No Image
FlashInfer Bench AI 기반 LLM 시스템을 위한 선순환 구축
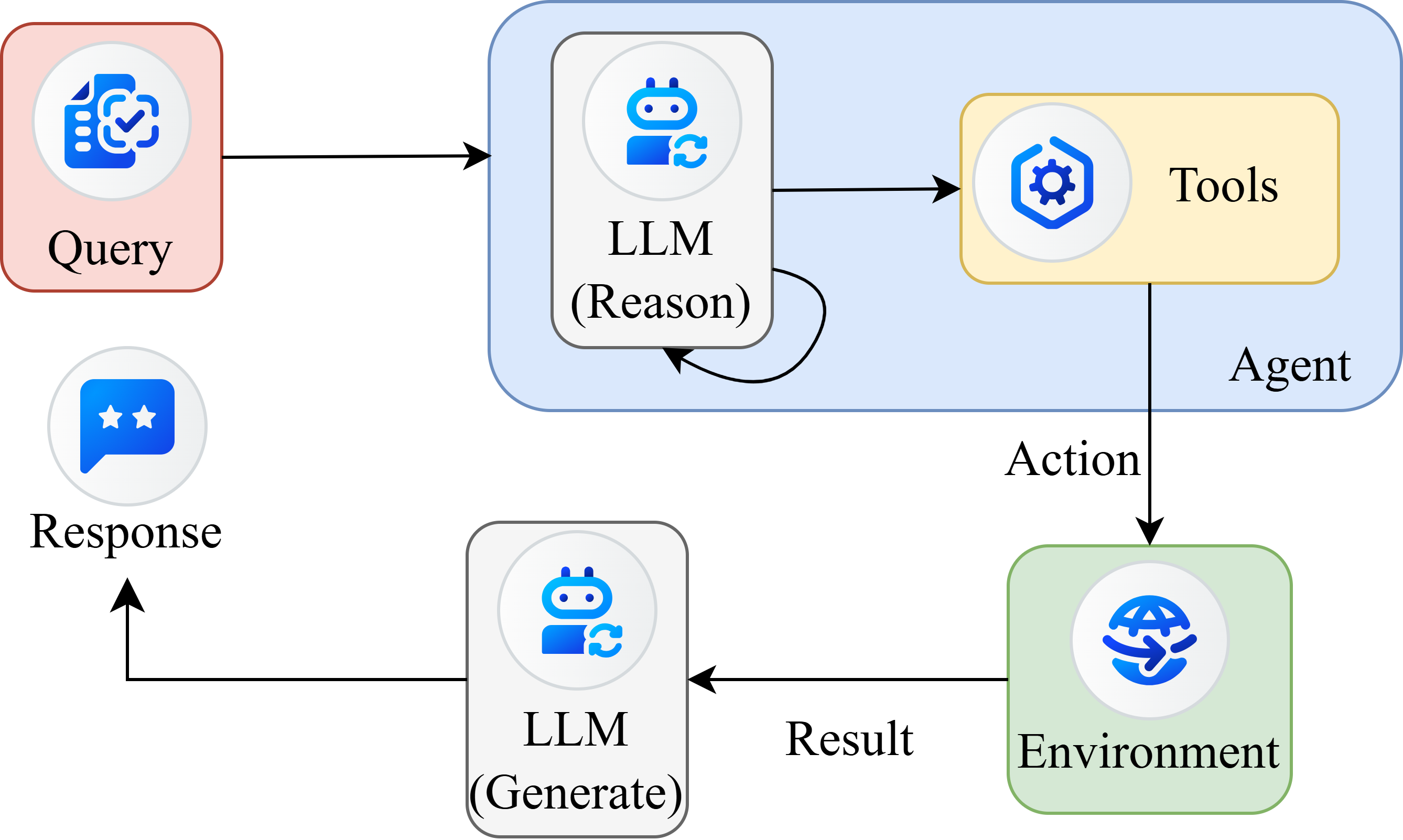
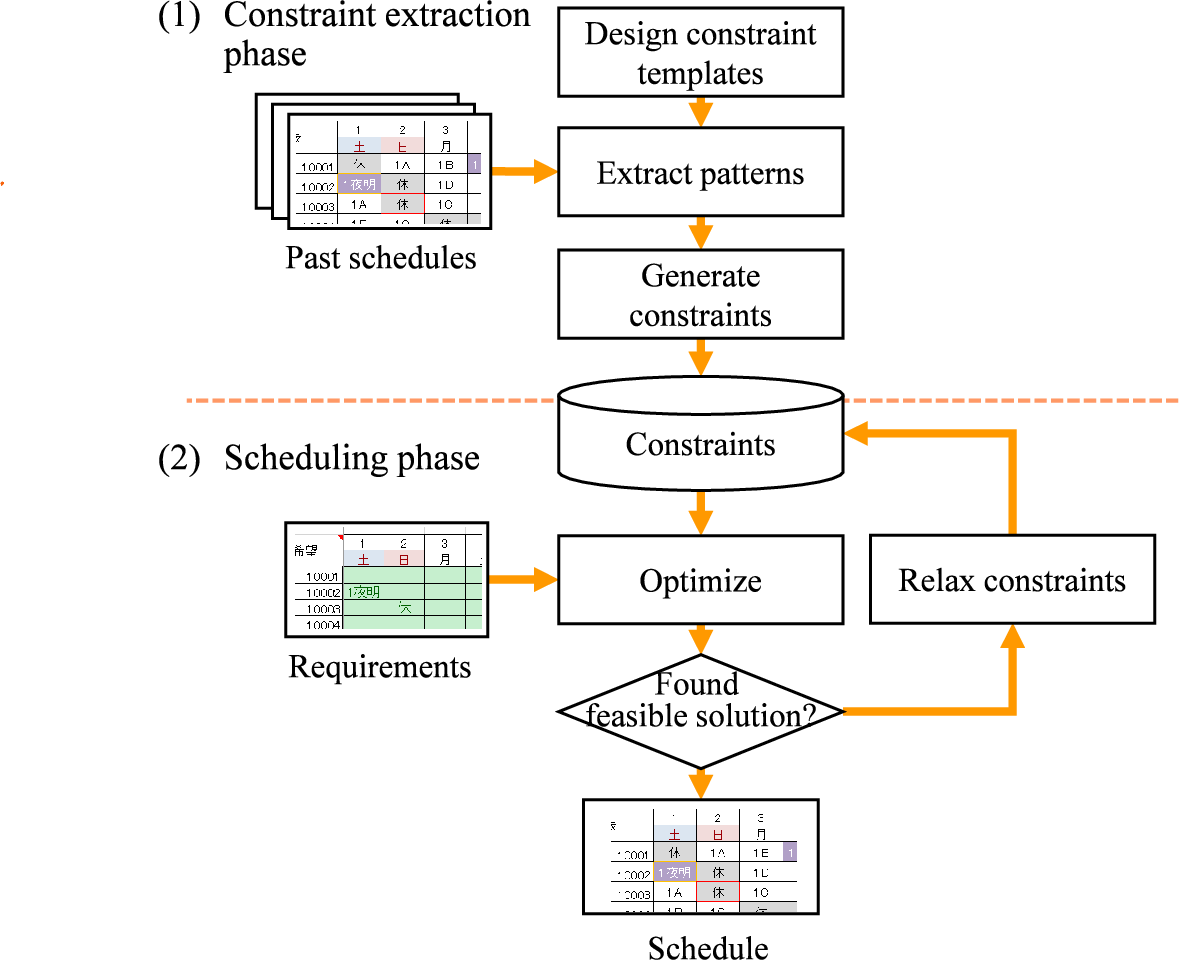
FlashInfer‑Bench 논문은 “AI‑generated GPU kernel”이라는 최신 연구 흐름을 실제 서비스 환경에 적용하기 위한 인프라스트럭처 설계라는 관점에서 매우 의미 있는 기여를 하고 있다. 첫 번째 핵심은 FlashInfer Trace 라는 메타데이터 스키마이다. 기존에 LLM이 생성한 코드를 단순히 텍스트로 저장하고 인간이 수동으로 검증하는 방식은 확장성이 떨어진다. Trace는 커널 인터페이스(입출력 텐서 형태, 메모리 요구량), 워크로드 특성(배치 크기, 시퀀스 길이), 구현 세부사항(언어, 컴파일 옵션)
Computer Science
Artificial Intelligence
System