비조영 CT 기반 폐색전증 자동 진단을 위한 3D 딥러닝 모델
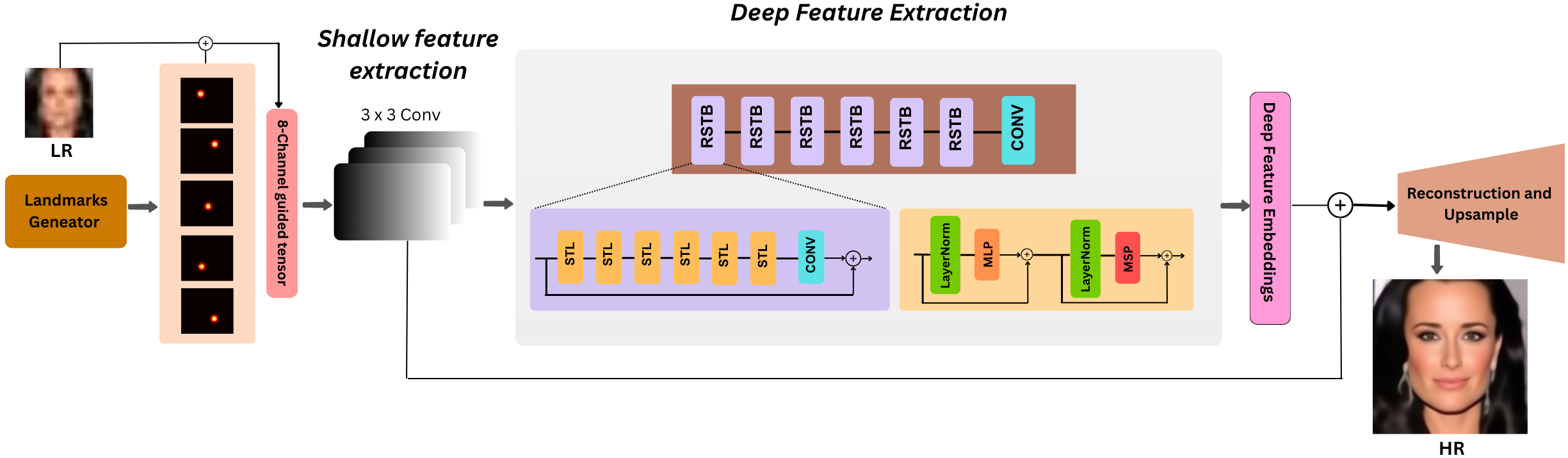
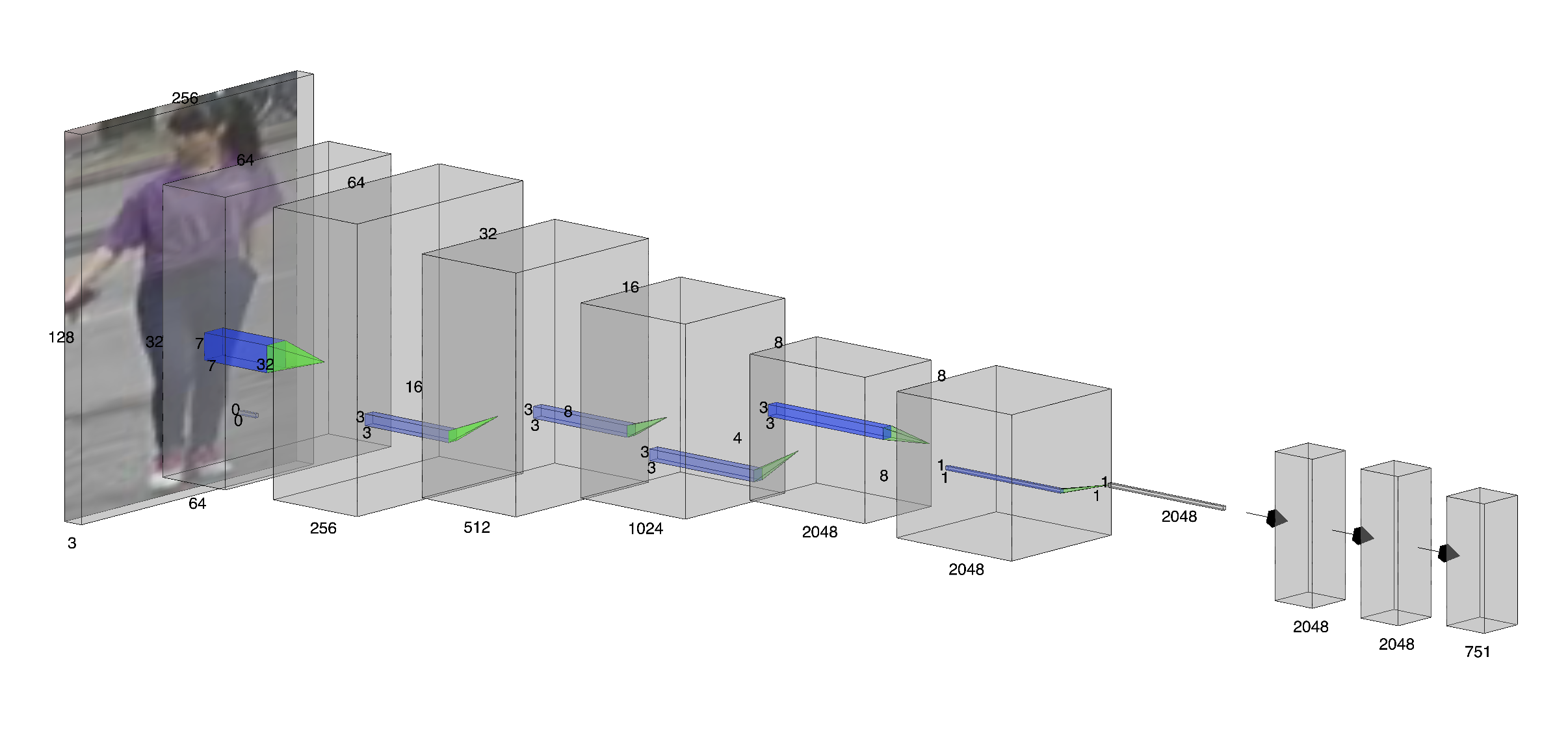
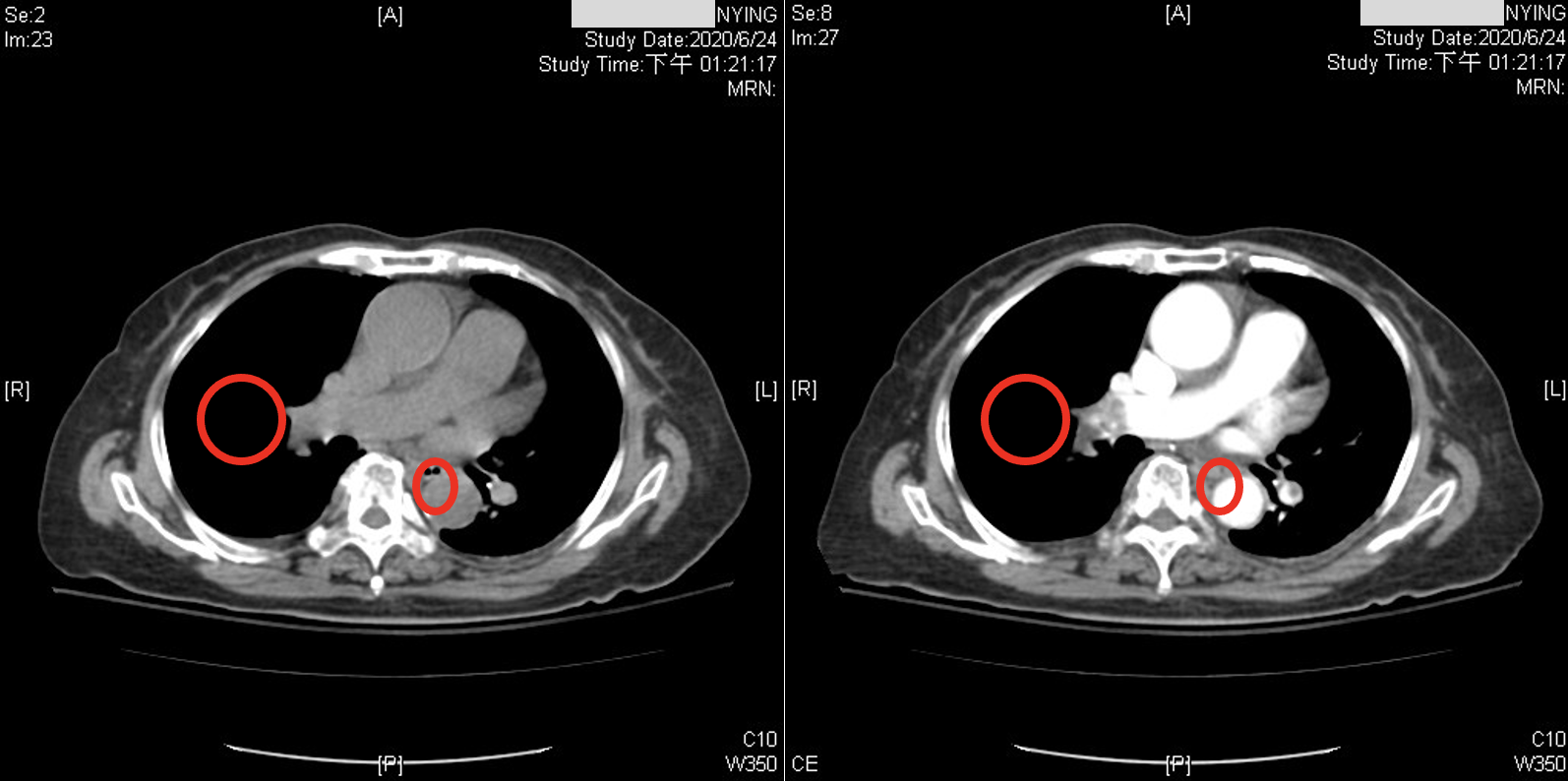
본 논문은 임상 현장에서 조영제 사용에 따른 부작용과 시간 지연 문제를 해결하고자, 비조영 CT 영상만을 이용해 폐색전증을 자동으로 판별하는 3D 합성곱 신경망(3D‑CNN) 모델을 개발하였다. 먼저 데이터셋 구축 단계에서 조영제 사용이 금지된 환자군과 기존 CTPA 영상에서 라벨링된 폐색전증 사례를 매칭시켜, 비조영 CT와 라벨 정보를 일치시켰다. 이는 라벨링 비용을 크게 절감하면서도 실제 임상 상황을 반영한 데이터베이스를 확보하는 전략이다. 모델 구조는 입력 볼륨을 3차원으로 처리하여 폐혈관 및 주변 조직의 미세한 밀도 차이를
Computer Vision
Computer Science
Learning