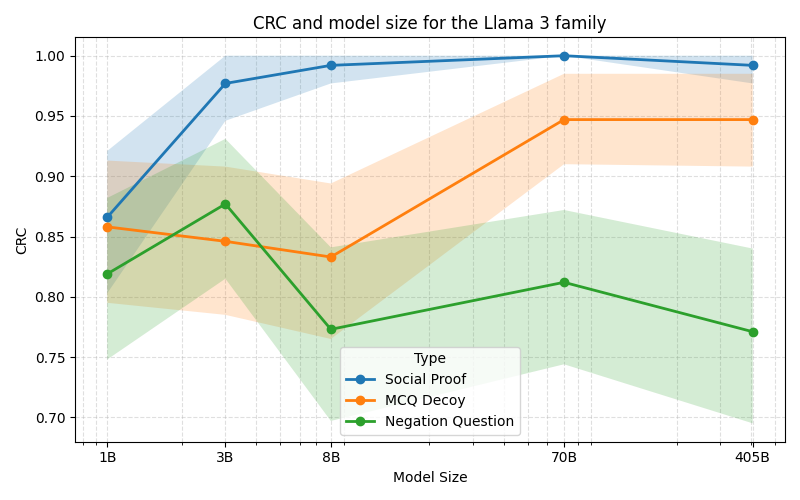
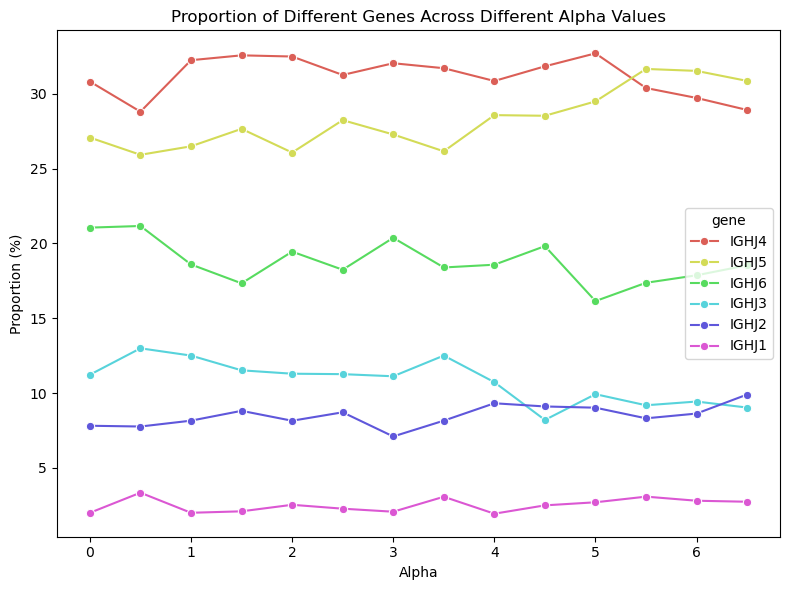
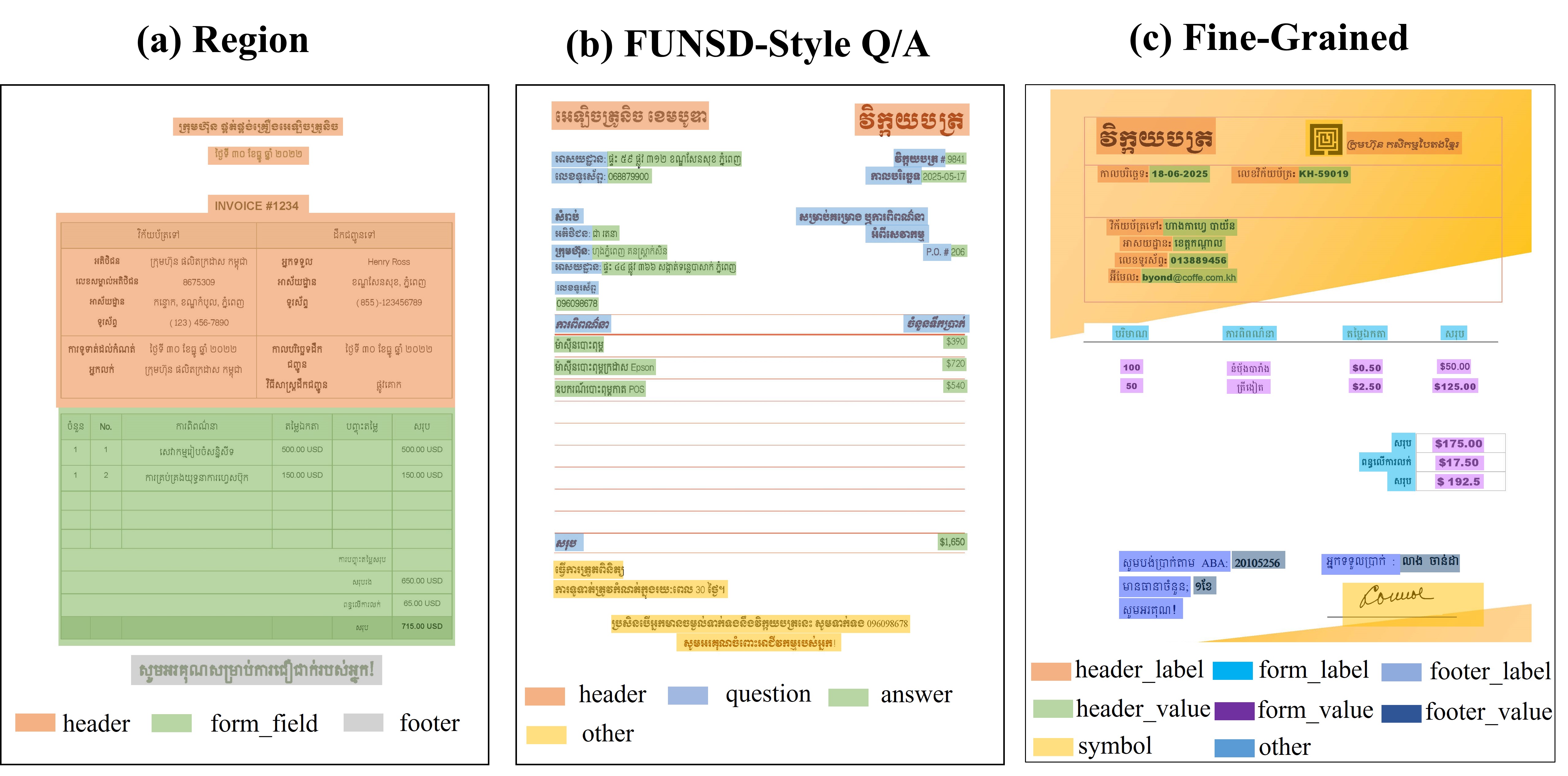
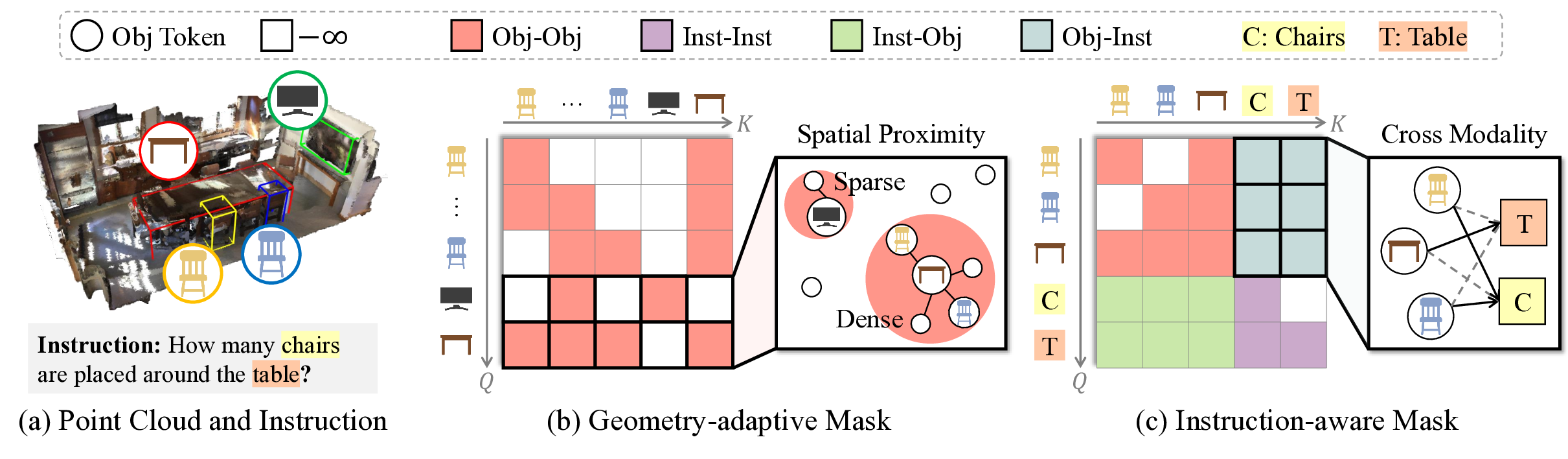
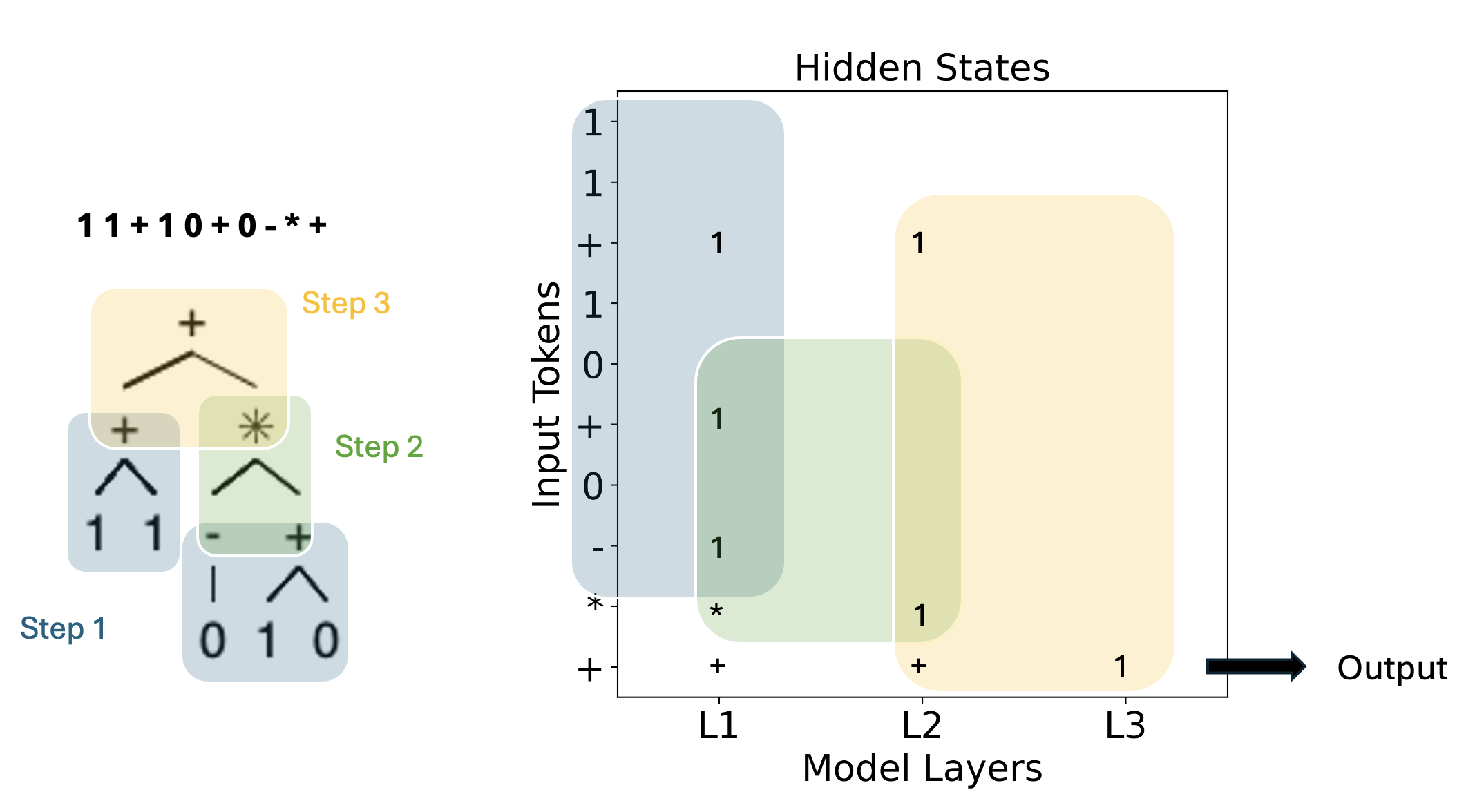
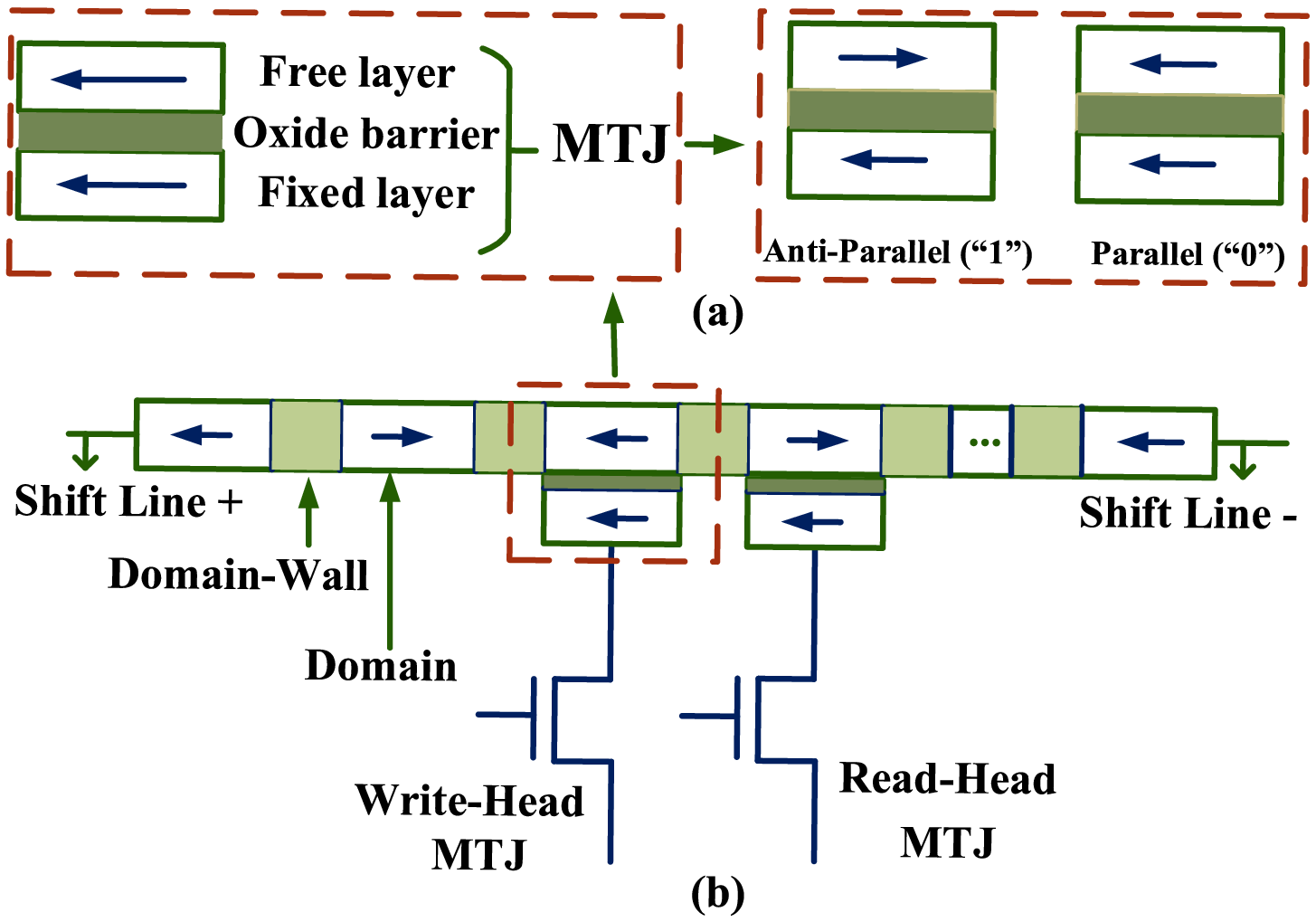
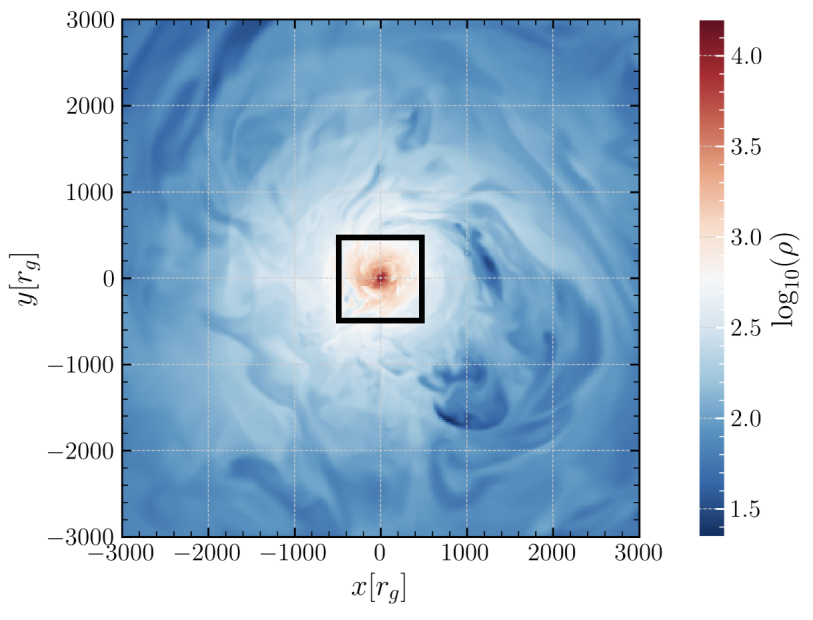
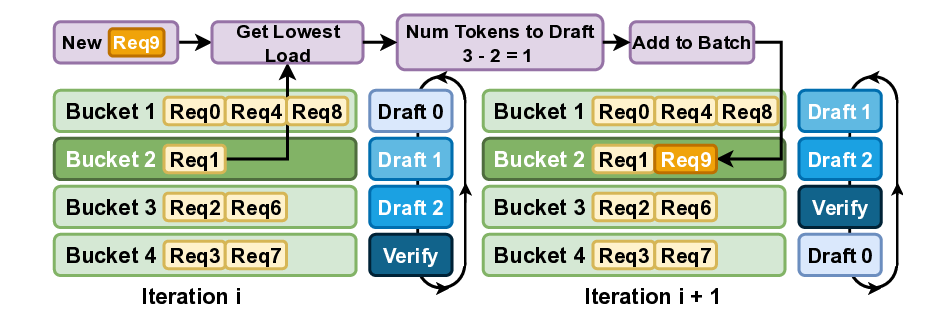
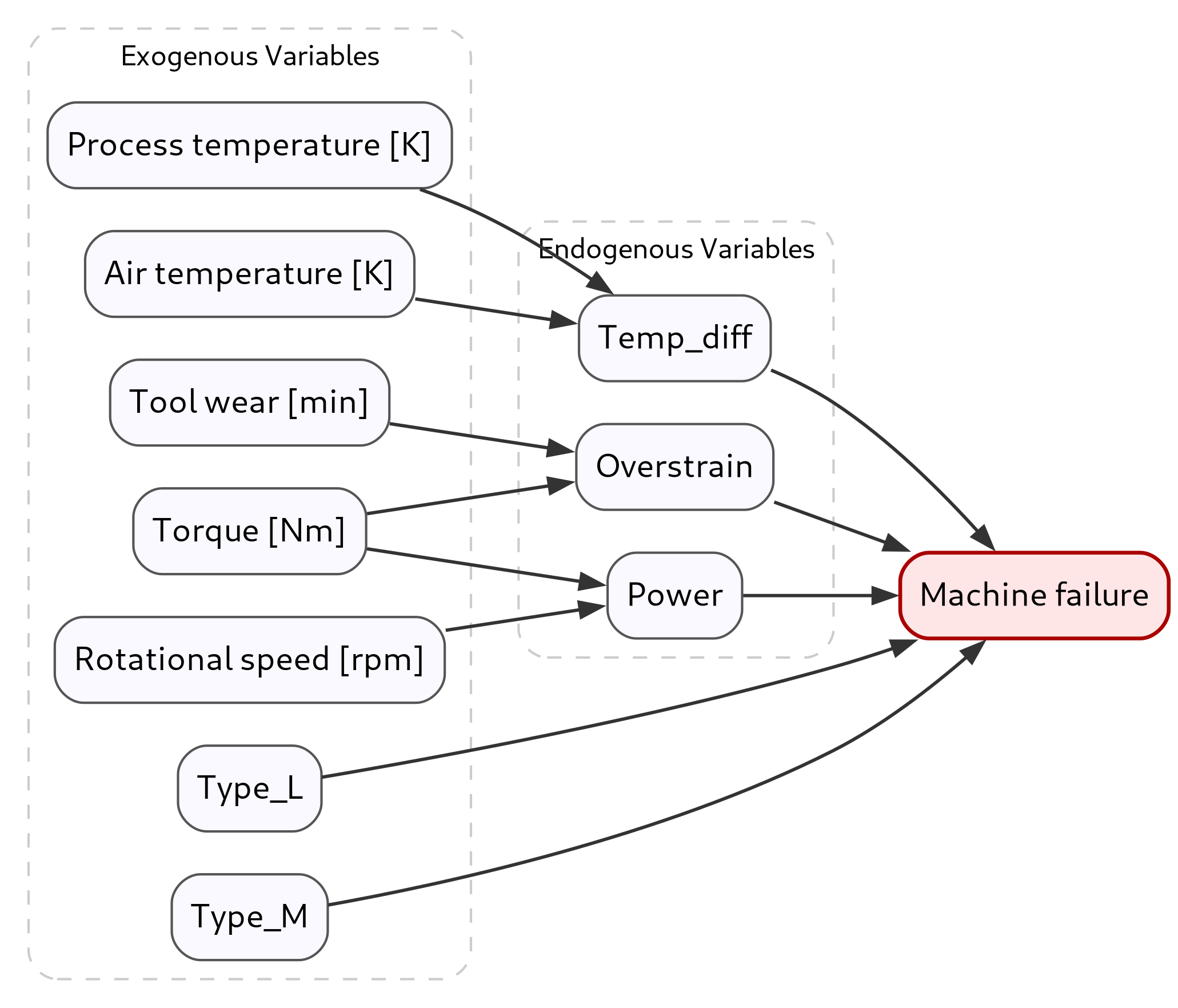
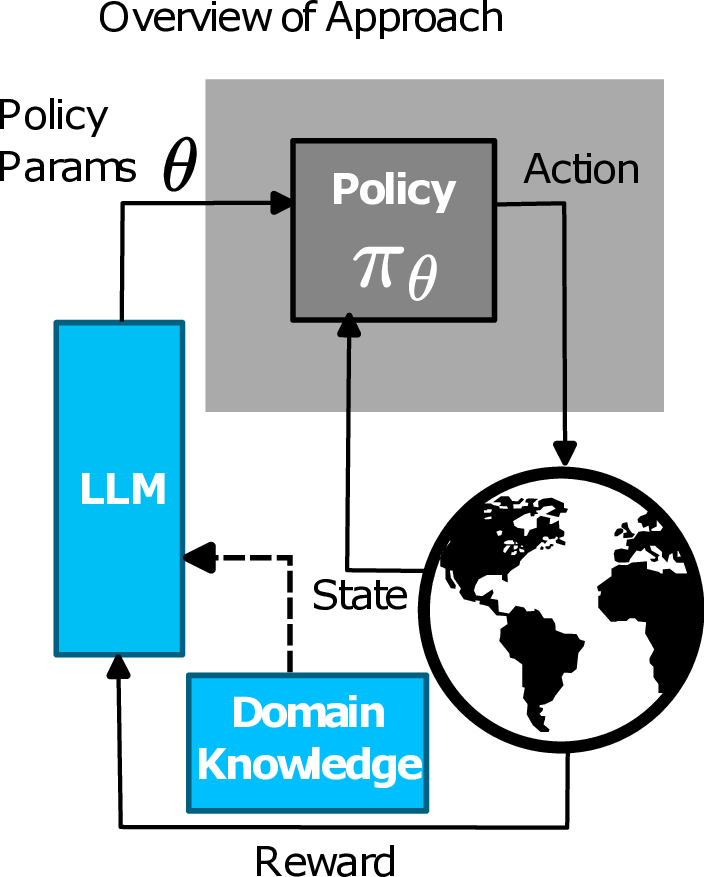
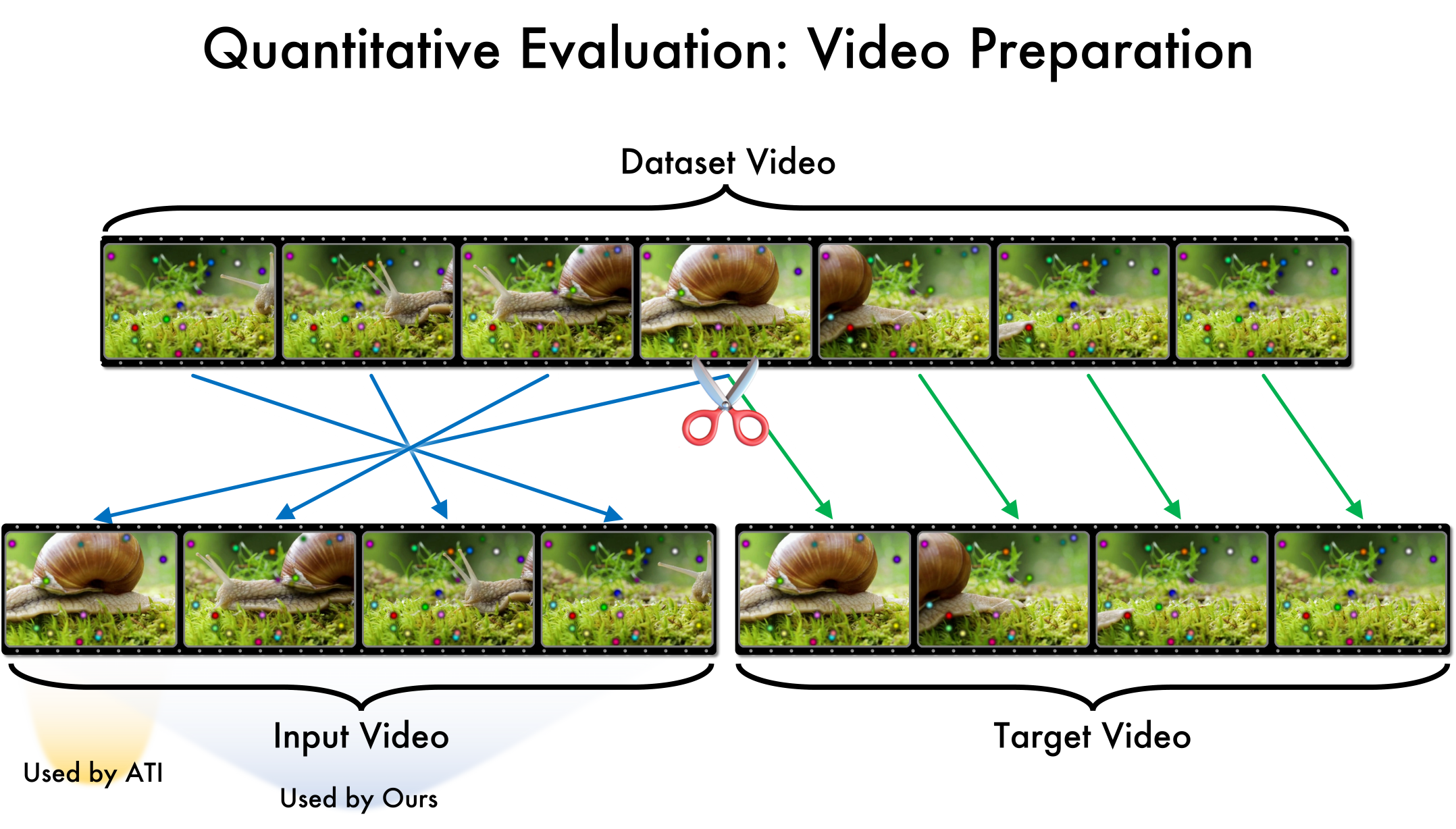
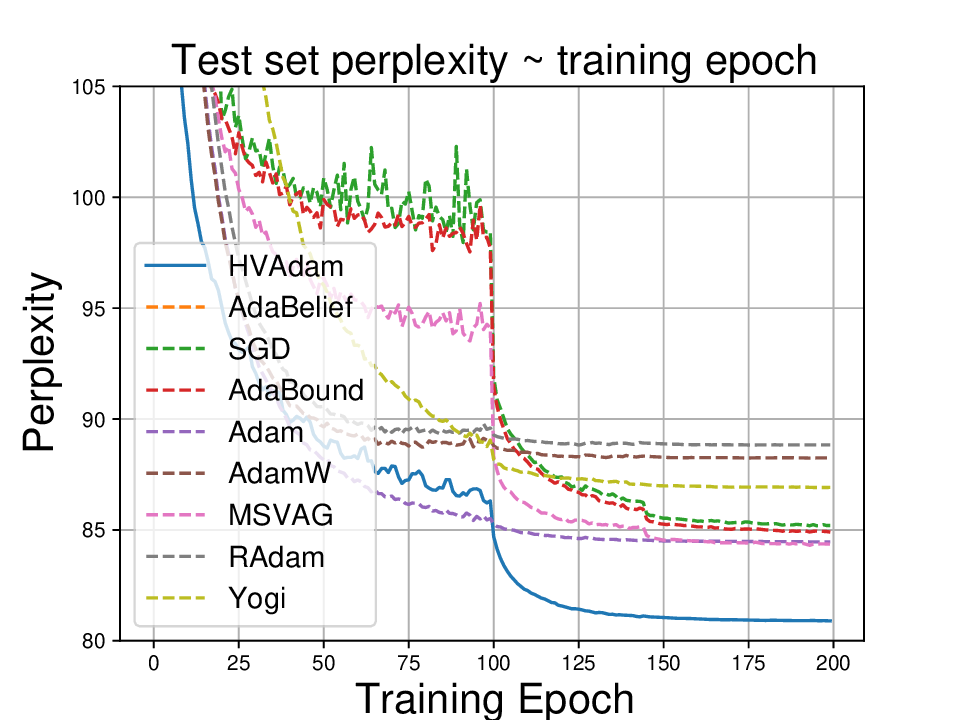
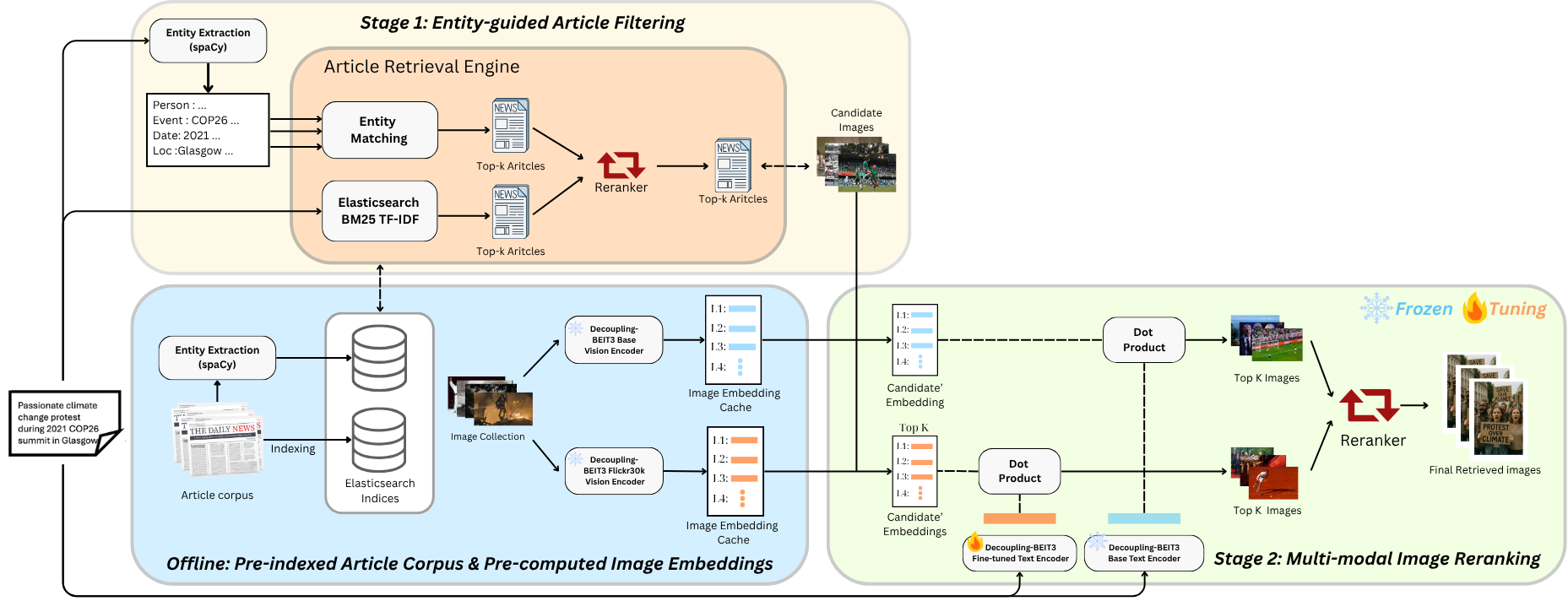
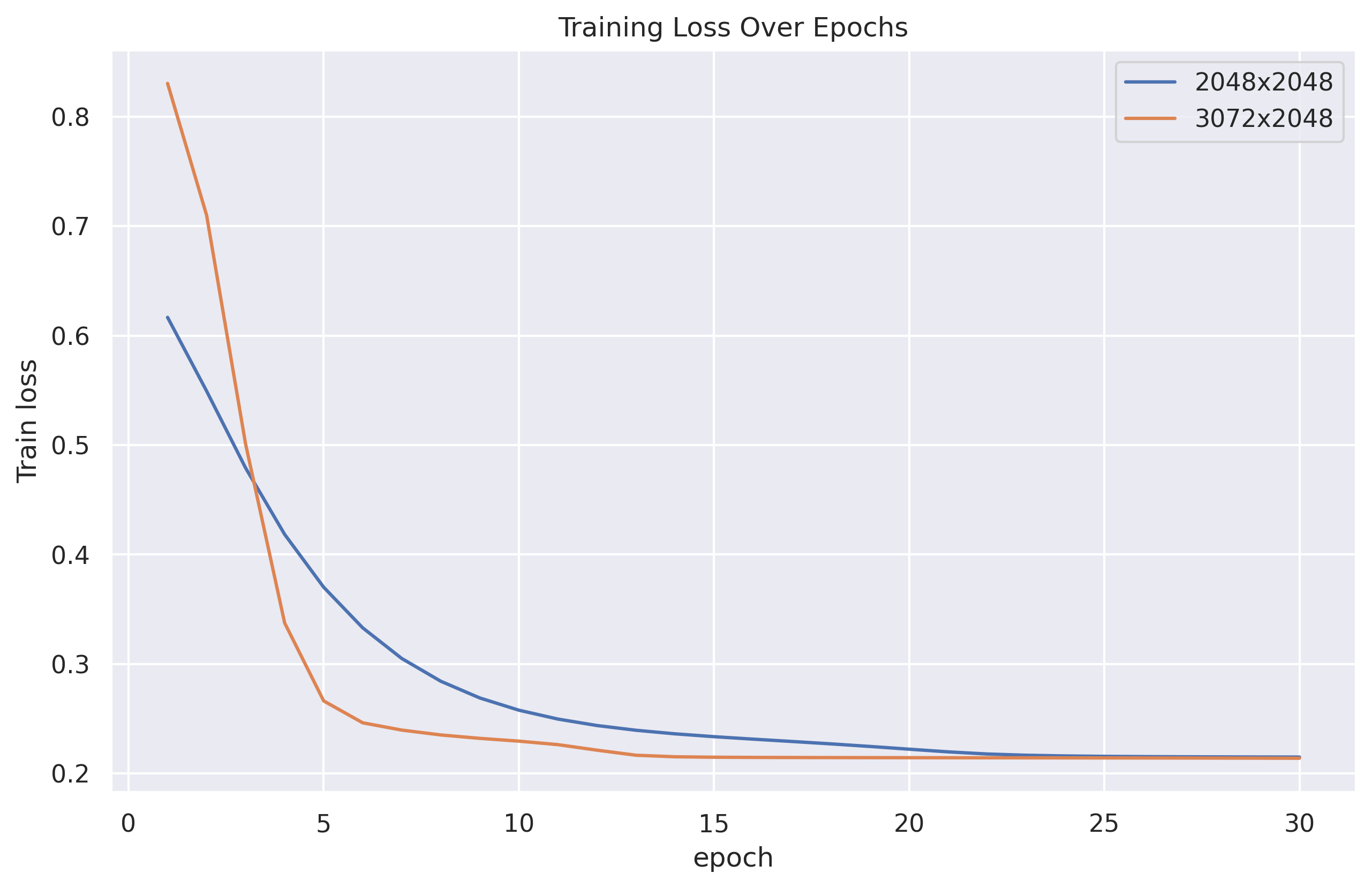
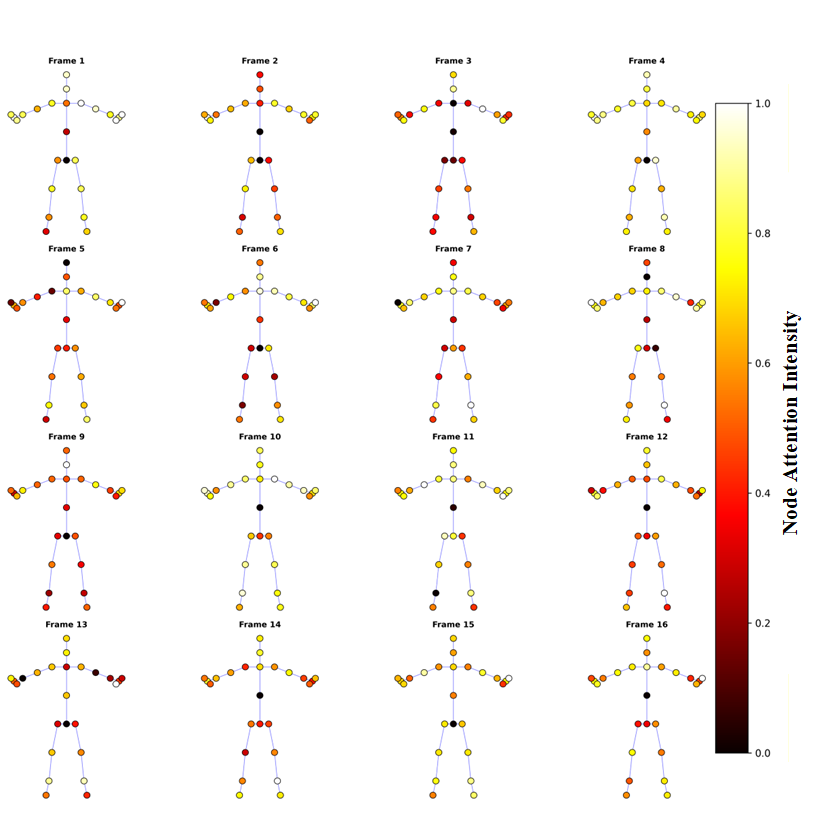
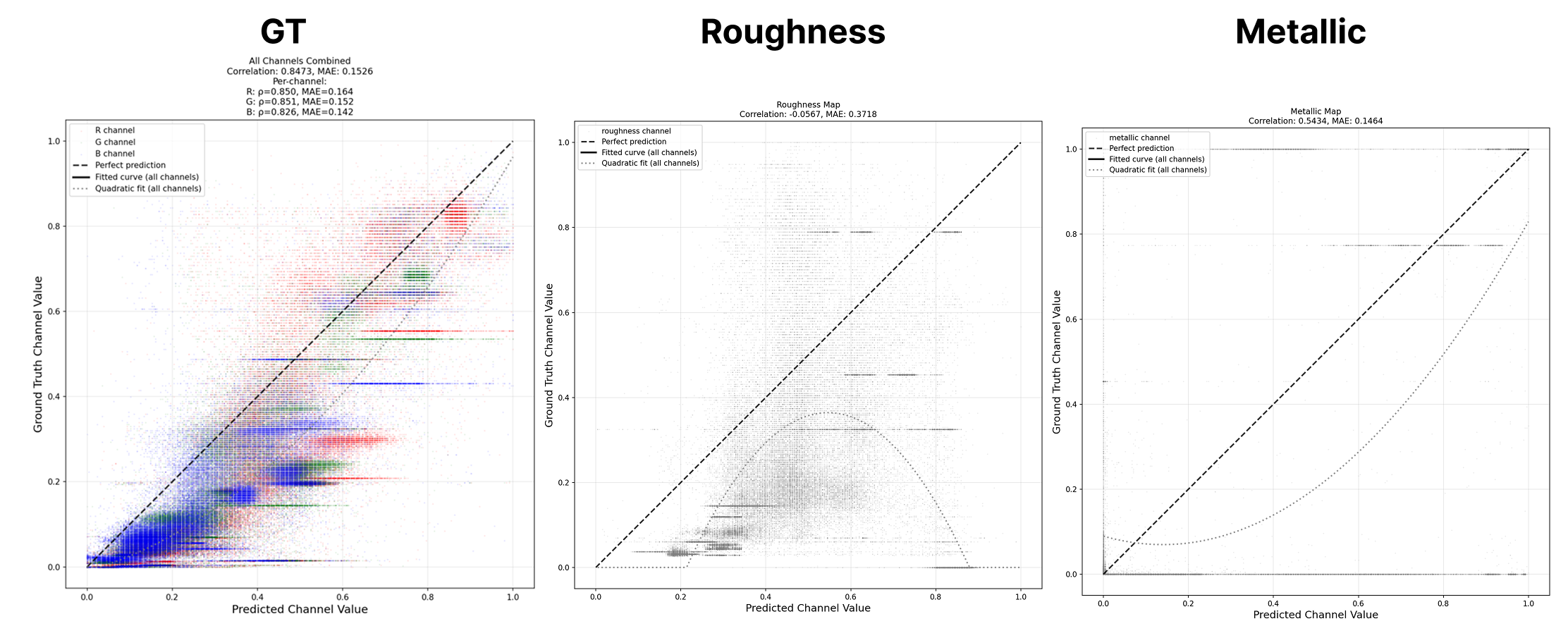
UltraShape 1.0이 만든 고품질 3D 에셋의 혁신
Paper Analysis Based on the Korean Translation Title and Abstract The paper titled 'UltraShape 1.0: An Innovative Deep Learning Approach for High Quality 3D Assets' introduces a novel deep learning framework designed to address challenges in generating high quality 3D assets. The abstract highlights