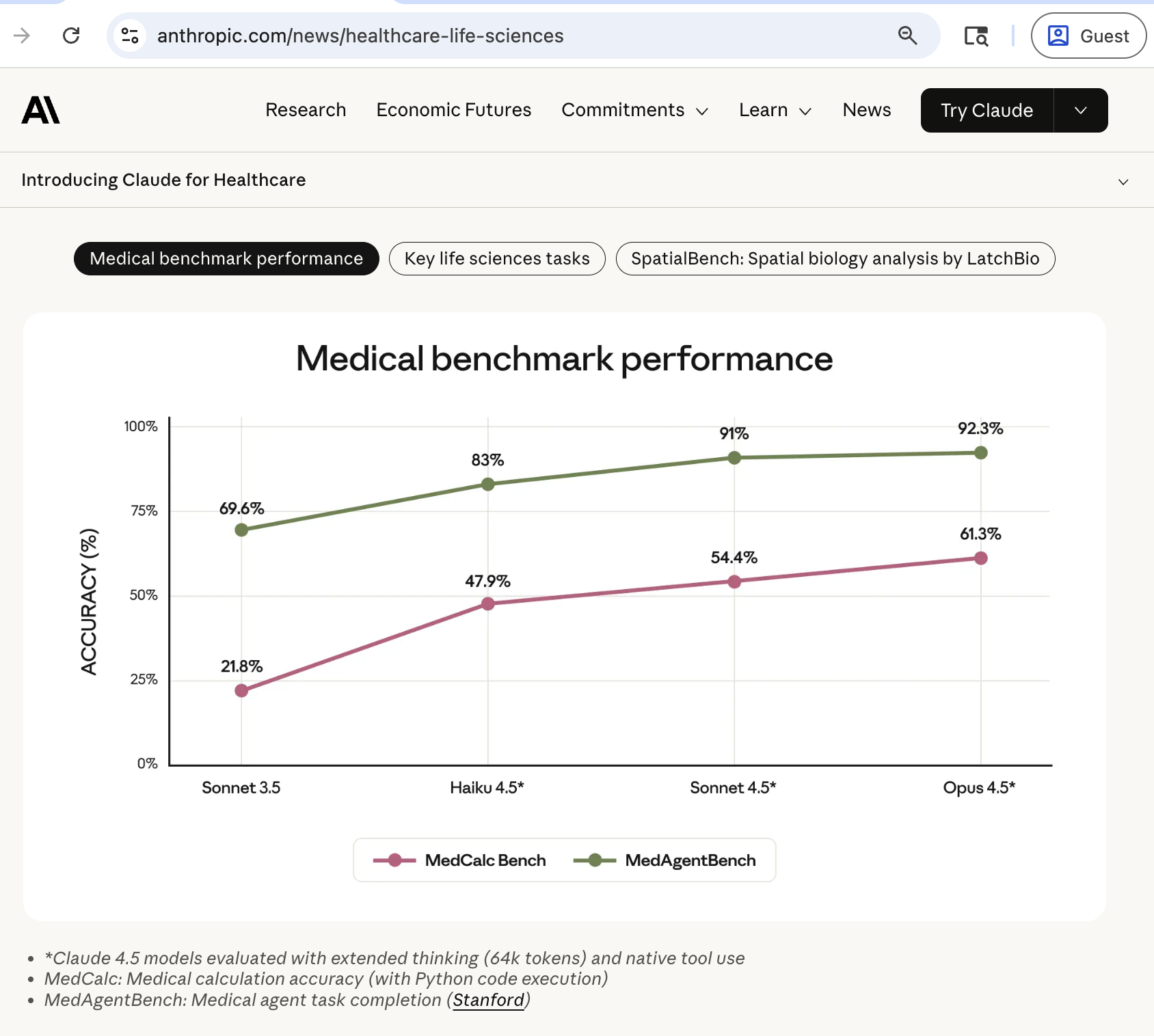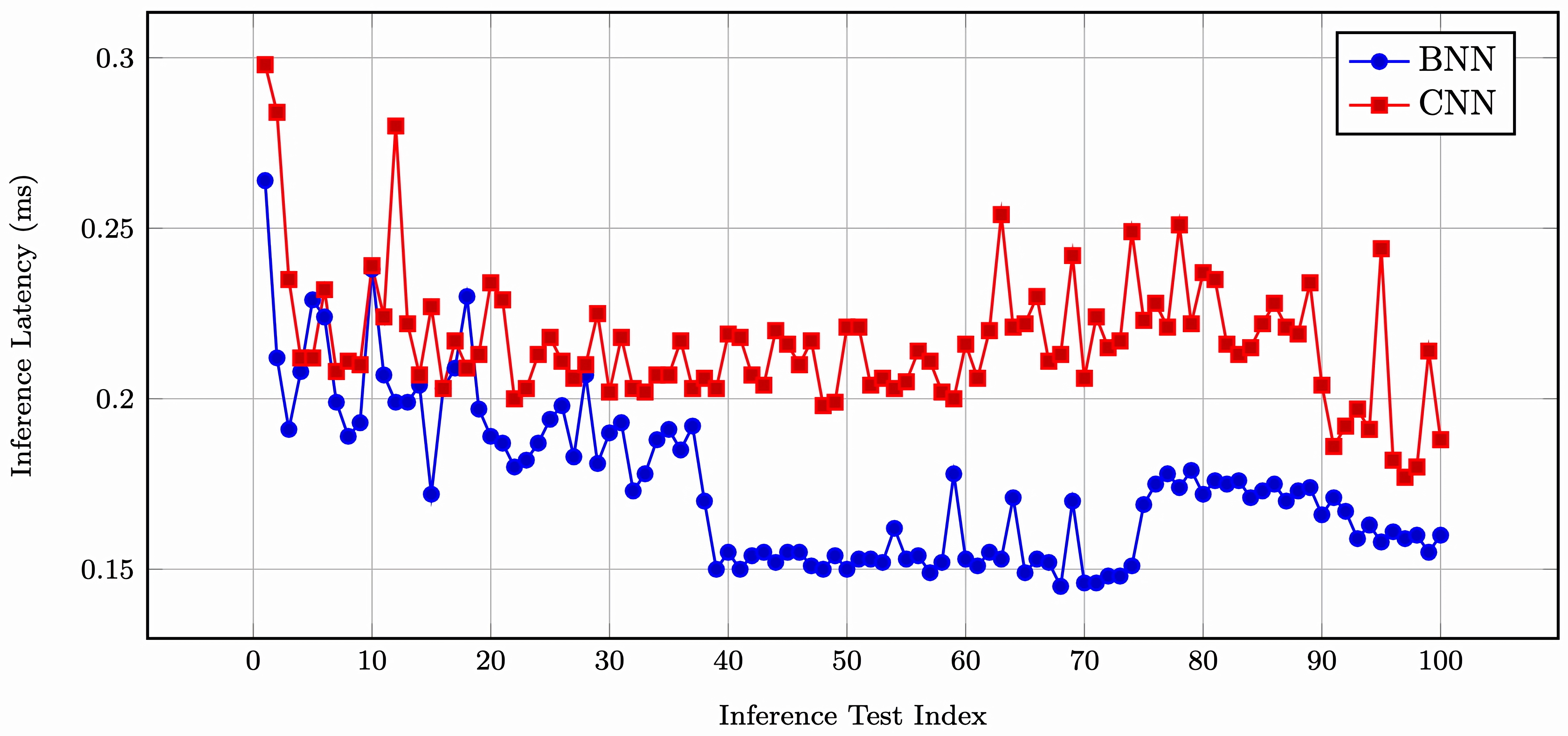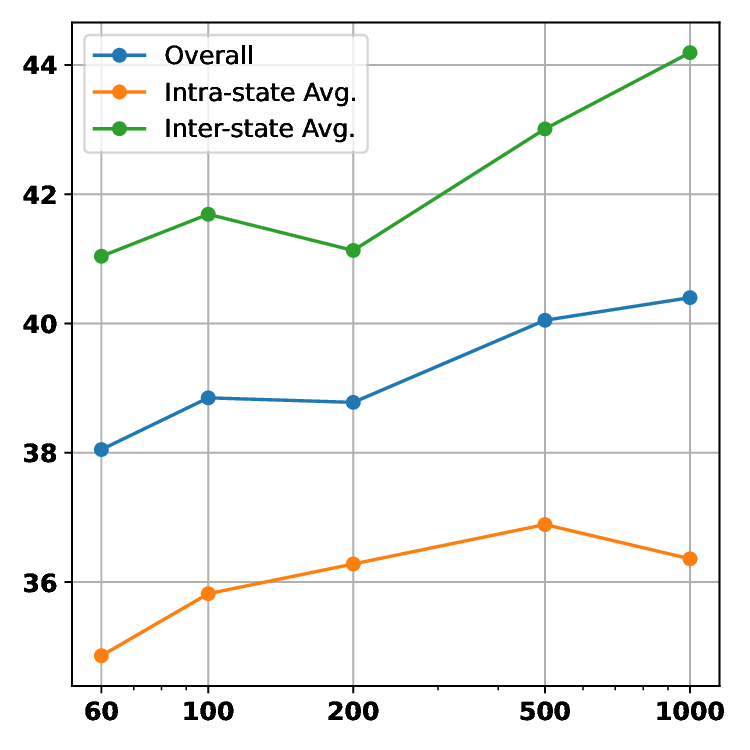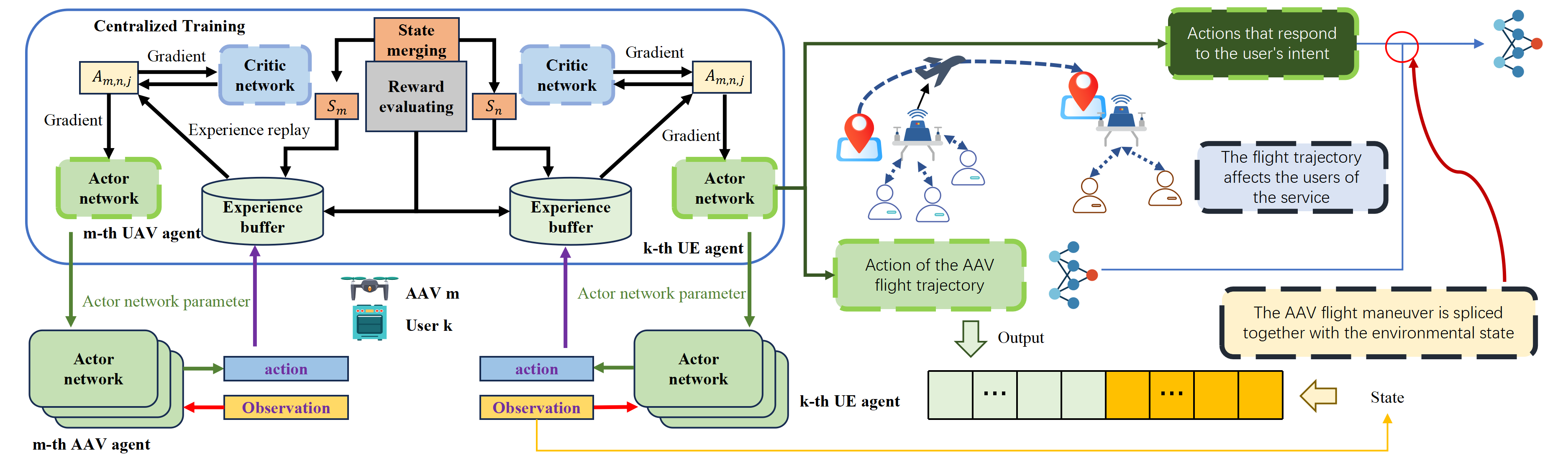
하이퍼차원 트랜스포머와 이중행동 MAPPO 기반 자율항공기 6G IoT 의도 최적화 프레임워크
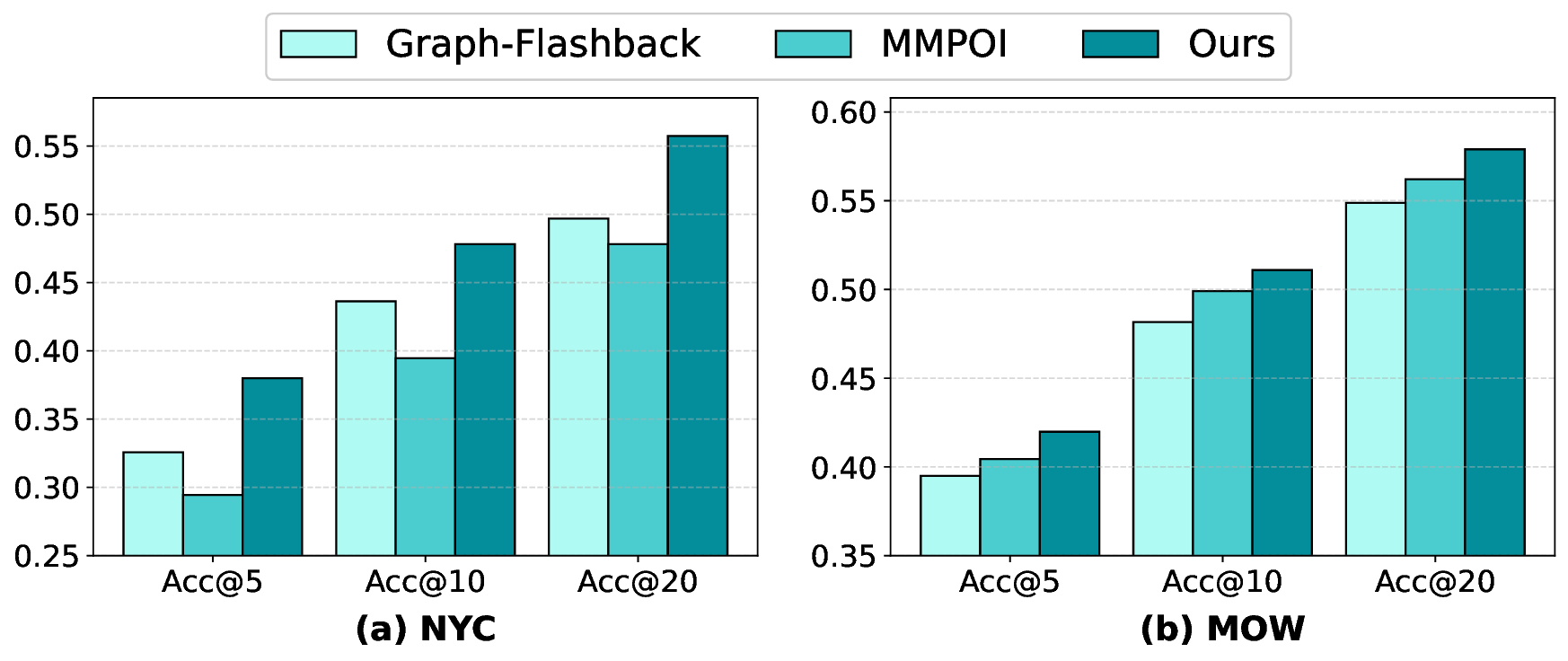
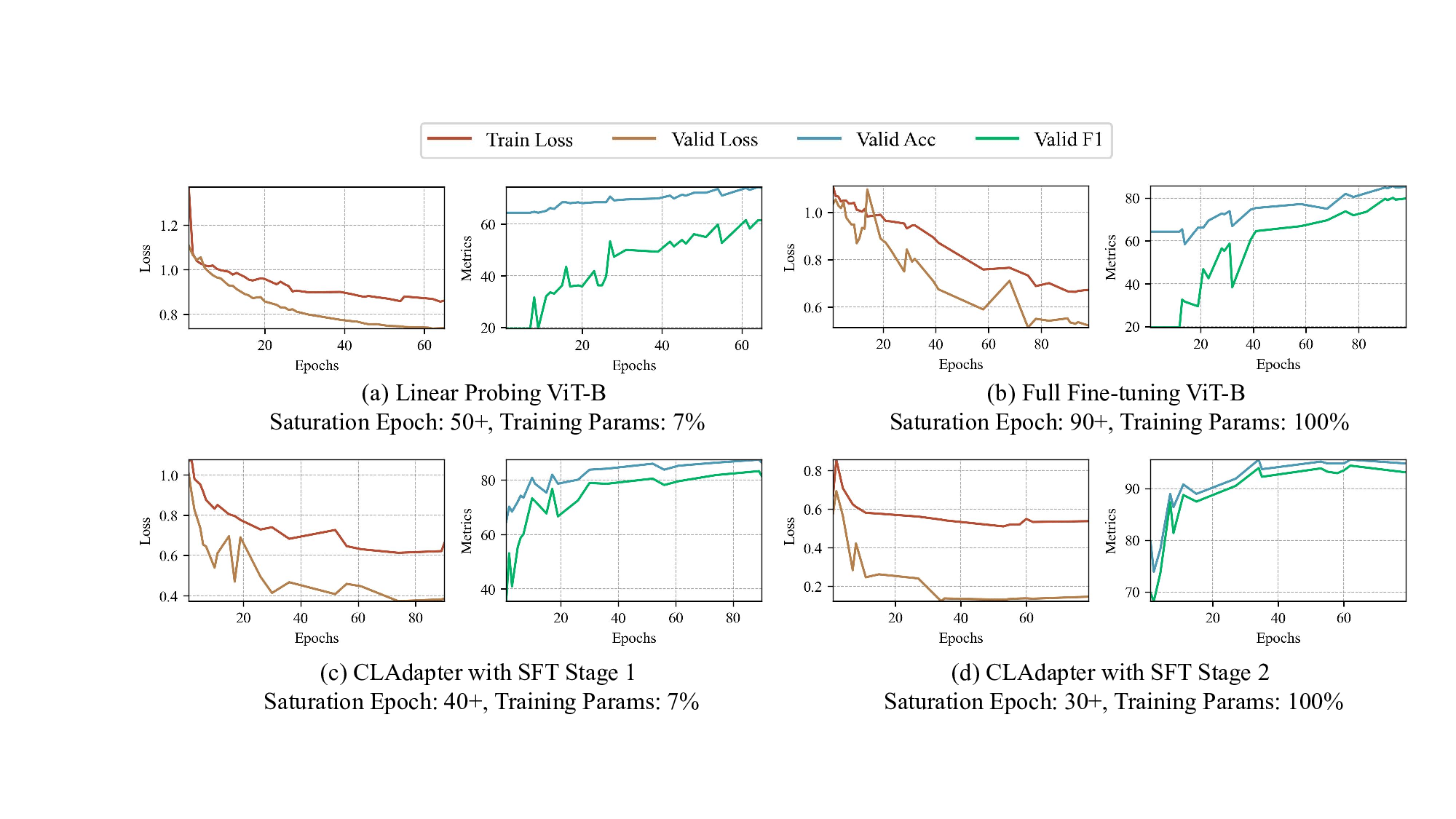
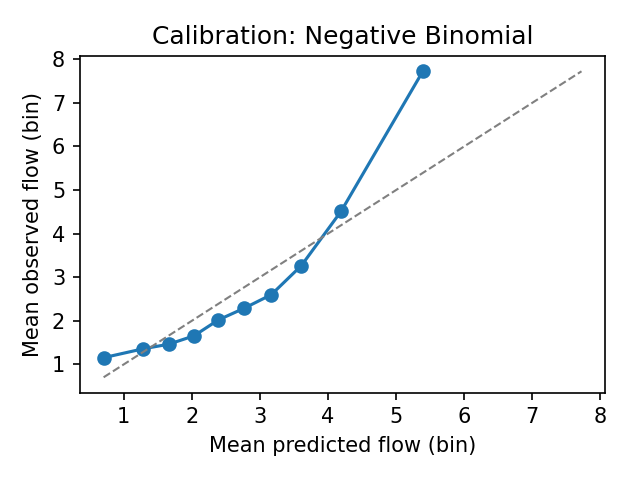
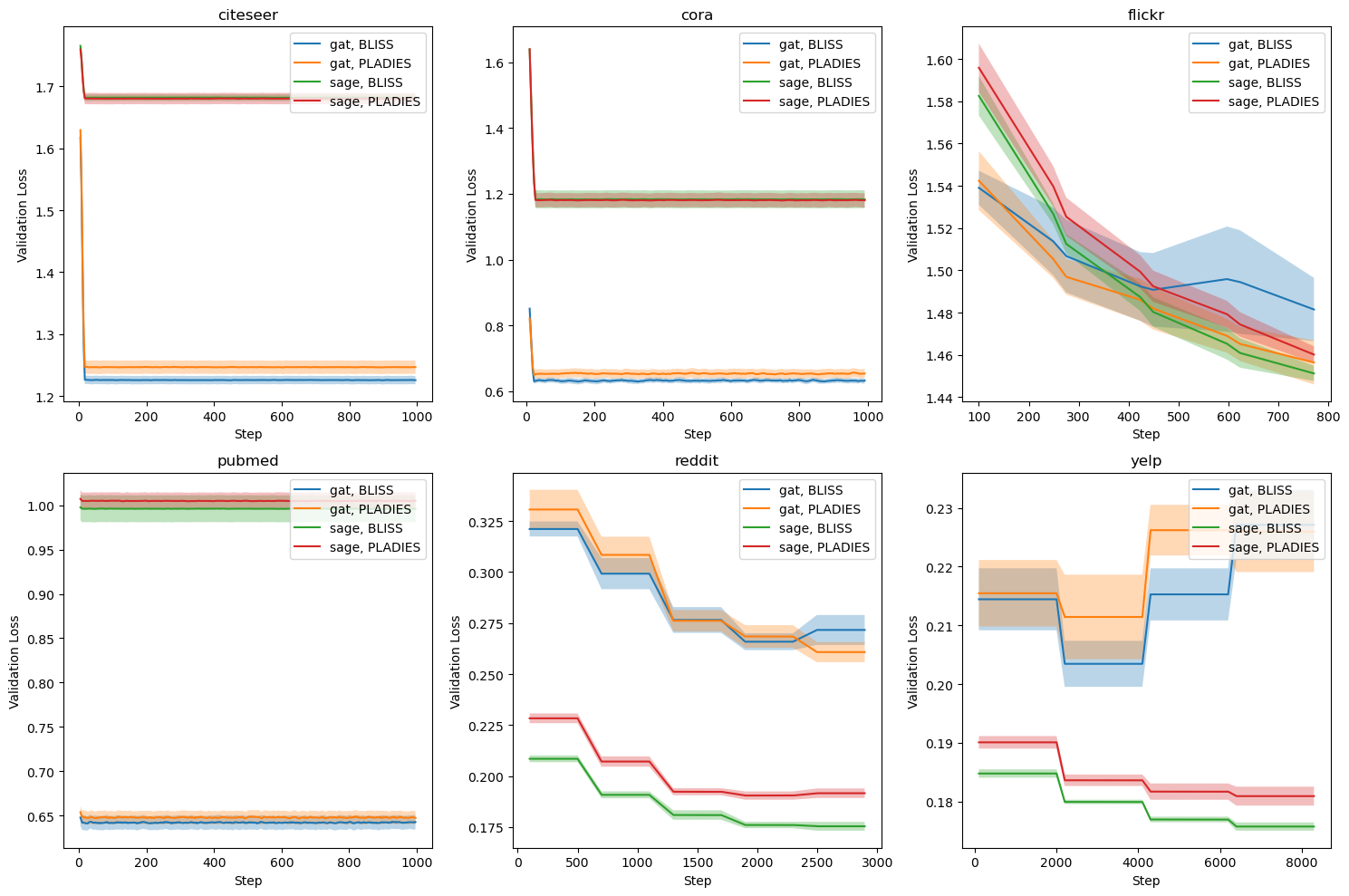
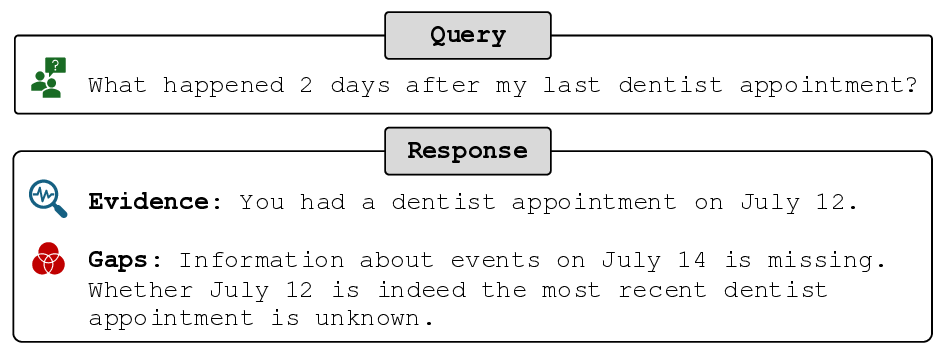
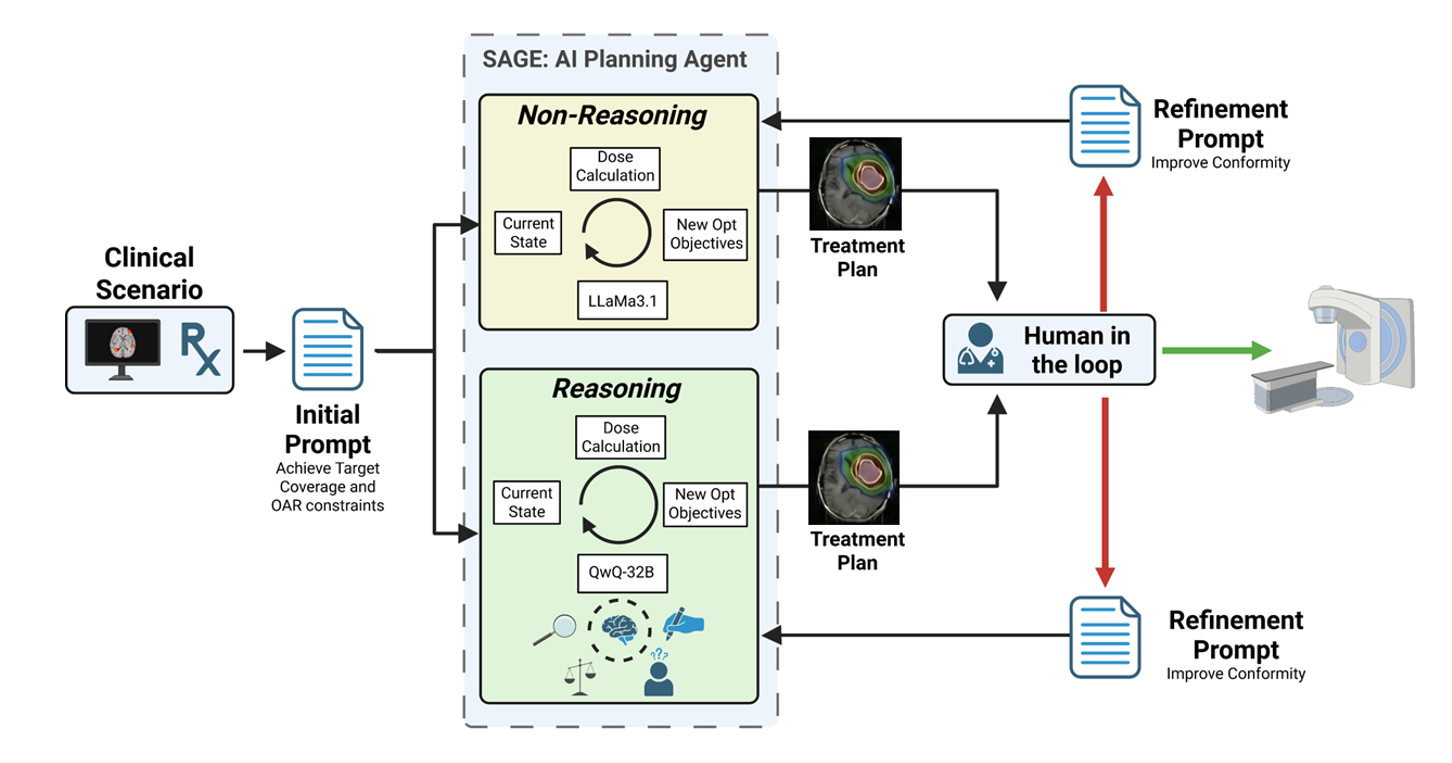
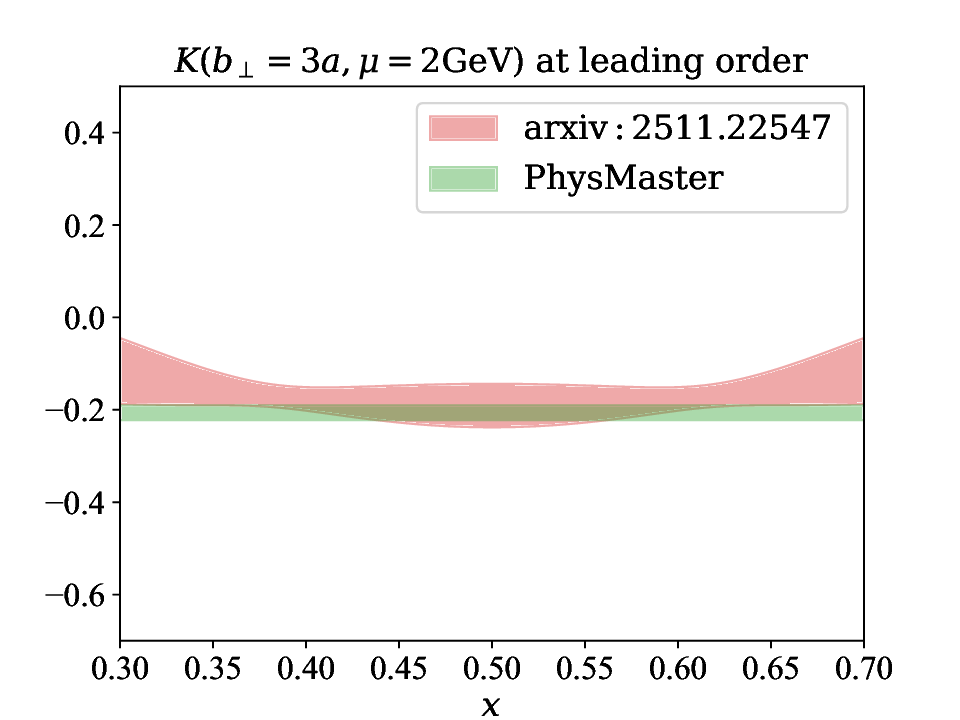
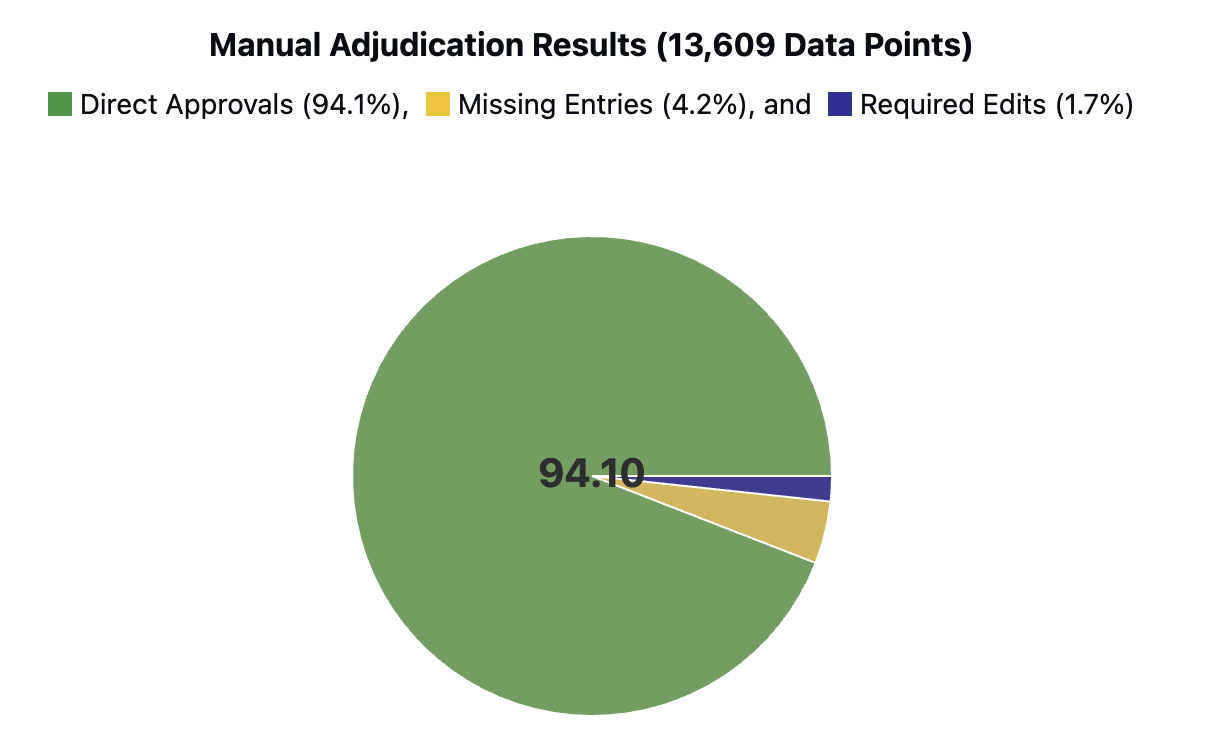
본 연구는 6G 시대에 급증하는 초연결 IoT 환경과 자율항공기(AAV)의 협업을 위한 핵심 기술적 과제를 체계적으로 해결하고자 한다. 첫 번째 과제는 사용자 의도를 정확히 파악하는 것이다. 기존의 의도 추론 모델은 주로 텍스트 기반의 명시적 표현에 의존하는데, 실제 현장에서는 음성, 센서 데이터, 비정형 신호 등 다양한 형태의 모호하고 불완전한 입력이 존재한다. 이러한 상황에서 암시적 의도 모델링을 도입함으로써, 입력의 불확실성을 확률적 표현으로 전환하고, 하이퍼차원(Hyperdimensional) 공간에 매핑함으로써 고차원 특성
Network