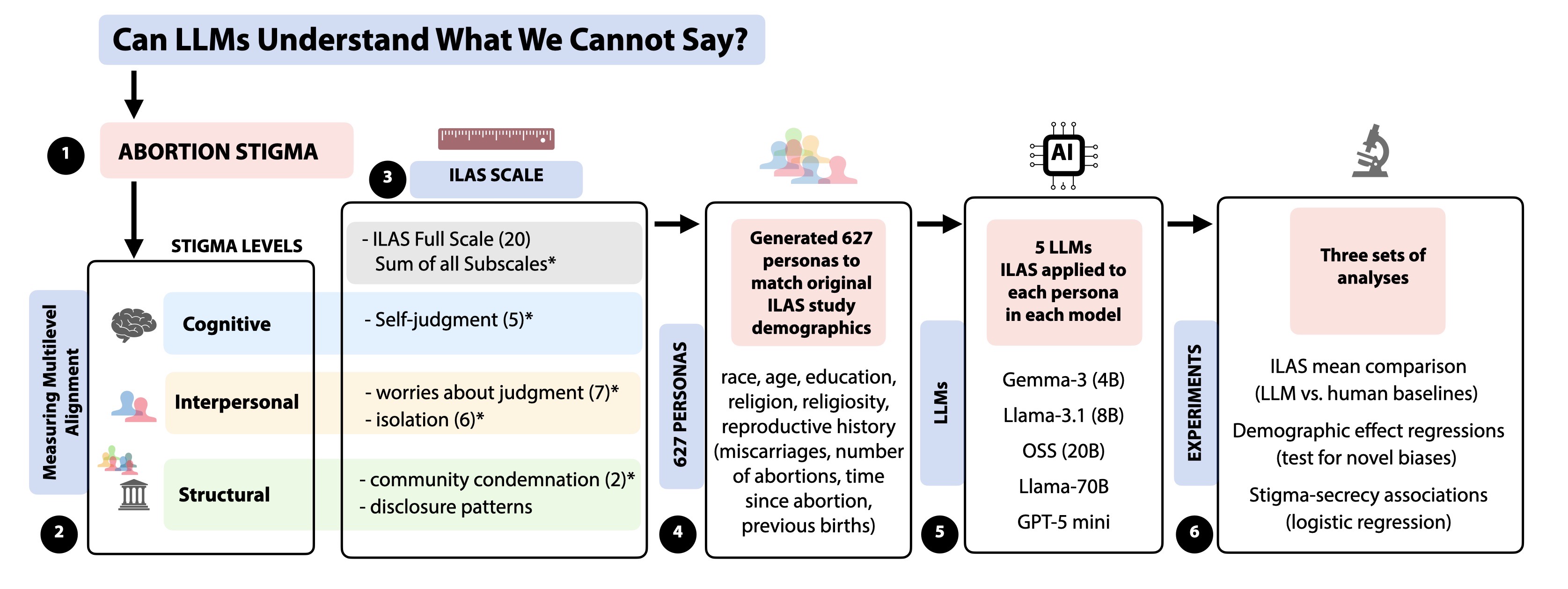
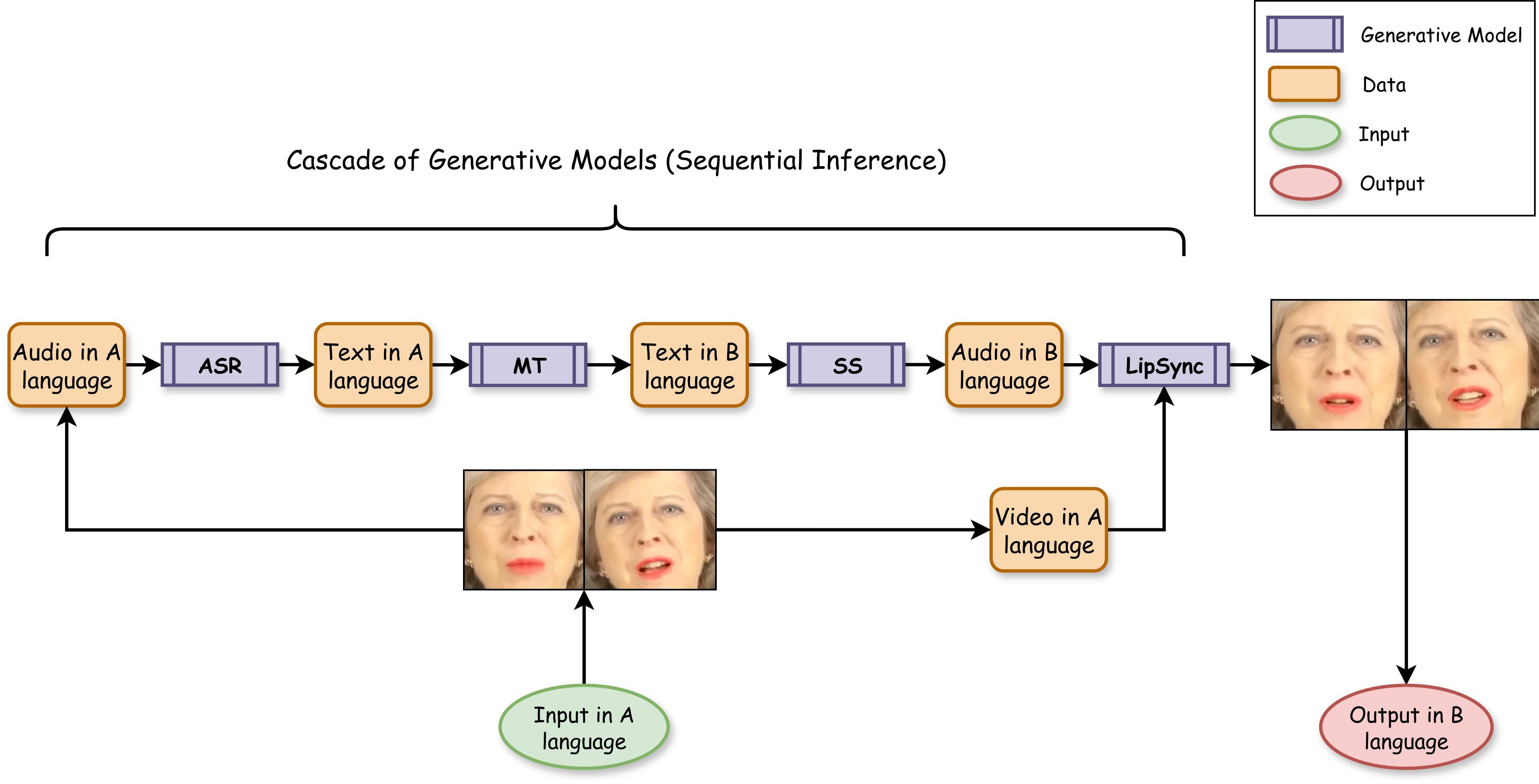
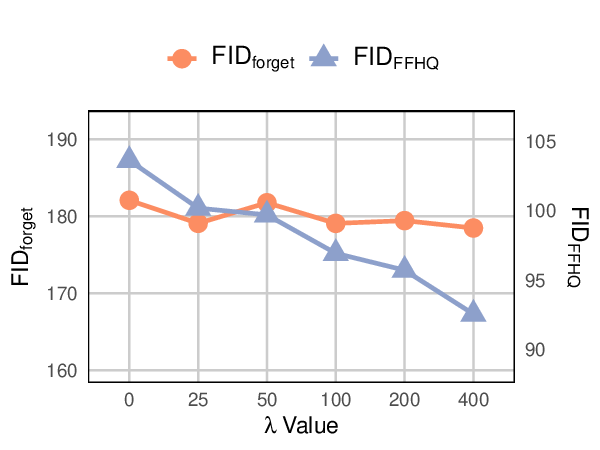
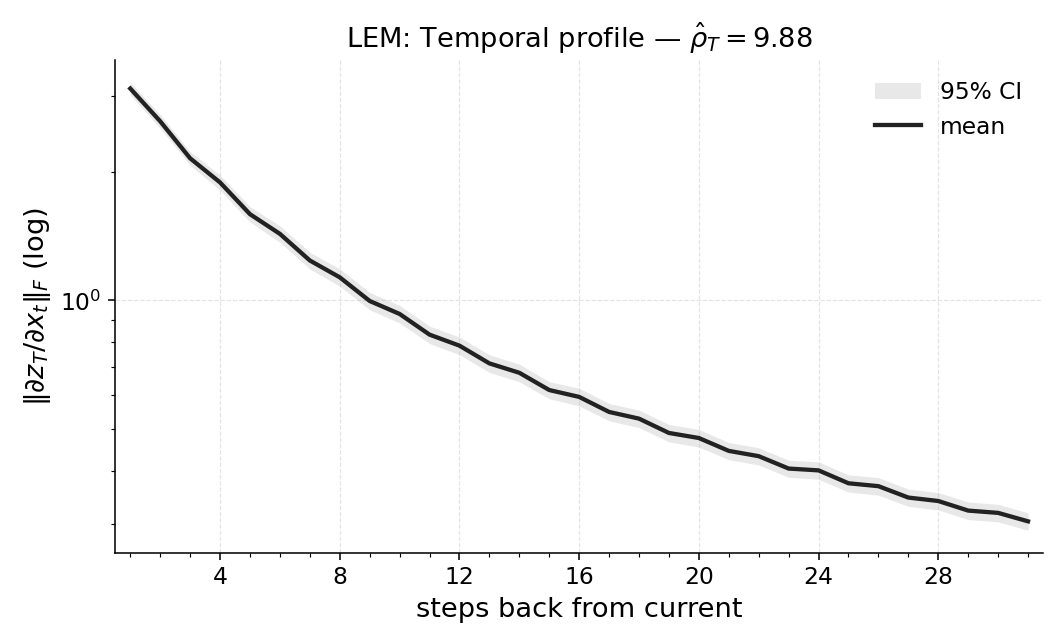
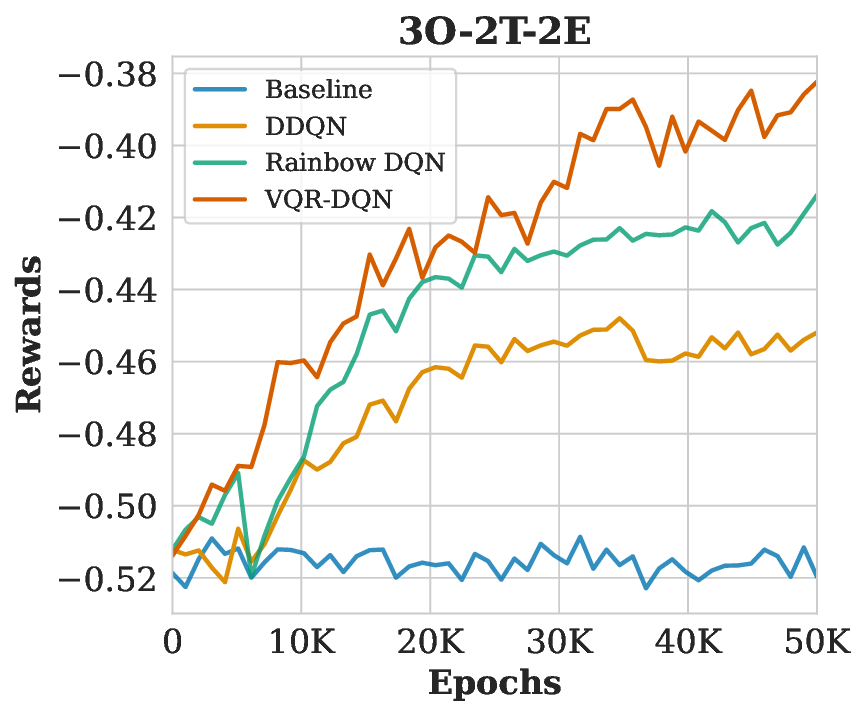
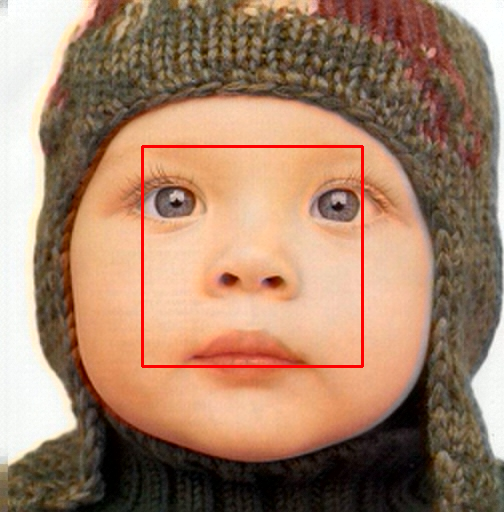
3차원 신경망 표현을 활용한 얼굴 이미지 통합 설명
본 연구는 3차원 신경망 표현을 활용하여 캘리브레이션되지 않은 여러 개의 인간 얼굴 이미지를 통합하고 일관된 설명을 제공하는 방법을 제시합니다. 특히, Gaussian Splatting 기법이 NeRFs보다 더 명확하게 구조화되어 있어 제약 조건에 잘 대응할 수 있다는 점에서 주목할 만한 연구입니다. 본 논문은 세그멘테이션 주석을 활용하여 얼굴의 의미적 영역을 정렬함으로써, 11장의 이미지만으로 중립 자세를 재구성하는 데 성공했습니다. 이는 기존에 긴 동영상이 필요했던 것과 대조되는 중요한 발전입니다. 또한 본 논문은 Gaussia